一、开发环境
单片机型号:STM32H743IIT6
工程配置环境:STM32CubeMX 6.3.0
固件库:STM32CubeH7 1.9.0
开发工具:MDK Keil 5.32
二、原理过程
在STM32上接9个串口,每个串口约收发50个字节数据每帧,若使用传统的按字节中断HAL_UART_Receive_IT()的方式,则会因中断响应过于频繁导致系统响应不过来,因此需要使用IDLE中断+DMA接收的方式接收数据。DMA的作用是无需CPU干预下自动将串口接收到的数据转移到缓存数组中。然而若是直接使用DMA接收串口数据,则必须得等长接收,当DMA存不满时CPU就无法判断一帧是否接收完毕,因此需要使用IDLE中断判断串口线是否空闲,当串口空闲时则触发IDLE中断,此时进行取数据帧的操作。
三、步骤方法
1、在CubeMX中配置串口DMA接收
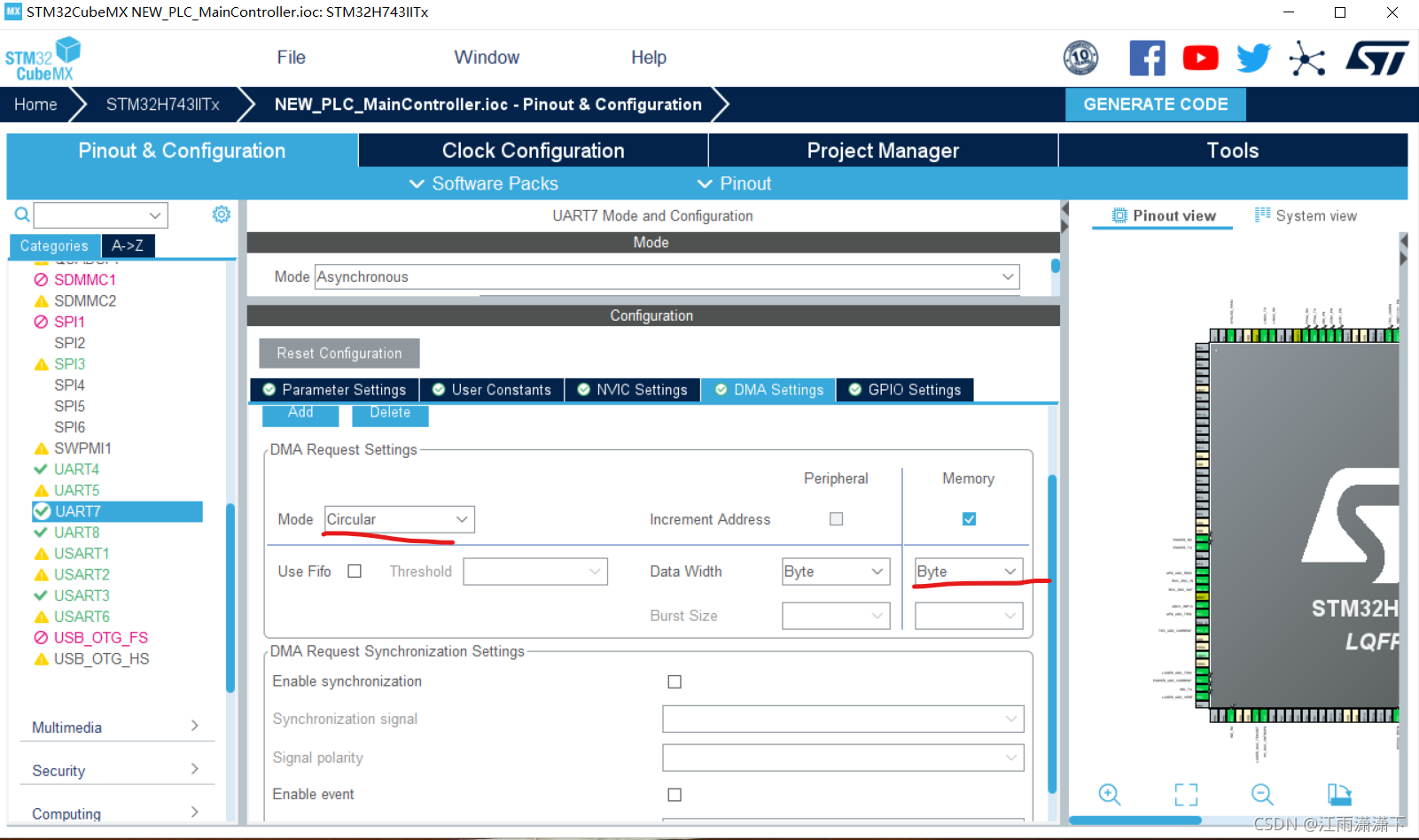
串口基本配置略,在DMA选项卡里,将接收模式配置为循环,数据长度配置为Byte,如图所示
2、打开串口接收
按照其他教程的说明,打开IDLE中断需要使用__HAL_UART_ENABLE_IT(&huart7, UART_IT_IDLE)这个函数来使能IDLE中断,开启DMA接收则需要使用HAL_UART_Receive_DMA(&huart7,rx_buffer,BUFFER_SIZE)这个函数来开启,并将响应IDLE中断接收数据的函数写在IRQHandler中,每次都需要代码清除中断标志位并重新使能。这种做法就没有充分利用到HAL库分层的特性,不方便进行移植和修改。
为了方便以后的项目进行移植,利用HAL库中的函数完成这项功能,在这里使用stm32h7xx_hal_uart_ex.c中定义的
HAL_UARTEx_ReceiveToIdle_DMA()这个函数。该函数原型如下:
HAL_StatusTypeDef HAL_UARTEx_ReceiveToIdle_DMA(UART_HandleTypeDef *huart, uint8_t *pData, uint16_t Size);
在开启串口DMA接收的同时也开启了IDLE中断,当中断发生时会进入void HAL_UARTEx_RxEventCallback(UART_HandleTypeDef *huart, uint16_t Size)回调函数,因此可以做到在不修改CubeMX生成的代码的前提下完成了该功能,方便了后续在其他STM32芯片上的实现。
由于我们不使用DMA自身的中断,因此在调用HAL_UARTEx_ReceiveToIdle_DMA()使能串口空闲中断DMA接收之后需要使用__HAL_DMA_DISABLE_IT(&hdma_uart7_rx,DMA_IT_HT)关闭中断
开启接收代码如下:
void uart_start_receive()
{
HAL_UARTEx_ReceiveToIdle_DMA(&huart7, rxBufArr, BUFARR_SIZE);
__HAL_DMA_DISABLE_IT(&hdma_uart7_rx,DMA_IT_HT);
}
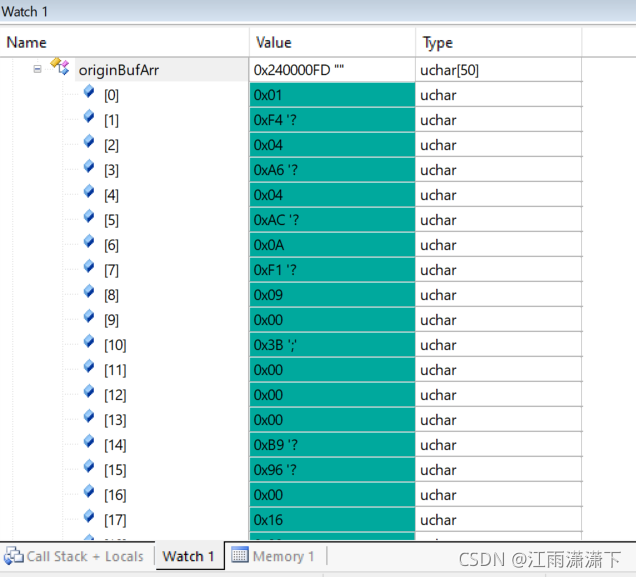
这样就打开了串口DMA。我们可以通过调试口看到,当开启DMA之后,数据自动从串口移入缓存数组rxBufArr中:
然而,这个时候缓存数组的帧头位置是不确定的,这样CPU不能从缓存数组中提取出数据帧来,在这里IDLE中断起作用了。串口发送数据每一帧直接有较长的空闲时间,因此当STM32接收完一个数据帧后检测到串口处于空闲状态时就会触发IDLE中断,在HAL_UARTEx_ReceiveToIdle_DMA()中开启了空闲中断,在这时就会进入void HAL_UARTEx_RxEventCallback(UART_HandleTypeDef *huart, uint16_t Size),中断回调函数代码如下:
//响应Idle中断回调函数,MSG_LEN为报文长度
int pos = 0;
void HAL_UARTEx_RxEventCallback(UART_HandleTypeDef *huart, uint16_t Size)
{
if (huart == &huart7)
{
for(int j = 0;j<=MSG_LEN;j++) //在缓存数组里循环接收报文字节
{
rxbuf = rxBufArr[pos];
//开启解析流程
}
uart_start_receive(); //重新开启接收
pos++;
if(pos>=BUFARR_SIZE)
{
pos = 0;
}
}
}
在这里,pos为数组的下标,表明当前读到缓存数组的某个字节位置上,当下次报文发送过来时则在原来位置上继续往下读MSG_LEN个字节。当超过DMA缓存长度时,则将pos置零,从头开始。
因此我们可以从缓存数组中取出指令,解析结果如下(0x34 0xB0为帧头):
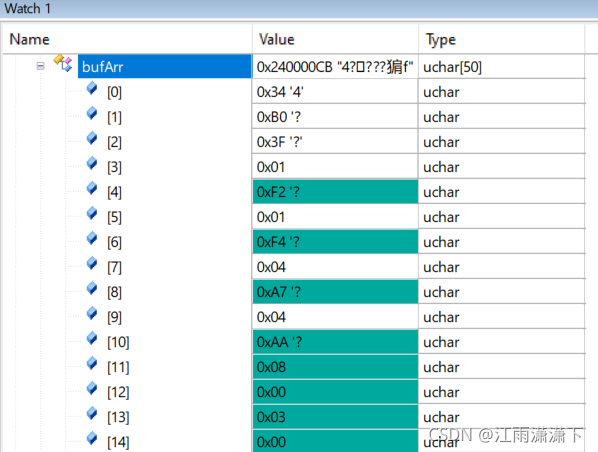
该数据包为一帧35字节,若用按字节中断的方式接收则一帧需要进入35次中断,并且从外设取到CPU的内存中也需要占用CPU时间,而使用该方法则一帧只需要进入1次中断,并且取出数据帧的过程由DMA完成,极大的节省了CPU时间。