����Ŀ¼
1�����ڴ����ļ�
1.1��������115200
????������ʹ������SUBת����ģ����̨�ʼDZ�����,������ת���ڵ�RX��TX,GND��GND,3V3��3V3,Ȼ���������,���������ڵ�ʽ����,�ֱ�ѡ����������
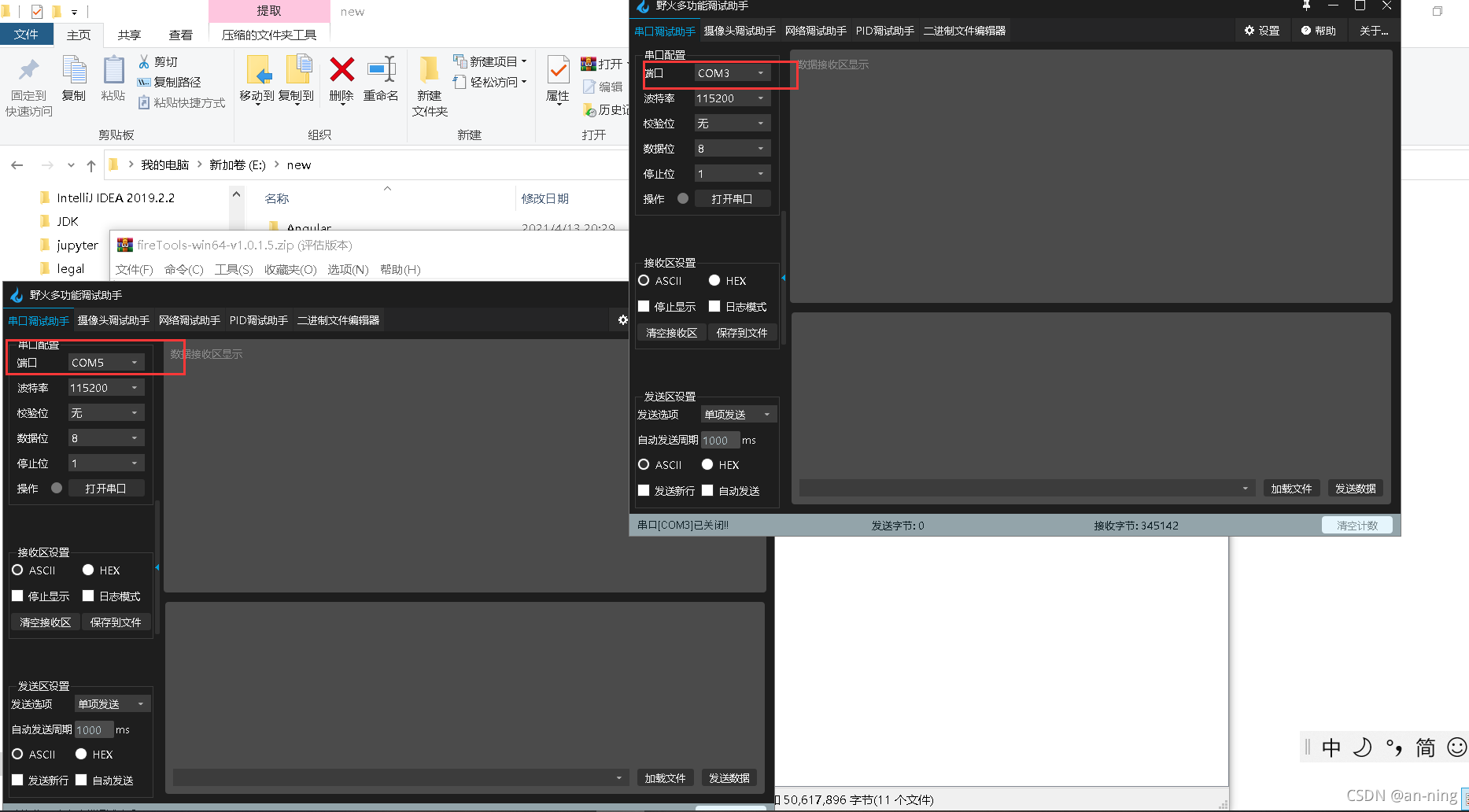
????Ȼ��ѡ������������ļ�ѡ��ѡ����Ҫ������ļ�
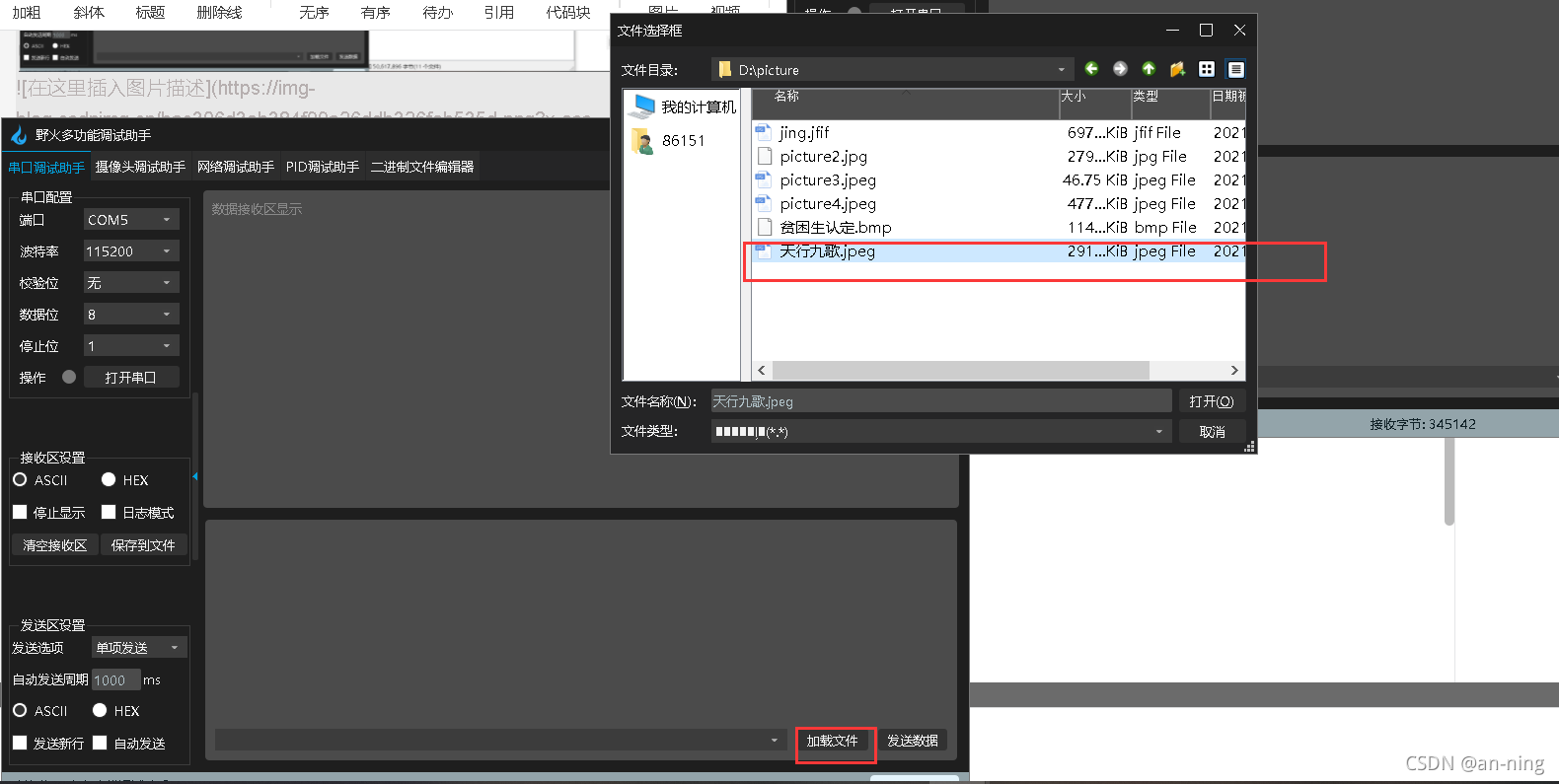
????��������ļ�,�������ݴ���,���Կ��������ٶȺ���,���������˰����
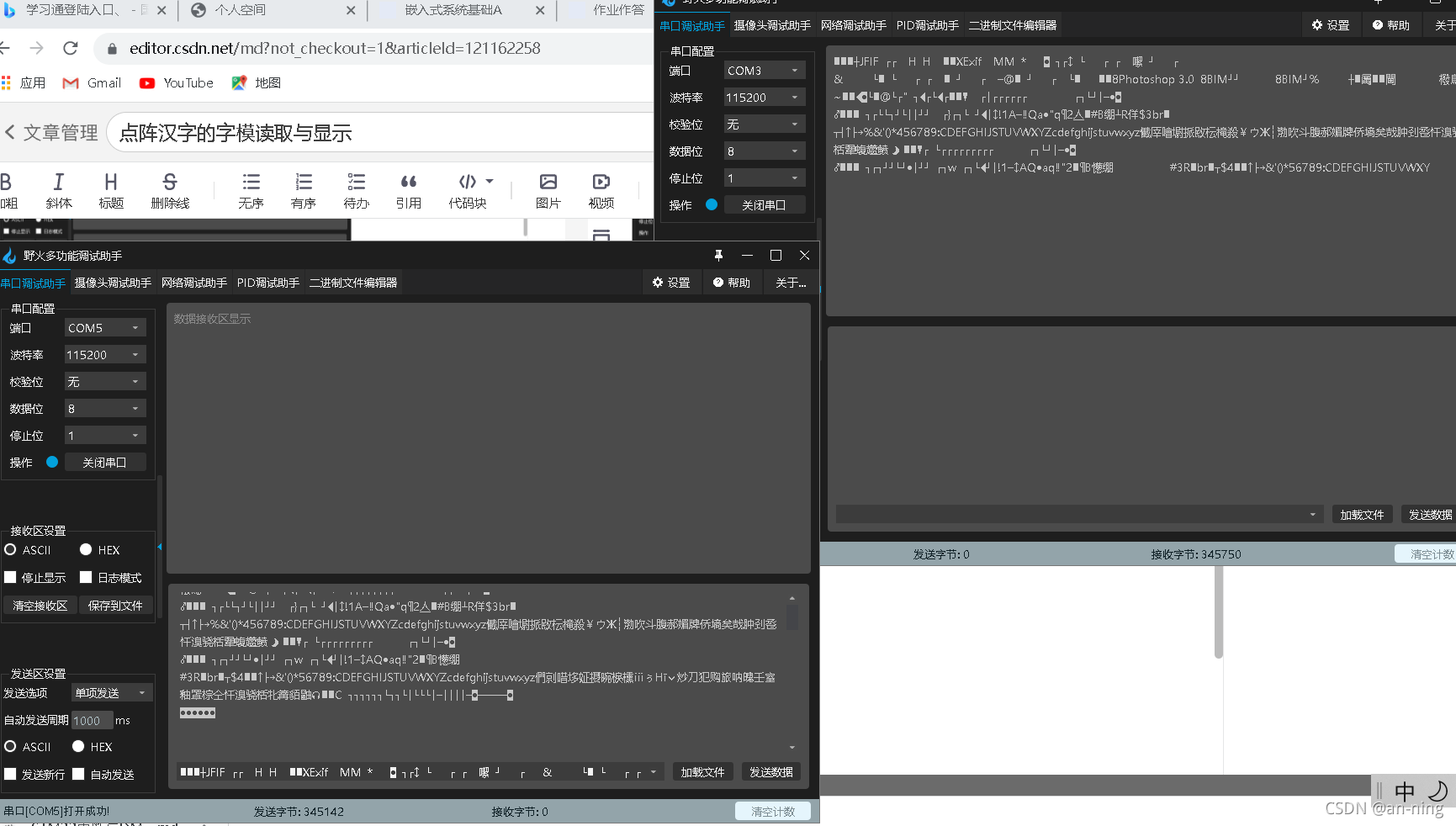
1.2����������
????�����ʵ���230400,�ظ�����IJ���,��Ȼ�ᴫ��ɹ�,�����ٶȿ���һЩ
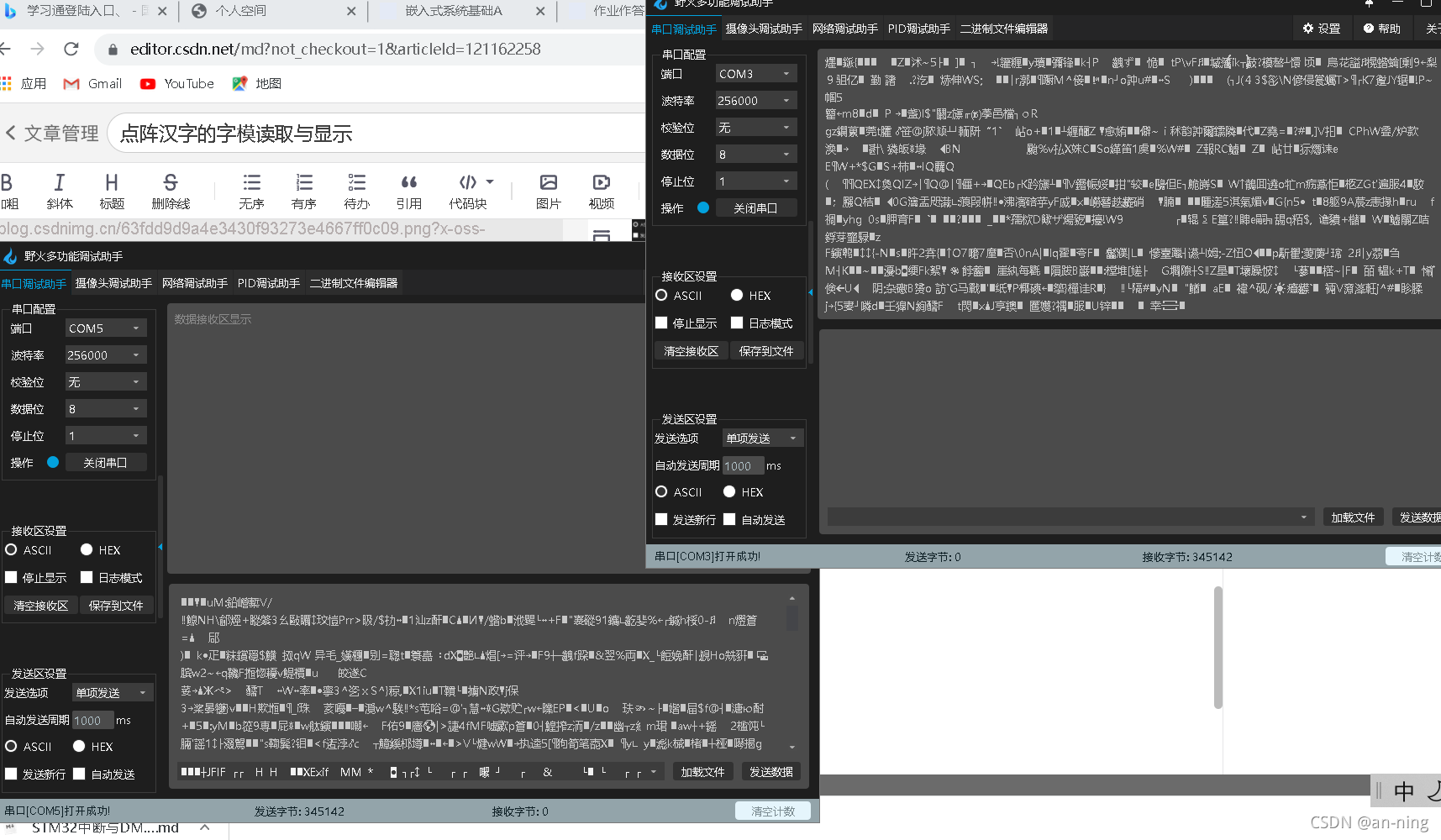
????�����ʵ���256000,�ظ�����IJ���,��Ȼ����ɹ�,�����ٶȸ������һЩ
1.3����������
????�������ʵ���9600,�������Ѿ���������������,ֻ�ܴ���һ����,Ȼ�������Ӧ
????�ɴ˿ɼ�,��һ����Χ��,������������ʱ,����ͬ�ȴ�С���ļ�,����ʱ������,��������һ��Χʱ,�����ʶԴ���ʱ���Ӱ��ͻ��С���������ִ������
????�����ʺ����ݵĴ��������й�ϵ,���Dz����ʲ��������ݴ�������,���ݴ��������DZ����ʡ�����������ֵ�ϺͲ������������Ĺ�ϵ: I=Slog2N
????����IΪ������,SΪ������,NΪÿ�����ų��ص���Ϣ��,���Ա���Ϊ��λ��������������ʵĹ�ϵҲ�ɻ����:������=��������������״̬��Ӧ�Ķ�����λ����
2�������ֿ����
2.1�����ֿ�ԭ��
????1�����еĺ��ֻ���Ӣ�Ķ��������ԭ��:
��������,ÿ8����ռ��һ���ֽ�,�����8���ֽڵ�ռ��һ���ֽ�,���Ҵ����λ�����λ���С�
????2�����ɵ��ֿ�˵��:(��12��12����)
һ������ռ���ֽ���:12��8=1��������4Ҳ����ռ����2��12=24���ֽڡ�
��������A0A0��A0FEA1A0��A2FE��������
��12��12�ֿ�ġ��ҡ�Ϊ��:���ҡ��ı���ΪCED2,�����ں�������CEH-AOH=2EH����D2H-A0H=32H����������12��12�ֿ����ʼλ�þ���[{FE-A0}*2EH+32H]*24=104976��ʼ��24���ֽھ����ҵĵ���ģ��
2.2�����ֵĻ����롢��λ����������������ݴ洢��ʽ
2.2.1��������(������)
????1����������һ����λʮ��������,����һ�������������ֽڱ�ʾ,ÿ���ֽ�ֻ��7λ,��ASCII�����ơ�
????2��Ϊ�˱ܿ�ASCII�ַ��еIJ�����ʾ�ַ�0000 0000 ~ 0001 1111(ʮ������Ϊ0 ~ 1F,ʮ����Ϊ0 ~ 31)���ո��ַ�0010 0000(ʮ������Ϊ20,ʮ����Ϊ32)(����ΪʲôҪ�ܿ�����Ϊʲôֻ�ܿ�ASCII��0~32�IJ�����ʾ�ַ��Ϳո��ַ�,�����н���),������(�ֳ�Ϊ������)�涨��ʾ���ֵķ�ΧΪ(0010 0001,0010 0001) ~ (0111 1110,0111 1110),ʮ������Ϊ(21,21) ~ (7E,7E),ʮ����Ϊ(33,33) ~ (126,126)(ע��,GB�຺�ֱ���Ϊ˫�ֽڱ���)�����,���뽫�����롱�͡�λ�롱�ֱ����32(ʮ������Ϊ20H,��H��ʾʮ������),��Ϊ�����롣Ҳ����˵,�������൱�ڽ���λ�����ƫ����32,�Ա�����ASCII�ַ���0~32�IJ�����ʾ�ַ��Ϳո��ַ����ͻ��
2.2.2�����ֻ�����
????������:Ϊ�˱���ASCII�������ͬʱʹ��ʱ��������������,�ֺ���ϵͳ�����ý�������ÿ���ֽڸ�λ��1��Ϊ���ֻ����롣�����Ƚ���˺��ֻ����������Ļ�����֮��Ķ�����,��ʹ���ֻ��������������м��Ķ�Ӧ��ϵ��
| ���� | ���� |
|---|---|
| ������ | ���ֻ����� |
| ��� | ����ASCII�� |
| ��� | ���� |
| ��ʽ | ���ֻ�����=���ֹ�����+8080H |
| �ص� | �ڼ�����ڲ���������Ψһ�� |
2.2.3���������
????��λ��һ����λ��ʮ������,����GB2312��80��ȫ���ַ������һ��94��94�ķ���,ÿһ�г�Ϊһ��������,���Ϊ01~94;ÿһ�г�Ϊһ����λ��,���Ϊ01~94,�����õ�GB2312��80����λͼ,����λͼ��λ������ʾ�ĺ��ֱ���,��Ϊ��λ�롣
| ���� | ���� |
|---|---|
| ������ | ������� |
| ��; | Ϊÿ�����ֱ�һ��Ψһ�Ĵ��� |
| �ŵ� | ʹ��������ױ�ʶ�����պʹ��� |
????GB2312�ַ�������λ��λ��:
(1)01~09��(682��):������š����֡�Ӣ���ַ����Ʊ�����,����������ĸ��ϣ����ĸ������ƽ������Ƭ������ĸ�������������ĸ�����ڵ�682��ȫ���ַ�;
(2)10~15��:����,������չ;
(3)16~55��(3755��):���ú���(Ҳ��һ������),��ƴ������;
(4)56~87��(3008��):�dz��ú���(Ҳ�ƶ�������),������/�ʻ�����;
(5)88~94��:����,������չ��
2.2.4�����ֻ����롢���������λ�����߹�ϵ
????1����ϵ:
������ = ��� + 2020H;
������ = ������ + 8080H;
????�������;
(1)����λ���е������λ��ֱ�ת��Ϊʮ��������;
(2)��λ���ʮ��������+2020H = ������;
(3)������+8080H = ������
????2��ע��:
2020H:��ΪASCLL���з�Ϊ�����ͱ���������ַ�����,ǰ32λ�ǿ�����(��س�,�˸��),����ǰ32��,���Ǻ���ġ��ʹ�����涨����λ��Ļ�����ÿ���ֽڷֱ����20H(32��ʮ�����Ʊ�ʾ)��
�Ӵ���ʽ8080H:Ϊ������ASCLL�����ͻ,�Ӷ��涨��ÿ���ֽڵ����λ���� 0 ���� 1(��֮ǰ���Ƕ��� 0),����˵��ÿ���ֽ�(����λ)���ټ��� 80H(128��ʮ�����Ʊ�ʾ)��
2.3���������δ����ʽ
????1�������ֿ�洢
�ں��ֵĵ����ֿ���,ÿ���ֽڵ�ÿ��λ������һ�����ֵ�һ����,ÿ�����ֶ�����һ�����εĵ������,0����û��,1�����е�,��0��1�ֱ��ò�ͬ��ɫ����,���γ���һ������,���õĵ��������1212, 1414, 16*16�����ֿ⡣�ֿ�����ֽ�����ʾ��IJ�ͬ�з�Ϊ���������������,Ŀǰ�������ֿⶼ�Ǻ������Ĵ洢��ʽ(�õ�����Ӧ��������UCDOS�ֿ�),�������һ������Ϊ��ijЩҺ���Dz�������ɨ����ʾ��,Ϊ�������ʾ�ٶ�,���DZ���ֿ������������,ʡ������ʾʱ��Ҫ������ת����
????2�����ֵ����ȡ
(1)������λ���ȡ����
���ֵ����ֿ��Ǹ�����λ���˳����д洢��,���,���ǿ��Ը�����λ����ȡһ���ֿ�ĵ���,���ļ��㹫ʽ����:
������ʼλ�� = ((����- 1)*94 + (λ�� �C 1)) * ���ֵ����ֽ���
��ȡ������ʼλ�ú�,���ǾͿ��Դ����λ�ÿ�ʼ,��ȡ��һ�����ֵĵ���
(2.) ���ú��ֻ������ȡ����
ǰ�����Ǽ�������,���ֵ���λ��ͻ�����Ĺ�ϵ����:
�������λ�ֽ� = ���� + 20H + 80H(������ + A0H)
�������λ�ֽ� = λ�� + 20H + 80H(��λ�� + AOH)
������˵,����Ҳ���Ը��ݻ������������λ��:
���� = �������λ�ֽ� - A0H
λ�� = �������λ�ֽ� - AOH
�������ʽ���ȡ���ֵ���Ĺ�ʽ���кϲ��ƾͿ��Եõ����ֵĵ���λ��
3������Ƕ��
????1�������������ϵͳ�´���һ���µĹ���Ŀ¼Chinese,����24����.hz�ļ�,ASCII��.zf�ļ��Ͳ���ͼƬ�ƶ���Chinese�ļ���
????Ȼ����Ŀ¼�ﴴ��һ��c++�����ļ�,���������
��һվ 21:53:50
#include<iostream>
#include<opencv/cv.h>
#include"opencv2/opencv.hpp"
#include<opencv/cxcore.h>
#include<opencv/highgui.h>
#include<math.h>
using namespace cv;
using namespace std;
void paint_chinese(Mat& image,int x_offset,int y_offset,unsigned long offset);
void paint_ascii(Mat& image,int x_offset,int y_offset,unsigned long offset);
void put_text_to_image(int x_offset,int y_offset,String image_path,char* logo_path);
int main(){
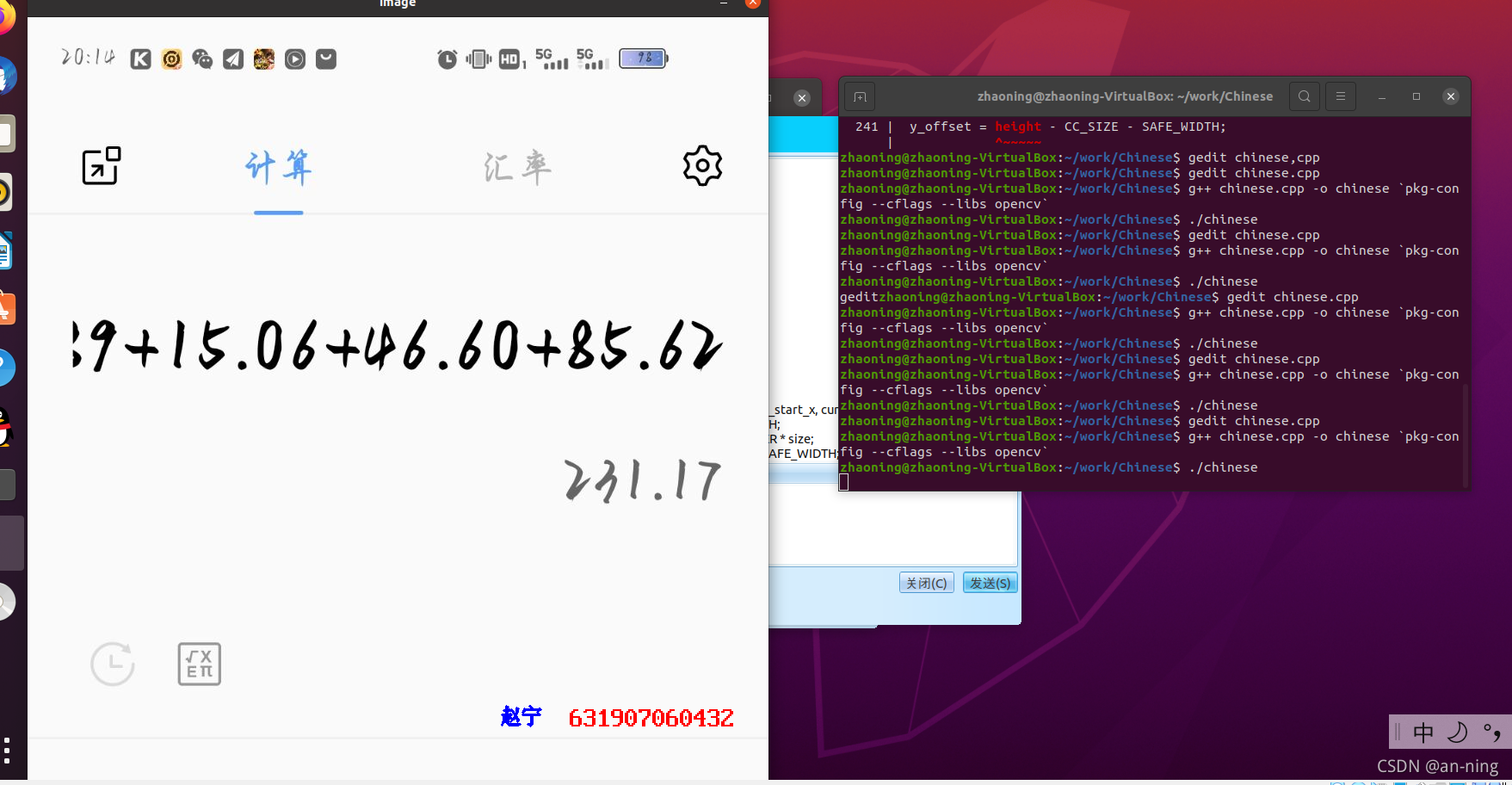
String image_path="test.jpg";
char* logo_path=(char*)"logo.txt";
put_text_to_image(20,300,image_path,logo_path);
return 0;
}
void paint_ascii(Mat& image,int x_offset,int y_offset,unsigned long offset){
//���Ƶ��������
Point p;
p.x = x_offset;
p.y = y_offset;
//���ascii��Ĥ
char buff[16];
//��ascii�ֿ��ļ�
FILE *ASCII;
if ((ASCII = fopen("Asci0816.zf", "rb")) == NULL){
printf("Can't open ascii.zf,Please check the path!");
//getch();
exit(0);
}
fseek(ASCII, offset, SEEK_SET);
fread(buff, 16, 1, ASCII);
int i, j;
Point p1 = p;
for (i = 0; i<16; i++) //ʮ����char
{
p.x = x_offset;
for (j = 0; j < 8; j++) //һ��char�˸�bit
{
p1 = p;
if (buff[i] & (0x80 >> j)) /*���Ե�ǰλ�Ƿ�Ϊ1*/
{
/*
����ԭ��ascii��Ĥ��8*16��,������,
����ԭ����һ�����ص���4�����ص��滻,
�滻�����16*32�����ص�
ps:�о�����д���������,��Ŀǰ��ʱֻ�뵽�����ַ���
*/
circle(image, p1, 0, Scalar(0, 0, 255), -1);
p1.x++;
circle(image, p1, 0, Scalar(0, 0, 255), -1);
p1.y++;
circle(image, p1, 0, Scalar(0, 0, 255), -1);
p1.x--;
circle(image, p1, 0, Scalar(0, 0, 255), -1);
}
p.x+=2; //ԭ����һ�����ص��Ϊ�ĸ����ص�,����x��y��Ӧ��+2
}
p.y+=2;
}
}
��һվ 21:54:07
void paint_chinese(Mat& image,int x_offset,int y_offset,unsigned long offset){//��ͼƬ�ϻ�����
Point p;
p.x=x_offset;
p.y=y_offset;
FILE *HZK;
char buff[72];//72���ֽ�,������ź��ֵ�
if((HZK=fopen("HZKs2424.hz","rb"))==NULL){
printf("Can't open HZKf2424.hz,Please check the path!");
exit(0);//�˳�
}
fseek(HZK, offset, SEEK_SET);/*���ļ�ָ���ƶ���ƫ������λ��*/
fread(buff, 72, 1, HZK);/*��ƫ������λ�ö�ȡ72���ֽ�,ÿ������ռ72���ֽ�*/
bool mat[24][24];//����һ���µľ�����ת�ú��������Ĥ
int i,j,k;
for (i = 0; i<24; i++) /*24x24������,һ����24��*/
{
for (j = 0; j<3; j++) /*������3���ֽ�,ѭ���ж�ÿ���ֽڵ�*/
for (k = 0; k<8; k++) /*ÿ���ֽ���8λ,ѭ���ж�ÿλ�Ƿ�Ϊ1*/
if (buff[i * 3 + j] & (0x80 >> k)) /*���Ե�ǰλ�Ƿ�Ϊ1*/
{
mat[j * 8 + k][i] = true; /*Ϊ1�Ĵ����µ���Ĥ��*/
}
else {
mat[j * 8 + k][i] = false;
}
}
for (i = 0; i < 24; i++)
{
p.x = x_offset;
for (j = 0; j < 24; j++)
{
if (mat[i][j])
circle(image, p, 1, Scalar(255, 0, 0), -1); //д(�滻)���ص�
p.x++; //����һ�����ص�
}
p.y++; //����һ�����ص�
}
}
void put_text_to_image(int x_offset,int y_offset,String image_path,char* logo_path){//������Ū��ͼƬ
//x��y���ǵ�һ������ͼƬ�ϵ���ʼ����
//ͨ��ͼƬ·����ȡͼƬ
Mat image=imread(image_path);
int length=18;//Ҫ��ӡ���ַ�����
unsigned char qh,wh;//��������,�
unsigned long offset;//ƫ����
unsigned char hexcode[30];//���ڴ�ż��±���ȡ��ʮ������,�ǵ�Ҫ������
FILE* file_logo;
if ((file_logo = fopen(logo_path, "rb")) == NULL){
printf("Can't open txtfile,Please check the path!");
//getch();
exit(0);
}
fseek(file_logo, 0, SEEK_SET);
fread(hexcode, length, 1, file_logo);
int x =550,y =800;//x,y:��ͼƬ�ϻ������ֵ���ʼ����
for(int m=0;m<length;){
if(hexcode[m]==0x23){
break;//����#��ʱ����
}
else if(hexcode[m]>0xaf){
qh=hexcode[m]-0xaf;//ʹ�õ��ֿ������Ժ��ְ���ͷ,�������Ժ��ַ��ſ�ͷ
wh=hexcode[m+1] - 0xa0;//�����
offset=(94*(qh-1)+(wh-1))*72L;
paint_chinese(image,x,y,offset);
/*
�����ں��ֿ��е�ƫ����
����ÿ������,ʹ��24*24�ĵ�������ʾ��
һ���������ֽ�,һ��24��,������Ҫ72���ֽ�����ʾ
������
�����5352
ʮ������λ3534
���������d5d4
d5-af=38(ʮ����),��Ϊ�ǴӺ��ְ���ʼ��,���Լ�ȥ����af������a0,38+15����53���������Ӧ
d4-a0=52
*/
m=m+2;//һ�����ֵĻ�����ռ�����ֽ�,
x+=24;//һ������Ϊ24*24�����ص�,������ˮƽ����,�����������ƶ�24�����ص�
}
else{//����ȡ���ַ�ΪASCII��ʱ
wh=hexcode[m];
offset=wh*16l;//����Ӣ���ַ���ƫ����
paint_ascii(image,x,y,offset);
m++;//Ӣ���ַ����ļ����ʾֻռһ���ֽ�,����������һλ������
x+=16;
}
}
cv::imshow("image", image);
cv::waitKey();
}

????2��ʹ������g++ chinese.cpp -o chinesepkg-config --cflags --libs opencv�������
????3��Ȼ��ʹ������./chinese���г���
????�ο�:https://blog.csdn.net/weixin_56102526/article/details/121178128
????????????? https://www.diangongwu.com/dianzi/160152.html