USCCampusEastStreet
вЛИіВЩгУscrapyХРГцвдDjangoЮЊКѓЖЫЕФЮЂаХаЁГЬађ
ЯюФПЕижЗ:https://github.com/WGowi/USCCampusEastStreet
ЮФеТФПТМ
ЕквЛеТ ЯЕЭГИХвЊЗжЮі
дкЩЯвЛеТЭъГЩЕФЯрЙиММЪѕНщЩмЩЯ,дкетеТжаБОЮФЮвУЧНЋЛсЖдвдЩЯЬсЕНЕФЗНУц,зіГіИќМгЯъЯИПЩааЕФНтОіЗНАИ,етвЛеТжївЊЕФФкШнЪЧЖдХРГцЯЕЭГЁЂКѓЖЫDjangoвдМАЧАЖЫЮЂаХаЁГЬађЕФИХвЊЩшМЦ,жївЊЪЧДгЩшМЦддђМАФПБъЁЂЬхЯЕНсЙЙЁЂЙІФмНсЙЙКЭЪ§ОнПтЩшМЦЩЯРДНщЩмСЫЯЕЭГЕФећЬхМмЙЙЁЃ
(ЯШНщЩмзмЬхПђМм,дйЗжВПНщЩмУПИіЕФЙІФм)
1.1 ЯЕЭГзмЬхЩшМЦ
1.1.1 ЯЕЭГзщГЩВПЗжЗжЮі
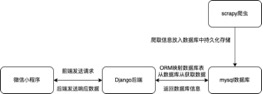
ЭМ Ш§.1ЯЕЭГзмЬхМмЙЙЭМ
1.1.2 ЯЕЭГдЫааСїГЬ
ЖдЯЕЭГЙЄзїСїГЬНјааШчЯТЗжЮі:
\1. ЪзЯШDjangoКѓЖЫЭЈЙ§ORMЖдЯѓЙиЯЕгГЩфаЮГЩЯьгІЕФЪ§ОнПтБэ
\2. ScrapyХРГцЭЈЙ§СЌНгЯрЖдгІЕФЪ§ОнПт,ЭљБэжаЬэМгЯьгІЕФЪ§Он
\3. DjangoКѓЖЫЕФAdminУцАхПЩвдЖдscrapyХРГцЬэМгЕФЪ§ОнНјааЙмРэ
\4. ЧАЖЫЮЂаХаЁГЬађЭЈЙ§ЗЂЫЭrequestЧыЧѓИјDjangoКѓЖЫ,DjangoКѓЖЫЯьгІРДздЧАЖЫЕФЧыЧѓ,ВЂЛёЕУЦфаЏДјЕФЯрЙиВЮЪ§,ЯђЪ§ОнПтжаЧыЧѓЯрЙиаХЯЂ
\5. Ъ§ОнПтНгЪмРДздКѓЖЫЕФЧыЧѓ,ВЂЗЕЛиЯьгІЕФЪ§Он
\6. DjangoКѓЖЫНгЪмРДздЪ§ОнПтЕФЪ§Он,ВЂзЊЛЏЮЊЯргІЕФИёЪНЗЂЫЭИјЮЂаХаЁГЬађ
\7. ЮЂаХаЁГЬађЕУЕНЯргІЕФЪ§ОнКѓ,фжШОвГУцВЂЯдЪОЯрЙиаХЯЂ
1.2 ХРГцзмЬхЩшМЦНщЩм
1.2.1 ХРШЁЖдЯѓМђНщ
БОЮФЪЕЯжЕФХРГцвдФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЕФНЬг§бєЙтаХЯЂСаБэЧхЕЅФЃПщ(http://nhedu.tabbyedu.com/column/lbqd/index.shtml)вдМАЪЇЮяеаСьФЃПщ(http://nhedu.tabbyedu.com/column/swlt/index.shtml)вдМАжаЙњбаОПЩњеаЩњаХЯЂЭјЕФЫЖЪПФПТМФЃПщ(https://yz.chsi.com.cn/zsml/zyfx_search.jsp)зїЮЊХРШЁЖдЯѓ,ХРШЁНЬг§бєЙтаХЯЂСаБэЧхЕЅФЃПщЕФУПвЛИіЬћзгЕФIDЁЂБъЬтЁЂФкШнЁЂРрБ№ЁЂВПУХЁЂЛиИДЁЂЩэЗнвдМАИНМўЭМЦЌ;ХРШЁЪЇЮяеаСьФЃПщЕФIDЁЂБъЬтЁЂЯИНкУшЪіЁЂСЊЯЕШЫЁЂСЊЯЕЗНЪНЁЂЪАШЁЛђвХЪЇЪБМфЁЂЪАШЁЛђвХЪЇЕиЕуЁЂеаСьЕиЕу;ХРШЁЫЖЪПФПТМЕФбЇаЃУћГЦЁЂбЇаЃЫљдкЕиЁЂеаЩњдКЯЕЁЂеаЩњШЫЪ§ЁЂПМЪдПЦФПЁЂбаОПЗНЯђЁЂжИЕМРЯЪІЁЂбЇПЦУХРрЁЂбЇПЦРрБ№ЁЂбЇЯАЗНЪНЁЂеаЩњзЈвЕЁЂЪЧЗёздЛЎЯпЁЂЪЧЗёгЕгабаОПЩњдКЁЂЪЧЗёгЕгаВЉЪПЕуЁЃ
ФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЪЧФЯЛЊДѓбЇЙигкбЇЩњЩњЛюЕФвЛИіЦНЬЈ,зїЮЊХРШЁЖдЯѓгазХСЂзуБОаЃЕФвтвх,ЭЌЪБФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЪЧВЩгУЖЏЬЌМгдиЕФЁЂгазХВХгУjsЯТдиЕШЗДХРГцДыЪЉжаЙњбаОПЩњеаЩњаХЯЂЭјЕФЫЖЪПФПТМдђгазХIPМьВтЕШЗДХРГцДыЪЉ,ЖјетНЋАяжњЮвУЧИќМгЯИжТЕФСЫНтХРГцгыЗДЗДХРЕФЙЄзїдРэКЭСїГЬЁЃ
1.2.2 ХРГцзмЬхМмЙЙЩшМЦ
БОЮФНЋХРГцЗжЮЊШ§ИіФЃПщМДЭјвГаХЯЂзЅШЁФЃПщЁЂжаМфМўФЃПщвдМАЪ§ОнДІРэФЃПщЁЃ
ЭјвГаХЯЂзЅШЁФЃПщЪзЯШИљОнЖЈвхЕФURLЕижЗЗжЮіЭјвГelementНсЙЙ,дкИљОнПЊЗЂепЖЈвхЕФxpathРДЬсШЁЯрЙизжЖЮЁЃ
жаМфМўФЃПщ,ЭЈЙ§User-AgentЮБзА,ДњРэIPЕШММЪѕЪЕЯжЗДЗДХРЁЃ
Ъ§ОнДІРэФЃПщНЋЖдХРГцХРШЁЕФЪ§ОнНјааЯрЙиДІРэ,ШЛКѓдкmysqlЪ§ОнПтжаЪЕЯжГжОУЛЏДцДЂЁЃ
1.3 DjangoКѓЖЫзмЬхЩшМЦНщЩм
1.3.1 ORMЖдЯѓЙиЯЕгГЩфЩшМЦ
DjangoПЩвдЭЈЙ§ORMЖдЯѓЙиЯЕгГЩфАбМЬГаздmodels.ModelЕФpythonРргГЩфГЩЪ§ОнПтжаЕФБэ,АбРрФкЪєадгГЩфЮЊЪ§ОнжаЕФзжЖЮ,ВЂЧвDjangoЮЊORMЬсЙЉСЫЯргІЕФЪ§ОнРраЭШчCharFieldМДПЩгГЩфЮЊmysqlжаЕФvarcharЁЃетбљЪЙЕУПЊЗЂепдкГЬађЩшМЦЪБИќМгЙизЂРрЕФБОЩэ,ЖјЗЧЪ§ОнПтЁЃМЋДѓСЫЬсИпСЫГЬађЕФПЩвЦжВадЁЃНЕЕЭСЫГЬађгыЪ§ОнПтЕФёюКЯадЁЃ
ЭЌЪБРрФкЪєадЕФЩшМЦвВИќХРГцХРШЁЕФзжЖЮЯрЙи,вЊИљОнscrapyХРГцжаЕФitems.pyЖЈвхЕФscrapy.Field()РДЩшМЦФЃаЭРрЁЃ
1.3.2 ViewЪгЭМЩшМЦ
DjangoПђМмжаViewЪгЭМжївЊИКд№Ъ§ОнТпМЕФДІРэ,Ъ§ОнНгПкЕФЪЕЯж,ЭЌЪБгыTemplateФЃАцРрвдЧАЪЕЯжНчУцЕФЯдЪО[27]ЁЃЖјБОЮФжаЪЙгУСЫЮЂаХаЁГЬађзїЮЊЧАЖЫ,ЪЙгУViewжївЊЖдЦфЪ§ОнНгПкЕФЪЕЯжЁЃЦфФПЕФЪЧЮЊСЫЯьгІРДздЧАЖЫЕФrequestЧыЧѓЁЃ
ViewжївЊЮЊЧАЖЫЬсЙЉСЫЛёШЁЪЇЮяеаСьЕФаХЯЂЁЂЛёШЁбАЮяЦєЪТЕФаХЯЂЁЂЛёШЁаЃдАзЪбЖЁЂЖдбАЮяЦєЪТФкШнНјааЫбЫї,ЖдЪЇЮяеаСьаХЯЂНјааЫбЫїЁЂЖдаЃдАзЪбЖНјааЫбЫїЁЂЛёШЁбЇПЦРрБ№гыбЇПЦУХРрЕФаХЯЂ,ЕМГіПМбадКаЃаХЯЂЁЃ
ЭЌЪБЭЈЙ§urls.py,АбЯргІЕФURLЕижЗгыЦфЪгЭМНјааАѓЖЈЁЃМДПЩвдЭЈЙ§urlЖдЪгЭМЕФЗЂЩњЗУЮЪЧыЧѓЁЃ
1.3.3 adminУцАхЩшМЦ
DjangoЮЊЪ§ОнПтЙмРэдБЬсЙЉСЫПЩЪгЛЏЕФЪ§ОнПтЙмРэУцАх,ПЩвдЖдЪ§ОнПтжаЪ§ОнНјааВйзїЁЃ
ПЊЗЂепжЛашвЊдкadmin.pyжаЩшМЦМЬГаздadmin.ModelAdminЕФРр,ВЂЧвНЋФЃаЭРргыЦфНјааАѓЖЈМДПЩ,ПьЫйБуНнЁЃ
1.4 ЮЂаХаЁГЬађзмЬхЩшМЦНщЩм
1.4.1 ЮЂаХаЁГЬађЙІФмЩшМЦ
ЮЂаХаЁГЬађжївЊЪЧИКд№ЧАЖЫНчУцЕФЯдЪО,ЮЂаХаЁГЬађНчУцжївЊЗжЮЊжївГЁЂЙуГЁвГЁЂПМбааХЯЂвГЁЂЫбЫївГЁЂЯъЧщвГЁЂПЭЗўвГЕШЁЃ
ЧвЮЂаХаЁГЬађЭЈЙ§ЗЂЫЭrequestЧыЧѓИјКѓЖЫ,КѓЖЫЯьгІРДздЮЂаХаЁГЬађЕФrequestЧыЧѓВЂЗЕЛиЦфЯрЙиЪ§Он
1.4.2 ЮЂаХаЁГЬађНчУцЩшМЦ
ЦфжївГЁЂЙуГЁвГЁЂПМбааХЯЂвГЁЂЫбЫївГЁЂЯъЧщвГЁЂПЭЗўвГИїНчУцЕФзїгУШчЯТ:
(1). жївГжївЊИКд№ЯдЪОзюНќЗЂВМЕФЮхЬѕЪЇЮяеаСьгыбАЮяЦєЪТ,ЕуЛїМДПЩЬјзЊЕНЯргІЕФЯъЧщвГЁЃ
(2). ЙуГЁвГПЩвдЗжБ№ЯдЪОЪЇЮяеаСьЁЂбАЮяЦєЪТЁЂвдМАаЃдАзЪбЖВЂжЇГжЯТРЪНЫЂаТ,ВЂЧвЮЊЦфЬсЙЉЯргІЕФЫбЫїЗўЮё,ЭЌЪБжЇГжЬјзЊЕНЯргІЕФЯъЧщвГЁЃ
(3). ПМбааХЯЂвГжївЊЪЧИКд№ЖдЗЂЫЭЧыЧѓЛёШЁexcelИёЪНЯргІЕФПМбааХЯЂЁЃ
(4). ЫбЫївГжЇГжЖдЪЇЮяеаСьЁЂбАЮяЦєЪТЁЂвдМАаЃдАзЪбЖНјааФЃК§ЪНЫбЫї,ВЂЧвжЇГжЕуЛїЬјзЊЯъЧщвГЁЃ
(5). ЯъЧщвГжЇГжЖдЪЇЮяеаСьЁЂбАЮяЦєЪТЁЂвдМАаЃдАзЪбЖЯъЯИаХЯЂЕФЯдЪОЁЃ
(6). ПЭЗўвГжївЊИКд№гыПЭЗўЕФЖдЛА
1.4 ЯЕЭГИХвЊ
1.4.1 ЯЕЭГзщГЩВПЗжЗжЮі
ЭМ 3.1 ЯЕЭГзмЬхМмЙЙЭМ
1.4.1ЯЕЭГдЫааСїГЬ
ЖдЯЕЭГЙЄзїСїГЬНјааШчЯТЗжЮі:
-
ЪзЯШDjangoКѓЖЫЭЈЙ§ORMЖдЯѓЙиЯЕгГЩфаЮГЩЯьгІЕФЪ§ОнПтБэ
-
ScrapyХРГцЭЈЙ§СЌНгЯрЖдгІЕФЪ§ОнПт,ЭљБэжаЬэМгЯьгІЕФЪ§Он
-
DjangoКѓЖЫЕФAdminУцАхПЩвдЖдscrapyХРГцЬэМгЕФЪ§ОнНјааЙмРэ
-
ЧАЖЫЮЂаХаЁГЬађЭЈЙ§ЗЂЫЭrequestЧыЧѓИјDjangoКѓЖЫ,DjangoКѓЖЫЯьгІРДздЧАЖЫЕФЧыЧѓ,ВЂЛёЕУЦфаЏДјЕФЯрЙиВЮЪ§,ЯђЪ§ОнПтжаЧыЧѓЯрЙиаХЯЂ
-
Ъ§ОнПтНгЪмРДздКѓЖЫЕФЧыЧѓ,ВЂЗЕЛиЯьгІЕФЪ§Он
-
DjangoКѓЖЫНгЪмРДздЪ§ОнПтЕФЪ§Он,ВЂзЊЛЏЮЊЯргІЕФИёЪНЗЂЫЭИјЮЂаХаЁГЬађ
-
ЮЂаХаЁГЬађЕУЕНЯргІЕФЪ§ОнКѓ,фжШОвГУцВЂЯдЪОЯрЙиаХЯЂ
ЕкЖўеТ ЯЕЭГЕФЯъЯИЩшМЦгыЪЕЯж
дкЩЯвЛеТЯЕЭГИХвЊЩшМЦЕФЛљДЁЩЯ,БОеТжївЊНщЩмЯЕЭГЕФЯъЯИЩшМЦ,вдМАЪЕЯждРэ,жївЊДгдѕУДЩшМЦХРГцзжЖЮЕНORMЕФЖдЯѓЙиЯЕгГЩф,ДгХРГцзжЖЮЕФЬсШЁЕНЪ§ОнПтЕФДцДЂЁЃ
2.1 scrapyХРГцЯъЯИЩшМЦ
2.1.1 ЭјвГХРШЁВпТдЕФЩшМЦ
ЭјТчХРГцЕФжївЊШЮЮёЪЧдкЛЅСЊЭјжаХРаа,ЯТдиФПБъЭјвГЕФФкШнЁЃБОЮФжївЊВЩгУЩюЖШгХЯШЫбЫї[28]зїЮЊХРГцХРШЁВпТдЁЃХРГцЪзЯШДгspiderФПТМЯТЛёЕУГѕЪМЕФURLЕижЗЁЃЦфжаБОЮФЮвУЧвдбаеаЭјЫЖЪПФПТМ(https://yz.chsi.com.cn/zsml/queryAction.do)ЮЊР§РДЗжЮіПЩжЊ,фЏРРЦїЖдЭјвГЗЂЫЭpostЧыЧѓВЂЧваЏДјВЮЪ§ШчЯТ:
Бэ ЫФ.1баеаЭјЫЖЪПФПТМpostЧыЧѓЗЂЫЭЪ§ОнЗжЮі
| БэЕЅЪ§Он | КЌвх | ЪОР§ | ЪОР§КЌвх |
|---|---|---|---|
| ssdm | ЪЁЪаДњТы | 43 | КўФЯЪЁ |
| dwmc | ЕЅЮЛУћГЦ | ФЯЛЊДѓбЇ | ФЯЛЊДѓбЇ |
| mldm | УХРрДњТы | 08 | ЙЄбЇ |
| yjxkdm | баОПбЇПЦДњТы | 0835 | ШэМўЙЄГЬ |
| zymc | зЈвЕУћГЦ | ШэМўЙЄГЬ | ШэМўЙЄГЬ |
| xxfs | бЇЯАЗНЪН | 1 | ШЋШежЦ |
Бэ 4.1 баеаЭјЫЖЪПФПТМpostЧыЧѓЗЂЫЭЪ§ОнЗжЮі
ЗжЮіЭјвГЕФelementНсЙЙЁЃЬсШЁЯрЙизжЖЮВЂДцШыitemжаЁЃЭЌЪБХРГцЭЈЙ§ХРШЁЛёШЁЭјвГЕФЯъЧщвГвдМАЯТвЛвГЕФСДНг,НјааЯъЧщвГЕФХРШЁвдМАЗвГВйзїЁЃ

ЭМ ЫФ.1баеаЭјбЇаЃвГЕФhref
ЭМ4.1баеаЭјбЇаЃвГЕФhref
ШчЭМ4.1ЫљЪОЮвУЧПЩвдЭЈЙ§РћгУresponse.xpath(ЁЎ//tbody/tr//a/@hrefЁЏ)РДЖдОпЬхбЇаЃЕФURLЕижЗНјааЬсШЁЁЃЭЌРэЮвУЧПЩвдЖдЯТвЛвГЕФВйзїНјааЗжЮіПЩвдЕУжЊжЛашвЊаЏДјвЛИіpagenoВЮЪ§МДПЩЭъГЩЗвГВйзїЁЃ
ЭЈЙ§зЅШЁЭјвГаХЯЂКѓ,ЮвЕФЕУЕНСЫЯрЙизжЖЮ,ВЂЮвУЧвЊЗХШыЪ§ОнПтжаНјааГжОУЛЏДцДЂ,етРяБОЮФЮвУЧв§Шыmysql,ЪзЯШЮвУЧдкitempipelines.pyжаЛёЕУЮвУЧЕФitem,ШЛКѓЭЈЙ§open_spiderЖдЪ§ОнНјааСЌНг,етРяБОЮФСЌНгЪ§ОнПтбЁгУЕФЪЧpymysqlЁЃШЛКѓдкprocess_itemжаЭЈЙ§БраДsqlгяОфНЋЪ§ОнБЃДцгкЪ§ОнПтжа,зюКѓЭЈЙ§close_spiderРДЙиБегкЪ§ОнПтЕФСЌНгЁЃ
2.1.2 ЖЏЬЌЭјвГЕФДІРэ
ФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЭјеОжївЊВЩгУjsЖЏЬЌфжШОРДЗРжЙЖёвтХРГцЁЃ
ScrapyЪЧЯждкЪЎЗжСїааЕФХРГцПђМм,ЕЋЪЧЫћгаЦфВЛзужЎДІ,МДScrapyУЛгаJavascript engine, вђДЫЫќЮоЗЈХРШЁJavaScriptЩњГЩЕФЖЏЬЌЭјвГ,жЛФмХРШЁОВЬЌЭјвГ,ЖјдкЯжДњДѓВПЗжЭјвГЖМЛсВЩгУJavaScriptРДЗсИЛЭјвГЕФЙІФмЁЃЫљвд,етЮовЩScrapyЕФвХКЖжЎДІЁЃЫљвдБОЮФОіЖЈЪЙгУscrapy-splashФЃПщЁЃSplashЪЧвЛИіОЭЪЧвЛИіJavascriptфжШОЗўЮёЁЃЫќЪЧвЛИіЪЕЯжСЫHTTP APIЕФЧсСПМЖфЏРРЦї,SplashЪЧгУPythonЪЕЯжЕФ,ЭЌЪБЪЙгУTwistedКЭQT[29]ЁЃTwisted(QT)гУРДШУЗўЮёОпгавьВНДІРэФмСІ,вдЗЂЛгwebkitЕФВЂЗЂФмСІЁЃЦфЪЕscrapyвВЪЧвЛИіЛљгкTwistedЕФЭјТчХРГцПђМмЁЃСНепНсКЯИќФмЗЂЛгЦфTwistedЕФвьВНФмСІ
ЮЊСЫдкscrapyжав§гУSplashЗўЮё,ЮвУЧЪзЯШвЊдкdockerЩЯАВзАsplash,ВЂЧвПЊЦєsplashЗўЮёЁЃШЛКѓдкжеЖЫжажДааpip install scrapy-splash,ЮЊЦфАВзАжЇГжsplashЕФЕкШ§ЗНПтЁЃзюКѓдкsettings.pyжаЮЊХфжУsplashЕФURLЕижЗВЂЦфПЊЦєЯТдижаМфМўгыХРГцжаМфМўЁЃ
SPLASH_URL = ЁЎhttp://192.168.59.103:8050ЁЏ
SPIDER_MIDDLEWARES = {
ЁЎscrapy_splash.SplashDeduplicateArgsMiddlewareЁЏ: 100,
}
DOWNLOADER_MIDDLEWARES = {
ЁЎscrapy_splash.SplashCookiesMiddlewareЁЏ: 723,
ЁЎscrapy_splash.SplashMiddlewareЁЏ: 725,
ЁЎscrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddlewareЁЏ: 810,
}
ЦфжаscrapyПЩвдЭЈЙ§ЕїгУscrapy-splashЬсЙЉЕФSplashRequestРДЪЕЯжЖдЭјвГЕФЖЏЬЌфжШОЁЃ
SplashRequest(
? url=url,
? callback=self.parse,
? args={ЁАwaitЁБ: 10},
? endpoint=ЁАrender.htmlЁБ,
? )
дкФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЭјеОЪЇЮяеаСьФЃПщвбОЮоЗЈЭЈЙ§ЗжЮіhrefЛёШЁЯТвЛвГЕФURLЕижЗ
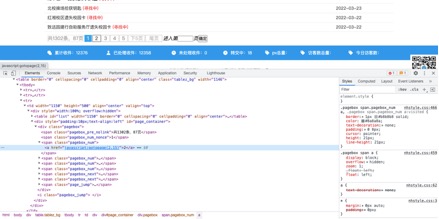
ЭМ ЫФ.2ФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЭјеОЪЇЮяеаСьФЃПщЯТвЛвГЕФhtmlНсЙЙ
ЭМ 4.2ФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЭјеОЪЇЮяеаСьФЃПщЯТвЛвГЕФhtmlНсЙЙ
ПЊЗЂепЮвУЧПЩвдЭЈЙ§БраДLuaНХБОЪЕЯжЖдфЏРРЦїЕФФЃФтЕуЛїВйзї
next_page_lua_script = ЁАЁБ"
? function main(splash, args)
? assert(splash:go(args.url))
? assert(splash:wait(0.5))
? splash:runjs(args.script)
? assert(splash:wait(0.5))
? return splash:html()
? end
? ЁАЁБ"
2.1.3 javaScriptФцЯђЗжЮі
ЕБХРГцЮвУЧзЅШЁЭјвГЖЫЪ§ОнЪБ,ОГЃБЛМгУмВЮЪ§ЁЂМгУмЪ§ОнЫљРЇШХ,ШчКЮПьЫйЖЈЮЛетаЉМгНтУмКЏЪ§,гШЮЊживЊЁЃЕБЮвУЧНјШыЪЇЮяеаСьЕФЯъЧщвГЪБ,ОЭЛсЗЂЯжгааЉЬћзгЬсЙЉСЫЯТдиИННќЕФЙІФмЁЃЭЌбљЮФМўЕФURLЕижЗЪЧгУJavaScriptЬсЙЉЕФЁЃвЛАугаСНжжЗНЪНРДЪЕЯжЮФМўЕФЯТди,ЦфжавЛжжЪЧЭЈЙ§здЖЏЛЏВтЪдНХБОseleniumРДФЃФтфЏРРЦїВйзїЪЕЯжЁЃДЫВйзїЭљЭљашвЊЗћКЯфЏРРЦїАцБОЕФwebdriverРДЧ§ЖЏ,ЖјЧвЮЊБЃГжадЛсЛАВйзї,ЫфШЛЪЕЯжЦ№РДБШНЯМђЕЅ,ЕЋЪЧЭљЭљаЇТЪБШНЯЕЭЁЃетРяБОЮФбЁгУJavaScriptФцЯђЗжЮіРДЛёШЁЕФЮФМўЫљдкЕФURLЕижЗ[30]ЁЃ
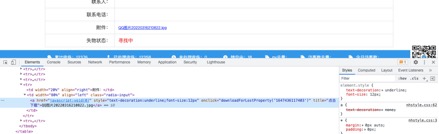
ЭМ ЫФ.3ФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЭјеОЪЇЮяеаСьФЃПщЯъЧщвГИНМўЕФhtmlНсЙЙ
ЭМ 4.3ФЯЛЊДѓбЇбєЙтНЬг§ЗўЮёДѓЬќЭјеОЪЇЮяеаСьФЃПщЯъЧщвГИНМўЕФhtmlНсЙЙ
ЕЋЪЧЕБЭъГЩJavaScriptФцЯђВйзїЪБ,ЛёЕУЕНЕФЮФМўЕФURLЪЧОЙ§МгУмДІРэЕФЖјЧвЪЧвЛДЮадЪЙгУЕФЁЃетРяБОЮФЮвУЧв§ШыАЂРядЦЕФossЖдЯѓДцДЂММЪѕ,БОЮФЪЙгУе§дђБэДяЪНРДЖдЮФМўжжРрНјааХаЖЯВЂЛёШЁЬћзгЕФЮЈвЛID,ЕБИННќЮЊЭМЦЌЪБ,НЋЮФМўжиаТУќУћЮЊЬћзгЕФID,ВЂНЋНЋЮФМўЯТдизЊДцжСАЂРядЦжаЪЕЯжЮФМўЕФГжОУЛЏДцДЂЁЃЭЌЪБАЂРядЦвВЮЊПЊЗЂепЮвУЧЬсЙЉСЫЯргІЕФURLРДЕижЗРДЗУЮЪЯргІЮвУЧЕФЮФМўЁЃ
2.1.4 User-AgentЮБзАгыIPДњРэ
КмЖрЭјеОЖМгаЯргІЕФЗДХРГцДыЪЉ,БОЮФжївЊВЩгУЫцЛњUser-AgentРДЪЕЯжUser-AgentЮБзА,вђЮЊscrapyБОЩэЬсЙЉЕФUser-AgentЮЊЙЬЖЈЕФИёЪНКмШнвзБЛЭјеОЪЖБ№ЮЊЖёвтХРГц,ЪзЯШБОЮФЯШНЈСЂСЫвЛИіUser-AgentГи,ШЛКѓРћгУpythonПтrandomдкЦфжаНјааЫцЛњбЁдё,ДгЖјЪЕЯжЫцЛњUser-AgentЮБзАЁЃЭЌбљЕФЕБвЛИіIPЖдЭјеОЧыЧѓЖрДЮЕФЪБКђ,ЭјеОвВЛсШЯЮЊетЪЧвЛИіЖёвтХРГц,ДгЖјЖдДЫIPЪЕЯжЗтНћВйзїЁЃБОЮФв§гУПьДњРэЕФЫэЕРIPДњРэ,ДгЖјЪЕЯжIPДњРэ,ЪЙЕУУПДЮЗЂЫЭЧыЧѓЪЧИФБфIPЁЃВЂЧвдкscrapyЕФsettings.pyжаПЊЦєЯргІЕФжаМфМўЁЃ
1.1
2.2 DjangoКѓЖЫЯъЯИЩшМЦ
2.2.1 ORMЖдЯѓЙиЯЕгГЩфЕФЩшМЦ
гЩгкDjangoЮЊПЊЗЂепЬсЙЉСЫmodels.ModelЕФpythonРрЕНЪ§ОнПтЕФгГЩфВйзїЫљвдЮвУЧжЛашвЊЭъГЩЖдmodels.ModelЕФpythonРрЪЕЯжМДПЩЁЃБОЮФжївЊЪЕЯжСЫвдЯТЮхИіФЃаЭРр,ВЂЭъГЩСЫЖдЪ§ОнПтгГЩфВйзїаЮГЩСЫЯргІЕФЪ§ОнПтБэЁЃ(етРяВЛвЊгУБэРДБэЪО,гУERЭМРДБэЪО)
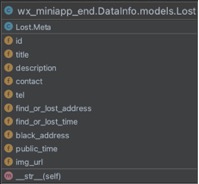
ЭМ ЫФ.4LostРрЭМ
ЭМ ЫФ.5Lost ERЭМ
ЭМ ЫФ.6FoundРрЭМ
ЭМ ЫФ.7Found ERЭМ
ЭМ ЫФ.8YZWРрЭМ
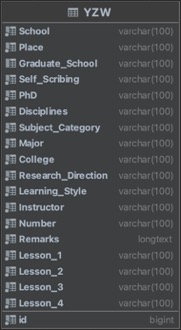
ЭМ ЫФ.9YZW ERЭМ
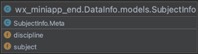
ЭМ ЫФ.10SubjectInfoРрЭМ
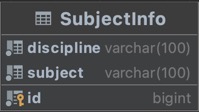
ЭМ ЫФ.11Subject ERЭМ
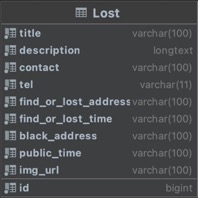
| Ъєад | Ъ§ОнРраЭ | зюДѓГЄЖШ | ЪЧЗёЮЊПе | гГЩфзжЖЮ | гГЩфЪ§ОнРраЭ | БИзЂ |
|---|---|---|---|---|---|---|
| id | BigIntegerField | Зё | id | Bigint | жїМќ,ЬћзгID | |
| title | CharField | 100 | Зё | title | Varchar(100) | БъЬт |
| description | TextField | Зё | description | Text | УшЪі | |
| contact | CharField | 100 | Зё | contact | Varchar(100) | СЊЯЕШЫ |
| tel | CharField | 11 | Зё | tel | Varchar(11) | СЊЯЕЗНЪН |
| find_or_lost_address | CharField | 100 | Зё | find_or_lost_address | Varchar(100) | вХЪЇЕиЕу |
| find_or_lost_time | CharField | 100 | Зё | find_or_lost_time | Varchar(100) | вХЪЇЪБМф |
| black_address | CharField | 100 | Зё | black_address | Varchar(100) | еаСьЕиЕу |
| public_time | CharField | 100 | Зё | public_time | Varchar(100) | ЗЂВМШеЧА |
| img_url | CharField | 100 | Зё | img_url | Varchar(100) | ЭМЦЌURL |
Бэ 4.2 LostФЃаЭРргыLostБэ
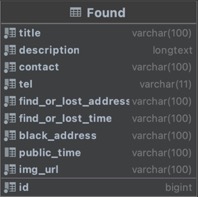
| Ъєад | Ъ§ОнРраЭ | зюДѓГЄЖШ | ЪЧЗёЮЊПе | гГЩфзжЖЮ | гГЩфЪ§ОнРраЭ | БИзЂ |
|---|---|---|---|---|---|---|
| id | BigIntegerField | Зё | id | Bigint | жїМќ,ЬћзгID | |
| title | CharField | 100 | Зё | title | Varchar(100) | БъЬт |
| description | TextField | Зё | description | Text | УшЪі | |
| contact | CharField | 100 | Зё | contact | Varchar(100) | СЊЯЕШЫ |
| tel | CharField | 11 | Зё | tel | Varchar(11) | СЊЯЕЗНЪН |
| find_or_lost_address | CharField | 100 | Зё | find_or_lost_address | Varchar(100) | ЪАШЁЕиЕу |
| find_or_lost_time | CharField | 100 | Зё | find_or_lost_time | Varchar(100) | ЪАШЁЪБМф |
| black_address | CharField | 100 | Зё | black_address | Varchar(100) | еаСьЕиЕу |
| public_time | CharField | 100 | Зё | public_time | Varchar(100) | ЗЂВМШеЧА |
| img_url | CharField | 100 | Зё | img_url | Varchar(100) | ЭМЦЌURL |
Бэ 4.2 FoundФЃаЭРргыFoundБэ
| Ъєад | Ъ§ОнРраЭ | зюДѓГЄЖШ | ЪЧЗёЮЊПе | гГЩфзжЖЮ | гГЩфЪ§ОнРраЭ | БИзЂ |
|---|---|---|---|---|---|---|
| id | IntegerField | Зё | id | int | жїМќ,ЬћзгID | |
| title | CharField | 100 | Зё | title | Varchar(100) | БъЬт |
| kind | CharField | 100 | Зё | kind | Varchar(100) | жжРр |
| department | CharField | 100 | Зё | department | Varchar(100) | ВПУХ |
| public_time | CharField | 100 | Зё | pulic_time | Varchar(100) | ЗЂВМЪБМф |
| content | TextField | Зё | content | text | ФкШн | |
| reply | TextField | Зё | reply | Varchar(100) | ЛиИД | |
| identity | CharField | 100 | Зё | identity | Varchar(100) | ЩэЗн |
| img_url | CharField | 100 | Зё | img_url | Varchar(100) | ЭМЦЌURL |
Бэ 4.3 InfoФЃаЭРргыInfoБэ
| Ъєад | Ъ§ОнРраЭ | зюДѓГЄЖШ | ЪЧЗёЮЊПе | гГЩфзжЖЮ | гГЩфЪ§ОнРраЭ | БИзЂ |
|---|---|---|---|---|---|---|
| id | BigIntegerField | Зё | id | bigint | жїМќ | |
| discipline | CharField | 100 | Зё | discipline | Varchar(100) | бЇПЦУХРр |
| subject | CharField | 100 | Зё | subject | Varchar(100) | бЇПЦРрБ№ |
Бэ 4.3 SubjectInfoФЃаЭРргыSubject InfoБэ
| Ъєад | Ъ§ОнРраЭ | зюДѓГЄЖШ | ЪЧЗёЮЊПе | гГЩфзжЖЮ | гГЩфЪ§ОнРраЭ | БИзЂ |
|---|---|---|---|---|---|---|
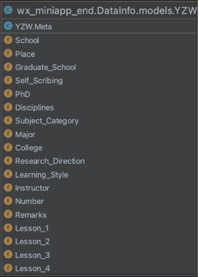
| id | BigIntegerField | Зё | id | int | жїМќ | |
| School | CharField | 100 | Зё | School | Varchar(100) | бЇаЃ |
| Place | CharField | 100 | Зё | Place | Varchar(100) | ЫљдкЕи |
| Graduate_School | CharField | 100 | Зё | Graduate_School | Varchar(100) | баОПЩњдК |
| Self_Scribing | CharField | 100 | Зё | Self_Scribing | Varchar(100) | здЛЎЯп |
| PhD | CharField | 100 | Зё | PhD | Varchar(100) | ВЉЪПЕу |
| Disciplines | CharField | 100 | Зё | Disciplines | Varchar(100) | бЇПЦУХРр |
| Subject_Category | CharField | 100 | Зё | Subject_Category | Varchar(100) | бЇПЦРрБ№ |
| Major | CharField | 100 | Зё | Major | Varchar(100) | зЈвЕ |
| College | CharField | 100 | Зё | College | Varchar(100) | бЇдК |
| Research_Direction | CharField | 100 | Зё | Research_Direction | Varchar(100) | баОПЗНЯђ |
| Learning_Style | CharField | 100 | Зё | Learning_Style | Varchar(100) | бЇЯАЗНЪН |
| Instructor | CharField | 100 | Зё | Instructor | Varchar(100) | ЕМЪІ |
| Number | CharField | 100 | Зё | Number | Varchar(100) | еаЩњШЫЪ§ |
| Remarks | TextField | Зё | Remarks | Text | БИзЂ | |
| Lesson1 | CharField | 100 | Зё | Lesson1 | Varchar(100) | ПЦФПвЛ |
| Lesson2 | CharField | 100 | Зё | Lesson2 | Varchar(100) | ПЦФПЖў |
| Lesson3 | CharField | 100 | Зё | Lesson3 | Varchar(100) | ПЦФПШ§ |
| Lesson4 | CharField | 100 | Зё | Lesson4 | Varchar(100) | ПЦФПЫФ |
Бэ 4.4 YZWФЃаЭРргыYZWБэ
ЕБУПДЮЖдЪ§ОнПтНјаааоИФЪБ,ЖМжЛашвЊЖдDjangoжаЕФФЃаЭРрНјааВйзї,ШЛКѓжДааЧЈвЦВйзїМДПЩЁЃЧЈвЦЪЧDjango НЋФуЖдФЃаЭЕФаоИФ(Р§ШчдіМгвЛИізжЖЮ,ЩОГ§вЛИіФЃаЭ)гІгУжСЪ§ОнПтМмЙЙжаЕФЗНЪНЁЃЫќУЧБЛЩшМЦЕФОЁПЩФмздЖЏЛЏЁЃ
2.2.2 DjangoЪ§ОнНгПкЕФЩшМЦ
DjangoЭЈЙ§дк Django ПђМмжа,ЪгЭМЪЧНгЪе Web ЧыЧѓВЂЗЕЛи Web ЯьгІЕФ Python КЏЪ§ЛђРрЁЃЯьгІПЩвдЪЧМђЕЅЕФ HTTP ЯьгІЁЂHTML ФЃАхЯьгІЛђНЋгУЛЇжиЖЈЯђЕНСэвЛИівГУцЕФ HTTP жиЖЈЯђЯьгІЁЃЪгЭМАќКЌНЋаХЯЂзїЮЊЯьгІвдШЮКЮаЮЪНЗЕЛиИјгУЛЇЫљашЕФТпМЁЃзїЮЊзюМбЪЕМљ,ДІРэЪгЭМЕФТпМБЃДцдкviews.pyЕФDjango гІгУГЬађЕФЮФМўжаЁЃ
БОЮФжївЊВЩгУJsonзїЮЊЗЕЛиаХЯЂ,ЦфЖЈвхЕФЪгЭМРргыЯргІЕФURLНјааАѓЖЈ,ПЩвдЭЈЙ§ЗУЮЪЯргІЕФURLРДЗЂЫЭЧыЧѓЁЃ
Бэ ЫФ.2 DjangoКѓЖЫЗЕЛиаХЯЂгыURLАѓЖЈЧщПі
| URLЕижЗ | аЏДјВЮЪ§ | АѓЖЈЪгЭМ | ЗЕЛиРраЭ | УшЪі |
|---|---|---|---|---|
| data/yzw | n:ЧыЧѓвГТы yjxkmd:баОПбЇПЦДњТы | getYZWData | json | вдУПвГ25ЬѕаХЯЂЕФИёЪНЗЕЛиЕкnвГПМбааХЯЂ |
| data/lost | page:ЧыЧѓвГТы | getLostData | json | вдУПвГ5ЬѕаХЯЂЕФИёЪНАДзюаТЪБМфДЮађЗЕЛибАЮяЦєЪТаХЯЂ |
| data/found | page:ЧыЧѓвГТы | getFoundData | json | вдУПвГ5ЬѕаХЯЂЕФИёЪНАДзюаТЪБМфДЮађЗЕЛиЪЇЮяеаСьаХЯЂ |
| data/info | page:ЧыЧѓвГТы | getInfoData | json | вдУПвГ5ЬѕаХЯЂЕФИёЪНАДзюаТЪБМфДЮађЗЕЛиаЃдАзЪбЖаХЯЂ |
| data/lostdetail | id:Ьћзгid | getLostDetailInfo | json | ЗЕЛибАЮяЦєЪТОпЬхЬћзгаХЯЂ |
| data/founddetail | id:Ьћзгid | getfoundDetailInfo | json | ЗЕЛиЪЇЮяеаСьОпЬхЬћзгаХЯЂ |
| data/infodetail | id:Ьћзгid | getInfoDetailInfo | json | ЗЕЛиаЃдАзЪбЖОпЬхЬћзгаХЯЂ |
| data/subject | id:бЇПЦУХРрДњТы | getSubjectInfo | json | ЗЕЛибЇПЦУХРргыбЇПЦРрБ№ХфЖдаХЯЂ |
| data/subject/detail | mldm:бЇПЦУХРрДњТы yjxkdm:баОПбЇПЦДњТы | getYZWDetail | xlxs | ЗЕЛиОпЬхПМбааХЯЂ |
| search/lost | context:ЫбЫїФкШн | searchLost | json | ЗЕЛиЫбЫїЕНЕФбАЮяЦєЪТаХЯЂ |
| search/found | context:ЫбЫїФкШн | searchFound | json | ЗЕЛиЫбЫїЕНЕФЪЇЮяеаСьаХЯЂ |
| search/info | context:ЫбЫїФкШн | searchInfo | json | ЗЕЛиЫбЫїЕНЕФаЃдАзЪбЖаХЯЂ |
Бэ 4.5 DjangoКѓЖЫЗЕЛиаХЯЂгыURLАѓЖЈЧщПі
2.3 ЮЂаХаЁГЬађЯъЯИЩшМЦ
2.3.1 гУЛЇНчУцЩшМЦ
ЮЂаХаЁГЬађжївЊгЩШ§ВПЗжзщГЩЗжБ№ЪЧЪзвГЁЂЙуГЁвГвдМАПМбааХЯЂвГЁЃ
ЮЂаХаЁГЬађжївГжївЊгЩЫФВПЗжзщГЩЗжБ№ЮЊТжВЅЭМ,зюНќвХЪЇЁЂзюНќЪАШЁвдМАСЊЯЕПЭЗўЁЃЦфжазюНќвХЪЇгызюНќЪАШЁеЙЪОзюНќЮхЬѕаХЯЂВЂЧвЕуЛїОЭПЩвдЬјзЊЕНЯргІЕФЯъЧщвГЁЃ
ЙуГЁвГдђгЩЫбЫїРИ,TabБъЧЉвГвдМАЙіЖЏаХЯЂРИзщГЩЁЃTabвГЗжЮЊШ§ВПЗжЗжБ№ЮЊбАЮяЦєЪТЁЂЪЇЮяеаСьвдМАаЃдАзЪбЖ,ЕуЛїОЭПЩвддкШ§епжаЪЕЯжздгЩЧаЛЛЁЃЕуЛїбАЮяЦєЪТдђЯТБпЙіЖЏаХЯЂРИЯдЪОЕФЮЊбАЮяЦєЪТаХЯЂЧвЮЊЖЏЬЌМгдиЕФаЮЪНЪЕЯж,УПДЮЕБаХЯЂДЅЕзЪБ,ЮЂаХаЁГЬађЛсздЖЏМгдиГіКѓЮхЬѕаХЯЂЁЃЭЌЪБЕуЛїЫбЫїРИ,дђЛсЬјзЊНјШыЕНЫбЫївГ,ЫбЫїгыTabРИжабЁжаБъЧЉвЛжТЕФФкШн,ВЂЪЕЯжБфЪфШыБфЖЏЬЌМгди,ЭЌЪБЕуЛїЦфЫбЫїНсЙћОЭЛсЬјзЊНјШыЯъЧщвГ,ЯъЧщвГЯдЪОЯрЙиЕФаХЯЂвдМАЭМЦЌЁЃ
ПМбааХЯЂвГжївЊгЩСНИіЯТРПђзщГЩ,ЕквЛИіЮЊбЇПЦУХРр,ЕкЖўИідђЮЊбЇПЦРрБ№,ЦфжабЇПЦРрБ№ЕФЯдЪОгЩбЇПЦУХРрЫљОіЖЈ,ВЂжЇГжЯТдиЦфЮФМўЁЃ
2.3.2 ЭјТчЧыЧѓЩшМЦ
дкЮЂаХаЁГЬађЖЫ,УПвЛИіpageвГУцЛђепcomponentзщМўЖМгавЛИівдjsНсЮВЕФJavaScriptЮФМўРДПижЦвГУцЕФНЛЛЅ,JavaScriptПЩвдЪЙЕУЮЂаХаЁГЬађгЕгаЖЏЬЌЪННЛЛЅФмСІЁЃ

ЭМ ЫФ.12TabБъЧЉРИ
ЭМ4.4 TabБъЧЉРИ
ШчЩЯЭМ4.4ЫљЪО,TabБъЧЉПЩвдЪЕЯжШ§жжРрБ№ЕФздгЩЧаЛЛЁЃЭЌЪБЪЙЕУЯТЗНЙіЖЏаХЯЂРИЕФФкШнгыTabБъЧЉРИбЁжаФкШнБЃГжвЛжТ,ЦфжаУПвЛИіTabРИЕФБъЧЉвГЕФURLвВИїВЛЯрЭЌЁЃ
ЭЌЪБдкЮЂаХаЁГЬађжаЭЈЙ§ЕїгУwx.request(Object object)ЗУЮЪПЊЗЂепЬсЙЉЕФURLЕижЗДгЖјЪЕЯжЗУЮЪЗўЮёЦїЛёШЁЯрЙиЪ§ОнЕФФПЕФЁЃЭЌЪБИУAPIжЛжЇГжЖдjsonЮФМўЕФНтЮіЙЄзїЁЃЫљвдDjangoКѓЖЫжївЊЗЕЛиЕФЪ§ОнЮЊjsonЮФМўЁЃ
ЮЊСЫЪЕЯжЮФМўЕФЯТди,ЮЂаХЙйЗНЮЊЦфЩшМЦСЫвЛИіwx.downloadFile(Object object)APIНгПкЁЃЦфжївЊЙІФмЪЧЯТдиЮФМўзЪдДЕНБОЕиЁЃПЭЛЇЖЫжБНгЗЂЦ№вЛИі HTTPS GET ЧыЧѓ,ЗЕЛиЮФМўЕФБОЕиСйЪБТЗОЖ (БОЕиТЗОЖ),ЕЅДЮЯТдидЪаэЕФзюДѓЮФМўЮЊ 200MBЁЃгЩДЫЮвУЧПЩвдЭЈЙ§ЯргІЕФURLЗЂЫЭЯТдиЮФМўЕФЧыЧѓ,ВЂЧвНЋЮФМўБЃДцЕНБОЕиСйЪБТЗОЖжаЁЃШЛКѓЭЈЙ§wx.openDocument(Object object)APIРДДђПЊЯТдиЯТРДЕФЮФМўЁЃ
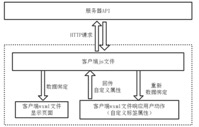
ЭМ ЫФ.13ЮЂаХаЁГЬађЭјТчЗжЮіЭМ
ЭМ4.5 ЮЂаХаЁГЬађЭјТчЗжЮіЭМ
ЕкШ§еТ ЯЕЭГзмЬхНсЙЙЗжЮівдМАдЫааЧщПі
дкЩЯвЛеТжаЮФБОвбОЯъЯИЕиНщЩмСЫЯЕЭГЕФЯъЯИЩшМЦгыЪЕЯжЫМТЗ,дкетвЛеТ,БОЮФзХжиНщЩмИїзгЯЕЭГЕФдЫааЧщПівдМАНсЙЙЁЃ
3.1 ХРГцЯЕЭГ
3.1.1 YZWХРГцдЫааНсЙћеЙЪО
жДааYZWХРГцПЩМћspiderЛсДгЭјвГЩЯзЅШЁЯргІЕФзжЖЮ,ВЂзЊЛЛЮЊsqlгяОфДцШыЪ§ОнПтжа
ЭМ Юх.1ХРГцYZWдЫааЧщПі
ЭМ5.1 ХРГцYZWдЫааЧщПі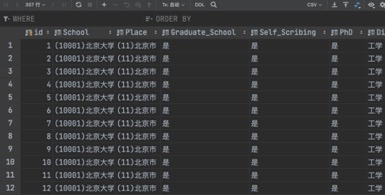
ЭМ Юх.2Ъ§ОнПтБэYZWНиЭМ
ЭМ5.2 Ъ§ОнПтБэYZWНиЭМ
3.1.2 Lost_and_foundХРГцдЫааНсЙћеЙЪО
дкdockerжаПЊЦєsplashЗўЮё,ВЂжДааLost_and_foundХРГцЁЃ
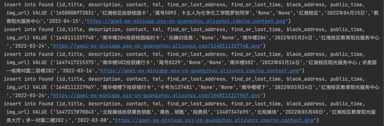
ЭМ Юх.3ХРГцLost_and_foundдЫааЧщПі
ЭМ5.3 ХРГцLost_and_foundдЫааЧщПі
ПЩМћХРГцЭЈЙ§splashЗўЮёЪЕЯжСЫЖдЖЏЬЌЭјвГЕФзжЖЮЬсШЁ,ЭЌЪБгІгУJavaScriptФцЯђЗжЮіЕФЗНЗЈГЩЙІЛёЕУСЫЭМЦЌЕФURLТЗОЖ,ШєВЛДцдкЭМЦЌдђЪЙгУФЌШЯЭМЦЌ,ВЂДцДЂдкАЂРядЦЕФossЖдЯѓДцДЂжа,гжЭЈЙ§жДааsqlгяОфАбЪ§ОнЗХШыmysqlжазіГжОУЛЏДцДЂЁЃ
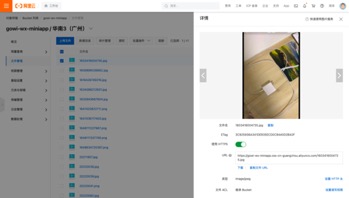
ЭМ Юх.4АЂРядЦossЖдЯѓДцДЂЧщПі
ЭМ5.4 АЂРядЦossЖдЯѓДцДЂЧщПі
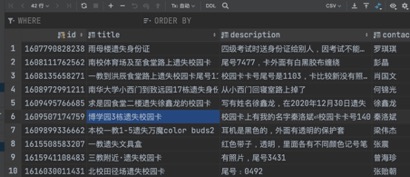
ЭМ Юх.5Ъ§ОнПтБэLostНиЭМ
ЭМ5.5 Ъ§ОнПтБэLostНиЭМ

ЭМ Юх.6ХРГцcomplaintдЫааЧщПі
ЭМ5.6 ХРГцcomplaintдЫааЧщПі
ЭМ Юх.7Ъ§ОнПтБэInfoНиЭМ
ЭМ5.7Ъ§ОнПтБэInfoНиЭМ
3.2 Django КѓЖЫЯЕЭГ
3.2.1 Django ORMЖдЯѓЙиЯЕгГЩф
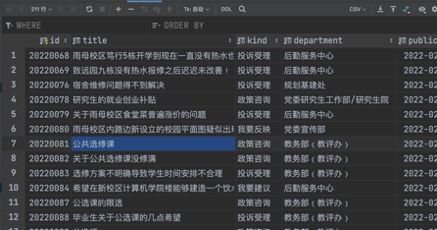
ЕБНјШыDjangoЯюФПФПТМЪБ,жДааpython3 manage.py makemigrationsгыpython3 manage.py migrateУќСю,ПЩжЊDjangoЭЈЙ§ЖдЯѓЙиЯЕгГЩфАбМЬГаздmodels.ModelЕФРргГЩфГЩЪ§ОнПтжаЕФБэЁЃ
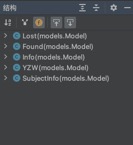
ЭМ Юх.8DjangoФЃаЭРр
ЭМ5.8 DjangoФЃаЭРр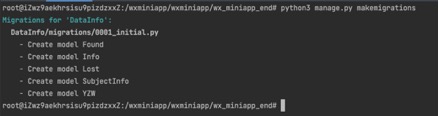
ЭМ Юх.9 DjangoЭЈЙ§ORMгГЩфЪ§ОнПт
ЭМ5.9 DjangoЭЈЙ§ORMгГЩфЪ§ОнПт
3.2.2 ЪгЭМЗУЮЪ
фЏРРЦїПЩвдЭЈЙ§ЪгЭМгыжЎАѓЖЈЕФurlРДЗУЮЪЯрЙиЪгЭМ,ВЂПЩвдЭЈЙ§аЏДјВЮЪ§ЕФаЮЪНРДЗУЮЪЪгЭМжаЕФЬиЖЈФкШн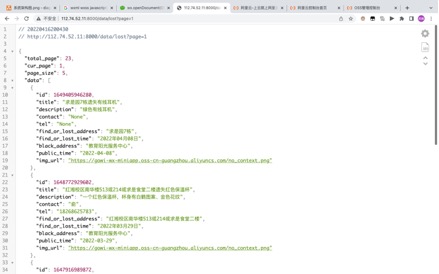
ЭМ Юх.10lostЪгЭМ
ЭМ5.10 lostЪгЭМ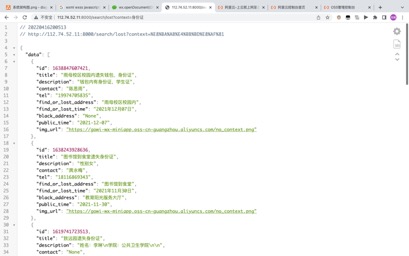
ЭМ Юх.11дкlostЪ§ОнПтжаЫбЫїЩэЗнжЄ
ЭМ5.11дкlostЪ§ОнПтжаЫбЫїЩэЗнжЄ
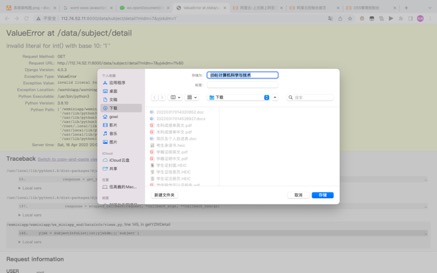
ЭМ Юх.12ЯТди0812МЦЫуЛњПЦбЇгыММЪѕ
ЭМ5.12 ЯТди0812МЦЫуЛњПЦбЇгыММЪѕ
3.2.3 adminУцАх
дкDjangoЯюФПФПТМЪБ,жДааpython3 manage.py createsuperuserУќСю,БуЛсзЂВсГЌМЖЙмРэдБгУЛЇЁЃОЭПЩвдЭЈЙ§URL IP:PORT/adminЗУЮЪadminУцАх,МДПЩвдЖдЪ§ОнПтжаЪ§ОнНјааПЩЪгЛЏВйзїЁЃ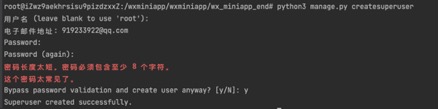
ЭМ Юх.13ДДНЈГЌМЖЙмРэдБ
ЭМ5.13 ДДНЈГЌМЖЙмРэдБ
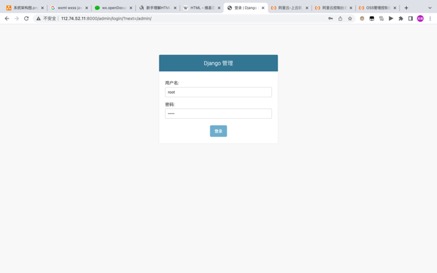
ЭМ Юх.14ГЌМЖЙмРэдБЕЧТМУцАх
ЭМ5.14 ГЌМЖЙмРэдБЕЧТМУцАх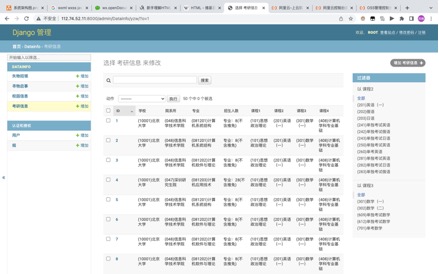
ЭМ Юх.15ВщПДYZWЪ§ОнПтаХЯЂ
ЭМ5.15 ВщПДYZWЪ§ОнПтаХЯЂ
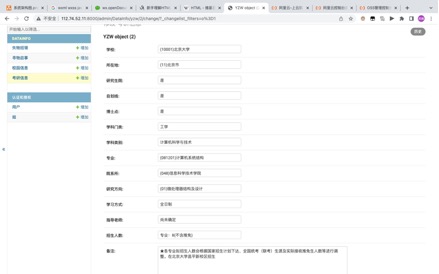
ЭМ Юх.16аоИФYZWЪ§ОнПтжаЕФаХЯЂ
ЭМ5.16 аоИФYZWЪ§ОнПтжаЕФаХЯЂ
3.3 ЮЂаХаЁГЬађ
3.3.1 ЮЂаХаЁГЬађНчУцеЙЪО
ЮЂаХаЁГЬађжївЊИКд№гыгУЛЇЕФНЛЛЅвдМАНчУцЯдЪОаЇЙћЁЃ

ЭМ Юх.17жївГ
ЭМ5.17жївГ

ЭМ Юх.18ЙуГЁвГбАЮяЦєЪТ
ЭМ5.20 ЙуГЁвГбАЮяЦєЪТ

ЭМ Юх.19ЙуГЁвГаЃдАзЪбЖ
ЭМ5.21 ЙуГЁвГаЃдАзЪбЖ

ЭМ Юх.20ЫбЫївГ
ЭМ5.21ЫбЫївГ

ЭМ Юх.21бАЮяЦєЪТЯъЧщвГ
ЭМ5.22бАЮяЦєЪТЯъЧщвГ

ЭМ Юх.22ЪЇЮяеаСьЯъЧщвГ
ЭМ5.23ЪЇЮяеаСьЯъЧщвГ

ЭМ аЃдАзЪбЖЯъЧщвГ
ЭМ5.24аЃдАзЪбЖЯъЧщвГ

ЭМ Юх.23бЇПЦУХРрЯТРПђ
ЭМ5.25бЇПЦУХРрЯТРПђ

ЭМ Юх.24бЇПЦРрБ№ЯТРПђ
ЭМ5.26бЇПЦРрБ№ЯТРПђ

ЭМ Юх.25ЮФМўЗжЯэ
ЭМ5.26ЮФМўЗжЯэ
ЭМ Юх.26СЊЯЕПЭЗў
ЭМ5.27СЊЯЕПЭЗў
ЕкЫФеТ аоИФЯюФПХфжУаХЯЂ
4.1 ХРГцЯюФПХфжУ
4.1.1 USC_Sunshine
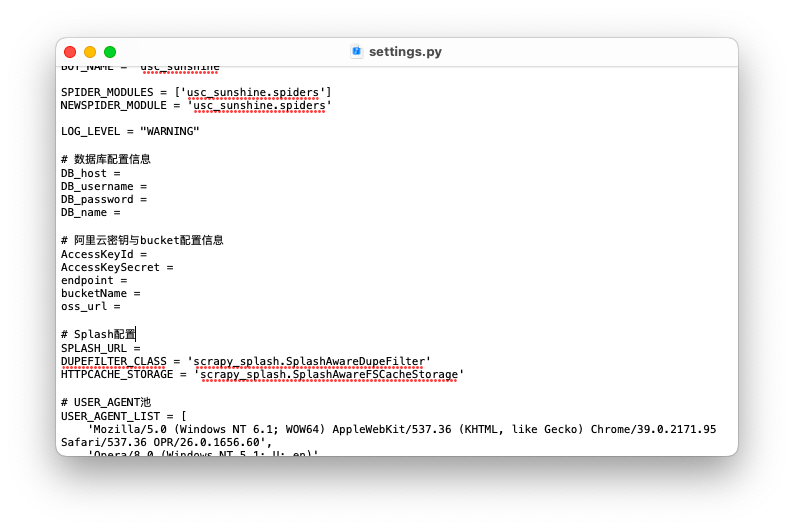
ЖдАЂРядЦOSSЁЂMysqlЪ§ОнПтгыsplashНјааХфжУ
4.1.2 YZW
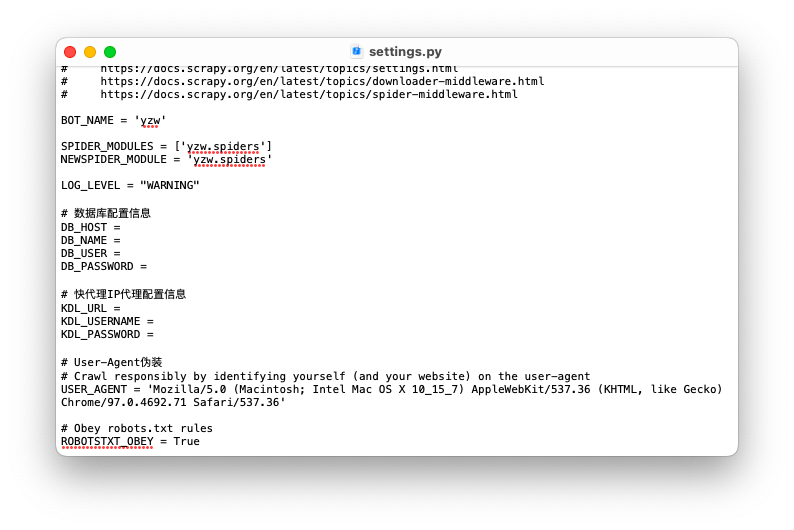
ЖдmysqlЪ§ОнПтвдМАПьДњРэНјааЯрЙиХфжУ
4.2 Django
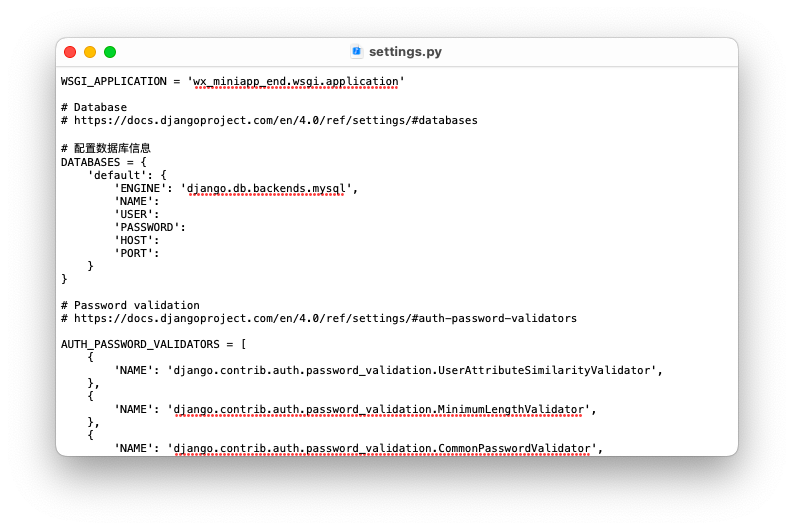
ЖдЪ§ОнПтНјааХфжУ
4.3 ЮЂаХаЁГЬађ
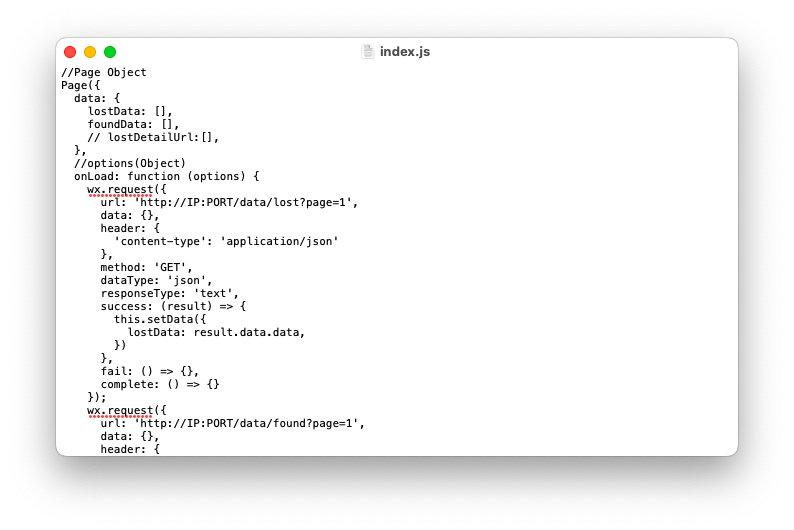
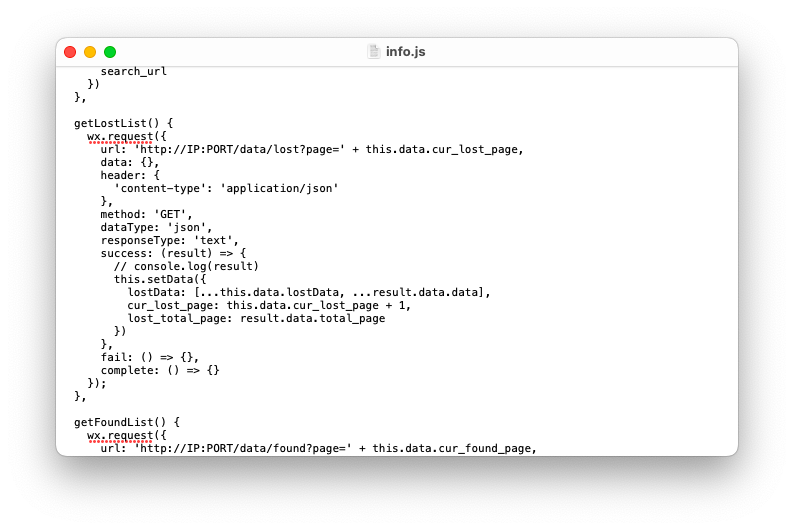
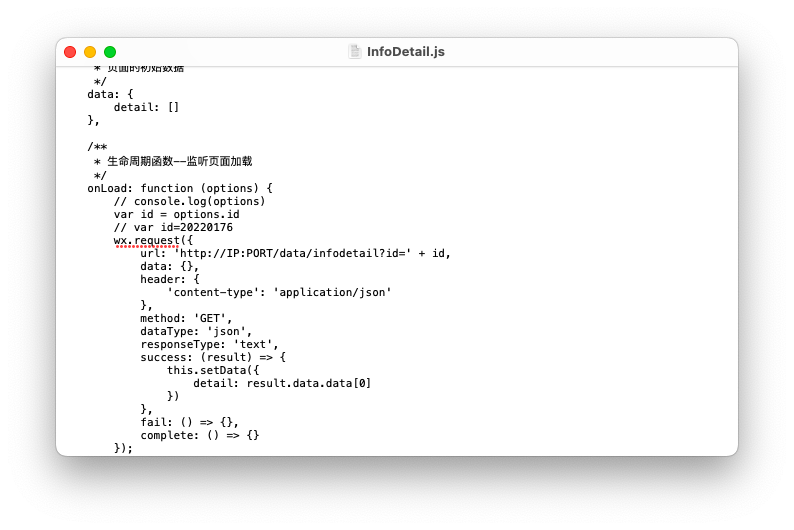
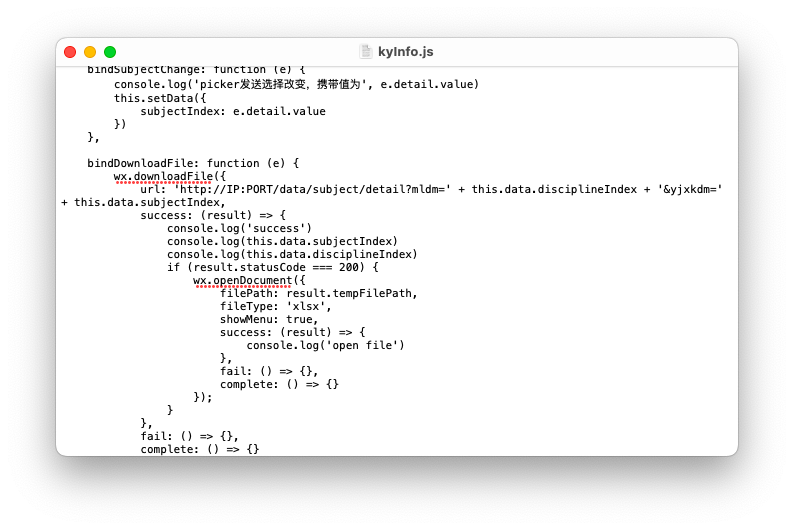
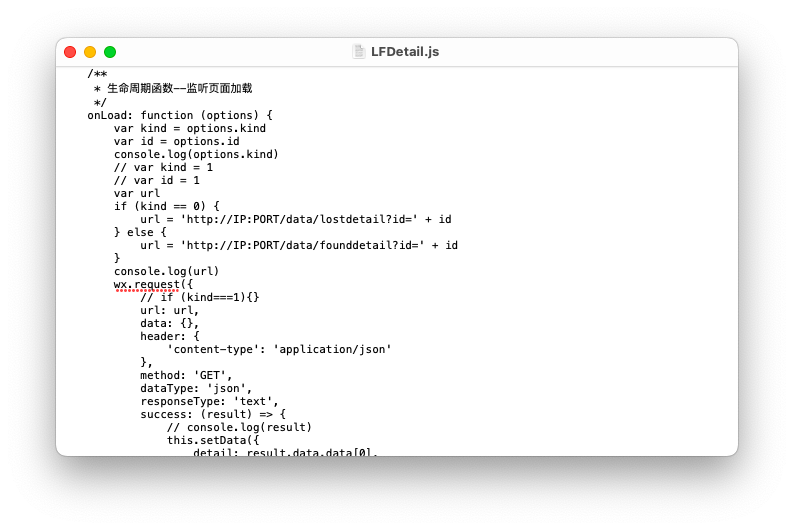
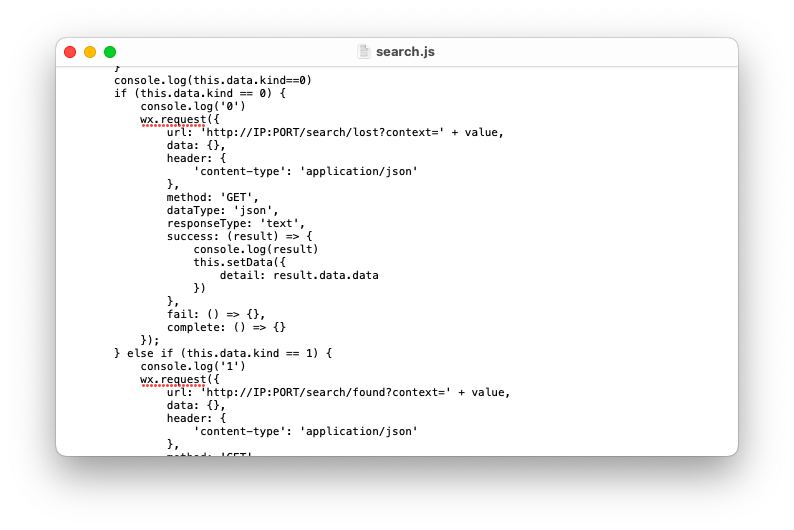
аоИФЮЂаХаЁГЬађjsЮФМўжаЖдIPЕижЗвдМАЖЫПкКХ
ЕкЮхеТ дЫааЯюФП
дкdockerжаЦєЖЏsplashЗўЮё
НјШы wx_miniapp_endФПТМжа,ВЂдкжеЖЫЪфШы
python3 manage.py makemigrations
python3 manage.py migrate
python3 manage.py createsuperuser
НјШыspider/yzwгыspider/usc_sunshineжадЫааstart.py
ЦєЖЏЮЂаХПЊЗЂепЙЄОп,БрвыДњТы

