目录
安装包
基础语法
安装包:
Python:Download Python | Python.org?下载地址
在Windows上运行Python时,请先启动命令行,然后运行python。
在Mac和Linux上运行Python时,请打开终端,然后运行python3。
本人使用的开发环境是mac pro 苹果操作系统:
pip3 install Pillow
pip3 install PyMySQL
pip3 install?pandas
还有其他包用的时候在安装即可。
基础语法:
round()浮点数四舍五入
abs()取绝对值
pow()乘方
print("{}".format(变量))
Python的输入函数是input()
int()函数
浮点数转换函数float()
eval() 输入的算术表达式直接计算出结果
随机数的函数randint()
var和name都是字符串类型
字符串的起始数字是0,结束数字并不包含其自身。
len()函数是Python内部函数,可以计算出字符串长度
字符串格式运算符”%“
Python并不区分单引号和双引号
#注释用
upper()?? ?字符串小写字母转大写
lower()?? ?字符串大写字母转小写
capitalize()字符串首字母大写,多用于英文句子
count()?? ?统计子串在字符串中出现的次数
startswith()查找方法,判断字符串是否以给定子串开头
endswith()查找方法,判断字符串是否以给定子串结尾
find()查找方法,判断子串是否在字符串中
replace()用指定子串替换部分字符串
join()?? ?把列表中所有元素连接成字符串
strip()?? ?删除字符串头尾的空格
split()?? ?按给定分隔符将字符串分割成列表
input() # 输入函数
print() # 输出函数
float() # 把字符串转换成浮点数
format() # 字符串格式函数
/ ? # 除法
** ?# 乘法
> ? # 大于
< ? # 小于
>= ?# 大于等于
<= ?# 小于等于
DataFrame是由多个Series组合在一起的多维表
Series实际上就是一维数组
import pandas as pd
最简单的99乘法口诀表来一个:
#99乘法表
for i in range(1,10):
for j in range(1,i+1):
d = i * j
print('%d*%d=%-2d'%(i,j,d),end = ' ' )
print()#爬虫
import pandas as pd
url = 'http://www.espn.com/nba/salaries'
df5 = pd.DataFrame()
df5 = df5.append(pd.read_html(url), ignore_index=True)
df5 = df5[[x.startswith('$') for x in df5[3]]]
df5
df5.to_excel("/users/jick/desktop/nba.xlsx", index=False, header=['排名', '姓名', '球员', '薪资'])
#DataFrame - 数据读取
import pandas as pd
data = {
'姓名': ['郑尚力', '田中露', '柳雨风', '慕容续会', '练卉', '洪丽茗', '董红才'],
'所在城市': ['成都', '北京', '武汉', '杭州','上海', '乌鲁木齐', '西双版纳'],
'年龄': [41, 28, 33, 34, 38, 31, 37],
'Python成绩': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
}
df = pd.DataFrame(data, index=[101, 102, 103, 104, 105, 106, 107])
df#Pandas的文件操作 - CSV格式
#to_csv()写文件
#mac
import pandas as pd
df = pd.DataFrame()
df.to_csv('/users/jick/desktop/python/nba.csv', index=False)
#windows
df.to_csv('C:\\users\\apple\\desktop\\picture\\data\\mi.csv')#参数:columns
按指定的列写入文件,我在下面只写入文件3列,有意去掉了读操作。
df.to_csv('/users/apple/desktop/picture/data/mi.csv', column['文件类型', '格式', '写操作'])
#read_csv()读文件
import pandas as pd
df = pd.DataFrame()
df.to_csv('/users/jick/desktop/python/nba.csv', index=False)
df1 = pd.read_csv('/users/jick/desktop/python/nba.csv',header=0,names=range(2,4))
df1#excel
import pandas as pd
import numpy as np
df = pd.read_excel('/users/jick/desktop/python/nba.xlsx')
#data[data.姓名 == '张三'].语文
#缺少第一列
df = pd.read_excel('/users/jick/desktop/python/nba.xlsx', index_col=0)
df
import pandas as pd
file = "/users/jick/desktop/python/nba.xlsx"
data = pd.read_excel(file) #reading file
print(data)#excel查询
import pandas as pd
import numpy as np
df = pd.read_excel('/users/jick/desktop/python/nba.xlsx')
df #打印所有数据
df.info() #数据表信息
df.dtypes #查看数据表各列格式
df['Name'].isnull() #检查特定列空值
df['city'].unique() #查看city列中的唯一值
df.values #查看数据表的值
df.columns #查看列名称
df.head(3) #查看前3行数据
df.tail(3) #查看最后3行
df.dropna(how='any') #删除数据表中含有空值的行
df.fillna(value=0) #使用数字0填充数据表中空值
df['Name'].drop_duplicates() #删除后出现的重复值
df['Name'].drop_duplicates(keep='last') #删除先出现的重复值
df['Name'].replace('Tom', 'Tom11') #数据替换
df_inner[:'2013-01-04'] #提取4日之前的所有数据
df[df.Name == 'Tom'].Age #姓名为Tom的年龄
info.xlsx
?
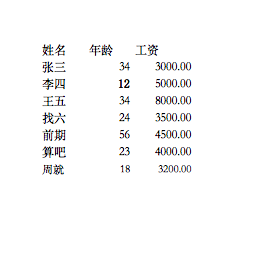
#导入需要用到的模块
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
rcParams['font.family'] = 'simhei'
#读取目标表格文件,并用people代表读取到的表格数据
people = pd.read_excel('/users/jick/desktop/python/info.xlsx')
#x轴是姓名,y轴是年龄,让直方图排序显示,默认升序
people.sort_values(by='age',inplace=True,ascending=False)
#在控制台中输出表格数据
people
#将直方图颜色统一设置为蓝色
people.plot.bar(x='name',y='age',color='#000')
#旋转X轴标签,让其横向写
plt.xticks(rotation=360)
plt.show()?