? 大家好,我是爬虫新手看我,今天我给大家分享一下如何爬取一个网站的表情包,这个网站的名字是逗逼拯救世界,相信不少的小伙伴们也接触过这个网站,就算没接触过,也不要紧,我们现在就可以接触了😂😘。今天我们只分享如何提取其首页的表情包哈,如果有需要,可以私信我,届时我会分享更多的方法于技巧。
我们先到其网站的根目录下查看它的robots协议,发现它是空的,那么我们可以放心测试了。如果有对robots协议不清楚的小伙伴,可以去直接百度robots协议,就可以了。
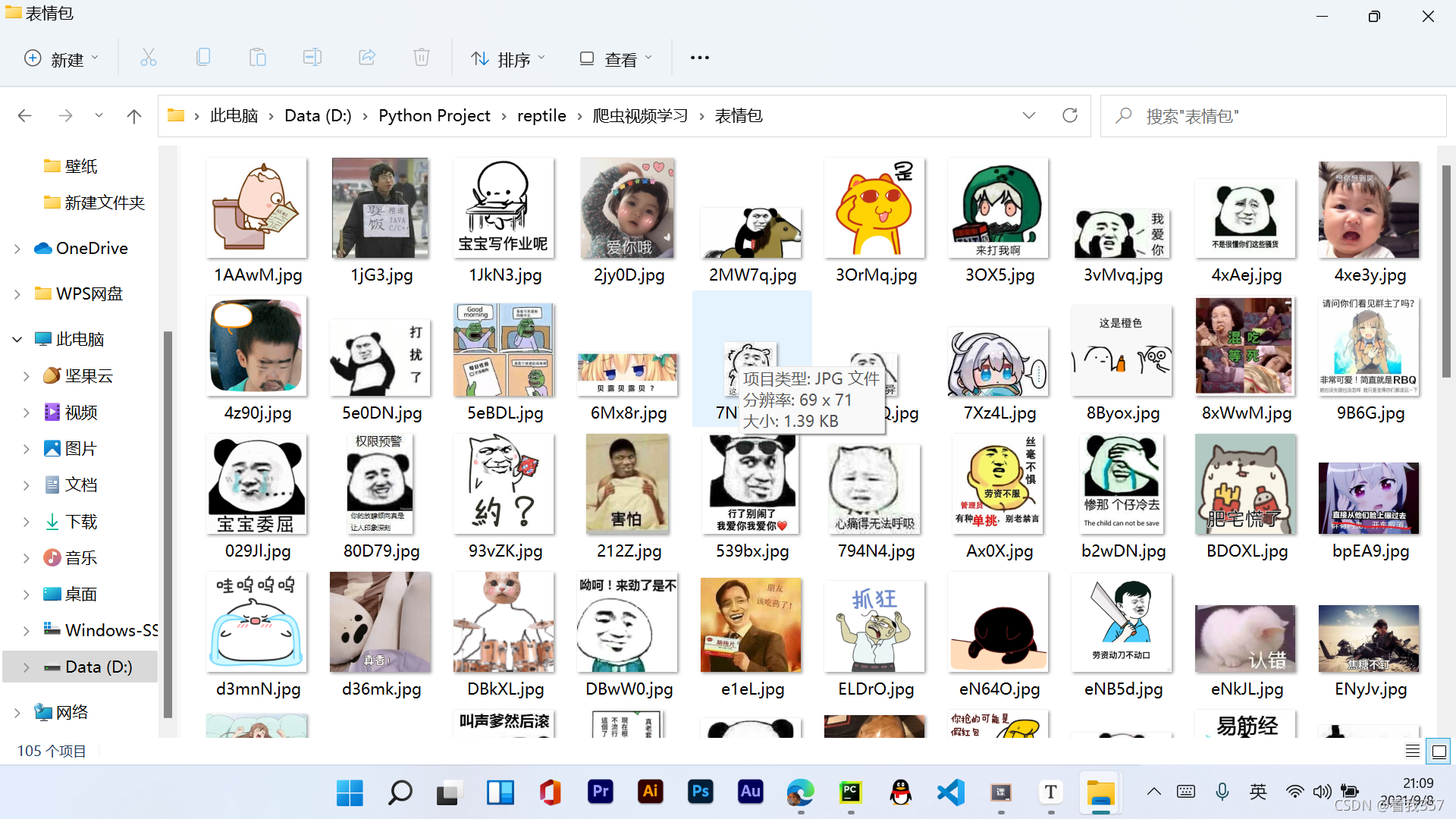
哈哈,先来一张结果图吧,看:
首先我们先进行环境的配置,
如果是用Pycharm的小伙伴打开我们的Pycharm,如图所示:
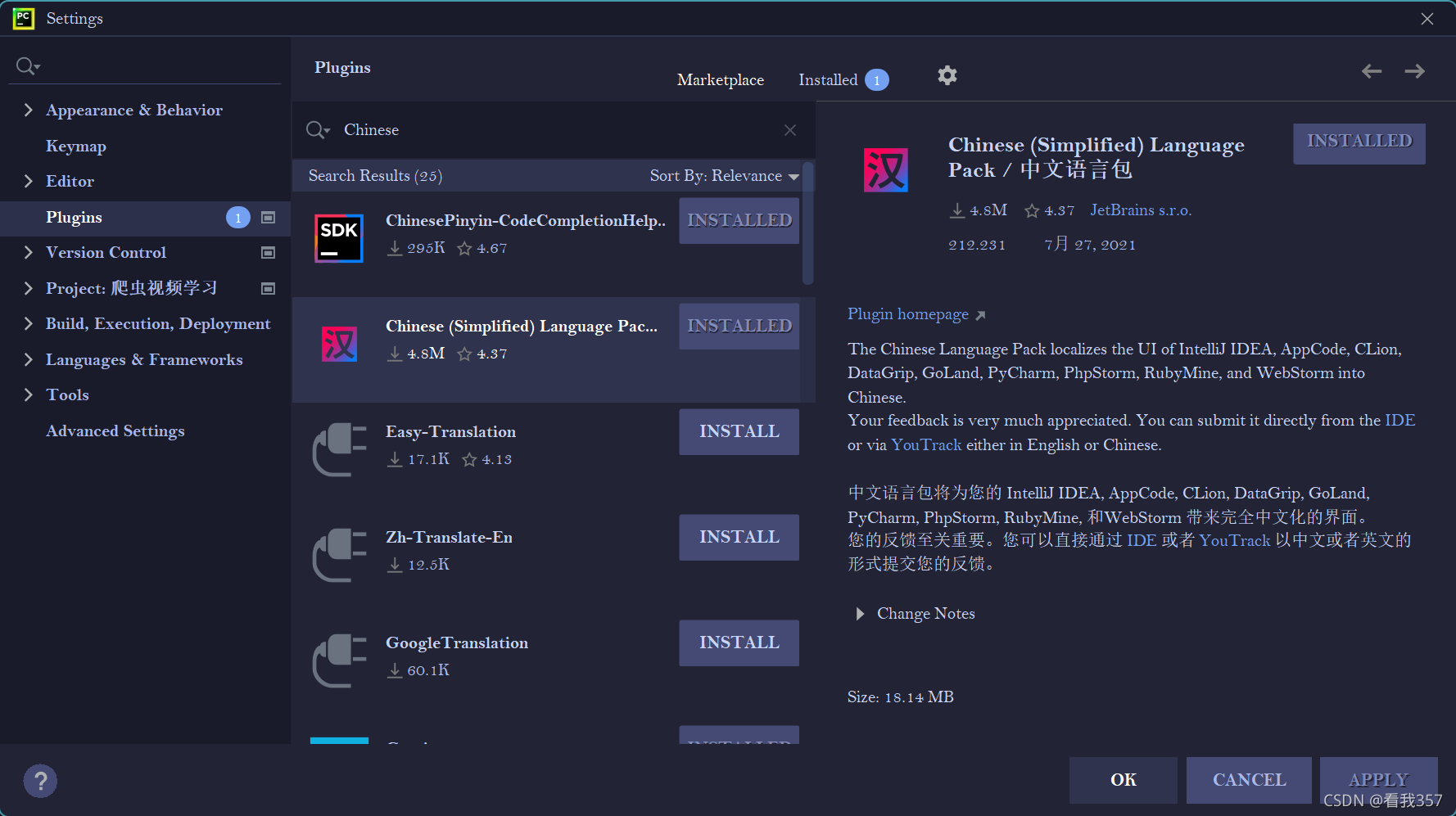
? 如果你们的Pycharm还是英文的话可以点击File -> Settings -> Plugins 然后在Marketplace中搜索Chinese即可,注意是这个中文语言包哦。
? 接下来回归正题:
打开Pycharm后,在文件->设置->项目+文件名称->Python解释器中点击加号,搜索requests这个库,今天我们主要就是利用这个Python的第三方库来进行网络请求。
如果是用Python IDLE的话直接在命令提示符(Win + R,然后输入cmd)中输入pip install requests即可。
? 好啦,现在环境配置好了,我们可以去看看这个网站了,逗逼拯救世界,(不得不说这个网站的表情包是真的多,挺不错的😘。)
? 首先我们要确定我们要爬的主题――该网站的表情包,那么,我们可以打开这个网站之后,点击一个表情包之后,进入它的详情页,复制图像链接,在这我展示两个链接:
https://image.dbbqb.com/202109081951/bc98c4c4f08284d0dbcf6abcdff76078/zwnde
https://image.dbbqb.com/202109082003/61d7f27498c0340a0df26342a712482f/Qz9zE
? 可以发现每一个表情包的详情页只有后面的部分是不同的,那么这些不同的字符从哪可以获得呢🤪?带着这个疑问,我们继续看下去。
? 接下来我们分析一下这个网站的表情包数据是从何而来的,是我们请求访问这个链接时就自带的还是说我们请求这个链接之后这个网站的平台服务器发送给我们的,好的,带着这个问题,我们开始访问这个网站,同时打开开发者工具(F12或者Ctrl + Shift + I),切换到网络选项,然后点击刷新,捕获网页的活动。
? 从这里我们可以看见第一个就是一个名称为www.dbbqb.com的响应,我们可以观察到这个是和我们访问的链接是一样的,所以我们可以点击响应,点击一下响应的数据,然后按住Ctrl + F进行搜索,例如在网页显示的推荐表情四个字,我们发现,这里面竟然搜索不到,那么,这就说明网页中的表情包并不是该链接自带的,而是由后台服务器发送过来的:(该截图下面的搜索是做其他用途的,不要混淆🤣)
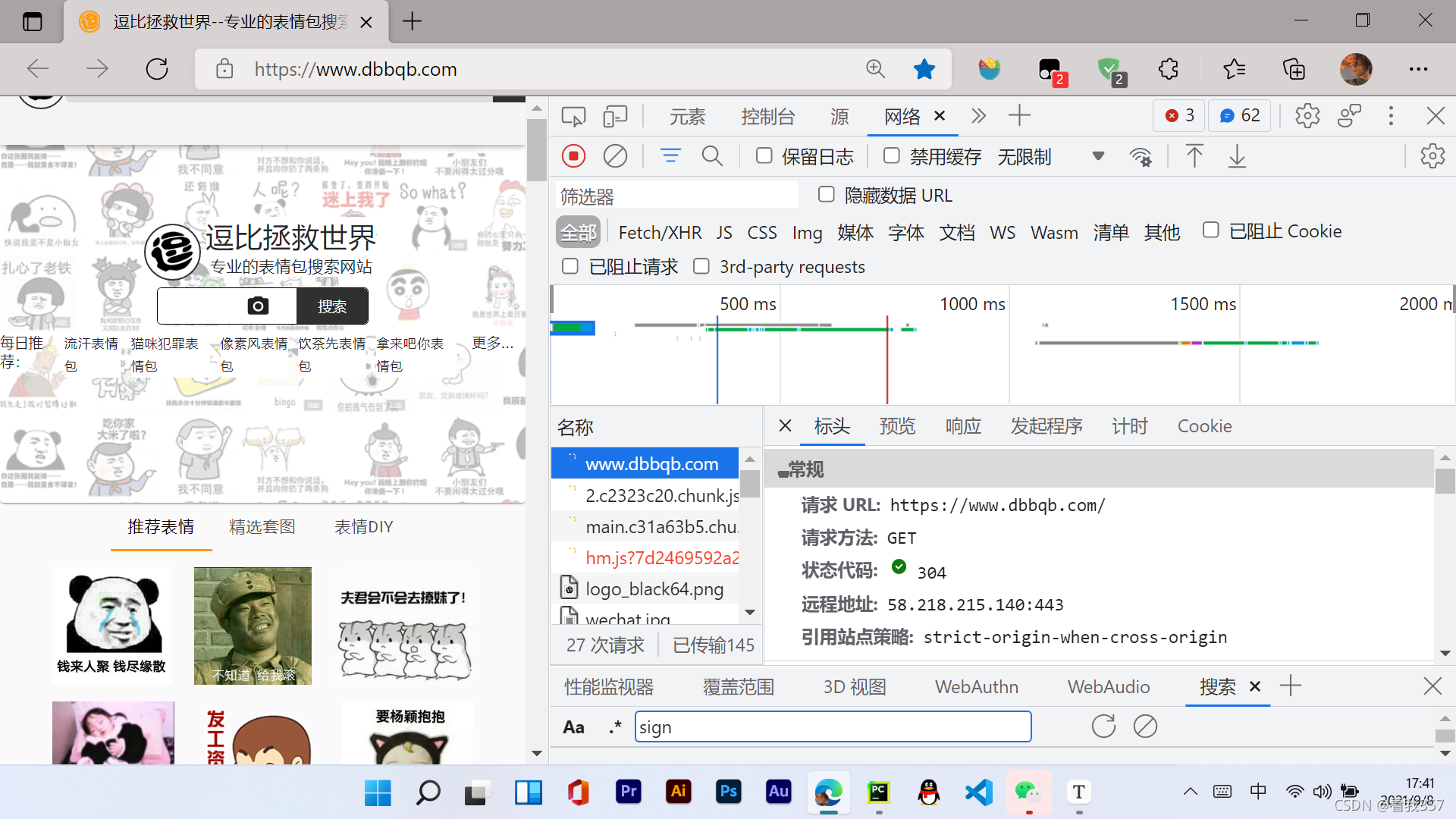
? 那么我们就切换到Fetch/XHR选项卡,在该选项卡中可以检测服务器和浏览器窗口的交互信息。可以看到有一个json?size=100的名称,我们可以想,这个100是什么?是100张图片吗,那么我们查看它的预览,好家伙:
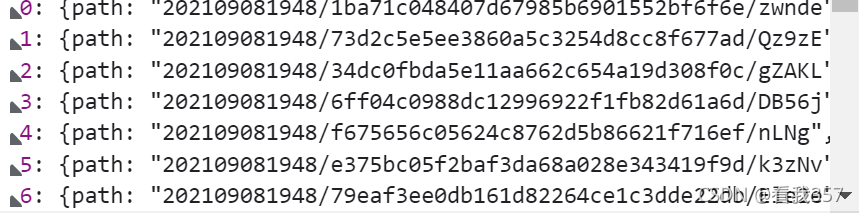
大家可以看到,里面有从0到99的一百组数据,我们打开一组数据进行查看:
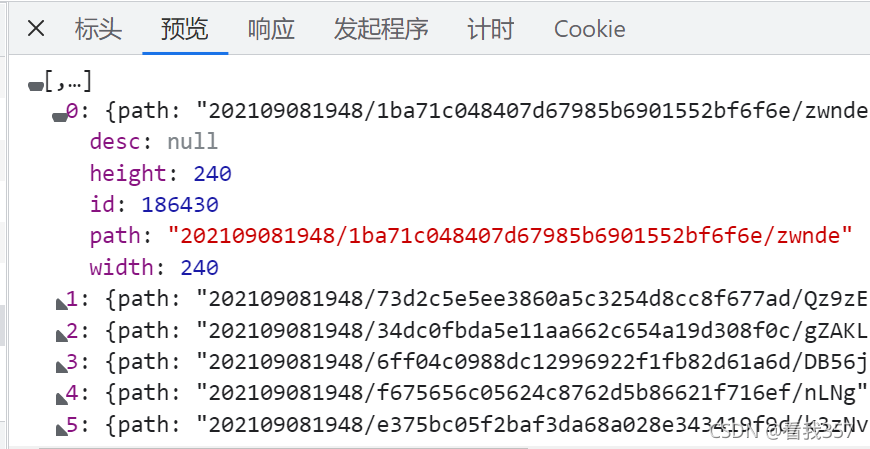
这些就是第0组里面的数据了,咦,我们可以看到,里面有一个path的属性,这不就是我们的每一个表情包的链接的后面部分吗?我们可以多尝试几次,可以得出:每一表情包的链接,就是https://image.dbbqb.com/+path的值。接下来,就是写代码的时候了!😏
首先导入需要的库:
import requests
import os # 这个os库是python自带的库,在这是用来创建文件夹的
get_url = 'https://www.dbbqb.com/api/search/json?size=100' # 这个url就是json?size=100的请求URL
同时,我们可以看到:
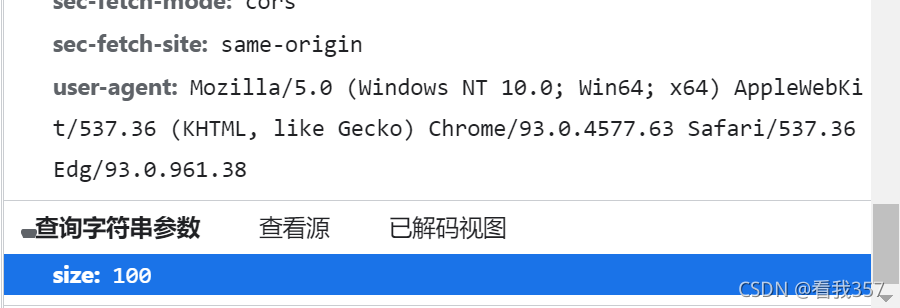
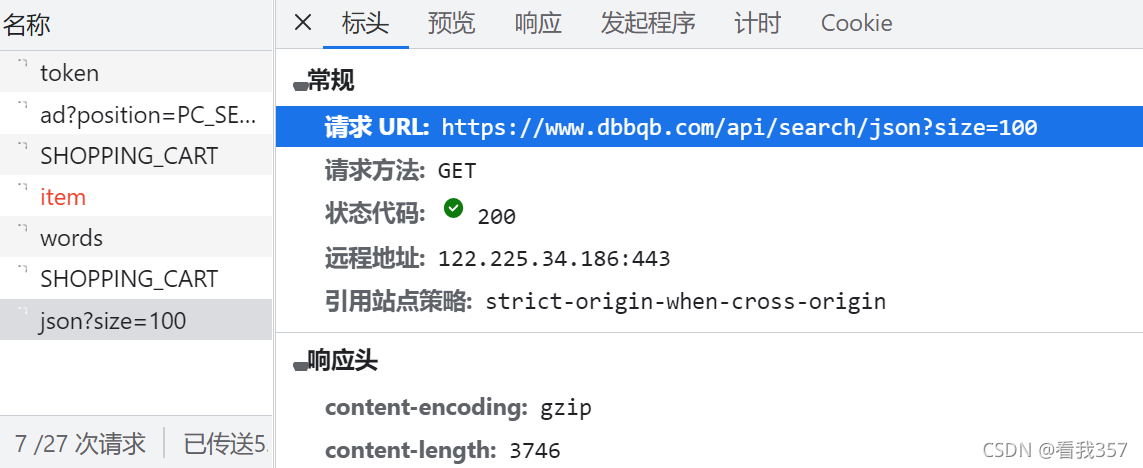
它的请求方法是GET方法,同时还有一个查询参数,为size: 100,既请求了一百组数据,基于此,你们可以自己尝试获取更多的数据,当然,如果要获得更多的数据,需要将之前的进行一些修改:
import requests
import os # 这个os库是python自带的库,在这是用来创建文件夹的
get_url = 'https://www.dbbqb.com/api/search/json?'
params = {
'size': 100
}
# 这样,就可以进行size的修改,自己可以去尝试哦
# 然后:
# 我们对其发起请求
# 为了防止该网站拒绝我们的请求,我们加上浏览器的标识,并将其放在一个名为headers的字典中,该标识可以在上图的user-agnet中获得,然后复制粘贴即可。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.38',
}
# 上面提到的GET方法对应了此处的get,params是将里面的数据自动拼接到请求链接当中,headers是为了设置我们之前写的User-Agent。
response = requests.get(url=get_url, params=params, headers=headers)
# 同时我们可以在json?size的响应头中可以看到它的content-type是application/json,即为json格式,所以我们直接获得response的json格式即可
data_json = response.json()
# 然后我们进行循环,获得每一个图片的path值,并将其存储在一个列表中
pic_paths = []
for detail_data in data_json:
pic_path = detail_data['path']
pic_paths.append(pic_path)
# 如果没有表情包这个文件夹,就新建一个文件夹,将下载的图片保存在表情包这个文件夹中
if not os.path.exists('./表情包'):
os.makedirs('./表情包')
# 之后在进行循环,对每一个图片的链接进行请求
for pic_url in pic_paths:
# 由于我们只获得了path值,所以还要将其进行拼接
url = 'https://image.dbbqb.com/' + pic_url
# 设置图片的名称
pic_name = pic_url.split('/')[-1]
# 由于图片的数据都是二进制的,所以我们利用content接收二进制数据的信息
response = requests.get(url=url, headers=headers).content
with open(f'./表情包/{pic_name}.jpg', 'wb')as f:
f.write(response)
print(f'{pic_name}.jpg下载完成')
哈哈,到此就结束啦,有事可以私信我哦,记得点赞收藏哦,拜😘。
