在对多核设备进行编程时,考虑处理模型是非常重要的。通常希望每个内核将执行共享内存中的部分或全部代码,数据主要是存在本地内存。
如果每个内核都有自己的代码和数据空间,则L1/L2的别名地址就不应该被使用。只应使用全局地址,这样对于每个存储位置的整个系统提供了一个通用的视角。这也意味着对于软件开发来说,每个核心都有自己的工程,独立于其他核心而构建。共享区域通常在每个内核的映射中定义,并由任何的核心都可以使用相同地址进行访问。
在存在共享代码段的情况下,可能希望对公共函数中对于数据结构或暂存存储器使用别名地址。这将允许任何的内核使用相同的地址,而不用考虑它属于哪个内核。数据结构/暂存缓冲区需要有一个使用别名地址区域定义的运行地址,以便当被函数访问时,它是与内核无关的。加载地址需要是相同偏移量的全局地址。运行时别名地址可用于CPU直接加载/存储和内部DMA(IDMA)分页,但不适用于EDMA、PKTDMA或其他主要处理。这些处理必须使用全局地址。
软件始终可以验证它在哪个内核上运行,因此不需要在公共代码中使用别名地址。有一个CPU寄存器(DNUM),保存数字信号处理器内核号,可以在运行时读取,有条件地执行代码和更新指针。
任何共享数据资源都应该进行仲裁,这样就不会有所有权冲突。有一个片上信号量外设,它允许在不同CPU上执行的线程仲裁共享资源的所有权。这确保了对共享资源的读-修改-写更新可以自动进行
为了加快从外部DDR3存储器和共享L2存储器读取程序和数据的速度,每个内核都有一组专用预取寄存器。这些预取寄存器用于在内核需要之前从外部存储器(或共享L2存储器)预加载连续存储器。预取机制评估从外部存储器读取数据和程序的方向,并且预加载将来可能读取的数据和程序,如果需要预加载数据,则导致更高的带宽,或者如果稍后不读取读取的数据,则从外部存储器进行不需要的读取。每个内核可以分别控制每个内存段(16MB)的预取和缓存。
CPU View of the Device
每个中央处理器都有一个相同的设备视图。下图所示,
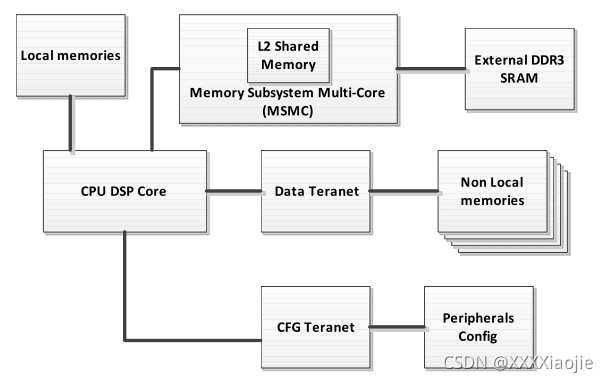
除了每个内核的L2内存之外,还有一个交换中央资源(SCR),它通过交换结构将内核、外部内存接口和片内外设互联起来。
每个内核都是配置(访问外围控制寄存器)和DMA(内部和外部数据存储器)交换结构的主机。此外,每个内核都有一个到直接存储器存取交换结构的从接口,允许访问其L1和L2静态随机存取存储器。所有内核均可平等访问所有从端点,用户软件为每个主端点分配优先级,以便在每个端点的所有访问之间进行仲裁。
系统中的每个从机(例如Timer control、DDR3 SDRAM、each core’s L1\L2 SRAM)在设备的内存映射中有一个唯一的地址,供任何主机访问。在大多数情况下,每个内核都可以访问内存映射中的所有控制寄存器和所有内存位置
每个内核都有直接连接到CPU的Level 1 program和data memory,以及Level 2 unified memory,每个存储器都是用户可配置的,以使某些部分成为存储器映射SRAM
如前所述,本地核心的L1/L2存储器在存储器映射中有两个实体。处理器本地的所有内存都有全局地址,设备中的所有主机都可以访问这些地址。此外,相关处理器可以通过别名地址直接访问本地存储器,其中八个最高有效位被屏蔽为零。混叠在内核中处理,允许公共代码在多个内核上不加修改地运行。本地地址应仅用于共享代码或数据,允许内存中包含单个映像。任何以特定内核为目标的代码/数据,或者特定内核在运行时分配的内存区域,都应始终只使用全局地址
每个内核通过内存子系统多核(MSMC)模块访问任何共享内存,无论是L2共享内存(MSM-multicore shared memory)还是外部内存DDR3。每个核心都有一个直接进入MSMC的主端口。MSMC仲裁和优化从所有主设备对共享存储器的访问,包括每个核心、EDMA访问或其他主设备,并执行错误检测和纠正。XMC(外部内存控制器)寄存器和EMC(增强型内存控制器)寄存器分别管理每个内核的MSMC接口,并提供内存保护和从32位到26位的地址转换,以支持各种地址操作,例如访问高达8GB的外部存储
Cache and Prefetch Considerations
需要指出的是,在没有软件管理的情况下,硬件保证的唯一一致性是L1D缓存与同一内核内的L2静态随机存取器的一致性。硬件将保证对L2的任何更新都将反映在L1D内存中,反之亦然。硬件将保证对L2的任何更新都将反映在L1D缓存中,反之亦然。在同一个内核中,L1P缓存和L2之间没有保证的一致性,一个内核上的L1/L2和另一个内核上的L1/L2之间没有一致性,芯片上的任何L1/L2和共享的L2内存和外部内存之间也没有一致性。
TCI66xx和C66xx设备不支持自动缓存一致性,因为这涉及到功耗和引入的延迟开销。针对这些设备的实时应用需要可预测性和确定性,这来自于应用软件在特定时间协调的数据一致性。当开发人员管理这种一致性时,他们开发出运行更快、功耗更低的设计,因为他们可以控制何时以及是否必须将本地数据复制到不同的内存中。下图描述了缓存的一致性和非一致性:
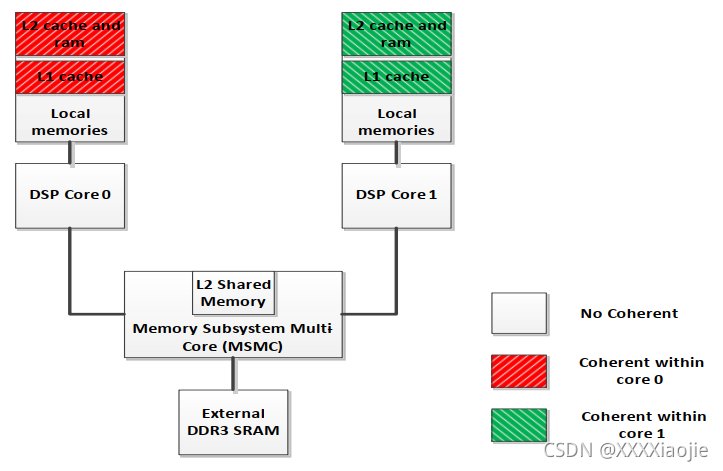
与L2缓存一样,预取一致性不会跨内核保持。应用程序负责管理一致性,可以通过禁用特定内存段的预取,也可以在必要使预取数据无效。
TI提供了一组API函数来执行缓存一致性和预取一致性操作,包括缓存线失效、缓存线回写到存储内存以及回写失效操作。
此外,如果L1的任何部分被配置为内存映射SRAM,则内核(IDMA)中内置了一个小型分页引擎,可用于在CPU运行的背景下在L1和L2之间传输线性内存块。IDMA传输具有用户可编程的优先级,可以针对系统中的其他主机进行仲裁。IDMA还可用于执行批量外围配置寄存器访问。
在编程TCI66XX或C66XX设备时,考虑处理模型是很重要的。上图显示了每个内核如何具有本地L1/L2内存以及与MSMC的(内存子系统)直接连接,MSMC提供对共享L2内存和外部DDR3 SDRAM(如果系统中存在)的访问
参考文献:
- 《Multicore Programming Guide》