在试图使用学校服务器的时候遇到并解决了一些问题
软件下载和安装
需要的软件(个人使用的是这样的,也可以是其他的)
1.xshell
使用xshell连接服务器,并且进行指令操作(也可以使用其他软件,如ssh)
下载和安装:可以在网上找到免费的(建议支持正版),下载后按照引导安装即可。
2.xmanager
下载和安装:如果不使用图形化功能可以不安装,同理可以在网上找到免费的(建议支持正版),下载后按照引导安装即可。
3.pycharm
下载和安装:有社区版和专业版可以选择,社区版是免费的,一般的功能是支持的,专业版可以试用一个月,后续需要注册码。在这里我们仅需要借助pycharm上传和下载代码以及训练好的权值,社区版的功能就够用了。
配置xshell
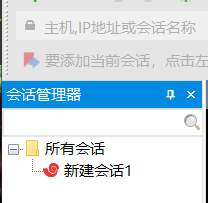
在会话管理器中右键所有会话,新建->会话
注:这里的这个新建会话1是作者已经新建的会话,初次使用没有这个会话
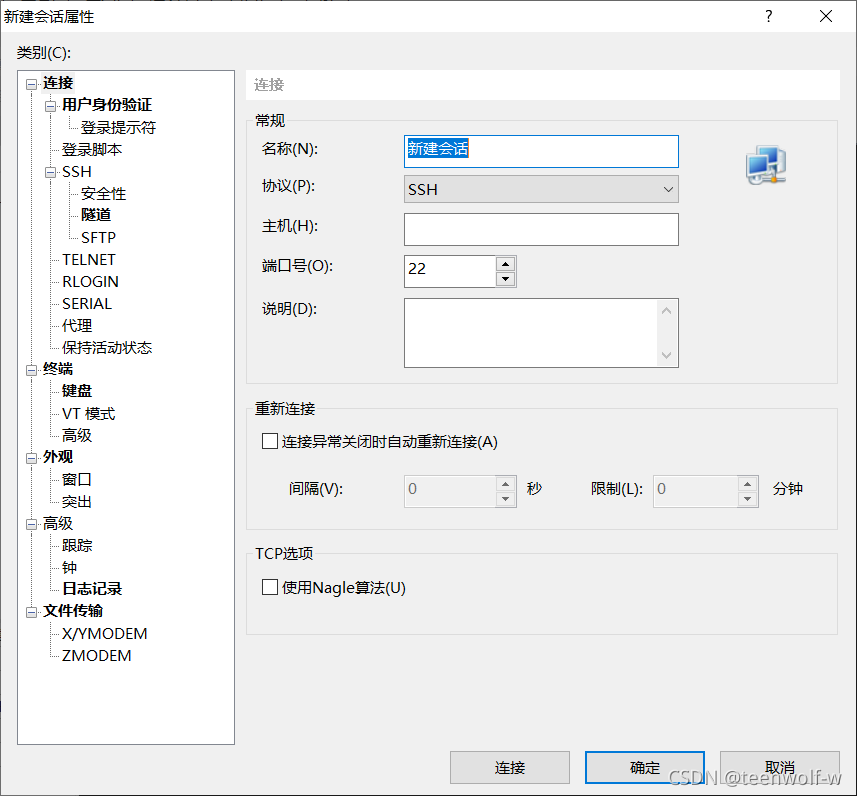
输入会话名称(也可以不输入),主机和端口号
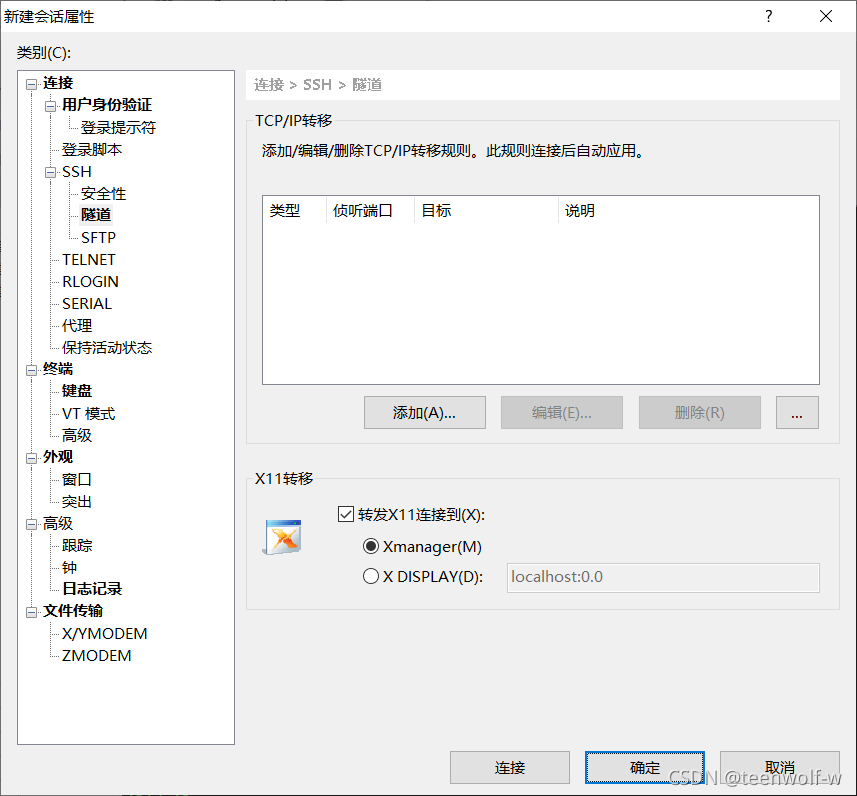
将SSH中的隧道选项中的X11转移设置成Xmanager
使用xshell连接服务器
如果使用的是学校内网等内网的服务器需要先登入内网
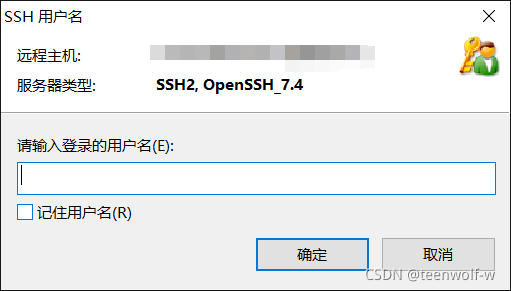
输入用户名
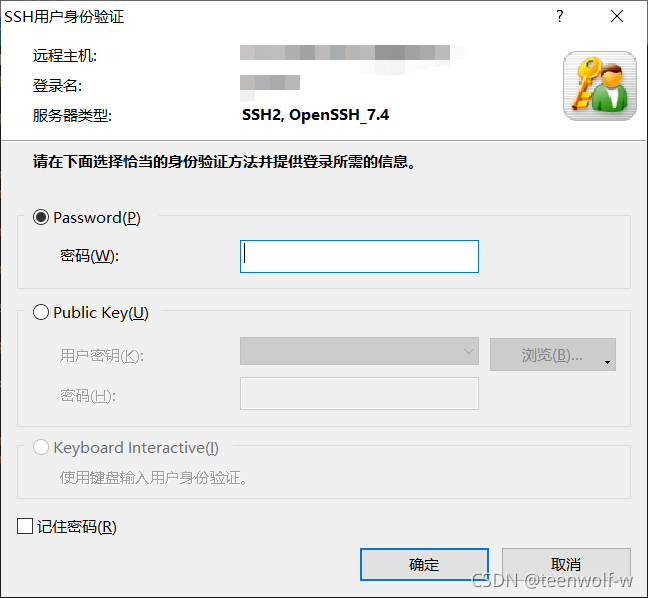
输入密码
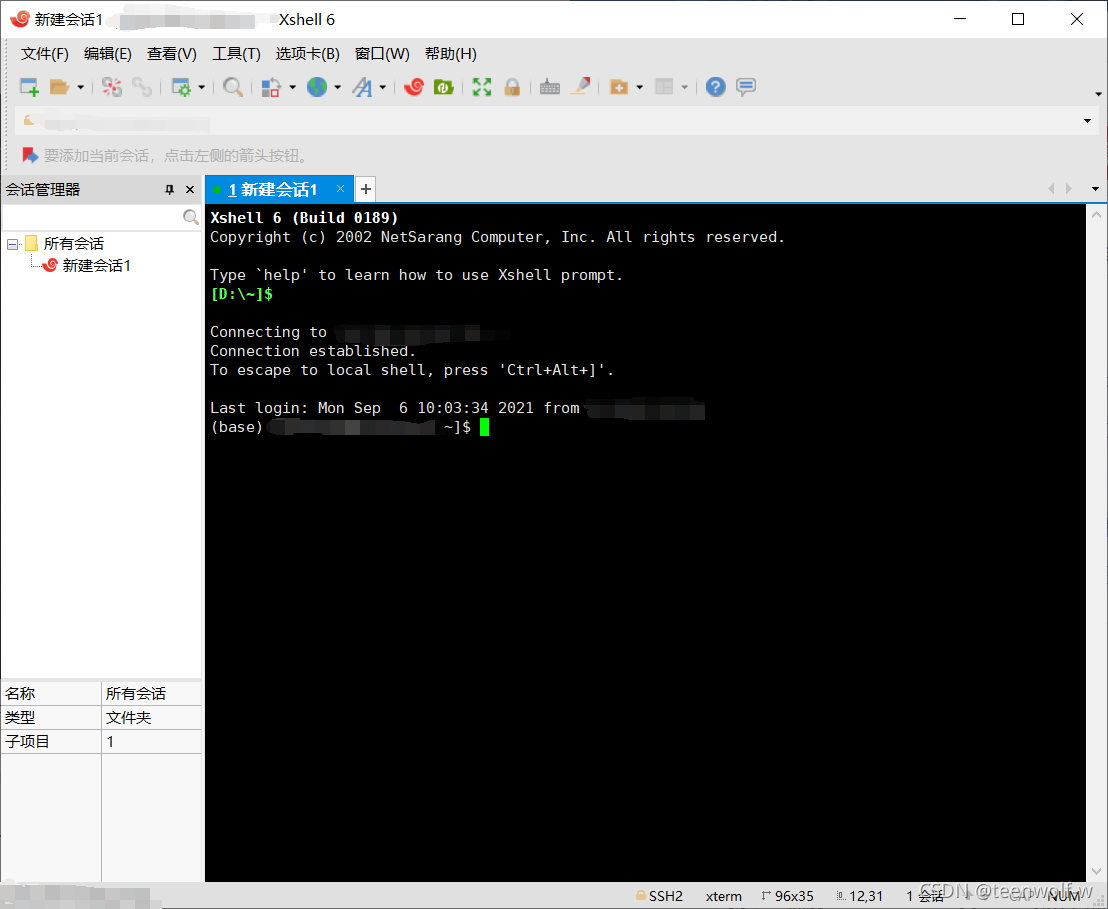
连接成功
配置pycharm
社区版和专业版都可以配置,位置可能会不太一样,这里使用专业版进行配置

首先在菜单上找到并选择Tools
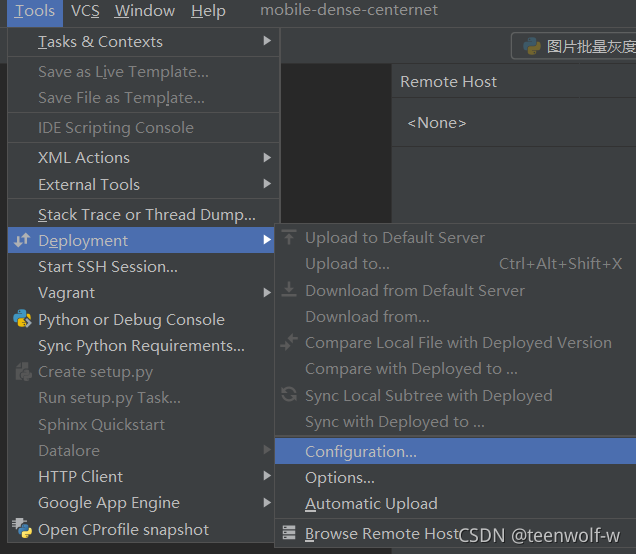
选择Deployment->Configuration
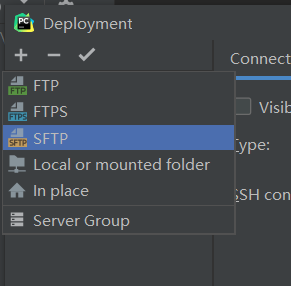
选择“+”号->SFTP
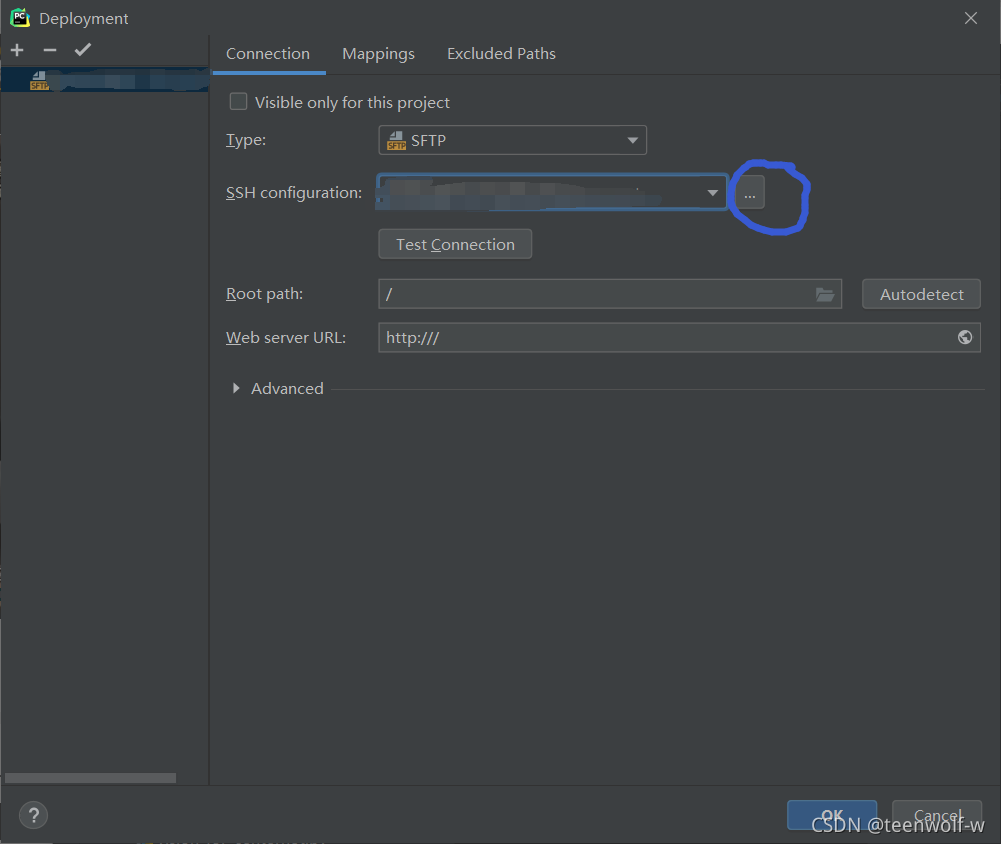
点击SSH configuration后的‘…’
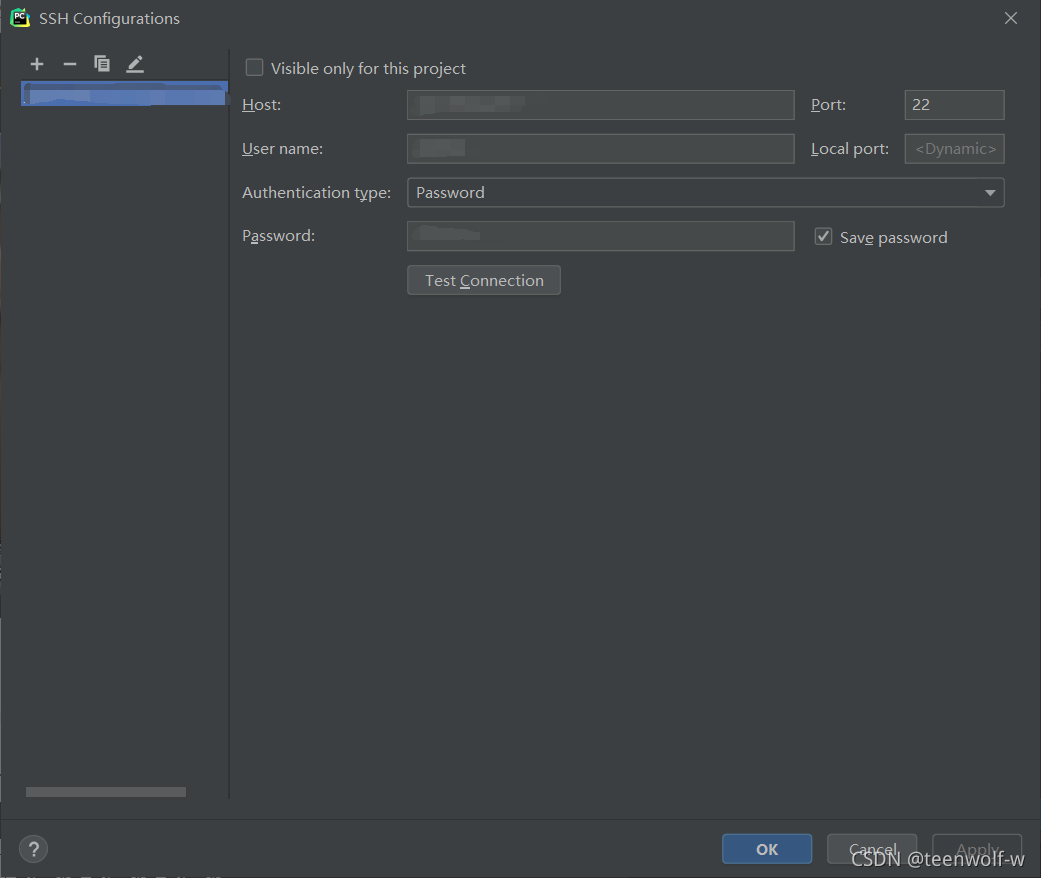
Host输入地址,User Name输入用户名,PassWord输入用户密码,如果端口号不是默认的22端口号还需要修改端口号
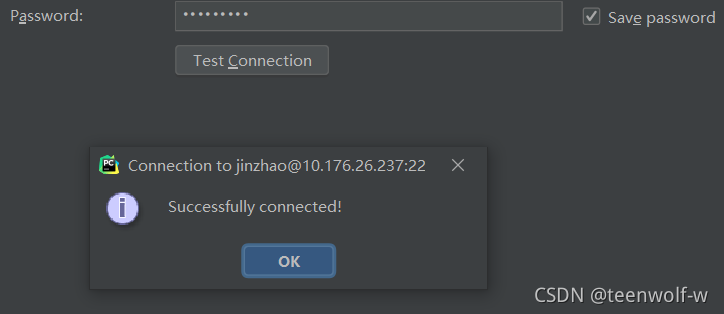
选上Save password并点击Test Connection测试连接,如果是图上的提示说明连接成功
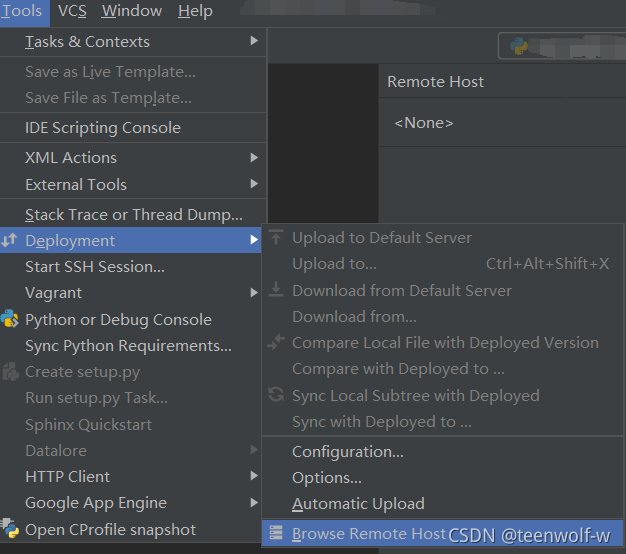
按照Tools->Deployment->Browse Remote Host即可打开remote host
显示Remote Host
点击向下的箭头,选择刚刚配置好的SFTP
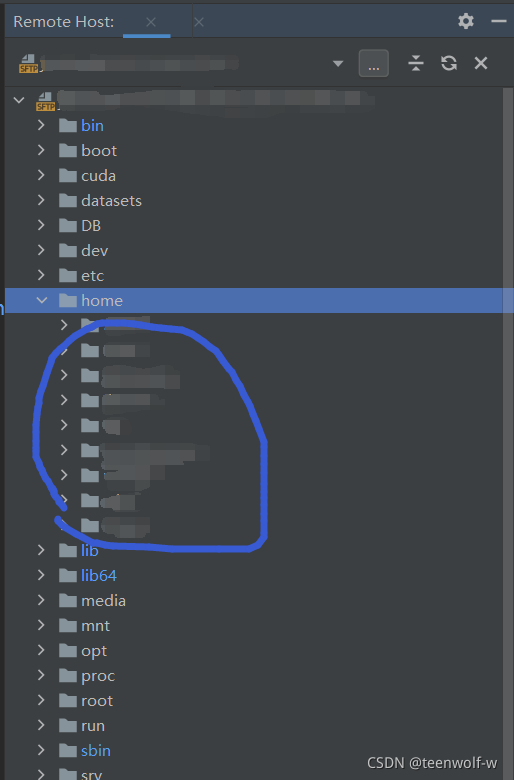
在这个目录下可以看到自己用户的文件夹,最好在自己的文件夹里面上传代码
文件的上传和下载只需要选中并拖拽即可,如:将代码上传到服务器,选中pycharm左侧的代码,将它拖拽到右侧需要上传到的文件夹中,如果要下载训练好的权值只需在右侧选中服务器中的权值文件拖拽到左侧文件夹即可
安装依赖包
一般情况下刚刚配置好的服务器环境的依赖包都不够满足代码的运行,所以我们训练前要先安装依赖包。
pip超时问题:有些服务器平时是不联网的,此时服务器运行的命令相当于服务器本地离线运行
解决方式:在pip前输入这段命令。
注:这段命令不能直接使用,很多地方需要改为自己环境的信息,如:写有“服务器地址”的位置,改成自己的服务器地址,(X11; Ubuntu; Linux x86_64; rv:81.0) 中也要改成服务器linux对应的版本,这些信息一般是有命令可以查到的,查不到的可以去问服务器管理员。
curl 'http://服务器地址/0.htm' -H 'User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:81.0) Gecko/20100101 Firefox/81.0' -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' -H 'Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2' --compressed -H 'Content-Type: application/x-www-form-urlencoded' -H 'Origin: http://服务器地址' -H 'DNT: 1' -H 'Connection: keep-alive' -H 'Referer: http://服务器地址/0.htm' -H 'Upgrade-Insecure-Requests: 1' --data-raw 'R3=1&v6ip=&DDDDD=2018405A122&upass=260613&save_me=1&0MKKey=123'
联网后就可以正常使用pip了,但是因为很多包是外网,下载将会非常慢,所以应该使用镜像源,同时也要注意pip时包的名称
这里以opencv为例
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
包名后面的-i https://pypi.tuna.tsinghua.edu.cn/simple就是使用了清华镜像
安装Cuda出现的问题
如何安装符合linux版本和tensorflow的方法网上已经有很多了,这里重点说明一下cudnn的问题。
由于我环境变量配置的问题导致有一些cudnn的lib在使用gpu加速时不能正常引用。这种情况下程序会报错说明在某个路径下找不到某某文件。我的做法是搜索到该文件,把该文件复制到报错的文件路径中
搜索文件的命令
locate 文件名字
训练时间的问题
因为各个服务器都有时间限制,大概30分钟没有进行操作就会自动断开,而这个时间对于很多模型都是不够用的,所以我们要想办法延长时间,或者永久防止断开。
1.脚本
在网页右键->检查->控制台,在控制台输入脚本进行防止断开(其原理是每隔一段时间就进行一次网页操作)
这里以Colab和kaggle为例
Colab适用的脚本
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
function closeButton(){
console.log("close");
document.querySelector("body > colab-dialog > paper-dialog > colab-sessions-dialog").shadowRoot.querySelector("#footer > div > paper-button.dismiss").click()
}
setInterval(ConnectButton,60000);
kaggle适用代码
function closeButton(){
console.log("close");
document.querySelector("#root > div > div > div.AppView-sc-16eb2j.kZXkZl > div.App_Body-sc-16c8j4p.hxOBfv > div.Layout_Body-sc-6piylv.bXAYPy > div > div > div > div.ToolbarContainer_Body-sc-2h8iu7.fhvgBU > button").click()
}
setInterval(closeButton,60000);
function closeButton(){
console.log("close");
document.querySelector("#root > div > div > div.AppView-sc-16eb2j.kZXkZl > div.App_Body-sc-16c8j4p.hxOBfv > div.Layout_Body-sc-6piylv.bXAYPy > div > div > div > div.ToolbarContainer_Body-sc-2h8iu7.fhvgBU > div.DetailedStatus_Body-sc-zfwb95.fMzpPO > button > i").click()
}
setInterval(closeButton,60000);
缺点:从上述可以看出来每个不同的网页的代码是不同的,这样会比较麻烦,所以我们将介绍使用nohup命令实现离线运行。
nohup命令:
nohup命令要在xshell或者ssh的命令行下运行,在要执行的命令前输入nohup即可进行离线运行命令,执行python文件的命令也是一样的。执行时该命令无屏幕输出,未加nohup时的屏幕输出输出到当前文件夹生成的nohup.out文件中

运行之后就可以关闭xshell,甚至关机都可以,服务器会自己运行下去。
nohup.out占内存过多
当训练的模型论次数过多时nohup.out储存的字符会很多,这样会很占空间。我这边的做法是确定他已经开始运行后将nohup.out文件删掉,这样也可以正常运行(不太清楚是什么原理,所以不确定每个服务器都支持这样),这样就不用担心nohup.out过大的问题。
终止nohup进程
首先需要找到该进程
输入命令:
ps aux | less
运行结果:
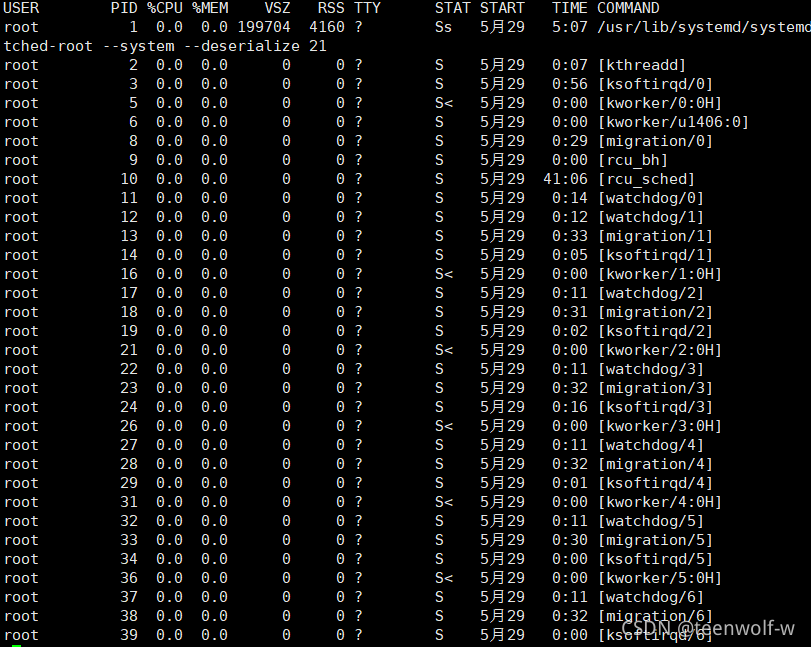
需要注意的是第二列是进程的ID(PID),最后一行是命令(COMMAND),如果是python程序,命令形似于:python 程序名 参数
然后杀死这个进程
kill -9 PID