УшЪіЮЪЬт
ФуУЧЫљЫЕЕФЪ§ОнЕЙЙрЦфЪЕИљБОВЛЪЧвЛИіЮЪЬтЛђеп bug.
LiveData ЩшМЦОЭЪЧШчДЫ. НгЪмзюНќвЛИіаХКХ. ЖдгІСїЕФ Behavior ФЃЪН.
ЮвУЧгажЊУћЖШвЛЕуЕФСїЕФЪЕЯжга RxJava КЭ Kotlin ЕФ Flow. дкЫћУЧЕФЪЕЯжжа, ЗжБ№ЖдгІ BehaviorSubject КЭ StateFlow
ЫћУЧЕФЭМЪОШчЯТ, ФуУЧПЩвдПДЕН, дкВЛЭЌЕФЪБМфЕуЗЂЩњЖЉдФ, ФузмЪЧФмЪеЕНзюНќЕФвЛИіаХКХ. Г§ЗЧвЛПЊЪМОЭУЛЗЂЩфЙ§аХКХ. Жј LiveData е§ЪЧРрЫЦгкДЫжжФЃЪН. ЫљвдФуУЧЫЕЫќЕФЪ§ОнЕЙЙр, ЦфЪЕИљБОВЛЪЧЮЪЬт, ШЫМвЩшМЦБОЪЧШчДЫ.
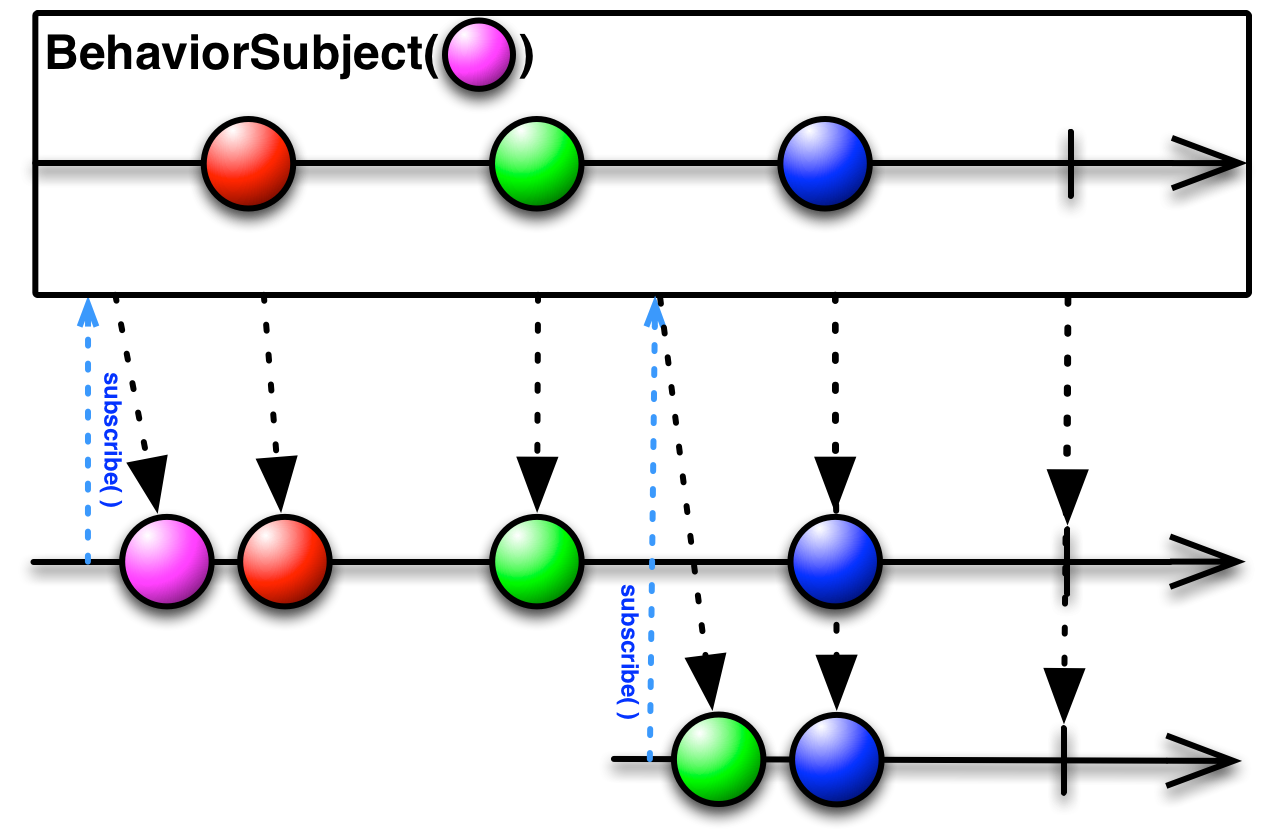
ФЧФуУЧЫЕЕФЪ§ОнЕЙЙрИљБОдвђЪЧвђЮЊЪВУДФи?
ЦфЪЕЪЧвђЮЊФуУЧМрЬ§СЫ Behavior ФЃЪНЕФСїЛђеп LiveData ШЅзіСЫЯргІЕФВйзї.
БШШчФуМрЬ§вЛИі LiveData ШЅзіСЫЭјТчЧыЧѓ
ЕБФуНчУцЕквЛДЮНјШы, LiveData жаВњЩњСЫвЛИіаХКХ, ФуЪеЕНжЎКѓзіСЫвЛДЮЧыЧѓ, КѓРДгЩгкЯЕЭГХфжУИќИФв§Ц№НчУцжиНЈ, ЕЋЪЧ ViewModel ЛЙЪЧдЯШФЧИі, ЫљвддкНчУцжиНЈКѓФуШЅМрЬ§ LiveData, ОЭЛсСЂТэЪеЕНвЛИіаХКХ, ЕМжТФугжзіСЫвЛДЮЧыЧѓ.
етРяЫЕУїЕФГЁОА, ЪЧгЩгкДэЮѓЪЙгУСЫ LiveData в§Ц№ЕФ. ШчЙћФувЊМрЬ§вЛИіаХКХзівЛЖЈЕФааЮЊ, етРрЭЈГЃЪЧашвЊМрЬ§ Publish ФЃЪНЕФСї. Жј LiveData ЩшМЦжЎГѕОЭЪЧ Behavior ФЃЪН, Publish ФЃЪНЕФааЮЊЪОвтЭМШчЯТ, ФужЛФмЪеЕНФуЖЉдФЕужЎКѓЕФаХКХ.
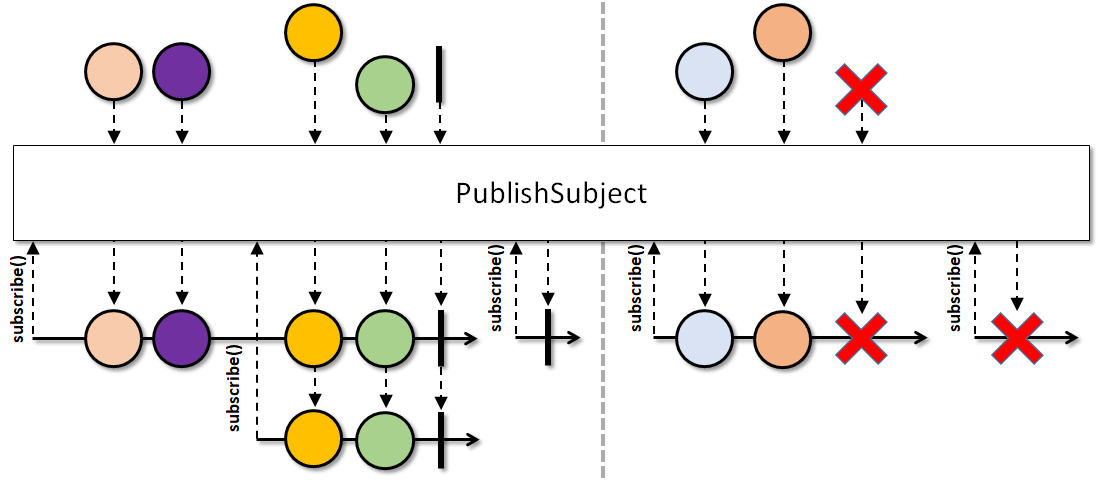
змНс
- Behavior ФЃЪНПЩбЁЕФЗНАИ
- RxJava ЕФ BehaviorSubject
- Kotlin Flow ЕФ StateFlow
- LiveData
- Publish ФЃЪНПЩбЁЕФЗНАИ
- RxJava ЕФ PublishSubject
- Kotlin Flow ЕФ SharedFlow
- ЮвУЧздЖЈвхЕФ Listener ЕШ
злЩЯЫљЪі, дкЯьгІЪНБрГЬжа, гЩгкФуНгЪмЕФаХКХдДгаВЛЭЌЕФФЃЪНЪЕЯж. ЫљвддкЦНГЃЕФвЕЮёашЧѓжа, ЮвУЧвВвЊКЯРэЕФНјаабЁдё.
БШШчЮвУЧгУгкЯдЪОНчУцЕФГЁОА, Behavior ФЃЪНЪЧзюЪЪКЯВЛЙ§СЫ, етвВЪЧЮЊЪВУД LiveData ГіЯжЕФдвђ. БООЭЮЊСЫЯдЪОвГУцЕФЪ§ОнШЅЕФ. дкНчУцжиНЈвВФмжиаТНјааЯдЪО.
дйБШШчЮвУЧгУгкжДааФГаЉааЮЊЕФГЁОА, БШШчФуЪеЕНвЛИіаХКХНјаавЛДЮЭјТчЧыЧѓЁЂЪ§ОнПтВйзїЁЂЬјзЊЕШЕШ. етаЉЦфЪЕЖМЪЧашвЊЪЙгУ Publish ФЃЪНЕФ.
ЯЃЭћЮвдкетРяЕФГЄЦЊДѓТл, ФмКмКУЕФНтЪЭФуУЧГіЯжЕФЫљЮНЕФЪ§ОнЕЙЙрЕФЮЪЬт. дкЯюФПжаФмКЯРэЕФбЁдёЖдгІЕФЪЕЯжШЅНтОіЮЪЬт. ВЂЧвЖдвЛИіЯьгІЪНЕФЪ§ОндДНјааМрЬ§ЕФЪБКђ, ашвЊЯШжЊЕРЫќЕФЪЕЯжФЃЪНЪЧ Behavior ЛЙЪЧ Publish, вдБугкФузіГіХаЖЯ, ПЩвдгУзїФФаЉГЁОАЕФЪЙгУ