һ���洢��ϵͳ���Լ��
cortex-m ���������Զ�32λ�洢������Ѱַ,��˴洢���ռ��ܹ��ﵽ4GB���洢���ռ���ͳһ,��Ҳ��ζ��ָ������ݹ�����ͬ�ĵ�ַ�ռ䡣���ݼܹ�����,4GB�Ĵ洢���ռ䱻��Ϊ�˶����������,cortex-M3��cortex-M4�������Ĵ洢��ϵͳ֧�ֶ������:
�ٶ�����߽ӿ�,ָ������ݿ���ͬʱ����(�������ܹ�)
�ڻ���AMBA(�����������ܹ�)�����߽ӿ����,ʵ����Ҳ��һ��Ƭ�����߱�:���ڴ洢����ϵͳ������ˮ�߲�����AHB(AMBA����������)LiteЭ��,�Լ����ں͵��Բ���ͨ�ŵ�APB(����������)Э�顣
��ͬʱ֧��С�˺ʹ�˵Ĵ洢��ϵͳ��
��֧�ַǶ������ݴ���
��֧����������(���ھ���Ƕ��ʽOS��RTOS��ϵͳ���ź�������)
��λѰַ�Ĵ洢���ռ�(λ��)
�߲�ͬ�洢������Ĵ洢�����Ժͷ���Ȩ��
���ѡ�Ĵ洢��������Ԫ(MPU)����MPU����,�����������ʱ���ô洢�����Ժͷ���Ȩ�����á�
�����洢��ӳ��
��4GB��Ѱַ�Ĵ洢���ռ���,��Щ���ֱ�ָ��Ϊ�������е��ڲ�����,��NVIC�ε��Բ����ȡ���Щ�ڲ������Ĵ洢��λ���ǹ̶���,����洢���ռ��ڼܹ��ϱ�����Ϊ����ͼ��ʾ�Ķ���洢������,���ִ���ʹ��:
���������֧�ֲ�ͬ����Ĵ洢�����豸
ϵͳ���Դﵽ���ŵ�����
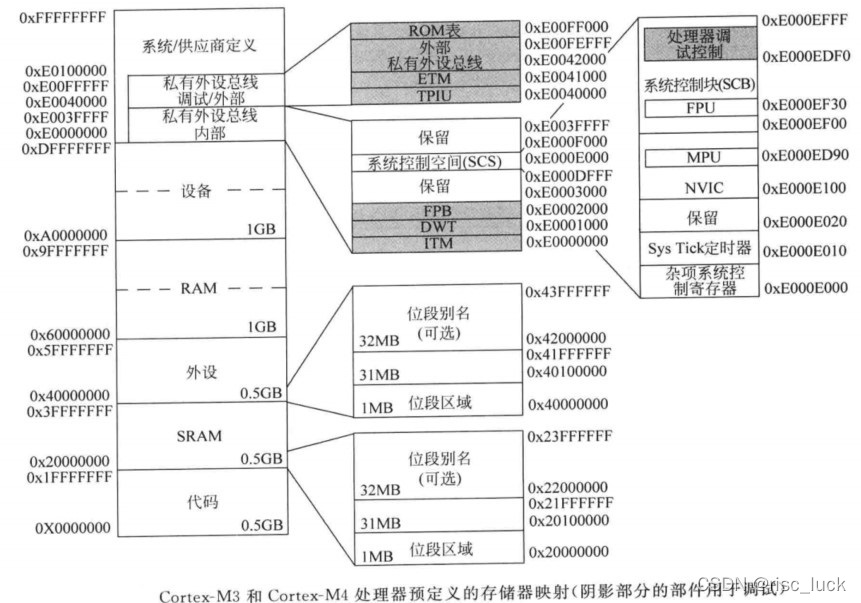
����Ԥ����Ĵ洢��ӳ���ǹ̶���,�ܹ���Ȼ���и߶ȵ������,оƬ����߿��������ǵIJ�Ʒ�м�����в��컯�IJ�ͬ�洢�����衣
| ���� | ��ַ��Χ | ���� |
|---|---|---|
| ���� | 0x00000000 ---- 0x1FFF FFFF | 512MB�Ĵ洢���ռ�,��Ҫ���ڳ������,������Ϊ����洢��һ���ֵ�Ĭ��������,������Ҳ�������ݷ��� |
| SRAM | 0X20000000 ��0X3FFFFFFF | SRAM����λ�ڴ洢���ռ��е���һ��512MB,��Ҫ��������SRAM,���ΪƬ��SRAM,�����Դ洢��������û��ʲô���ơ���֧�ֿ�ѡ��λ������,��SRAM����ĵ�һ��1M��λѰַ,�����������������ִ�г�����롣 |
| ���� | 0x40000000 �� 0x5FFFFFFF | ����洢������Ĵ�Сͬ��Ϊ512MB,���Ҷ�������Ƭ�����衣��SRAM��������,��֧�ֿ�ѡ��λ������,����������ĵ�һ��1MB�ǿ�λѰַ�ġ� |
| RAM | 0x60000000 �� 0x9FFFFFFF | RAM�����������512MB�洢������(�ܹ�1GB),����Ƭ��洢��������RAM,�ҿɴ�ų����������� |
| �豸 | 0xA0000000��0xDFFFFFFF | �豸�����������512MB�洢���ռ�(�ܹ�1GB),����Ƭ������������洢�� |
| ϵͳ | 0xE0000000 �� 0XFFFFFFFF | ϵͳ����ɷ�Ϊ��������:���ڲ�˽����������(PPB),0XE0000000 ----0XE003FFFF PPB���ڷ���NVIC ��SysTick��MPU��ϵͳ����,�Լ�Cortex-M3/M4�ڵĵ��Բ��������������,�ô洢���ռ�ֻ������������Ȩ״̬�ij��������ʡ� ���ⲿ˽����������(PPB)0XE0040000 ----0XE00FFFFF ����һ��PPB��������������Ŀ�ѡ���Բ���,оƬ��Ӧ��Ҳ���������Լ��ĵ��Ի������ض��������ô洢���ռ�ֻ������������Ȩ״̬�ij��������ʡ���Ҫע�����,�������ϵ��Բ����Ļ���ַ���ܻᱻоƬ������ġ��۹�Ӧ�̶������� 0xE0100000 �� 0XFFFFFFFF ʣ�µĴ洢���ռ����ڹ�Ӧ�̶���IJ���,������������ò��ϵ� |
���ܿ��Խ���������SRAM��RAM����ִ��,����������ڽ������ֲ���ʱЧ���������ŵ�,��ȡÿ��ָ��ʱ����Ҫһ����������ڡ����,��ͨ��ϵͳ����ִ�г������ʱ���ܻ�����һЩ���������������衢�豸��ϵͳ�洢��������ִ�С�
�洢��ӳ���д��ڶ�����ò���,����幦����������:
| ���� | ���� |
|---|---|
| NVIC | Ƕ�������жϿ����� �쳣(�����ж�)�����������жϿ����� |
| MPU | �洢��������Ԫ ��ѡ�Ŀɱ�̵�Ԫ,�������ø��洢������Ĵ洢������Ȩ�ʹ洢����������(���Ի���Ϊ),��ЩCORTEX-M3/M4�������п��ܻ�û��MPU |
| SysTick | ϵͳ���Ķ�ʱ�� 24λ��ʱ��,��Ҫ���ڲ��������Ե�OS�жϡ���δʹ��OS,���ɱ�Ӧ�ó������ʹ�� |
| SCB | ϵͳ���ƿ� ���ڿ��ƴ�������Ϊ��һ��Ĵ���,�����ṩ״̬��Ϣ |
| FPU | ���㵥Ԫ ������ڶ���Ĵ���,���ڿ��Ƹ��㵥Ԫ����Ϊ,�����ṩ״̬��Ϣ��FPU����cortex-m4�д��� |
| FPB | Flash �����Ͷϵ㵥Ԫ ���ڵ��Բ���,���а������8���Ƚ���,ÿ���Ƚ������ɱ�����Ϊ����Ӳ���ϵ��¼�������,��ִ�жϵ��ַ����ָ��ʱ,���������滻ԭ�ȵ�ָ��,��˿�Ϊ�̶��ij���ʵ�ֲ������� |
| DWT | ���ݼ��ӵ���ٵ�Ԫ ���ڵ��Ժ��ٲ���,���а������4���Ƚ���,ÿ���Ƚ������ɱ�����Ϊ�������ݼ��ӵ�ʱ��,�����ض��Ĵ洢����ַ������������ʱ���������Բ������ݸ��ٰ�,��������ʹ���Թ۲��صĴ洢��λ�� |
| ITM | ָ����ٺ굥Ԫ ���ڵ��Ժ��ٵIJ������������������������ɱ����ٽӿڲ�������ݸ��١����������ڸ���ϵͳ������ʱ����� |
| ETM | Ƕ��ʽ���ٺ굥Ԫ ���������������õ�ָ����ٵIJ��� |
| TPIU | ���ٶ˿ڽӿڵ�Ԫ �ò������Խ����ٰ��Ӹ���Դת�������ٽӿ�Э��,�������������ٵ����Ų�����ٵ����� |
| ROM�� | ROM�� ���Թ����õļ��ұ�,��ʾ���Ժ��ٲ����ĵ�ַ,�Ա���Թ���ʶ���ϵͳ�п��õĵ��Բ����������ṩ������ϵͳʶ���ID�Ĵ��� |
�������Ӵ��������洢��������
cortex-m �������ṩ�˻���AMBA��ͨ�����߽ӿڡ�AMBA֧�ֶ�������Э��,����Cortex-M3��Cortex-M4������,��Ҫ�����߽ӿ�ʹ��AHB LiteЭ��,��APBЭ��������˽����������(PPB),����Ҫ���ڵ��Բ���������APB���������߲�����������������������Ų������ӵ�ϵͳ�����ϡ�Ϊ���������,CODE�洢�������Ѿ������߽ӿڴ�ϵͳ�����ж�������,����ͼ��ʾ,�������ݷ��ʺ�ȡָ���Բ���ִ�С�
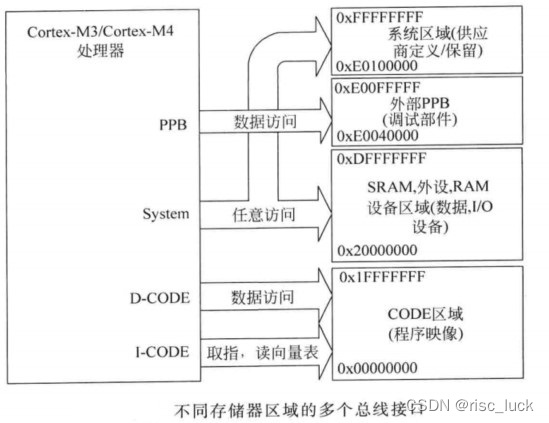
���ַ�������߽ṹ����ӿ��ж���Ӧ,������Ϊ���жϴ����ڼ�,ջ���ʺͶ�ȡ����ӳ���е�����������ͬʱִ�С�
�����ڴ����������߽ӿ��в���ȴ�״̬,���,�������е�cortex-M���������Է����ٶȽϵ͵Ĵ洢�������衣���߽ӿڻ�֧�ִ�����Ӧ������,�������˴���,������������δ�ںϷ��洢�������ڵĵ�ַʱ,����ϵͳ��Դ��������ش�����Ӧ,�����ᴥ�������쳣,�����������ڴ������ϵ�����������һ����������д�����
�ڼ������������,����洢��һ��ᱻ���ӵ�I-CODE ��D-CODE����,��SRAM��������ᱻ����ϵͳ���ߡ�cortex-m3��cortex-m4��һ�ּ��������ͼ��ʾ:
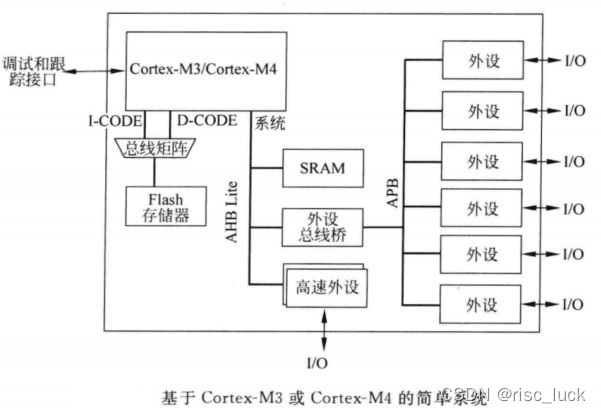
��������ͨ���ᱻ���ӵ��������������߶�,�����������е�cortex-m3 ��cortex-m4��Ʒ,������������ҵ�����������߶Ρ��������ַ�ʽ,ÿ�����߶����������ڲ�ͬ���ٶ����Խ�ʡ���ġ���Щ�����,���������Դ��������ϵͳ����(����,����ϵͳ��ʱ��Ҫ֧����̫����DMA���ʺ���USB)��
�ġ����ݶ���ͷǶ������ݷ���֧��
���ڴ洢��ϵͳΪ32λ��(���ٴӱ��ģ�͵ĽǶ�������������),��СΪ32λ��16λ�����Ƕ���Ҳ�����Dz�����ġ����봫�����˼�ǵ�ֵַΪ��С(���ֽ�Ϊ��λ)�������������ִ�С�Ķ��봫�����ִ�еĵ�ַΪ0x00000000��0x00000004����0x00001000��;���ִ�С�Ķ��봫�����ִ�еĵ�ַ��Ϊ0x00000000��0x00000002����0x00001000�ȡ�����ͷǶ��봫���ʵ������ͼ��ʾ:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-pTM7f30s-1640258996550)(D:\M4Ȩ��ָ���Ķ�����\pic\����ͷǶ���.jpg)]](https://img-blog.csdnimg.cn/87d58b16ec27475f9b0aa5cd66ba353d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_20,color_FFFFFF,t_70,g_se,x_16)
һ����˵,��������ARM������(ARM7 ARM9 ARM10)��ֻ�������봫��,�����ζ���ڷ��ʴ洢��ʱ,�ִ����ַ��bit[1]��bit[0]Ϊ0,���ִ����ַ��bit[0]Ϊ0.cortex-m3��cortex-m4��������֧����ͨ�洢������(LDR LDRH STR�Լ�STRHָ��)�ķǶ������ݴ��䡣�����һЩ����:
�ٶ����/�洢ָ�֧�ַǶ��봫��
��ջ����ָ��(PUSH/POP)�����Ƕ���ġ�
����������(��LDREX��STREX)�����Ƕ����,����ͻᴥ�������쳣(ʹ�ô���)��
��λ�β�����֧�ַǶ��봫��,��Ϊ�����Dz���Ԥ��ġ�
���Ƕ��봫�����ɴ���������ʱ,����ʵ���ϻᱻ�����������߽ӿڵ�Ԫת��Ϊ������봫�䡣���ת���Dz��ɼ���,���Ӧ�ó�����Ա���迼��������⡣�����������Ƕ��봫��ʱ,���ᱻ���Ϊ�������봫��,��˱������ݷ��ʻỨ�Ѹ����ʱ������,���ܶ���Ҫ�����ܵ����β�����������ߵ�����,ȷ�����ݴ��ں��ʵĶ������б�Ҫ�ġ�
���������,C��������������Ƕ��봫��,��ֻ������������г���:
�� ֱ�Ӳ���ָ��
�� �����Ƕ������ݵ����ݽṹ���� ��_packed�� ����
�� ����/Ƕ��ʽ������
Ҳ���Զ�Cortex-m3 ��cortex-m4��������������,ʹ�÷Ƕ��봫�����ʱ���Գ����쳣,��������Ҫ�������ÿ��ƼĴ�����UNALIGN_TRP(�Ƕ�������)λ�Լ�ϵͳ���ƿ�SCB��CCR(��ַ0xE000ED14)����������֮��,Cortex-m3 ��cortex-m4�������Ϳ����ڳ��ַǶ��봫��ʱ����ʹ�ô����쳣��������������������в��Գ����Ƿ������Ƕ��봫��dz����á�
�� λ�β���
����λ�β���,һ�μ���/�洢�������Է���(��/д)һ��λ������Cortex-m3 ��cortex-m4������,������Ϊλ�������Ԥ����洢������֧�����ֲ���,����һ��λ��SRAM����ĵ�һ��1MB,��һ����λ����������ĵ�һ��1MB���������������ͬ��ͨ�洢��һ������,���һ�����ͨ����Ϊλ�α�����һ������Ĵ洢��������з��ʡ���ʹ��λ�α�����ַʱ,ÿ��λ������ͨ����Ӧ���ֶ����ַ�����(LSB)��������,����ͼ��ʾ:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-sJebMnJW-1640258996551)(D:\M4Ȩ��ָ���Ķ�����\pic\ͨ��λ�α�������λ����.jpg)]](https://img-blog.csdnimg.cn/f0a2a92dc28943548acf06ebccadc1fb.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_20,color_FFFFFF,t_70,g_se,x_16)
����,Ҫ���õ�ַ0x20000000�������ݵĵ�2λ,����ʹ������ָ���ȡ���ݡ�����λ,Ȼ���д��֮��,������ʹ��һ��������ָ��,����ͼ��ʾ:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-LGJmkslU-1640258996553)(D:\M4Ȩ��ָ���Ķ�����\pic\ʹ�ü���ʹ��λ��д��λ�Ļ������.jpg)]](https://img-blog.csdnimg.cn/cb2e6c1ad94e43b5afd546bff68d527d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_20,color_FFFFFF,t_70,g_se,x_16)
���Ƶ�,����Ҫ����ij�洢��λ���е�һλ,λ������Ҳ���Լ�Ӧ�ó�����롣��������Ҫȷ����ַ0x20000000�ĵ�2λ,���Բ�ȡ��ͼ��ʾ�IJ���:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Wl4s60as-1640258996554)(D:\M4Ȩ��ָ���Ķ�����\pic\��ȡλ�α���.jpg)]](https://img-blog.csdnimg.cn/af4e4ca5e37c4baa89f79e43de486d27.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_19,color_FFFFFF,t_70,g_se,x_16)
��λ������,ÿ������λ�α�����ַ����32���ֵ�LSB��ʾ��ʵ�������,������λ�α�����ַʱ,�õ�ַ�ͻᱻ��ӳ�䵽λ�ε�ַ�����ڶ�����,�ֱ�������ѡ��λ��λ�ñ��Ƶ����������ݵ�LSB������д����,��д��λ���ݱ��Ƶ������λ��,Ȼ��ִ�ж��C�ġ�д������
���Խ���λ�β����Ĵ洢������������:
0x20000000 ~ 0x200FFFFFF(SRAM ,1MB)
0x40000000 ~ 0x400FFFFFF(����, 1MB)
����SRAM�洢������,λ�α�������ӳ��,���±���ʾ
| λ������ | �����ȼ� |
|---|---|
| 0x20000000 bit[0] | 0x22000000 bit[0] |
| 0x20000000 bit[1] | 0x22000004 bit[0] |
| 0x20000000 bit[2] | 0x22000008 bit[0] |
| �� | �� |
| 0x20000000 bit[31] | 0x2200007C bit[0] |
| 0x20000004 bit[0] | 0x22000080 bit[0] |
| �� | �� |
| 0x200FFFFC bit[31] | 0x23FFFFFC bit[0] |
���Ƶ�,����洢�������λ�ο���ͨ��λ�α�����ַ����,���±���ʾ
| λ������ | �����ȼ� |
|---|---|
| 0x40000000 bit[0] | 0x42000000 bit[0] |
| 0x40000000 bit[1] | 0x42000004 bit[0] |
| 0x40000000 bit[2] | 0x42000008 bit[0] |
| �� | �� |
| 0x40000000 bit[31] | 0x4200007C bit[0] |
| 0x40000004 bit[0] | 0x42000080 bit[0] |
| �� | �� |
| 0x400FFFFC bit[31] | 0x43FFFFFC bit[0] |
�ڷ���λ�α�����ַʱ,ֻ���õ����ݵ�LSB(bit[0])������,��λ�α�������ķ��ʲ�Ӧ���ǷǶ���ġ����Ƕ��������λ�α�����ַ������֧��,����Dz���Ԥ��ġ�
5.1 λ�β���������
λ�β�������������Щ��?
�ٿ���������ʵ�ִ�ͨ��Ŀ������/����˿��������豸�Ĵ������ݴ��䡣���ڴ������ݺ�ʱ���źŵķ����Ƿֿ���,���Ӧ�ó������ʵ������Ҳ�dz���
��λ�β������Լ���ת���ϡ�����,����תӦ�û���������ij��״̬�Ĵ�����һλ��ִ��,���˶�ȡ�����Ĵ���������δʹ�õ�λ���ȽϺ���ת,�����Խ�������Ϊ ͨ��λ������ȡ״̬λ(�õ�0��1)���ȽϺ���ת��
�۳��˿��������������ָ���λ�������ٶ���,M3/M4��������λ�����Ի���������Դ(��I/O�˿ڵĸ�����)����ֹһ�����̹��õ����Ρ�λ�β�������Ҫ��һ�����ƻ��ص���������ԭ���ԡ�����λ������,���Ա��⾺̬����,��Ϊ���C�ġ�дʱ��Ӳ���ȼ�ִ�е�,��ԭ���Եġ�
��λ�����Կ����ڴ洢�ʹ���SRAM�����е�Boolean���ݡ�����,���boolean���ݿɱ��ϲ���ͬһ���洢��λ����,�Խ�ʡ�洢���ռ䡣������ͨ��λ�α�����ַ����ִ�в���,��ÿ��λ�ķ�����Ȼ�Ƕ����ġ�
λ�β��������������ִ���,�ֽڴ������ִ���Ҳ����ִ�С����������ֽڷ���ָ��(LDRB/STRB)����λ�α�����ַ����ʱ,�������Ķ�λ������ķ��ʾ����ֽڴ�С�ġ����Ƶ�,��λ�α����İ��ִ���(LDRH/STRH)��ᱻ��ӳ�䵽��λ������İ��ִ�С�Ĵ��䡣
��λ�α�����ַ��ִ�з��ִ���ʱ,��ֵַ��ȻӦ�����ֶ���ġ�
5.2 C����ʵ�ֵ�λ�β���
C/C++���Ա�����֧��λ�β���������,C�������Ͳ�֪��ͬһ���洢��������������ͬ�ĵ�ַ��Ѱַ,����Ҳ���˽��λ�α����ķ���ֻ������洢��λ�õ�LSB��Ҫ��Cʵ��λ������,��ķ������Ƿֱ������洢��λ�õĵ�ַ��λ�α���������:
#define DEVICE_REG0 *((volatile unsigned long *) (0x40000000))
#define DEVICE_REG0_BIT0 *((volatile unsigned long *) (0x42000000))
#define DEVICE_REG0_BIT1 *((volatile unsigned long *) (0x42000004))
......
DEVICE_REG0 = 0XAB; //ʹ����ͨ��ַ����Ӳ���Ĵ���
...
DEVICE_REG0_BIT1 = 0x1;//����λ������ͨ��λ�α�����ַ���õ�1λ
Ҳ��������C���Եĺ궨���λ�α����ķ��ʡ�����,����ʵ��һ����,��λ�ε�ַ��λ��ת��Ϊλ�α�����ַ,����������һ���꽫��ַ��Ϊһ��ָ�������ʴ洢����ַ��
//��λ�ε�ַ��λ���ת��Ϊλ�α�����ַ
#define BIT_BAND(addr, bitnum) ((addr&0xf0000000)+0x20000000 + ((addr&0xfffff)<<5)+(bitnum<<2))
//����ַת��Ϊָ��
#define MEM_ADDR(addr) *((volatile unsigned long*)) (addr)
��������ӿ�����д����:
MEM_ADDR(DEVICE_REG0) = 0xAB; //������ͨ��ַ����Ӳ���Ĵ���
MEM_ADDR(BIT_BAND(DEVICE_REG0,1)) = 0x1; //����λ���������õ�1λ
��Ҫע�����,��ʹ��λ������ʱ,������Ҫ�����ʵı�������Ϊvolatile��C��������֪��ͬһ�����ݻ������ֲ�ͬ�ĵ�ַ����,�����Ҫ����volatile����,��ȷ����ÿ�η��ʱ���ʱ,�������Ǵ洢��λ�ö����Ǵ������ڵı��ر��ݡ�
����Ĭ�ϵĴ洢������Ȩ��
cortex-m3��cortex-m4�Ĵ�����ӳ�����Ĭ�ϵĴ洢������Ȩ������,���ڳ���(����Ȩ)����������NVIC��ϵͳ���ƴ洢���ռ䡣��û��MPU��MPU���ڵ�δʹ��ʱ��ʹ��Ĭ�ϵĴ洢������Ȩ�ޡ�
��MPU������ʹ��,MPU�������������������Ȩ��Ҳ������Ƿ������û����������Ĵ洢������
Ĭ�ϵĴ洢������Ȩ�����±���ʾ:
| �洢������ | ��ַ | �û�����ķ���Ȩ���� |
|---|---|---|
| ��Ӧ�̶��� | 0xE0100000 ~ 0xFFFFFFFF | ȫ���� |
| ROM�� | 0xE00FF000 ~ 0xE00FFFFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| �ⲿPPB | 0XE0042000 ~ 0XE00FEFFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| ETM | 0XE0041000 ~ 0XE0041FFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| TPIU | 0XE0040000 ~ 0XE0040FFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| �ڲ�PPB | 0XE000F000 ~ 0XE003FFFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| NVIC | 0XE000E000 ~ 0XE000EFFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| FPB | 0XE0002000 ~ 0XE0003FFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| DWT | 0XE0001000 ~ 0XE0001FFF | ��ֹ,����Ȩ���ʵ������ߴ��� |
| ITM | 0XE0000000 ~ 0XE0000FFF | ������,д����,�����Ƿ���Ȩ���ʼ����˿�(ʵʱ������) |
| �ⲿ�豸 | 0XA0000000 ~ 0XDFFFFFFF | ȫ���� |
| �ⲿRAM | 0X60000000 ~ 0X9FFFFFFF | ȫ���� |
| ���� | 0X40000000 ~ 0X5FFFFFFF | ȫ���� |
| SRAM | 0X20000000 ~ 0X3FFFFFFF | ȫ���� |
| ���� | 0X00000000 ~ 0X1FFFFFFF | ȫ���� |
������Ȩ���ʱ���ֹʱ,�����쳣�ͻ������������������ߴ����쳣�Ƿ�ʹ���Լ����ȼ�����,��������Ӳ����������ߴ����쳣��
�ߡ��洢����������
�洢��ӳ��������ÿ���洢�������������IJ���,���˽��������ʵĴ洢������豸��,�洢��ӳ�仹�����˷��ʵĴ洢�����ԡ�Cortex-M3��cortex-M4�������д��ڵĴ洢�����������¼���:
�ٿɻ��塣������������ִ����һ��ָ��ʱ,�Դ洢����д��������д����ִ�С�
�ڿɻ��档���洢�����õ������ݿɱ����Ƶ��洢������,�Ա��´��ٷ���ʱ���Դӻ�����ȡ�������ֵ,�������Լӿ����ִ�С�
�ۿ�ִ�С����������Դӱ��洢������ȡ����ִ�г������
�ܿɹ��������ִ洢����������ݿɱ�����������豸���á��洢��ϵͳ��Ҫȷ���ɹ����洢�������в�ͬ�������豸�����ݵ�һ���ԡ�
��ÿ��ָ������ݴ���ʱ,���������߽ӿڶ��Ὣ�洢������������Ϣ������洢��ϵͳ����MPU������MPU�������ú�Ĭ�ϵIJ�ͬ,��Ĭ�ϵĴ洢���������ûᱻ���ǡ��������еĶ���cortex-m3��cortex-m4������,ֻ�п�ִ�кͿɻ������Ի�Ӱ�쵽Ӧ�ó����ִ�С��ɻ���Ϳɹ���������һ���ɻ��������ʹ��,����ȷ���洢�����ͺͻ�����ơ����±���ʾ:
| �ɻ��� | �ɻ��� | �洢������ |
|---|---|---|
| 0 | 0 | ǿ��,cortex-m3��cortex-m4���������ڼ�����һ������ǰ�ȴ����߽ӿ��ϵĴ�����ɡ��Ӽܹ�����˵,���������Լ���ִ����һ������,������������һ��������Ϊǿ����豸�Ĵ洢���ķ��ʡ� |
| 1 | 0 | �豸������һ��ָ��Ҳ�Ǵ洢������,��cortex-m3��cortex-m4�豸������ʹ��д���崦�������ͬʱ,����ִ����һ��ָ��Ӽܹ�����˵,���������Լ���ִ����һ������,������������һ��������Ϊǿ����豸�Ĵ洢���ķ��� |
| 0 | 1 | ����дͨ(WT)�������ͨ�洢�� |
| 1 | 1 | ����д��(WB)�������ͨ�洢�� |
��ϵͳ�д��ڶ���������Լ����л�������Կ��ƵĻ��浥Ԫ����Ҫ�õ��ɹ������ԡ������ݷ�����ʾΪ�ɹ���ʱ,�����������Ҫȷ������ֵͬ�������浥Ԫ��һ�µ�,������Ϊ�����ܱ�����һ�����������沢�ġ�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-kY96wIvB-1640258996554)(D:\M4Ȩ��ָ���Ķ�����\pic\�ദ����ϵͳ�еĻ���һ������Ҫ��������.jpg)]](https://img-blog.csdnimg.cn/6ff4310b8cf1464db42e102d85316e53.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_11,color_FFFFFF,t_70,g_se,x_16)
����cortex-m3��cortex-m4�������в������ڻ���洢����������,����������Ȼ���Լ��ϻ��浥Ԫ,���������ô洢��������Ϣ����洢��������Ϊ������,����оƬ��������ʹ�õĴ洢��������,�������Կ��ܻ���Ӱ�쵽Ƭ�Ϻ�Ƭ��洢���������IJ������ɻ����������ڴ������ڲ���Ϊ���ṩ���ŵ�����,cortex-m3��cortex-m4������֧�����߽ӿ��ϵĵ����д���塣��ʹ���߽ӿ��ϵ�ʵ�ʴ�����Ҫ���ʱ�����ڲ������,�Կɻ���洢�������д�������ڵ���ʱ��������ִ��,�����������ִ����һ��ָ�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-sFJVNpBR-1640258996555)(D:\M4Ȩ��ָ���Ķ�����\pic\����д����.jpg)]](https://img-blog.csdnimg.cn/2090fbbfa9ef4415995946507721ceb9.png)
ÿ���洢�������Ĭ�Ϸ����������±���ʾ,����,XN��ʾ����ִ��,��Ҳ��ζ�ű������ڲ���������ִ�С�
| ���� | �洢��/�豸���� | XN | ���� | ��ע |
|---|---|---|---|---|
| CODE�洢������(0X00000000 ~ 0X1FFFFFFF) | ��ͨ | �� | WT | �ڲ�д����ʹ��,����Ĵ洢������ʼ��Ϊ�ɻ����Լ����ɻ��� |
| SRAM�洢������(0X20000000 ~ 0X3FFFFFFF) | ��ͨ | �� | WB-WA | д��,д���� |
| ��������(0X40000000 ~ 0X5FFFFFFF) | �豸 | Y | �� | �ɻ���,���ɻ��� |
| RAM����(0X60000000 ~ 0X7FFFFFFF) | ��ͨ | �� | WB�CWA | д��,д���� |
| RAM����(0X80000000 ~ 0X9FFFFFFF) | ��ͨ | �� | WT | дͨ |
| �豸(0XA0000000 ~ 0XBFFFFFFF) | �豸 | Y | �C | д����,���ɻ��� |
| �豸(0XC0000000 ~ 0XDFFFFFFF) | �豸 | Y | �C | д����,���ɻ��� |
| ϵͳ-PPB(0XE0000000 ~ 0XE00FFFFF) | ǿ�� | Y | �C | ���ɻ���,���ɻ��� |
| ϵͳ�C��Ӧ�̶���(0XE0100000 ~ 0XFFFFFFFF) | �豸 | Y | �C | �ɻ���,���ɻ��� |
ע��,���ڴӰ汾1��ʼ��cortex-M3�����з������cortex-M4������,��������I-CODE��D-CODE���߽ӿ��ϵ�CODE����洢�������źű�Ӳ�����ӱ�ʾΪ�ɻ���Ͳ��ɻ��塣MPU���ò��ܽ��串��,ֻ��Ӱ�쵽��������Ļ���洢��ϵͳ(��2�������ijЩ���л������ԵĴ洢��������)���ڴ�������,�ڲ�д�����Կ���������CODE�����д���塣
�ˡ���������
cortex-m3��cortex-m4��������֧��SWPָ��(����)����ָ��һ������ARM7TDMI�ȴ�ͳARM���������ź�������,Ŀǰ���ѱ��������ʲ��������
�ź��������ڸ�Ӧ�÷��乲����Դ����ij��������Դֻ������һ���ͻ��˻�Ӧ�ô�����ʱ,���ɽ����Ϊ������(MUTEX)�������������,��ij����Դ��һ������ռ��,���ͻᱻ�������������,���������ǰ�������������̡�Ҫ����MUTEX�ź���,��Ҫ��ij���洢����ַ����Ϊ����״̬,�Ա�ʾ������Դ�Ƿ��ѱ�һ�����������������̻�Ӧ��Ҫʹ����Դʱ,����Ҫ���ȼ����Դ�Ƿ��ѱ�����,��δ��ʹ��,�������������״̬,��ʾ����ԴĿǰ�ѱ����������ڴ�ͳ��ARM������,������״̬�ķ�����SWPָ��ִ��,������ȷ����д����״̬������ԭ����,������Դ����������ͬʱ������
���ڽ��µ�ARM������,��/д���ʿ��ɶ���������ִ�С�����,�����������������еĶ�д����Ҫλ��ͬһ������,���SWPָ������֤�洢�����ʵ�ԭ����,��������Ҳ�ͱ���������ȡ���ˡ��������ʲ����������൱��,������SWP��ͬ��������������,�ź����Ĵ洢��λ�ñ���һ�����������豸��ͬһ�������������е���һ�����̷���Ҳ�����˿�����,����ͼ��ʾ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-9qmiUMrF-1640258996556)(D:\M4Ȩ��ָ���Ķ�����\pic\mutex�ź�����������.jpg)]](https://img-blog.csdnimg.cn/29eb8915416a48c1b8ccc22759e061ef.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_20,color_FFFFFF,t_70,g_se,x_16)
�����������������֮һ,����д(��STREX)���ܻ�ʧ��:
��ִ����CLREXָ��
�ڲ������������л�(���ж�)
��ǰ��û��ִ�й�LDREX
���ⲿӲ��ͨ�����߽ӿ��ϵıߴ��ź���������������ʧ��״̬
�������洢�õ�һ��ʧ��״̬,��洢���в������ʵ�ʵ�д����,��Ϊ�������Ѿ����������ں˻��ⲿӲ����ֹ��
Ҫʹ�����������ڶദ������������������,��Ҫ��������һ����Ϊ���������ص�Ӳ�����ü�ػ��鵽������ַ�Ĵ���,����֪���������������Ƿ�ɹ������������߽ӿڻ�����ṩ�˶���Ŀ����ź�,�Ա������δ����Ƿ�Ϊ�������ʡ�
���洢���豸�ѱ���һ���������豸����,�Ҵ���������������д֮��,�ڴ�������ͼ��������дʱ,�������ʼ�ػ�ͨ������ϵͳ����һ������ʧ��״̬�������Ὣ����д�ķ���״̬��1,��������дʧ�ܵ�����,�������ʼ�ػ���ֹд��������������ʵ�ַ��
cortex-m3��cortex-m4�������е���������ָ�����LDREX(��)��LDREXB(�ֽ�)��LDREXH(����)��STREX(��)��STREXB(�ֽ�)�Լ�STREXH(����)�����ʵ��������ʾ:
LDREX <Rxf>, [Rn, #offset]
STREX <Rd>, <Rxf>, [Rn, #offset]
����,RdΪ����д�ķ���״̬(0Ϊ�ɹ�, 1λʧ��)��
��ʹ����������ʱ,����MPU��������Ϊ�˿ɻ����,Ҳ����ʹ�ô��������߽ӿ��ϵ�д���塣��������ȷ�������洢���е��ź�����Ϣ�������µ�,�����ָ��������豸���һ���ԡ�����cortex-M3��cortex-M4���жദ����SOC��Ƶ���ԱӦ��ȷ���ڳ�����������ʱ,�洢��ϵͳ�����ݵ�һ���ԡ�
�š��������еĴ洢��ϵͳ
���������������豸,����л������������Ĵ洢��ϵͳ����,����:bootloader���洢����ӳ�䡢�洢����������Щ�����ڴ������в�����,��ͬ��Ӧ�̵���������ʵ�ַ�ʽ����������,ʹ��ȫ����Щ���Կ�����ߴ洢��ӳ�䴦��������ԡ�
���������,���˿��Դ�ų������ij���洢����(��FLASH),���������ܻ�����һ��������ROM,��������FLASHҲ�����Dz����ĵ���ĤROM����Щ�����ij���洢��һ������һ��BootLoader,��Ҳ�����Լ���Ӧ�ó���ʼǰִ�еij���
оƬ�����Ա��BootLoader����ϵͳ�е�ԭ���Ƕ��ġ�����:
���ṩFLASH��̹���,�����Ϳ�������һ����UART�ӿ������FLASH,���ߵ���������ʱ,���Լ���Ӧ�ó����б��Flash�洢����ijЩ���֡�
���ṩͨ��Э��ջ�ȶ���Ĺ̼�,�ɱ�����������Աͨ��API���á�
���ṩоƬ���õ��Լ칦��(BIST)��
���ھ���BootLoader ROM��оƬ,��ϵͳ��ʼʱִ��BootLoader,��˵�ϵͳ���ϵ�����ʱ������Ҫλ�ڵ�ַ0��������,��ϵͳ�´�����ʱ,���ܻ���Ҫ�ٴ�ִ��BootLoader����Flash��ֱ������Ӧ�ó���,�����Ҫ�Ĵ洢��ӳ�䡣
Ϊ�˴ﵽ���Ŀ��,��ַ��������ҪΪ�ɱ�̵�,����ʹ��Ӳ���Ĵ���(��ϵͳ���Ƶ�Ԫ�е�����Ĵ���)��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-suM1W24U-1640258996556)(D:\M4Ȩ��ָ���Ķ�����\pic\���п����ô洢��ӳ��ļ洢��ϵͳ.jpg)]](https://img-blog.csdnimg.cn/7d60b2d2259849328d523108b99a53b9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_13,color_FFFFFF,t_70,g_se,x_16)
�л��洢��ӳ��IJ������������洢����ӳ�䡱,�ò�����BootLoaderʵ�֡�����,�����л��洢��ӳ���ͬʱ��ת��BootLoader����λ��,���,������һ�ֱ����������ķ�����ͨ���洢����ַ����,���BootLoader��ROM���Դ�������ͬ�Ĵ洢��������ʡ�һ����˵,BootLoader�ɴӵ�ַ0���ô洢����ַ�������з���,���Ҹñ����ɱ��رա����ܵĴ洢�������кܶ���,��ͼ�����е�һ�ֿ��ܡ�����һЩ������,����BootLoaderλ�ڵ�ַ0,ÿ��ϵͳ����ʱ����ִ��,���������д洢����ӳ�䡣�������������ô������ṩ���������ض�λ���Խ����ض�λ,����ڴ���ȡ����ʱҲ���������ӳ�䡣
(��ϵͳ���Ƶ�Ԫ�е�����Ĵ���)��
![[����ͼƬת����...(img-suM1W24U-1640258996556)]](https://img-blog.csdnimg.cn/c0082f12e67d41afa0f5afadccaa259e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAcmlzY19sdWNr,size_20,color_FFFFFF,t_70,g_se,x_16)
��ע:�ο�ARM Cortex-M3��Cortex-M4Ȩ��ָ��