һ�� ��������
�ڿ���������,��������������HardFault��ѭ��������,��Ҫԭ������:
- ����Խ�����
- �ڴ����,����Խ��
- ��ջ���,�����ܷ�
- �жϴ�������
��Գ���HardFault����,����������ں˶��쳣����Ӧ�������̷���,ͬʱ���ͨ��keil���ɵ�map�ļ����鿴����������,�ڴ��С,�����С����Ϣ���жϡ�
��������֪ʶ
1. CortexM3�ں�
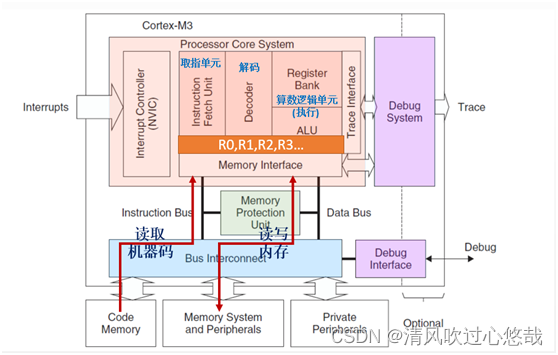
2. �Ĵ�����
Cortex�\M3 ������ӵ�� R0�\R15 �ļĴ����顣���� R13 ��Ϊ��ջָ�� SP�� SP������,����ͬһʱ��ֻ����һ�����Կ���,��Ҳ������ν�ġ�banked���Ĵ�����
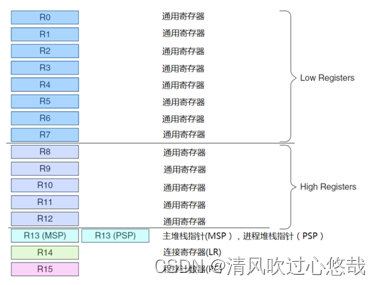
��R0-R12:ͨ�üĴ���
R0�\R12 ���� 32 λͨ�üĴ���,�������ݲ���������ע��:������� 16 λ Thumbָ��ֻ�ܷ��� R0�\R7,�� 32 λ Thumb�\2 ָ����Է������мĴ�����
��Banked R13: ������ջָ��
Cortex�\M3 ӵ��������ջָ��,Ȼ�������� banked,�����һʱ��ֻ��ʹ�����е�һ����
����ջָ��(MSP),��д�� SP_main������ȱʡ�Ķ�ջָ��,���� OS �ںˡ��쳣���������Լ�������Ҫ��Ȩ���ʵ�Ӧ�ó��������ʹ�á�
���̶�ջָ��(PSP),��д�� SP_process�����ڳ����Ӧ�ó������(�������쳣����������ʱ)��
Ϊ���ڽ���ģʽת����ʱ��,���ٶ�ջ�ı��湤����ͬʱҲ����Ϊ��ͬȨ�Ĺ���ģʽ���ò�ͬ�Ķ�ջ��
��R14�Ĵ��������ӼĴ���(LR),������һ���ӳ���ʱ,��R14�洢���ص�ַ��
��R15�Ĵ����dz���Ĵ���(PC),ָ�����ǰ�ĵ�ַ�����������ֵ,���ܸı�����ִ������
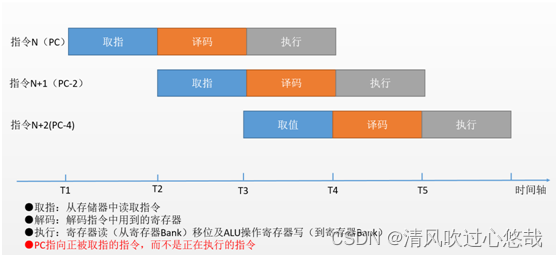
3. ������ˮ��
CortexM3�ܹ�����������ˮ�ߵķ�ʽʵ��ָ��IJ�������ˮ�߲����ı���������ָ�����еIJ�ͬ��ʹ�õ�CPU Ӳ��������ͬ,���������ж���ָ��,�Ӷ����ʱ��Ч�ʡ�
������ˮ�߲�����������ָ��ķ�ʽ: �ڶԵ�1��ָ����������ʱ��,����ͬʱ�Ե�2��ָ�����ȡָ����;�ڶԵ�1��ָ�����ִ�е�ʱ��,����ͬʱ�Ե�2��ָ������������,�Ե�3��ָ�����ȡָ��������Ȼ,�����Ϳ��Խ��ó����������ʱ���30������Ϊ12��,���ٽ�3����
4. �쳣
Cortex�\M3 ���ں�ˮƽ�ϴ�����һ���쳣��Ӧϵͳ, ֧��Ϊ���ڶ��ϵͳ�쳣���ⲿ��
�ϡ�����,���Ϊ 1-15 �Ķ�Ӧϵͳ�쳣,���ڵ��� 16 ����ȫ���ⲿ�жϡ����˸����쳣�����ȼ���������, �����쳣�����ȼ����ǿɱ�̵�(�����ܴ������ִ�������¼�����Ϊ�쳣)��
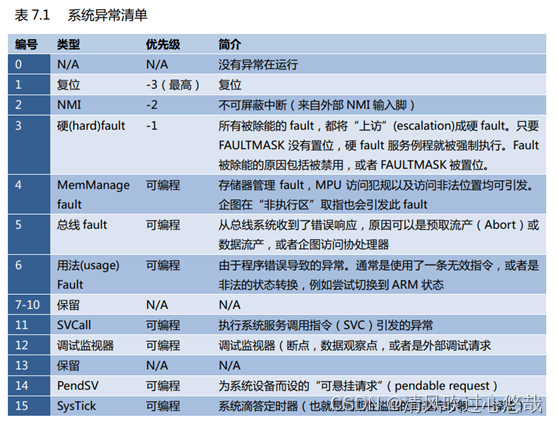
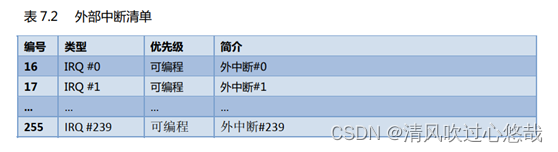
�� CM3 ��,���ȼ�����ֵԽС,�����ȼ�Խ�ߡ�CM3 ֧���ж�Ƕ��,ʹ�ø����ȼ��쳣����ռ(preempt)�����ȼ��쳣���� 3 ��ϵͳ�쳣:��λ, NMI �Լ�Ӳ fault,�����й̶������ȼ�,�������ǵ����ȼ����Ǹ���,�Ӷ��������������쳣�����������쳣�����ȼ����ǿɱ�̵�(�����ܱ��Ϊ����)��
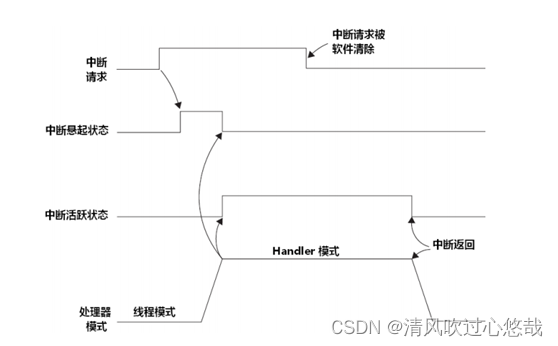
�жϵ����뼰������Ϊ
��ij�жϵķ������̿�ʼִ��ʱ,�ͳƴ��жϽ����ˡ���Ծ��״̬,����������λ�ᱻӲ���Զ����,��һ���жϻ�Ծ��,ֱ�����������ִ�����,���ҷ�����,���ܶԸ��жϵ�������������Ӧ��
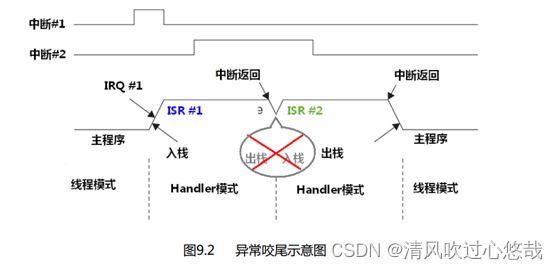
ҧβ�ж�
��ǰ����ִ���ж�,����һ���жϵ���������ж����ȼ�������ִ�е��ж����ȼ���,����ж���ʱ������,�ȵ���ǰ�ж�ִ�������ִ�ж�ջ����,��ֱ�ӽ��������ж�,����Ҫ�ٽ��г�ջ��ջ������