虽说不使用系统框架也能编写 Objective-C代码,但几乎没人这么做。即便是NSObject 这个标准的根类,也属于Foundation框架,而非语言本身。若不使用Foundation,就必须自己编写根类,同时还要自己来写collection、事件循环,以及其他会用到的类。此外,若不用系统框架,也就无法使用Objective-C来开发 Mac OS X及 iOS应用程序了。系统框架很强大,不过它是历经多年研发才成了今天这个样子的。因此,里面也许会有不合时宜而且用起来很蹩脚的地方,但也会有遗失的珍宝藏于其间。
一、熟悉系统框架
编写Objective-C应用程序时几乎都会用到系统框架,其中提供了许多编程中经常使用的类,比如 collection。若是不了解系统框架所提供的内容,那么就可能会把其中已经实现过的东西又重写一遍。用户升级操作系统后,你所开发的应用程序也可以使用最新版的系统库了。所以说,如果直接使用这些框架中的类,那么应用程序就可以得益于新版系统库所带来的改进,而开发者也就无须手动更新其代码了。
将一系列代码封装为动态库(dynamic library),并在其中放入描述其接口的头文件,这样做出来的东西就叫框架。有时为iOS平台构建的第三方框架所使用的是静态库(static library),这是因为 iOS应用程序不允许在其中包含动态库。这些东西严格来讲并不是真正的框架,然而也经常视为框架。不过,所有iOS平台的系统框架仍然使用动态库。
在为 Mac OSX或 iOS系统开发"带图形界面的应用程序"(graphical application)时,会用到名为Cocoa 的框架,在 iOS上称为Cocoa Touch。其实Cocoa本身并不是框架,但是里面集成了一批创建应用程序时经常会用到的框架。
开发者会碰到的主要框架就是 Foundation,像是NSObject、NSArray、NSDictionary 等类都在其中。Foundation框架中的类,使用NS这个前缀,此前缀是在 Objective-C语言用作NeXTSTEP操作系统°的编程语言时首度确定的。Foundation框架真可谓所有Objective-C 应用程序的"基础",若是没有它,那么本书大部分内容就不知所云了。
Foundation 框架不仅提供了collection 等基础核心功能,而目还提供了字符串处理这样的复杂功能。比方说,NSLinguisticTagger 可以解析字符串并找到其中的全部名词、动词、代词等。简言之,Foundation 所提供的功能远远不止那几个基础类。
还有个与Foundation相伴的框架,叫做 CoreFoundation。虽然从技术上讲,CoreFound-ation 框架不是 Objective-C框架,但它却是编写Objective-C 应用程序时所应熟悉的重要框架,Foundation框架中的许多功能,都可以在此框架中找到对应的C语言 API。CoreFoundation 与 Foundation不仅名字相似,而且还有更为紧密的联系。有个功能叫做"无缝桥接"(toll-free bridging)3,可以把 CoreFoundation中的 C语言数据结构平滑转换为 Foundation中的Objective-C对象,也可以反向转换。比方说,Foundation框架中的字符串是 NSString,而它可以转换为CoreFoundation 里与之等效的 CFString 对象。无缝桥接技术是用某些相当复杂的代码实现出来的,这些代码可以使运行期系统把CoreFoundation框架中的对象视为普通的Objective-C对象。但是,像无缝桥接这么复杂的技术,想自己编写代码实现它,可不太容易。开发程序时可以使用此功能,但若决定以手工编码的方式来复刻这套机制,则需认真审视自己的想法了。
除了Foundation与CoreFoundation 之外,还有很多系统库,其中包括但不限于下面列出的这些∶
■CFNetwork 此框架提供了C语言级别的网络通信能力,它将"BSD套接字"(BSDsocket)抽象成易于使用的网络接口。而 Foundation 则将该框架里的部分内容封装为Objective-C语言的接口,以便进行网络通信,例如可以用NSURLConnection 从 URL 中下载数据。
■ CoreAudio 该框架所提供的C语言API可用来操作设备上的音频硬件。这个框架属于比较难用的那种,因为音频处理本身就很复杂。所幸由这套 API可以抽象出另外一套 Objective-C 式 API,用后者来处理音频问题会更简单些。
■ AVFoundation 此框架所提供的 Objective-C对象可用来回放并录制音频及视频,比如能够在 UI视图类里播放视频。
■ CoreData 此框架所提供的 Objective-C接口可将对象放入数据库,便于持久保存。CoreData 会处理数据的获取及存储事宜,而且可以跨越 Mac OS X及 iOS平台。
■ CoreText 此框架提供的C语言接口可以高效执行文字排版及渲染操作。
除此之外,还有别的框架,然而通过此处列出的这几个框架,可以看出Objective-C 编程的一项重要特点,那就是∶经常需要使用底层的C语言级 API。用C语言来实现API的好处是,可以绕过 Objective-C的运行期系统,从而提升执行速度。当然,由于ARC只负责Objective-C的对象(参见第 30条),所以使用这些 API时尤其需要注意内存管理问题。若想使用这种框架,一定得熟悉C语言基础才行。
读者可能会编写使用 UI框架的 Mac OS X或iOS 应用程序。这两个平台的核心 U框架分别叫做AppKit 及 UIKit,它们都提供了构建在 Foundation与CoreFoundation之上的Objective-C类。框架里含有 UI元素,也含有粘合机制,令开发者可将所有相关内容组装为应用程序。在这些主要的 U框架之下,是 CoreAnimation与 CoreGraphics框架。
CoreAnimation是用Objective-C语言写成的,它提供了一些工具,而UI框架则用这些工具来渲染图形并播放动画。开发者编程时可能从来不会深入到这种级别,不过知道该框架总是好的。CoreAnimation 本身并不是框架,它是QuartzCore框架的一部分。然而在框架的国度里,CoreAnimation 仍应算作"一等公民"(first-class citizen)。
CoreGraphics 框架以C语言写成,其中提供了2D渲染所必备的数据结构与函数。例如,其中定义了CGPoint、CGSize、CGRect等数据结构,而 UIKit 框架中的 UIView类在确定视图控件之间的相对位置时,这些数据结构都要用到。
还有很多框架构建在 UI框架之上,比方说 MapKit框架,它可以为 iOS程序提供地图功能。又比如 Social框架,它为 Mac OS X及iOS程序提供了社交网络(social networking)功能。开发者通常会将这些框架与操作系统平台所对应的核心 UI框架结合起来使用。
总的来说,许多框架都是安装 Mac OS X与 iOS系统时的标准配置。所以,在打算编写新的工具类之前,最好在系统框架里搜一下,通常都有写好的类可供直接使用。
要点
■ 许多系统框架都可以直接使用。其中最重要的是 Foundation与CoreFoundation,这两个框架提供了构建应用程序所需的许多核心功能。
■ 很多常见任务都能用框架来做,例如音频与视频处理、网络通信、数据管理等。
■请记住∶用纯C写成的框架与用 Objective-C写成的一样重要,若想成为优秀的Objective-C 开发者,应该掌握C 语言的核心概念。
多用块枚举,少用 for循环
在编程中经常需要列举 collection 中的元素,当前的 Objective-C 语言有多种办法实现此功能,可以用标准的 C语言循环,也可以用Objective-C1.0的 NSEnumerator 以及 Objective-C 2.0的快速遍历(fast enumeration)。语言中引入"块"这一特性后,又多出来几种新的遍历方式,而这几种方式容易为开发者所忽视。采用这几种新方式遍历 collection 时,可以传入块,而 collection 中的每个元素都可能会放在块里运行一遍,这种做法通常会大幅度简化编码过程,笔者下面将会详细说明。
本条所讲的 collection包含 NSArray、NSDictionary、NSSet 这几个频繁使用的类型。此外,这里所说的遍历技巧也适用于自定义的collection,但是具体做法并不在本条范围内。
for 循环
遍历数组的第一种办法就是采用老式的 for 循环,这令人想起∶在作为 Objective-C 根基的C语言里,就已经有此特性了。这是个很基本的办法,因而功能非常有限。通常会这样写代码∶
NSArray *anArray =/*...*/;
for (int i = 0; i< anArray.count; i++) {
id object= anArray[i];
// Do something with 'object'
}
这么写还好,不过若要遍历字典或 set,就要复杂一些了∶
// Dictionary
NSDictionary *aDictionary = /*...*/;
NSArray *keys = [aDictionary allKeys];
for (int i = 0;i< keys.count;i++) {
id key = keys[i];
id value = aDictionary[key];
// Do something with 'key' and 'value'
}
//Set
NSSet *aSet = /* ...*/;
NSArray *objects = [aSet allObjects];
for (int i = 0; i< objects.count; i++) {
id object = objects[i];
// Do something with 'object'
}
根据定义,字典与set 都是"无序的"(unordered),所以无法根据特定的整数下标来直接访问其中的值。于是,就需要先获取字典里的所有键或是 set 里的所有对象,这两种情况下,都可以在获取到的有序数组上遍历,以便借此访问原字典及原 set中的值。创建这个附加数组会有额外开销,而且还会多创建一个数组对象,它会保留 collection中的所有元素对象。当然了,释放数组时这些附加对象也要释放,可是要调用本来不需执行的方法。其他各种遍历方式都无须创建这种中介数组。
for循环也可以实现反向遍历,计数器的值从"元素个数减1"开始,每次迭代时递减,直到0为止。执行反向遍历时,使用 for循环会比其他方式简单许多。
使用 Objective-C 1.0的 NSEnumerator 来遍历
NSEnumerator是个抽象基类,其中只定义了两个方法,供其具体子类(concrete subclass)来实现∶
- (NSArray*) allObjects
- (id) nextObject
其中关键的方法是 nextObject,它返回枚举里的下个对象。每次调用该方法时,其内部数据结构都会更新,使得下次调用方法时能返回下个对象。等到枚举中的全部对象都已返回之后,再调用就将返回 nil,这表示达到枚举末端了。
Foundation框架中内建的 collection类都实现了这种遍历方式。例如,想遍历数组,可以这样写代码∶
NSArray* anArray = /*...*/;
NSEnumerator *enumerator = [anArray objectEnumerator];
id object;
while((object = [enumerator nextObject])!= nil){
// Do something with'object'5
}
这种写法的功能与标准的 for循环相似,但是代码却多了一些。其真正优势在于∶不论遍历哪种 collection,都可以采用这套相似的语法。比方说,遍历字典及 set 时也可以按照这种写法来做∶
// Dictionary
NSDictionary *aDictionary = /*...*/;
NSEnumerator *enumerator = [aDictionary keyEnumerator];
id key;
while((key =[enumerator nextObject])!= nil){
id value = aDictionary [ key];
// Do something with'key' and 'value'!
}
//Set
NSSet *aSet = /*...*/;
NSEnumerator *enumerator = [aSet objectEnumerator];
id object;
while((object =[enumerator nextObject])!= nil) {
// Do something with'object'!
}
遍历字典的方式与数组和 set 略有不同,因为字典里既有键也有值,所以要根据给定的键把对应的值提取出来。使用NSEnumerator 还有个好处,就是有多种"枚举器"(enumerator))可供使用。比方说,有反向遍历数组所用的枚举器,如果拿它来遍历,就可以按反方向来迭代 collection中的元素了。例如∶
NSArray *anArray = /*...*/;
NSEnumerator *enumerator = [anArray reverseObjectEnumerator];
id object;
while ((object = [enumerator nextObject])!= nil) {
// Do something with 'object'
}
与采用 for循环的等效写法相比,上面这段代码读起来更顺畅。
快速遍历
Objective-C 2.0引入了快速遍历这一功能。快速遍历与使用NSEnumerator来遍历差不多,然而语法更简洁,它为 for循环开设了 in关键字。这个关键字大幅简化了遍历collection 所需的语法,比方说要遍历数组,就可以这么写∶
NSArray *anArray = /*...*/;
for(id object in anArray) {
// Do something with 'object'
}
这样写简单多了。如果某个类的对象支持快速遍历,那么就可以宣称自己遵从名为NSFastEnumeration 的协议,从而令开发者可以采用此语法来迭代该对象。此协议只定义了一个方法∶
-(NSUInteger)countByEnumeratingWithState:
(NSFastEnumerationState*)state
objects:(id*)stackbuffer
count:(NSUInteger)length
该方法的工作原理不在本条目所述范围内。不过网上能找到一些优秀的教程,它们会把这个问题解释得很清楚。其要点在于∶该方法允许类实例同时返回多个对象,这就使得循环遍历操作更为高效了。
遍历字典与 set也很简单∶
// ictionary
NSDictionary *aDictionary = /*...*/;
for (id key in aDictionary) {
id value = aDictionary[key];
// Do something with 'key' and 'value'
}
// Set
NSSet *aSet = /*...*/;
for (id object in aSet) {
// Do something with 'object'
}
由于NSEnumerator 对象也实现了NSFastEnumeration 协议,所以能用来执行反向遍历。若要反向遍历数组,可采用下面这种写法∶
NSArray *anArray = /*...*/;
for (id object in [anArray reverseObjectEnumerator]) {
// Do something with'object'
}
在目前所介绍的遍历方式中,这种办法是语法最简单且效率最高的,然而如果在遍历字典时需要同时获取键与值,那么会多出来一步。而且,与传统的 for循环不同,这种遍历方式无法轻松获取当前遍历操作所针对的下标。遍历时通常会用到这个下标,比如很多算法都需要它。
基于块的遍历方式
在当前的 Objective-C语言中,最新引入的一种做法就是基于块来遍历。NSArray中定义了下面这个方法,它可以实现最基本的遍历功能∶
-(void)enumerateObjectsUsingBlock:
(void (^)(id object,NSUInteger idx,BOOL *stop))block
除此之外,还有一系列类似的遍历方法。它们可以接受各种选项.以控制遍历操作。稍后将会讨论那些方法。
在遍历数组及set 时,每次迭代都要执行由 block参数所传入的块,这个块有三个参数,分别是当前迭代所针对的对象、所针对的下标,以及指向布尔值的指针。前两个参数的含义不言而喻。而通过第三个参数所提供的机制,开发者可以终止遍历操作。
例如,下面这段代码用此方法来遍历数组∶
NSArray*anArray =/*...*/;
[anArray enumerateObjectsUsingBlock:
^(id object,NSUInteger idx,BOOL *stop){
// Do something with 'object'
if (shouldStop){
*stop = YES;
}
}];
这种写法稍微多了几行代码,不过依然明晰,而且遍历时既能获取对象,也能知道其下标。此方法还提供了一种优雅的机制,用于终止遍历操作,开发者可以通过设定 stop变量值来实现,当然,使用其他几种遍历方式时,也可以通过break 来终止循环,那样做也很好。
此方式不仅可用来遍历数组。NSSet 里面也有同样的块枚举方法,NSDictionary 也是这样,只是略有不同∶
-(void) enumerateKeysAndObjectsUsingBlock:
(void(^)(id key, id object, BOOL *stop))block
因此,遍历字典与 set也同样简单∶// Dictionary
NSDictionary* aDictionary = /* ...*/;
[aDictionary enumerateKeysAndObjectsUsingBlock:
^(id key,id object,BOOL*stop) {
// Do something with'key'and 'object'
if (shouldStop) {
*stop = YES;
}
// Set
NSSet *aSet = /* ... */;
[aSet enumerateObjectsUsingBlock:
^(id object, BOOL *stop) {
//Do something with 'object'
if (shouldStop) {
*stop = YES;
}
}];
此方式大大胜过其他方式的地方在于:遍历时可以直接从块里获取更多信息。在遍历数组时,可以知道当前所针对的下标。遍历有序 set(NSOrderedSet)时也一样。而在遍历字典时,无须额外编码,即可同时获取键与值。因而省去了根据给定键来获取对应值这一步。用这种方式遍历字典。可以同时得知键与值。这很可能比其他方式快很多。因为在字典内部的数据结构中,键与值本来就是存储在一起的。
另外一个好处是,能够修改块的方法签名。以免进行类型转换操作,从效果上讲,相当于把本来需要执行的类型转换操作交给块方法签名来做。比方说,要用"快速遍历法"来遍历字典。若已知字典中的对象必为字符串,则可以这样编码;
for (NSString *key in aDictionary) {
NSString *object =(NSString*)aDictionary[key];
// Do something with 'key' and 'object'
}
如果改用基于块的方式来遍历,那么就可以在块方法签名中直接转换∶
NSDictionary *aDictionary = /* ...*/;
[aDictionary enumerateKeysAndObjectsUsingBlock:
^(NSString *key,NSString *obj,BOOL *stop) {
// Do something with'key' and 'obj'
}];
之所以能如此,是因为 id类型相当特殊,它可以像本例这样,为其他类型所覆写。要是原来的块签名把键与值都定义成NSObject*,那这么写就不行了。此技巧初看不甚显眼,实则相当有用。指定对象的精确类型之后,编译器就可以检测出开发者是否调用了该对象所不具备的方法,并在发现这种问题时报错。如果能够确知某 collection 里的对象是什么类型,那就应该使用这种方法指明其类型。
用此方式也可以执行反向遍历。数组、字典、set都实现了前述方法的另一个版本,使开发者可向其传入"选项掩码"(option mask)∶
- (void)enumerateObjectsWithOptions:
(NSEnumerationOptions) options
usingBloCk:
(void(^)(id obj,NSUInteger idx,BOOL*stop))block
-(void)enumerateKeysAndObjectsWithOptions:
(NSEnumerationOptions) options
usingBlock:
(void(^)(id key,id obj,BOOL *stop))block
NSEnumerationOptions类型是个enum,其各种取值可用"按位或"(bitwise OR)连接,用以表明遍历方式。例如,开发者可以请求以并发方式执行各轮迭代,也就是说,如果当前系统资源状况允许,那么执行每次迭代所用的块就可以并行执行了。通过NSEnumerationConcurrent 选项即可开启此功能。如果使用此选项,那么底层会通过GCD来处理并发执行事宜,具体实现时很可能会用到 dispatch group(参见第 44条)。不过,到底如何来实现,不是本条所要讨论的内容。反向遍历是通过NSEnumerationReverse 选项来实现的。要注意;只有在遍历数组或有序 set 等有顺序的collection 时,这么做才有意义。
总体来看,块枚举法拥有其他遍历方式都具备的优势,而且还能带来更多好处。与快速遍历法相比,它要多用一些代码,可是却能提供遍历时所针对的下标,在遍历字典时也能同时提供链键与值,而目还有选项可以开启并发迭代功能,所以多写这点代码还是值得的。
要点
■ 遍历 collection有四种方式。最基本的办法是 for循环,其次是 NSEnumerator遍历法及快速遍历法,最新、最先进的方式则是"块枚举法"。
■"块枚举法"本身就能通过GCD来并发执行遍历操作,无须另行编写代码。而采用其他遍历方式则无法轻易实现这一点。
■ 若提前知道待遍历的 collection 含有何种对象,则应修改块签名,指出对象的具体类型。
二、对自定义其内存管理语义的 collection 使用无缝桥接
Objective-C的系统库包含相当多的 collection类,其中有各种数组、各种字典、各种set。Foundation框架定义了这些 collection 及其他各种 collection 所对应的 Objective-C类。与之相似,CoreFoundation框架也定义了一套C语言 API,用于操作表示这些 collection 及其他各种 collection 的数据结构。例如,NSArray 是 Foundation框架中表示数组的 Objective-C类,而 CFArray 则是CoreFoundation框架中的等价物。这两种创建数组的方式也许有区别,然而有项强大的功能可在这两个类型之间平滑转换,它就是"无缝桥接"(toll-freebridging)。
使用"无缝桥接"技术,可以在定义于 Foundation框架中的Obiective-C类和定义于CoreFoundation框架中的 C数据结构之间互相转换。笔者将C语言级别的 API称为数据结构,而没有称其为类或对象,这是因为它们与 Obiective-C 中的类或对象并不相同。例如. CFArray 要通过 CFArrayRef来引用,而这是指向 struct CFArray 的指针。CFArrayGetCount 这种函数则可以操作此 struct,以获取数组大小。这和 Objective-C中的对应物不同,在Objective-C中,可以创建 NSArray 对象,并在该对象上调用 count 方法,以获取数组大小。
下列代码演示了简单的无缝桥接∶
NSArray *anNSArray = @[@1, @2, @3, @4, @5];
CFArrayRef aCFArray=(__bridge CFArrayRef)anNSArray;
NSLog(@"Size of array = %li",CFArrayGetCount(aCFArray));
// Output: Size of array = 5
转换操作中的 bridge 告诉 ARC(参见第30条)如何处理转换所涉及的 Objective-C 对象。 bridge 本身的意思是∶ARC仍然具备这个 Objective-C 对象的所有权。而_bridge_retained则与之相反,意味着 ARC将交出对象的所有权。若是前面那段代码改用它来实现,那么用完数组之后就要加上 CFRelease(aCFArray)以释放其内存。与之相似.反向转换可通过 bridge transfer来实现。比方说,想把CFArrayRef转换为NSArray*,并且想令 ARC 获得对象所有权,那么就可以采用此种转换方式。这三种转换方式称为"桥式转换"(bridged Cast)。
可是,你也许会问∶以纯 Objective-C来编写应用程序时,为何要用到这种功能呢? 这是因为;Foundation 框架中的 Objective-C类所具备的某些功能,是 CoreFoundation框架中的C语言数据结构所不具备的,反之亦然。在使用 Foundation框架中的字典对象时会遇到一个大问题,那就是其键的内存管理语义为"拷贝",而值的语义却是"保留"。除非使用强大的无缝桥接技术,否则无法改变其语义。
CoreFoundation框架中的字典类型叫做 CFDictionary。其可变版本称为CFMutable Dictionary。创建 CFMutableDictionary 时,可以通过下列方法来指定键和值的内存管理语义;
CFMutableDictionaryRef CFDictionaryCreateMutable {
CFAllocatorRef allocator,
CFIndex capacity,
const CFDictionaryKeyCallBacks *keyCallBacks,
const CFDictionaryValueCallBacks *valueCallBacks
}
首个参数表示将要使用的内存分配器(allocator)e。如果你大部分时间都在编写Objective-C代码,那么也许会对 CoreFoundation 框架中的这部分稍感陌生。CoreFoundation 对象里的数据结构需要占用内存,而分配器负责分配及回收这些内存。开发者通常为这个参数传入NULL,表示采用默认的分配器。
第二个参数定义了字典的初始大小。它并不会限制字典的最大容量,只是向分配器提示了一开始应该分配多少内存。假如要创建的字典含有10 个对象,那就向该参数传入 10。
最后两个参数值得注意。它们定义了许多回调函数,用于指示字典中的键和值在遇到各种事件时应该执行何种操作。这两个参数都是指向结构体的指针,二者所对应的结构体如下;
struct CFDictionaryKeyCallBacks {
CFIndex version;
CFDictionaryRetainCallBack retain;
CFDictionaryReleaseCallBack release;
CFDictionaryCopyDescriptionCallBack copyDescription;
CFDictionaryEqualCallBack equal;
CFDictionaryHashCallBack hash;
};
struct CFDictionaryValueCallBacks {
CFIndex version;
CFDictionaryRetainCallBack retain;
CFDictionaryReleaseCallBack release;
CFDictionaryCopyDescriptionCallBack copyDescription;
CFDictionaryEqualCallBack equal;
}
version参数目前应设为0。当前编程时总是取这个值,不过将来苹果公司也许会修改此结构体,所以要预留该值以表示版本号。这个参数可以用于检测新版与旧版数据结构之间是否兼容。结构体中的其余成员都是函数指针,它们定义了当各种事件发生时应该采用哪个函数来执行相关任务。比方说,如果字典中加入了新的键与值,那么就会调用retain 函数。此参数的类型定义如下∶
typedef const void* (*CFDictionaryRetainCallBack) (
CFAllocatorRef allocator,
const void *value
}
由此可见,retain是个函数指针,其所指向的函数接受两个参数,其类型分别是CFAllocatorRef与const void*。传给此函数的 value 参数表示即将加入字典中的键或值。而返回的 void* 则表示要加到字典里的最终值。开发者可以用下列代码来实现这个回调函数;
const void* CustomCallback (CFAllocatorRef allocator,
const void *value) {
return value;
}
这么写只是把即将加入字典中的值照原样返回。于是,如果用它充当retain 回调函数来创建字典,那么该字典就不会"保留"键与值了。将此种写法与无缝桥接搭配起来,就可以创建出特殊的 NSDictionary 对象,而其行为与用Objective-C创建出来的普通字典不同。
下列范例代码完整演示了这种字典的创建步骤∶
串
#import <Foundation/Foundation.h>
#import <CoreFoundation/CoreFoundation.h>
const void* EOCRetainCallback(CFAllocatorRef allocator,
const void *value) {
return CFRetain (value);
}
void EOCReleaseCallback(CFAllocatorRef allocator,
const void *value) {
CFRelease (value);
}
CFDictionaryKeyCallBacks keyCallbacks = {
0,
EOCRetainCallback,
EOCReleaseCallback,
NULL,
CFEqual,
CFHash
};
CFDictionaryValueCallBacks valueCallbacks = {
0,
EOCRetainCallback,
EOCReleaseCallback,
NULL,
CFEqual
};
CFMutableDictionaryRef aCFDictionary =
CFDictionaryCreateMutable (NULL, 0, &keyCallbacks, &valueCallbacks);
NSMutableDictionary *anNSDictionary = (_bridge_transfer NSMutableDictionary*)aCFDictionary;
在设定回调 函数时,copyDescription取值为NULL,因为采用默认实现就很好。而 equal与hash 回调函数分别设为 CFEqual与CFHash,因为这二者所采用的做法与NSMutableDictionary 的默认实现相同。CFEqual最终会调用NSObject 的"isEqual∶"方法,而CFHash则会调用 hash 方法。由此可以看出无缝桥接技术更为强大的一面。
键与值所对应的 retain与 release 回调函数指针分别指向 EOCRetainCallback与 EOCRelease Callback 函数。为什么要这么做呢?回想一下,前面说过,在向NSMutableDictionary 中加入键和值时,字典会自动"拷贝"键并"保留"值。如果用作键的对象不支持拷贝操作,那会如何呢?此时就不能使用普通的 NSMutableDictionary 了,假如用了,会导致下面这种运行期错误∶
*** Terminating app due to uncaught exception 'NSInvalidArgumentException',reason:'-[EOCClass copyWithZone:]: unrecognized selector sent to instance 0x7fd069c080b0
该错误表明,对象所属的类不支持 NSCopying 协议,因为"copyWithZone;“方法未实现。开发者可以直接在 CoreFoundation 层创建字典,于是就能修改内存管理语义,对键执行"保留"而非"拷贝"操作了。
通过类似手段,也可创建出不保留其元素对象的数组或 set。这么做或许有用,因为有时如果令数组保留对象的话,那么可能会引入"保留环”。不过要注意,这个问题可以改用更好的办法来解决。不保留其元素对象的那种数组,很容易出错。要是数组中的某个对象已为系统所回收,而应用程序又去访问该对象的话,那很可能就崩溃了。
要点
■通过无缝桥接技术,可以在 Foundation框架中的 Objective-C对象与CoreFoundation框架中的C语言数据结构之间来回转换。
■在 CoreFoundation 层面创建collection时,可以指定许多回调函数,这些函数表示此collection 应如何处理其元素。然后,可运用无缝桥接技术,将其转换成具备特殊内存管理语义的Objective-C collection。
二、构建缓存时选用 NSCache 而非 NSDictionary
开发 Mac OS X或iOS 应用程序时,经常会遇到一个问题,那就是从因特网下载的图片应如何来缓存。首先能想到的好办法就是把内存中的图片保存到字典里,这样的话,稍后使用时就无须再次下载了。有些程序员会不假思索,直接使用NSDictionary 来做(准确来说,是使用其可变版本),因为这个类很常用。其实,NSCache 类更好,它是 Foundation框架专为处理这种任务而设计的。
NSCache 胜过NSDictionary 之处在于,当系统资源将要耗尽时,它可以自动删减缓存。如果采用普通的字典,那么就要自己编写挂钩,在系统发出"低内存"(low memory)通知时手工删减缓存。而NSCache 则会自动删减,由于其是 Foundation框架的一部分,所以与开发者相比,它能在更深的层面上插入挂钩。此外,NSCache 还会先行删减"最久未使用的"(lease recently used)对象。若想自己编写代码来为字典添加此功能,则会十分复杂。
NSCache 并不会"拷贝"键,而是会"保留"它。此行为用NSDictionary 也可以实现,然而需要编写相当复杂的代码(参见第 49 条)。NSCache 对象不拷贝键的原因在于∶很多时候,键都是由不支持拷贝操作的对象来充当的。因此,NSCache 不会自动拷贝键,所以说,在键不支持拷贝操作的情况下,该类用起来比字典更方便。另外,NSCache 是线程安全的。而 NSDictionary 则绝对不具备此优势,意思就是∶在开发者自己不编写加锁代码的前提下,多个线程便可以同时访问 NSCache。对缓存来说。线程安全通常很重要,因为开发者可能要在某个线程中读取数据,此时如果发现缓存里找不到指定的键,那么就要下载该键所对应的数据了。而下载完数据之后所要执行的回调函数,有可能会放在背景线程中运行,这样的话,就等于是用另外一个线程来写入缓存了。
开发者可以操控缓存删减其内容的时机。有两个与系统资源相关的尺度可供调整,其一是缓存中的对象总数,其二是所有对象的"总开销"(overall cost)。开发者在将对象加入缓存时,可为其指定"开销值"。当对象总数或总开销超过上限时,缓存就可能会删减其中的对象了,在可用的系统资源趋于紧张时,也会这么做。然而要注意,"可能"会删减某个对象,并不意味着"一定"会删减这个对象。删减对象时所遵照的顺序,由具体实现来定。这尤其说明∶想通过调整"开销值"来迫使缓存优先删减某对象,不是个好主意。
向缓存中添加对象时,只有在能很快计算出"开销值"的情况下,才应该考虑采用这个尺度。若计算过程很复杂,那么照这种方式来使用缓存就达不到最佳效果了,因为每次向缓存中放入对象时,还要专门花时间来计算这个附加因素的值。而缓存的本意则是要增加应用程序响应用户操作的速度。比方说,如果计算"开销值"时必须访问磁盘才能确定文件大小,或是必须访问数据库才能决定具体取值,那就不太好了。然而,如果要加入缓存中的是NSData 对象,那么就不妨指定"开销值"了,可以把数据大小当作"开销值"来用。因为NSData 对象的数据大小是已知的,所以计算"开销值"的过程只不过是读取一项属性。
下面这段代码演示了缓存的用法∶
#import <Foundation/Foundation.h>
// Network fetcher class
typedef void(^EOCNetworkFetcherCompletionHandler)(NSData *data);
@interface EOCNetworkFetcher :NSObject
-(id)initWithURL:(NSURL*)url;
-(void)startWithCompletionHandler : (EOCNetworkFetcherCompletionHandler)handler;
@end
// Class that uses the network fetcher and caches results
@interface EOCClass : NSObject
@end
@implementation EOCClass {
NSCache *_cache;
}
- (id) init (
if ((self = [super init])){
_cache = [NSCache new];
// Cache a maximum of 100 URLs __cache.countLimit = 100;
/*★
* The size in bytes of data is used as the cost, * so this sets a cost limit of 5MB. */
_cache.totalCostLimit =5 * 1024* 1024;
}
return self;
- (void) downloadDataForURL:(NSURL*)url {
NSData *cachedData=[ cache objectForKey:url];
if (cachedData) {
// Cache hit
[self useData:cachedData];
} else {
// Cache miss
EOCNetworkFetcher*fetcher =
[[EOCNetworkFetcher alloc] initWithURL:url];
[fetcher startWithCompletionHandler:^(NSData *data){[_cache setObject:data forKey:url cost:data.length];[self useData:data];
}];
}
}
@end
在本例中,下载数据所用的 URL,就是缓存的键。若缓存未命中(cache miss)9,则下载数据并将其放入缓存。而数据的"开销值"则设为其长度。创建NSCache 时,将其中可缓存的总对象数目上限设为100,将"总开销’上限设为5MB,不过,由于’开销值"以"字节"为单位,所以要通过算式将 MB 换算成字节。
还有个类叫做NSPurgeableData,和 NSCache 搭配起来用,效果很好,此类是NSMut-ableData 的子类,而且实现了NSDiscardableContent 协议。如果某个对象所占的内存能够根据需要随时丢弃,那么就可以实现该协议所定义的接口。这就是说,当系统资源紧张时,可以把保存 NSPurgeableData 对象的那块内存释放掉。NSDiscardableContent 协议里定义了名为isContentDiscarded 的方法,可用来查询相关内存是否已释放。
如果需要访问某个NSPurgeableData 对象,可以调用其 beginContentAccess方法,告诉它现在还不应丢弃自己所占据的内存。用完之后,调用endContentAccess 方法,告诉它在必要时可以丢弃自己所占据的内存了。这些调用可以嵌套,所以说,它们就像递增与递减引用计数所用的方法那样。只有对象的"引用计数"为0时才可以丢弃。
如果将 NSPurgeableData 对象加入 NSCache,那么当该对象为系统所丢弃时,也会自动从缓存中移除。通过NSCache 的evictsObjectsWithDiscardedContent 属性,可以开启或关闭此功能。
刚才那个例子可用NSPurgeableData 改写如下∶
-(void) downloadDataForURL:(NSURL*)url {
NSPurgeableData *cachedData = [ cache objectForKey:url];
if (cachedData) {
// Stop the data being purged
[cacheData beginContentAccess];
// Use the cached data
[self useData:cachedData];
//Mark that the data may be purged again
[cacheData endContentAccess];
} else {
// Cache miss
EOCNetworkFetcher *fetcher = [[EOCNetworkFetcher alloc] initWithURL:url];
[fetcher startWithCompletionHandler:^(NSData *data){
NSPurgeableData *purgeableData =
[NSPurgeableData dataWithData∶data];
[_cache setObject:purgeableData forKey:url
cost:purgeableData.length];
// Don't need to beginContentAccess as it begins // with access already marked
// Use the retrieved data
[self useData:data];
// Mark that the data may be purged now
[purgeableData endContentAccess];
}];
}
}
注意,创建好 NSPurgeableData 对象之后,其"purge引用计数"会多1,所以无须再调用beginContentAccess了,然而其后必须调用endContentAccess,将多出来的这个"1"抵消掉。
要点
■ 实现缓存时应选用 NSCache 而非 NSDictionary 对象。因为 NSCache 可以提供优雅的自动删减功能,而且是"线程安全的",此外,它与字典不同,并不会拷贝键。
■ 可以给 NSCache 对象设置上限,用以限制缓存中的对象总个数及"总成本",而这些尺度则定义了缓存删减其中对象的时机。但是绝对不要把这些尺度当成可靠的"硬限制"(hard limit),它们仅对NSCache 起指导作用。
■ 将 NSPurgeableData与 NSCache 搭配使用,可实现自动清除数据的功能,也就是说,当NSPurgeableData 对象所占内存为系统所丢弃时,该对象自身也会从缓存中移除。
■ 如果缓存使用得当,那么应用程序的响应速度就能提高。 只有那种"重新计算起来很费事的"数据,才值得放入缓存,比如那些需要从网络获取或从磁盘读取的数据。
三、精简 initialize 与load 的实现代码
有时候,类必须先执行某些初始化操作,然后才能正常使用。在Objective-C中,绝大多数类都继承自 NSObject 这个根类,而该类有两个方法,可用来实现这种初始化操作。
首先要讲的是load方法,其原型如下∶
+ (void) load
对于加入运行期系统中的每个类(class)及分类(category)来说,必定会调用此方法,而且仅调用一次。当包含类或分类的程序库载入系统时,就会执行此方法,而这通常就是指应用程序启动的时候,若程序是为 iOS平台设计的,则肯定会在此时执行。Mac OS X应用程序更自由一些,它们可以使用"动态加载"(dynamic loading)之类的特性,等应用程序启动好之后再去加载程序库。如果分类和其所属的类都定义了load 方法,则先调用类里的。再调用分类里的。
load方法的问题在于,执行该方法时,运行期系统处于"脆弱状态"(fragile state)。在执行子类的load方法之前,必定会先执行所有超类的load方法,而如果代码还依赖了其他程序库,那么程序库里相关类的load方法也必定会先执行。然而,根据某个给定的程序库,却无法判断出其中各个类的载入顺序。因此,在 load方法中使用其他类是不安全的。比方说,有下面这段代码∶
#import <Foundation/Foundation.h>
#import "EOCClassA.h"//< From the same library
@interface EOCClasSB :NSObject
@end
@implementation EOCClassB
+ (void) load {
NSLog (@"Loading EOCClassB");
EOCClassA *object =[EOCClassAnew];
// Use 'object'
}
@end
此处使用NSLog没问题,而且相关字符串也会照常记录,因为 Foundation框架肯定在运行load方法之前就已经载入系统了。但是,在 EOCClassB的load方法里使用 EOCClassA 却不太安全,因为无法确定在执行 EOCClassB的load方法之前,EOCClassA是不是已经加载好了。可以想见∶EOCClassA这个类,也许会在其 load方法中执行某些重要操作,只有执行完这些操作之后,该类实例才能正常使用。
有个重要的事情需注意,那就是 load方法并不像普通的方法那样,它并不遵从那套继承规则。如果某个类本身没实现load方法,那么不管其各级超类是否实现此方法,系统都不会调用。此外,分类和其所属的类里,都可能出现load方法。此时两种实现代码都会调用,类的实现要比分类的实现先执行。
而且load方法务必实现得精简一些,也就是要尽量减少其所执行的操作,因为整个应用程序在执行load方法时都会阻塞。如果 load方法中包含繁杂的代码,那么应用程序在执行期间就会变得无响应。不要在里面等待锁,也不要调用可能会加锁的方法。总之,,能不做的事情就别做。实际上,凡是想通过load在类加载之前执行某些任务的,基本都做得不太对。其真正用途仅在于调试程序,比如可以在分类里编写此方法,用来判断该分类是否已经正确
载入系统中。也许此方法一度很有用处,但现在完全可以说∶时下编写 Objective-C代码时,不需要用它。
想执行与类相关的初始化操作,还有个办法,就是覆写下列方法:
+(void)initialize
对于每个类来说,该方法会在程序首次用该类之前调用,且只调用一次。它是由运行期系统来调用的,绝不应该通过代码直接调用。其虽与load相似,但却有几个非常重要的微妙区别。首先,它是"惰性调用的",也就是说,只有当程序用到了相关的类时,才会调用。因此,如果某个类一直都没有使用,那么其initialize 方法就一直不会运行。这也就等于说,应用程序无须先把每个类的 initialize 都执行一遍,这与load方法不同,对于load来说,应用程序必须阻塞并等着所有类的 load都执行完,才能继续。
此方法与load还有个区别,就是运行期系统在执行该方法时,是处于正常状态的,因此,从运行期系统完整度上来讲,此时可以安全使用并调用任意类中的任意方法。而且,运行期系统也能确保 initialize 方法一定会在"线程安全的环境"(thread-safe environment)中执行,这就是说,只有执行initialize 的那个线程可以操作类或类实例。其他线程都要先阻塞,等着initialize 执行完。
最后一个区别是∶initialize 方法与其他消息一样,如果某个类未实现它,而其超类实现了,那么就会运行超类的实现代码。这听起来并不稀奇。但却经常为开发者所忽视。比方说有下面这两个类∶
#import <Foundation/Foundation.h>
@interface EOCBaseClass : NSObject
@end
@implementation EOCBaseClass
+(void)initialize {
NSLog(@"%@ initialize", self);
}
@end
@interface EOCSubClass : EOCBaseClass
@end
@implementation EOCSubClass
@end
即便 EOCSubClass类没有实现 initialize方法,它也会收到这条消息。由各级超类所实现的 initialize 也会先行调用。所以,首次使用EOCSubClass 时,控制台会输出如下消息;
EOCBaseClass initialize
EOCSubClass initialize
你可能认为输出的内容有些奇怪,不过这完全符合规则。与其他方法(除去 load)一样,initialize 也遵循通常的继承规则,所以,当初始化基类 EOCBaseClass 时,EOCBaseClass 中定义的 initialize方法要运行一遍,而当初始化子类 EOCSubClass 时,由于该类并未覆写此方法,因而还要把父类的实现代码再运行一遍。鉴于此,通常都会这么来实现 initialize 方法:
+(void)initialize {
if(self == [EOCBaseClassclass]){
NSLog (@"%@ initialized",self);
}
}
加上这条检测语句之后,只有当开发者所期望的那个类载入系统时,才会执行相关的初始化操作。如果把刚才的例子照此改写,那就不会打印出两条记录信息了,这次只输出一条∶
EOCBaseClass initialize
看过load与initialize方法的这些特性之后,又回到了早前提过的那个主要问题上,也就是这两个方法的实现代码要尽量精简。在里面设置一些状态,使本类能够正常运作就可以了,不要执行那种耗时太久或需要加锁的任务。对于load方法来说,其原因已在前面解释过了,而initialize 方法要保持精简的原因,也与之相似。首先,大家都不想看到应用程序"挂起"(hang)。对于某个类来说,任何线程都可能成为初次用到它的那个线程,并导致其初始化。如果这个线程碰巧是 UI线程,那么初始化期间就会一直阻塞,导致应用程序无响应。有时很难预测到底哪个线程会先用到这个类,强令某线程去初始化该类,显然不是好办法。
其二,开发者无法控制类的初始化时机。类在首次使用之前,肯定要初始化,但编写程序时不能令代码依赖特定的时间点,否则会很危险。运行期系统将来更新了之后,可能会略微改变类的初始化方式,这样的话,开发者原来如果假设某个类必定会在某个具体时间点初始化,那么现在这条假设可能就不成立了。
最后一个原因是,如果某个类的实现代码很复杂,那么其中可能会直接或间接用到其他类。若那些类尚未初始化,则系统会迫使其初始化。然而,本类的初始化方法此时尚未运行完毕。其他类在运行其initialize 方法时,有可能会依赖本类中的某些数据,而这些数据此时也许还未初始化好。例如∶
import <Foundation/Foundation.h>
static id EOCClassAInternalData;
@interface EOCClassA : NSObject
@end
staticid EOCClassBInternalData;
@interface EOCClassB :NSObject
@end
@implementation EOCClassA
+(void)initialize {
if(self == [EOCClassAclass]){
[EOCClassBdoSomethingThatUsesItsInternalData];
EOCClassAInternalData =(self setupInternalData];
}
}
@end
@implementation EOCClassB
+(void) initialize {
if (self == [EOCClassBclass]) {
[EOCClassAdoSomethingThatUsesItsInternalData];
EOCClassBInternalData = [self setupInternalData];
}
}
@end
若是 EOCClassA先初始化,那么 EOCClassB 随后也会初始化,它会在自己的初始化方法中调用 EOCClassA 的 doSomethingThatUsesItsInternalData,而此时 EOCClassA 内部的数据还没准备好。在实际编码工作中,问题不可能像此处说的那样明显,而且牵涉的类可能也不止两个。因此,当代码无法正常运行时,想要找出错误就更难了。
所以说,initialize 方法只应该用来设置内部数据。不应该在其中调用其他方法,即便是本类自己的方法,也最好别调用。因为稍后可能还要给那些方法里添加更多功能,如果在初始化过程中调用它们.那么还是有可能导致刚才说的那个问题。若某个全局状态无法在编译期初始化,则可以放在 initialize 里来做。下列代码演示了这种用法∶
// EOCClass.h
#import <Foundation/Foundation.h>
@interface EOCClass :NSObject
@end
// EOCClass.m
#import"EOCClass.h"
static const int kInterval = 10;
static NSMutableArray *kSomeObjects;
@implementation EOCClass
+(void)initialize {
if(self-= [EOCClassclass]){
kSomeObjects = [NSMutableArray new];
}
}
@end
整数可以在编译期定义,然而可变数组不行,因为它是个 Objective-C 对象,所以创建实例之前必须先激活运行期系统。注意,某些 Objective-C对象也可以在编译期创建,例如NSString 实例。然而,创建下面这种对象会令编译器报错∶
static NSMutableArray *kSomeObjects = [NSMutableArray new];
编写load 或 initialize 方法时,一定要留心这些注意事项。把代码实现得简单一些,能节省很多调试时间。除了初始化全局状态之外,如果还有其他事情要做,那么可以专门创建一个方法来执行这些操作,并要求该类的使用者必须在使用本类之前调用此方法。比如说,如果"单例类"(singleton class)在首次使用之前必须执行一些操作,那就可以采用这个办法。
要点
■在加载阶段,如果类实现了load方法,那么系统就会调用它。分类里也可以定义此方法,类的load方法要比分类中的先调用。与其他方法不同,load方法不参与覆写机制。
■ 首次使用某个类之前,系统会向其发送 initialize 消息。由于此方法遵从普通的覆写规则,所以通常应该在里面判断当前要初始化的是哪个类。
■load与 initialize 方法都应该实现得精简一些,这有助于保持应用程序的响应能力,也能减少引入"依赖环"(interdependency cycle)5 的几率。
■无法在编译期设定的全局常量,可以放在 initialize 方法里初始化。
四、别忘了NSTimer会保留其目标对象
计时器是一种很方便也很有用的对象。Foundation框架中有个类叫做 NSTimer,开发者可以指定绝对的日期与时间,以便到时执行任务,也可以指定执行任务的相对延迟时间。计时器还可以重复运行任务,有个与之相关联的"间隔值"(interval)可用来指定任务的触发频率。比方说,可以每5秒轮询某个资源。
计时器要和"运行循环"(run loop)相关联,运行循环到时候会触发任务。创建 NSTimer 时,可以将其"预先安排"在当前的运行循环中,也可以先创建好,然后由开发者自己来调度。无论采用哪种方式,只有把计时器放在运行循环里,它才能正常触发任务。例如,下面这个方法可以创建计时器,并将其预先安排在当前运行循环中∶
+(NSTimer *)scheduledTimerWithTimeInterval:
(NSTimeInterval) seconds
target:(id) target
selector:(SEL) selector
userInfo:(id)userInfo
repeats:(BOOL) repeats
用此方法创建出来的计时器,会在指定的间隔时间之后执行任务。也可以令其反复执行任务,直到开发者稍后将其手动关闭为止。target与selector参数表示计时器将在哪个对象上调用哪个方法。计时器会保留其目标对象,等到自身"失效"时再释放此对象。调用invalidate 方法可令计时器失效;执行完相关任务之后,一次性的计时器也会失效。开发者若将计时器设置成重复执行模式,那么必须自己调用invalidate方法,才能令其停止。
由于计时器会保留其目标对象,所以反复执行任务通常会导致应用程序出问题。也就是说,设置成重复执行模式的那种计时器,很容易引入"保留环"。要想知道其中缘由,请看下列代码:
#import <Foundation/Foundation.h>
@interface EOCClass :NSObject
-(void)startPolling;
-(void)stopPolling;
@end
@implementation EOCClass {
NSTimer *_pollTimer;
- (id) init {
return [super init];
}
- (void) dealloc {
[_pollTimer invalidate];
}
-(void)stopPolling[
[_pollTimer invalidate];
_pollTimer = ni1;
}
-(void) startPolling {
pollTimer = [NSTimerscheduledTimerWithTimeInterval:5.0
target:self
selector:@selector (p_doPoll)
userInfo:nil
repeats:YES];
}
-(void) p_doPoll {
// Poll the resource
}
@end
能看出问题吗?如果创建了本类的实例,并调用其 startPolling方法,那会如何呢?创建计时器的时候,由于目标对象是 self,所以要保留此实例。然而,因为计时器是用实例变量存放的,所以实例也保留了计时器。(回想一下,第 30条说过,在 ARC环境中,这种情况将执行保留操作。)于是,就产生了"保留环",如果此环能在某一时刻打破,那就不会出什么问题。然而要想打破保留环,只能改变实例变量或令计时器无效。所以说,要么调用stopPolling,要么令系统将此实例回收,只有这样才能打破保留环。除非使用该类的所有代码均在你的掌控之中,否则无法确保 stopPolling一定会调用。而且即便能满足此条件,这种通过调用某方法来避免内存泄漏的做法,也不是个好主意。另外,如果想在系统回收本类实例的过程中令计时器无效,从而打破保留环,那又会陷入死结。因为在计时器对象尚且有效时,EOCClass 实例的保留计数绝不会降为0,因此系统也绝不会将其回收。而现在又没人来调用invalidate 方法,所以计时器将一直处于有效状态。图7-1演示了此情况。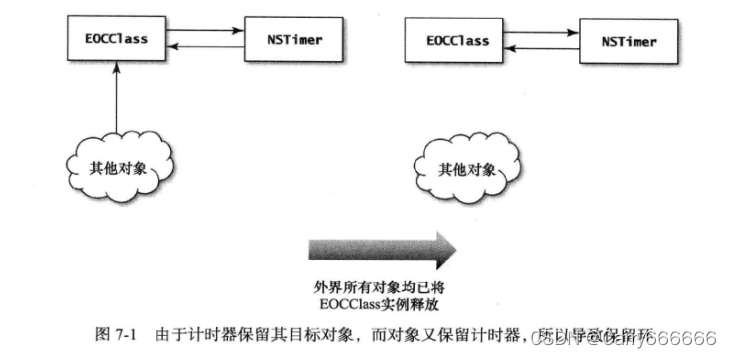
当指向 EOCClass 实例的最后一个外部引用移走之后,该实例仍然会继续存活,因为计时器还保留着它。而计时器对象也不可能为系统所释放,因为实例中还有个强引用正在指向它。更糟糕的是;除了计时器之外,已经没有别的引用再指向这个实例了,于是该实例就永远"丢失"了。而除了该实例之外,又没有其他引用指向计时器。于是,内存就泄漏了。这种内存泄漏问题才为严重。因为计时器还将继续反复地执行轮询任务。要是每次轮询时都得联网下载数据的话,那么程序就会一直下载数据,这又更容易导致其他内存泄漏问题。
单从计时器本身入手,很难解决这个问题。可以要求外界对象在释放最后一个指向本实例的引用之前,必须先调用 stopPolling 方法。然而这种情况无法通过代码检测出来,此外,假如该类随着某套公开的 API 对外发布给其他开发者,那么无法保证他们一定会调用此方法。
这个问题可通过"块"来解决。虽然计时器当前并不直接支持块,但是可以用下面这段代码为其添加此功能∶
import <Foundation/Foundation.h>
@interface NSTimer(EOCBlocksSupport)
+(NSTimer*)eoc_scheduledTimerWithTimeInterval : (NSTimeInterval)interval block:(void (^)())block repeats:(BOOL) repeats;
@end
@implementation NSTimer(EOCBlocksSupport)
+(NSTimer*)eoc scheduledTimerWithTimeInterval: (NSTimeInterval)interval block:(void(^)())block repeats:(BOOL) repeats
{
return [self scheduledTimerWithTimeInterval:interval
target:self
selector:@selector(eoc blockInvoke:)
userInfo:[block copy]repeats: repeats];
}
+(void)eoc_blockInvoke:(NSTimer*)timer {
void(^block)() = timer.userInfo;
if (block) {
block();
}
}
@end
这个办法为何能解决"保留环"问题呢?大家马上就会明白。这段代码将计时器所应执行的任务封装成"块",在调用计时器函数时,把它作为 userInfo参数传进去。该参数可用来存放"不透明值"(opaque value)=,只要计时器还有效,就会一直保留着它。传入参数时要通过 copy 方法将block拷贝到"堆"上(参见第 37条),否则等到稍后要执行它的时候,该块可能已经无效了。计时器现在的 target是NSTimer类对象,这是个单例,因此计时器是否会保留它,其实都无所谓。此处依然有保留环,然而因为类对象(class object)无须回收,所以不用担心。
这套方案本身并不能解决问题,但它提供了解决问题所需的工具。修改刚才那段有问题的范例代码,,使用新分类中的 eoc scheduledTimerWithTimeInterval方法来创建计时器∶
- (void) startPolling {
_pollTimer =
[NSTimereoc_scheduledTimerWithTimeInterval:5.0
block:"{
[self P_doPoll];
}
repeats:YES];
}
仔细看看代码,就会发现还是有保留环。因为块捕获了self变量,所以块要保留实例。而计时器又通过userlnfo参数保留了块。最后,实例本身还要保留计时器。不过,只要改用weak 引用(参见第 33条),即可打破保留环∶
-(void)startPolling {
_weak EOCClass *weakSelf = self;
_pol1Timer = [NSTimer eoc scheduledTimerWithTimeInterval:5.0
block:^{
EOCClass *strongSelf = weakSelf;
[strongSelf p_doPoll];
}
repeats:YES];
}
这段代码采用了一种很有效的写法,它先定义了一个弱引用,令其指向 self,然后使块捕获这个引用,而不直接去捕获普通的 self变量。也就是说,self不会为计时器所保留。 当块开始执行时,立刻生成 strong 引用,以保证实例在执行期间持续存活。
采用这种写法之后,如果外界指向 EOCClass 实例的最后一个引用将其释放,则该实例就可为系统所回收了。回收过程中还会调用计时器的 invalidate 方法(请读者参看原来那段范例代码),这样的话,计时器就不会再执行任务了。此处使用 weak 引用还能令程序更加安全,因为有时开发者可能在编写 dealloc 时忘了调用计时器的 invalidate 方法,从而导致计时器再次运行,若发生此类情况,则块里的 weakSelf会变成 nil。
要点
■ NSTimer对象会保留其目标,直到计时器本身失效为止,调用 invalidate 方法可令计时器失效,另外,一次性的计时器在触发完任务之后也会失效。
■ 反复执行任务的计时器(repeating timer),很容易引入保留环,如果这种计时器的目标对象又保留了计时器本身,那肯定会导致保留环。这种环状保留关系,可能是直接发生的,也可能是通过对象图里的其他对象间接发生的。
■ 可以扩充 NSTimer 的功能,用"块"来打破保留环。不过,除非NSTimer将来在公共接口里提供此功能,否则必须创建分类,将相关实现代码加入其中。