序言
最近手上拿到一块jetson TX2的板子,通常情况下,nvidia系列的产品部署的话Tensorrt无疑是首选,因为之前写过关于ncnn在arm板子上部署的项目,当时用的是rk系列的板子,无法调用板子上的gpu进行推理,主要原因还是Vulkan支持的问题,刚好jetson系列的板子是arm linux系统,且是支持vulkan驱动的,所以理论上是可以调用GPU进行推理的,尽管目前ncnn vulkan支持的op算子和性能都不太友好,听说up已经在优化这块了,出于对ncnn使用gpu推理速度的遐想,决定在之前的项目基础之上尝试ncnn分别使用cpu和gpu的推理速度对比。
一、ncnn vulkan
ncnn在调用gpu时,必需要有vulkan的支持,所以在尝试之前要确保已经正确安装了vulkan SDK,当然了,在jetson系列的板子上,系统刷好后,vulkan是默认安装好的,可以使用vulkaninfo命令进行查看,对于vulkan在其他平台的支持情况,可以在vulkan支持设备列表中进行查找:
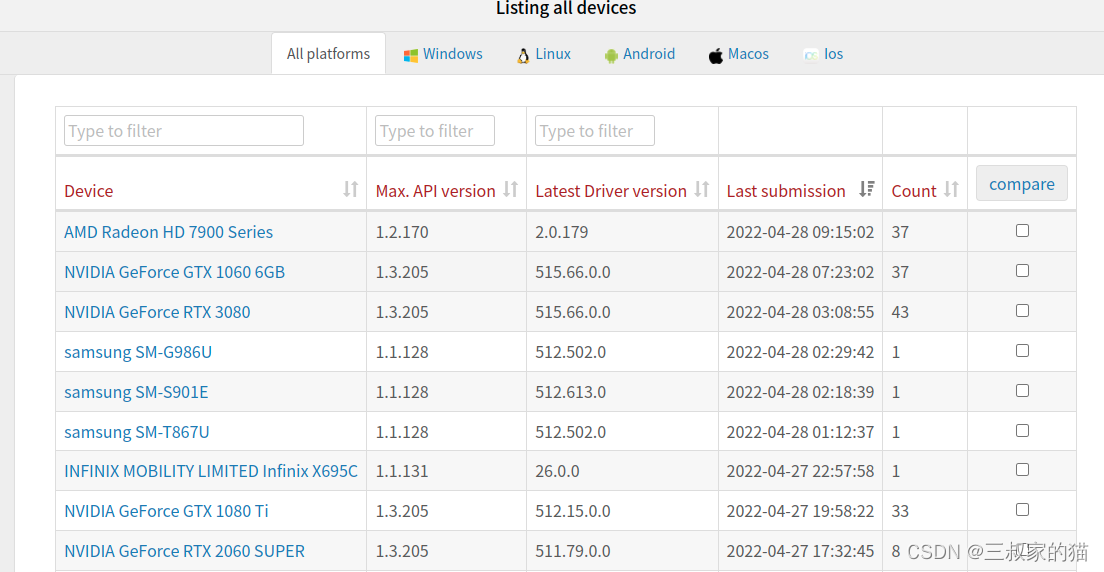
查看tx2的支持情况,可以看到:
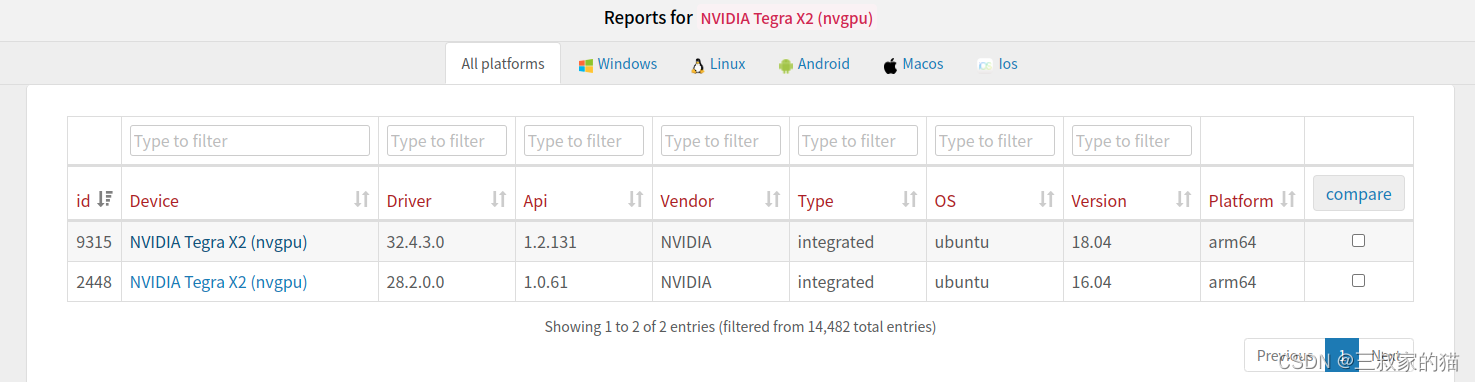
其他平台的vulkan SDK包下载地址:https://vulkan.lunarg.com/sdk/home
二、编译ncnn
确保平台支持vulkan后,接下来要编译ncnn,因为板子上有cmake编译机制,所以可以直接在板子上编译,无需交叉编译,进入tx2系统的终端命令行中,使用如下命令进行编译:
git clone https://github.com/Tencent/ncnn.git
cd ncnn
git submodule update --init
cd ncnn
mkdir -p build
cd build
cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=../toolchains/jetson.toolchain.cmake -DNCNN_VULKAN=ON -DNCNN_BUILD_EXAMPLES=ON ..
make -j$(nproc)
make install
因为有之前的项目代码基础,编译完后只需要关注build/install目录下的include和lib文件夹即可,这里要替换之前没编译vulkan时的文件,往下在CMakeList.txt文件中会指出。
编译完后可以将ncnn/benchmark目录下的权重文件全部拷贝到ncnn/build/benchncnn进行基准测试,首先是cpu运行情况,使用命令./benchncnn 1 1 0 -1:
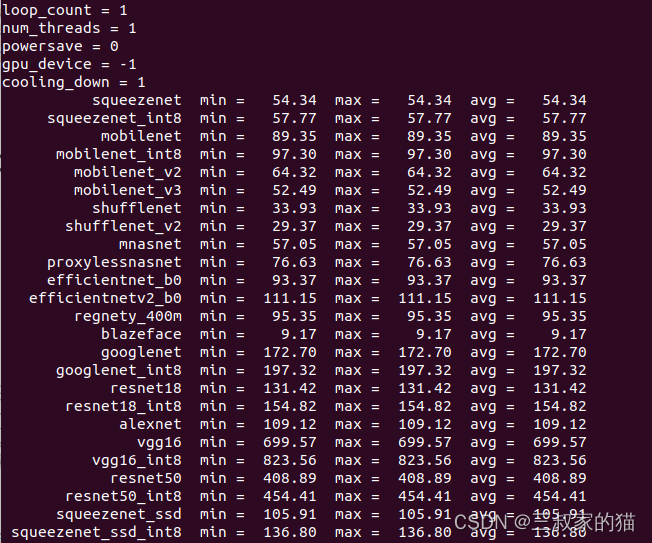
再看看使用gpu时的情况,使用命令./benchncnn 1 1 0 0,可以看到速度提升还是很大的,但是很明显对int类型的推理并不友好,应该还是GPU设备不支持int推理,运算回退到cpu进行的原因,不过总体来说加速还是很明显的:
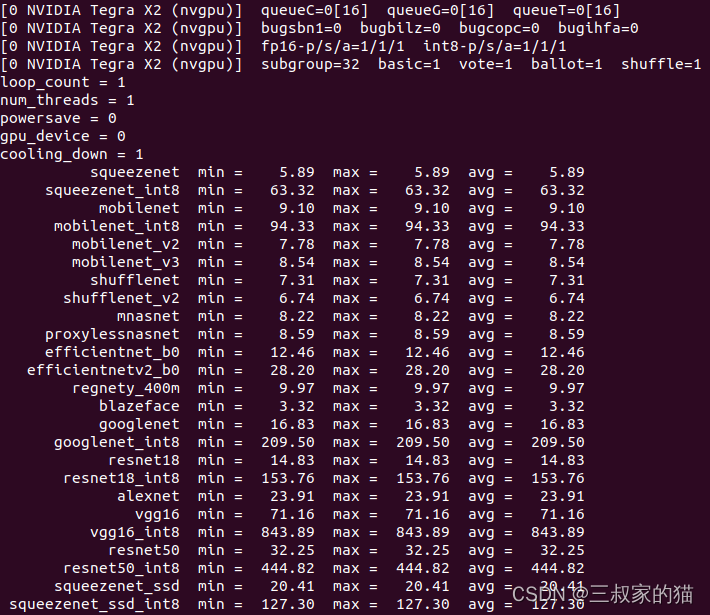
三、vulkan调用和CMakeList.txt修改
vulkan调用非常简单,只需要加一行代码即可:
ncnn::Net net;
net.opt.use_vulkan_compute = true; // 添加这行
然后修改CMakeList.txt编译文件,将头文件、库文件、以及静态库链接上,修改为刚才的ncnn编译后的install路径里相应文件夹即可,根据自己路径来:
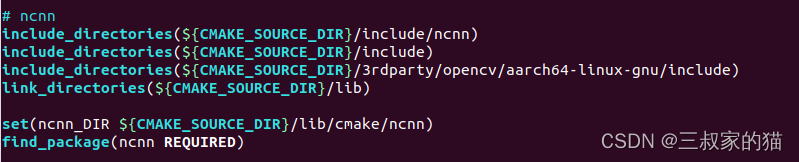
本以为能很顺利的编译,但是编译的时候却报了如下错误:
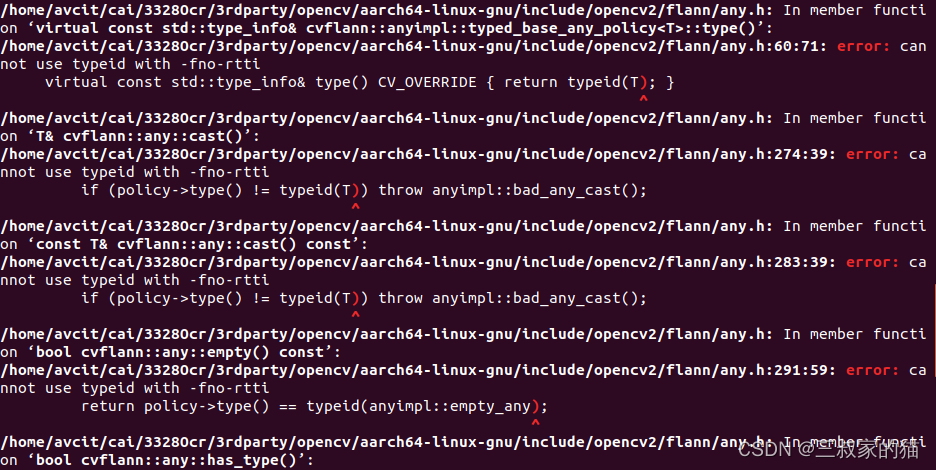
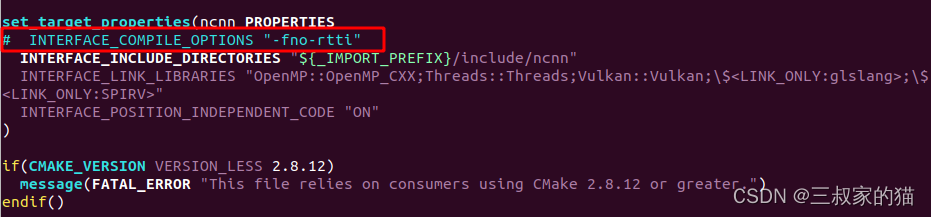
折腾了好久,终于找到解决办法,修改/lib/cmake/ncnn/ncnn.cmake文件里,将这行注释掉重新编译:
取一张表格图作为对比,先上cpu推理的情况:
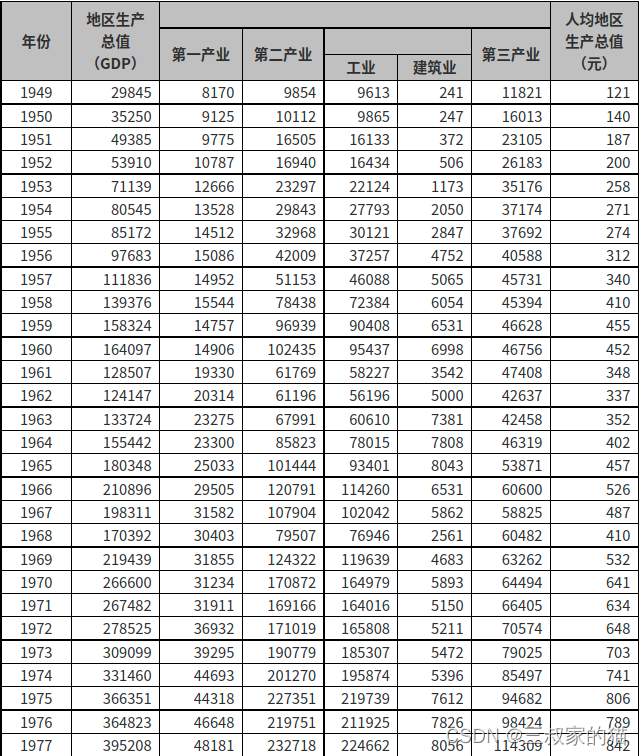
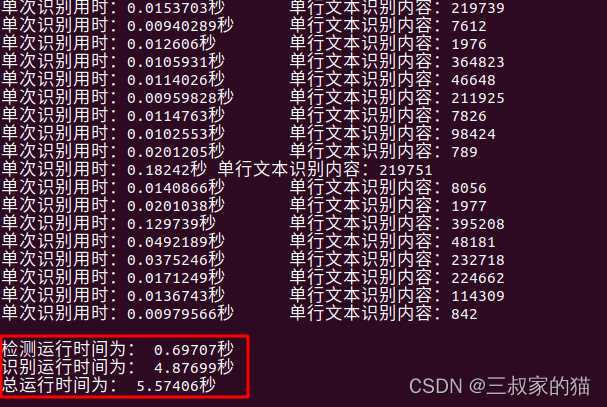

身份证识别CPU用时:

再看GPU推理情况:
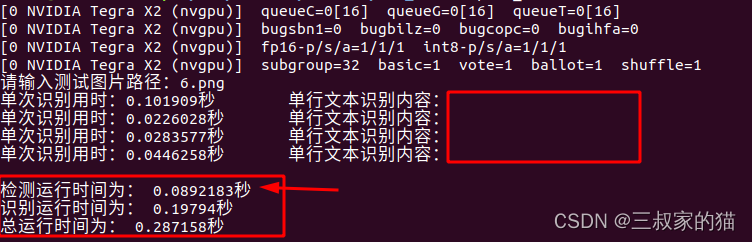
推理的加速部分主要是在文字检测模型上,识别模型因为本身速度就很快,所以接近存在瓶颈了,检测速度是快了许多,但是为啥识别模型推理出来是错的????我也没找出问题所在。。。难道是LSTM的原因?感觉是某些层不支持导致的,索性还好我还有自己训练的识别模型,具体识别模型可以看我上一篇rknn上部署的模型优化结构。
我的识别模型是纯卷积结构,并且是repvgg,所以已经没有任何模型比这更简洁了,部署起来真的好用,完全不用担心转换的时候某些层不支持的问题。所以这里还是上一个我自己训练的识别模型的效果:
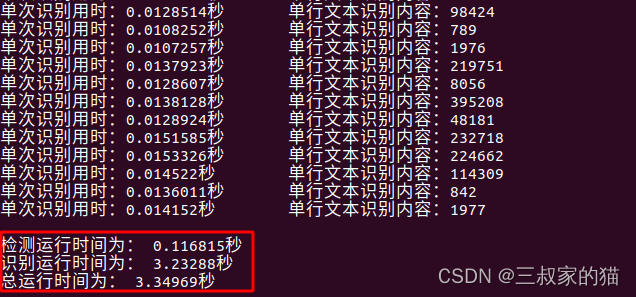
首先是上面那张表格,可以看到检测和识别速度都有比较大的提升,然后再看看身份证识别情况:

和上面的cpu对比情况,提速也还是挺大的。
不过跟trt相比,这个提速应该还是比较差的,毕竟ncnn针对的还是arm平台的cpu优化,后面有时间再出一篇文章在TX2上和trt的速度对比。
四、ncnn vulkan的其他说明
因为ncnn对于这块的优化并不是很好,所以在使用过程中难免会遇到一些问题,一些常见的问题请看ncnn中关于这章的说明文档。

