��������
1 ����ж϶�����Ի���
1.1 ���ü�����
����˼��,ÿ������һ�ξ�+1;
����ѭ�����õ����,ѭ�����õĶ���Ͳ��ᱻ����,����ڴ�й©��

1.2 �ɴ��Է����㷨
Java������е��������������ÿɴ��Է�����̽�����д��Ķ���;ɨ����еĶ���,���ܷ�����GC Root����(������)Ϊ�����������ҵ��ö���,�Ҳ�����ʾ���Ի��ա�����ȷ��������,�ɸ�������ӻ�ֱ�������Ķ����ܻ��ա�
��Щ���������Ϊ��������
- �����ջ(ջ֡�еľֲ�������)�����õĶ���
- ���ط���ջ��Native�������õĶ���
- ���������ྲ̬�������õĶ��� �Լ� �������õĶ���
1.3 ��������
1.ǿ����
- ͨ��new �ؼ��ֵļ���ǿ����
- ֻ�� ����GCRoots���� ����ͨ����ǿ���á����øö���,�ö�����ܱ���������
2.������(SoftReference)
- �������������øö���ʱ,���������պ�,�ڴ��Բ���ʱ���ٴγ�����������,���������ö���,����������ö������ͷ�����������
3.������(WeakReference)
- �������������øö���ʱ,����������ʱ,�����ڴ��Ƿ����,������������ö���,����������ö������ͷ�����������
4.������(PhantomReference)
- ����������ö���ʹ��,��Ҫ���ByteBufferʹ��,�����ö������ʱ,�Ὣ���������,�� Reference Handler�̵߳�����������ط����ͷ�ֱ���ڴ� �C ������Cleaner���ݼ�¼��ֱ���ڴ��ַ������ֱ���ڴ�
5.�ս�������(FinalReference)
- �����ֶ�����,�����ڲ�������ö���ʹ��,����������ʱ,�ս����������(�����ö�����ʱû�б�����),����Finalizer�߳�ͨ���ս��������ҵ������ö���������finalize����,�ڶ���GCʱ���ܻ��ձ����ö���
������Ӧ��
public static void soft() {
//list-> SoftReference--> byte[]
List<SoftReference<byte[]>> list= new ArrayList<>();
for(int i=0;i<5;i++){
SoftReferencec<byte[]> ref=new SoftReference<>(new byte[_4MB]);
System.out.println(ref.get());
list.add(ref);
System.outprintln(list.size())
}
System.out.println("�����:"+list.size());
for(SoftReference<byte[]> ref :list){
System.out.println(ref.get());
}
}
ʹ�����ö���������õ�������
private static final int_4MB=4* 1024* 1024;
public static void main(string[] args){
List<SoftReference<byte[]>> list = new ArrayList<>();
ReferenceQueue<byte[]> queue=new ReferenceQueue<>();//���ö���
for(int i=0;i<5;i++){
//���������ö���,����������������byte[]������ʱ,�������Լ�����뵽queue��ȥ
SoftReference<byte[]> ref=newSoftReference<>(new byte[_4MB],queue);
System.out.println(ref.get());
list.add(ref);
System.out.println(list.size());
}
//�Ӷ����л�ȡ���õ� �����ö���,���Ƴ�
Reference<? extends byte[]>poll=queue.poll();
while( poll != null) {
list.remove(poll);
poll = queue.poll();
}
System.out.println("========");
for(SoftReference<byte[]> reference :list){
System.outprintln(reference.get());
}
}
������Ӧ��
public static void soft() {
//list-> WeakReference--> byte[]
List<WeakReference<byte[]>> list= new ArrayList<>();
for(int i=0;i<5;i++){
WeakReference<byte[]> ref=new WeakReference<>(new byte[_4MB]);
System.out.println(ref.get());
list.add(ref);
for(WeakReference<byte[]> w :list){
System.out.println(w.get());
}
}
}
2 ���������㷨
2.1 ������
��dz�������Ҫ���յĶ���,���ձ���Ƕ���
- �ٶȽϿ�
- ������ڴ���Ƭ
2.2�������
��dz�������Ҫ���յĶ���,���ձ���Ƕ���,��δ����Ƕ�����ڴ� ������ �������ڴ�ռ�,��������̻�ʹ�ö����ַ�ı�,���
- �ٶ���
- û���ڴ���Ƭ
2.3 ����
���ڴ滮��Ϊ�ȴ������,ÿ��ֻʹ�����е�һ�顣��һ�������˴�����������:��dz�������Ҫ���յĶ���,��δ����ǵĶ����Ƶ���һ���ڴ�ռ�,��һ�������ڴ�ռ����;�´δ�����������ʱ�ֽ���һ����ĸ��Ƶ����,��һ������һ�����,ѭ��������
- �������ڴ���Ƭ
- ��Ҫռ��˫���ڴ�ռ�,�ڴ������ʲ���
2.4 �ִ��㷨
���ڴ�����Ϊ�������������,��Բ�ͬ�����ȡ��ͬ�㷨:
- ��������ȡ�����㷨,�������ȡ�������/�������㷨
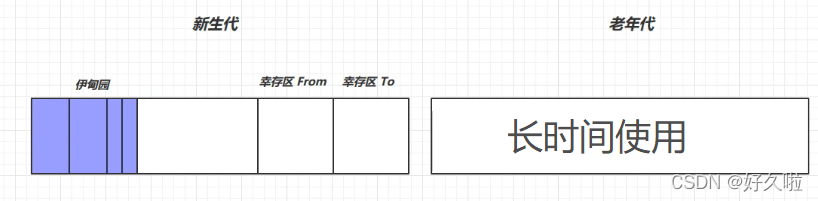
- �������ȷ�������������
- �������ռ䲻��ʱ,��������������(Minor GC),�������Ķ������Ƶ��Ҵ�����,���Ķ��������1;�´δ���Minor GCʱ,�������Ҵ������Ķ���,���Ķ��������1,���Ƶ���һ���Ҵ���,ѭ������
- From �� To ������Ϊ������Ҵ���From���Ƶ���һ���Ҵ���To,����Ҵ������ֲ����̶�,������ΪֻΪ�������
- Minor gc������ stop the world(STW),��ͣ�����û����߳�,���������ս���,�û��̲߳Żָ�����
- ��������������һ����ֵʱ,������������,�������15(4bit)
- ��������ռ䲻��,���ȳ��Դ�������������,���֮��ռ��Բ���,��ᴥ��Full GC,STWʱ�����
ע��:
�������̵߳����в���Ӱ�����̵߳��������,�������̵߳��ڴ����,����Ӱ�����̵߳���������
3 ����������
�ܵ���˵�����������ɷ�Ϊ����:���С����С�������G1
3.1 ����
-
�����ڵ��̡߳����ڴ��С
-
����ͣ���������߳�
Serial�ռ���:����������ȡ����(Serial),���������ȡ�������(Serial Old)
��Ӧ��JVM����:-XX:+UseSerialGC

3.2 ����
- �����������̲߳��й���,����ͣ���������߳�
- ��������������
ParNew�ռ���: ֻ����������Ļ���,��Serial�ռ����������IJ��ж��̰߳汾,ͬ������������ȡ���ơ�
��Ӧ��JVM����:-XX:+UseParNewGC �C ParNew + Serial Old���ռ������
Parallel�ռ���:����������ȡ����(Parallel Scavenge),���������ȡ�������(Parallel Old)��
-
Parallel Scavenge�ռ���:����ParNew�ռ���Ҳ��һ�����еĶ��̵߳������ռ���,�׳������������ռ�����
������: �����û�����ʱ�� ռ�� (�����û�����ʱ�� + ��������ʱ��)
���������10����, ��������5��,������ԼΪ99%
-
Parallel Old�ռ���:��SerialOld�ռ�����������IJ��ж��̰߳汾
��ӦJVM����:-XX:+UseParallelGC �� -XX:+UseParallelOldGC �C Parallel Scanvenge + Parallel Old���ռ������
ParNew�ռ��� �� Parallel Scavenge�ռ��� ���� �C Parallel Scavenge�ռ���������Ӧ����
- ���������ݵ�ǰϵͳ����������ռ����ܼ����Ϣ,��̬�����������ṩ����ʵ�ͣ��ʱ��(-XX:MaxGCPauseMillis)������������
3.3 ����
-
���������̺߳������߳̿ɲ���ִ��,����ֹͣ�����߳�
-
�����ڶ���Ӧʱ����Ҫ���,���ڴ��,CPU����֧��
���������������

CMS�ռ��� :Concurrent Mark Sweep: ���������� ,��һ���Ի�ȡ��̻���ͣ��ʱ��ΪĿ����ռ�����
- ��ʼ���:��Ǹ�����ֱ�����õĶ���,��STW��ֹͣ�����߳�
- �������:�ҳ������������õĴ�����,�����̲߳���ִ��
- ���±��:������������ڼ��������̼߳������ж����±�Dz����䶯����һ���ֶ���ı�Ǽ�¼,��STW
- �������:���ս�Ҫ���ն���
��Ӧ��JVM����: -XX:+UseConcMarkSweepGC (�Զ���-XX:+UseParNewGC��)�C
ParNew + CMS + Serial Old���ռ������,Serial Old����ΪCMS�����ĺ��ռ���
ע��:
- ��������������,��֮ǰ�жϸö���������,�����û��߳�ͬʱҲ�������й����е�,���������֮ǰ�ö����Ѿ��������������,������ɱ��ñ����յ�û�б�����,ֻ�ܵȴ���һ��GC�ٽ��ö������
- Ҫ��CMS�����ڼ�Ԥ�����ڴ�������������Ҫ,�ͻ����Concurrent Mode Failure,������ʱ����Serial Old�ռ�������������������ռ�,STWʱ��Ҳ����˱䳤
3.4 G1
G1������ȫ��,�ȿ�����������ʹ�ú������ʹ��
-
ͬʱע���������͵��ӳ�,Ĭ�ϵ���ͣ��200ms
-
������ڴ�,�Ὣ�ѻ���Ϊ�����С��ȵ�region,��ͨ��-XX:G1HeapRegionSize�������������С,������2���ݴη�
-
�������DZ��+�����㷨,����region����֮���Ǹ����㷨
G1�ռ���: һ���������ڴ���̵������ռ���,��������ܶ��ڴ���Ƭ;STW���ɿ�,��ͣ��ʱ���ϼ���Ԥ�����,�û�����ָ������ͣ��ʱ�䡣
�ɷ�Ϊ�����ĸ�����:
-
��ʼ���:��Ǹ�����ֱ�����õĶ���,��STW��ֹͣ�����߳�;
������TAMS��ֵ,����һ���û���������ʱ,������ȷ���õ�Region�д����¶���
ÿ�� Region ��¼������ top-at-mark-start (TAMS) ָ��,�ֱ�Ϊ
prevTAMS��nextTAMS,�� TAMS ���ϵ��ڴ�ռ��Ӧ�Ķ�������·���� -
�������:�ҳ������������õĴ�����,�����̲߳���ִ��
-
���ձ��:������������ڼ��������̼߳������ж����±�Dz����䶯����һ���ֶ���ı�Ǽ�¼,��STW
-
ɸѡ����:�Ը���Region�Ļ��ռ�ֵ�ͳɱ���������,�����û���������GCͣ��ʱ�����ƶ����ռƻ�,�Ѿ������յ���һ����Region�Ĵ������Ƶ��յ�Region��,��������������Region��ȫ���ռ�,��STW
�������ս�
����������:����GC Root�ij�ʼ���,��STW;
����������+�������:�����ռ�öѿռ�����ﵽ��ֵʱ,���в������(����STW);
��ϻ���:����ȫ��Ļ���,���ձ�ǺͿ������,��STW��(������ֹͣʱ����,Ϊ���������պ���ͷŵĶѿռ�϶�,��ѡ���ڴ�ϴ�Ŀռ�
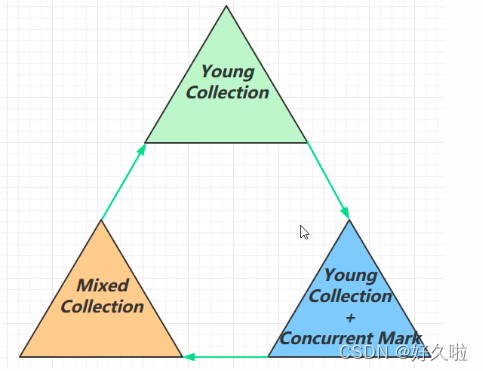
�������
�������������������
��������ʱ��Ҫ���ݸ�������пɴ��Է���,�����������Ҳ���и�����,������ÿ��Բ���Ҫ��ȫ���������,����ͨ����������õ�������
���
���ж�����������Ǻ�,����֪����Щ��ٱ�ʹ��,��һ��������������������ʹ��,��ж���������ص������ࡣ
���վ��Ͷ���
-
һ���������region��һ��ʱ,��֮Ϊ���Ͷ���
-
G1����Ծ��Ͷ�����п���
-
����ʱ�����ȿ���
-
G1��������������incoming����,���������incoming����Ϊ0�ľ��Ͷ���Ϳ�����������ʱ������
4 �������յ���
��������
- �ڴ�
- ������
- CPUռ��
- io
ȷ��Ŀ��
���ӳٻ��Ǹ�������,ѡ����ʵĻ�����
- CMS G1 ZGC �C ���ӳ�
- ParallelGC --��������
- Zing ����� �C ���ӳ�
4.1 ����GC�Dz�����GC
��Ϊ���Ƶ���ķ���GC�Ǿ�˵��STW��ʱ��Խ��,��ô�Գ��������Ҳ�Dz����ġ�
-
�鿴FullGCǰ����ڴ�ռ��,������������
-
�����Dz���̫��
�����ݿ���������,�������Щ����Ҫ������,��ͨ��limit����
-
���ݱ�ʾ�Ƿ�̫ӷ��
-
�Ƿ�����ڴ�й©
static Map map ���ֳ��ȴ��ڵĶ���
������/������
����������ʵ�� ���м�� redis
-
4.2 ����������
- ���������ص�
- ���е�new�������ڴ����dz�����
- ��������Ļ��մ�����0
- �ֶ����ù�����
- ����������Minor GCʱ��ԶԶ����Full GC
�������ڴ�Խ��Խ����:
- С:�Ϳ��ܻ�Ƶ������Minor GC;Oracle�Ƽ�ռ�ݶ��ڴ��25%-50%;
- ̫��:��ô��������ʱ��ľͿ���Խ����
�������:
-
���������������С�������*(����-��Ӧ)��������
-
�Ҵ�����������ǰ��Ծ����+��Ҫ��������
����Ҵ���̫С,���Զ�����������ֵ,�Ϳ��ܻ���ǰ����������������,��ɵ�Ӱ��:ԭ�ȱ��������̵ܶĶ���õȵ�Full GCʱ���ܽ�������
-
������ֵ���õõ�,�ó�ʱ����������
Minor GC��Ҫ�DZ�Ǻ���,��Ҫ����ʱ���ڸ�����;��������ܳ��Ķ����ܾ������,�Ǿ�˵�����Ҵ����ᱻ����������ȥ,��ô�����ܶ��Է����Ǹ�������
4.3 ���������
��CMS��
CMS�����ռ���������ȱ��,��һ����������������,���ڲ��������Ĺ�����,�û��߳��ֲ������µ�����,��Щ���������ֻ�ܵȵ��´�FullGC���������������������ҪԤ��һ���Ŀռ�װ�¸�����������CMS�����оͿ��ܵ��²���ʧ��,��CMS����ʱ�ڴ�ռ�������,��ʱ������Ž�Serial Old�ó�������STW,���д��е�����������
-
CMS��������ڴ�Խ��Խ��,���⸡����������IJ���ʧ��
-
�ȳ��Բ�������,���û��Full GC��ô˵�������û���ڴ�ռ䲻��,��ʹ�з���Full GC,�ȳ��Ե���������
-
�۲췢��Full GCʱ,������ڴ�ռ��,��������ڴ�Ԥ�����1/4 ~1/3,����Full GC�ķ���
-XX:CMSInitiatingOccupancyFraction=percent ��������CMSʱ����������ڴ�ռ��ֵ

ע��:ͼƬ��Դ��ĸվJVMϵ����Ƶ��ͼ