单片机多串口数据转发模型
51黑电子论坛地址:http://www.51hei.com/bbs/dpj-213065-1.html
实际需求
最近在做一个西门子 Step 200 系列的PLC通讯口扩展项目时,遇到了这样的问题:
224XP,这个CPU的外部通讯端口只用两个,在物联网大火的当下,这样的扩展口数量,在加入联网模块后,显然无法满足更多的联网需求。当前实际需求如下:
| 编号 | 功能 |
|---|---|
| 01 | PLC串口屏通讯 |
| 02 | EBM风扇通讯 |
| 03 | 4G/WIFI模块通讯 |
| 04 | 以太网通讯 |
- 在考虑到成本与技术可行性前提下,尽可能保留产品研发核心技术手段,选用STC8系列单片机对PLC原有的两个通讯口利用串口进行扩展。设计思路如下:
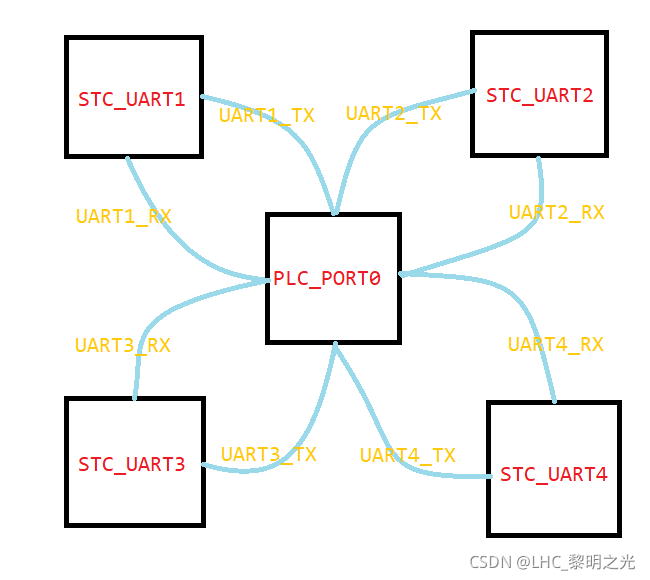
从图中可以看出,数据信息的主要请求目标主要是通过
PLC_PORT0获得PLC内部存储区数据(PLC_PORT1默认用于连接屏幕)。因此,进行软件拓展的目标物理链路就是PLC_PORT0。
矛盾的产生
- 从上面的模型可以看出,当前工作模式应该是一个多主单从结构。那么按照常理应该是由STC8的4个串口通过轮询的方式对共享设备PLC
目标地址发出数据请求的命令,随后由PLC把响应数据返回给当前请求对象。如果严格遵循这样的工作模式,不会存在任何问题。但是,实际的架构设计需求如下:
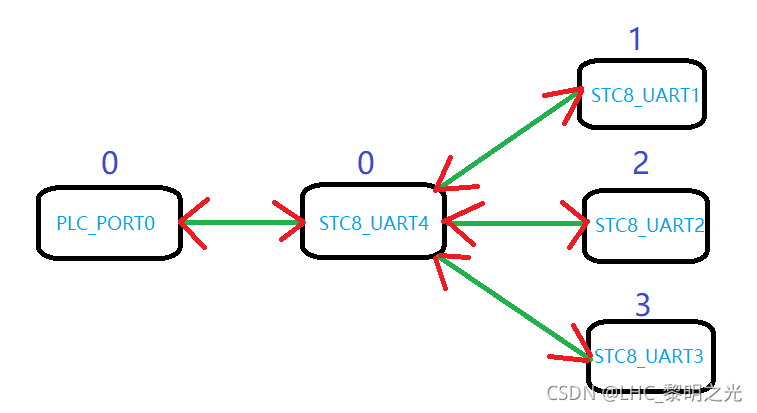
其中每个通讯端口上端的标号都代表在实际的通讯过程中,STC8单片机作为扩展主机时轮询框架下的调度关系(数字越小,优先级越高;数字相等,代表处于同一优先级)。
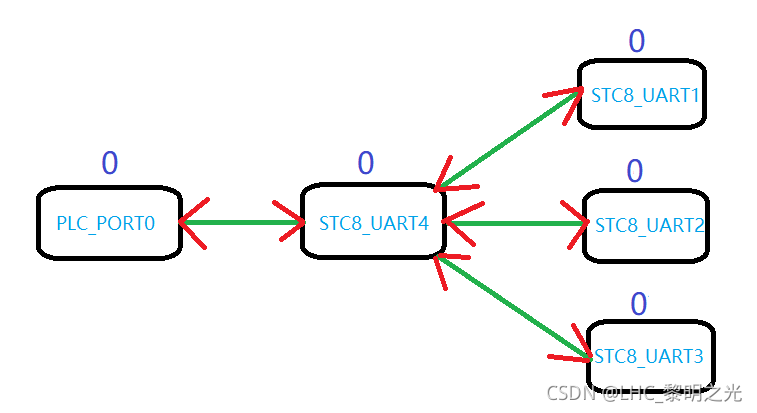
- 这里实际使用的时候是通过
PLC_PORT0与STC8_UART4进行物理上的连接,在通过STC8内部软件协议通过其他串口与拓展设备进行数据交互。很显然当前的架构无法满足这样的实际需求,矛盾就应运而生了。 - 既然多主机,单从机的通讯模型无法在PLC作为主机时满足需求,那么就可以重新考虑另外一种工作模式。为了适应更多可能的情况,
建立一种不分主从结构的工作模式,在多对象数据交互的基础上建立一种相对是一对一的通讯机制。
软件设计思想
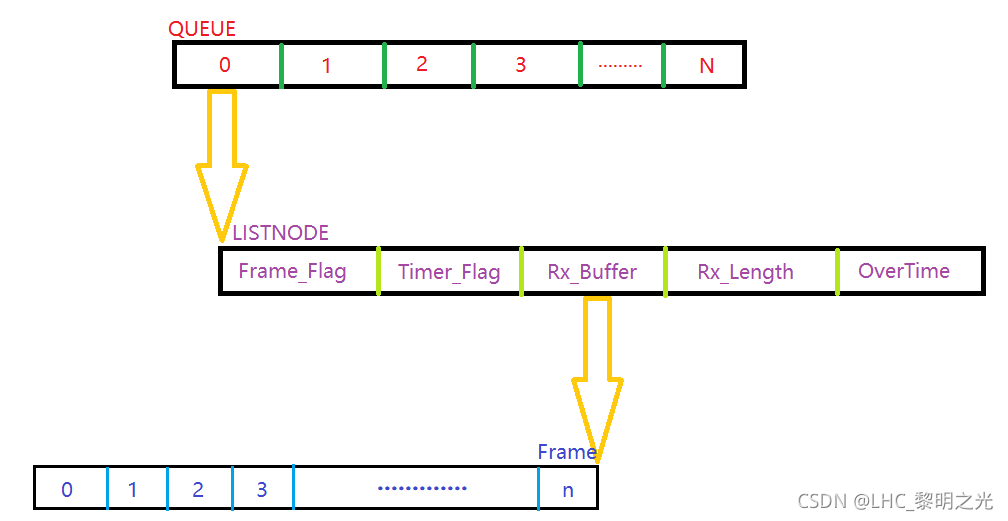
从图中可以看出,最上层采用的是循环队列,每个队列的元素由一条链表进行连接,每条链表的一个节点代表一帧数据。
| 标识符 | 意义 |
|---|---|
| Frame_Flag | 帧标志:由定时器帧中断机制置为true;轮询转发程序转发当前帧后置为false |
| Timer_Flag | 帧中断定时器开启标志:当任意串口接收中断收到一个字节数据时设置为true;超时后设置false |
| Rx_Buffer | 数据帧接收缓冲区 |
| Rx_Length | 当前数据帧长度 |
| OverTime | 帧判定时间:该变量在串口中断有字节数据接收时会不断刷新;在帧仲裁定时器中其值不断减小至0 |
详细工作原理:
以PLC通过485总线发送数据为例,假设PLC当前要像EBM请求某一个状态值,发出一帧数据 15 21 01 CA,此时EBM响应数据为 35 01 01 00 CA ,则:
- 串口四接收中断收到PLC发出的第一个字节,打开帧中断定时器,判断当前写指针所对应的链表节点帧标志是否为false,条件成立后判断当前节点帧长度是否溢出,如果没有就刷新当前帧链表块中
OverTime, 最后把当前字节15存到当前帧缓冲区Rx_Buffer的位置上。 - 后续字符
21 01 CA的接收操作与第一个字符一致,其中每个字节间间隔由通讯的波特率决定,<<Timer(OverTime) ,当接收完这一帧数据后,OverTime值将不会在串口接收中断中被刷新,而是由帧中断定时器中不断减小为0,最终标志该节点上这帧数据接收完成,并把对应的Frame_Flag置为true。 - 在主程序轮询机制中,一旦检测到有
Frame_Flag产生,则利用读指针访问当前节点帧缓冲区,对目标设备发出请求命令。 - 响应数据返回给目标对象的工作过程与前三个步骤完全一致。值得注意的是,入果存在对个数据交换序列
PLC_PORT0-->UART4-->UART3和UART2-->UART4-->PLC_PORT0,存在相反的公共序列PLC_PORT0-->UART4,UART4-->PLC_PORT0,此时如果公用的是同一个缓冲区,且不对不同类型的数据进行分流,将会造成不同请求对象数据响应错误,所以必须加以条件限制。
建立数据结构
@function:1.0.0 **基础数据结构**
/*链队数据结构*/
typedef struct
{
uint8_t Frame_Flag; /*帧标志*/
uint8_t Timer_Flag; /*打开定时器标志*/
uint8_t Rx_Buffer[MAX_SIZE]; /*数据接收缓冲区*/
uint16_t Rx_Length; /*数据接收长度*/
uint16_t OverTime; /*目标设备响应超时时间*/
}Uart_Queu;
typedef struct
{
Uart_Queu LNode[MAX_NODE];
/*存储R ,W指针,表示一个队列*/
uint8_t Wptr;
uint8_t Rptr;
}Uart_List;
/*声明链队*/
extern Uart_List Uart_LinkList[MAX_LQUEUE];
顶层数据结构采用环形队列,只不过队列中的单个元素并不是一个单一的值,而是一个带有记录信息的数据块
Uart_Queu。这样做的目的在于,使用的单片机是C51,其本身的串口是不带有空闲中断或者DMA这些高级硬件的,那这就需要我们通过软件算法模拟这一些硬件功能 来完成功能设计。
@function: 1.0.1 **改进后基础数据结构**
/*链队数据结构*/
typedef struct
{
uint8_t Frame_Flag; /*帧标志*/
uint8_t Timer_Flag; /*打开定时器标志*/
uint8_t Rx_Buffer[MAX_SIZE]; /*数据接收缓冲区*/
uint16_t Rx_Length; /*数据接收长度*/
uint16_t OverTime; /*目标设备响应超时时间*/
Uart_Queu *Next; /*指向下一个节点*/
}Uart_Queu;
主要改进了队列下数据块元素的内存分配方式,由原来的静态的分配,改为程序运行过程根据实际需求来分配。考虑
Malloc函数在51编译器中安全性和适用性,实际使用过程建议非必要情况采用静态内存分配方式。当然,采用动态内存分配方式,使用循环链表将会带来更多的可操作性、灵活性和内存节约。
@function: 1.0.2 **串口帧中断机制设计**
/**
* @brief 定时器0的中断服务函数
* @details
* @param None
* @retval None
*/
void Timer0_ISR() interrupt 1
{
if(COM_UART1.LNode[COM_UART1.Wptr].Timer_Flag)
/*以太网串口接收字符间隔超时处理*/
SET_FRAME(COM_UART1);
if(COM_UART2.LNode[COM_UART2.Wptr].Timer_Flag)
/*4G/WiFi串口接收字符间隔超时处理*/
SET_FRAME(COM_UART2);
if(COM_UART3.LNode[COM_UART3.Wptr].Timer_Flag)
/*RS485串口接收字符间隔超时处理*/
SET_FRAME(COM_UART3);
if(COM_UART4.LNode[COM_UART4.Wptr].Timer_Flag)
/*PLC串口接收字符间隔超时处理*/
SET_FRAME(COM_UART4);
}
/**
* @brief 串口4中断函数
* @details 使用的是定时器4作为波特率发生器,PLC口用
* @param None
* @retval None
*/
void Uart4_Isr() interrupt 18
{ /*发送中断*/
if (S4CON & S4TI)
{
S4CON &= ~S4TI;
/*发送完成,清除占用*/
Uart4.Uartx_busy = false;
}
/*接收中断*/
if (S4CON & S4RI)
{
S4CON &= ~S4RI;
/*当收到数据时打开帧中断定时器*/
COM_UART4.LNode[COM_UART4.Wptr].Timer_Flag = true;
/*当前节点还没有收到一帧数据*/
if (!COM_UART4.LNode[COM_UART4.Wptr].Frame_Flag)
{
/*刷新帧超时时间*/
COM_UART4.LNode[COM_UART4.Wptr].OverTime = MAX_SILENCE;
if (COM_UART4.LNode[COM_UART4.Wptr].Rx_Length < MAX_SIZE)
{ /*把数据存到当前节点的缓冲区*/
COM_UART4.LNode[COM_UART4.Wptr].Rx_Buffer[COM_UART4.LNode[COM_UART4.Wptr].Rx_Length++] = S4BUF;
}
}
}
}
因为硬件定时器数量有限,所以几个串口的帧中断机定时器均采用了
Timer0进行仲裁,可能会存在中断延时的问题,在硬件定时器资源充足情况下,尽可能选用硬件定时器较佳。
@function: **1.0.3 帧中断宏**
/*置位目标串口接收帧标志*/
#define SET_FRAME(COM_UARTx) (COM_UARTx.LNode[COM_UARTx.Wptr].OverTime ? \
(COM_UARTx.LNode[COM_UARTx.Wptr].OverTime--): \
((COM_UARTx.LNode[COM_UARTx.Wptr].Frame_Flag = true), \
(COM_UARTx.Wptr = ((COM_UARTx.Wptr + 1U) % MAX_NODE)), \
(COM_UARTx.LNode[COM_UARTx.Wptr].Timer_Flag = false)))
最后,有了这些软件机制,仅仅只需要编写对应的逻辑就可以了。
@function: **1.0.4 多串口数据轮询处理机制**
/*设置队列读指针*/
#define SET_RPTR(x) ((COM_UART##x).Rptr = (((COM_UART##x).Rptr + 1U) % MAX_NODE))
/*设置队列写指针*/
#define SET_WPTR(x) ((COM_UART##x).Wptr = (((COM_UART##x).Wptr + 1U) % MAX_NODE))
/*串口一对一数据转发数据结构*/
typedef struct
{
SEL_CHANNEL Source_Channel; /*数据起源通道*/
SEL_CHANNEL Target_Channel; /*数据交付通道*/
void (*pHandle)(void);
} ComData_Handle;
/*定义当前串口交换序列*/
const ComData_Handle ComData_Array[] =
{
{CHANNEL_PLC, CHANNEL_RS485, Plc_To_Rs485},
{CHANNEL_WIFI, CHANNEL_PLC, Wifi_To_Plc},
};
/*增加映射关系时,计算出当前关系数*/
#define COMDATA_SIZE (sizeof(ComData_Array) / sizeof(ComData_Handle))
/**
* @brief 串口1对1数据转发
* @details
* @param None
* @retval None
*/
void Uart_DataForward(SEL_CHANNEL Src, SEL_CHANNEL Dest)
{
uint8_t i = 0;
for (i = 0; i < COMDATA_SIZE; i++)
{
if ((Src == ComData_Array[i].Source_Channel) && (Dest == ComData_Array[i].Target_Channel))
{
ComData_Array[i].pHandle();
}
}
}
/**
* @brief 串口事件处理
* @details
* @param None
* @retval None
*/
void Uart_Handle(void)
{
/*数据交换序列1:PLC与RS485进行数据交换*/
Uart_DataForward(CHANNEL_PLC, CHANNEL_RS485);
/*数据交换序列2:WIFI与PLC进行数据交换*/
Uart_DataForward(CHANNEL_WIFI, CHANNEL_PLC);
}
/**
* @brief PLC数据交付到RS485
* @details
* @param None
* @retval None
*/
void Plc_To_Rs485(void)
{
/*STC串口4收到PLC发出的数据*/
if ((COM_UART4.LNode[COM_UART4.Rptr].Frame_Flag)) //&& (COM_UART4.LNode[COM_UART4.Rptr].Rx_Length)
{
/*如果串口4接收到的数据帧不是EBM所需的,过滤掉*/
if (COM_UART4.LNode[COM_UART4.Rptr].Rx_Buffer[0] != MODBUS_SLAVEADDR)
{ /*标记该接收帧以进行处理*/
COM_UART4.LNode[COM_UART4.Rptr].Frame_Flag = false;
/*允许485发送*/
USART3_EN = 1;
/*数据转发给RS485时,数据长度+1,可以保证MAX3485芯片能够最后一位数据刚好不停止在串口的停止位上*/
Uartx_SendStr(&Uart3, COM_UART4.LNode[COM_UART4.Rptr].Rx_Buffer, COM_UART4.LNode[COM_UART4.Rptr].Rx_Length + 1U);
/*接收到数据长度置为0*/
COM_UART4.LNode[COM_UART4.Rptr].Rx_Length = 0;
/*发送中断结束后,清空对应接收缓冲区*/
memset(&COM_UART4.LNode[COM_UART4.Rptr].Rx_Buffer[0], 0, MAX_SIZE);
/*发送完一帧数据后拉低*/
USART3_EN = 0;
/*读指针指到下一个节点*/
SET_RPTR(4);
}
/*目标设备发出应答*/
if ((COM_UART3.LNode[COM_UART3.Rptr].Frame_Flag)) //&& (COM_UART3.LNode[COM_UART3.Rptr].Rx_Length)
{
/*标记该接收帧已经进行处理*/
COM_UART3.LNode[COM_UART3.Rptr].Frame_Flag = false;
/*数据返回给请求对象*/
Uartx_SendStr(&Uart4, COM_UART3.LNode[COM_UART3.Rptr].Rx_Buffer, COM_UART3.LNode[COM_UART3.Rptr].Rx_Length);
/*接收到数据长度置为0*/
COM_UART3.LNode[COM_UART3.Rptr].Rx_Length = 0;
/*发送中断结束后,清空对应接收缓冲区*/
memset(&COM_UART3.LNode[COM_UART3.Rptr].Rx_Buffer[0], 0, MAX_SIZE);
/*读指针指到下一个节点*/
SET_RPTR(3);
}
}
}
如果需要PDF文档,请到51黑电子论坛主页下载。