��1�����е�æ,������10���С����2��3����,���ҵĸо����ǻ�������,�ض�ɽҡ��һ������Ե��������������,����ϸ�ڡ��ֽڵ�һ��������һ����Сʱ,��˼һ��,��Ļ����dz�����Ҫ,һЩ��С�����ܻ�����ᵽ��ҵ�����桢������������,������Ҫ�������רҵ��������ࡣ
������˵,���������ڱ��ʵ���һЩ���,Ҳ�鿴��ȫ������������,���ܽ���һЩ��Android���е�Java�⡣
���ڱ��˼�ʶ�dz�����,д�IJ��������д����������ĵط�,ϣ����λ�˲���ָ��һ����
Ŭ������,ʱ�ⲻ������������!
һ��Java����
1.JVM��JRE��JDK�Ĺ�ϵ
- JVM:Java�����,Java������Ҫ�����������
- JRE:Java�����+Java�������������
- JDK:Java�����+Java��������ĺ������(JRE)+Java�������߰�
2.̸̸������������ڵ���ʶ?
jvm(java�����)�еļ����Ƚ���Ҫ���ڴ�����,�⼸��������java���������
���а����űȽ���Ҫ�Ľ�ɫ:
- ������: ��java�����������һ��ר����������Ѿ����ص�����Ϣ����������̬�����Լ�����������ڴ�����,������������
- ������: �������Ƿ�������һ����,��Ҫ������ų��������еķ������õ���Ϣ��
- ����: ���ڴ����Ķ���ʵ����
- ջ��: Ҳ��java�����ջ,����һ��һ����ջ֡��ɵĺ���ȳ���ջʽ�ṹ,ջ���д�ŷ�������ʱ�����ľֲ��������������ڵ���Ϣ��������һ������ʱ,�����ջ�оͻᴴ��һ��ջ֡�����Щ����,�������������ʱ,ջ֡��ʧ,��������е�������������,�������ջ�������µ�ջ�塣
���DZ�дһ��java��Դ�ļ���,�������������һ������Ϊclass���ļ�,�����ļ������ֽ����ļ�,ֻ�������ֽ����ļ����ܹ���java�����������,java����������ھ���ָһ��class�ļ��Ӽ��ص�ж�ص�ȫ���̡�һ��java����������������ڻᾭ�����ء����ӡ���ʼ����ʹ�á���ж�������
3.̸̸�����������������̵�����
�������:�����������������Ҫ�IJ���,Ȼ���ú�������Щ����һ��һ��ʵ��
�������:�ѹ�����������ֽ�ɸ�������,Ȼ�������������Ϊ
�ٸ�����:��������:
- ������̵����˼·:1����ʼ��Ϸ,2����������,3�����ƻ���,4���ж���Ӯ,5���ֵ�����,6�����ƻ���,7���ж���Ӯ,8�����ز���2,9������������
- �����������˼·:1���ڰ�˫��,����������Ϊ��һģһ����,2������ϵͳ,������ƻ���,3������ϵͳ,�����ж����緸�桢��Ӯ�ȡ���һ�����(��Ҷ���)��������û�����,����֪�ڶ������(���̶���)���Ӳ��ֵı仯,���̶�����յ������ӵı仯��Ҫ��������Ļ������ʾ�����ֱ仯,ͬʱ���õ��������(����ϵͳ)������ֽ����ж�
4.������̺�����������ȱ��
�������:
- �ŵ�:���ܱ���������,��Ϊ�����ʱ��Ҫʵ����,�����Ƚϴ�,�Ƚ�������Դ;���絥Ƭ����Ƕ��ʽ������Linux/Unix��һ�����������̿���,����������Ҫ�����ء�
- ȱ��:û�����������ά�������á�����չ
�������:
- �ŵ�:���ܱ���������,��Ϊ�����ʱ��Ҫʵ����,�����Ƚϴ�,�Ƚ�������Դ;���絥Ƭ����Ƕ��ʽ������Linux/Unix��һ�����������̿���,����������Ҫ�����ء�
- ȱ��:û�����������ά�������á�����չ
�ٸ�����:
������̵ij�����һ�ݵ�����,�������ij�����һ�ݸǽ�����
�������ĺô�������ζ����,�������㡣���ǡ���㲻���Լ���,ֻ������˵Ļ�,��ôΨһ�İ취����������һ����˳����ˡ��ǽ�������һ�ݸDz˾Ϳ����ˡ��ǽ�����ȱ������ζ����,����û�е�������ô�㡣
�����ǵ������û��Ǹǽ�������?��ʵ�������ⶼ���ѻش�,��Ҫ�ȸ����¸ߵ͵Ļ�,�ͱ����趨һ������,����ֻ��˵�Ǹ��������������Ҷ�������ʳ��,û��ô�ི��,��ô�ӷ��ݽǶ������Ļ�,���ǽ�����Ȼ�ȵ�������������,��������ϳ������������,���Ҳ����˷ѡ�
�ǽ����ĺô�����"��"����"����,�Ӷ�����������ǽ���������ԡ���������ͻ���,�˲�����ˡ����������̵�רҵ�������"��ά����"�ȽϺ�,������ ��"��"����϶ȱȽϵ͡���������"��������"������һ��,�뻻"����"��"���κ�һ�ֶ�������,��϶Ⱥܸ�,������"��ά����"�Ƚϲ�����������Ŀ��֮һ���ǿ�ά����,��ά������Ҫ������3������:�������ԡ��ɲ����ԺͿ����ԡ��������ĺô�֮һ���������ĸ���������ϵͳ�Ŀ�ά���ԡ�
5.Java��C++������
- ����������������,��֧�ַ�װ���̳кͶ�̬
- Java���ṩָ����ֱ�ӷ����ڴ�,�����ڴ���Ӱ�ȫ
- Java�����ǵ��̳е�,�ӿڿ��Զ�̳�,C++֧�ֶ��ؼ̳�
- Java���Զ��ڴ��������,����Ҫ����Ա�ֶ��ͷ������ڴ�
- Java�ɿ�ƽ̨����,C++Ҫ��עƽ̨������
���������
6.&��&&������
| ����� | �������� | ˵�� |
|---|---|---|
| && | ��·�� | ��Ϊtrue��Ϊtrue,�����������ж�,��ʡ�������Դ�����������ٶ� |
| & | �������� | ȫ����Ҫ�ж� |
|| | ��·�� | ȫΪfalse��Ϊfalse,�����������ж�,��ʡ�������Դ�����������ٶ� |
| | �������� | ȫ����Ҫ�ж� |
7. "= =����equals����������ʲô����?
== �Ի������ͺ�������������Ч���Dz�ͬ��,������ʾ:
- ��������:�Ƚϵ���ֵ�Ƿ���ͬ;
- ��������:�Ƚϵ��������Ƿ���ͬ;
equals Ĭ������������ñȽ�,ֻ�Ǻܶ��������� equals ����,���� String��Integer �Ȱ��������ֵ�Ƚ�,����һ������� equals �Ƚϵ���ֵ�Ƿ����
8.�ؼ���final��static����ôʹ�õ�?
static�ؼ�����Ҫ����������:
- ��һ,Ϊij�ض��������ͻ������䵥һ�Ĵ洢�ռ�,���봴������ĸ����ء�
- �ڶ�,ʵ��ij��������������������Ƕ��������һ��
static���η���/����:static����һ�������̬����,���ھ�̬�������������κζ���Ϳ��Խ��з���,��˶��ھ�̬������˵,��û��this��;����Java�ж������λ�õIJ�ͬ,������������:��Ա�����;ֲ�����,����Ա���������������static�����ֿɷ�Ϊ�������ʵ������
- ��̬�����в���ֱ�ӷ��ʷǾ�̬��Ա�����ͷǾ�̬��Ա����,�Ǿ�̬��Ա������ֱ�ӿ��Է������г�Ա����/��Ա����
- ͬ���ֱ�ӵ��þ�̬����/�����,��ͬ��������.��̬����/�����
- ͬ��Ǿ�̬�������÷Ǿ�̬����/ʵ������ʱ,��ֱ�ӵ��÷�����()/ʵ��������;��������µ��÷Ǿ�̬������Ҫʵ��������ͨ��������÷Ǿ�̬����,���� ������ = new ����(); ������.��̬������()/ʵ��������;
- ��̬������,����ʹ��this�ؼ���, this�������ij��������Ե�,static���εķ�������������,��˲����ھ�̬��������this
static������:
- ʵ���ڲ���:ֱ�Ӷ������൱�е�һ����,����ǰ��û���κ�һ�����η���
- ��̬�ڲ���:���ڲ���ǰ�����һ��static��
- �ֲ��ڲ���:�����ڷ������е��ڲ���,�ֲ��൱�в���ʹ��static����,����ʹ�� public��protected��private ���Ρ�
- �����ڲ���:���ھֲ���һ�����������
final�����/����/��
- final�в��ɸı�,���յ���˼,�����������ηdz����ࡢ��Ա�����ͱ���
- ������:��������������µ�����,������Ϊ���౻�̳С����,һ�����ͬʱ������Ϊabstract �� final,������Ҫ������,���Բ�����final����
- ���η���:�÷������ܱ�������д��
- ���α���:�ñ�������������ʱ������ֵ,�����Ժ�ֻ�ܶ�ȡ,�����ġ� ��������Ƕ���,��ָ�������ò�����,���Ƕ�������Ի��ǿ����ĵġ�
9.switch����Ŀ��Ʊ���ʽ
- JDK1.0 - 1.4? ? �������ͽ��� byte short int char
- JDK1.5 ? ? �������ͽ��� byte short int char enum(ö��)
- JDK1.7? ? �������ͽ��� byte short int char enum(ö��), String,��Ӧ�İ�װ����
10.��Ա�����;ֲ�����������
| ��ͬ�� | �ֲ����� | ��Ա���� |
|---|---|---|
| ����λ�� | �����ڲ� | �����ⲿ |
| ���÷�Χ | �������� | ������ |
| Ĭ��ֵ | �ֶ���ֵ | ��Ĭ��ֵ |
| �ڴ�λ�� | ջ�ڴ� | ���ڴ� |
| �������� | ������ջ������,������ջ����ʧ | ����������,�����������ն���ʧ |
11.lamda����ʽ�˽��?
Lambda��ǰ������
- Lambdaֻ�������滻���ҽ���һ�������Ľӿں������ڲ������,���ֽӿڳ�Ϊ����ʽ�ӿ�
- Lambda�����������ƶϵĹ���,�������DzŻ����Lambda��ʡ�Ը�ʽ
Lambda��ʹ�ó���
- �б�����:����б���ÿ��Ԫ��
- �¼�����
- Predicate �ӿ�
- Map ӳ��
- Reduce �ۺ�:�Զ��������й��˲�ִ����ͬ�Ĵ�����
- ���� Runnable:�����߳�
12.�������ʽ���չ���,����Ŀ������ô�õ���
�������ʽ��һ������ƥ���ַ�����ǿ����������,��һ�������Ե����Զ���һ������,���Ƿ��Ϲ�����ַ���,���Ǿ���Ϊ����ƥ�䡱��
ʹ�ó���:
- ������Ч����֤:�û�ע��ģ����Ӧ���������ʽ��еĵط�,��Ҫ��������֤�û��ʺš����롢EMAIL���绰���롢QQ���롢����֤���롢��ͥ��ַ����Ϣ�������д���������������ʽ��ƥ��,���Զ϶���д�������Dz��Ϻ�Ҫ�����ٵ���Ϣ;
- ģ����ѯ,�����滻:�������ĵ���ʹ��һ���������ʽ������ƥ����ض�����,Ȼ�����ȫ������ɾ��,�����滻Ϊ������֡�
Android���������ʽ���÷�:
- ������:
? ?Pattern:�������ʽ�ı����Ķ�����ʽ,������ģʽ: ��һ���ַ���ת������ƥ��ģʽ����
? ?Matcher������ģʽƥ������ַ�����ƥ����,Pattern�������ƥ����matcher()����,���ҷ���ƥ��Ҫ���ƥ����
13.ʲô�Dz��� & װ��,�ܸ��Ҿ�������?
����:��װ����ת��Ϊ��������
װ��:��������ת��Ϊ��װ����
Integer i1 = 40;Integer i2= 40;���бȽ�ʱ,��������int��װ��Ϊ��װ����Integer����Java��,�������ͱȽϵ���ֵ,����װ���ͱȽϵ��Ƕ���ĵ�ַ��������������װ�������ͬһ��������ΪInteger��,�����漰���������,��������Ļ�������intֵ��-128��127֮��Ļ�,�ͻ�ֱ��ȥcache������ȡ,������������Χ�Ļ�,��ô�ͻᴴ�µĶ���
`ƽ��������Java��ʹ�õĶ���HashMap������������,������һ�����ص��������HashMap���key�Լ�value���Ƿ���,��ô�ͻ�ɱ��������װ��Ͳ���Ĺ���,����������Ǻܺ�ʱ��,����Ϊ�˹��װ��������Ч��,���ǵ�����SparseArray�ȼ�����,����SparceArrayЧ�ʸ�Ҳ����������,���������������Ƚ�С�ij���,����Android������,�ֳ��������������Ƚ�С��,�����ݺܴ�������,��Ȼ����hashmapЧ�ʽ��š�
����ʵ�����
14.����ʱ���˽�?̸̸������Щҵ��?
�л�ʱ���ʽ,���Ӳ�ͬ����ʱ���ù���,�õ���TextClock��Calendar��SimpleDateFormat��AlarmManager�ࡣ
TextClock��setFormat24Hour��������24Сʱ�ƶ�/12Сʱ��
Calendar��SimpleDateFormat��,���õ�ǰʱ���Լ���ǰʱ����ʾ�ĸ�ʽ
AlarmManager��:setTimeZone(String timeZone)������������ϵͳ��Ĭ��ʱ������Ҫandroid.permission.SET_TIME_ZONE.Ȩ��:mAlarmManager = (AlarmManager) getContext().getSystemService(Context.ALARM_SERVICE);
15.�ַ����ĸ���
���л�ϵͳ����ʱ,���õ�һЩ��string��д�����в�ͬ,һ�����������ַ�ʽѡ��:
.�ַ����ķ�ת
- charAt():ͨ��String���charAt()�ķ�������ȡ�ַ����е�ÿһ���ַ�,Ȼ����ƴ��Ϊһ���µ��ַ���
- toCharArray():ͨ��String��toCharArray()�������Ի���ַ����е�ÿһ���ַ���ת��Ϊ�ַ�����,Ȼ����һ���յ��ַ����Ӻ���ǰһ������ƴ�ӳ��µ��ַ�����
- reverse():ͨ��StringBuiler��StringBuffer��reverse()�ķ���
�ַ����滻
- replace():�滻�ַ���������ָ�����ַ�,Ȼ������һ���µ��ַ���,ԭ�����ַ����������ı�
- replaceAll():�ַ�����ij��ָ�����ַ����滻Ϊ�����ַ���
replaceFirst():�滻��һ�����ֵ�ָ���ַ���
ArrayMap��key-value�ı��ַ���
��֤keyֵ��ͬ,ѡ��ͬϵͳ����ʱ,�ı�valueֵ:
if(true){
arrayMap.put(��A��, ��GB��);
}else {
arrayMap.put(��A��, ��GA��);
16.String��StringBuilder��StringBuffrer������
- String���Dz��ɱ���,�κζ�String�ĸı䶼�������µ�String���������;
- StringBuffer�ǿɱ���,�κζ�����ָ�����ַ����ĸı䶼��������µĶ���,�̰߳�ȫ�ġ�
- StringBuilder�ǿɱ���,���Բ���ȫ��,��֧�ֲ�������,���ʺ϶��߳���ʹ��,�����ڵ��߳��е����ܱ�StringBuffer�ߡ�
�ġ��̳�
17.̸һ̸��ֵ���ݺ����ô��ݵ�����
�������ʹ�����ջ��ַ�Ĵ���,�����κ�һ�����ñ�������Ӱ�쵽�ڶ��ڴ���ʵ�ʶ����ֵ
�����ʹ����Ǿ���ֵ����,����ڱ����ݺ����иı��������������ֵ,����ı�ԭʼ��ֵ
18.super �� this ����ͬ
ָ���ϵ�����
- super:�ǶԵ�ǰ�����и���������á�
- This:ָ��ǰ����IJο���
���ö����ϵ�����
- super:ֱ�Ӹ��������õ�ǰ����ij�Ա(��������Ա�������������ͬ��Աʱ,���ڷ���ֱ�Ӹ��������ظ����еij�Ա���ݻ�������)��
- This:��ʾ��ǰ���������(���������׳�������ĵط�,Ӧ��������ʾ��ǰ����;��������ij�Ա����������г�Ա���ݵ�������ͬ,Ӧ���ڱ�ʾ��Ա��������)��
���ú����ϵ�����
- super:�ڻ����е��ù��캯��(�ǹ��캯���еĵ�һ�����)��
- This:�ڴ����е�����һ���ṹ���Ĺ��캯��(�ǹ��캯���еĵ�һ�����)��
�塢��̬
19.����(Overload)����д(Override)������
���������غ���д����ʵ�ֶ�̬�ķ�ʽ,��������ǰ��ʵ�ֵ��DZ���ʱ�Ķ�̬��,������ʵ�ֵ�������ʱ�Ķ�̬�ԡ�
����:һ�������ж��ͬ���ķ���,���Ǿ����в�ͬ�IJ����б�(�������Ͳ�ͬ������������ͬ���߶��߶���ͬ)��
��д:�����������븸��֮��,����Ը���ķ���������д,���������ܸı�,����ֵ���Ϳ��Բ���ͬ,���DZ����Ǹ����ֵ�������ࡣ����Dz���,������д!��д�ĺô�����������Ը�����Ҫ,�����ض����Լ�����Ϊ��
| ��д | ���� | |
|---|---|---|
| �Ƿ�ͬ�� | ����ͬ�� | ��ͬ��Ҳ�ɲ�ͬ�� |
| �������IJ�����ʽ�Ƿ���ͬ | ������ͬ | ���벻ͬ |
| �������� | ������ͬ | ��ͬ�ɲ�ͬ |
| �������η� | ����ܱȸ���Ȩ��С | ��Ҫ�� |
| �������쳣 | �����׳��µ��쳣���쳣���ܷ�Χ��� | ��Ҫ�� |
| ���췽�� | ���ܱ���д | ���Ա����� |
| ��̬ʵ�ַ�ʽ | ʵ������ʱ��̬ | ʵ�ֱ���ʱ��̬ |
20. �ӿ�����������ͬ
���Ƶ�
- ���߶��ɰ���������ʵ�ֳ�����ͽӿڵķdz��������ʵ����Щ����
- ���߶���������ʵ��������������������ͽӿڵı���,�Գ�������˵,Ҫ�ó�����ķdz���������ʵ�����ñ���;�Խӿ���˵,Ҫ��ʵ�ֽӿڵķdz���������ʵ�����ñ���
- ���ߵ����������û��ʵ�ֳ�����(�ӿ�)�����������г���,���������dz�����
- ���߶�����ʵ�ֳ���Ķ�̬��
��ͬ��
- һ����ֻ�ܼ̳�һ��ֱ�Ӹ���,���ǿ���ʵ�ֶ���ӿ�
- �����������ʹ�� extends ���̳�;�ӿڱ���ʹ�� implements ��ʵ�ֽӿڡ�
- ����������й��캯��;�ӿڲ����С�
- ����������� main ����,����������������;�ӿڲ����� main ������
- �ӿ��еķ���Ĭ��ʹ�� public ����;�������еķ�������������������η���
- ���������Java 8 �� lambda ����ʽ��ʹ��
- �ӿ����ֵ���һ�ֹ淶(��ӡ����������д�ӡ�Ĺ���),��ʵ�ֽӿڵ������в����ڸ����ӵĹ�ϵ;����������������ڸ����ӵĹ�ϵ(Բ�κͷ��ζ���һ����״)
���� �쳣����
21. Exception��Error������,RuntimeException
Error(����):ͨ���������Ե���������,���dz���(����Գ)���Կ��Ƶ�,���ڴ�ľ���JVMϵͳ����ջ����ȡ�Ӧ�ó���Ӧ��ȥ�����������,�ҳ���Ա��Ӧ��ʵ���κ�Error������ࡣ
Exception(�쳣):�û����ܲ�����쳣���,����ʹ������ԵĴ�����д���,��:��ָ���쳣�����������жϡ������±�Խ��ȡ�
RuntimeException�༰��������Ϊ�Ǽ�����쳣,Java���������Զ������쳣������ԭ��������Ӧ���͵��쳣,�����п���ѡ����Ҳ���Բ�����,��ȻJava����������������ʱ�쳣,����Ҳ����ȥ���в�����׳�������RuntimeException��������Լ�Error��Ƿ��ܼ��쳣��
22.�����쳣����
Java �������쳣���Է�Ϊ�ܼ��쳣(checked exception)�ͷ��ܼ��쳣(unchecked exception)��
�ܼ��쳣
������Ҫ����봦�����쳣��Exception �г� RuntimeException ��������֮����쳣�������ܼ��쳣����������������쳣,Ҳ����˵����������鵽Ӧ���е�ij�����ܻ�����쳣ʱ,������ʾ�㴦�����쳣����Ҫôʹ��try-catch����,Ҫôʹ�÷���ǩ������ throws �ؼ����׳�,������벻ͨ����
���ܼ��쳣
������������м�鲢�Ҳ�Ҫ����봦�����쳣,Ҳ��˵�������г��ִ����쳣ʱ,��ʹ����û��try-catch������,Ҳû��ʹ��throws�׳����쳣,����Ҳ������ͨ���������쳣��������ʱ�쳣(RuntimeException��������)�ʹ���(Error)��
����ʱ�쳣
����:RuntimeException �༰�����ࡣ
�ص�:RuntimeExceptionΪJava�����������ʱ�Զ����ɵ��쳣,�类����ͷǷ��������������������鷶Χ�����ļ������ڵȡ������쳣�ij��־���������Ǵ��뱾��������Ӧ�ô�����ȥ������Ľ����롣
RuntimeException�༰�������Ϊ�Ǽ�����쳣,Java���������Զ������쳣������ԭ��������Ӧ���͵��쳣,�����п���ѡ����Ҳ���Բ�����,��ȻJava����������������ʱ�쳣,����Ҳ����ȥ���в�����׳�������RuntimeException��������Լ�Error��Ƿ��ܼ��쳣��
����ʱ�쳣
�ص�: Exception�г�RuntimeException��������֮����쳣,���쳣�����ֶ��ڴ��������Ӳ���������������쳣������ʱ�쳣Ҳ��Ϊ�ܼ��쳣,һ�㲻�����Զ������쳣����
23. Java������ν����쳣����,�ؼ���:throws��throw��try��catch��finally�ֱ����ʹ��?
try����д�ŵ��ǿ��ܷ����쳣����䡣���쳣�׳�ʱ,�쳣�������Ƹ�����Ѱ�������쳣������ƥ��ĵ�һ����������,Ȼ�����catch�����ִ��,��ʱ��Ϊ�쳣�õ��˴���������������������ݺܶ�,ǰ��Ĵ����׳����쳣,����������������ִ��,ϵͳֱ��catch�����쳣���Ҵ���
catch�������ж��,����ƥ�����쳣,�����쳣��˳����catch����˳���й�,������Ӧ���쳣����ʱ,ʣ�µ�catch��䲻�ٽ���ƥ��,����ڰ���catch����˳��ʱ,����Ӧ�ò�����������쳣,Ȼ��һ�㻯��catch��������Java���Զ���Ļ��߳���Ա�Լ������,��ʾ�׳��쳣�����͡��쳣�ı�������ʾ�׳��쳣�Ķ��������,���catch����ƥ���˸��쳣,��ô�Ϳ���ֱ��������쳣��������ָ����ƥ����쳣,������catch�����ֱ�����á�����ϵͳ���ɵ��쳣��Java����ʱ�Զ��׳�,Ҳ��ͨ��throws�ؼ��������÷���Ҫ�׳����쳣,Ȼ���ڷ������׳��쳣����
final���Ϊ�쳣�ṩһ��ͳһ�ij���,һ������³���ʼ�ն�Ҫִ��final���,final�ڳ����п�ѡ��finalһ���������ر��Ѵ��ļ����ͷ�����ϵͳ��Դ��try-catch-final����Ƕ�ס�
throws�ؼ��ֺ� throw �ؼ�����ʹ���ϵļ�����������:
- throw �ؼ������ڷ����ڲ�,ֻ�������׳�һ���쳣,�����׳������������е��쳣��
- throws �ؼ������ڷ���������,�����׳�����쳣,������ʶ�÷��������׳����쳣�б������ø÷����ķ�����������ɴ����쳣�Ĵ���,����ҲҪ�ڷ����������� throws �ؼ���������Ӧ���쳣��
��4���������,finally�鲻�ᱻִ��:
- finally�����з������쳣
- ǰ��Ĵ�����ִ����System.exit()�˳�����
- ���������ڵ��߳�����
- �ر�CPU
24. ����return��finally�Ĺ�ϵ
try����return
������ʲôλ������return,finally�Ӿ䶼�ᱻִ��
catch��try���return
��try���׳��쳣��catch����return���,finally��û��return���,java��ִ��catch�з�return���,��ִ��finally���,���ִ��return��䡣��try��û���׳��쳣,�����ִ��catch����������,java��ִ��try�з�return���,��ִ��finally���,�����ִ��try�е�return��䡣
finally ����return
finally����returnʱ,�Ḳ�ǵ�try��catch�е�return��
finally��û��return���,���Ǹı��˷���ֵ
���finally�ж���������ǻ����������ͻ��ı��ַ���,����finally�жԸû������ݵĸı䲻������,try�е�return�����Ȼ�᷵�ؽ���finally����֮ǰ�����ֵ;���finally�ж��������������������,��finally�е�����������,try��return����ֵ������finally�иı������Ե�ֵ��
�ߡ������������
25.java �� IO ��������?
Java IO�����漰40�����,��Щ���ȥ������,��ʵ���Ϻ��й���,���ұ˴�֮����ڷdz����ܵ���ϵ, Java IO����40�����ֶ��Ǵ�����4����������������������ġ�
- InputStream/Reader: ���е��������Ļ���,ǰ�����ֽ�������,�������ַ���������
- OutputStream/Writer: ����������Ļ���,ǰ�����ֽ������,�������ַ��������
- �������������,���Է�Ϊ�������������;
- ���ղ�����Ԫ����,���Է�Ϊ�ֽ������ַ���;
- �������Ľ�ɫ����,���Է�Ϊ�ڵ����ʹ�������
26.BIO,NIO,AIO ��ʲô����,�������ͬ�����첽,�����ͷ�����
ͬ�����첽
- ͬ��: ͬ�����Ƿ���һ�����ú�,��������δ����������֮ǰ,���ò����ء�
- �첽: �첽���Ƿ���һ�����ú�,���̵õ��������ߵĻ�Ӧ��ʾ�ѽ��յ�����,���DZ������߲�û�з��ؽ��,��ʱ���ǿ��Դ�������������,��������ͨ�������¼�,�ص��Ȼ�����֪ͨ�������䷵�ؽ����
- ͬ�����첽��������������첽�Ļ������߲���Ҫ�ȴ��������,��������ͨ���ص��Ȼ�����֪ͨ�������䷵�ؽ����
�����ͷ�����
- ����: �������Ƿ���һ������,������һֱ�ȴ�����������,Ҳ���ǵ�ǰ�̻߳ᱻ����,��������������,ֻ�е������������ܼ�����
- ������: ���������Ƿ���һ������,�����߲���һֱ���Ž������,������ȥ���������顣
- �����ͷ��������������������û��һֱ�ڸ������Ļ��
BIO��ʲô
ͬ������:�ٸ����� : �������ϲ��� ���ڲ����Ŀ��Ѿ����� ��ʲô���鶼���� �Ҿ�һֱ��(�����۲�)��һ�� ��û���� ,�Ҿ�����ȥռ�� ͨ�����ʾ�� ������������ͬ��������IO
NIO��ʲô
NIO : ͬ�������� New IO Non-Block IO �ٸ�����: �������ϲ��� ���ڲ����Ŀ��Ѿ����� ��ʱ���Ҳ�����֮ǰһ�� �һ��ȥ��֧�� ������ҡһҡ Ȼ���һ�ʱ��ʱ��ȥ������������ ������û������ Ȼ����ռ�п�
AIO��ʲô
�첽������IO �ٸ�����: ��û���ڲ���������� �����ڲ����������ֻ�,����������������������: �Һ��� ��ȥ��, ��ʱ�����ٻ�ȥ���������Լ�������
�첽����IO �ٸ�����: �����зdz��� �������ϲ��� ���ڲ����Ŀ��Ѿ����� ��ʱ��Ƚ��� ʲôҲ���� ���ڿ��Ըɵ��� ���ϲ��������Ϻ���֮������� �Һ��� ��ȥ��
����֮�������
BIO: ��������C>һֱ�����C>�������
NIO: Selector������ѯchannel�C>��������C>�������
AIO: ��������C>֪ͨ�ص���
�ˡ�����(����)
27.̸̸Java��������Щ�̰߳�ȫ�ļ��� & ʵ��ԭ��
����Ҫ�����̰߳�ȫ����˵���̷߳���ͬһ����,���������ȷ���Ľ������д�̰߳�ȫ�Ĵ����ǵ������߳�ͬ����
Vector��ArrayList��LinkedList
- Vector�ķ�������ͬ����(Synchronized),���̰߳�ȫ��(thread-safe),��ArrayList,LinkedList�ķ�������,�����̵߳�ͬ����ȻҪӰ������,���,ArrayList�����ܱ�Vector��
��һ�����ݵĺ����������ݶ�������ǰ����м�,������Ҫ����ط������е�Ԫ��ʱ,ʹ��ArrayList���ṩ�ȽϺõ�����,�����������е�ij��Ԫ��ʱ,�ͱ����������һ�˿�ʼ�������ӷ���һ��һ��Ԫ�ص�ȥ����,ֱ���ҵ������Ԫ��Ϊֹ,����,����IJ�������һ�����ݵ�ǰ����м����ӻ�ɾ������,���Ұ���˳��������е�Ԫ��ʱ,��Ӧ��ʹ��LinkedList
HashTable,HashMap,HashSet
- Hashtable:���ڹ�ϣ��ʵ�ֵ�,ͬ��ÿ��Ԫ����һ��key-value��,���ڲ�Ҳ��ͨ�������������ͻ����,��������(�����˷�ֵ)ʱ,ͬ�����Զ�������
HashtableҲ��JDK1.0�������,���̰߳�ȫ��,�����ڶ��̻߳����С�- HashMap,HashSet�����̰߳�ȫ��
- HashMap:��ʵ����Map�ӿ�,Map�ӿڶԼ�ֵ�Խ���ӳ�䡣Map�в������ظ��ļ���Map�ӿ�������������ʵ��,HashMap��TreeMap��TreeMap�����˶�������д���,��HashMap���ܡ�HashMap
��������ֵΪnull��HashMap�Ƿ�synchronized��,����HashMap����ͨ��Collections����ͬ��:Map m = Collections.synchronizeMap(hashMap);��,����������߳�ͬʱ����HashMapʱ,�ܱ�ֻ֤��һ���̸߳���Map��public Object put(Object Key,Object value)����������Ԫ�����ӵ�map��- HashSet:��ʵ����Set�ӿ�,���������������ظ���ֵ,����洢��HashSet֮ǰ,Ҫ��ȷ��������дequals()��hashCode()����,�������ܱȽ϶����ֵ�Ƿ����,��ȷ��set��û�д�����ȵĶ����������û����д����������,����ʹ�����������Ĭ��ʵ�֡�public boolean add(Object o)����������Set������Ԫ��,��Ԫ��ֵ�ظ�ʱ�����������false,����ɹ����ӵĻ��᷵��true��
28.HashMap��Hashtable������
Hashtable�̳���Dictionary��,��HashMap�̳���AbstractMap�ࡣ�����߶�ʵ����Map�ӿڡ�����������һ��֮ǰ��ҪŪ�������֮��ķֱ���Ҫ��������:�̰߳�ȫ��,ͬ��(synchronization),�Լ��ٶȡ�
- HashMap�������Եȼ���Hashtable,����HashMap�Ƿ�synchronized��,�����Խ���null(HashMap���Խ���Ϊnull�ļ�ֵ(key)��ֵ(value),��Hashtable����)��
- HashMap�Ƿ�synchronized,��Hashtable��synchronized,����ζ��Hashtable���̰߳�ȫ��,����߳̿��Թ���һ��Hashtable;�����û����ȷ��ͬ���Ļ�,����߳��Dz��ܹ���HashMap�ġ�Java 5�ṩ��ConcurrentHashMap,����HashTable�����,��HashTable����չ�Ը��á�
- ��һ��������HashMap�ĵ�����(Iterator)��fail-fast������,��Hashtable��enumerator������,����fail-fast�ġ����Ե��������̸߳ı���HashMap�Ľṹ(���ӻ����Ƴ�Ԫ��),�����׳�ConcurrentModificationException,��������������remove()�����Ƴ�Ԫ�����׳�ConcurrentModificationException�쳣�����Ⲣ����һ��һ����������Ϊ,Ҫ��JVM������ͬ��Ҳ��Enumeration��Iterator������
- ����Hashtable���̰߳�ȫ��Ҳ��synchronized,�����ڵ��̻߳���������HashMapҪ�����������Ҫͬ��,ֻ��Ҫ��һ�߳�,��ôʹ��HashMap����Ҫ�ù�Hashtable��
- HashMap���ܱ�֤����ʱ�������Map�е�Ԫ�ش����Dz���ġ�
29.HashSet��HashMap������
- HashMapʵ����Map�ӿ�, HashSetʵ����Set�ӿ�
- HashMap�����ֵ��, HashSet�����洢����
- HashMapʹ��put()������Ԫ�ط���map��, HashSetʹ��add()������Ԫ�ط���set��
- HashMap��ʹ�ü�����������hashcodeֵ, HashSetʹ�ó�Ա����������hashcodeֵ,��������������˵hashcode������ͬ,����equals()���������ж϶���������,�����������ͬ�Ļ�,��ô����false
- HashMap�ȽϿ�,��Ϊ��ʹ��Ψһ�ļ�����ȡ���� HashSet��HashMap��˵�Ƚ���.
30.TreeMap��TreeSet����������ϵ
��ͬ��:
- TreeMap��TreeSet��������ļ���(���̰߳�ȫ��),Ҳ����˵���Ǵ洢��ֵ�����ź���
�ġ�- TreeMap��TreeSet���Ƿ�ͬ������,������Dz����ڶ��߳�֮�乲��,��������ʹ�÷���Collections.synchroinzedMap()��ʵ��ͬ��
- �����ٶȶ�Ҫ��Hash������,�����ڲ���Ԫ�صIJ���ʱ�临�Ӷ�ΪO(logN),��
HashMap/HashSet��ΪO(1)��- Ҫ���ŵĶ��������������ʵ��Comparable�ӿ�,�ýӿ��ṩ�˱Ƚ�Ԫ�ص�compareTo()����,������Ԫ��ʱ��ص��÷����Ƚ�Ԫ�صĴ�С��
��ͬ��:
- ����Ҫ���������TreeSet��TreeMap�ֱ�ʵ��Set��Map�ӿ�
- TreeSetֻ�洢һ������,��TreeMap�洢��������Key��Value(����key��������)
- TreeSet�в������ظ�����,��TreeMap�п��Դ���
- TreeMap�ĵײ���ú������ʵ��,�����������IJ���,���������Ҫ��һ��Ҫ��Key�Ƚϵķ���,Ҫô����Comparatorʵ��,Ҫôkey����ʵ��Comparable�ӿڡ�
31. ArrayMap��HashMap������
HashMap:
�ڲ���ʹ��һ��Ĭ������Ϊ16���������洢���ݵ�,��������ÿһ��Ԫ��ȴ����һ��������ͷ���,����,��ȷ����˵,HashMap�ڲ��洢�ṹ��ʹ�ù�ϣ���������ṹ(����+����),HashMap��ȡ������ͨ������Entry[]�������õ���Ӧ��Ԫ��,���������ܴ�ʱ���Ƚ���,������Android��,HashMap�DZȽϷ��ڴ�ġ�
ArrayMap:
��һ��<key,value>ӳ������ݽṹ,������ϸ�����ǿ����ڴ���Ż�,�ڲ���ʹ����������������ݴ洢,һ�������¼key��hashֵ,����һ�������¼Valueֵ,����SparseArrayһ��,Ҳ���keyʹ�ö��ַ����д�С��������,�����ӡ�ɾ�����������ݵ�ʱ������ʹ�ö��ֲ��ҷ��õ���Ӧ��index,Ȼ��ͨ��index���������ӡ����ҡ�ɾ���Ȳ���,����,Ӧ�ó�����SparseArray��һ��,������������Ƚϴ�������,��ô�������ܽ��˻�����50%��
HashMap��ArrayMap���Ե������������Ƚ�С,������ҪƵ����ʹ��Map�洢���ݵ�ʱ��,�Ƽ�ʹ��ArrayMap��
���������Ƚϴ��ʱ��,���Ƽ�ʹ��HashMap��
- ������
HashMap��Ϊ�����hashcode��ֱֵ�����index,���������Ч�����������鳤����������ӵġ�ArrayMapʹ�õ��Ƕ��ַ�����,���Ե����鳤��ÿ����һ��ʱ,����Ҫ�����һ���ж�,Ч���½������Զ��������Ƚϴ�������,�Ƽ�ʹ��HashMap- ��������
HashMap��ʼֵ16������,ÿ�����ݵ�ʱ��,ֱ������˫��������ռ䡣
ArrayMapÿ�����ݵ�ʱ��,���size���ȴ���8ʱ����size*1.5������,����4С��8ʱ����8��,С��4ʱ����4���������Ƚ�ArrayMap��ʵ�������˸��ٵ��ڴ�ռ�,�������ݵ�Ƶ�ʻ���ߡ����,������������Ƚϴ��ʱ��,����ʹ��HashMap������,��Ϊ�����ݵĴ���Ҫ��ArrayMap�ٺܶࡣ- ����Ч��
HashMapÿ�����ݵ�ʱ��ʱ���¼���ÿ�������Ա��λ��,Ȼ��ŵ��µ�λ�á�
ArrayMap����ֱ��ʹ��System.arraycopy������Ч���Ͽ϶���ArrayMap��ռ���ơ�������Ҫ˵��һ��,������һ��˵��ΪArrayMapʹ��System.arraycopy��ʡ�ڴ�ռ�,��һ�������û�п�������arraycopyҲ�ǰ��ϵ�����Ķ���һ��һ���ĸ����µ����顣��ȻЧ���Ͽ϶�arraycopy����,��Ϊ��ֱ�ӵ��õ�c��Ĵ��롣- �ڴ�ķ�
��ArrayMap������һ�ֶ��صķ�ʽ,�ܹ��ظ���������Ϊ�������ݶ���������������ռ�,������һ��ArrayMap��ʹ�á���HashMapû��������ơ�����ArrayMapֻ�����˳�����4��8��ʱ��,�������Ƶ����ʹ�õ�Map,�������������Ƚ�С��ʱ��,ArrayMap�������൱�Ľ�ʡ�ڴ�ġ�
32. Collection �� Collections������?
Collection:
�Ǽ�������ϲ�ӿڡ�������һ��Interface,���������һЩ���ϵĻ���������Collection�ӿ�ʱSet�ӿں�List�ӿڵĸ��ӿ�
Collections
Collections��һ�����Ͽ�ܵİ�����,�������һЩ�Լ��ϵ�����,�����Լ����л��IJ��������������Collections��һ����,Collections ��һ����װ��,Collection ��ʾһ�����,��Щ����Ҳ��Ϊ collection ��Ԫ�ء�һЩcollection �������ظ���Ԫ��, ����һЩ������,һЩ collection �������,����һЩ��������ġ�
33. Map�ı�����ʽ����Щ?
��for-eachѭ����ʹ��entries������
��for-eachѭ���б���keys��values��
ʹ��Iterator����
ͨ������ֵ����(Ч�ʵ�)
�š�Java����
34. ʲô���߳�,ʲô�ǽ���,��������?
���� :�����Dz���ִ�г�����ִ�й�������Դ��������Ļ�����λ(��Դ�������С��λ)�����̿�������Ϊһ��Ӧ�ó����ִ�й���,Ӧ�ó���һ��ִ��,����һ�����̡�ÿ�����̶����Լ������ĵ�ַ�ռ�,ÿ����һ������,ϵͳ�ͻ�Ϊ�������ַ�ռ�,�������ݱ���ά������Ρ���ջ�κ����ݶΡ�ͨ����˵,Ӧ���е� Activity��Service ���Ĵ����Ĭ�϶�λ��һ����������,��������������Ƶ�Ĭ��ֵ�������Ǹ�Ӧ�ö���İ�����ϵͳΪÿ�����̷�����ڴ�������,��������ǰ�ĵͶ��ֻ��ϳ����� 16M,���ڵĻ����ڴ����һЩ,32M��48M,�������ߡ�����,��������,�Ͼ�һ���ֻ�����֮��RAM �Ĵ�С�Ͷ���,��������������Ӧ�õ���������,һ�����ǵ�ѡ�����ʹ�ö����,��һЩ�������ķ��Ƚ϶��������൱ռ���ڴ�Ĺ�������������һ�����̵���,�����ֵ������̵��ڴ����ġ�������,Ӧ���е����ͷ���,������App �ĺ�̨�������ȵ�,����������һ�������С�
�߳�: ����ִ�е���С��λ��ÿ�����̶����Լ��ĵ�ַ�ռ�,�����̿ռ�,���������û�������,һ��������ͨ����Ҫ���մ�����ȷ�������û��IJ�������,Ϊÿһ��������һ��������Ȼ�в�ͨ(ϵͳ��������Ӧ�û�����Ч�ʵ�),��˲���ϵͳ���̸߳������������Ŀ����Ϊ�˼��ٳ����ڲ���ִ�й����еĿ���,ʹOS�IJ���Ч�ʸ��ߡ�
�������̵߳�����
- ����:�߳���Ϊ���Ⱥͷ���Ļ�����λ,������Ϊӵ����Դ�Ļ�����λ;
- ��ַ�ռ�: ͬһ���̵������̹߳��������̵ĵ�ַ�ռ�,����ͬ�Ľ���֮��ĵ�ַ�ռ��Ƕ����ġ�
- ��Դӵ��: ͬһ���̵������̹߳��������̵���Դ,���ڴ�,CPU,IO�ȡ�����֮�����Դ�Ƕ�����,��������
- ִ�й���:ÿһ�����̿���˵����һ����ִ�е�Ӧ�ó���,ÿһ�������Ľ��̶���һ������ִ�е����,˳��ִ�����С������̲߳��ܹ�����ִ��,����������Ӧ�ó�����,�ɳ���Ķ��߳̿��ƻ��ƽ��п��ơ�
- ��׳��: ��Ϊͬһ���̵������̹߳������̵߳���Դ,��˵�һ���̷߳�������ʱ,�˽���Ҳ�ᷢ�������� ���Ǹ�������֮�����Դ�Ƕ�����,��˵�һ�����̱���ʱ,����Ӱ���������̡���˽��̱��߳̽�׳���߳�ִ�п���С,����������Դ�Ĺ����뱣�������̵�ִ�п�����,�����Խ�����Դ�Ĺ����뱣�������̿��Կ����ǰ�ơ�
�������̵߳���ϵ:
- һ���߳�ֻ������һ������,��һ�����̿����ж���߳�,��������һ���߳�;
- ��Դ���������,ͬһ���̵������̹߳����ý��̵�������Դ;
-�������ָ��߳�,�������ڴ����������е����߳�;
-�߳���ִ�й�����,��ҪЭ��ͬ������ͬ���̵��̼߳�Ҫ������Ϣͨ�ŵİ취ʵ��ͬ����
�ٸ����Ӹ�������:
�������ǰ�������·������һ�������̡��Ļ�,���ɰ�ɫ���߷ָ������ĸ����������ǽ����еĸ������̡߳��ˡ���Щ�߳�(����)�����˽���(��·)�Ĺ�����Դ(������Դ)����Щ�߳�(����)���������ڽ���(��·),Ҳ����˵,�̲߳��������ڽ��̶�����(�����뿪�˵�·,����Ҳ��û��������)����Щ�߳�(����)֮����Բ���ִ��(���������������,�����ҵ�),Ҳ���Ի���ͬ��(ijЩ�����ڽ�ͨ����ʱ��ֹ����ǰ�л�ת��,����ȴ����������ij���ͨ�����)����Щ�߳�(����)֮������������(��ͨ��)����������,һ����������������(����,����߳�ͬʱ����Ψһ��Դ),��ô�߳̽��������,����֮�С���Щ�߳�(����)֮��˭��������δ֪��,ֻ�����̸߳պñ����䵽CPUʱ��Ƭ(��ͨ�Ʊ仯)����һ�̲���֪����
ʹ�ó���
- �ڳ�����,�����ҪƵ�����������ٵ�,ʹ���̡߳���Ϊ���̴��������ٿ����ܴ�(��Ҫ��ͣ�ķ�����Դ),�����߳�Ƶ���ĵ���ֻ�Ǹı�CPU��ִ��,����С
- �����Ҫ������ӵ��ȶ���ȫʱ,����ѡ����̡�������ٶ�,��ѡ���̡߳�
35. ���̵߳�3��ʵ�ַ�ʽ
1.�̳�Thread�ഴ���߳���
- ����Thread�������, ����д�����run����, ��run�����ķ�����ʹ�����
�߳�Ҫ��ɵ����� ��˰�run()������Ϊִ���塣- ����Thread�����ʵ��, ���������̶߳���
- �����̶߳����start()�������������߳�
2.ͨ��Runnable�ӿڴ����߳���
- ����runnable�ӿڵ�ʵ����, ����д�ýӿڵ�run()����, ��run()�����ķ�����ͬ���Ǹ��̵߳��߳�ִ���塣
- ���� Runnableʵ�����ʵ��, ������ʵ����ΪThread��target������Thread����, ��Thread��������������̶߳���
- �����̶߳����start()�������������̡߳�
3.ͨ��Callable��Future�����߳�
- ����Callable�ӿڵ�ʵ����, ��ʵ��call()����, ��call()��������Ϊ�߳�ִ����, �����з���ֵ
- ����Callableʵ�����ʵ��, ʹ��FutureTask������װCallable����, ��FutureTask�����װ�˸�Callable�����call()�����ķ���ֵ��
- ʹ��FutureTask������ΪThread�����target�������������̡߳�
- ����FutureTask�����get()������������߳�ִ�н�����ķ���ֵ, ����get()�����������߳�
�����̵߳����ַ�ʽ�ĶԱ�
- ����ʵ��Runnable��Callable�ӿ��ķ�ʽ�������߳�ʱ:
- ����
�߳���ֻ��ʵ����Runnable�ӿڻ�Callable�ӿ�,�����Լ̳������ࡣ�����ַ�ʽ��,����߳̿��Թ���ͬһ��target����,���Էdz��ʺ϶����ͬ�߳�������ͬһ����Դ�����,�Ӷ����Խ�CPU����������ݷֿ�,�γ�������ģ��,�Ϻõ���������������˼�롣- ����
���������,���Ҫ���ʵ�ǰ�߳�,�����ʹ��Thread.currentThread()������
- ʹ�ü̳�Thread��ķ�ʽ�������߳�ʱ
- ����
��д��,�����Ҫ���ʵ�ǰ�߳�,������ʹ��Thread.currentThread()����,ֱ��ʹ��this���ɻ�õ�ǰ�̡߳�- ����
�߳����Ѿ��̳���Thread��,���Բ����ټ̳��������ࡣ
runnable �� callable ������
- Callcble�ǿ����з���ֵ��,����ķ���ֵ������Callable�Ľӿڷ���call���ص�,�����������ֵ������ͨ��ʵ��Future�ӿڵĶ����get������ȡ��,��������ǻ�����߳�������;��Runnable��û�з���ֵ��,��ΪRunnable�ӿ��е�run������û�з���ֵ��;
- Callable�����call�����ǿ����׳��쳣��,���ǿ��Բ����쳣���д���;����Runnable�����run�����Dz������׳��쳣��,�쳣Ҫ��run�����ڲ�����õ�����,����������׳�;
- callable��runnable������Ӧ����executors����thread��ֻ֧��runnable
36.������̵��������:ԭ����,������,�ɼ���
Java �ڴ�ģ�� (JMM)�ؼ������㶼��Χ���Ŷ��̵߳�ԭ���ԡ��ɼ��ԡ����������۵ġ�JMM ����˿ɼ��Ժ������Ե�����,���������ԭ���Ե����⡣Java�ڴ�ģ�涨�����еı������洢�����ڴ���,ÿ���߳��л����Լ��Ĺ����ڴ�,�̵߳Ĺ����ڴ��б����˱����߳���ʹ�õ��ı���(��Щ�����Ǵ����ڴ��п�������)���̶߳Ա��������в���(��ȡ,��ֵ)�������ڹ����ڴ��н��С���ͬ�߳�֮��Ҳ��ֱ�ӷ��ʶԷ������ڴ��еı���,�̼߳����ֵ�Ĵ��ݾ���Ҫͨ�����ڴ�����ɡ�
ԭ����:��һ���������߶������,Ҫôȫ��ִ��,����ִ�еĹ��̲��ᱻ�κ����ش��,Ҫô�Ͷ���ִ�С�ֻ�мĶ�ȡ����ֵ(���ұ����ǽ����ָ�ֵ��ij������,����֮������ֵ����ԭ�Ӳ���)����ԭ�Ӳ�����Java�ڴ�ģ��ֻ��֤�˻�����ȡ��ֵ��ԭ���Բ���,���Ҫʵ�ָ���Χ������ԭ����,����ͨ��synchronized��Lock��ʵ�֡�����synchronized��Lock�ܹ���֤��һʱ��ֻ��һ���߳�ִ�иô����,��ô��Ȼ�Ͳ�����ԭ����������,�Ӷ���֤��ԭ���ԡ�
�ɼ���:��ָ������̷߳���ͬһ������ʱ,һ���߳��������������ֵ,�����߳��ܹ��������õ��ĵ�ֵ��Java�ṩ��volatile�ؼ�������֤�ɼ���,��һ������������volatile����ʱ,���ᱣ֤�ĵ�ֵ�����������µ�����,���������߳���Ҫ��ȡʱ,����ȥ�ڴ��ж�ȡ��ֵ������ͨ�Ĺ����������ܱ�֤�ɼ���,��Ϊ��ͨ������������֮��,ʲôʱ��д�������Dz�ȷ����,�������߳�ȥ��ȡʱ,��ʱ�ڴ��п��ܻ���ԭ���ľ�ֵ,�������֤�ɼ��ԡ�ͨ��synchronized��LockҲ�ܹ���֤�ɼ���,synchronized��Lock�ܱ�֤ͬһʱ��ֻ��һ���̻߳�ȡ��Ȼ��ִ��ͬ������,�������ͷ���֮ǰ�Ὣ�Ա�������ˢ�µ����浱�С���˿��Ա�֤�ɼ��ԡ�
������:������ִ�е�˳���մ�����Ⱥ�˳��ִ�С�һ����˵,������Ϊ����߳�������Ч��,���ܻ����ָ��������,Ҳ���Ƕ������������Ż�,������֤�����и�������ִ���Ⱥ�˳��ͬ�����е�˳��һ��,�������ᱣ֤��������ִ�н���ʹ���˳��ִ�еĽ����һ�µġ�ָ��������Ӱ�쵥���̵߳�ִ��,���ǻ�Ӱ�쵽�̲߳���ִ�е���ȷ�ԡ�Ҳ����˵,Ҫ�벢��������ȷ��ִ��,����Ҫ��֤ԭ���ԡ��ɼ����Լ������ԡ�ֻҪ��һ��û�б���֤,���п��ܻᵼ�³������в���ȷ������ͨ��volatile�ؼ�������֤һ���ġ������ԡ�,volatile�ؼ����ܽ�ָֹ��������,����volatile����һ���̶��ϱ�֤�����ԡ��������ͨ��synchronized��Lock����֤������,����Ȼ,synchronized��Lock��֤ÿ��ʱ������һ���߳�ִ��ͬ������,�൱�������߳�˳��ִ��ͬ������,��Ȼ�ͱ�֤�������ԡ�
synchronized�ؼ����Ƿ�ֹ����߳�ͬʱִ��һ�δ���,��ô�ͻ��Ӱ�����ִ��Ч��,��volatile�ؼ�����ijЩ���������Ҫ����synchronized,����Ҫע��volatile�ؼ����������synchronized�ؼ��ֵ�,��Ϊvolatile�ؼ�������֤������ԭ���ԡ�
37.���кͲ�����ʲô����?
�ٸ�����:��Է��Ե�һ��,�绰����,��һֱ���������Ժ��ȥ��,˵���㲻֧�ֲ���Ҳ��֧�ֲ��С�
��Է��Ե�һ��,�绰����,��ͣ�������˵绰,Ȼ������Է�,˵����֧�ֲ�����(��һ����ͬʱ)
��Է��Ե�һ��,�绰����,��һ�ߴ�绰һ�����Է�,˵����֧�ֲ��С�
�����Ĺؼ������д�������¼�������,��һ��Ҫͬʱ�������Ĺؼ�������ͬʱ��������¼���������
�������������Ƿ���ͬʱ��������������������¼�,������ͬʱ��������¼���
38.�ػ��߳���ʲô?
����:��ָ�ڳ�������ʱ �ں�̨�ṩһ��ͨ�÷�����߳�,�����̲߳������ڳ����в��ɻ�ȱ�IJ��֡�ͨ�㽲,�κ�һ���ػ��̶߳�������JVM�����з��ػ��̵߳�"��ķ"��
�ص�:���ػ��߳�ӵ���Զ������Լ��������ڵ�����,�����ػ��̲߳��߱�����ص㡣�� JVM �в������κ�һ���������еķ��ػ��߳�ʱ,JVM ���̼����˳�,Ҳ����˵ֻҪ���κη��ػ��̻߳�������,����Ͳ�����ֹ,��JVM��ֻ���ػ��߳�����ʱJVM���Զ��رա�JVM �е����������߳̾��ǵ��͵��ػ��̡߳�
ʹ�÷���:����Java������,�ػ��߳�һ����нϵ͵����ȼ�,������ֻ��JVM�ڲ��ṩ,�û��ڱ�д����ʱҲ�����Լ������ػ��߳�,����:��һ���߳�����Ϊ�ػ��̵߳ķ��������ڵ���start()�����߳�֮ǰ���ö����setDaemon(true)����,�������ϲ�������Ϊfalse,���ʾ�����û�����ģʽ,��Ҫע�����,����һ���ػ��߳��в������������߳�,��ô��Щ�²������߳�Ĭ�ϻ����ػ��߳�,�û��߳�Ҳ����ˡ�
Ӧ�ó���:ͨ����˵,�ػ��߳̾���������ִ��һЩ��̨����,������,����ϣ���ڳ����˳�ʱ,����˵ JVM �˳�ʱ,�߳��ܹ��Զ��ر�,��ʱ,��ѡ�ػ��̡߳�
39.�� java ��������ô��֤���̵߳����а�ȫ?
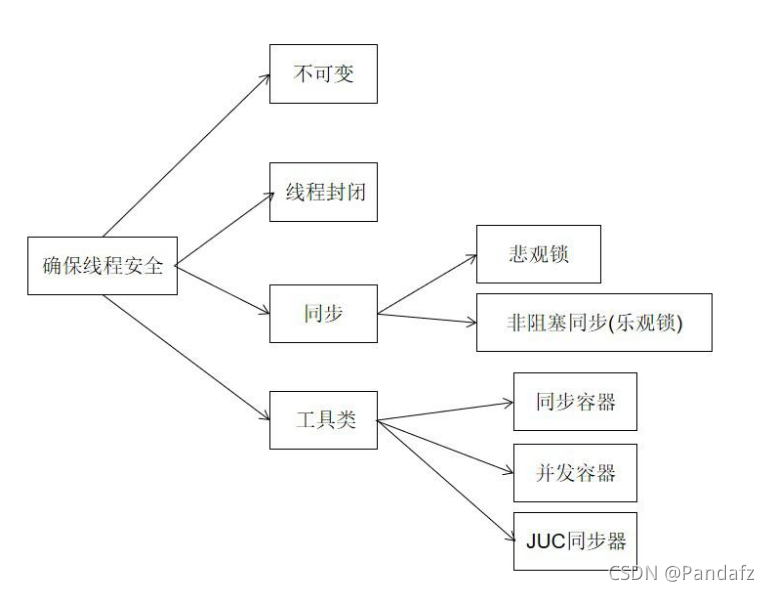
������˵�̰߳�ȫ��������������:
ԭ����:�ṩ�������,ͬһʱ��ֻ����һ���̶߳����ݽ��в���,
(atomic,synchronized)��
�ɼ���:һ���̶߳����ڴ���Ŀ��Լ�ʱ�ر������߳̿���,(synchronized,volatile)��
������:һ���̹߳۲������߳��е�ָ��ִ��˳��,����ָ��������,�ù۲���һ����������,(happens-beforeԭ��)��
����ԭ��:
- ���浼�µĿɼ�������
- �߳��л�������ԭ��������
- �����Ż�����������������
����취:
ȷ���̰߳�ȫ�������ó���������Ԥ�ڵ���Ϊȥִ��
- JDK Atomic��ͷ��ԭ����(AtomicInteger,AtomicLong,AtomicBoolean�ȵ�)��synchronized��LOCK,���Խ��ԭ��������
- synchronized��volatile��LOCK,���Խ���ɼ�������
- Happens-Before ������Խ������������,synchronized��Lock����֤������
- ʹ��java�ṩ�İ�ȫ��:java.util.concurrent���µ������������̰߳�ȫ��,�ڱ�֤��ȫ��ͬʱ���ܱ�֤����;
Happens-Before ��������:
- ����������:��һ���߳���,���ճ��������˳��,��д��ǰ��IJ������з�������д�ں���IJ���
- �ܳ���������:һ��unlock�������з����ں����ͬһ������lock����
- volatile��������:��һ��volatile������д�������з����ں������������Ķ�����
- �߳���������:Thread�����start()�������з����ڴ��̵߳�ÿһ������
- �߳���ֹ����:�߳��е����в��������з����ڶԴ��̵߳���ֹ���
- �߳��жϹ���:���߳�interrupt()�����ĵ������з����ڱ��ж��̵߳Ĵ�����ж��¼��ķ���
- �����ս����:һ������ij�ʼ�����(���캯��ִ�н���)���з���������finalize()�����Ŀ�ʼ
40.˵һ�� synchronized �ײ�ʵ��ԭ��?
���ڶ���ļ�����(ObjectMonitor),��ͬ������ִ��ǰ��,������ָ��,����ͬ������ǰmonitorenter,����ִ����ɺ�monitorexit;
����һ������ӵ���Լ��ļ�����,��ͬ��������ͬ������ʱ,ִ�з������̱߳����Ȼ�øö���ļ��������ܽ���ͬ�����ͬ������,û�л�ȡ�����������߳̽��ᱻ����,������ͬ������,״̬��Ϊ BLOCKED �����ɹ���ȡ���������߳��ͷ�������,�ỽ��������ͬ�����е��߳�,ʹ�����³��ԶԼ������Ļ�ȡ��
����:һ��synchronize����������monitorexit,���DZ�֤synchronize��һ���ͷ����Ļ���,һ���Ƿ�������ִ�����ͷ�,һ����ִ�й��̷����쳣ʱ������ͷ�;
synchronized�����������µط�
- ����ʵ������,�Ե�ǰʵ������this����
- ���ξ�̬����,�Ե�ǰ���Class�������
- ���δ����,ָ����������,�Ը����������
41.synchronized �� volatile ��������ʲô?
1��
volatile�������ڸ���jvm��ǰ�����ڼĴ���(�����ڴ�)�е�ֵ�Dz�ȷ����,��Ҫ�������ж�ȡ;synchronized����������ǰ����,ֻ�е�ǰ�߳̿��Է��ʸñ���,�����̱߳�����ס��
2��volatile����ʹ���ڱ�������;synchronized�����ʹ���ڱ��������������༶���
3��volatile����ʵ�ֱ������Ŀɼ���,���ܱ�֤ԭ����;��synchronized����Ա�֤�������Ŀɼ��Ժ�ԭ����
4��volatile��������̵߳�����;synchronized���ܻ�����̵߳�������
5��volatile��ǵı������ᱻ�������Ż�;synchronized��ǵı������Ա��������Ż�
42.synchronized �� Lock ��ʲô����?
1��synchronized����Ҫ�ֶ��ͷ���,lock��Ҫ������������unlock�ͷ���;
2��synchronizedֻ����Ĭ�ϵķǹ�ƽ��,lock����ָ��ʹ�ù�ƽ�����߷ǹ�ƽ��;
3��lock�ṩ��Condition(����)����ָ��������Щ�߳�,��synchronizedֻ���������һ������ȫ������;
43.���߳���������ԭ����ʲô?
JVM�Ż�synchronized�����л���,��JVM����ͬ�ľ���״̬ʱ,�ͻ������Ҫ�Զ��л������ʵ���,�����л��������������������Dz������,Ҳ����˵ֻ�ܴӵ͵���,���ܹ�������
���ļ���ӵ͵���:
���� -> ƫ���� -> �������� -> ��������
���ּ���ԭ��:
û���Ż���ǰ,synchronized����������(������),ʹ�� wait �� notify��notifyAll ���л��߳�״̬�dz�����ϵͳ��Դ;�̵߳Ĺ���ͻ��Ѽ���ܶ���,�������˷���Դ,Ӱ�����ܡ����� JVM �� synchronized �ؼ��ֽ������Ż�,������Ϊ ������ƫ������������������������ ״̬��
����:û�ж���Դ��������,���е��̶߳��ܷ��ʲ���ͬһ����Դ,��ͬʱֻ��һ���߳����ijɹ�,������ʧ�ܵ��̻߳������ֱ���ijɹ���
ƫ����:HotSpot���߷���,����������,�����������ڶ��߳̾���,����������ͬһ�̶߳�λ�á���һ���̷߳���ͬ���鲢�����ʱ,���ڶ���ͷ��ջ֡�е�����¼����洢ƫ����߳�ID,�Ժ���߳��ٽ�����˳�ͬ����ʱ����Ҫ����CAS�����������ͽ�����
��������:Java SE 1.6 Ϊ�˼��ٻ��/�ͷ�����������������,�����ˡ������������͡�ƫ������,�����������������ʹ�ò���ϵͳ��������ʵ�ֵĴ�ͳ�����Եġ�����,������Ҫǿ��һ�����,��������������������������������,���ı�������û�ж��߳̾�����ǰ����,���ٴ�ͳ����������ʹ�ò������������ġ��ڽ�������������ִ�й���֮ǰ,������һ��,������������Ӧ�ij������߳̽���ִ��ͬ��������,�������ͬһʱ�����ͬһ�������,�ͻᵼ��������������Ϊ����������
��������:ָ����һ���̻߳�ȡ��֮��,�������еȴ���ȡ�������̶߳��ᴦ������״̬����������ͨ�������ڲ��ļ�����(monitor)ʵ��,������ monitor �ı����������ڵײ����ϵͳ�� Mutex Lock ʵ��,����ϵͳʵ���߳�֮����л���Ҫ���û�̬�л����ں�̬,�л��ɱ��dz��ߡ�
| �� | �ŵ� | ȱ�� | ���ó��� |
|---|---|---|---|
| ƫ���� | �����ͽ�������Ҫ���������,��ִ�з�ͬ�������Ƚ��������뼶�IJ�� | ����̼߳����������,���������������������� | ������ֻ��һ���̷߳���ͬ���鳡�� |
| �������� | �������̲߳������� ,����˳������Ӧ�ٶ� | ���ʼ�յò������������߳�ʹ������������CPU | ����Ӧʱ��,ͬ����ִ���ٶȷdz��� |
| �������� | �߳̾�����ʹ������,��������CPU | �߳�����,��Ӧʱ�仺�� | ��������,ͬ����ִ���ٶȽϳ� |
44.ʲô������?
������ָ�������������ϵĽ�����ִ�й�����,���ھ�����Դ�������ڱ˴�ͨ�Ŷ���ɵ�һ������������,������������,���Ƕ������ƽ���ȥ����ʱ��ϵͳ��������״̬��ϵͳ����������,��Щ��Զ�ڻ���ȴ��Ľ��̳�Ϊ�������̡��Dz���ϵͳ�����һ������,�ǽ��������ļ��,ϵͳ�������������˷Ѵ�����ϵͳ��Դ,������������ϵͳ����,���������Ժ����
45.��ô��ֹ����?
һ����˵,Ҫ��������������Ҫ��������4������:
- ��������:һ����Դÿ��ֻ�ܱ�һ���߳�ʹ�á�
- �����뱣������:һ���߳���������Դ������ʱ,���ѻ�õ���Դ���ֲ��š�
- ����������:�߳��ѻ�õ���Դ,��δʹ����֮ǰ,����ǿ�а��ᡣ
- ѭ���ȴ�����:�����߳�֮���γ�һ��ͷβ��ӵ�ѭ���ȴ���Դ��ϵ��
��JAVA�����,��3�ֵ��͵���������:
- ��̬����˳������:a��b������������Ҫ���A����B����һ���߳�ִ��a�������Ѿ������A��,�ڵȴ�B��;��һ���߳�ִ����b�������Ѿ������B��,�ڵȴ�A������������ǽ�������Ҫ��������߳�,������ͬ�Ķ���˳�����������
- ��̬����˳������:ָ�����̵߳���ͬһ������ʱ,����IJ����ߵ���ɵ�����,���������ʹ��System.identifyHashCode����������˳��,ȷ�����е��̶߳�����ͬ��˳��������
- Э������֮�䷢��������:һ���̵߳�����A�����a����,��һ���̵߳�����B�����b��������ʱ���ܻᷢ��,��һ���̳߳���A���������ȴ�B������,��һ���̳߳���B���������ȴ�A�������������������Ҫ����ij���ⲿ����ʱ����Ҫ������,�������ڳ�����������µ����ⲿ�ķ�����
��д����ʱ,Ҫȷ���߳��ڻ�ȡ�����ʱ����һ�µ�˳��ͬ
ʱ,Ҫ�����ڳ�����������µ����ⲿ������
46.ThreadLocal ��ʲô?
ThreadLocal��ʲô:
JDK1.2�İ汾�о��ṩjava.lang.ThreadLocal��,ÿһ��ThreadLocal�ܹ���һ���̼߳���ı���, �������ܹ�������̹߳���ʹ��,�������ܹ��ﵽ�̰߳�ȫ��Ŀ��,�Ҿ����̰߳�ȫ��ThreadLocal�ǽ���̰߳�ȫ����һ���ܺõ�˼·,��ͨ��Ϊÿ���߳��ṩһ�������ı�����������˱����������ʵij�ͻ���⡣�ںܶ������,ThreadLocal��ֱ��ʹ��synchronizedͬ�����ƽ���̰߳�ȫ�������,������,�ҽ������ӵ�и��ߵIJ����ԡ�
47.Synchronized �� ReentrantLock ������ʲô?
���Ƶ�:
������ͬ����ʽ�кܶ�����֮��,���Ƕ��Ǽ�����ʽͬ��,���Ҷ�������ʽ��ͬ��,Ҳ����˵�����һ���̻߳���˶�����,������ͬ����,�������ʸ�ͬ������̶߳�����������ͬ��������ȴ�,�������߳������ͻ��ѵĴ����DZȽϸߵ�(����ϵͳ��Ҫ���û�̬���ں�̬֮�������л�,���ۺܸ�,��������ͨ�������Ż����и���)��
��ͬ��:
- �����:
Synchronized��java���Ե��ؼ���,��ԭ�������Ļ���,��Ҫjvmʵ��,ReentrantLock��JDK 1.5֮���ṩ��API�����Ļ�����,Synchronized��������ʵ������,��̬����,����顣�Զ��ͷ�����ReentrantLockһ����Ҫtry catch finally���,��try�л�ȡ��,��finally�ͷ�������Ҫ�ֶ��ͷ�����Synchronized���ķ�Χ������������synchronized�鲿��,ReentrantLock��Ϊ�Ƿ�������,���Կ緽��,����Ը���
- ʵ�ַ�ʽ������:
Synchronized����������������������Ҫ���̴߳��ں�̬���û�̬�����л�����:A�߳��л���B�߳�,A�߳���Ҫ���浱ǰ�ֳ�,B�߳��л�Ҳ��Ҫ�����ֳ�����������ȱ���Ǻķ�ϵͳ��Դ������һ�ֱ�������������,״̬��blockReentrantLock����������������cas+volatile�����߳�,����Ҫ�߳��л��л���ȡ���߳�,����һ���ֹ۵�˼��(����ʧ��),����һ�������������ֹ���,״̬��wait
- ��ƽ�ͷǹ�ƽ
��ƽ��,����̵߳ȴ�ͬһ����ʱ,���밴����������ʱ��˳������,
Synchronizedֻ�зǹ�ƽ����ReentrantLockĬ�ϵĹ��캯���Ǵ����ķǹ�ƽ��,����ͨ������true��Ϊ��ƽ��,����ƽ�����ֵ����ܲ��Ǻܺá���ƽ��ͨ�����캯������true��ʾ��
- ���жϵ�
���������̳߳��ڲ��ͷŵ�ʱ��,���ڵȴ����߳̿���ѡ������ȴ�
Synchronized�Dz����жϵġ�ReentrantLock�ṩ���жϺͲ����ж����ַ�ʽ������lockInterruptibly������ʾ���ж�,lock������ʾ�����жϡ����൱��Synchronized��˵���Ա�����������������
- ��������
ͬ������:���߳�ͬʱ����һ����ʧ�ܱ�������̡߳�
��������:����ִ�е��̵߳���await/wait,��ͬ�����м�����̻߳�����������С�����ִ���̵߳���signal/signalAll/notify/notifyAll,�Ὣ��������һ���̻߳����̼߳��뵽ͬ�����С�
�ȴ�����:����������һ�����
Synchronizedֻ��һ���ȴ�����,Ҫô�������һ���߳�Ҫô����ȫ���̡߳�ReentrantLock��һ�������Զ�Ӧ����������С�ͨ��newCondition��ʾ��һ��ReentrantLock�������ͬʱ�Ը�����ReenTrantLock�ṩ��һ��Condition(����)��,����ʵ�ַ��黽����Ҫ���ѵ��߳�
48.�߳�����Щ״̬?
- ����(NEW):�´�����һ���̶߳���
- ����(RUNNABLE):�̶߳�����,�����߳�(����main�߳�)�����˸ö����
start()��������״̬���߳�λ�ڿ������̳߳���,�ȴ����̵߳���ѡ��,��ȡcpu ��ʹ��Ȩ ��- ����(RUNNING):������״̬(runnable)���̻߳����cpu ʱ��Ƭ(timeslice) ,ִ�г�����롣
- ����(BLOCKED):����״̬��ָ�߳���Ϊij��ԭ�������cpu ʹ��Ȩ,Ҳ���ó���cpu timeslice,��ʱֹͣ���С�ֱ���߳̽��������(runnable)״̬,���л����ٴλ��cpu timeslice ת������(running)״̬�����������������:
- �ȴ�����:����(running)���߳�ִ��
o.wait()����,JVM��Ѹ��̷߳���ȴ�����(waitting queue)�С�- ͬ������:����(running)���߳��ڻ�ȡ�����ͬ����ʱ,����ͬ����������߳�ռ��,��JVM��Ѹ��̷߳�������(lock pool)�С�
- ��������:����(running)���߳�ִ��
Thread.sleep(long ms)��t.join()����,���߷�����I/O����ʱ,JVM��Ѹ��߳���Ϊ����״̬����sleep()״̬��ʱ��join()�ȴ��߳���ֹ���߳�ʱ������I/O�������ʱ,�߳�����ת�������(runnable)״̬��
- ����(DEAD):�߳�run()��main() ����ִ�н���,�������쳣�˳���run()����,����߳̽����������ڡ��������̲߳����ٴθ�����
49.sleep() �� wait() ��ʲô����?
��������
- sleep��Thread��ķ���,wait��Object���ж���ķ���
- sleep�����������κεط�����
- wait����ֻ����synchronized������synchronized����ʹ��
��������
- Thread.sleep��static��̬����,���ܸı����Ļ���,��һ��synchronized���е�����sleep() ����,�߳���Ȼ��������,���Ƕ���Ļ���û�б��ͷ�,�����߳���Ȼ�������������ֻ���ó�CPU,���ᵼ������Ϊ�ĸı�
- Object.wait�����ó�CPU,�����ͷ��Ѿ�ռ�е�ͬ����Դ��
| ���� | wait() | sleep() |
|---|---|---|
| ������ | Object��ʵ������ | Thread�ྲ̬���� |
| �Ƿ��ͷ��� | �ͷ��� | �����ͷ��� |
| �߳�״̬ | �ȴ� | ˯�� |
| ʹ��ʱ�� | ֻ����ͬ����(Synchronized)��ʹ�� | ���κ�ʱ��ʹ�� |
| �������� | �����̵߳���notify()��notifyAll()���� | ��ʱ�����Interrupt()���� |
| cpuռ�� | ��ռ��cpu,����ȴ�n�� | ռ��cpu,����ȴ�n�� |
50.notify()�� notifyAll()��ʲô����?
- ����̵߳����˶���� wait()����,��ô�̱߳�ᴦ�ڸö���ĵȴ�����,�ȴ����е��̲߳���ȥ�����ö��������
- �����̵߳����˶���� notifyAll()����(�������� wait �߳�)�� notify()����(ֻ�������һ�� wait �߳�),�����ѵĵ��̱߳�����ö����������,�����е��̻߳�ȥ�����ö�������Ҳ����˵,������notify��ֻҪһ���̻߳��ɵȴ��ؽ�������,��notifyAll�Ὣ�ö���ȴ����ڵ������߳��ƶ���������,�ȴ�������
- ���ȼ��ߵ��߳̾������������ĸ��ʴ�,����ij�߳�û�о������ö�����,����������������,Ψ���߳��ٴε��� wait()����,���Ż����»ص��ȴ����С������������������߳����������ִ��,ֱ��ִ������ synchronized �����,�����ͷŵ��ö�����,��ʱ�����е��̻߳���������ö�������
- ���wait������֮ǰnotify�Ļ���֪ͨ������,��ô����̲߳����ܱ�֤������,�п��ܻᵼ���������⡣
51.�̵߳� run()�� start()��ʲô����?
����һ���߳� Thread t1 = new Thread()
t1.run():run�������߳�ִ��,ֻ�ǵ�����һ����ͨ����,��û��������һ���߳�,�����ǻᰴ��˳��ִ����Ӧ�Ĵ���,�������������ִ�����˴�����������ߡ�t1.start():start��new��һ���߳�ִ�е�,��ʾ���¿���һ���߳�,���صȴ������߳�������,ֻҪ�õ�cup�Ϳ������и��̡߳��ж���߳�ʹ��start��������ʱ,������Ҫ�ȴ�����һ�����,�������ǵ�ִ��˳��Ӧ���Dz��еġ�
52.�����̳߳����ļ��ַ�ʽ?
Executors�ഴ���̳߳�,�����������̳߳ض�ʵ����ExecutorService�ӿ�
newCachedThreadPool()�����ɻ�����̳߳�,����̳߳ص�����������������,�Զ����տ����߳�,��������ʱ�����Զ��������߳�,�̳߳ص����������ơ��Ƚ��ʺϴ���ִ��ʱ��Ƚ�С������newFixedThreadPool()�����̶���Ŀ�̵߳��̳߳�,ÿ���ύһ������ʹ���һ���߳�,ֱ���ﵽ�̳߳ص��������,��ʱ�߳��������ٱ仯,���̷߳����������ʱ,�̳߳ػᲹ��һ���µ��̡߳�����������֪����ѹ���������,���߳��������ơ�newScheduledThreadPool����һ��֧�ֶ�ʱ�������Ե�����ִ�е��̳߳�,��������¿��������Timer�ࡣ��������Ҫ�����̨�߳�ִ����������ij�����newSingleThreadExecutor����һ�����̻߳���Executor,�߳��쳣����,�ᴴ��һ���µ��߳�,��ȷ������ָ��˳��(FIFO,LIFO,���ȼ�)ִ�С�����������Ҫ��֤˳��ִ�еij���,����ֻ��һ���߳���ִ��
53.�̳߳ض�����Щ״̬?

ThreadPoolExecutor��Executor���µ�ʵ����,�����г��õ��̳߳ؾ�����
�̳߳ص�5��״̬:Running��ShutDown��Stop��Tidying��Terminated��
Running
- ״̬˵��:�̳߳ش���RUNNING״̬ʱ,�ܹ�����������,�Լ��������ӵ�������д�����
- ״̬�л�:�̳߳صij�ʼ��״̬��RUNNING�����仰˵,�̳߳ر�һ��������,�ʹ���RUNNING״̬,�����̳߳��е�������Ϊ0!
ShutDown
- ״̬˵��:�̳߳ش���SHUTDOWN״̬ʱ,������������,���ܴ��������ӵ�����
- ״̬�л�:�����̳߳ص�shutdown()�ӿ�ʱ,�̳߳���RUNNING -> SHUTDOWN��
Stop
- ״̬˵��:�̳߳ش���STOP״̬ʱ,������������,�����������ӵ�����,���һ�
�ж����ڴ���������- ״̬�л�:�����̳߳ص�
shutdownNow()�ӿ�ʱ,�̳߳���(RUNNING or SHUTDOWN ) -> STOP��
Tidying
- ״̬˵��:�����е���������ֹ,ctl��¼�ġ�����������Ϊ0,�̳߳ػ��ΪTIDYING״̬�����̳߳ر�ΪTIDYING״̬ʱ,��ִ�й��Ӻ���terminated()��terminated()��ThreadPoolExecutor�����ǿյ�,���û������̳߳ر�ΪTIDYINGʱ,������Ӧ�Ĵ���;����ͨ������terminated()������ʵ�֡�
- ״̬�л�:���̳߳���SHUTDOWN״̬��,��������Ϊ�ղ����̳߳���ִ�е�����ҲΪ��ʱ,�ͻ��� SHUTDOWN -> TIDYING��
���̳߳���STOP״̬��,�̳߳���ִ�е�����Ϊ��ʱ,�ͻ���STOP -> TIDYING��
Terminated
- ״̬˵��:�̳߳س�����ֹ,�ͱ��TERMINATED״̬��
- ״̬�л�:�̳߳ش���TIDYING״̬ʱ,ִ����terminated()֮��,�ͻ��� TIDYING -> TERMINATED��
54.�̳߳��� submit()�� execute()������ʲô����?
���߶���ִ������ķ���
execute()�����ڲ���Ҫ��ע����ֵ�ij���,ֻ��Ҫ���̶߳����̳߳���ȥִ�оͿ����ˡ�
submit()������������Ҫ��ע����ֵ�ij���
ʮ��Java�����
55.�����ռ��㷨/�ռ���
һ�ж���Ϊ��JVM����Ч��
���-����㷨
- ����: ���ȱ�dz�������Ҫ���յĶ���,�ڱ����ɺ�ͳһ�������б���ǵĶ���
- ȱ��
- Ч������:��Ǻ�����������̵�Ч�ʶ�����
- �ռ�����:������֮������������������ڴ���Ƭ,���ܻᵼ�³������й�������Ҫ����ϴ����ʱ,���ҵ��㹻�������ڴ�����ò���ǰ������һ�������ռ�������
�����㷨
- ����:�������ڴ水������С����Ϊ��С��ȵ�����,ÿ��ֻʹ�����е�һ�顣��һ���ڴ�ʹ������,�ͽ�������ŵĶ����Ƶ���һ������,Ȼ���ٰ���ʹ�ù����ڴ�ռ�һ��������������ʹ��ÿ�ζ��Ƕ��������������ڴ����,�ڴ����ʱҲ�Ͳ��ÿ����ڴ���Ƭ�ȸ���������ִ�����ҵ����������������ռ��㷨��������������
- ȱ��: ���ڴ���СΪ��ԭ����һ��,�ڶ������ʽϸ�ʱ,��Ҫ���н϶�ĸ��Ʋ���,Ч�ʾͻ��͡���
���-�����㷨
- ����: ���ȱ�dz�������Ҫ���յĶ���, �ڱ����ɺ������д��Ķ�����һ���ƶ�,Ȼ��ֱ���������߽�������ڴ档
�ִ��ռ��㷨
- ����:��Java�ѷ�Ϊ�������������,��������ص�����ʵ����ռ��㷨������������,ÿ�������ռ�ʱ�������д���������ȥ,ֻ���������,�Ǿ�ѡ�������㷨��
���������,��Ϊ�������ʸߡ�û�ж���ռ�������з��䵣��,�ͱ�����á����-��������-�������㷨�����л��ա�
56.�ж϶����Ƿ���
- �ж϶����Ƿ����롰���á��й�
����ϣ�������������������Ļ���ʱ���IJ�ͬ������һЩ�Ƚ���Ҫ�Ķ���,����ϣ��������������Զ��ȥ������,��ʹ��ʱ�ڴ�ռ��Ѿ�������,��Ϊһ����������,���������صĺ����������һЩ����ô��Ҫ�Ķ���,��������ͼƬ�����ʱ�����ɵĴ���ͼƬ�Ļ������,����ϣ������������ֻ���ڴ治��������ȥ�������л����������û����顣
Java��ʵ����������ǿ�Ȳ�ͬ������,��ǿ�������Ƿֱ���,ǿ����(Strong Reference),������(Soft Reference),������(Weak Reference)��������(Phantom Reference)��
ǿ����: ����ָ�ڳ������֮���ձ���ڵ�,���ơ�Object obj = new Object()�����������,ֻҪǿ���û�����,�����ռ�����Զ������յ������õĶ���
������: ���������ڴ������������ôǿ�����á�ʹ��WeakReference,��ϵͳ��Ҫ�����ڴ�����쳣֮ǰ,�������Щ�����н����շ�Χ֮�н��еڶ��λ��ա������÷dz��ʺ��ڴ������档��ϵͳ�ڴ治���ʱ��,�����е������ǿ��Ա��ͷŵġ�
������: �����DZ������ġ��������ù����Ķ���ֻ�����浽��һ�������ռ�����֮ǰ���������ռ�������ʱ,���۵�ǰ�ڴ��Ƿ��㹻,������յ�ֻ�������ù����Ķ���������������ô��ڹ�ϣ���С���һ����ֵ�Ա����뵽��ϣ����֮��,��ϣ�������������˶���Щ����ֵ��������á��������������ǿ���õĻ�,��ôֻҪ��ϣ�������������,�����������ļ���ֵ�����Dz��ᱻ���յġ����ij�����ʱ��ܳ��Ĺ�ϣ���а����ļ�ֵ�Ժܶ�,���վ��п������ĵ�JVM��ȫ�����ڴ档
������: һ��������ͨ����������ȡ��һ������ʵ��,������ͬ����,�������������ò�ͬ����,�����ò��������������������ڡ����һ�����������������,��ô���ͺ�û���κ�����һ��,���κ�ʱ���ܱ��������������ա���������Ҫ�������ٶ����������������յĻ�������ñ�������ö���(ReferenceQueue)����ʹ�á�������������������һ������ʱ,�������������������,�ͻ��ڻ��ն�����ڴ�֮ǰ,����������ü��뵽��֮ ���������ö���queue�С�
ReferenceQueue queue = new ReferenceQueue ();
//�����ö���
PhantomReference pr = new PhantomReference (object, queue);
�������ͨ���ж����ö������Ƿ��Ѿ�������������,���˽ⱻ���õĶ����Ƿ�Ҫ���������ա����������ij���������Ѿ������뵽���ö���,��ô�Ϳ����������õĶ�����ڴ汻����֮ǰ��ȡ��Ҫ���ж���- ���ü������ж϶���
����������һ�����ü�����,ÿ����һ���ط�������ʱ,������ֵ�ͼ�1;������
ʧЧʱ,������ֵ�ͼ�1;�κ�ʱ�̼�����Ϊ0�Ķ�����Dz����ܱ���ʹ�õġ�
������JVM����û��ѡ�����ü����㷨�������ڴ�,��������Ҫ��ԭ���������ѽ�
�������Ļ�ѭ�����õ����⡣- �ɴ��Է����㷨
ʮһ�� ����
57.���ҽ���5������ģ��
��ΪӦ�ò�,�����,�����,������·���������
������:���������豸��δ������ݡ�����˵,������������ǵ��Ե�Ӳ��,���ǵ������˿�,����,�Լ�������������ȥ֮��Ҫ����������Ϊ���ǰ����ݴ��䵽������,û������,���ǵ�������û�а취ȥ�����,����������,������ЩӲ���豸��صĶ�����
������·��:��ͨ�ŵ�������佨��������·����,��̨����,ҲҪ��һ����������������ͨ���������豸ȥ����һ����·������,Ҳ����˵�����߿��Դ�������,������ľ��ǵ��Դ������ݡ�
�����:Ϊ�����ڽ��֮�䴫�䴴������·������˵���ҵĵ��Է��ʰٶȵķ�����,��ô����ȥѰ�Ұٶ���̨�����������ڵĵ�ַ,������һ������ϵ,��ô�����ϵ���������Ϊ����ȥ�����ġ�
�����:����������·�㡢������ڽ������˴ӵ��Ե��ٶȵ�������֮�����ôһ������֮��,���ڲ�ͬ���ݵĴ��䷽ʽ���ɴ������ʵ�ֵġ�����ʹ��httpЭ��Ҫ����һ������,����ֻ��Ҫ���������������һ��url,���ͻ��Զ�ȥ������ص�һ�����ݵ���������,Ȼ����������ܹ�������Щ���ݷ��ظ����ǵ������,Ȼ���ҳ����ʾ����,��ô��������url�������,��ʵ�漰����һϵ�е����ݵ�ƴװ�Լ�����,�������Dz���Ҫָ����Щ�������浽������ôȥ��Ƭ,��ôȥ������������һ�����ӵĹ�ϵ,��Ϊ������Ѿ�������ʵ���ˡ�
Ӧ�ò�:Ϊ����Ӧ�������ṩ�˺ܶ����д��ҳ��ʱ��,����ʹ��httpЭ��ȥ��������,�����Ƿdz������,ֻҪȥnewһ��request����,Ȼ��Ϳ���ȥ��һЩ����,����post,get�ķ�ʽȥ���͵������,����Ӧ�ò���httpЭ������,��������ʵ����httpЭ��,Ȼ������ֻ��Ҫȥʹ��httpЭ����ص�һЩ����,�Ϳ�������ȥ����һЩ����,���ǹ�����tcpЭ��֮�ϵ�,����������ķ�ʽ,����Ҫ��ʵ��tcp,ipЭ�����档
58.HTTP���HTTPS������
- HTTP �����Ĵ���Э��,HTTPS Э������ SSL+HTTP Э�鹹���Ŀɽ��м��ܴ��䡢������֤������Э��,�� HTTP Э�鰲ȫ��
- HTTPS��HTTP���Ӱ�ȫ,������������Ѻ�,����SEO,�ȸ衢�ٶ���������HTTPS��ҳ;
- HTTPS��Ҫ�õ�SSL֤��,��HTTP����;
- HTTPS���˿�443,HTTP���˿�80;
- HTTPS���ڴ����,HTTP����Ӧ�ò�;
- HTTPS���������ʾ��ɫ��ȫ��,HTTPû����ʾ;
59.TCP��UDPЭ�鹤������һ��
�����Э��:TCP��UDPЭ�顣������Э��+�˿��Ϳ��Ա�ʶһ��Ӧ�ò�Э��,TCP/IPЭ���еĶ˿ڷ�Χ�Ǵ�0~65535������֪��,һ̨ӵ��IP��ַ�����������ṩ�������,����Web����FTP����SMTP�����,��Щ������ȫ����ͨ��1��IP��ַ��ʵ��
�������:IP��
Ӧ�ò�Э��:FTP��HTTP��SMTP
60.�������ֺ��Ĵλ���
TCP �� UDP������Э��Ĵ�����ϵ����ֲ�ͬ��Э�顣TCP���ص����������ӵġ��ɿ����ֽ������ͻ�����Ҫ�ͷ�����֮�佨��һ��TCP����,֮����ܴ������ݡ����ݵ���֮ǰ�Է���һֱ�ڵȴ�,���ǶԷ�ֱ�ӹر�����,��������,�ȷ��ȵ���UDP��һ�������ӡ����ɿ������ݷ���Э�顣���ͷ����ݶԷ���ip��ַ�������ݰ�,���Dz���֤���շ��Ӱ�������,������������������ȻUDPЭ�鲻�ȶ������ڼ�ʱͨѶ(QQ���졢������Ƶ�����������绰)�ij�����,��������ż���Ķ���,��������Э���ٶȿ졣
TCP���ӽ�����ǰ��,��ͨ�ŵ�˫����Ҫ֪�������ͶԷ��ķ��ͺͽ��չ���,������������Ҳ������TCP���ӽ���֮ǰ,�������˸���ȷ����:����˺Ϳͻ��˶�Ҫ֪������˷��͡�����˽��ա��ͻ��˷��͡��ͻ��˽����������ġ�
- ��һ������:�ͻ��˷�����������,����˽���,���Է���˿���ȷ�Ͽͻ��˵ķ�����,����˵Ľ��չ�������;
- �ڶ�������:������յ����������Ķκ�,ͬ�����ӷ���Ӧ��,�ͻ��˽��յ��ڶ������ֱ��ĺ�,�ͻ����ܹ�ȷ�Ϸ���˷��͡�����˽���,�ͻ��˵Ľ��չ��ܺͷ�������������;���Ǵ�ʱ����˲���֪���Լ��ķ�����,�ͻ��˵Ľ��չ����Ƿ�����,������Ҫ����������
- ����������: �ͻ����յ�����ͬ���Ӧ���,��Ҫ�����˷���һ��ȷ�ϱ��Ķ�,��ʾ:����˷���������ͬ��Ӧ���Ѿ��ɹ��յ�����ʱ,����˾Ϳ���ȷ���Լ��ķ�����,�ͻ��˵Ľ��չ����������ġ�
- ΪʲôҪ��������?
client�����ĵ�һ�����������Ķβ�û�ж�ʧ,������ij�������㳤ʱ���������,�������������ͷ��Ժ��ij��ʱ��ŵ���server����������һ������ʧЧ�ı��ĶΡ���server�յ���ʧЧ�����������Ķκ�,������Ϊ��client�ٴη�����һ���µ������������Ǿ���client����ȷ�ϱ��Ķ�,ͬ�⽨�����ӡ����費���á��������֡�,��ôֻҪserver����ȷ��,�µ����Ӿͽ����ˡ���������client��û�з����������ӵ�����,��˲�������server��ȷ��,Ҳ������server�������ݡ���serverȴ��Ϊ�µ����������Ѿ�����,��һֱ�ȴ�client�������ݡ�����,server�ĺܶ���Դ�Ͱװ��˷ѵ��ˡ�
�Ĵλ�����ָ��ֹTCP����Э��ʱ,��Ҫ�ڿͻ��˺ͷ�����֮�䷢���ĸ���,���ֵ�ǰ����˫���ж�֪���Է�û�����ݿ��Է����Է���:
- ��һ�η���:����1(����ʹ�ͻ���,Ҳ�����Ƿ�������),����SequenceNumber,������2����һ��FIN���Ķ�;��ʱ,����1����FIN_WAIT_1״̬;���ʾ����1û������Ҫ��������2��;
- �ڶ��η���:����2�յ�������1���͵�FIN���Ķ�,������1��һ��ACK���Ķ�,Acknowledgment NumberΪSequence Number��1;����1����FIN_WAIT_2״̬;����2��������1,�ҡ�ͬ�⡱��Ĺر�����;
- �����η���:����2������1����FIN���Ķ�,����ر�����,ͬʱ����2����LAST_ACK״̬;
- ���Ĵη���:����1�յ�����2���͵�FIN���Ķ�,������2����ACK���Ķ�,Ȼ������1����TIME_WAIT״̬;����2�յ�����1��ACK���Ķ��Ժ�,�ر�����;��ʱ,����1�ȴ�2MSL����Ȼû���յ��ظ�,��֤��Server���������ر�,�Ǻ�,����1Ҳ���Թر������ˡ�
- ΪʲôҪ�Ĵη���?
TCPЭ����һ���������ӵġ��ɿ��ġ������ֽ����������ͨ��Э�顣TCP��ȫ˫��ģʽ,�����ζ��,������1����FIN���Ķ�ʱ,ֻ�DZ�ʾ����1�Ѿ�û������Ҫ������,����1��������2,���������Ѿ�ȫ�����������;����,���ʱ������1���ǿ��Խ�����������2������;������2����ACK���Ķ�ʱ,��ʾ���Ѿ�֪������1û�����ݷ�����,��������2���ǿ��Է������ݵ�����1��;������2Ҳ������FIN���Ķ�ʱ,���ʱ��ͱ�ʾ����2Ҳû������Ҫ������,�ͻ��������1,��Ҳû������Ҫ������,֮��˴˾ͻ������ж����TCP���ӡ�
ʮ���������ģʽ
61.��˵˵����ģʽ & ����Ŀ�г��õĵ���ģʽ
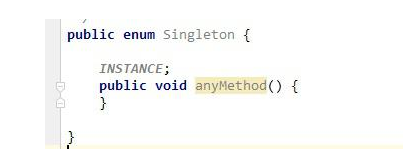
����˼�����ֻ��һ��ʵ��,�������Լ������Լ��Ķ���,������ṩ��һ�ַ�����Ψһ�Ķ���ķ�ʽ,����ֱ�ӷ���,����Ҫʵ��������Ķ����Ĵ���:���췽��˽�л�,private��
�����
- ����ʽ:����˼�����ʵ�����õ���ʱ���ȥ����,���Ƚ�����,�õ�ʱ���ȥ�����û��ʵ��,�������,û�����½������̰߳�ȫ���̲߳���ȫ����д��,�������synchronized�ؼ��֡�
- ����ʽ: ��������Ҳ�ܺ�����,���ǡ��Ƚ��ڡ�,ʵ���ڳ�ʼ����ʱ����Ѿ�������,��������û���õ�,���Ƚ�������˵���ô���û���̰߳�ȫ������,�������˷��ڴ�ռ䡣
- ˫����,�ֽ�˫��У����,�ۺ�������ʽ�Ͷ���ʽ���ߵ���ȱ�����϶��ɡ��ص�����synchronized�ؼ������ⶼ����һ�� if �����ж�,�����ȱ�֤���̰߳�ȫ,�ֱ�ֱ�����������ִ��Ч��,����ʡ���ڴ�ռ䡣
- ��̬�ڲ���:��̬�ڲ���ķ�ʽЧ������˫����,��ʵ�ָ��������ַ�ʽֻ�����ھ�̬������,˫������ʽ����ʵ������Ҫ�ӳٳ�ʼ��ʱʹ�á�
- ö���ķ�ʽ�DZȽ��ټ���һ��ʵ�ַ�ʽ,���ǿ�����Ĵ���ʵ��,ȴ��������������������Զ�֧�����л�����,���Է�ֹ���ʵ������
62.�˽�������ģʽ
������ģʽ
�����ʵ�������̽����˳���,�ܹ�������ģ���ж���Ĵ����Ͷ����ʹ�÷��롣Ϊ��ʹ�����Ľṹ��������,��������Щ����ֻ��Ҫ֪�����ǹ�ͬ�Ľӿ�,�������������ʵ��ϸ��,ʹ����ϵͳ����Ƹ��ӷ��ϵ�һְ��ԭ��
- ����ģʽ(Simple Factory)
- ��������ģʽ(Factory Method)
- ����ģʽ(Abstract Factory)
- ������ģʽ(Builder)
- ԭ��ģʽ(Prototype)
- ����ģʽ(Singleton)
�ṹ��ģʽ
������ν�����߶� ������һ���γɸ���Ľṹ,������ľ,����ͨ�� ��ľ������γɸ��ӵġ����ܸ�Ϊǿ��Ľṹ��
- ������ģʽ(Adapter)
- �Ž�ģʽ(Bridge)
- ���ģʽ(Composite)
- װ��ģʽ(Decorator)
- ���ģʽ(Facade)
- ��Ԫģʽ(Flyweight)
- ����ģʽ(Proxy)
��Ϊ��ģʽ
�Ƕ��ڲ�ͬ�Ķ���֮�仮�����κ��㷨�ij�����Ϊ��ģʽ��������ע��Ͷ���Ľṹ,�����ص��ע����֮�������á�ͨ����Ϊ��ģʽ,���Ը��������ػ�����������ְ��,���о�ϵͳ������ʱʵ������ ֮��Ľ�������ϵͳ����ʱ,�����ǹ�����,���ǿ���ͨ���ͨ����Э�����ijЩ���ӹ���,һ������������ʱҲ��Ӱ�쵽������������С�
- ְ����ģʽ(Chain of Responsibility)
- ����ģʽ(Command)
- ������ģʽ(Interpreter)
- ������ģʽ(Iterator)
- �н���ģʽ(Mediator)
- ����¼ģʽ(Memento)
- �۲���ģʽ(Observer)
- ״̬ģʽ(State)
- ����ģʽ(Strategy)
- ģ�巽��ģʽ(Template Method)
- ������ģʽ(Visitor)