����
Executor��Ϊһ�������ǿ����첽ִ�п��,��֧�ֶ��ֲ�ͬ���͵�����ִ�в���,�ṩ��һ�ֱ��ķ�����������ύ���̺�ִ�й��̽����˽����,���������ߺ�������ģ��,���ṩ�˶��������ڵ�֧��,�Լ�ͳ����Ϣ�ռ�,Ӧ�ó���������ƺ����ܼ��Ȼ��ơ�
��Ա��Ϊ�ĸ�����:��������ִ�С�����ִ�н���Լ�����ִ�й�����
- ����:ʵ��Callable�ӿڻ�Runnable�ӿ�
- ����ִ�в���:ThreadPoolExecutor�Լ�ScheduledThreadPoolExecutor
- ����ִ�н��:Future�ӿ��Լ�FutureTaskʵ����
- ����ִ�й�����:Executors
Executor
Java���̼߳��ǹ�����ԪҲ��ִ�е�Ԫ
new Thread(new Runnable() {
@Override
public void run() {
log.info("hello");
}
}).start();
��JDK5��ʼ,�ѹ�����Ԫ��ִ�л��Ʒ��뿪��,������Ԫ����Runnable��Callable,��ִ�л�����Executor����ṩ��
Executor�ӿڽ���������������ִ��,�ýӿ�ֻ��һ������
public interface Executor {
/**
* ִ�и�����Runnable����.
* ����Executor��ʵ�ֲ�ͬ, ����ִ�з�ʽҲ����ͬ.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
���ǿ�������������ִ������,��������ʾ�Ĵ����߳�(new Thread(new RunnableTask()).start()):
Executor executor = anExecutor();
executor.execute(new RunnableTask1());
executor.execute(new RunnableTask2());
...
Executor������һ���ӿ�,���Ը�����ʵ�ֵIJ�ͬ,ִ������ľ��巽ʽҲ������ͬ��Executor �ӿ������ϸ�Ҫ��ִ�����첽��,Ҳ����˵������ͬ���Ļ����첽��:
- ͬ��
class DirectExecutor implements Executor {
public void execute(Runnable r) {
r.run();
}
}
DirectExecutor��һ��ͬ������ִ����,���ڴ��������,ֻ��ִ����ɺ�execute�Ż᷵�ء�
- �첽
class ThreadPerTaskExecutor implements Executor {
public void execute(Runnable r) {
new Thread(r).start();
}
}
ThreadPerTaskExecutor��һ���첽����ִ����,����ÿ������,ִ�������ᴴ��һ���µ��߳�ȥִ������
���� Executor ʵ�ֶ�����ĵ��ȷ�ʽ��ʱ��ʩ����ij������,ͨ�������������������ʵ���Կ����̳߳صij��Ρ�
class SerialExecutor implements Executor {
final Queue<Runnable> tasks = new ArrayDeque<>();
final Executor executor;
Runnable active;
SerialExecutor(Executor executor) {
this.executor = executor;
}
public synchronized void execute(Runnable r) {
tasks.add(() -> {
try {
r.run();
} finally {
scheduleNext();
}
});
if (active == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((active = tasks.poll()) != null) {
executor.execute(active);
}
}
}
�ܽ�:Executor ��Ŀ����Ϊ�˽����������������ִ��
ExecutorService
ExecutorService�̳���Executor,����Executor�Ļ�������ǿ�˶�����Ŀ���,ͬʱ�����������������ڵĹ���,��Ҫ������:
- �ر�ִ����,��ֹ������ύ;
- ����ִ������״̬;
- �ṩ���첽�����֧��;
- �ṩ�������������֧�֡�
public interface ExecutorService extends Executor {
/**
* �ر�ִ����, ��Ҫ�������ص�:
* 1. �Ѿ��ύ����ִ�������������ִ��, ���Dz��ٽ�����������ύ;
* 2. ���ִ�����Ѿ��ر���, ���ٴε���û�и�����.
*/
void shutdown();
/**
* �����ر�ִ����, ��Ҫ�������ص�:
* 1. ����ֹͣ��������ִ�е�����, ����֤�ܹ�ֹͣ�ɹ�, ���ᾡ������(����, ͨ�� Thread.interrupt�ж�����, ���Dz���Ӧ�жϵ������������ֹ);
* 2. ��ͣ�����Ѿ��ύ��δִ�е�����;
*
* @return �����Ѿ��ύ��δִ�е������б�
*/
List<Runnable> shutdownNow();
/**
* �����ִ�����Ѿ��ر�, ��true.
*/
boolean isShutdown();
/**
* �ж�ִ�����Ƿ��Ѿ�����ֹ��.
* <p>
* ����ִ�����ѹر������������Ѿ�ִ�����, �ŷ���true.
* ע��: �������ȵ��� shutdown �� shutdownNow, ����÷�����Զ����false.
*/
boolean isTerminated();
/**
* ���������߳�, �ȴ�ִ���������ֹ��״̬.
*
* @return {@code true} ���ִ�������յ�����ֹ״̬, ��true; ����false
* @throws InterruptedException if interrupted while waiting
*/
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
/**
* �ύһ�����з���ֵ����������ִ��.
* ע��: Future��get�����ڳɹ����ʱ���᷵��task�ķ���ֵ.
*
* @param task ���ύ������
* @param <T> ����ķ���ֵ����
* @return ���ظ������Future����
* @throws RejectedExecutionException �������������ִ��
* @throws NullPointerException if the task is null
*/
<T> Future<T> submit(Callable<T> task);
/**
* �ύһ�� Runnable ��������ִ��.
* ע��: Future��get�����ڳɹ����ʱ���᷵�ظ����Ľ��(���ʱָ��).
*
* @param task ���ύ������
* @param result ���صĽ��
* @param <T> ���صĽ������
* @return ���ظ������Future����
* @throws RejectedExecutionException �������������ִ��
* @throws NullPointerException if the task is null
*/
<T> Future<T> submit(Runnable task, T result);
/**
* �ύһ�� Runnable ��������ִ��.
* ע��: Future��get�����ڳɹ����ʱ���᷵��null.
*
* @param task ���ύ������
* @return ���ظ������Future����
* @throws RejectedExecutionException �������������ִ��
* @throws NullPointerException if the task is null
*/
Future<?> submit(Runnable task);
/**
* ִ�и��������е���������, ����������ִ����ɺ�, ���ر�������״̬�ͽ���� Future �б�.
* <p>
* ע��: �÷���Ϊͬ������. �����б��е�����Ԫ�ص�Future.isDone() Ϊ true.
*
* @param tasks ����
* @param <T> ����ķ��ؽ������
* @return �����Future�����б�,�б�˳���뼯���еĵ����������ɵ�˳����ͬ,
* @throws InterruptedException ����ȴ�ʱ�����ж�, �Ὣ����δ��ɵ�����ȡ��.
* @throws NullPointerException ��һ����Ϊ null
* @throws RejectedExecutionException �����һ����������ִ��
*/
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
/**
* ִ�и��������е���������, ����������ִ����ɺ��ʱ����ʱ(�����ĸ����ȷ���), ���ر�������״̬�ͽ���� Future �б�.
*/
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException;
/**
* ִ�и��������е�����, ֻ������ij���������ȳɹ����(δ�׳��쳣), ������.
* һ���������쳣���غ�, ��ȡ����δ��ɵ�����.
*/
<T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException;
/**
* ִ�и��������е�����, ����ڸ����ij�ʱ����ǰ, ij�������ѳɹ����(δ�׳��쳣), ������.
* һ���������쳣���غ�, ��ȡ����δ��ɵ�����.
*/
<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
ScheduledExecutorService
ScheduledExecutorService ��ExecutorService�Ļ������ṩ��һϵ��schedule����,�����ڸ������ӳٺ�ִ���ύ������,����ÿ��ָ��������ִ��һ���ύ������
����
import static java.util.concurrent.TimeUnit.*;
/**
* ����scheduleAtFixedRate�����ύ��һ��������������,ÿ��10s�������ִ��һ��, 1Сʱ��, ȡ����������
*/
class BeeperControl {
private final ScheduledExecutorService scheduler =
Executors.newScheduledThreadPool(1);
public void beepForAnHour() {
Runnable beeper = () -> System.out.println("beep");
ScheduledFuture<?> beeperHandle =
scheduler.scheduleAtFixedRate(beeper, 10, 10, SECONDS);
Runnable canceller = () -> beeperHandle.cancel(false);
scheduler.schedule(canceller, 1, HOURS);
}
}
ScheduledExecutorService�����Ľӿ���������:
public interface ScheduledExecutorService extends ExecutorService {
?
/**
* �ύһ����ִ�е�����, ���ڸ������ӳٺ�ִ�и�����.
*
* @param command ��ִ�е�����
* @param delay �ӳ�ʱ��
* @param unit �ӳ�ʱ��ĵ�λ
*/
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
?
/**
* �ύһ����ִ�е�����(���з���ֵ), ���ڸ������ӳٺ�ִ�и�����.
*
* @param command ��ִ�е�����
* @param delay �ӳ�ʱ��
* @param unit �ӳ�ʱ��ĵ�λ
* @param <V> ����ֵ����
*/
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
?
/**
* �ύһ����ִ�е�����.
* �������� initialDelay ��ʼִ��, Ȼ���� initialDelay+period ��ִ��, ������ initialDelay + 2 * period ��ִ��, ��������.
*
* @param command ��ִ�е�����
* @param initialDelay �״�ִ�е��ӳ�ʱ��
* @param period ����ִ��֮�������
* @param unit �ӳ�ʱ��ĵ�λ
*/
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
?
/**
* �ύһ����ִ�е�����.
* �������� initialDelay ��ʼִ��, �����ÿһ��ִ����ֹ����һ��ִ�п�ʼ֮�䶼���ڸ������ӳ�.
* ����������һִ�������쳣, �ͻ�ȡ������ִ��. ����, ֻ��ͨ��ִ�г����ȡ������ֹ��������ֹ������.
*
* @param command ��ִ�е�����
* @param initialDelay �״�ִ�е��ӳ�ʱ��
* @param delay һ��ִ����ֹ����һ��ִ�п�ʼ֮����ӳ�
* @param unit �ӳ�ʱ��ĵ�λ
*/
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
}
��
- Executor:�ύ��ͨ�Ŀ�ִ������
- ExecutorService:�ṩ���̳߳��������ڵĹ������첽�����֧��
- ScheduledExecutorService:�ṩ�������������ִ��֧��
���Ͻ��ܵ���, Executor ExecutorService ScheduledExecutorService ���ǽӿڵĶ���,���濴һ�¾����ʵ�֡�
�����ᵽ�Ľӿں���Ĺ�ϵ����ͼ��ʾ:


-
Executor
ִ�����ӿ�,Ҳ�����ij�����Ľӿ�, ����������������ִ�С�
-
ExecutorService
��Executor�Ļ������ṩ��ִ�����������ڹ���,�����첽ִ�еȹ��ܡ�
-
ScheduledExecutorService
��ExecutorService�������ṩ��������ӳ�ִ��/����ִ�еĹ��ܡ�
-
Executors
���������ִ�����ľ�̬����
-
ThreadFactory
�̹߳���,���ڴ��������߳�,�����ֹ������̵߳ķ�������,ͬʱ�ܹ����ù��������ԡ�
-
AbstractExecutorService
ExecutorService�ij���ʵ��,Ϊ����ִ�������ʵ���ṩ������
-
ThreadPoolExecutor
�̳߳�Executor,Ҳ����õ�Executor,�������̳߳صķ�ʽ�����̡߳�
-
ScheduledThreadPoolExecutor
��ThreadPoolExecutor������,�����˶�����������ȵ�֧�֡�
-
ForkJoinPool
Fork/Join�̳߳�,��JDK1.7ʱ����,ʱʵ��Fork/Join��ܵĺ����ࡣ
Executorִ����������:

Executors
Executors�ṩһ��������һϵ�й��߷���,�������з�������static��,�û����Ը�����Ҫ,ѡ����Ҫ������ִ����ʵ��,Executorsһ���ṩ����������:
- �����ͷ��������˾��г������õ�
ExecutorServiceʵ���ķ��� - �����ͷ��������˾��г������õ�
ScheduledExecutorServiceʵ���ķ��� - �����ͷ���
ExecutorService�İ�װ��ʵ���ķ���,��Щ������������������ʵ��,ֻ��¶����ķ��� - �����ͷ��� ���´������߳�����Ϊ��֪״̬��
ThreadFactoryʵ���ķ��� - ���������Ʊհ�����ʽ�д����ͷ��� Callable ʵ���ķ���,���ǿ�������Ҫ Callable �ķ�����ʹ�á�
���Ǵ�����ͼ�ķ���ǩ����Ҳ���¿��ij���:

ΪʲôҪ�а�װ��?
��Ϊ���ֱ�ӷ����� ThreadPoolExecutor��������,�����һЩ�����̳߳صķ���,���� setCorePoolSize,����ʱ�����Dz�ϣ��ʹ����ǿ��ת����ʹ����Щ����(����:newSingleThreadExecutor),����Ҫ��װһ��,�������ص���ֻ��¶ExecutorService�����ķ���
DelegatedExecutorService���Ƕ�ExecutorService��һ�ְ�װ,����ֻ��ʹ���߱�¶ ExecutorService�Ľӿڷ���,���ε�����ʵ����Ķ��з�����DelegatedScheduledExecutorService�Ƕ�ScheduledExecutorService�İ�װ,����ֻ��ʹ���߱�¶ ScheduledExecutorService�Ľӿڷ���,��FinalizableDelegatedExecutorService���ڶ�ExecutorService�İ�װ������,�������Զ��̳߳ػ��յĹ���,��finalize�������������gc��������ʱ������,�Ӷ����û����ǹرյ������̳߳عرղ����ա�
ThreadPoolExecutor
Executor���ճ�ʹ��������ij��������̳߳��ˡ�
ʲô���̳߳�?
�̳߳�(Thread Pool)��һ�ֻ��ڳػ�˼������̵߳Ĺ���
�̳߳ص�������ʲô?
�̳߳����Ĺ�����Ҫ�ǿ������е��̵߳�����,���������н�����������,Ȼ�����̴߳�����������Щ����,����߳�����������������������������߳��ŶӵȺ�,�������߳�ִ�����,�ٴӶ�����ȡ��������ִ�С�������Ҫ�ص�Ϊ:�̸߳���;���������;�����̡߳�
�����̳߳صĺô���ʲô?
�����̳߳��ܹ����߳̽���ͳһ����,���źͼ��:
- ������Դ����:ͨ���ػ������ظ������Ѵ������߳�,�����̴߳�����������ɵ���ġ�
- �����Ӧ�ٶ�:����ʱ,����ȴ��̴߳�����������ִ�С�
- ����̵߳Ŀɹ�����:�߳���ϡȱ��Դ,��������ƴ���,����������ϵͳ��Դ,������Ϊ�̵߳IJ������ֲ�������Դ����ʧ��,����ϵͳ���ȶ��ԡ�ʹ���̳߳ؿ��Խ���ͳһ�ķ��䡢���źͼ�ء�
- �ṩ�����ǿ��Ĺ���:�̳߳ؾ߱�����չ��,����������Ա���������Ӹ���Ĺ��ܡ�������ʱ��ʱ�̳߳�ScheduledThreadPoolExecutor,��������������ִ�л���ִ�С�
�̳߳ؽ����������ʲô?
�̳߳ؽ���ĺ������������Դ�������⡣�ڲ���������,ϵͳ���ܹ�ȷ��������ʱ����,�ж���������Ҫִ��,�ж�����Դ��ҪͶ�롣���ֲ�ȷ���Խ�����������������:
- Ƶ������/������Դ�͵�����Դ,���������������,���ܻ�dz���
- ����Դ��������ȱ�������ֶ�,������ϵͳ��Դ�ľ��ķ��ա�
- ϵͳ�����������ڲ�����Դ�ֲ�,�ή��ϵͳ���ȶ��ԡ�
Ϊ�����Դ�����������,�̳߳ز����ˡ��ػ���(Pooling)˼�롣
Pooling is the grouping together of resources (assets, equipment, personnel, effort, etc.) for the purposes of maximizing advantage or minimizing risk to the users. The term is used in finance, computing and equipment management.����wikipedia
�ػ�,����˼��,��Ϊ��������沢��С������,������Դͳһ��һ�������һ��˼�롣
�ػ�˼�벻������Ӧ���ڼ��������,�ڽ��ڡ��豸����Ա��������������������Ҳ����ص�Ӧ�á�
�ڼ���������еı���Ϊ:ͳһ����IT��Դ,�������������洢����������Դ�ȵȡ�ͨ��������Դ,ʹ�û��ڵ�Ͷ���л��档
��ȥ�̳߳�,���������Ƚϵ��͵ļ���ʹ�ò�����:
- �ڴ��(Memory Pooling):Ԥ�������ڴ�,���������ڴ��ٶ�,�����ڴ���Ƭ��
- ���ӳ�(Connection Pooling):Ԥ���������ݿ�����,�����������ӵ��ٶ�,����ϵͳ�Ŀ�����
- ʵ����(Object Pooling):ѭ��ʹ�ö���,������Դ�ڳ�ʼ�����ͷ�ʱ�İ�����ġ�
Executors �ṩ��һϵ�й����������ڴ����̳߳�,��ʱ���²���,���ǿ�һ�����ĵ��� ThreadPoolExecutor,Ȼ������ٿ���
ThreadPoolExecutor���������,���ͬʱά���̺߳�ִ���������?
�����л�������ͼ��ʾ:

�̳߳����ڲ�ʵ���Ϲ�����һ��������������ģ��,���̺߳��������߽���,����ֱ�ӹ���,�Ӷ����õĻ�������,�����̡߳�
�̳߳ص�������Ҫ�ֳ�������:
- �������
- �̹߳���
����������ֳ䵱�����ߵĽ�ɫ,�������ύ��,�̳߳ػ��жϸ������������ת:
- ֱ�������߳�ִ�и�����;
- ���嵽�����еȴ��߳�ִ��;
- �ܾ��������̹߳���������������,���DZ�ͳһά�����̳߳���,����������������̵߳ķ���,���߳�ִ�����������������ȡ�µ�����ȥִ��,���յ��̻߳�ȡ���������ʱ��,�߳̾ͻᱻ���ա�
�̳߳����ά������״̬?
�̳߳����е�״̬,�������û���ʽ���õ�,���ǰ������̳߳ص�����,���ڲ���ά�����̳߳��ڲ�ʹ��һ������ά������ֵ:����״̬(runState)���߳����� (workerCount)���ھ���ʵ����,�̳߳ؽ�����״̬(runState)���߳����� (workerCount)�����ؼ�������ά��������һ��,���´�����ʾ:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ctl���AtomicInteger����,�Ƕ��̳߳ص�����״̬���̳߳�����Ч�̵߳��������п��Ƶ�һ���ֶ�, ��ͬʱ���������ֵ���Ϣ:�̳߳ص�����״̬ (runState) ���̳߳�����Ч�̵߳����� (workerCount),��3λ����runState,��29λ����workerCount,��������֮�以�����š���һ������ȥ�洢����ֵ,�ɱ���������ؾ���ʱ,���ֲ�һ�µ����,����Ϊ��ά�����ߵ�һ��,��ռ������Դ��ͨ���Ķ��̳߳�Դ����Ҳ���Է���,��������Ҫͬʱ�ж��̳߳�����״̬���߳�������������̳߳�Ҳ�ṩ�����ɷ���ȥ���û�����̳߳ص�ǰ������״̬���̸߳��������ﶼʹ�õ���λ����ķ�ʽ,����ڻ�������,�ٶ�Ҳ���ܶࡣ
�����ڲ���װ�Ļ�ȡ��������״̬����ȡ�̳߳��߳������ļ��㷽�������´�����ʾ:
private static int runStateOf(int c) { return c & ~CAPACITY; } //���㵱ǰ����״̬
private static int workerCountOf(int c) { return c & CAPACITY; } //���㵱ǰ�߳�����
private static int ctlOf(int rs, int wc) { return rs | wc; } //ͨ��״̬���߳�������ctl
ThreadPoolExecutor������״̬��5��,�ֱ�Ϊ:

����������ת����������ʾ:

�������������������?
����������̳߳ص���Ҫ���,���û��ύ��һ������,����������������ִ�ж���������ξ����ġ��˽��ⲿ�־��൱���˽����̳߳صĺ������л��ơ�����,��������ĵ��ȶ�����execute������ɵ�,�ⲿ����ɵĹ�����:��������̳߳ص�����״̬�������߳��������в���,����������ִ�е�����,��ֱ�������߳�ִ��,���ǻ��嵽������ִ��,�����ֱ�Ӿܾ���������ִ�й�������:
- ���ȼ���̳߳�����״̬,�������RUNNING,��ֱ�Ӿܾ�,�̳߳�Ҫ��֤��RUNNING��״̬��ִ������
- ���workerCount < corePoolSize,��������һ���߳���ִ�����ύ������
- ���workerCount >= corePoolSize,���̳߳��ڵ���������δ��,���������ӵ������������С�
- ���workerCount >= corePoolSize && workerCount < maximumPoolSize,���̳߳��ڵ�������������,��������һ���߳���ִ�����ύ������
- ���workerCount >= maximumPoolSize,�����̳߳��ڵ�������������, ����ݾܾ�����������������, Ĭ�ϵĴ�����ʽ��ֱ�����쳣��
��ִ����������ͼ��ʾ:

�����������?
����ģ�����̳߳��ܹ���������ĺ��IJ��֡��̳߳صı����Ƕ�������̵߳Ĺ���,��������һ����ؼ���˼����ǽ�������߳����߽���,��������ֱ�ӹ���,�ſ����������ķ��乤�����̳߳�������������������ģʽ,ͨ��һ������������ʵ�ֵġ��������л�������,�����̴߳����������л�ȡ����
��������(BlockingQueue)��һ��֧���������Ӳ����Ķ��С����������ӵIJ�����:�ڶ���Ϊ��ʱ,��ȡԪ�ص��̻߳�ȴ����б�Ϊ�ǿա���������ʱ,�洢Ԫ�ص��̻߳�ȴ����п��á��������г����������ߺ������ߵij���,��������������������Ԫ�ص��߳�,�������ǴӶ�������Ԫ�ص��̡߳��������о��������ߴ��Ԫ�ص�����,��������Ҳֻ����������Ԫ�ء�
��ͼ��չʾ���߳�1����������������Ԫ��,���߳�2�������������Ƴ�Ԫ��
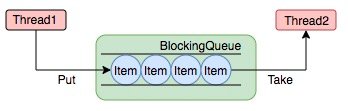
ʹ�ò�ͬ�Ķ��п���ʵ�ֲ�һ���������ȡ����:

�߳���Ҫ������ģ���в��ϵ�ȡ����ִ��,�����̴߳����������л�ȡ����,ʵ���̹߳���ģ����������ģ��֮���ͨ�š��ⲿ�ֲ�����getTask����ʵ��,��ִ����������ͼ��ʾ:

��������ξܾ���?
����ܾ�ģ�����̳߳صı�������,�̳߳���һ����������,���̳߳ص������������,�����̳߳��е��߳���Ŀ�ﵽmaximumPoolSizeʱ,����Ҫ�ܾ���������,��ȡ����ܾ�����,�����̳߳ء�
�û�����ͨ��ʵ������ӿ�ȥ���ƾܾ�����,
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
Ҳ����ѡ��JDK�ṩ���������оܾ�����,���ص�����:
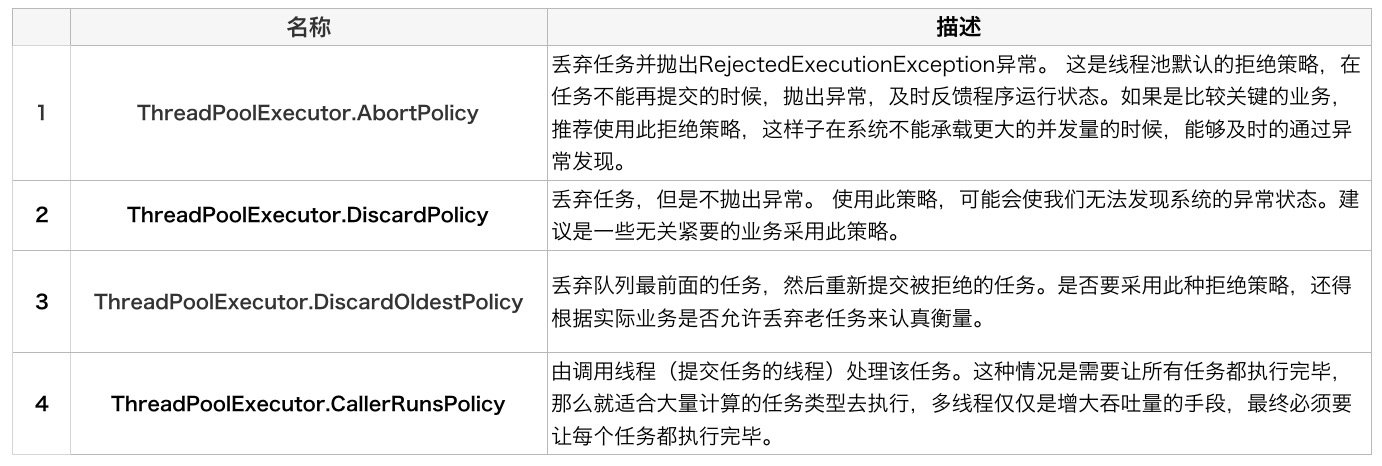
�߳�����ô������?
˵���˾���һ���̼߳���workerSet��һ����������workQueue�����û����̳߳��ύһ������(Ҳ�����߳�)ʱ,�̳߳ػ��Ƚ��������workQueue�С�workerSet�е��̻߳�ϵĴ�workQueue�л�ȡ�߳�Ȼ��ִ�С���workQueue��û�������ʱ��,worker�ͻ�����,ֱ���������������˾�ȡ��������ִ�С�

Workerִ�������ģ������ͼ��ʾ:

���IJ���
�˽���������Щ,������ ThreadPoolExecutor �Ĺ��췽���ͺ��IJ����ͺ�����������:
- corePoolSize:�����߳�����
- maximumPoolSize:����߳�����
- keepAliveTime:�̴߳��ʱ�䡣
- unit:keepAliveTime�ĵ�λ
- workQueue:Runnable���������С����̳߳��Ѿ���ռ��,��ö������ڴ�����ٷ����̳߳��е�Runnable��
- threadFactory:�̹߳���
- handler:�ܾ�����
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
�м�����Ҫע���:
- һ�������,
corePoolSize��maxiunmPoolSizeֻ���ڹ�����ʱ����г�ʼ��,���ǿ���ͨ��setCorePoolSize(int)�� setMaximumPoolSize(int)����̬���ġ� - Ĭ�������,��ʹ�����߳����ֻ������������Ҫʱ�Ŵ����������ġ��������ǿ���ʹ��
prestartCoreThread()(����һ�����������̵߳ȴ�����ĵ���) ��prestartAllCoreThreads()(���������̳߳������Ŀ��������̵߳ȴ�����ĵ���)������̬������ - ���һ�������������е��߳�������
corePoolSize,���������̱߳��ֿ��е�ʱ�����keepAliveTime,��ô��Щ�߳̾ͻᱻ�رա������������̳߳ز���Ծ��ʱ����Դ�����ġ�Ĭ�������,keep-alive ���Խ������ڴ���corePoolSize�߳������߳�,���Ǻ����߳�,������allowCoreThreadTimeOut(boolean) Ҳ�����ڽ��˳�ʱ����Ӧ�õ������߳�,ֻҪ keepAliveTime ֵ����. - ThreadPoolExecutor�ṩ��ÿ������ִ��ǰ���ṩ�˹��ӷ���,��д
beforeExecute(Thread,Runnable)��afterExecute(Runnable,Throwable)����������ִ�л���; ����,���³�ʼ��ThreadLocals,�ռ�ͳ����Ϣ���¼��־�ȡ�terminated()����Ҳ���Ա�����,���̳߳���ȫ��ֹ��ʱ��,�����ͨ�����������һЩ����Ĵ�����
��κ��������߳�����
ҵ���һЩ�̳߳ز������÷���,������˵,����һ������,����Ҫ�����Լ�ҵ���ʵ�������������

��ιر�
��һ���̳߳ز��ٱ�������������,���ҳ���û���̵߳�ʱ��,�ͻ��Զ�shutdown��
�������������:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
// ʵ��������ǻ����̵߳���Ҫ������,�Ƴ��̳߳ضԸ��̵߳�����,ʹ����Ա�JVM�����ػ���
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
// ���������̻߳��յĿ������кܶ�,�̳߳ػ�Ҫ�ж���ʲô��������λ���,
// �Ƿ�Ҫ�ı��̳߳ص��ֽ�״̬,�Ƿ�Ҫ������״̬,���·����߳�,���Ǿ����������ⲿ����
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
Ҳ�����ֶ�,����:
-
shutdown
���̳߳�״̬��ΪSHUTDOWN,����������ֹͣ:
- ֹͣ�����ⲿsubmit������
- �ڲ������ܵ�����Ͷ�����ȴ�������,��ִ����
- �ȵ��ڶ�����ɺ�,������ֹͣ
-
shutdownNow
���̳߳�״̬��ΪSTOP����ͼ����ֹͣ,��ʵ�ϲ�һ��:
- ��shutdown()һ��,��ֹͣ�����ⲿ�ύ������
- ���Զ�����ȴ�������
- ���Խ������ܵ�����interrupt�ж�
- ����δִ�е������б�
����ͼ��ֹ�̵߳ķ�����ͨ������Thread.interrupt()������ʵ�ֵ�,�������ַ�������������,����߳���û��sleep ��wait��Condition����ʱ����Ӧ��, interrupt()���������жϵ�ǰ���̵߳ġ�����,shutdownNow()���������̳߳ؾ�һ�����������˳�,��Ҳ���ܱ���Ҫ�ȴ���������ִ�е�����ִ������˲����˳��� ���Ǵ����ʱ�����������˳���
-
awaitTermination(long timeOut, TimeUnit unit)
��ǰ�߳�����,ֱ��
- ���������ύ������(���������ܵĺͶ����еȴ���)ִ����
- ���ߵȳ�ʱʱ�䵽
- �����̱߳��ж�,�׳�InterruptedException Ȼ��true(shutdown�������������ִ�����)��false(�ѳ�ʱ)
ע��:
- shuntdown()��awaitTermination()Ч�����,����ִ��֮��,��Ҫ�ȵ��ύ������ȫ��ִ�����ͣ��
- shutdown()��,�������ύ�µ������ȥ;����awaitTermination()��,���Լ����ύ
- awaitTermination()��������,���ؽ�����̳߳��Ƿ���ֹͣ(true/false);shutdown()������
������Źر�?
��һ�ַ���
���ȿ���Դ��ע��:
A pool that is no longer referenced in a program AND has no remaining threads may be reclaimed (garbage collected) without being explicitly shutdown. You can configure a pool to allow all unused threads to eventually die by setting appropriate keep-alive times, using a lower bound of zero core threads and/or setting allowCoreThreadTimeOut(boolean).
��������в��ٳ����̳߳ص�����,�����̳߳���û���߳�ʱ,�̳߳ؽ����Զ��رա�
�̳߳��Զ��رյ���������:
- �̳߳ص����ò��ɴ�;
- �̳߳���û���̡߳�
�����������2����һ��,�̳߳���û���߳���ָ�̳߳��е������̶߳����������Զ�������Ȼ���������ThreadPool�ĺ����߳�û�г�ʱ����,�̳߳ز������Զ��رա�
������Ҫ����:
//�̳߳���ִ���������,������ʱʱ��,�����п��е��̶߳��ͷŵ�,���̳��������̾Ϳ����˳�
pool.allowCoreThreadTimeOut(true);
�ڶ��ַ���
����Runtime.getRuntime().addShutdownHook ��guava�ķ������Źر�
static {
Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() {
@Override
public void run() {
System.out.println("====��ʼ�ر��̳߳�");
CommonThreadPool.gracefulShutdown(pool, 10, TimeUnit.SECONDS);
System.out.println("====�����ر��̳߳�");
}
}));
}
public static boolean gracefulShutdown(ExecutorService threadPool, int shutdownTimeout,
TimeUnit timeUnit) {
return threadPool == null || MoreExecutors
.shutdownAndAwaitTermination(threadPool, shutdownTimeout, timeUnit);
}
����
��Ҫ���̳߳��߳�����Ϊ�ػ��߳�,��Ȼ**�ػ��̲߳�����ֹ JVM �˳�,**��������������,����л�δִ���������ͻ�����쳣��,(����ûִ������˳�)
Executors �����̳߳�
����**Executors**�ľ�̬�������Դ�����ͬ���͵��̳߳�,�����Ƽ�ʹ�á�
- newFixedThreadPool(int nThreads) �C �����̶���Ŀ�̵߳��̳߳�
- ����ʱ���,���ֻ���й̶���Ŀ�Ļ�̴߳���,��ʱ������µ��߳�Ҫ����,ֻ�ܷ�������Ķ���(��һ������� LinkedBlockingQueue,��������Ϊ Integer.MAX_VALUE)�еȴ�,ֱ����ǰ���߳���ij���߳���ֱֹ�ӱ��Ƴ����ӡ� �������һЩ���ȶ��̶ܹ������沢���߳�,�����ڷ�������
- newSingleThreadExecutor ����һ�����̻߳���Executor
- ����SingleThreadExecutor�ύ�˶������,��ô��Щ�����Ŷӡ�
- newCachedThreadPool-- ����һ���ɻ�����̳߳�,����execute��������ǰ������߳�(����߳̿���)����������߳�û�п��õ�,��һ������ �̲����ӵ����С���ֹ���ӻ������Ƴ���Щ���� 60 ����δ��ʹ�õ��̡߳�
- newScheduledThreadPool(int corePoolSize) ����һ��֧�ֶ�ʱ�������Ե�����ִ�е��̳߳�,��������¿��������Timer��
��������
Ϊʲô�̳߳ز�����ʹ��Executorsȥ����? �Ƽ���ʽ��ʲô?
Executors ���ص��̳߳ض���ı�����:
- FixedThreadPool �� SingleThreadPool:
������������г���Ϊ Integer.MAX_VALUE,���ܻ�ѻ�����������,�Ӷ����� OOM��
- CachedThreadPool �� ScheduledThreadPool:
�����Ĵ����߳�����Ϊ Integer.MAX_VALUE,���ܻᴴ���������߳�,�Ӷ����� OOM��
�̳߳ز�����ʹ�� Executors ȥ����,����ͨ�� ThreadPoolExecutor �ķ�ʽ,�����Ĵ�����ʽ��д��ͬѧ������ȷ�̳߳ص����й���,�����Դ�ľ��ķ��ա�
�ο�
- https://nullwy.me/2017/03/java-executor/
- https://www.jianshu.com/p/f54b224e24f6
- https://segmentfault.com/a/1190000016586578
- https://www.cnblogs.com/liuyishi/p/10508596.html
- https://juejin.cn/post/6922069411981426702
- https://pdai.tech/md/java/thread/java-thread-x-juc-executor-ThreadPoolExecutor.html
- https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html

