1.写在前面
前面的博客的我们已经介绍了大部分的指令了,这个时候我们需要了解一下MIPS指令和X86指令,也就是把计算机组成的第二章剩下的部分给整理完。
2.以C排序程序为例的汇总整理
2.1swap过程
交换的代码如下:
void swap(long long int v[], size_t k){
long long int temp;
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
}
当手动把C程序翻译成汇编语言时,具体的步骤如下:
- 为程序中的变量分配寄存器
- 为过程题生成汇编代码
- 保存过程调用间的寄存器
swap的寄存器分配
RISC-V的参数传递默认使用寄存器x10到X17。由于swap只有两个参数v和k,因此可以在寄存器x10和x11中保存。唯一的一个变量是temp,我们用寄存器X5来保存它,因为swap是一个叶过程。
swap过程体的代码
swap剩下的C代码如下所示:
temp = v[k];
v[k] = v[k+1];
v[k+1] = temp;
RISC-V的内存地址是字节寻址,因此双字实际上相差8个字节。因此,在将索引k与地址相加之前,需要将索引k乘以8。忘记相邻的双字地址间相差8而不是1是汇编语言编程中常见的错误。
因此,第一步是通过左移3位使k乘8以得到v[k]的地址:
slli x6,x11,3 // reg x6 = k * 8(8=2^3)
add x6,x10,x6 // reg x6 = v + (k*8)
现在我们使用X6加载v[k],然后通过向x6加8来加载v[k+1]:
ld x5,0(x6) // reg x5(temp) = v[k]
ld x7,8(x6) // reg x7 = v[k+1]
// refers to net element of v
接下来,我们将x5和x7中的值存储到交换的地址:
sd x7,0(x6) // v[k] = reg x7
sd x5,8(x6) // v[k+1] = reg x5 (temp)
剩下的是保存swap程序中使用过的保留寄存器。因为在这个叶过程没有使用保留寄存器,所以没有需要保存的寄存器。
完整的swap的过程
swap:
slli x6,x11,3 // reg x6 = k * 8(8=2^3)
add x6,x10,x6 // reg x6 = v + (k*8)
ld x5,0(x6) // reg x5(temp) = v[k]
ld x7,8(x6) // reg x7 = v[k+1]
sd x7,0(x6) // v[k] = reg x7
sd x5,8(x6) // v[k+1] = reg x5 (temp)
jalr x0,0(x1) //return to calling routine
2.2sort过程
我们将构建一个调用swap过程的例程。这个程序使用冒泡或交换排序对整数数组进行排序,这是最简单的排序之一,但不是最快的排序。先看下面的代码,具体的如下:
void sort(long long int v[], size_t int n){
size_t i,j;
for(i = 0; i < n; i += 1){
for(j = i - 1; j >= 0 && v[j] > v[j+1]; j -= 1){
swap(v.j);
}
}
}
sort的寄存器分配
过程sort的v和n两个参数保存在参数寄存器x10和x11中,我们将寄存器X19分配给i,并将x20分配给j。
sort过程体的代码
过程体由两个嵌套的for循环和一个包含参数的swap调用组成。让我们从外而内展开代码。
第一个翻译步骤是第一个for循环:
for(i = 0; i < n; i += 1){
回想一下,C的for语句有三个部分:初始化、循环判断和循环增值。只需要一条指令就可以将i初始化为0,这是for语句的第一部分:
li x19,0
然后还需要一条指令来递增i,即for语句的最后一部分:
addi x19,x19,1 // i += 1
如果i < n非真,则应该退出循环,换句话说,如果 i >= n,则应该退出。此判断只需一条指令:
forltst: bge x19,x11, exitl // go to exit1 if x19 >= x1(i >= n)
循环的底部只是跳转回到循环判断处
j forltst //branch to test of outer looop
exit1:
那么第一个for循环的代码框架是
li x19,0
forltst: bge x19,x11, exitl // go to exit1 if x19 >= x1(i >= n)
addi x19,x19,1 // i += 1
j forltst //branch to test of outer looop
exit1:
第二个for循环的c语句如下:
for(j = i - 1; j >= 0 && v[j] > v[j+1]; j -= 1){
该循环的初始部分仍然是一条指令:
addi x20,x19,-1 // j = i - 1
循环结束时j的自减也是一条指令:
addi x20,x20,-1 // j -= 1
循环判断有两个部分。如果任一条件为假,我们退出循环,因此如果第一个判断(j < 0)为假则必须退出循环:
for2tst:
blt x20,x0,exit2 // go to exit2 if x20 < 0 (j<0)
该分支将跳过第二个条件判断。如果没有跳过,则j>=0
如果第二个判断v[j] > v[j+1]非真,或者如果v[j] <= v[j+1],则先退出。首先,我们通过将j乘以8来穿件地址并将其加到v的基础上:
slli x5,x20,3 // reg x5 = j * 8
add x5,x10,x5 // reg x5 = v + (j * 8)
现在我们加载v[j]:
ld x6,0(x5) // reg x6 = v[j]
因为我们知道第二个元素是紧跟的一个双字,所以,将寄存器X5中的地址加8,得到v[j+1]
ld x7,8(x5) //reg x7 = v[j+1]
我们判断v[j] <= v[j+1] 以退出循环:
ble x6,x7,exit2 //go to exit2 if x6 <= x7
循环的底部跳转回到内循环的判断处:
j for2tst //branch to test of inner loop
将这些部分结合到一起,第二个for循环的代码的框架是这样的:
add x20,x19,-1 //j = i - 1
for2tst: blt x20,x0,exit2 //go to exit2 if x20 < 0 (j < 0)
slli x5,x20,3 // reg x5 = j * 8
add x5,x10,x5 // reg x5 = v + (j * 8)
ld x6,0(x5) // reg x6 = v[j]
ld x7,8(x5) // reg x7 = v[j + 1]
ble x6,x7,exit2 // go to exit2 if x6 <= x7
addi x20,x20,-1 // j -= 1
j for2tst // branch to test of inner loop
exit2:
sort中的过程调用
下一步是翻译第二个for循环的循环体:
swap(v.j)
调用swap很容易:
jal x1,swap
sort中的参数传递
当传递参数时问题就出现了,因为sort过程需要寄存器x10和x11中的值,但swap过程需要将其参数放在哪些相同的寄存器中。一种解决方案是在过程较早的地方将sort中参数复制到其他寄存器中,使得寄存器X10和x11在调用swap时可用。我们首先在过程中将x10和x11复制到x21和x22:
mv x21,x10 // copy parameter x10 into x21
mv x22,x11 // copy parameter x11 into x22
然后用这两个指令将参数传递到swap:
mv x10,x21 //first swap paramerter is v
mv x11,x20 // second swap parameter is j
保留sort中的寄存器
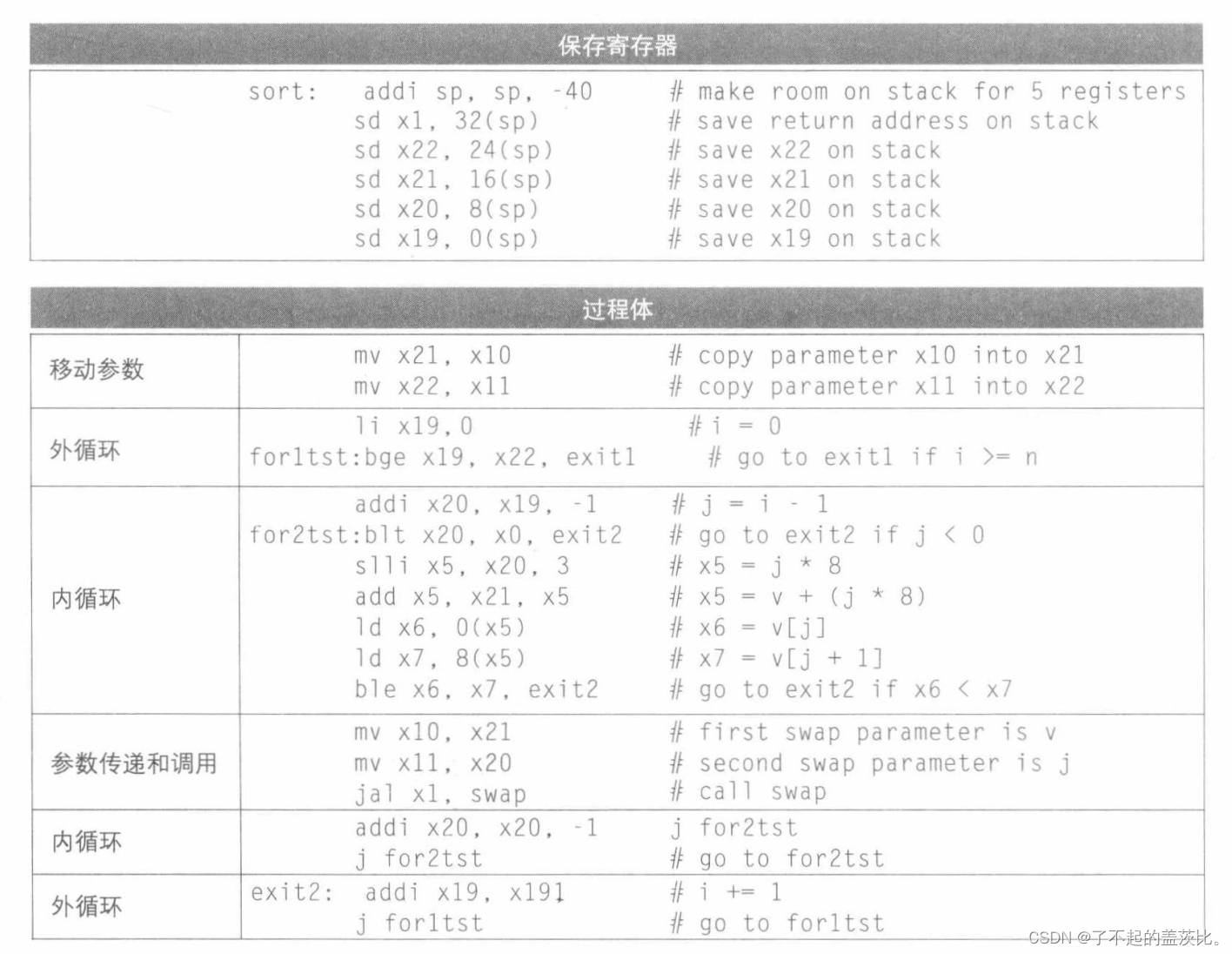
唯一剩下的代码是寄存器的保存和恢复。显然,我们必须在寄存器x1中保存返回地址,因为sort是一个过程并且调用自己。sort过程还使用被调用者保存的寄存器x19、x20、x21和x22,因此必须保存它们。所以sort的过程头如下:
addi sp,sp -40 // make room on stack for 5regs
sd x1,32(sp) // save x1 on stack
sd x22,24(sp) // save x22 on stack
sd x21,16(sp) // save x21 on stack
sd x20,8(sp) // save x20 on stack
sd x19,0(sp) // save x19 on stack
过程尾简单地反转所有这些指令,然后加一个jalr以便返回。
完成的sort过程
现在我们将所有部分放在一起,注意在for循环中用寄存器x21和x22替换对寄存器X10和X11的引用。再一次,为了使代码更容易理解,我们用过程中的每个代码块的用途来标识它们。

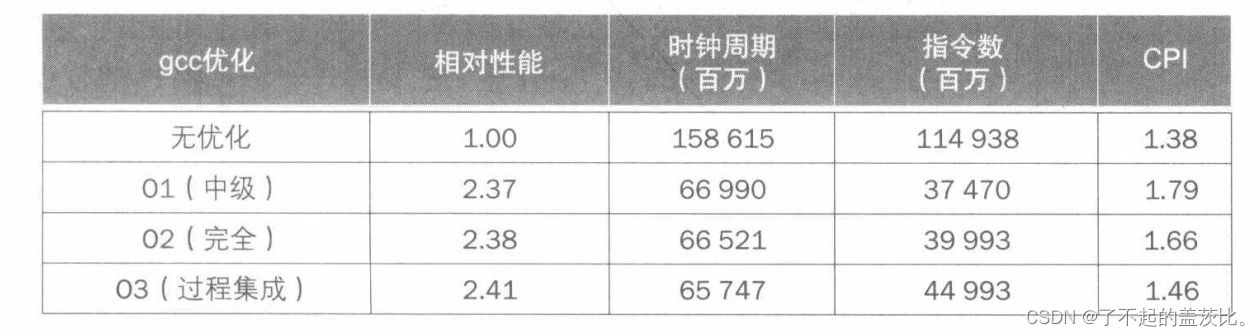
这个例子中一个有效的优化是过程内联。在调用swap过程的代码出现的地方,编译器将从swap过程体中复制代码,而不是传递参数和使用jal指令调用代码。在这个例子中,内联将避免使用四条指令。内联优化的缺点是如果从多个地方调用内联过程,编译后的代码会增大。如果因此增加了cache失效率,这样的代码扩展可能导致性能较低。
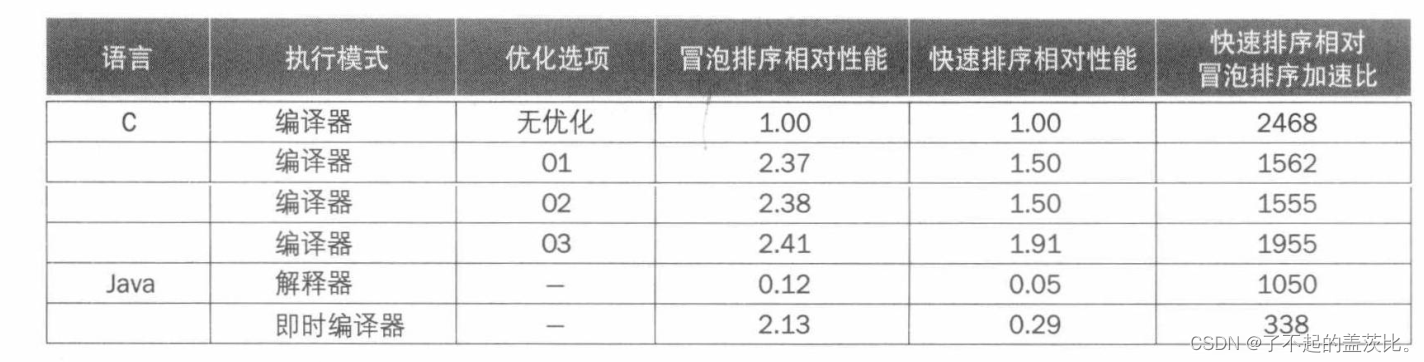
注意:JVM版本是sun 1.3.1,JIT版本是sun Hotspot 1.3.1
3.数组和指针
通过比较使用数组和数组下标的汇编代码与使用指针的汇编代码,可以从本质上理解指针。本节展示了清除内存中一个双字序列的两个过程的C和RISC-V汇编版本:一个使用数组下标,另一个使用指针。具体的代码如下:
clear1(long long int array[], size_t int size){
size_t i;
for(i = 0; i < size; i += 1){
array[i] = 0;
}
}
clear2(long long int *array,size_t int size){
long long int *p;
for(p = &array[0]; p < &array[size]; p = p + 1)
*p = 0;
}
3.1用数组实现clear
假设两个参数Array和size分别在寄存器X10和x11中,并且给i分配寄存器X5
for循环的第一部分,id初始化是很简单的:
li x5,0 // i = 0(register x5 = 0)
要将array[i]设置为0,必须首先获取其地址。先将i乘以8得到字节地址:
loopl:slli x6,x5,3 // x6 = i * 8
由于数组的起始地址在寄存器中,必须使用加法指令将其加到下标中以获取array[i]的地址:
add x7,x10,x6 // x7 = address of array[i]
最后,即可将0存到改地址:
sd x0,0(x7) //array[i] = 0
这条指令是循环体的结尾,因此下一步是增加i值:
addi x5,x5,1 // i = i + 1
循环测试检测i是否小于size:
blt x5,x11,loop1 // if (i < size) go to loop1
现在已经得到了程序所有片段。具体的代码如下:
li x5,0 // i = 0
loopl:slli x6,x5,3 // x6 = i * 8
add x7,x10,x6 // x7 = address of array[i]
sd x0,0(x7) //array[i] = 0
addi x5,x5,1 // i = i + 1
blt x5,x11,loop1 // if (i < size) go to loop1
3.2用指针实现clear
使用指针的第二个过程给两个参数Array和size分别分配寄存器x10和x11,并给p分配寄存器X5。第二个过程的代码首先吧指针p赋值为数组第一个元素的地址:
mv x5,x10 // p = address of array[0]
以下代码是for循环体,将0存入p:
loop2:sd x0,0(x5) // memory[p] = 0
这条指令实现循环体,因此以下代码迭代增加,即修改p以指向下一个双字:
addi x5,x5,8 // p = p + 8
在C语言中,指针自增1意味着将指针移动到下一个序列对象。由于p是声明为long long int 的指向整数的指针,且每个整数占用8个字节,所以编译器将p增加8.
接下来是循环测试。首先计算Array的最后一个元素地址。先将Size乘以8得到它的字节地址:
slli x6,x11,3 //x6 = size * 8
然后将乘积加上数组的初始地址得到数组之后的第一个双字的地址:
add x7,x10,x6 //x7 = address of array[size]
循环测试只需要判断p是否小于array的最后一个元素:
bltu x5,x7,loop2 // if (p < &array[size]) go to loop2
完成所有片段后,可以给出将数组清零的指针版的代码:
mv x5,x10 // p = address of array[0]
loop2:sd x0,0(x5) // memory[p] = 0
addi x5,x5,8 // p = p + 8
slli x6,x11,3 //x6 = size * 8
add x7,x10,x6 //x7 = address of array[size]
bltu x5,x7,loop2 // if (p < &array[size]) go to loop2
注意,该程序在循环的每次迭代中均计算数组末端地址,即使它没有改变。更快的代码版本是将该计算移出循环:
mv x5,x10 // p = address of array[0]
addi x5,x5,8 // p = p + 8
slli x6,x11,3 //x6 = size * 8
loop2:sd x0,0(x5) // memory[p] = 0
add x7,x10,x6 //x7 = address of array[size]
bltu x5,x7,loop2 // if (p < &array[size]) go to loop2
3.3比较两个版本的clear
数组版的循环内必须具有"乘"和加,因为i增加了,每个地址必须由新的下标重新计算。指针版直接增加指针p。指针版本吧实现缩放的移位操作和数组相关的加法操作移到循环外,从而将每次迭代执行的指令从5条减少到3条。这种手动优化对应于强度削弱和循环变量消除的编译器优化。
4.MIPS指令
MIPS指令和RISC-V指令的共同特性:
- 对于两种体系结构,所有指令都是32位宽。
- 两者均有32个通用寄存器,其中一个寄存器硬连线为0。
- 访问内存的唯一方法是通过两种体系结构的加载和存储指令。
- 与其他一些体系结构不同,在MIPS或RISC-V中,没有可以加载或存储许多寄存器的指令。
- 两者都具有寄存器等于零跳转和寄存器不等于零跳转的分支指令。
- 两个指令系统的寻址模式都适用于所有字长。

它们主要区别之一就是除相等或不等娃外的条件分支。RISC-V提供分支指令来比较两个寄存器,而MIPS提供的比较指令,该指令根据比较是否为真将寄存器设为0或1。接着,程序员根据预期比较结果,在该比较指令后跟上一条等于或不等于零的分支指令。
5.X86指令
兼容性这个金手指对x86的影响,因为每一个阶段存在的软件基础都至关重要,不会因重大体系结构变化而使其受到危害。
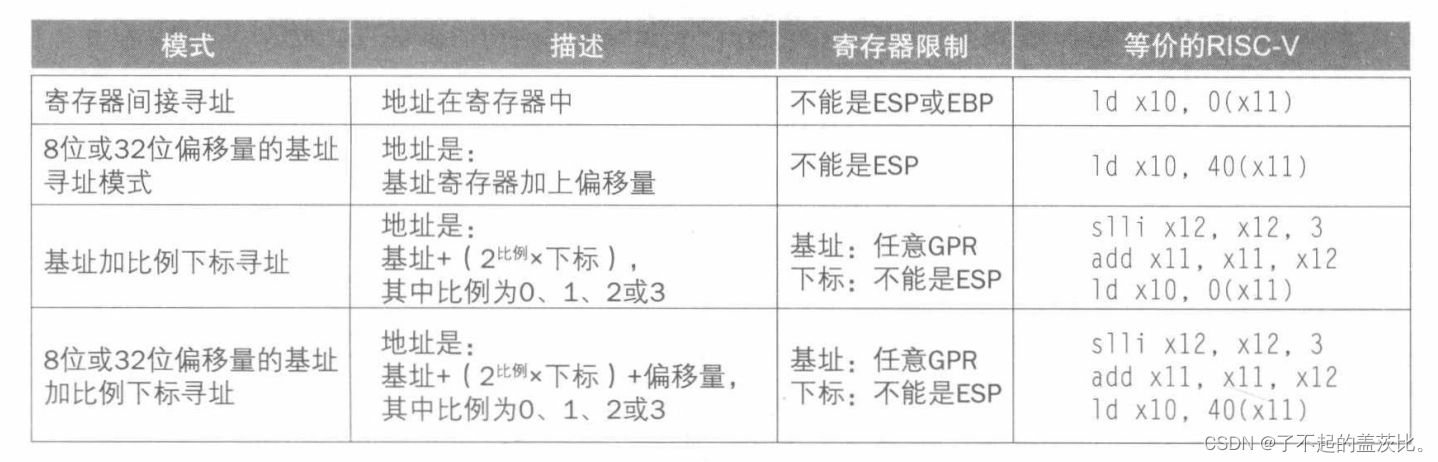
5.1x86寄存器和寻址模式
80386将所有16位寄存器(段寄存器外)扩展为32位,给名称加上前缀E来表示32位版本。通常被称为GPR。80386只包含8个GPR。


5.2X86整数操作
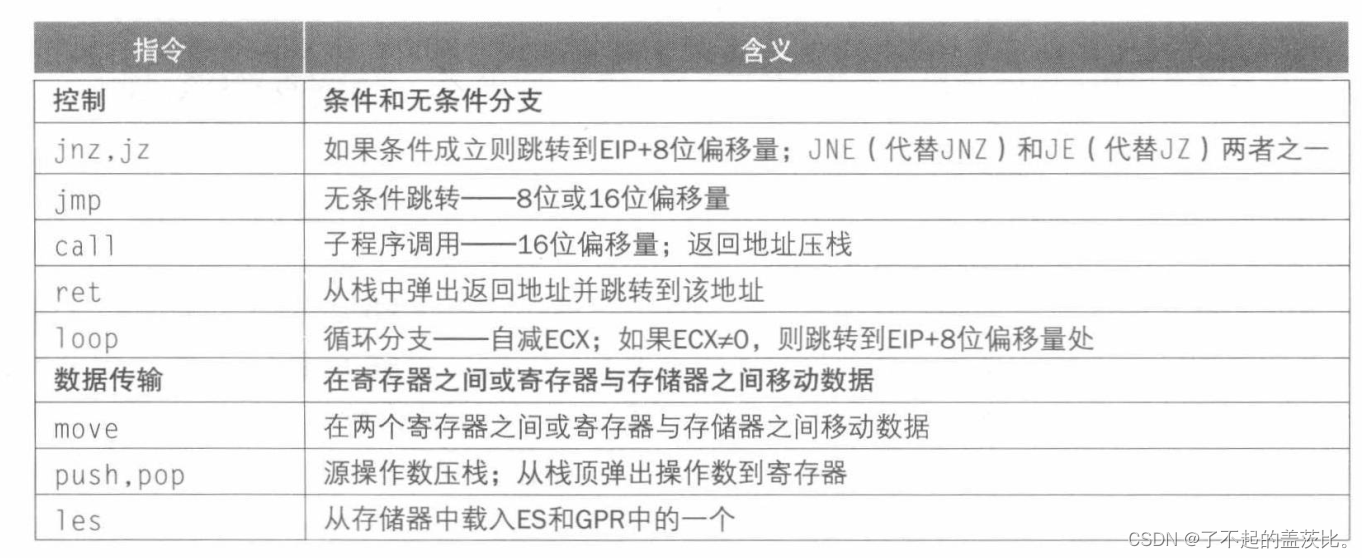
x86整数运算可分为四大类:
- 数据传送指令,包括move、push和pop
- 算术和逻辑指令,包括测试、整数和小数算术运算
- 控制流,包括条件分支、无条件分支、调用和返回
- 字符串指令,包括字符串传送和字符串比较。
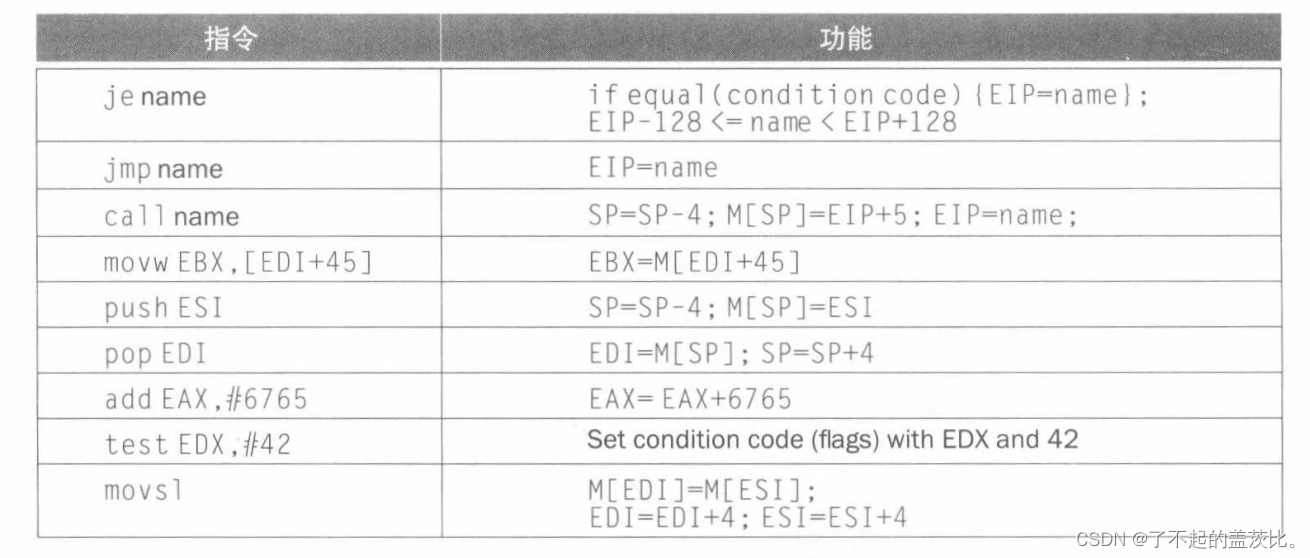

5.3X86指令编码
80386中的指令编码很复杂,有很多不同的指令格式。当只有一个操作数时,80386的指令可能从1个字节到15个字节。
6.RISC-V指令系统的剩余部分
将指令系统划分为一个基本体系结构和几个扩展体系。每个都用字母表中的字母命名,基本体系结构命名为I,表示整数。相当于当今其他流行指令系统,该基本体系结构仅有极少数指令。

第一条指令为auipc,用于PC相对存储器寻址。与lui指令一样,它保存一个20位的常数,对应于整数的第12位到第31位。auipc用于将该数与PC相加并将结果写入寄存器。结合addi这样的指令,可以寻址4GB内的存储器的任意字节。这个特征对于位置无关代码非常有用,无论从存储器的何处加载可以正确执行。最常见用于动态链接库。
接下来的四条指令比较两个整数,然后将比较后的布尔结果写入寄存器。slt和sltu分别将两个寄存器作为有符号和无符号进行比较,如果第一个值小于第二个值,则将1写到寄存器,否则写0。slti和sltiu执行相同的比较,但它们的第二个操作数为立即数。
这就是基本体系结构,最后我们再来看看另外五个标准扩展。
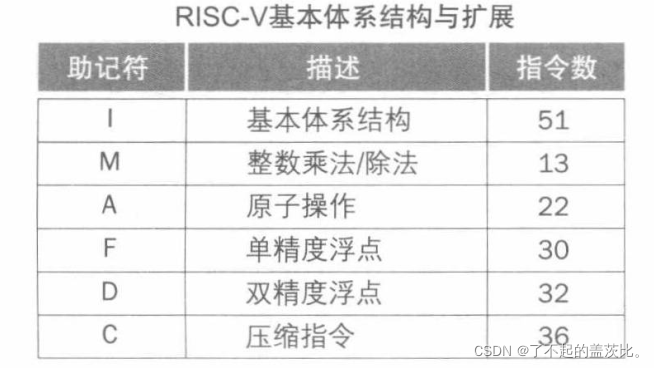
第一个命名为M,添加整数乘法和除法指令
第二个扩展为A,支持多处理器同步的原子存储器操作。
第三和第四扩展F和D提供浮点数操作。
最后一个扩展C不提供任何新功能。
总而言之,RISC-V的基本体系结构及其扩展共有184条指令一级13条系统指令。
7.谬误与陷阱
谬误:更强大的指令意味着更高的性能。
谬误:用汇编语言编程以获得最高性能
谬误:商用计算机二进制兼容的重要性意味着成功的指令系统无须改变。
陷阱:忘记在字节寻址的机器中,连续的字或双字地址相差不为1。
陷阱:在变量的定义过程外,使用一个指针指向该变量。
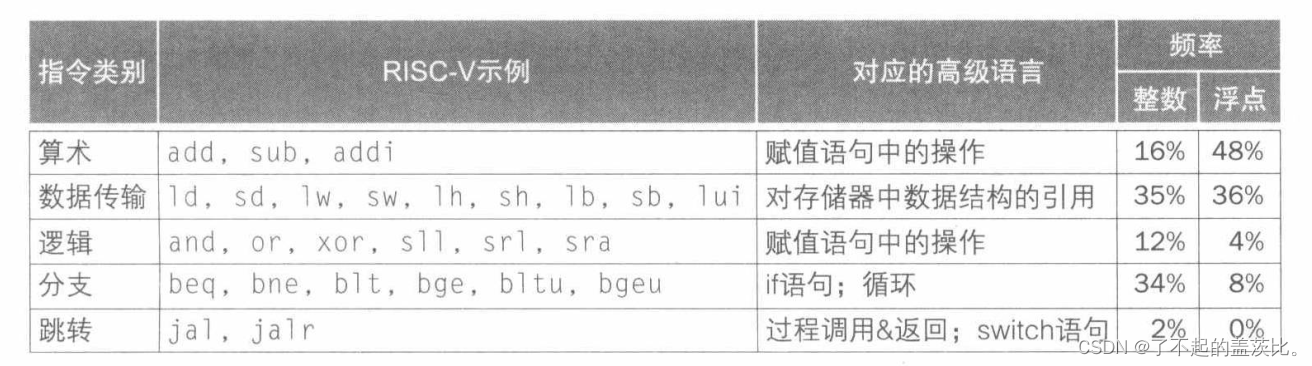
8.指令总结
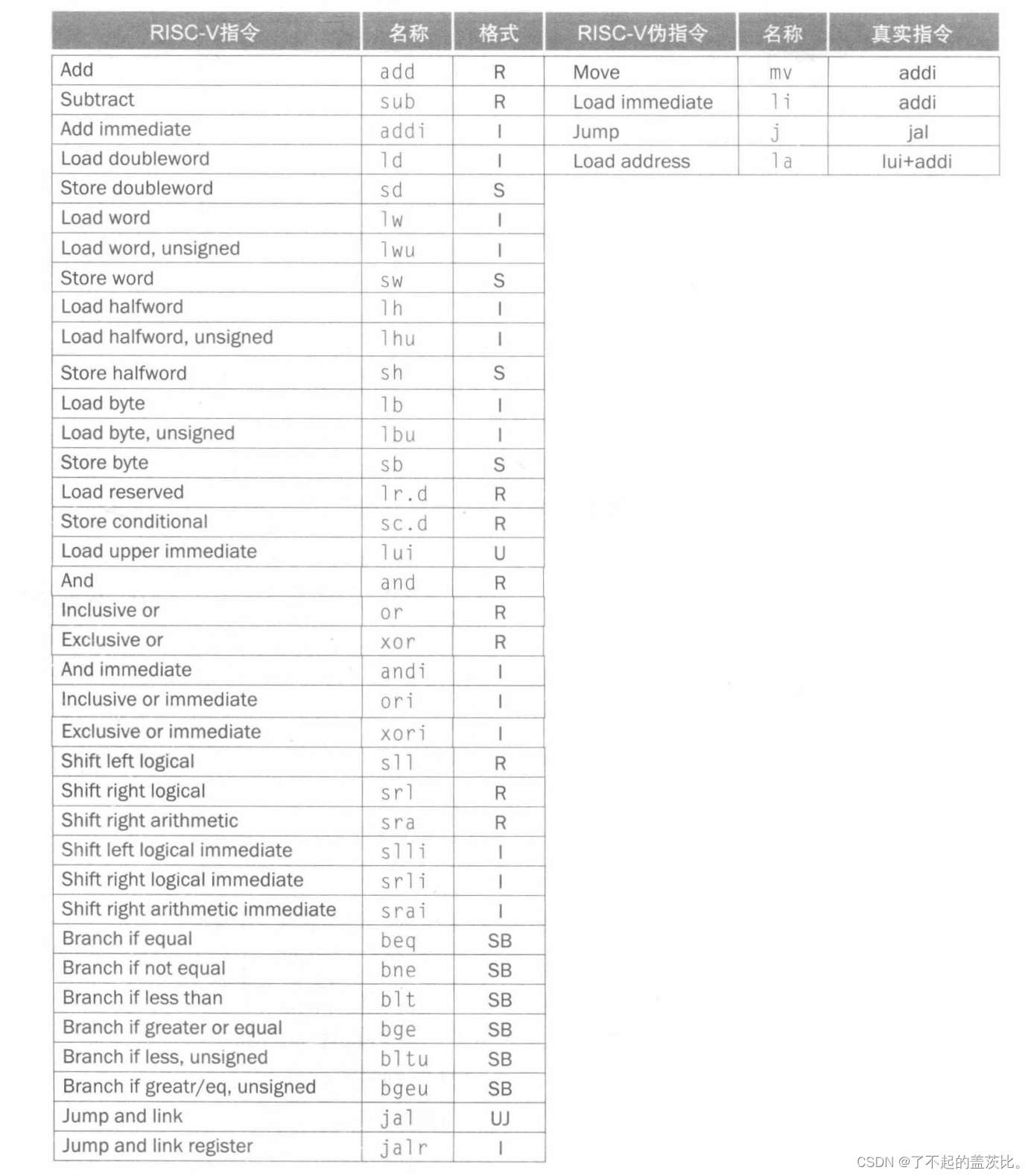
左边是真实的指令,右边是伪指令。
每种类型的RISC-V指令与编程语言中出现的结构相关:
- 算术指令对应于赋值语句的操作
- 传输指令最有可能发生在处理数组或结构体等数据结构时。
- 条件分支用于if语句和循环中。
- 无条件分支用于过程调用和返回,以及case/switch语句。
8.写在最后
本篇博客我们已经介绍完了计算机组成的第二章的指令,下篇博客主要介绍计算机的算术运算。