�ڽӴ�Android��Ƶ������,½½�����Ŀ��˲��ٵ�����,���˵��ȱ��©����Щ�����������,Ȼ���������,��ôȷʵҲ���������Ƶ�����Ƶ������Ҫ���յļ��������Ƕ��ڳ�ѧ����˵,�����ڿ����в����ܶ��ϰ��Լ���֪ʶһ֪��⡣
����Ϊ��ϵͳ��,������,������ʵ����Ľ���Ƶ��������֪ʶչ�ָ����,ͬʱҲ��Ϊ�˶��Լ����ʱ����Ƶѧϰ���ܽ�,��������ƪ���¡�
�������ǽ���dz����,�Ը�����ʵ�ʿ����IJ���,�ô���Ķ�����Ƶ��һ����Ϊȫ����˽⡣
��˵һ�����⻰,����Ƶ����ҵ����һ�����߲���,���߲��ѵļ���ģ��,���������ѵ���ʵ���漰����Э��㷺,�漰���ĸ����ر��,������Щ���ǹ̶���(����˵���ǻ�ʱ���������),�������������Ҳ���Ը���ҵ�������������������Ҫʹ�õļ���������������ֵ��ѵ���Ҫ����Ҫ����ǿʶ������һ��˵,������Ҫ������������Ƶ�ļܹ���ϵ,֪������ҵ������̱ջ���������,���������ǽӴ�������ʱ��Ϳ���ר��ͻ�ơ�
һ����Ƶ�����ر�����֪ʶ
1.1 �����ı���
��������������������,һ�����ڷ��������嶼����
1.1.1 ����������������
����������������:
������ -> ���� -> �������� -> ����(�ռ�����)-> �����(��������) -> ��Ĥ(������ת������)
-> ��С��(�Ŵ���)
-> ����(����ת���ɵ��ź�) -> ������(���ݵ��ź�) -> ����(�γ�����)
�������������IJ�������,������ת�������,�����ֽ�����ת���ɵ��źš�
�˶����������Ĺ�����ʵ�������ڼ�����д�����Ƶ�Ĺ��̷dz�����
���������˶�����������,���ڼ������δ�����ƵҲ�нϴ�IJο���ֵ��
1.1.2 ��������Ҫ��
һ�������ͻ��������,��������Ҫ����Ƶ�ʡ�����Ͳ���
- Ƶ�ʴ������ĸߵ�
- ����������
- ���δ�����ɫ��
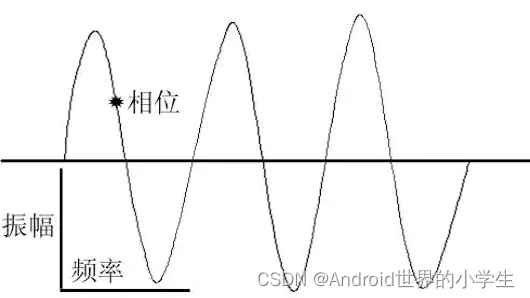
�������ǻ���,����ʱѧ������ʵ��,�������ö�����ʱ,�����ϵ���,��������������
��ô�������Ȼ����Ƶ�ʵ�,ͬʱ�����û����Ȳ�ͬ,�������������Ҳ��ͬ��

������ʵ������,ͬһʱ���,��Ȼ������ֻ��һ������Դ,һ�㶼�Ƕ����Դͬʱ����,��ô���ǵIJ�����ȻҲ�������������ֹ��ɵ������ڵ�ͼ�Ρ�
1.1.3 �ܽ�
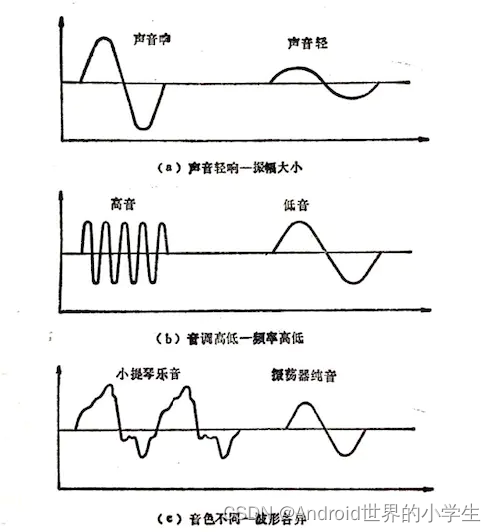
1.2 ��Ƶ���ֻ�
���潲�������ı�������������ʽ,��������ģ���ź�,�����ڼ���������ʹ洢���������ź�;������Ҫ��ģ���ź�ת�������źź���д洢,��һ����,��Ϊ��Ƶ���ֻ��������ڻ�����������������,�����Ⱦ���¼�ƺ�תΪ��������Ƶ,�ٴ��䵽�������ϵġ�
��Ƶ���ֻ��ij�����������������������(PCM,Pulse Code Modulation),�����õ�Ҳ�Ǹ÷�����
��Ҫ����:���� ������ ������
1.2.1 ������
ģ���źŵIJ��������⻬��,���Կ����������������,���ڴ洢�ռ����������,���ֱ��������,����Ҫ�Բ��εĵ���в����� ��������ÿ��һ��ʱ��ɼ�һ��ģ���źŵ�����,��ʱ���Ͻ�ģ���ź���ɢ���Ĺ��̡�
���ݲ�������(�ο�˹�بC��ũ��������),ֻ�е������ʸ��������ź����Ƶ�ʵ�2��ʱ,���ܰѲɼ��������ź�Ψһ�ػ�ԭ��ԭ��������;���Ҫ�����������Ƶ�ʸ�2�����ϵ�Ƶ�ʶ��������в���;�˶��ܹ�������Ƶ�ʷ�Χ��20Hz~20kHz,���Բ���Ƶ��һ��Ϊ 44.1kHz,�����Ϳ��Ա�֤���������ﵽ20kHzҲ�ܱ����ֻ�,�Ӷ�ʹ�þ������ֻ�����֮��,�˶������������������ᱻ���͡�
- ��������ʾÿ��ɼ�����������,44.1kHz���Ǵ���1������44100��;
1.2.2 ����
������ָ�ڷ������϶��źŽ������ֻ�,��ÿһ�������������ֵ���ֻ���
������16���صĶ������ź�����ʾ������һ������,��16��������ʾ�� ��Χ��[-32768,32767],����2^16=625536������ȡֵ,�������ģ�����Ƶ�ź��ڷ�����Ҳ��Ϊ��65536��;�����16bit��Ϊλ���(��������/������С):ʹ�ö��ٸ�������λ���洢һ�������������ֵ;λ���Խ��,��ʾ�����Խ��ȷ;
��������Ҫ��ע����λ���������,���Ǵ�ȡһ��������ʹ�õ�����λ����С�������������Ƶ��Ҳ���õ�,����洢һ��������ʹ�õ�λ�
1.2.3 ����
�����漰�˺ܶ��ָ�ʽ,ͨ��˵����Ƶ�����ݸ�ʽ����PCM(����������)���ݡ�PCM��Ҫ���¼�������:������ʽ(sampleFormat)�������� (sampleRate)��������(channel)��
������ʽ:��������λ��ȡ���С��ģʽ���������з�ʽ��;
�������16bit�����ϵ�λ�����в���,��ô�ͻ��漰��С��ģʽ��
- ���з�ʽ Packed:
����˫������Ƶ��˵,Packed��ʾ�������������ݽ����洢,��:LRLRLRLR �Ĵ洢��ʽ;

- ���з�ʽ Planar
��ʾ���������ֿ��洢,Ҳ����ƽ�̷ֿ�,��:LLLLRRRR �Ĵ洢��ʽ;
����:����������һ����������,˫����(������)���������������ݡ�
1.3 ��Ƶ�����ļ���
����������ʽ,����һ�����������������Ĵ�С,��Ϊ������(byteRate),��ָ��λʱ���ڴ�������ı�������;��λ��:����ÿ��(bps),����:ǧ����ÿ��(Kbps)���ױ���ÿ��(Mbps)�ȵȡ�
��CD��������:
λ���Ϊ16����(2�ֽ�),������Ϊ44.1kHZ,������Ϊ2,��Щ��Ϣ��������CD�����ʡ�����1����CD���ʵ�����,������Ϊ:
44100 * 16 * 2 = 1378.125 Kbps
һ����¼��ռ�õĴ洢�ռ�Ϊ:
1378.125 * 60 / 8 / 1024 = 10.09MB
����¼��
2.1 ʹ��AudioRecord¼��
��������Ļ������������Ķ������ʱ������ͻ��������,�Ǿ������Ǹ���ʵ�ʵ�ҵ������ȥ����������Ҫ����Ƶ������
2.2 AudioRecord����
�������ǿ���ʹ�� AudioRecord.Builder ������AudioRecord����
mAudioRecord = new AudioRecord.Builder()
.setAudioSource(MediaRecorder.AudioSource.VOICE_COMMUNICATION)
.setAudioFormat(audioFormat)
.setBufferSizeInBytes(Config.AUDIO_CONFIG.READ_AUDIO_BUFFER_SIZE_BY_BYTES)
.build();
2.2.1 setAudioSource
������������ñ�¼������ƵԴ����,һ����˵����¼��������һ��,��ô������ƵԴ����Ҳ��һ����
| Audio Source | Value | remark |
|---|---|---|
| AUDIO_SOURCE_INVALID | -1 | |
| DEFAULT | 0 | |
| MIC | 1 | ��˷� |
| VOICE_UPLINK | 2 | ¼��������Ƶ SystemApi |
| VOICE_DOWNLINK | 3 | ¼��������Ƶ SystemApi |
| VOICE_CALL | 4 | ¼������+������Ƶ SystemApi |
| CAMCORDER | 5 | ��˷���ƵԴ�ѵ���Ϊ��Ƶ¼��,����������ͷ��ͬ(�������) |
| VOICE_RECOGNITION | 6 | Ϊ����ʶ���������˷���ƵԴ |
| VOICE_COMMUNICATION | 7 | Ϊ����ͨ��(��VoIP)��г����˷���ƵԴ������,�������û����������Զ��������(�������)�� |
| REMOTE_SUBMIX | 8 | ���ڴ���ϵͳ��������Ƶ����Զ��,����������ų� AudioManager.STREAM_RING, AudioManager.STREAM_ALARM, and AudioManager.STREAM_NOTIFICATION.ͬʱ��Щ���������IJ��š�SystemApi |
| UNPROCESSED | 9 | ������õĻ�,����δ����������Ƶ��,��Default���� |
| VOICE_PERFORMANCE | 10 | ���ӳ���������ʵʱ��Ƶ���� |
| ECHO_REFERENCE | 1997 | �������Ʋο��ź� ,SystemApi |
| RADIO_TUNER | 1998 | ��̨�㲥����,SystemApi |
| HOTWORD | 1997 | ��ռʽ���ȴʼ��,SystemApi |
��ע:SystemApi - ����˼����Ҫ
android.Manifest.permission.CAPTURE_AUDIO_OUTPUT
Ȩ�ޡ���Ȩ�ޱ�����ϵͳ���ʹ��,�������ڵ�����Ӧ�ó���
2.2.2 AudioFormat
�ڶ�������AudioFormat����������¼����������Ҫ��,ͬ������ҲΪ�����ṩ��Builder�����ٴ�������
AudioFormat audioFormat = new AudioFormat.Builder()
.setEncoding(Config.AUDIO_CONFIG.ENCODING_PCM)
.setSampleRate(Config.AUDIO_CONFIG.SAMPLE_RATE_IN_Hz)
.setChannelMask(Config.AUDIO_CONFIG.RECORD_CHANNEL_CONFIG)
.build();
2.2.2.1 Encoding
�������˵�һ�����ֵĻ���֧�����������ٿ���Щ����о���������,�������õı����ʽ,��AudioFormat��ҲΪ�����ṩ�˺ܶ�ı����ʽ,����������ֱ���Ľ�ͼ,ȫ�����ݴ�ҿ����Լ���Դ���в鿴��
�����漰������IJ���������
ENCODING_
��Ϊ��ͷ��,���Դ�ҽ��뵽 android.media.AudioFormat ��ܷ���Ϳ��Կ�������������Ҫ����˵����һ�µ���: ENCODING_PCM_16BIT
����ע������:
Audio data format: PCM 16 bit per sample. Guaranteed to be supported by devices.
Ҳ����˵�����������֤�������豸֧�ֵ���
ע:
- ��
1.2.3������˵���������з�ʽ,������õ��� Packed ,������������˵������Packed�� - ������õ��Ǵ�˴洢,���Ե��漰����ҪС����Ϊ�������ʱ,��Ҫת���ߵ�λ��
The audio sample is a 16 bit signed integer typically stored as a Java short in a short array, but when the short is stored in a ByteBuffer, it is native endian (as compared to the default Java big endian).The short has full range from [-32768, 32767], and is sometimes interpreted as fixed point Q.15 data.
2.2.2.2 SampleRate
����������Dz����ʺ������� 1.2.1 �����ᵽ�ĸ���һ��,��ÿ����ж��ٴβ�����
һ�㳣���IJ����ʹ������:
Pair<Integer, Integer> SAMPLE_RATE_96000 = new Pair<>(0x00, 96000);
Pair<Integer, Integer> SAMPLE_RATE_88200 = new Pair<>(0x01, 88200);
Pair<Integer, Integer> SAMPLE_RATE_64000 = new Pair<>(0x02, 64000);
Pair<Integer, Integer> SAMPLE_RATE_48000 = new Pair<>(0x03, 48000);
Pair<Integer, Integer> SAMPLE_RATE_44100 = new Pair<>(0x04, 44100);
Pair<Integer, Integer> SAMPLE_RATE_32000 = new Pair<>(0x05, 32000);
Pair<Integer, Integer> SAMPLE_RATE_24000 = new Pair<>(0x06, 24000);
Pair<Integer, Integer> SAMPLE_RATE_22050 = new Pair<>(0x07, 22050);
Pair<Integer, Integer> SAMPLE_RATE_16000 = new Pair<>(0x08, 16000);
Pair<Integer, Integer> SAMPLE_RATE_12000 = new Pair<>(0x09, 12000);
Pair<Integer, Integer> SAMPLE_RATE_11025 = new Pair<>(0x0A, 11025);
Pair<Integer, Integer> SAMPLE_RATE_8000 = new Pair<>(0x0B, 8000);
��������Ҫע�����,���������������Сֵ��,���������IJ�����Ҫ���������֮��:
public static final int SAMPLE_RATE_HZ_MIN = AudioSystem.SAMPLE_RATE_HZ_MIN;
public static final int SAMPLE_RATE_HZ_MAX = AudioSystem.SAMPLE_RATE_HZ_MAX;
����������ڸ�����ᱨ��:
public Builder setSampleRate(int sampleRate) throws IllegalArgumentException {
if (((sampleRate < SAMPLE_RATE_HZ_MIN) || (sampleRate > SAMPLE_RATE_HZ_MAX)) &&
sampleRate != SAMPLE_RATE_UNSPECIFIED) {
throw new IllegalArgumentException("Invalid sample rate " + sampleRate);
}
mSampleRate = sampleRate;
mPropertySetMask |= AUDIO_FORMAT_HAS_PROPERTY_SAMPLE_RATE;
return this;
}
2.2.2.3 ChannelMask
���������������,�������ǿ�������Ϊ�������Ǻ��������������صġ����豸֧�ֵ������������Խ����������������Խ���塣
�ò�������Ҳ������AudioFormat��ͨ�� CHANNEL_ �鿴��
������Ҫ�ر�˵һ�µ���:
public static final int CHANNEL_IN_MONO = CHANNEL_IN_FRONT;
public static final int CHANNEL_IN_STEREO = (CHANNEL_IN_LEFT | CHANNEL_IN_RIGHT);
����������˫������
2.2.3 BufferSizeInBytes
��������¼����ʱ��,��Ƶ��������������ʽʵʱ���ص�,�������ǿ�������ÿ�η��ص�Buffer��С��
���С�����˷��ؼ�϶! ��Ϊ�����㡢��������λ��ȷ����,ÿ���������������ȷ����,��ôÿ�η��ص����ݿ��Сȷ����,�Ϳ��Թ����1���ӻ᷵�ض��ٴ�,������֪��������Ƶ���ݿ�ķ��ؼ�϶�����������и������ĸ����,�ں������Ƶ���䲿�����ǻ��õ���
�����øò�����ʱ��������ע��:
Sets the total size (in bytes) of the buffer where audio data is written during the recording. New audio data can be read from this buffer in smaller chunks than this size. See getMinBufferSize(int,int, int) to determine the minimum required buffer size for the successful creation of an AudioRecord instance.
�������˵�������õĴ�С����С�� MinBufferSize �Ĵ�С,�������ǿ���ʹ�� getMinBufferSize ����ȡ�����С��
int AudioRecord.getMinBufferSize(int sampleRateInHz, int channelConfig, int audioFormat);
����������ڿ�����Ҳ������ʲô�Ѷ���,��֮ǰ�Ѿ�ȷ���� �����ʡ������������ݸ�ʽ���ý�ȥ֮��ͻ�õ���¼�������µ� MinBufferSize ,�������õ� BufferSizeInBytes ���� MinBufferSize ���ɡ�
ע:��ͬ����Ƶ������ MinBufferSize �Dz�ͬ��!
2.3 ��ʼ¼��
�������IJ�������֮�����Ǿ;߱���¼��������
2.3.1 ¼��״̬
������AudioRecord�ڿ��Բ鿴¼��״̬:
public static final int STATE_UNINITIALIZED = 0;
public static final int STATE_INITIALIZED = 1;
public static final int RECORDSTATE_STOPPED = 1; // matches SL_RECORDSTATE_STOPPED
public static final int RECORDSTATE_RECORDING = 3;// matches SL_RECORDSTATE_RECORDING
����˵���Էֳ�����,���Ƿ��ʼ����;���Ƿ���¼���С�
�ڿ�ʼ¼��֮ǰ,Ϊ�����Ӵ���Ľ�׳��,���ǿ����ȼ��һ��AudioRecord�Ƿ���¼��״̬:
int recordingState = mAudioRecord.getRecordingState();
2.3.2 ��ʼ¼��
����������Ҫ�¿�һ���߳������ϵĴ� AudioRecord �ж�ȡ��Ƶ����:
while (mAudioRecord.getRecordingState() == AudioRecord.RECORDSTATE_RECORDING) {
byte[] tempAudioData = new byte[Config.AUDIO_CONFIG.READ_AUDIO_BUFFER_SIZE_BY_BYTES];
int bufferReadResult = mAudioRecord.read(tempAudioData, 0, Config.AUDIO_CONFIG.READ_AUDIO_BUFFER_SIZE_BY_BYTES);
if (bufferReadResult < 0) {
Log.w(TAG, "getRecordAndRTPSendRunnable bufferReadResult = " + bufferReadResult);
break;
}
}
read��������������Ϊ:
- audioData �C the array to which the recorded audio data is written.
- offsetInBytes �C index in audioData from which the data is written
- expressed in bytes. sizeInBytes �C the number of requested bytes.
�������Dz�û��������Ĵ�������Ҫ��,���Եڶ�������Ϊ0,����������������������tempAudioData ����ij��ȡ�
�������õ�ԭʼ��PCM��������,���ǵ�¼�����ܾ��Ѿ���������ˡ�
��������
3.1 MediaPlayer��AudioTrack
���˵������ý��Ļ����ǿ���������ѡ��:MediaPlayer��AudioTrack
����������Ҫ�˽�һ�����ǵ�����:
-
MediaPlayer���Բ��Ŷ��ָ�ʽ�������ļ�,����MP3,AAC,WAV,OGG,MIDI�ȡ�MediaPlayer����framework�㴴����Ӧ����Ƶ��������
��AudioTrackֻ�ܲ����Ѿ������PCM��,������ļ��Ļ�ֻ֧��wav��ʽ����Ƶ�ļ�,��Ϊwav��ʽ����Ƶ�ļ��ֶ���PCM����AudioTrack������������,����ֻ�ܲ��Ų���Ҫ�����wav�ļ��� -
��Ȼ����֮�仹���н��ܵ���ϵ��, MediaPlayer��framework�㻹�ǻᴴ��AudioTrack,�ѽ�����PCM�������ݸ�AudioTrack,AudioTrack�ٴ��ݸ�AudioFlinger���л���,Ȼ��Ŵ��ݸ�Ӳ�����š� ������MediaPlayer������AudioTrack��
-
ͨ���鿴API����֪��,MediaPlayer�ṩ��5��setDataSource����,��Ϊ����һ���Ǵ��ݲ����ļ����ַ���·����Ϊ����,����ֱ��ȡsd����mp3�ļ���·��,һ���Ǵ��ݲ����ļ���FileDescriptor�ļ���������Ϊ���ŵ�id,�������db�в�ѯ����Ƶ�ļ���id,�Ϳ���ֱ�Ӹ���MediaPlayer���в��š�����һ����Uri���͵���Դ�ļ�,���ڲ���content uri�ļ�����AudioTracker��write����֧��PCM��Ƶ��������ʽ���䵽��Ƶ�������Խ��в��š�
public int write(@NonNull byte[] audioData, int offsetInBytes, int sizeInBytes,
@WriteMode int writeMode)
���Կ�����Android�˵IJ��������ͨ��AudioTrack����PCM����ʵ�ֵġ����Խ�PCM����Android��Ƶ�����ͨ�����ԡ�
3.2 ����AudioTracker
������ֱ��ʹ��AudioTracker�Ĺ��췽��:
public AudioTrack(int streamType, int sampleRateInHz, int channelConfig, int audioFormat,
int bufferSizeInBytes, int mode)
���ﹲ�漰6�����������Ƚ�������Ϥ�Ĺ�һ��:
- sampleRateInHz:������,¼����ʱ�����ö���,������ʱ������ö��١�
- channelConfig:������,���÷���ͬ�ϡ�
- audioFormat:���ݴ洢�����ʽ,���÷���ͬ�ϡ�
- bufferSizeInBytes:ÿ��д��buffer��Ĵ�С,AudioTrackerҲ�ṩ�˺�AudioRecord���Ƶ�getMinBufferSize������
�ٽ���һ�������µIJ�����
3.2.1 streamType
�����������˼��������,����ע��������ȥAudioManager�н��в鿴��
/** Used to identify the volume of audio streams for phone calls */
public static final int STREAM_VOICE_CALL = AudioSystem.STREAM_VOICE_CALL;
/** Used to identify the volume of audio streams for system sounds */
public static final int STREAM_SYSTEM = AudioSystem.STREAM_SYSTEM;
/** Used to identify the volume of audio streams for the phone ring */
public static final int STREAM_RING = AudioSystem.STREAM_RING;
/** Used to identify the volume of audio streams for music playback */
public static final int STREAM_MUSIC = AudioSystem.STREAM_MUSIC;
/** Used to identify the volume of audio streams for alarms */
public static final int STREAM_ALARM = AudioSystem.STREAM_ALARM;
/** Used to identify the volume of audio streams for notifications */
public static final int STREAM_NOTIFICATION = AudioSystem.STREAM_NOTIFICATION;
����Ĵ���Ҳ�Ƚϼ�ֱ��,���Ǹ������Dz�ͬ��������,ϵͳ����ò�ͬ���������ý��в��š�
�������Ǹ��ݾ����ҵ�������þͿ����ˡ�
3.2.2 mode
mode��������ȡֵ: MODE_STATIC ��MODE_STREAM
- MODE_STATIC:����Ƶ��ʼ����֮ǰ,��Ƶ���ݽ���Java���䵽Native��һ�Ρ�
- MODE_STREAM:������Ƶʱ,��Ƶ���ݴ�Java��ʽ���䵽Native�㡣
����Ҳ�ȽϺ�����,����һ�δ��뻹������ʽ�ķ������ϵĴ���;��Ȼ������ǵ�ҵ���й�ϵ,����Dz���PCM��Ƶ�ļ�,���ǿ���ʹ��MODE_STATIC;�����ʵʱ����ƵͨѶҵ�����Ҫʹ��MODE_STREAM��
3.3 ������Ƶ
�ٴ����� AudioTrack �����ǾͿ��Ե��� play() �������в����ˡ�������������ڶ����߳��н�����:
public void play()
throws IllegalStateException {
if (mState != STATE_INITIALIZED) {
throw new IllegalStateException("play() called on uninitialized AudioTrack.");
}
//FIXME use lambda to pass startImpl to superclass
final int delay = getStartDelayMs();
if (delay == 0) {
startImpl();
} else {
new Thread() {
public void run() {
try {
Thread.sleep(delay);
} catch (InterruptedException e) {
e.printStackTrace();
}
baseSetStartDelayMs(0);
try {
startImpl();
} catch (IllegalStateException e) {
// fail silently for a state exception when it is happening after
// a delayed start, as the player state could have changed between the
// call to start() and the execution of startImpl()
}
}
}.start();
}
}
ͬʱ�������ʹ�õ�����ʽ�ķ�ʽ���в���,��Ҫ���ϵĽ�����д�뵽AudioTracker��:
while (true) {
mAudioTrack.write(pcmData, 0, pcmData.length);
}
3.4 stop��pause
-
AudioTrack#stop ֹͣ������Ƶ���ݡ�
����{@link#MODE_STREAM}ģʽ�´�����ʵ����ʹ��ʱ,�ڲ������һ��д��Ļ�������,��Ƶ��ֹͣ���š�Ҫ����ֹͣ,��ʹ��{@link#pause()},Ȼ��ʹ��{@link#flush()}.������δ���ŵ���Ƶ���ݡ� -
AudioTrack#pause ��ͣ������Ƶ���ݡ�
δ�طŵ����ݲ��ᱻ������������{@link#play}�����Ŵ����ݡ������{@link#flush()}�Զ��������ݡ�
�ġ����������
����ͽ���ʵ�����Ĺ�����������Ƶ����ȷ����һ������ת��������һ�����顣
4.1 Ԥ����
��1.3�����Ǽ�����:
- λ���Ϊ16����(2�ֽ�)
- ������Ϊ44.1kHZ
- ������Ϊ2
��Ϣ������CD���ʡ�����1����CD���ʵ�����,��洢�ռ�Ϊ:10.09MB;�������д����Ļ�,������̫����;Ϊ�˸����ڴ洢�ʹ���,һ�㶼��ʹ��ij����Ƶ����������б���ѹ��,Ȼ���ٴ��ij����Ƶ�ļ���ʽ��ͬʱ�ڲ��ŵ�ʱ��ͨ�����뻹ԭ��PCM�ٽ��в��š�
ѹ����Ϊ����ѹ��������ѹ����
- ����ѹ��:��ѹ�������ȫ��ԭ��ԭʼ����;
- ����ѹ��:��ѹ������ȫ��ԭ��ԭʼ����,�ᶪʧһ������Ϣ;һ����ѹ���������ź�(�����ź���ָ���ܱ��˶���֪�����ź�,�����˶�������Χ֮�����Ƶ�ź��Լ����ڱε�����Ƶ�źŵ�),�����б��봦����
4.2 �鿴�豸֧�ֵı�����ʽ
��Android���������ס��������,������Ҫʹ��MediaCodec���б����,������Ƶ����Ƶ�ı����ʽ�Ƿdz��ḻ��,���������豸�IJ�ͬ�����ն�֧�ֵı��������Ҳ��ͬ,����һ����������Ҫ���б���빤��֮ǰ�����Ȳ鿴һ�������豸֧�ֵı�����ʽ,���������豸��������ǵı���빦��ʧЧ��
�����ҽ��÷�����װ���˹�����,�����Ҫ�Ļ�����ֱ����ȥ��:
public static void getSupportMediaType() {
MediaCodecList mediaCodecList = new MediaCodecList(MediaCodecList.REGULAR_CODECS);
MediaCodecInfo[] supportCodes = mediaCodecList.getCodecInfos();
Log.d(TAG, "Support mediatypes:");
for (MediaCodecInfo codec : supportCodes) {
String name = codec.getName();
Log.d(TAG, name +" "+ (name.startsWith("OMX.google") ? "��" : "Ӳ") + (codec.isEncoder() ? "��" : "��"));
}
}
�÷����ͻ�Ϊ���Ƿ��ص�ǰ�豸֧�ֵı�����ʽ,�Լ��������������Ӳ��Ӳ�⡣
4.3 Media codec AAC ����
��������Ƶ�����ʽ,��������������վ���������Ķ�:
7�ֳ�������Ƶ��ʽ����:MP3,WMA,WAV,APE,FLAC,OGG,AAC
10����Ƶ�ļ���ʽ,��֪������?
������Ƶ��ʽ����ֻ��Ҫ��ס�������Լ���,����˵ AMR �ʺ�����ʱͨ����ҵ�� ; OGG�ʺ���������
�ٸ����һ������,���ڸ�ʽ�ľ���ʵ�ֲ���Ҫ�ر�Ĺ�ע,��ʵ�ֵ�ʱ����Э���ȥ�����ɡ���ʵ����������һ����ʽ�ķ�װ֮��,�����ĸ�ʽ�����϶������պ�«��ư��д������
�������ģ������ʹ��AAC������Ϊ��������,AAC(Advanced Audio Coding)����һ������Ƶ����ѹ������;
AAC������ļ���չ����Ҫ��3��:
- .acc:��ͳ��AAC����,ʹ��MPEG-2 Audio Transport Stream(ADTS)����
- .mp4:ʹ����MPEG-4 Part 14�ļ漴3GPP Media Release 6 Basic(3gp6)���з�װ��AAC����
- .m4a:Ϊ��������ƵMP4�ļ��Ͱ�����Ƶ��MP4�ļ�����Apple��˾ʹ�õ���չ��;
�ص�:
��С��128Kbit/s�������±�������,���Ҷ�������Ƶ�е���Ƶ���롣
����:
128Kbit/s���µ���Ƶ����,��������Ƶ����Ƶ��ı��롣
Media codec ����ϸʹ�ú�ԭ�����չ���˽��Ļ����ݱȽ϶�,�����Ƽ�ֱ��ȥgoogle�����߹���ȥ����
https://developer.android.google.cn/reference/android/media/MediaCodec
4.3.1 ����������
��ν�ı�����ǽ����ǵ�PCM��Ƶ���������һ�����ݸ�ʽ,�������ǵ�һ������Ҫȷ������Ҫ���еı���������ʲô:
try {
mediaCodec = MediaCodec
.createEncoderByType(MediaFormat.MIMETYPE_AUDIO_AAC);
} catch (IOException e) {
e.printStackTrace();
}
�������Dz��õ���AAC������������ʹ�� MediaFormat.MIMETYPE_AUDIO_AAC , ��֮ǰһ�� MediaFormatͬ��Ϊ�������˴����ı��������,��ҿ����Լ����뵽MediaFormat�н��в鿴��
4.3.2 ������
��һ����Ȼ���Ǵ������� mediaCodec ����,����������֪������Ҫ��������PCM���ݸ�ʽ��ʲô����,�����������Ǻ�ʹ��AudioTrackһ����Ҫ������Ƶ���������á�
public void configure(
@Nullable MediaFormat format,
@Nullable Surface surface, @Nullable MediaCrypto crypto,
@ConfigureFlag int flags) {
configure(format, surface, crypto, null, flags);
}
�������Dz��漰��Surface�����ݵļӽ���,��������������null��
flags�������������ݴ����DZ�����,�����������ڽ��еľ��DZ����������Ǵ� MediaCodec.CONFIGURE_FLAG_ENCODE
4.3.3 MediaFormat
����� MediaFormat ������ǰ��˵�� AudioFormat ��̫һ������������ǿ�������Ĵ���:
public static final @NonNull MediaFormat createAudioFormat(
@NonNull String mime,
int sampleRate,
int channelCount) {
MediaFormat format = new MediaFormat();
format.setString(KEY_MIME, mime);
format.setInteger(KEY_SAMPLE_RATE, sampleRate);
format.setInteger(KEY_CHANNEL_COUNT, channelCount);
return format;
}
public MediaFormat() {
mMap = new HashMap();
}
�Ӵ��������ǿ��Կ��� MediaFormat ʵ������һ�� HashMap ����ͨ��key-value����ʽ�洢�ͱ�����صIJ�����ʽ��
��ô�˴��������õ� MediaFormat Ϊ:
MediaFormat mediaFormat = MediaFormat.createAudioFormat(
MediaFormat.MIMETYPE_AUDIO_AAC,
Config.AUDIO_CONFIG.SAMPLE_RATE_IN_Hz,
Config.CODEC_CANNEL_COUNT);
mediaFormat.setInteger(MediaFormat.KEY_AAC_PROFILE, MediaCodecInfo.CodecProfileLevel.AACObjectLC);
mediaFormat.setInteger(MediaFormat.KEY_BIT_RATE, Config.AUDIO_CONFIG.BITRATES);
mediaFormat.setInteger(MediaFormat.KEY_MAX_INPUT_SIZE, Config.AUDIO_CONFIG.READ_AUDIO_BUFFER_SIZE_BY_BYTES);
�������Dz��ٽ���������Ϥ��: mime��sampleRate��format
��Ҫ�����µ�����:
-
MediaFormat.KEY_AAC_PROFILE
ֻ��ʹ��AAC��ʽʱ��ʹ�õ��ֶ�,���ֶ���������AAC�ļ���,��������ΪAAC��ʵ���㷨��
��MediaCodecInfo.CodecProfileLevel�Ѿ������Ƕ������,����ֱ�����ü��ɡ� -
MediaFormat.KEY_BIT_RATE
������,������ѹ����ÿ����������ݴ�С,bitrate in bits/sec�� -
MediaFormat.KEY_MAX_INPUT_SIZE
Media codec ���ݻ�����������ֽڴ�С,�����漰Media codec ��ԭ��,��������˾ͺܺ����⡣
4.3.4 ����AAC����
����ʽ����ǰ������Ҫ�������������½�һ��MediaCodec.BufferInfo��
mediaCodec.start();
bufferInfo = new MediaCodec.BufferInfo();
һ��������֮�����ǾͿ��Ա�����:
public byte[] offerEncoder(byte[] input);
4.3.4.1 �� Media codec ���������Buffer�鲢�������
���ﻹ�Ǹ���Ҽ�˵һ�� Media codec �Ĺ���ԭ��,�����ҶԺ�����������⡣
����һ����Ȼ˭������,��������ܰ�����������乤��ԭ����ͼ:
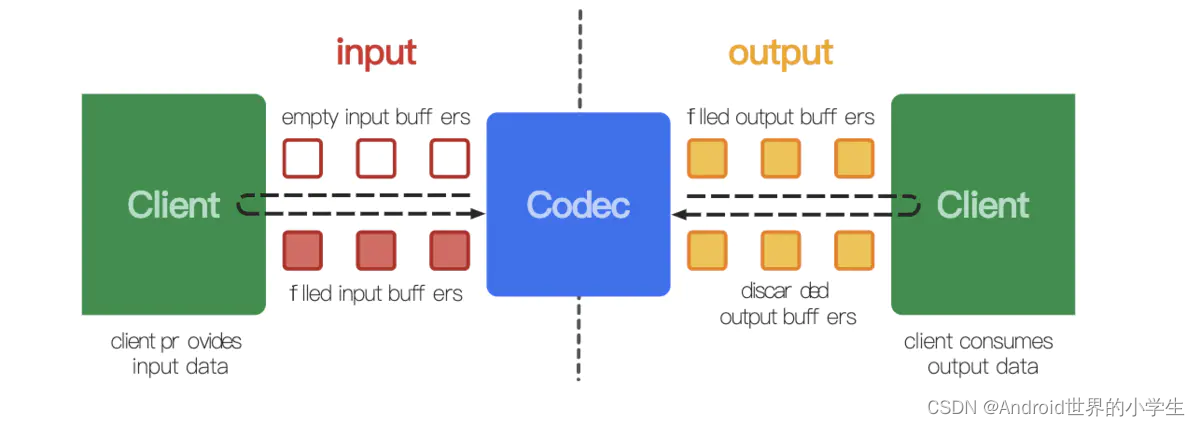
MediaCodec������2������������(inputBuffer��outputBuffer),�첽��������,
- �������ɷ�(���Client)��input�����������empty buffer����dequeueinputBuffer
- ����������(���Client)����Ҫ����������copy��empty buffer,Ȼ����뵽input������� ����queueInputBuffer
- MediaCodec��input������������ȡһ֡���б���봦��
- ����봦��������,MediaCodec��ԭʼinputbuffer��Ϊempty��Ż�����input�������,������������ݷ��뵽�Ҳ�output����������
- ���ѷ�Client(�Ҳ�Client)��output��������������������buffer ����dequeueOutputBuffer
- ���ѷ�client(�Ҳ�Client)�Ա������buffer������Ⱦ���߲���
- ��Ⱦ/������ɺ�,���ѷ�Client�ٽ���buffer�Żص�output���������� ����releaseOutputBuffer
�����ٿ�����ͼܶ���:
int inputBufferIndex = mediaCodec.dequeueInputBuffer(-1);
if (inputBufferIndex >= 0) {
ByteBuffer inputBuffer = mediaCodec.getInputBuffer(inputBufferIndex);
inputBuffer.put(input);
inputBuffer.limit(input.length);
long pts = computePresentationTime(presentationTimeUs);
mediaCodec.queueInputBuffer(inputBufferIndex, 0, input.length, pts, 0);
presentationTimeUs += 1;
}
����������˵���Ǻ� Media codec ������õ�InputBuffer,Ȼ�����ǵ���������InputBuffer,��Ȼ�����ǵ����ݷ��뵽 Media codec ��������С�
������Ҫע�����dequeueInputBuffer(-1),������ʾ��Ҫ�ȴ��ĺ�����
- -1��ʾһֱ��
- 0��ʾ����Ҫ��,��0�Ļ�����ȴ�,�����п��ܻᶪ֡
- ������ʾ�ȴ�ʱ�䡣
4.3.4.2 �� Media codec ���������Buffer��,�õ���������
int outputBufferIndex = mediaCodec.dequeueOutputBuffer(bufferInfo, 0);
if (outputBufferIndex < 0) {
Log.w(TAG, "offerDecoder dequeueOutputBuffer = " + outputBufferIndex);
}
while (outputBufferIndex >= 0) {
int outBitsSize = bufferInfo.size;
int outPacketSize = outBitsSize + 7;
ByteBuffer outputBuffer = mediaCodec.getOutputBuffer(outputBufferIndex);
outputBuffer.position(bufferInfo.offset);
outputBuffer.limit(bufferInfo.offset + outBitsSize);
//����ADTSͷ
byte[] outData = new byte[outPacketSize];
addADTStoPacket(outData,
outPacketSize,
MediaCodecInfo.CodecProfileLevel.AACObjectLC,
Config.AUDIO_CONFIG.SAMPLE_RATE_INDEX
);
outputBuffer.get(outData, 7, outBitsSize);
outputBuffer.position(bufferInfo.offset);
outputStream.write(outData);
mediaCodec.releaseOutputBuffer(outputBufferIndex, false);
outputBufferIndex = mediaCodec.dequeueOutputBuffer(bufferInfo, 0);
}
����������������������,�������������,�������� 4.3.4 �п�ͷ�ᵽ�� bufferInfo ���ݽ�ȥ,Ȼ���õ����õ����Buffer������
�������ǿ�һ�� BufferInfo ��ʵ��:
public final static class BufferInfo {
public int offset;
public int size;
public long presentationTimeUs;
public int flags;
public void set(int newOffset, int newSize, long newTimeUs, @BufferFlag int newFlags) {
offset = newOffset;
size = newSize;
presentationTimeUs = newTimeUs;
flags = newFlags;
}
public BufferInfo dup() {
BufferInfo copy = new BufferInfo();
copy.set(offset, size, presentationTimeUs, flags);
return copy;
}
};
���������������,���Ƕ�������ݵ�����,Ҳ����Ԫ����,������������ݵ������
�����¿����� outputBufferIndex ,���������õ�������ݿ������,�������������0,Ҳ����˵��С��0ʱ����Ч��!
ʣ�µľ��ǻ��ڱ�������,���Dz��ϵ��� Media codec ����ʣ���������ݿ�,����һ��������ꡣ
��Ҳ����whileѭ���ڵ����ݡ�
������Ҫ������˵��һ�µ������õ���Ƶ���ݺ�����Ϊÿ����Ƶ���ݿ������� ADTS ͷ:
addADTStoPacket(outData,
outPacketSize,
MediaCodecInfo.CodecProfileLevel.AACObjectLC,
Config.AUDIO_CONFIG.SAMPLE_RATE_INDEX
);
�������Ȼ˵��AAC���е�,���Ƕ������������ı��빤������һ��������,���õ�ԭʼ�����������洢���������,���ǿ�����Ҫ��һЩ������Ϣ�������������ת����һ����,ת��֮��Ĵ�������Ҳ��Ҫ��ע,��ͺ;����ʵ��Ҫ���й��ˡ�
4.3.5 �����ܽ�
����,���Ǿ�����:���� Media codec->���� Media codec->���� Media codec->�� Media codec������õ�����Buffer�� -> �� Buffer�������Ҫ��������� ->�ύ Buffer�� ->������ɱ����Buffer��->����ԭʼ�ı����->���ش�����ı����
��һϵ�еIJ���,����˱���Ĺ���,����������Ȼ����,������������ԭ�����DZȽϼġ�
4.4 Media codec AAC ����
4.4.1 ��֤����
����ɱ���֮��,���������뵽�ľ��ǽ��빤����,��ʵ��Ȼ,���ィ������������DZ��ı��빤��,������ʹ�ò���������һ�����ǵı������ݡ�����˵��������������AAC����,�������������ɺ�����洢���ļ���,Ȼ��ʹ�õ������IJ��������в���,������Ԥ����֤�����DZ��빤������ȷ��,��֤ͨ����Ϳ��Է��ĵĽ��н��빤���ˡ�
4.4.2 MediaExtractor
����˵��,ʹ���ļ��ķ�ʽ��֤��������ʵ��������һ���ô�,���ǰ����ǿ��ٵĹ���MediaFormat��ͨ�������ѧϰ���ǻ������Ѿ����ܵ���,¼���Ͳ�����ʵ��һ���ԳƵĹ���,����ͨ�в�����,ֻ�Ǽ��˼������ܱ�����Ҫ�IJ�����
�����������������ʵ�����Ǻ�����,һ����˵����ͨ���Ķ�Դ���е�ע�;Ϳ��Խ��,������û�и����Ը��ķ�����,�е�,�����MediaExtractor������MediaExtractor �dz���ǿ��,�������������Ƿ�����Ƶ�ļ���MediaFormat,���ܰ����Ƿ�������MP4�������ָ�ʽ��װ���ļ���
ʹ�� MediaExtractor Ҳ�Ƿdz���:
MediaExtractor extractor = new MediaExtractor();//ʵ��һ��MediaExtractor
try {
extractor.setDataSource(mFile.getAbsolutePath());//��������ý���ļ�·��
} catch (IOException e) {
e.printStackTrace();
}
int count = extractor.getTrackCount();//��ȡ�������
Log.d(TAG, "������� = "+count);
for (int i = 0; i < count; i++){
MediaFormat mediaFormat = extractor.getTrackFormat(i);
Log.d(TAG, i+"���ͨ����ʽ = "+mediaFormat.getString(MediaFormat.KEY_MIME));
}
����˵����:���� MediaExtractor ����,������Ҫ��������Ƶ�ļ�·��,�õ��ļ���Track,Ȼ��õ���Ӧ��MediaFormat��
4.4.3 ����������
try {
mediaCodec =MediaCodec.createDecoderByType(mediaFormat.getString(MediaFormat.KEY_MIME));
} catch (IOException e) {
e.printStackTrace();
}
��������ʹ�� MediaCodec �����˽�����,����IJ����� mediaFormat �е� MediaFormat.KEY_MIME;����Ա������ﻹ��ӡ��Ļ�,MediaCodec ��MediaFormatʹ�õ� MIME_TYPE��ʵ��һ���ġ�
4.4.4 ���ý�����
ʣ�µľͼ���,����mediaFormat�Ϳ����ˡ����һ������Flag���DZ��벻����Чֵ,�������Ǵ�0��
mediaCodec.configure(mediaFormat, null, null, 0);
4.4.5 ��ʼ����
�����ʵ�ֺͱ����ʵ��ԭ�����,��ʵ���ǽ���������ת������һ������,��������Ͳ����������ˡ�������һ��������Ҫ��ע����,�ڱ����ʱ������Ϊ�˷���AAC�����ʽ��ÿ��AAC��Ƶ���ݿ鶼����ADTSͷ,��ô���ǽ����ʱ�����Ҫȥ�����ͷ,��Ϊ����ͱ����ǶԳƵġ�ͬ�����������������빤��ʱ,ҲӦ�ù�עһ��,�����յ��ı��������Ƿ��ǿ���ֱ�ӽ��н����,�����������ݵĴ���,��ɽ������
4.5 �ܽ�
���ģ����Ҫ�ǽ��� :Media codec��MediaFormat��BufferInfo��ByteBuffer ��MediaExtractor ��ʹ��,����Ľ�����,�����ÿ��ģ�鶼�Ķ�һ�³��÷�����ע��,������ע������õ���ʦ,ǿ�������ϲ������ϡ���Ȼʵ���Ǽ���������Ψһ��,����ʵ����Ը��õ��˽�����Ƶ��������ع��ܡ�
�塢��Ƶ����
���ֻ�Ǽ�¼���洢�ļ�,��Դ�����Ŀ�������˵���DZȽϼ�,ͨ�������ѧϰ���ǿ��Կ��ٵ���������Ĺ��ܡ�����ҵ������ȷ����Ƶ������,����ֻ��Ҫ���AudioRecord��AudioTracker�Ĵ���������;ͬ����ʹ��Media codec + MediaForamt + MediaExtractor ��ɱ�������Ĵ���������,ʣ�µľ���¼����������¼���ļ�,Ȼ����벥��¼���ļ��ˡ�
����������ȻҪ˼��һ������,���������ʵʱ��Ƶ����,��Խ�����,�Ƿ��ܰ�������ķ�ʽ����ɡ����Dz����Ƚ���һ���Ա�:
| ������Դ��ʽ | ���� | ��ʧ | �����С���� | ʵʱ�Ա�֤ |
|---|---|---|---|---|
| �ļ� | ���� | ����ʧ | ���漰 | ��֤ |
| TCP | ���� | ����ʧ | ������ | ����֤ |
| UDP | ���� | ��ʧ | ������ | ��֤ |
����������Ҫ�ѹ�ע�����TCP�����UDP�������������ϾͿ����ˡ�
5.1 ��������
UDP��TCP��һ����Ҫ��ͬ����UDP�����Dz���֤����˳���,�������������ķ�����Ƶ����ʱ�����Ǻ��������ȵ���,��ǰ�������,��һ������:
����˵������Ҫ��:
һ �� �� ��
���ʹ��TCP��ô�Զ��յ���Ҳ�ǡ�һ �� �� �ġ�,����UDP�յ��ľͿ�����:
�� һ �� ��
����Ȼ��������ϣ����,�����������Ϊ�˴�Ҹ��õ�����������ⳡ����
ʵ������Ƶ����һ������Ƶ���ɵ����ݿ������֮ǰ���õ�¼�������й�,һ����˵���ݿ鶼��10������(Ҳ���ܸ�����߸���),���仰˵��������˵��ʱһ���ֵĴ������ɼ�������ɵ�,����Щ������ʱ,��Ȼ���������������������´�����Ϣ�����ݸı�,���ǻ���û����������Ӱ�졣�������ǿ��Ի���һ��֮ǰ˵����������,���������������֮��,��Ӧ��ƽ���仯�����߾ͻ���ܱ��ǰ�ߺ�Ͳ��Ҳ���ƽ��,���ʱ�����Ƶ�������ͻ�о��ܹ��졣
��ʵ����������ķ�ʽҲ�Ƚϼ�,�����ڽ��ն˼�һ���������,Ȼ�����Ƕ��յ�������������,������Ȼ��Ҫע�����漸����:
- ��ǰ�յ����������к�С�����ڲ��ŵ���Ƶ���ݿ����к�,��ô�������֡�Ѿ�û��������,��Ҫ������
- �����㷨��ѡ��,����������������������:һ���ǵ�ǰ��������ݿ���ڶ�β�����ݿ�,��ô��ʱֱ�ӷ��ڶ�β�Ϳ�����;һ���ǵ�ǰ��������ݿ�С�ڶ�β�����ݿ�,һ����˵�Ͷ�β�ľ��벻��̫��,���ǴӺ���ǰ��λ�û���졣���Ը���ҵ����ȡβ�巨��������,Ч�ʸ��ߡ�
- �����С��ѡ��,���ィ����ҵ��,һ����˵�϶��ǻ������Խ��,���Ƕ�ԭ��Ƶ���ݵ����л�ԭ��Խ��,����ͬ����,��ʼ������ʱ����ӳ�������ʹ��һ�������Ļ������Ҳ��ʮ���б�Ҫ�ġ�
- ���ݽṹ��ѡ��,��Ҫѡ���̰߳�ȫ����������,������Ҫ��עͬʱ��д��ɵ����⡣����һ����Ƶ���ݿ鲥����Ϻ�,�����Ƴ���һ����Ƶ���ݿ�,����ʱ�ֽ��յ��µ���Ƶ���ݿ���в���,��ͻ����ͬʱ��д,������̲߳���ȫ��������ArrayList�ͻᱨ����
5.2 ����
UDP���DZ�֤�ﵽ,��Ƶ���ݿ鶪ʧ�Ƿdz�������,��������ҵ��Ľ�չ�DZ�Ȼ�����ġ������������Ҳ�����DZ���Ҫ��������⡣
������ڵ��������������ǰ���������Ƶ���ݴ�С,���������Ƶһ���ȡ����������������ķ�ʽ�������ʧ�����⡣�ٸ�������:
����˵������Ҫ����: 1��2��3��4��5 �������,�ҿ����ٴ�һ��15,��1-5���ܺ�,��ôֻҪ�ܺͲ���,1-5��������ֶ�ʧ����һ�����Ƕ��ܽ�����ԭ��������������ӷdz��ļ�,ʵ�ʵ��㷨�����Ҫ���Ӻܶ�,����������������ݲ��ܶ�,������Ч������Ҳֻ�ܶ�1��,��Щ��������,ͬ������ЩҲ��FEC�㷨��Ҫ��������⡣
�������ǿ����ƶϳ�������,����Խ��,�����ܽ���ʧ���ݻ�ԭ�����Ŀ����Ծ�Խ����Ȼ����Ҳ���ܽ��������õ�̫��,��ô���������Ч���������һ��������Ҫ˼�������⡣
�����������һ���µĸ���������,��һ��ʱ���ڷ��͵İ��������յ��İ�����֮���ٱ��Ϸ��͵İ�����������˵���Ƿ�����100����,����ֻ�յ���80����ô��������20%,��ʱ���ǽ�����������õ������ڶ����ʾͿ����ˡ�
����������������ص�:
- �˽�FEC�㷨�ı��ʾͿ�����,��ͨ��������������,��ԭ����ʧ������
- ����Խ��,��ԭ��ʧ���ݵĿ����Ծ�Խ��
- �������ݴ�С��ѡ��Ͷ������й�
- ������Ӧ���ǻ��ڱ��δ���ķ��ͺ͵�����������
- ������Ӧ���Ƕ�̬��,���������������ݴ�СҲӦ���Ƕ�̬��
����FECǰ������㷨��ѡ��,����ֱ����ֲWebRTC��ʹ�õ��㷨,Ҳ�����Լ���Github�����ֳɵ�,��֮���ҵ��,ѡ�����ʺ��Լ��IJ����ص㡣