���

ʲô��Mybatis?
- MyBatis ��һ������ij־ò���.
- ��֧���Զ��� SQL���洢�����Լ���ӳ�䡣
- MyBatis ����˼������е� JDBC �����Լ����ò����ͻ�ȡ������Ĺ�����
- MyBatis ����ͨ���� XML ��ע�������ú�ӳ��ԭʼ���͡��ӿں� Java POJO(Plain Old Java Objects,��ͨ��ʽ Java ����)Ϊ���ݿ��еļ�¼��
- MyBatis ����apache��һ����Դ��Ŀ���� iBatis,
- 2010�������Ŀ��apache software foundation Ǩ�Ƶ���[google code](https://baike.baidu.com/item/google code/2346604),���Ҹ���ΪMyBatis ��
- 2013��11��Ǩ�Ƶ�Github��
- ���������ĵ� �������
���Mybatis
- Maven�ֿ�
<!-- https://mvnrepository.com/artifact/org.mybatis/mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
- Github :Github��������
���ݳ־û�
-
�־û����ǽ�����������ڳ־�״̬��˲ʱ״̬ת���Ĺ��̡�
-
�ڴ�: �ϵ缴ʧ��
-
�־û��ķ�ʽ��: ���ݿ�,IO�ļ��־û� �ȡ�
Ϊʲô��Ҫ�־û�?
- ��һЩ��������,��������������
- �ڴ�̫��
- ��
�־ò�
�����IJ�: �� Dao��,Service��,Controller�㡭
- �־ò��ֳ�Ϊ���ݷ��ʲ���ΪDAL��,������Ҫ�������ݿ��ķ���;
- ��˵,����ͨ��DAL�����ݿ���е�SQL���Ȳ���(CRUD)
- ����ɳ־û������Ĵ����
- ��Ľ�����ʮ�����Եġ�
Ϊʲô��ҪMybatis?
-
��������Գ�����ݴ������ݿ��С�
-
����
-
��ͳ��JDBC������ڸ��ӡ���,���,�Զ�����
-
����MybatisҲ���ԡ�(����û�иߵ�֮��)
-
�ص㼰�ŵ�:
- ����ѧ:ͨ���ĵ���Դ����,���ԱȽ���ȫ�������������˼·��ʵ�֡�
- ���: sqlд��xml��,����ͳһ�������Ż���ͨ��sql����������������ݿ����������
- ���sql������������:ͨ���ṩDAO��,��ҵ���������ݷ���������,sql�ʹ���ķ���,����˿�ά���ԡ�
- �ṩӳ���ǩ,֧�ֶ��������ݿ��orm�ֶι�ϵӳ��
- �ṩ�����ϵӳ���ǩ,֧�ֶ����ϵ�齨ά��
- �ṩxml��ǩ,֧�ֱ�д��̬sql��
-
����Ҫ��ԭ��: ʹ�õ��˶���
��һ��Mybatis����
˼·: ������C>����mybatis��jar���C>��д����C>����!
�����
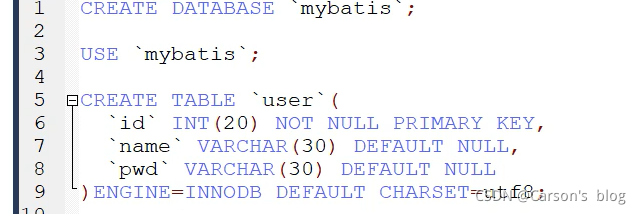
����ݿ⼰���ݱ�
�½���Ŀ
- �½�һ����ͨ��maven��Ŀ
- ɾ��srcĿ¼(���ڴ������ӹ���)
- ��pom.xml����������
<!--��������-->
<!--1.mysql��������-->
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
<!--2.mybatis����-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--3.Junit����-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
����һ��ģ��
- ��дMybatis�ĺ��������ļ�
<!--configuration���������ļ�-->
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/> <!--���������JDBC-->
<dataSource type="POOLED">
<!--�����������ݿ�ĸ�������ֵ-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<!--ע:�����&���ӷ�Ҫ��&���б�ʾ,& �� HTML �� & �ı�ʾ����-->
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!--ÿһ��Mapper.xml����Ҫ��mybatis�ĺ��������ļ���ע��-->
<mappers>
<!--·��Ҫ��/���зָ�-->
<mapper resource="com/carson/dao/UserMapper.xml"/>
</mappers>
</configuration>
- ��дmybatis������
//sqlSessionFactory-->����sqlSession
public class MybatisUtils {
//����������
private static SqlSessionFactory sqlSessionFactory;
//ͨ��SqlSessionFactoryBuilder��ȡ�����ļ��ķ�ʽ����sqlSessionFactoryʵ��
static{
try{
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//��Ȼ���� SqlSessionFactoryʵ��,����˼��,���ǿ��Դ��л�� SqlSession ��ʵ����
//SqlSession �ṩ�������ݿ�ִ�� SQL ������������з�����
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession();
}
}
�����
- ʵ����
package com.carson.pojo;
//ʵ����
public class User {
private int id;
private String name;
private String pwd;
public User() {
}
public User(int id, String name, String pwd) {
this.id = id;
this.name = name;
this.pwd = pwd;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPwd() {
return pwd;
}
public void setPwd(String pwd) {
this.pwd = pwd;
}
}
- Dao�ӿ�
public interface UserDao {
public List<User> getUserList();
}
- �ӿ�ʵ����(��ԭ����UserDaoImplת��Ϊһ��Mapper�����ļ�)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace��Ҫ��һ����Ӧ��Dao/Mapper�ӿ� ·��дȫ-->
<mapper namespace="com.carson.dao.UserDao">
<!--select��ǩ��Ӧselect��ѯ���-->
<!--id��ӦҪʵ�ֵĽӿڵķ���������,resultType��Ӧ����������·��Ҫдȫ-->
<select id="getUserList" resultType="com.carson.pojo.User">
select * from mybatis.user
</select>
</mapper>
����
ʹ��Junit���в���
package com.carson.dao;
import com.carson.pojo.User;
import com.carson.utils.MybatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class UserDaoTest {
@Test
public void test(){
//��һ��,���sqlSession����
SqlSession sqlSession = MybatisUtils.getSqlSession();
//��ʽһ:getMapper
UserDao userDao = sqlSession.getMapper(UserDao.class);
List<User> userList = userDao.getUserList();
//��ʽ��:(���Ƽ�)
//List<User> userList = sqlSession.selectList("com.carson.dao.UserDao.getUserList");
for(User user:userList){
System.out.println(user);
}
//�ر�sqlSession
sqlSession.close();
}
}
��������������?
- maven�г�������xml��Դ����ʧ�����⡣
����Maven��Ŀ������һ��resourcesĿ¼������������е���Դ�����ļ�,����������������Ŀ�в�����������е���Դ�����ļ�������resources��,ͬʱ����Ҳ�п��ܷ�����Ŀ�е�����λ��,��ôĬ�ϵ�maven��Ŀ��������ʱ�Ͳ������������Ŀ¼�µ���Դ�����ļ�������targetĿ¼��,�ͻᵼ�����ǵ���Դ�����ļ���ȡʧ��,�Ӷ��������ǵ���Ŀ���������쳣,����˵����������ʹ��MyBatis���ʱ,����Mapper.xml�����ļ��������dao���к�dao�ӿ������һ���,��ôִ�г����ʱ��,���е�xml�����ļ���һ�����ȡʧ��,�������ɵ�maven��targetĿ¼��,��������Ҫ����Ŀ��pom.xml�ļ��н�������,�����ҽ�����,ÿ�½�һ��maven��Ŀ,�ͰѸ����õ���pom.xml�ļ���,�Է�����!!!
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
- Caused by: com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 1 �ֽڵ� UTF-8 ���е��ֽ� 1 ��Ч��
- Caused by: com.sun.org.apache.xerces.internal.impl.io.MalformedByteSequenceException: 2 �ֽڵ� UTF-8 ���е��ֽ� 2 ��Ч��
�����������(�� xml�ļ��������������)����������:
- ������xml�ļ���**(mybatis-config.xml��UserMapper.xml)**��������ע��ʱ:
- **��mybatis����xml�����ļ�(mybatis-config.xml��UserMapper.xml)�����е�encoding="UTF-8"�е�-ȥ��,����Ϊ:encoding=��UTF8�� **
- ��encoding="UTF-8"����Ϊ:encoding=��GBK��,��ΪJDK���Բ���ϵͳĬ�ϵı����ʽȥ����,�����ǵ��Ե�Ĭ�ϱ�����GBK��
- �����Ե�JDKĬ�ϱ����ΪUTF-8,����Ͳ��ᱨ�������ķ�ʽ: �ο�����
- ������xml�ļ���**(mybatis-config.xml��UserMapper.xml)**û������ע��ʱ:
- ���ڲ���������,�������xml�ļ��������������������ļ�����������,��: encoding="UTF-8"����encoding="UTF-8"
������������������:
- ʵ�ֽӿڵ������ļ�û����mybatis�ĺ��������ļ��н���ע��
- �ӿڴ���
- ����������
- �������Ͳ���
�����ܽ�:
- ��д����sqlSessionFactory�Ĺ�����
- ��дmybatis�ĺ��������ļ�
- ��дpojoʵ����
- ��д�ӿ�
- ��д�ӿ�ʵ�ֵ������ļ�
- ��д���Դ���
Mybatis��CRUD
ע: һ�е���ɾ�Ķ�Ҫ����������
1.namespace
-
ʵ�ֽӿڵ������ļ���namespaceҪ��Dao/Mapper�ӿ���һ�¡�
-
��namespace����ʵ�ֵĽӿ���(Ҫдȫ·��)��
2.select��ǩ
- ʵ�ֽӿڵ������ļ��е�select��ǩ�е�id ��ʾ��Ҫ��д�Ľӿ���ķ�������
- resultType: ��sql���ִ�еķ���ֵ!(������������Ҫдȫ·��)
- parameterType: ��������
- ��д�ӿڷ���
public interface UserMapper {
//��ѯȫ���û�
public List<User> getUserList();
//����Id��ѯ�û�
public User getUserById(int id);
}
- ��д��Ӧ��mapper�����ļ��е�sql���
<mapper namespace="com.carson.dao.UserMapper">
<!--select��ǩ��Ӧselect��ѯ���-->
<!--id��ӦҪʵ�ֵĽӿڵķ���������,resultType��Ӧ����������·��Ҫдȫ-->
<select id="getUserList" resultType="com.carson.pojo.User">
select * from mybatis.user;
</select>
<!--select��ѯ��� #{������}��ʽȥ��дsql���IJ���-->
<select id="getUserById" parameterType="int" resultType="com.carson.pojo.User">
select * from user where id = #{id};
</select>
- ��д���Դ���
//��ѯȫ���û�
@Test
public void test(){
//��һ��,���sqlSession����
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
//��ʽһ:getMapper(��ȡ�ӿڶ���,���÷���)
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> userList = userMapper.getUserList();
//��ʽ��:(���Ƽ�)
//List<User> userList = sqlSession.selectList("com.carson.dao.UserDao.getUserList");
for(User user:userList){
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally {
//�ر�sqlSession
sqlSession.close();
}
}
//����id��ѯ�û�
@Test
public void getUserById(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(2);
System.out.println(user);
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
3.insert��ǩ
- ��д�ӿڷ���
//����һ���û�
public int addUser(User user);
- ��д��Ӧ��mapper�����ļ��е�sql���
<!--insert��� ��Ӧ insert��ǩ-->
<!--�����е�����,����ֱ��ȡ����-->
<insert id="addUser" parameterType="com.carson.pojo.User">
insert into user values(#{id},#{name},#{pwd});
</insert>
- ��д���Դ���
//����һ���û�
@Test
public void addUser(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int affectedRows = mapper.addUser(new User(5, "test", "111111"));
if(affectedRows>0){
//����һ�е���ɾ�Ķ�Ҫ��������,����Ҫ�ύ����
sqlSession.commit();
System.out.println("����ɹ�!");
}
}catch (Exception e){
//���ִ���,����ع�
sqlSession.rollback();
e.printStackTrace();
}finally {
sqlSession.close();
}
}
4.update��ǩ
- ��д�ӿڷ���
//��һ���û�
public int updateUser(User user);
- ��д��Ӧ��mapper�����ļ��е�sql���
<!--update��� ��Ӧ update��ǩ-->
<!--�����е�����,����ֱ��ȡ����-->
<update id="updateUser" parameterType="com.carson.pojo.User">
update user set name=#{name},pwd=#{pwd} where id=#{id};
</update>
- ��д���Դ���
//��һ���û�
@Test
public void updatUser(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int affectedRows = mapper.updateUser(new User(5,"test0","000000"));
if(affectedRows>0){
//����һ�е���ɾ�Ķ�Ҫ��������,����Ҫ�ύ����
sqlSession.commit();
System.out.println("�ijɹ�!");
}
}catch (Exception e){
//���ִ���,����ع�
sqlSession.rollback();
e.printStackTrace();
}finally {
sqlSession.close();
}
}
5.delete��ǩ
- ��д�ӿڷ���
//ɾ��һ���û�
public int delUser(int id);
- ��д��Ӧ��mapper�����ļ��е�sql���
<!--delete��� ��Ӧ delete��ǩ-->
<delete id="delUser" parameterType="int">
delete from user where id = #{id};
</delete>
- ��д���Դ���
//ɾ��һ���û�
@Test
public void delUser(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
int affectedRows = mapper.delUser(5);
if(affectedRows>0){
//����һ�е���ɾ�Ķ�Ҫ��������,����Ҫ�ύ����
sqlSession.commit();
System.out.println("ɾ���ɹ�!");
}
}catch (Exception e){
//���ִ���,����ع�
sqlSession.rollback();
e.printStackTrace();
}finally {
sqlSession.close();
}
}
6.ʵ��ģ����ѯ

-
��ʽһ: ��java����ִ�е�ʱ��,��ʵ�δ���ͨ���% %
�ӿڷ���:
//ģ����ѯʾ��
public List<User> getUserListLike(String value);
? ʵ�ֵĽӿڷ����������ļ�:
<!--ģ����ѯʾ��-->
<select id="getUserListLike" resultType="com.carson.pojo.User">
select * from user where name like #{value };
</select>
? ���Դ���:
//ģ����ѯʾ��
@Test
public void getUserListLike(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.getUserListLike("%��%");
for (User user : users) {
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
- ��ʽ��: ֱ����sqlƴ����ʹ��ͨ���!
? �ӿڷ���:
//ģ����ѯʾ��
public List<User> getUserListLike(String value);
? ʵ�ֵĽӿڷ����������ļ�:
<!--ģ����ѯʾ��-->
<select id="getUserListLike" resultType="com.carson.pojo.User">
select * from user where name like "%"#{value}"%";
</select>
? ���Դ���:
//ģ����ѯʾ��
@Test
public void getUserListLike(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.getUserListLike("��");
for (User user : users) {
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
7.Mybatis�е� #{} �� ${}����
Mybatis ��Mapper.xml�������SQL��䴫�������ַ�ʽ:
��: #{} �� ${}
- ���Ǿ���ʹ�õ���#{},һ���˵����Ϊ���ַ�ʽ���Է�ֹSQLע��,��˵#{}���ַ�ʽSQL����Ǿ���Ԥ�����,���ǰ�#{}�м�IJ���ת����ַ���,�ٸ�����:
select * from student where student_name = #{name}
Ԥ�����,�ᶯ̬������һ��������Ƿ� ? :
select * from student where student_name = ?
- ��ʹ��${}�ڶ�̬����ʱ��,�ᴫ������ַ���
select * from student where student_name = 'carson'
�ܽ�:
-
#{} ����ȡֵ�DZ����SQL�����ȡֵ, ʹ�õ���Ԥ����, ��ӦJBDC�е�PreparedStatement, ʹ��#{}ʱ,�����SQL���IJ�������ϵ�����.
-
${} ������ȡֵ�Ժ���ȥ����SQL���, mybatis�����Ļ���ת���ַ���,ֱ���������ֵ,������Բ��������š�
-
#{}��ʽ�ܹ��ܴ�̶ȷ�ֹsqlע�롣$��ʽ����ֹSqlע�롣
-
һ������#{}�� �ͱ��� ${}
8.���ܵ�Map
����,���ǵ�ʵ����������ݿ��б��� �ֶλ��߲�������,����Ӧ������ʹ��Map!
ʾ������:
- ��д�ӿڷ���(����Map���Ͳ���)
//ʹ�����ܵ�Map�����ݲ���
public int addUser2(Map<String,Object> map);
- ��д��Ӧ��mapper�����ļ��е�sql���
<!--ʹ��map��keyֵ��Ϊ�������д���,��keyֵ�����ֿ��Բ������ݿ��е��ֶ���һ��-->
<insert id="addUser2" parameterType="map">
insert into user values (#{mapId},#{mapName},#{mapPwd});<!--����Map��key-->
</insert>
- ��д���Դ���
//����һ���û�(����Map��keyֵ)
@Test
public void addUser2(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//����map
Map<String, Object> map = new HashMap<String, Object>();
map.put("mapId",5);
map.put("mapName","mapTest");
map.put("mapPwd","654545");
int affectedRows = mapper.addUser2(map);
if(affectedRows>0){
//��ɾ����Ҫ��������,�����ύ����
sqlSession.commit();
System.out.println("Map��ʽ���ӳɹ�!");
}
}catch (Exception e){
//�����쳣,����ع�
sqlSession.rollback();
e.printStackTrace();
}finally{
sqlSession.close();
}
}
ע:
-
Map���ݲ���,ֱ����sql��ȡ��key����!��parameterType=��map����
-
���ݲ���,ֱ����sql��ȡ��������Լ���!
��parameterType=��ʵ������ȫ·������
-
ֻ��һ�������������͵IJ��������,����ֱ����sql��ȡ��!
? ��parameterType=�������������͡������� ����д�������͡�
����: ���������Map ���� ע��!
���ý���
1.���������ļ�
-
��: mybatis-config.xml
-
mybatis�������ļ������˻�����Ӱ��mybatis��Ϊ�����ú�������Ϣ
- properties(����)
- settings(����)
- typeAliases(���ͱ���)
- typeHandlers(���ʹ�����)
- objectFactory(����)
- plugins(���)
- environments(��������)
- environment(��������)
- transactionManager(���������)
- dataSource(����Դ)
- environment(��������)
- databaseIdProvider(���ݿ⳧�̱�ʶ)
- mappers(ӳ����)
2.��������(environments)
Mybatis�������ó���Ӧ���ֻ�����
����Ҫ��ס:���ܿ������ö������,�������ļ���ֻ��ѡ��һ�ֻ���
MybatisĬ�ϵ��������������JDBC, Ĭ�ϵ�����Դ: POOLED(���ӳ�)
ѧ��ʹ�����ö������л�����(ʾ�����Ļ���Ϊtest)
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--ԭ����<environments default="development">
����ͨ��default��Ϊtest(��Ӧ���Ļ�����id)-->
<environments default="test">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
<!--�������ö�����-->
<environment id="test">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true"/>
</dataSource>
</environment>
</environments>
<!--ÿһ��Mapper.xml����Ҫ��mybatis�ĺ��������ļ���ע��-->
<mappers>
<!--·��Ҫ��/���зָ�-->
<mapper resource="com/carson/dao/UserMapper.xml"/>
</mappers>
</configuration>
3.����(properties)
���ǿ���ͨ��properties��ǩ��ʵ�����������ļ���
��Щ���Զ��ǿ��ⲿ�����Ҷ�̬�滻��, �ȿ����ڵ��͵�Java�����ļ�������, ���ͨ��propertiesԪ�ص� ��Ԫ�ر�ǩproperty ������(�����������property����name���Ժ�value���Եķ�ʽ ��������ֵ��)��
properties�����ⲿ�����ļ�ʾ��:
- resources��ԴĿ¼�±�дһ�������ļ�(db.properties)
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
username=root
password=root
- ��Mybatis�ĺ��������ļ�������:

ע: ��ͼ,xml��Ԫ�ر�ǩλ������Ҫ���, �����properties��ǩԪ����Ҫ����configuration ��ǩ����ĵ�һ��λ�á�
- ����ֱ�������ⲿ�����ļ�
<configuration>
<!--�����ⲿ�������ļ�-->
<!--���������ļ���resources��ԴĿ¼,���ļ�·������Ҫдȫ·��-->
<properties resource="db.properties"></properties>
<!---------------------------------------------->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--valueֱֵ�Ӷ�ȡ�����ļ� ${������}�ķ�ʽ-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
- ��������������һЩ�������á�
<configuration>
<!--�����ⲿ�������ļ�-->
<!--���������ļ���resources��ԴĿ¼,���ļ�·������Ҫдȫ·��-->
<properties resource="db.properties">
<!--��properties������һЩ��������-->
<property name="username" value="root"/>
<property name="password" value="root"/>
</properties>
<!---------------------------------------------->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<!--valueֱֵ�Ӷ�ȡ�����ļ� ${������}�ķ�ʽ-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
- ����ⲿ�����ļ����� ��property��ǩ�е�����������ͬһ���ֶ�,������ʹ�� �ⲿ�����ļ����ֶμ���ֵ��
4.���ͱ���(typeAliases)
- ���ͱ�����Ϊ Java��������һ���̵�����
- ���ڵ������������������ ����ȫ����������
- ��ʽһ: ֱ�Ӹ�ʵ���������
<!--���Ը�ʵ��������� ��ǩ˳������Ҫ���-->
<typeAliases>
<!--ֱ�Ӹ�ʵ���������-->
<typeAlias type="com.carson.pojo.User" alias="user" />
</typeAliases>
- ��ʽ��: ����ָ��һ������,Mybatis���ڰ�������������Ҫ��Java Bean,��ͨ��ɨ��ʵ����İ�,Ĭ�ϱ�����Ϊ��������������ĸСд��
<!--���Ը�ʵ��������� ��ǩ˳������Ҫ���-->
<typeAliases>
<!--ͨ��ɨ��ʵ�������ڵİ�,����Ĭ�ϱ��� ��Ϊ ������������Сд-->
<!--����İ��µ�����User, ��Ĭ�ϱ���Ϊ:user-->
<package name="com.carson.pojo" />
</typeAliases>
ע:
-
��ʵ����Ƚ��ٵ�ʱ��,���ͱ��� �Ƽ�ʹ�õ�һ�֡�
-
���ʵ����ʮ�ֶ�,���ͱ��� �Ƽ�ʹ�õڶ��֡�
-
��һ�����ͱ����ķ�ʽ���� DIY������
-
�ڶ������ͱ����ķ�ʽ����DIY����; �����Ҫ��,����Ҫ��ʵ����������ע�⡣��:
@Alias("user") public class User{...}
ע: ������һЩΪ������ Java ���� �ڽ������ͱ���
| ������ | ӳ���Ӧ������ |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
| �� |
��:�����������͵�Ĭ�ϱ���Ϊ: _��������
? ��װ���͵�Ĭ�ϱ���Ϊ: ��װ���͵�Сд��ʽ
5.����
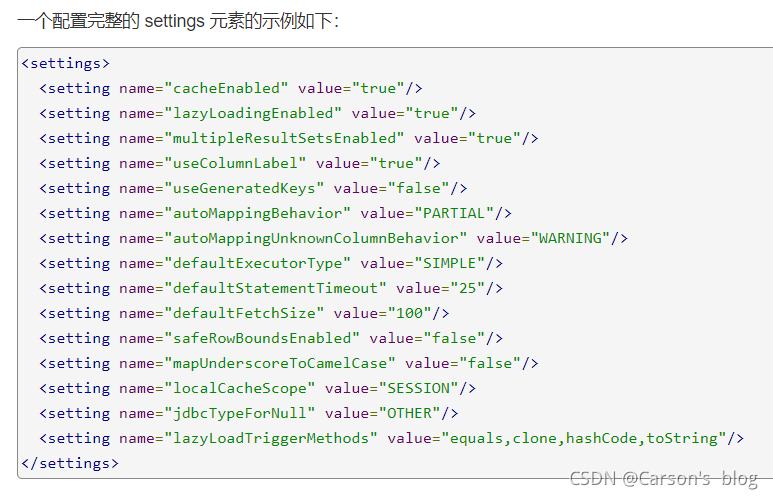
����Mybatis�м�Ϊ��Ҫ�ĵ�������,���ǻ�ı� Mybatis������ʱ��Ϊ��


ʾ��:
6.��������
- typeHandlers(���ʹ�����)
- objectFactory(����)
- plugins(���)
- mybatis-generator-core
- mybatis-plus
- ͨ��mapper
7.ӳ����(mappers)
MapperRegistry: ע������ǵ�Mapper�ļ�;
- ��ʽһ:���Ƽ�ʹ����
<!--ÿһ��Mapper.xml����Ҫ��mybatis�ĺ��������ļ���ע��-->
<mappers>
<!--·��Ҫ��/���зָ�-->
<mapper resource="com/carson/dao/UserMapper.xml"/>
</mappers>
- ��ʽ��:
<!--ÿһ��Mapper.xml����Ҫ��mybatis�ĺ��������ļ���ע��-->
<mappers>
<mapper class="com.carson.dao.UserMapper"/>
</mappers>
ע���:
- �ӿں�����Mapper�����ļ�����ͬ��
- �ӿں�����Mapper�����ļ�������ͬһ�����¡�
- ��ʽ��: ʹ��ɨ�������ע���
<!--ÿһ��Mapper.xml����Ҫ��mybatis�ĺ��������ļ���ע��-->
<mappers>
<package name="com.carson.dao"/>
</mappers>
ע���:
- �ӿں�����Mapper�����ļ�����ͬ��
- �ӿں�����Mapper�����ļ�������ͬһ�����¡�
8.�������ں�������
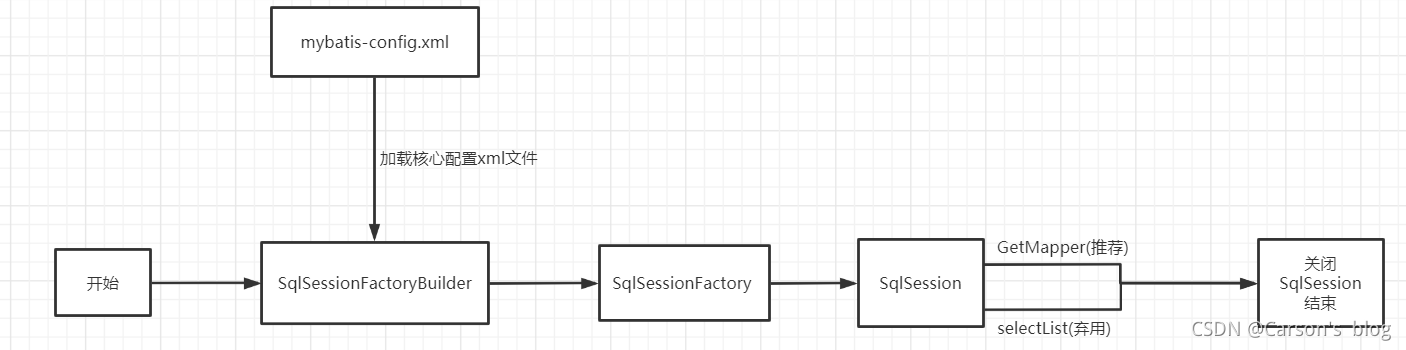
�������ں�������,��������Ҫ��,�������ʹ�ûᵼ�·dz����صIJ������⡣
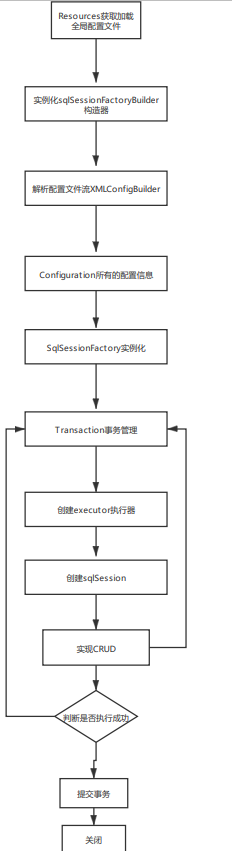
SqlSessionFactoryBuilder:
- SqlSessionFactoryBuilderһ��������SqlSessionFactory,�Ͳ�����ҪSqlSessionFactoryBuilder�ˡ�
- �ֲ�������
SqlSessionFactory:
- �൱��һ��: ���ݿ����ӳ�
- SqlSessionFactoryһ����������Ӧ����Ӧ�õ������ڼ�һֱ����,û�����ɶ����������´���һ��SqlSessionFactory.
- ���,SqlSessionFactory�������������Ӧ��������
- ��ľ���ʹ�� ����ģʽ ���� ��̬����ģʽ��
SqlSession:
- �൱�����ӵ����ӳص�һ������!
- SqlSession��ʵ�������̰߳�ȫ��,����Dz��ܱ�������,����������������� �� ����������
- ����֮��Ҫ�Ͻ��ر�,������Դ��ռ��!
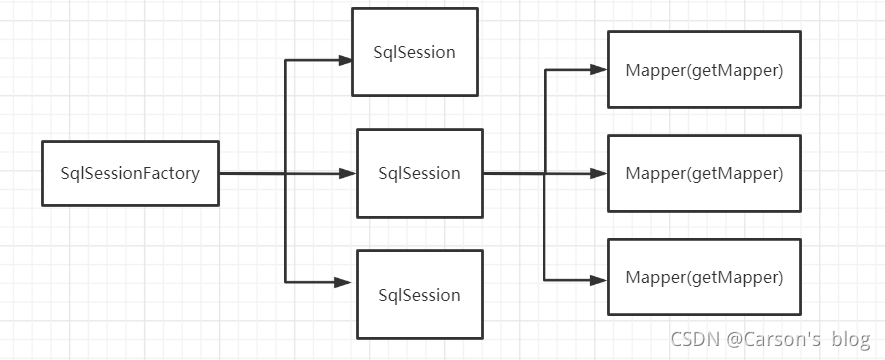
�������ÿһ��Mapper,�Ϳ��Դ���һ�������ҵ��
ʵ���������������ݿ���ֶ�����һ�µ�����
1. ����
���ݿ��е��ֶ�:
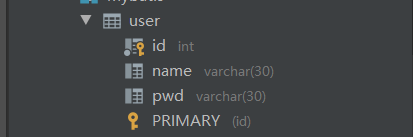
ʵ�����е��ֶ�:
public class User{
private int id;
private String name;
private String password;
......
}
Mapper.xml�ļ�:
<mapper namespace="com.carson.dao.UserMapper">
<select id="getUserById" parameterType="int" resultType="com.carson.pojo.User">
select * from user where id = #{id};
</select>
</mapper>
���Դ���:
//����id��ѯ�û�(�����û�����)
@Test
public void getUserById(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.getUserById(1);
System.out.println(user);
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
ִ�н��: (����pwd��password����Ӧ, �����������)

�������:
- SQL����н��ֶ� �����
<mapper namespace="com.carson.dao.UserMapper">
<select id="getUserById" parameterType="int" resultType="user">
select id,name,pwd as password from user where id = #{id};
</select>
</mapper>
- �����ӳ��
<mapper namespace="com.carson.dao.UserMapper">
<!--�����ӳ�� id:��ʶ�� type:��Ҫӳ���pojo-->
<resultMap id="userMap" type="User">
<!--column:���ݿ��е��ֶ� property:ʵ�����е�����-->
<!--����Ҫ����ֶ�ӳ����ֶβ���Ҫдresult��ǩ����ӳ��-->
<result column="pwd" property="password"></result>
</resultMap>
<select id="getUserById" parameterType="int" resultMap="userMap">
select * from user where id = #{id};
</select>
</mapper>
Ȼ����ʹ�����������ʹ��resultMap���ԾͿ�����(ע��ȥ���� resultType����)
<select id="getUserById" parameterType="int" resultMap="userMap">
select * from user where id = #{id};
</select>
2. �����ӳ��
- resultMapԪ����Mybatis������Ҫ��ǿ��ı�ǩԪ��
- Ĭ�������,MyBatis ����Ļ���Զ�����һ��
ResultMap,�ٸ�����������ӳ���е� JavaBean �������ϡ� - ResultMap�����˼��: ���ڼ�����������Ҫ������ʽ�Ľ��ӳ��,�����ڸ���һ������ֻ��Ҫ�������ǵĹ�ϵ�����ˡ�
- ResultMap������ĵط�����,��Ȼ���Ѿ��������൱�˽�,���Ǹ�������Ҫ��ʽ���õ����ǡ�
- �������ݿɲο�:�ٷ��ĵ�
��־
1.��־����
���һ�����ݿ����,�����˴���,��Ҫ�Ų�Ļ�����־������õĹ��ߡ�
��ǰ�Ų�ķ�ʽ: print��ӡ��� �� debug
�����Ų�ķ�ʽ: ��־����

- LOG4J ���ص����ա�
- STDOUT_LOGGING ���ص����ա�
- SLF4J
- JDK_LOGGING
- COMMONS_LOGGING
- NO_LOGGING
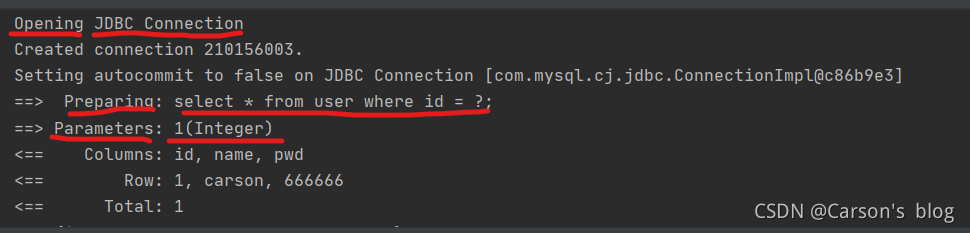
��Mybatis�о���ʹ����һ����־ʵ��,��mybatis�ĺ��������ļ��е�setting��ǩ�������á�
����mybaits�ĺ��������ļ������� STDOUT_LOGGING(����־���)Ϊ��:
<!--������־����-->
<settings>
<!--������־������ʵ�� ע���ַ����в��ܺ��пո�-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
2.LOG4J
ʲô��LOG4J ?
-
Log4j��һ�� �ⲿ����, ��ʹ��Log4j��Ҫ������
-
Log4j��Apache��һ����Դ��Ŀ,ͨ��ʹ��Log4j,���ǿ��Կ�����־��Ϣ���͵�Ŀ�ĵ�������̨���ļ���GUI����ȡ�
-
���Կ���ÿһ����־�������ʽ;
-
ͨ������ÿ����־��Ϣ�ļ���,�����ܹ�ϸ�µؿ�����־�����ɹ��̡�
-
����ͨ��һ�������ļ������ؽ�������,������Ҫ��Ӧ�õĴ��롣
ʹ����:
- �ȵ���Log4j�İ�:
<dependencies>
<!--����LOG4J��־����-->
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
- ��д�����ļ�,�� log4j.properties:
����Log4j���Կ�����־��Ϣ���͵�Ŀ�ĵ���/����̨(console)/�ļ�(file)/GUI�����; ��������־�����console��file�������ļ�Ϊ�� :
#���ȼ�ΪDEBUG����־��Ϣ�����console��file������Ŀ�ĵ�,console��file�Ķ���������Ĵ���
log4j.rootLogger=DEBUG,console,file
#����̨������������
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern = [%c]-%m%n
#�ļ�������������
log4j.appender.file = org.apache.log4j.RollingFileAppender
#��־�ļ�������ļ�λ��
log4j.appender.file.File = ./log/carson.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold = DEBUG
log4j.appender.file.layout = org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern = [%p][%d{yy-MM-dd}][%c]%m%n
#��־�������(����DEBUG�ȼ������)
log4j.logger.org.mybatis = DEBUG
log4j.logger.java.sql = DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement = DEBUG
- ����log4jΪ��־��ʵ��
<!--������־����-->
<settings>
<!--����LOG4JΪ��־��ʵ�� ע���ַ��������пո�-->
<setting name="logImpl" value="LOG4J"/>
</settings>
- ���в��Դ���:
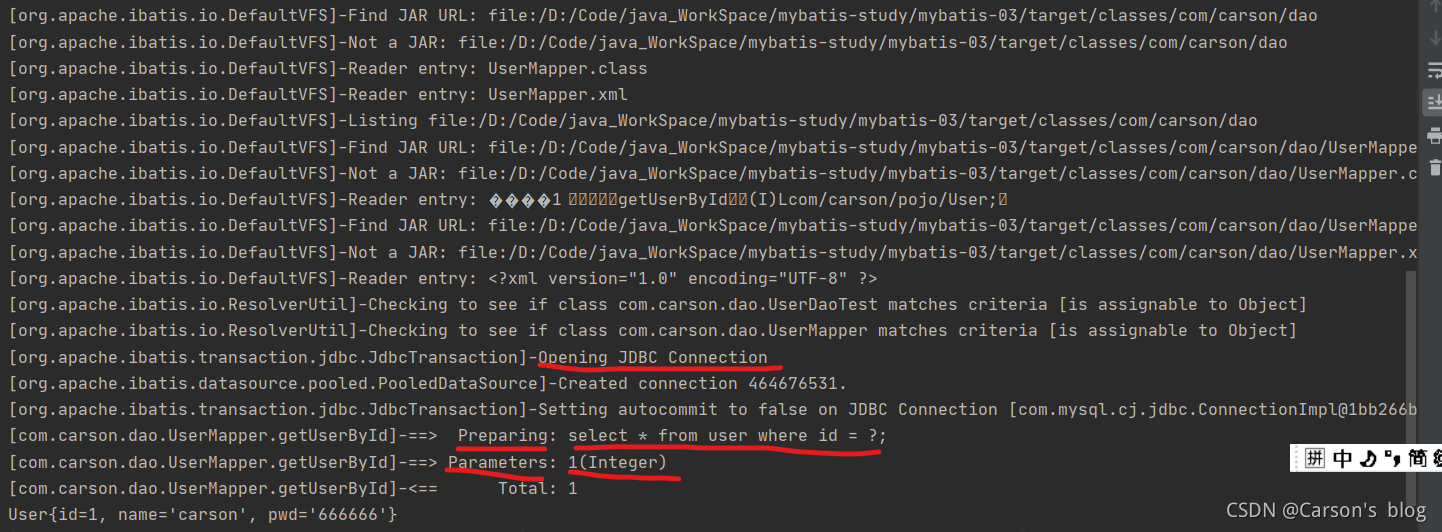
LOG4J�ļ�ʹ��:
-
��Ҫʹ��LOG4J������,�����
��: import org.apache.log4j.Logger
-
ʵ������־����,����Ϊ: ��ǰ���class
//ʵ������־����,Logger.getLogger�IJ���Ϊ ��ǰ���class
static Logger logger = Logger.getLogger(UserDaoTest.class);
- ���в��Դ���:
package com.carson.dao;
import com.carson.pojo.User;
import com.carson.utils.MybatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.apache.log4j.Logger;
import org.junit.Test;
public class UserDaoTest {
//ʵ������־����
static Logger logger = Logger.getLogger(UserDaoTest.class);
/*����log4j��־�ķ���*/
@Test
public void log4jTest(){
logger.info("info:������Log4j�IJ��Է���");
logger.debug("debug:������Log4j�IJ��Է���");
logger.error("error:������Log4j�IJ��Է���");
}
}

��־����(���):
�� ÿ����־��Ϣ�ļ���(��: **debug/error/info **�ȼ���)
�����ܹ�ϸ�µؿ�����־�����ɹ���,�����Կ��������ͬ�������־��Ϣ��
logger.info("info:������Log4j�IJ��Է���");
logger.debug("debug:������Log4j�IJ��Է���");
logger.error("error:������Log4j�IJ��Է���");
��ҳ
ΪʲôҪ��ҳ? -----> �������ݵĴ�����
ʹ��Limit��ҳ
�: SELECT * FROM user limit startIndex,pageSize;
select * from user limit 3; #һ��������[0,n]
��mybatis��ʹ��limit���з�ҳ :
- �ӿ�
//limitʵ�ַ�ҳ
public List<User> getUserByLimit(Map<String,Integer> map);
- Mapper.xml
<!--limitʵ�ַ�ҳ-->
<select id="getUserByLimit" parameterType="map" resultMap="userMap">
select * from user limit #{startIndex},#{pageSize};
</select>
- ����
//limit��ҳ���Է���
@Test
public void getUserByLimit(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//����map
HashMap<String, Integer> map = new HashMap<String, Integer>();
map.put("startIndex",1);
map.put("pageSize",4);
List<User> userList = mapper.getUserByLimit(map);
for (User user : userList) {
System.out.println(user);
}
}catch(Exception e){
e.printStackTrace();
}finally{
sqlSession.close();
}
}
RowBounds��ҳ
����ʹ��SQLʵ�ַ�ҳ��
- �ӿ�:
//RowBoundsʵ�ַ�ҳ
public List<User> getUserByRowBounds();
- Mapper.xml
<!--RowBoundsʵ�ַ�ҳ-->
<select id="getUserByRowBounds" resultMap="userMap">
select * from user;
</select>
- ����:
//RowBoundsʵ�ַ�ҳ
@Test
public void getUserByRowBounds(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
//RowBoundsʵ��
RowBounds rowBounds = new RowBounds(1, 4);
//ͨ��java�������ʵ�ַ�ҳ
List<User> userList = sqlSession.selectList("com.carson.dao.UserMapper.getUserByRowBounds", null, rowBounds);
for (User user : userList) {
System.out.println(user);
}
sqlSession.close();
}
��ҳ���ʵ�ַ�ҳ
֪���˽⼴��!
ʹ��ע���
- ע���ڽӿ���ʵ��:
public interface UserMapper {
//ʹ��ע���ѯȫ���û�
@Select("select * from user")
public List<User> getUsers();
}
- ��Mybatis�ĺ��������ļ��аӿ�
<!--�ӿ�-->
<mappers>
<mapper class="com.carson.dao.UserMapper"/>
</mappers>
- ��д���Դ���:
@Test
public void test(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
//�ײ���ҪӦ�� ����
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
List<User> users = mapper.getUsers();
for (User user : users) {
System.out.println(user);
}
}catch (Exception e){
e.printStackTrace();
}finally{
sqlSession.close();
}
}
ע��:
-
ʹ��ע�ⲻ��Ҫ��д�ӿ���Ӧ��xml�ļ���
-
����: �������ʵ��
-
ʹ��ע����ӳ�������ʹ�������ࡣȻ�����ڸ��ӵ����,Javaע�������������,���һ��Եø��ӻ��ҡ�
-
���,�����Ҫ��ɸ��ӵ�����,���ʹ��XML��ӳ����䡣
Mybatisִ������
CRUD
- �����ڹ����ഴ����ʱ�������Զ��ύ����(�����������������)
//true����Ϊ�Զ��ύ����
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession(true);
}
- ��д�ӿ�,����ע��
public interface UserMapper {
//ʹ��ע���ѯȫ���û�
@Select("select * from user")
public List<User> getUsers();
//ʹ��ע���ѯ�ص�id�û�(������������Ҫ@Param)
@Select("select * from user where id = #{id}")
public User getUserById(@Param("id") int id);
//ע�������û�(�����������Ͳ���@Param)
@Insert("insert into user values(#{id},#{name},#{password})")
public int addUser(User user);
//ע�����һ���û���Ϣ
@Update("update user set name=#{name},pwd=#{password} where id=#{id}")
public int updateUser(User user);
//ע�����idɾ��һ���û�(������������Ҫ@Param)
@Delete("delete from user where id=#{uid}")
public int delUser(@Param("uid")int id);
}
- ע���ں��������ļ��аӿ�
<!--�ӿ�-->
<mappers>
<mapper class="com.carson.dao.UserMapper"/>
</mappers>
- ��д���Դ�����Լ��ɡ�
����@Paramע��:
- �������͵IJ�������String����,��Ҫ���β�ǰ��������ע�⡣
- �������͵����ݲ��ü����ע�⡣
- ���ֻ��һ�����������βεĻ�,���Ժ��Բ�д,������д�ϡ�
- ������SQL�����õľ������������@Param���趨����������
Lombok
- java library plugin
- build tools
- with one annotation your class
- ��Ҳ������дһЩGetter��Setter����,��һ��ע�⼴��ʵ�֡�
- �� ͵���õIJ����
ʹ�ò���:
- ��IDEA����������װLombok���
- ����Ŀ�е���Lombok��jar��
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
- ��ʵ�����ϼ�ע�⼴�ɡ�
@Data
@AllArgsConstructor
@NoArgsConstructor
......
���һ����
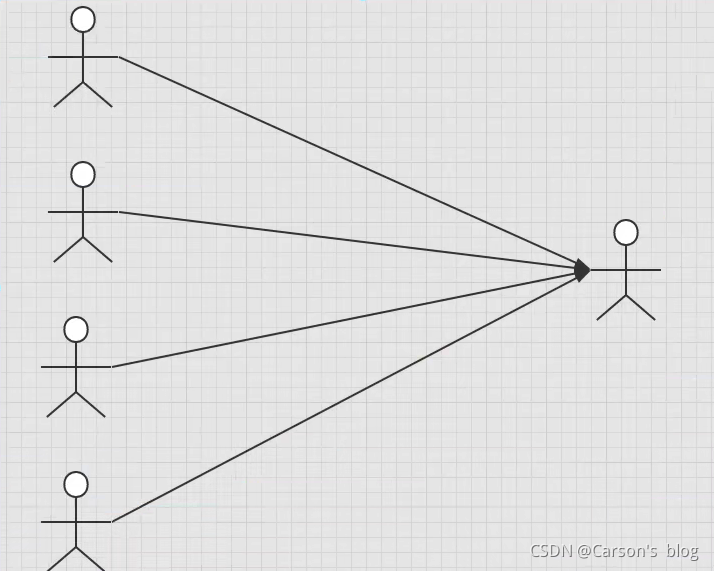
- ���ѧ�������Ӧһ����ʦ����
- ����ѧ�����,���ѧ�� ���� һ����ʦ�������һ��
- ������ʦ���,һ����ʦ �� �ܶ��ѧ������һ�Զࡿ
���Ի����
- ������Ӧ�����ݿ�����ֶ�:(����ѧ������tid�ֶβ�����ʦ����id�ֶ�)
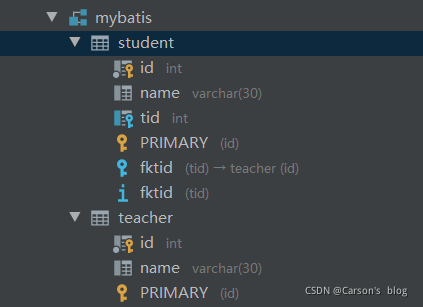
- �½�ʵ����
public class Teacher {
private int id;
private String name;
.......
}
public class Student {
private int id;
private String name;
//�������ݱ����ֶ������������ϵ
//ʵ����Ҳ��Ҫ���й���,�������ݰ�ȫ�ɾ�
//��ѧ����Ҫ����һ����ʦ����
private Teacher teacher;
......
}
- ����Mapper�ӿ�
public interface TeacherMapper {
//��sql��ע��,����sql��xml�����ļ�
//ʹ�ü�ע���ѯ�ض�id����ʦ
@Select("select * from teacher where id=#{tid}")
public Teacher getTeacherById(@Param("tid")int id);
}
public interface StudentMapper {
}
- �����ӿڶ�Ӧ��Mapper.xml�ļ�
- �ں��������ļ��а�Mapper�ӿڻ���xml�ļ��������ܶ�,����ѡ��
<!--���������ļ��ӿ�-->
<mappers>
<mapper class="com.carson.dao.TeacherMapper"/>
<mapper class="com.carson.dao.StudentMapper"/>
</mappers>
- ��д���Դ�����в��ԡ�
���ղ�ѯǶ�״���
�ص�: SQL��,��ǩ��д���ӡ�(����SQL�е��Ӳ�ѯ)
<!--��ѯ����ѧ������Ϣ����Ӧ����ʦ��Ϣ
˼·:(SQLǶ�ײ�ѯ��˼·)��д������ǩ
1 ��ѯ����ѧ������Ϣ
2 ���ݲ�ѯ������ѧ��tid��Ϣ,��ѯ��Ӧ����ʦ��Ϣ-->
<select id="getStudents" resultMap="StudentMap">
select * from student
</select>
<resultMap id="StudentMap" type="Student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!--���ӵ�����,������Ҫ��������
����: association ����: collection
����javaTypeָ�����������, select�����൱��Ƕ����һ����ѯ���
-->
<association property="teacher" column="tid" javaType="Teacher" select="getTeachers" />
</resultMap>
<select id="getTeachers" resultType="Teacher">
select * from teacher
</select>
���ս��Ƕ�״���(�Ƽ�)
�ص�: SQL����,��ǩ��д��(����SQL�е�������ѯ)
<!--���ս��Ƕ�ײ�ѯ-->
<select id="getStudents2" resultMap="StudentMap2">
select s.id sid,s.name sname,t.name tname from student s,teacher t where s.tid = t.id
</select>
<resultMap id="StudentMap2" type="Student">
<result property="name" column="sname" />
<result property="id" column="sid"/>
<!--���Ӷ�������,����:association ����:collection-->
<association property="teacher" javaType="Teacher">
<result property="name" column="tname"/>
</association>
</resultMap>
һ�Զദ��
����: һ����ʦӵ�ж��ѧ��!
������ʦ����,����һ�Զ�Ĺ�ϵ!
���Ի����
-
���ݿ�����ֶ�ͬ�ϡ�
-
ʵ����
public class Student {
private int id;
private String name;
private int tid;
......
}
public class Teacher {
private int id;
private String name;
//һ����ʦ�ж��ѧ��
private List<Student> students;
......
}
- ����Mapper�ӿ�
public interface TeacherMapper {
//���Ի�ȡ���е���ʦ
public List<Teacher> getTeacher();
}
- �����ӿڶ�Ӧ��Mapper.xml�ļ�
<!--namespaceָ��ʵ�ֵĽӿ�-->
<mapper namespace="com.carson.dao.TeacherMapper">
<!--���Ի�ȡ������ʦ-->
<select id="getTeacher" resultType="Teacher">
select * from teacher
</select>
</mapper>
- �ں��������ļ��а�Mapper�ӿڻ���xml�ļ��������ܶ�,����ѡ��
<!--���������ļ��ӿ�-->
<mappers>
<mapper class="com.carson.dao.TeacherMapper"/>
<mapper class="com.carson.dao.StudentMapper"/>
</mappers>
- ��д���Դ�����в��ԡ�
���ղ�ѯǶ�״���:
<!--���ղ�ѯǶ�״���-->
<select id="getTeacher2" resultMap="TeacherMap2">
select * from teacher
</select>
<resultMap id="TeacherMap2" type="Teacher">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!--���ӵĶ���,��Ҫ��������,����:association ����:collection
javaType: ָ�����Ե�����
ofType: ���������еķ�����Ϣ-->
<collection property="students" javaType="ArrayList" ofType="Student" column="id" select="getStudent"/>
</resultMap>
<select id="getStudent" resultType="Student">
select * from student where tid=#{tid}
</select>
���ս��Ƕ�״���(�Ƽ�)
<!--�����Ƕ�ײ�ѯ-->
<select id="getTeacher" resultMap="TeacherMap">
select s.id sid,s.name sname,t.name tname,t.id tid from student s,teacher t where s.tid=t.id and t.id=#{tid}
</select>
<resultMap id="TeacherMap" type="Teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<!--���ӵĶ���,��Ҫ��������,����:association ����:collection
javaType: ָ�����Ե�����
ofType: ���������еķ�����Ϣ-->
<collection property="students" ofType="Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="tid" column="tid"/>
</collection>
</resultMap>
��:
-
����: association �����һ��
-
����: collection ��һ�Զࡿ
-
����javaType �� ofType
- javaType ����ָ��ʵ���������Ե�����
- ofType ����ָ��ӳ�䵽�����е�pojo����,�������е�Լ������
ע���:
- ��֤SQL�Ŀɶ���,������֤ͨ����
- ע�� һ�Զ� �� ���һ,���������ֶε����⡣
- ���ղ�ѯǶ�״���
- ���ս��Ƕ�״���**(�Ƽ�)**
��̬SQL
ʲô�Ƕ�̬SQL:��̬SQL����ָ���ݵIJ�ͬ���������ɲ�ͬ��SQL�����
��̬SQL�ı���: ���ʻ���SQL���,ֻ�ǿ�����SQL����ִ����������
����ù� JSTL ���κλ����� XML ���Ե��ı�������,�Զ�̬ SQL Ԫ�ؿ��ܻ�о�������ʶ��MyBatis ֮ǰ�İ汾��,��Ҫ��ʱ���˽������Ԫ�ء�
MyBatis 3 �滻��֮ǰ�Ĵ�Ԫ��,������Ԫ������,����Ҫѧϰ��Ԫ�������ԭ����һ�뻹Ҫ����
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
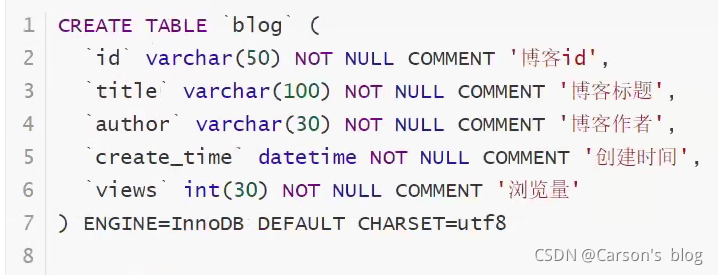
���Ի����
��Ҫ�õ������ݿ��:
��Ҫ�õ��� ����UUID�Ĺ�����:
package com.carson.utils;
import org.junit.Test;
import java.util.UUID;
//��ѹ����
@SuppressWarnings("all")
public class IDutils {
public static String getId(){
//����UUID��Ϊ��¼id���з���,ȷ��ÿ����¼��Ψһ��
return UUID.randomUUID().toString().replaceAll("-","");
}
//����UUID�ܷ���ȷ����
@Test
public void test(){
System.out.println(IDutils.getId());
System.out.println(IDutils.getId());
System.out.println(IDutils.getId());
}
}
����һ��maven��������:
- maven��pom.xml��������Դ��������:
<!--�½�maven��Ŀ,����������Դ��������,��ֹ��Դ����ʧ��-->
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/java/com/carson/dao</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
- ��дmybatis�ĺ��������ļ�
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!--configuration���������ļ�-->
<configuration>
<!--�����ⲿ�������ļ�-->
<!--���������ļ���resources��ԴĿ¼��,���ļ�·������Ҫдȫ·��-->
<properties resource="db.properties"/>
<!--������־����-->
<settings>
<!--����Ϊ����־���-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!--�Ƿ����շ������Զ�ӳ��
���Ӿ������ݿ����� A_COLUMN ӳ�䵽���� Java ������ aColumn
-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--���Ը�ʵ��������� ��ǩ˳������Ҫ���-->
<typeAliases>
<!--ͨ��ɨ��ʵ�������ڵİ�,����Ĭ�ϱ��� ��Ϊ ������������Сд-->
<!--����İ��µ�����User, ��Ĭ�ϱ���Ϊ:user-->
<package name="com.carson.pojo" />
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/><!--�������JDBC-->
<dataSource type="POOLED">
<!--valueֱֵ�Ӷ�ȡ�����ļ� ${������}�ķ�ʽ-->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!--���������ļ��ӿ�-->
<mappers>
<mapper class="com.carson.dao.BlogMapper"/>
</mappers>
</configuration>
- ��дʵ����
package com.carson.pojo;
import java.util.Date;
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;//�������������ֶβ�һ��,�ں��������ļ��п����շ�ӳ��
private int views;
public Blog() {
}
public Blog(String id, String title, String author, Date createTime, int views) {
this.id = id;
this.title = title;
this.author = author;
this.createTime = createTime;
this.views = views;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public int getViews() {
return views;
}
public void setViews(int views) {
this.views = views;
}
@Override
public String toString() {
return "Blog{" +
"id='" + id + '\'' +
", title='" + title + '\'' +
", author='" + author + '\'' +
", createTime=" + createTime +
", views=" + views +
'}';
}
}
- ��дʵ�����Ӧ��Mapper�ӿں�Mapper.xml�ļ�
public interface BlogMapper {
//��������
public int addBlog(Blog blog);
}
<mapper namespace="com.carson.dao.BlogMapper">
<!--��������-->
<insert id="addBlog" parameterType="Blog">
insert into blog values(#{id},#{title},#{author},#{createTime},#{views})
</insert>
</mapper>
- ��д���Դ��� ����������
public class DaoTest {
//���Բ�������
public static void main(String[] args) {
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
//create a blog object
Blog blog = new Blog();
blog.setId(IDutils.getId());//ID����ΪUUID,ȷ��Ψһ��
blog.setTitle("Mybatis���easy!");
blog.setAuthor("Carson");
blog.setCreateTime(new Date());
blog.setViews(9999);
int affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("�������ݳɹ�");
}
blog.setId(IDutils.getId());
blog.setViews(1000);
blog.setTitle("JAVA���easy!");
affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("�������ݳɹ�");
}
blog.setId(IDutils.getId());
blog.setViews(9999);
blog.setTitle("Spring���easy!");
affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("�������ݳɹ�");
}
blog.setId(IDutils.getId());
blog.setViews(9999);
blog.setTitle("�������easy!");
affectedRows = mapper.addBlog(blog);
if(affectedRows>0){
System.out.println("�������ݳɹ�");
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
}
�� ����Java�ű�Ҳ����ʵ��SQL�ű������ݷ�����
��̬SQL֮IF���
����: �����������ʱ�����ض���¼,����������ʱ�����м�¼
�������:
����һ: �ӿ�����д�������(������������ķ�����û����������ķ���)
������: ���ö�̬SQL��IF�������(test���Զ�Ӧһ��������ʽ)
- ��̬SQLͨ��Ҫ�����������������������Ƿ��where�Ӿ�����һ��������
- ��дMapper�ӿڷ���:
//��̬SQL֮IF���ʵ�ֲ�ѯ���ͼ�¼
public List<Blog> queryBlogIF(Map map);
- ��д�ӿڶ�Ӧ��Mapper.xml�ļ�:
<!--��̬SQL֮IF���ʵ�ֲ�ѯ���ͼ�¼-->
<select id="queryBlogIF" parameterType="map" resultType="blog">
select * from blog where 1=1
<if test="title != null">
and title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</select>
- ��д���Դ���:
//��̬SQL��ѯ���ͼ�¼
@Test
public void queryBlogIF(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
Map map = new HashMap();
//map.put("title","Mybatis���easy!");
//map.put("author","Carson");
List<Blog> blogs = mapper.queryBlogIF(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
��̬SQL֮ trim (where, set)
where
-
����ʹ��where��ǩ����������
-
<select id="queryBlogIF" resultType="blog"> SELECT * FROM blog WHERE <if test="state != null"> state = #{state} </if> <if test="title != null"> AND title like #{title} </if> </select> -
���û��ƥ�����������ô��?�������� SQL ��������:(��ѯʧ��)
-
SELECT * FROM blog WHERE -
���ƥ���ֻ�ǵڶ��������ֻ�����?���� SQL ��������:(��ѯʧ��)
-
SELECT * FROM blog WHERE AND title like ��someTitle��
-
ʹ��where��ǩ��
-
where Ԫ��ֻ������Ԫ�ط������ݵ�����²Ų��� ��WHERE�� �Ӿ䡣����,��where����Ԫ�صĿ�ͷΪ ��AND�� �� ��OR��,where Ԫ��Ҳ�Ὣ����ȥ����
-
<!--��̬SQL֮where��ǩʵ�ֲ�ѯ���ͼ�¼--> <select id="queryBlogWhere" parameterType="map" resultType="blog"> select * from blog <where> <if test="title != null"> title = #{title} </if> <if test="author != null"> and author = #{author} </if> </where> </select> -
��ƥ���һ������ʱ,�������� SQL ��������:
-
select * from blog WHERE title = ? -
��ƥ��ڶ�������ʱ,����Զ���andȥ��,���������� SQL ��������:
-
select * from blog WHERE author = ? -
��ƥ���һ����������������ʱ,�������where�Ӿ�, SQL ��������:
-
select * from blog -
ͨ���Զ��� trim Ԫ�������� where Ԫ�صĹ���
-
�� where Ԫ�صȼ۵��Զ��� trim Ԫ��Ϊ:
-
<trim prefix="WHERE" prefixOverrides="AND |OR "> ... </trim> -
prefixOverrides ���Ի����ͨ���ܵ����ָ����ı�����(ע��prefixOverrides�еĿո��DZ�Ҫ��)���������ӻ��Ƴ����� prefixOverrides ������ָ��������,���Ҳ��� prefix ������ָ�������ݡ�
-
������sql�ĵȼ���ʽΪ:
-
<select id="queryBlogWhere" parameterType="map" resultType="blog"> select * from blog <trim prefix="where" prefixOverrides="AND | OR"> <if test="title != null"> title = #{title} </if> <if test="author != null"> and author = #{author} </if> </trim> </select>
-
SET
-
���ڶ�̬���µ�SQL�������ƽ���������� set��ǩ��set Ԫ�ؿ������ڶ�̬������Ҫ���µ���,�������������µ��С�set Ԫ�ػᶯ̬�������ײ��� SET �ؼ���,����ɾ������Ķ��š�����:
-
<!--��̬SQL֮SETʵ���IJ��ͼ�¼--> <update id="updateBlogBySet" parameterType="map"> update blog <set> <if test="title != null"> title = #{title}, </if> <if test="author != null"> author = #{author} </if> </set> where id = #{id} </update> -
����������������ʱ,�����sql���Ϊ:
-
update blog SET title = ?, author = ? where id = ? -
����һ����������ʱ,���Զ�ȥ������,�������sql���Ϊ:
-
update blog SET title = ? where id = ?
-
-
�� set Ԫ�صȼ۵��Զ��� trim Ԫ��
-
�����˺�ֵ����,�����Զ�����ǰֵ��
-
<trim prefix="SET" suffixOverrides=","> ... </trim> -
������sql�ĵȼ���ʽΪ:
-
<update id="updateBlogBySet" parameterType="map"> update blog <trim prefix="SET" suffixOverrides=","> <if test="title != null"> title = #{title}, </if> <if test="author != null"> author = #{author}, </if> </trim> where id = #{id} </update>
-
��̬SQL֮ choose (when, otherwise)
��ʱ��,���Dz���ʹ�����е�����,��ֻ����Ӷ��������ѡ��һ��ʹ�á�����������,MyBatis �ṩ�� choose Ԫ��,���е��� Java �е� switch ��䡣
-
<!--��̬SQL֮choose,when,otherwiseʵ�ֲ�ѯ���ͼ�¼--> <select id="queryBlogChoose" parameterType="map" resultType="blog"> select * from blog <where> <choose> <when test="title != null"> title = #{title} </when> <when test="author != null"> and author = #{author} </when> <otherwise> and views = #{views} </otherwise> </choose> </where> </select>-
����������������ʱ,**ѡ���һ��ִ��,**�����sqlΪ:
-
select * from blog WHERE title = ? -
��ֻ�е�������������ʱ,ֻ����Ĭ�����,�����sqlΪ:
-
select * from blog WHERE views = ? -
��choose�������ϵ��µ�˳�����һ��������������
-
SQLƬ��
�е�ʱ��,���ǿ��ܻὫһЩ��ͬ���ܵĴ��벿����ȡ����,���㸴��!
- ʹ��sql��ǩ��ȡ�����IJ��֡�
<!--��ȡSQLƬ��ʵ�ֲ�ѯ���ͼ�¼-->
<sql id="if-title-author">
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
and author = #{author}
</if>
</sql>
- ����Ҫʹ�õĵط�ʹ��include��ǩ���ü��ɡ�
<!--SQLƬ�β���-->
<select id="queryBlogBySql" parameterType="map" resultType="blog">
select * from blog
<where>
<include refid="if-title-author"></include>
</where>
</select>
ע������:
- ����ǻ��ڵ���������SQLƬ��!
- ��ȡ�Ĺ�ͬ�����в�Ҫ����where��ǩ!��Ϊ��������չ��!
��̬SQL֮ foreach
��̬ SQL һ������ʹ�ó����ǶԼ��Ͻ��б���(�������ڹ��� IN �������ʱ)��
- ��д�ӿڷ���:
//��̬SQL֮foreachʵ�ֲ�ѯ���ͼ�¼
public List<Blog> queryBlogForeach(Map map);
- ��д�ӿ������ļ�:
<!--��̬SQL֮foreachʵ�ֲ�ѯ���ͼ�¼
collection:��Ӧ������
open:��Ӧ��ʼ����
close:��Ӧ��������
seperator:��Ӧ�ָ���
index:��Ӧ���������
item:��Ӧ�����ľ���ֵ
-->
<select id="queryBlogForeach" parameterType="map" resultType="blog">
select * from blog
<where>
id in
<foreach collection="ids" open="(" close=")" separator="," item="id">
#{id}
</foreach>
</where>
</select>
��Ӧ�����sqlΪ:
select * from blog WHERE id in ( ? , ? , ? )
- ��д���Դ���:
//queryBlogForeach
@Test
public void queryBlogForeach(){
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
//����һ������,����������
ArrayList<String> ids = new ArrayList<String>();
ids.add("58ee7492a6974aafa6a7712226d57188");
ids.add("6a1900626bd149bc98e48f246e2e21fb");
ids.add("b56e45facb67420e84c275cf0f39e043");
//���ܵ�map
Map map = new HashMap();
map.put("ids",ids);//����ids,ֵ��Ӧ����ids
List<Blog> blogs = mapper.queryBlogForeach(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
}catch (Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
}
��
- ��̬SQL������ƴ��SQL���,����ֻҪ��֤SQL����ȷ��,����SQL�ĸ�ʽ,ȥ������ϼ��ɡ�
- ����mysql����̨д��������sql��֤sql����ȷ��,�ٶ�Ӧ��ȥƴ�Ӷ�̬SQL����
����(�˽�)
���
-
ʲô�ǻ���(Cache)?
- �����ڴ� �е���ʱ���ݡ�
- ����ָ�ľ��� ��ѯ������
- �����û�������ѯ�����ݷ��ڻ���(�ڴ�)��,�û�ȥ��ѯ���ݾͲ��ôӴ�����(��ϵ�����ݿ������ļ�)��ѯ,���Ǵӻ����в�ѯ,�Ӷ���߲�ѯЧ��,������߲���ϵͳ���������⡾��д����,���Ӹ��ơ�
-
Ϊʲôʹ�û���?
- ���ٺ����ݿ�Ľ�������,����ϵͳ����,���ϵͳЧ�ʡ�
- ��ѯ��ͬ���ݵ�ʱ��,ֱ������,���������ݿ��ˡ�
- ��߲�ѯЧ����
-
ʲô���������ʺϻ���? ʲô�������ݲ��ʺϻ���?
- ������ѯ���Ҳ������ı�����ݡ��ʺϻ��桿
- ��������ѯ���Ҿ����ı�����ݡ����ʺϻ��桿
Mybatis����
- Mybatis����һ���dz�ǿ��IJ�ѯ��������,�����Էdz�����ض��ƺ����û���
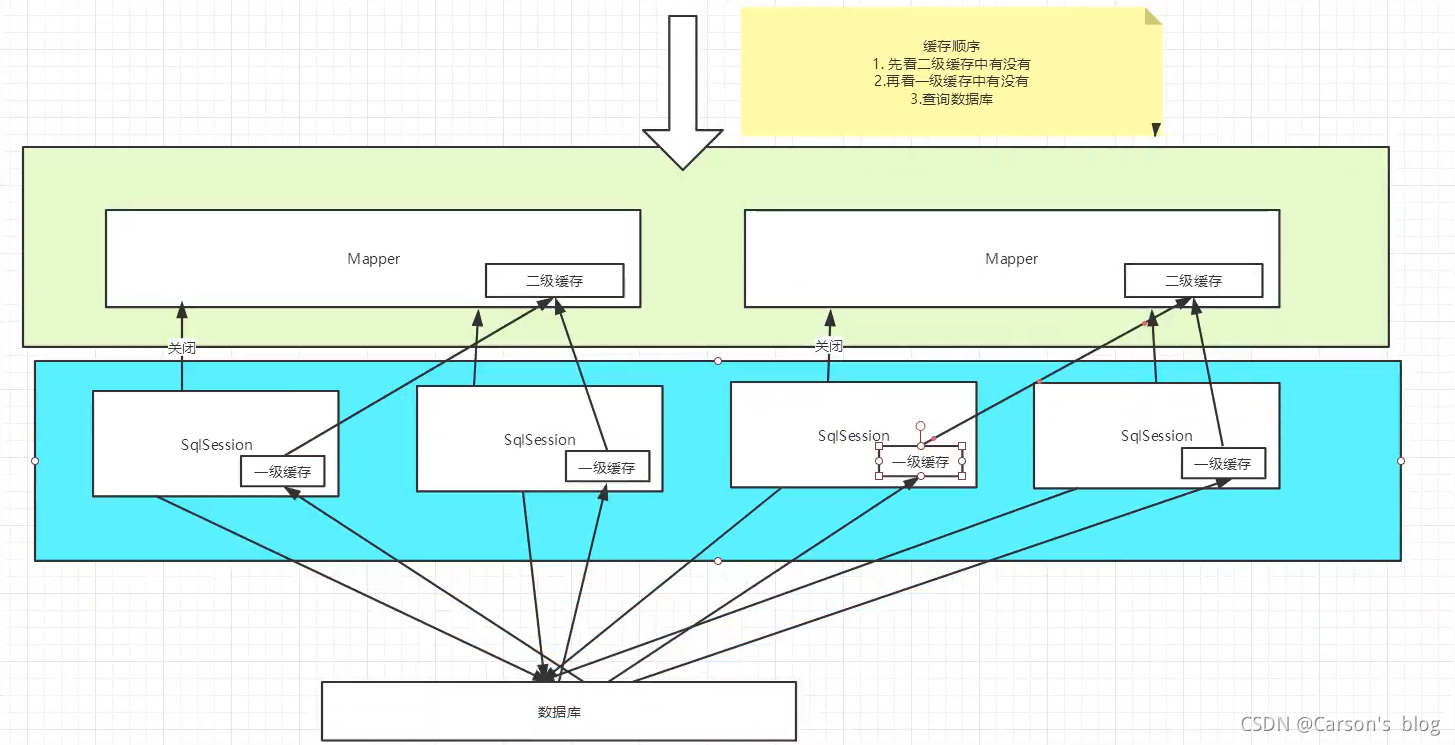
- ʹ�û�����Լ����������ѯЧ�ʡ�
- Mybatis��Ĭ�϶�������������: һ������������������
- Ĭ�������,ֻ��һ�����濪����(SqlSession����Ļ���,Ҳ��Ϊ���ػ���)
- ����������Ҫ�ֶ����������á�(����namespace����Ļ���)
- Ϊ�������չ��,Mybatis�����˻���ӿ�Cache,����ͨ��ʵ��Cache�ӿ����Զ���������档
һ������
-
һ������Ҳ�б��ػ��档
- Ĭ������� ������
- �����ݿ�ͬһ�λỰ�ڼ��ѯ�������ݻ���ڱ��ػ����С�
- �Ժ������Ҫ��ȡ��ͬ������,ֱ�Ӵӻ�������,û������ȥ��ѯ���ݿ⡣
- ӳ������ļ��е����� select ���Ľ�����ᱻ������
- ӳ������ļ��е����� insert��update �� delete ����ˢ�»�����
- �����ʹ���������ʹ���㷨(LRU, Least Recently Used)�㷨���������Ҫ�Ļ�����
- �������ᶨʱ����ˢ��(Ҳ����˵,û��ˢ�¼��)��
-
һ����ѯ�������:
- ������־��(����鿴�����Ϣ)
<!--����Ϊ����־���-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
- ������һ��sqlSession����ѯ������ͬ��¼��
SqlSession sqlSession = MybatisUtils.getSqlSession();
try{
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//��ѯͬһ���û���Ϣ
User user = mapper.queryUserByID(1);
System.out.println(user);
System.out.println("===============================");
//��ѯͬһ���û���Ϣ
User user1 = mapper.queryUserByID(1);
System.out.println(user1);
System.out.println(user==user1);
}catch(Exception e){
e.printStackTrace();
}finally {
sqlSession.close();
}
- �鿴��־��� (ִֻ����һ��sql���,�����ڶ��β�ѯ�������Ǵӻ����л�õ�)
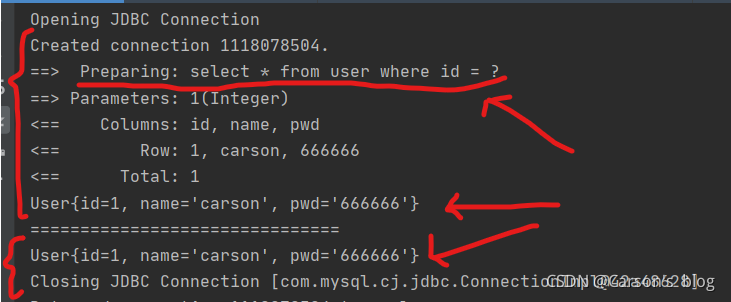
-
һ�� ˢ�»������(��ɾ�IJ�����ˢ�»���)
- ��������ѯ������ͬ��¼�м������²���:
SqlSession sqlSession = MybatisUtils.getSqlSession(); try{ UserMapper mapper = sqlSession.getMapper(UserMapper.class); //��ѯͬһ���û���Ϣ User user = mapper.queryUserByID(1); System.out.println(user); //���� �м����һ���û���Ϣ int affectedRows = mapper.updateUser(new User(3,"lin","08080808")); if(affectedRows > 0){ System.out.println("User Update Successfully!"); } System.out.println("==============================="); //��ѯͬһ���û���Ϣ User user1 = mapper.queryUserByID(1); System.out.println(user1); System.out.println(user==user1); }catch(Exception e){ e.printStackTrace(); }finally { sqlSession.close(); }- �鿴��־��� (���ڼ�����update���,����»���,�����β�ѯͬ����¼��������ݿ��в�����)
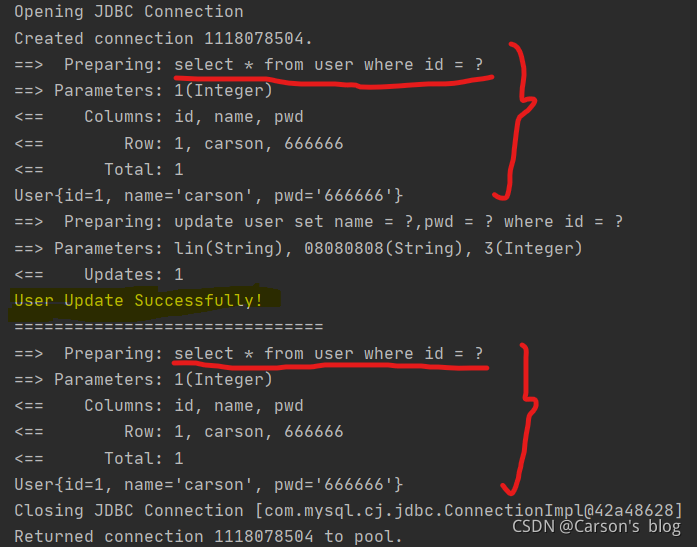
һ������ʧЧ�����:
- ��ѯ��ͬ�ļ�¼��
- ��ɾ�IJ���,���ܻ�ı�ԭ��������,���Աض���ˢ�»���!
- ��ѯ��ͬ��Mapper.xml�ļ���
- �ֶ��������档
//�ֶ���������
sqlSession.clearCache();
��:
- һ��������Ĭ�Ͽ�����,ֻ��һ��sqlSession����Ч,Ҳ�����õ����ӵ��ر�����������䡣
- һ�����汾�ʾ��Ǹ�Map��
��������
- ��������Ҳ��ȫ�ֻ���,һ�������������̫��,���Ե����˶������档
- ���������ǻ���namespace�����Ļ���,��һ�����ƿռ�,��Ӧһ���������档
- ��������:
- һ���Ự��ѯһ������,������ݾͻᱻ���ڵ�ǰ�Ự��һ��������;
- �����ǰ�Ự�ر���,����Ự��Ӧ��һ�������û��;��������Ҫ����,�Ự�ر���,һ�������е����ݱ����浽����������;
- �µĻỰ��ѯ��Ϣ,�Ϳ��ԴӶ��������л�ȡ���ݡ�
- ��ͬ��mapper�ӿڲ�������ݻ�����Լ���Ӧ�Ļ���(map)�С�
����:
- ��ʽ����ȫ�ֻ���:
<!--��ʽ�ؿ���ȫ�ֻ���(Ĭ��ȫ�ֻ����ǿ�����)-->
<setting name="cacheEnabled" value="true"/>
- Ҫ����ȫ�ֵĶ�������,ֻ��Ҫ��Mapper�����ļ�������һ��:
<cache/>
Ҳ�����Զ������:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
- ���ԡ�
//��������sqlSession
SqlSession sqlSession = MybatisUtils.getSqlSession();
SqlSession sqlSession2 = MybatisUtils.getSqlSession();
//��Ӧ��������mapper
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
//sqlsessionִ�з���
User user = mapper.queryUserByID(1);
System.out.println(user);
sqlSession.close();
//sqlSession2ִ�з���
User user2 = mapper2.queryUserByID(1);
System.out.println(user2);
//�����Ƿ���ͬ
System.out.println(user==user2);
ע: ������ʱ��������:
Caused by: java.io.NotSerializableException: com.carson.pojo.User
��������취:
- ��Ҫ��ʵ����������л�:(�漰io��������紫��.��ʵ������Ҫʵ��Serializable�ӿ�):
public class User implements Serializable {...}
- ��������������readonly����Ϊtrue:
<!--����ȫ�ֶ�������-->
<cache readOnly="true"/>
��:
- ֻҪ�����˶�������,��ͬһ��Mapper�¾���Ч��
- ���еĻ������ݶ����ȷ���һ��������;
- ֻ�е��Ự�ر������ύ��ʱ��,�ŻὫ ���������ύ������������!
����ԭ��
�Զ��建��-ehcache
EhCache һ�ֹ㷺ʹ�õĿ�ԴJava�ֲ�ʽ����,���١����ɵ��ص�,��Ҫ����ͨ�û���
֪������, �����Թ��������еĻ���ʹ�õ���redis,��k-v�ͷǹ�ϵ�����ݿ���
��������!��ӭ����/����!!!
