�ֵ���,������!
��CSDN��ä������һ��iPhone 13 �ɻ���,�������о���Ӧ��ȥ�����Ʊ,�������!
��ϸ��ͼ������ƪ������,�����Ķ�

�Ȳ��Nɪ��,���ǽ�������һ�±��صķ�Դ��Ϣ,��֪��������֮���ܲ��������~
һ��������
�����е㳤,�����ϰ�߿����µĻ�,Ҳ��ר�ŵ���Ƶ����,�ҳ���ϸ!
Python:��ȡ���ط�Դ��Ϣ,�����۸�����,�����Լ�����!
��Ҫ��֪ʶ��
1. ϵͳ������ҳ����
2. �ṹ�������ݽ���
3. csv���ݱ���
ʹ�õĻ���
Python3.8
pycharmרҵ��
ʹ�õ�ģ��
requests
parsel
csv
���ᰲװģ����ֵܿ��Կ��ҷ�����ƪ:��ΰ�װpythonģ��, pythonģ�鰲װʧ�ܵ�ԭ���Լ�����취
����˼·����
һ��������Դ����
����: ������ҳ������������ݽ��вɼ�����
- ȷ����ȡ��������ʲô����?
���ַ�Դ�Ļ������� - ͨ�������߹��߽���ץ������, ������Щ���������ǿ��������ȡ��
ͨ�������߹���, �����ɵ� >>> ������Ҫ�ķ�Դ��������(��Դ����ҳurl) ������������ҳԴ���롣
�����Ҫ��ȡ�����Դ����, ֻ��Ҫ���б�ҳ�� ��ȡ���еķ�Դ����ҳurl��
��������ʵ�ֲ���
�������� >>> ��ȡ���� >>> �������� >>> ��������
- ��������, �Ƕ��ڷ�Դ�б�ҳ��������
- ��ȡ����
- ��������, ��ȡ������Ҫ������, ��Դ����ҳurl��
- ��������, ���ڷ�Դ����ҳurl��ַ��������
- ��ȡ����
- ��������, ��ȡ��Դ������Ϣ���ۼۡ����⡢���ۡ���������͡�
- ��������
- ��ҳ���ݲɼ�
���˼·����Щ,����һ������ʵ�ְɡ�
����������Դ����
����Ҫȷ������������ʲô,���ǽ������������ҵ�һ�����ַ���Դ��Ϣ������˵�۸�С��¥�㡢���͵ȵ�һЩ������Ϣ,��Щ�������Ҫ����ȥ�ɼ��ġ�
��Ȼ����֪������Ҫ��Щ����,��ô���Ǿ�Ҫͨ�������߹���ȥץ������,������Щ���ݿ��Դ������ȡ��
�����߹��ߵĻ�����F12���߰�ס����Ҽ������鶼���Դ�
 Ȼ����ѡ��network
Ȼ����ѡ��network
 �տ�ʼ��ʱ����û���κ����ݵ�,��������Ҫˢ��һ�µ�ǰҳ��,�ͻ�����ܶ����ݡ�
�տ�ʼ��ʱ����û���κ����ݵ�,��������Ҫˢ��һ�µ�ǰҳ��,�ͻ�����ܶ����ݡ�
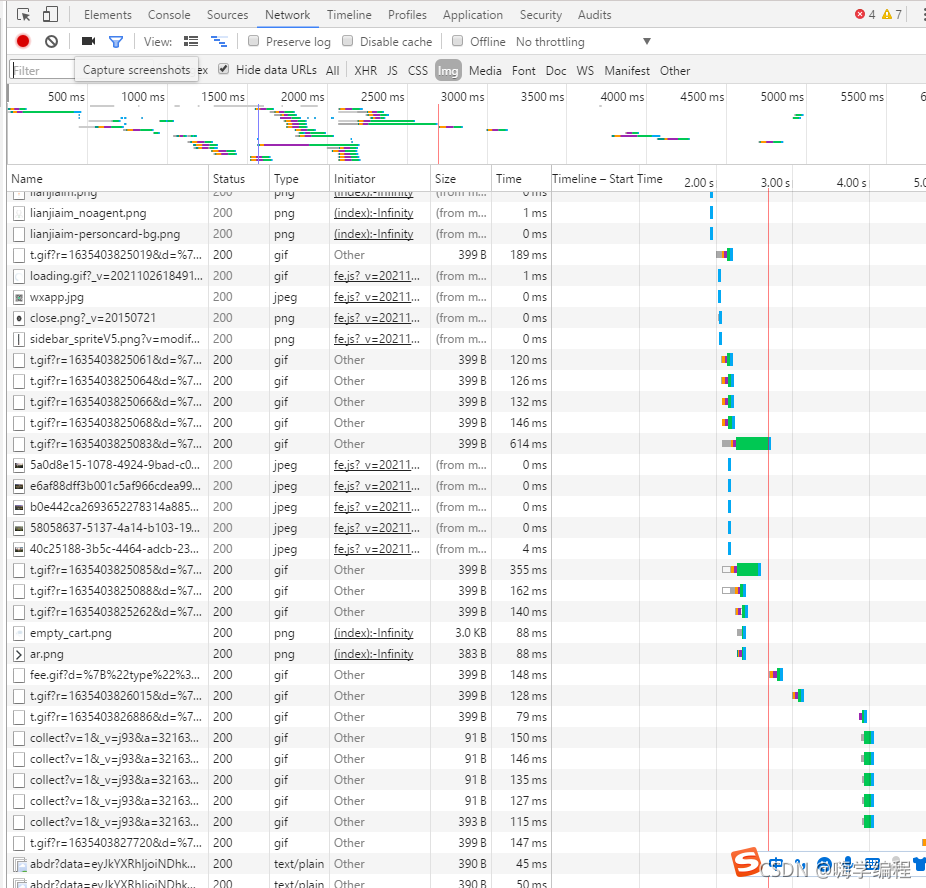 ������Щ���ݲ���������Ҫ��,��ô��ô�ҵ��Լ���Ҫ��������?
������Щ���ݲ���������Ҫ��,��ô��ô�ҵ��Լ���Ҫ��������?
����˵����Ҫ������ӵı��⡣
������ô���������������Ҫȥ��������?
�Թȸ������Ϊ��,��ʱ�����ǾͿ����õ������߹��ߵ�һ���������ܡ�
����������ܾͿ��Զ�������Ҫ�����ݽ�������,Ȼ�����ͻ�����Ƿ������Ӧ����������(���ݰ�)��
�����Է�������Ϊ��
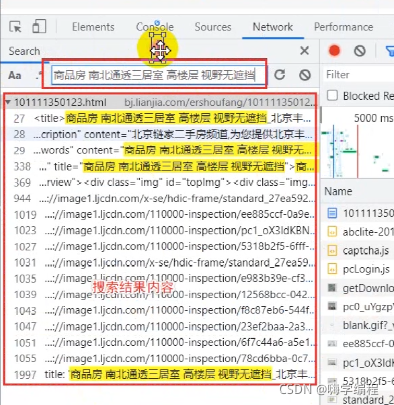 �����һ��,���ͻ����ұ߸����ǵ���һ��response���������,response�Ƿ��������ظ����ǵ�һ����Ӧ���ݡ�
�����һ��,���ͻ����ұ߸����ǵ���һ��response���������,response�Ƿ��������ظ����ǵ�һ����Ӧ���ݡ�
����title��ǩ�������������Ҫ������,��Դ�����֡�
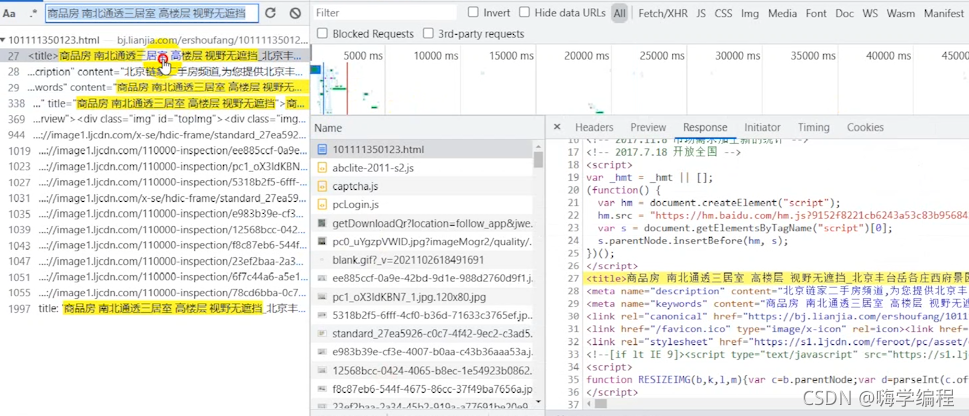 �����������ǵ��preview,�����Ԥ������˼,���������ݶ�����Ԥ���п�����
�����������ǵ��preview,�����Ԥ������˼,���������ݶ�����Ԥ���п�����
ȷ�������ݶ��еĻ�,���Ǿ͵��headers ,���Request URL �������ǵ�����Ҫ���͵�����url�����url��ַ�Ļ�,�����ǵ���ҳ��ַ��һ���ġ�
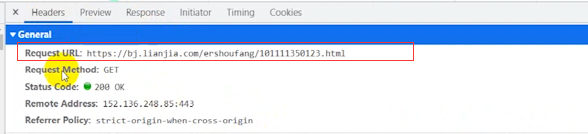
���get�����ǵ�����ʽ,���������ط���ʾ����һ��post��ʽ,���Ǿ���post��
��˵����ʲô��ʽ,���Ǿ���ʲô��ʽ,��������������ʲô��ʽ����ʲô��ʽ��

get��post������
getһ���ǻ�ȡ����,postһ���Ǵ������ݡ�
get����һ�������ֻ�Ǵӷ�������ȡ����,������Է�������Դ�����κ�Ӱ�졣
post�������������������������,����˵��¼���ϴ�������,���ֶԷ�������Դ����Ӱ���ʱ��ʹ�á�
���������ַ��ʾ��,�ʺź�������ݶ�������get����IJ�����post����Ļ�һ�㶼�����ص�,����Ҫͨ�������߹��߲��ܿ���������
��������ʵ�ֲ���
1����������
���ǻص�����
��������Ļ����ȵ�������Ҫ��ģ��
import requests
�������ǵ���������ģ��,Ҳ��һ��������ģ��,���Ӧ�ö���װ�˰�,���־�˵�˵ġ�
Ȼ�����Ƿ��������url��ַȷ�����ֱ�Ӹ��ƹ���
url = 'https://bj.lianjia.com/ershoufang/'
Ȼ������Ҫ����һ������ͷ,�����ǵ�Python�������αװ,αװ��������Է�������������,����ģ���������
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36'
}
headers�����Ļ�����������,��Ȼ����̫����,����û��Ҫ���ӽ�ȥ,����ֻҪUser-Agent��������ݾͺ��ˡ�
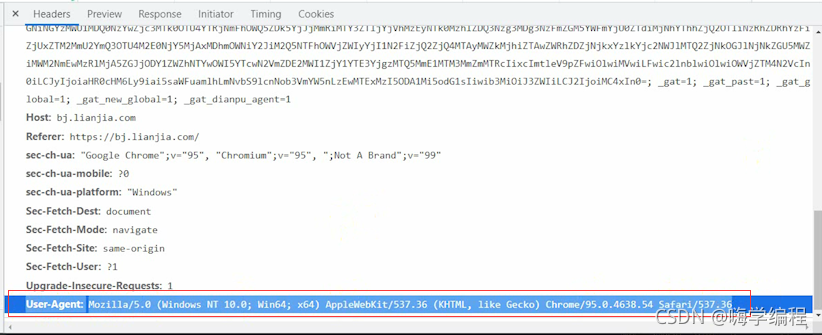
 User-Agent��Ҫ��ʾ����������Ļ�����Ϣ,���ݱ�ʶ��
User-Agent��Ҫ��ʾ����������Ļ�����Ϣ,���ݱ�ʶ��
 Ȼ�����Ƿ���������requestsģ�������get����ʽ��url��ַ��headers����ͷ������ȥ��
Ȼ�����Ƿ���������requestsģ�������get����ʽ��url��ַ��headers����ͷ������ȥ��
Ȼ��������response��������һ��
response = requests.get(url=url, headers=headers)
print(response)
Ȼ��ֱ������
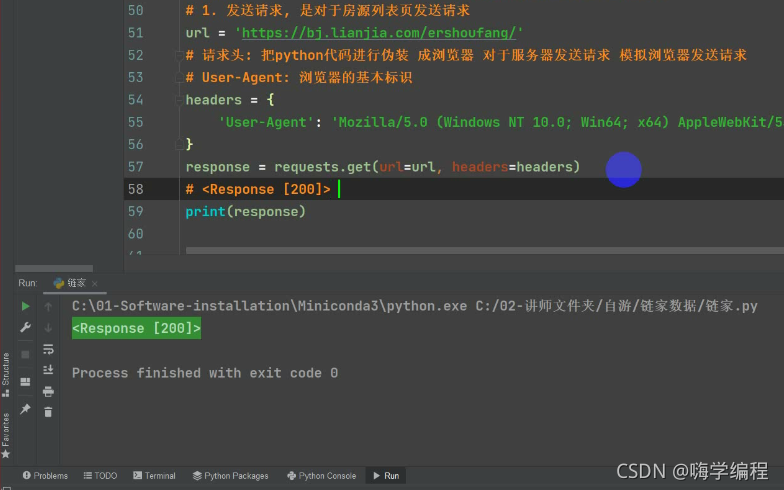 ���ﷵ�ص���response [200]>
���ﷵ�ص���response [200]>
������Ӧ���һ������
200 ��һ��״̬��,��ʾ����ɹ�,˵�����Ƕ���վ�ķ�������û�������ˡ�
��ôΪʲô���صIJ�������,����response [200]>��?
2����ȡ����
��ʱ�����Ǿ�Ҫ��ȡ�ı�������,��ӡ��ʱ����response�������text,��ȡ��Ӧ����ı����ݡ����������Dz��ܻ�ȡ������ҳԴ����һ���������ˡ�
print(response.text)
 �ܶ��˾��ñ����,����ʵ����,��������ʵ����,�����д���,���һ����϶��Ǹ���ճ���ġ����Լ��鲻�ͼ�ס��,�ɡ�
�ܶ��˾��ñ����,����ʵ����,��������ʵ����,�����д���,���һ����϶��Ǹ���ճ���ġ����Լ��鲻�ͼ�ס��,�ɡ�
3����������
��ȡ������Ҫ������, ��Դ����ҳurl��
���ȵ������ǵ����ݽ���ģ��
import parsel
���ǻ�ȡ����response.text ,����һ��html�ַ����������ݡ��������Ҫ�����ַ�����������ֱ�ӽ�����ȡ�Ļ�,ֻ����re�������ʽ��
�������ǽ������õ�parselģ��,��������Ҫ�����ǻ�ȡ����HTML�ַ������ݽ���ת��,ת��Selector����,Ȼ��response.text��������ȥ��
Ȼ����Selector��������һ��,��ӡ�����Ǹ�ɶ
print(Selector)
�����ﷵ�صľ���һ��Selector����
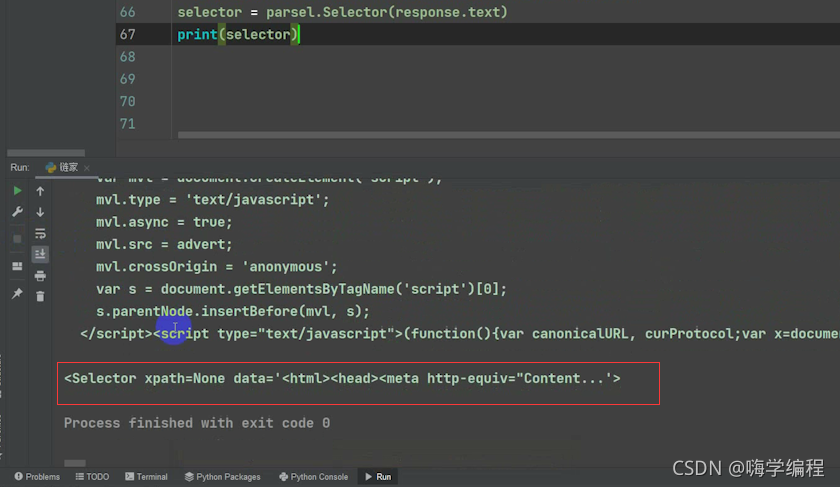 ����������������ǾͿ��Ե��������Ӧ��һЩ����, ���ǽ�����õ���һ��css��ѡ������
����������������ǾͿ��Ե��������Ӧ��һЩ����, ���ǽ�����õ���һ��css��ѡ������
cssѡ������һ����������,���ݱ�ǩ����������ȡ��ص����ݡ�
selector.css('')
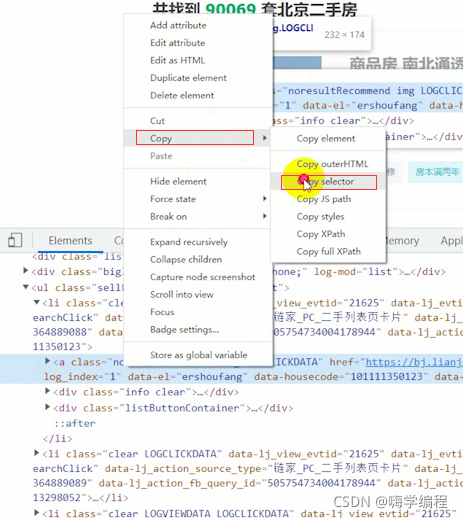
���ȵ�������߹����ϵ��Ǹ���ͷ,���������Ҫ�Ķ�����
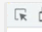
������Ҫ�������url��ַ
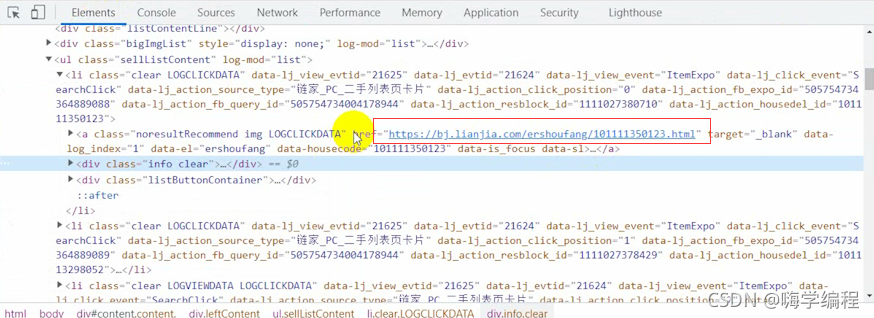 ������Dz���css�,��ֱ��ѡ������
������Dz���css�,��ֱ��ѡ������
 ������ֱ�Ӷ�λ������
������ֱ�Ӷ�λ������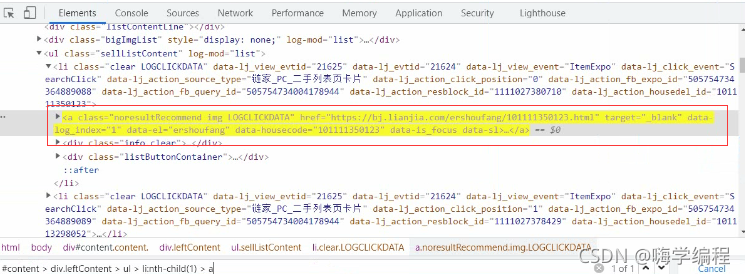 ����������ʾ����ֻ�����ǻ�ȡһ��,������Ҫ��ȡ���е���ô����?
����������ʾ����ֻ�����ǻ�ȡһ��,������Ҫ��ȡ���е���ô����?
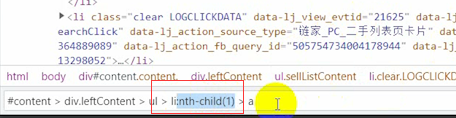
������ط���ʾ����һ��1,��˼����ֻȡ����һ��li��ǩ,����ֱ�Ӱ���ɾ�˾ͺ���,�����Ӿ�ȡ��31���ˡ�

31��Ҳ����,һҳ�ܹ���30ҳ����,��ô�����������ط���
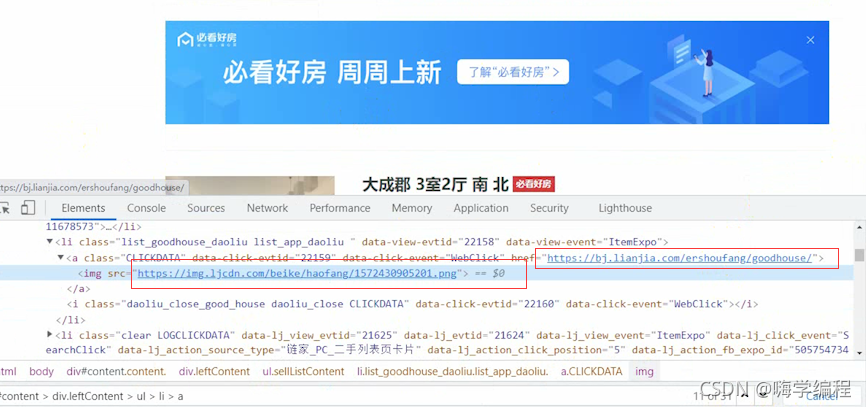 ����������һ�ֹ��,����!
����������һ�ֹ��,����!
�������������������Ҫ��,��Ҳ������ȡ����,��ôȥ����?
������Ҫ�����ݶ�����li��ǩ����,����Ψһ��ͬ�Ļ�����clear��������ط���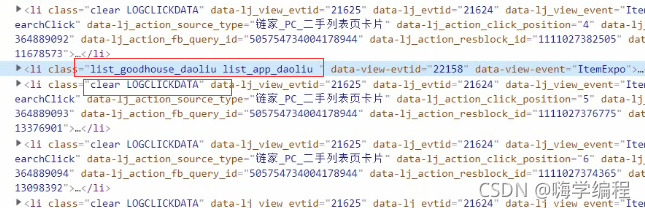 ����ֱ�Ӱ�����һ��,���ݱ�ǩ����ȥȡ,�Ѳ�Ҫ�Ĺ��˵���
����ֱ�Ӱ�����һ��,���ݱ�ǩ����ȥȡ,�Ѳ�Ҫ�Ĺ��˵���
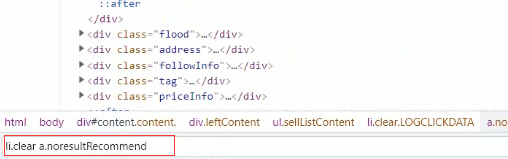
Ȼ����ȡhref����,��ӡһ�¿���
href = selector.css('li.clear a.noresultRecommend::attr(href)').getall()
print(href)
 ��ӡ֮��,�����ǻ�ȡ�������еķ�Դ����ҳurl��ַ��
��ӡ֮��,�����ǻ�ȡ�������еķ�Դ����ҳurl��ַ��
��ô���������Ǿ�Ҫ��������һ��,��������������ݶ�����һһ��ȡ������
Ȼ������һ��
href = selector.css('li.clear a.noresultRecommend::attr(href)').getall()
for index in href:
print(href)
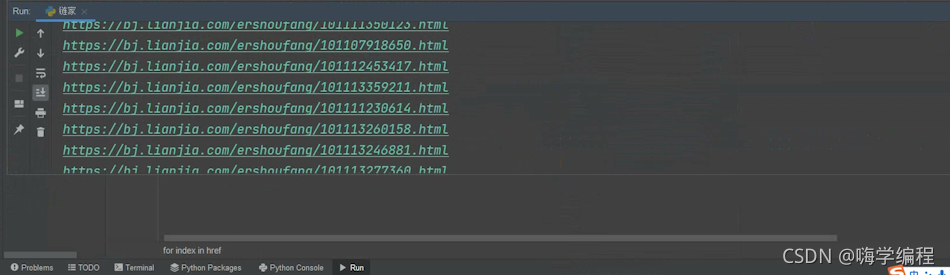 �����Ļ�,���ǾͰ������е�һ��url��ַ����ȡ�����ˡ�
�����Ļ�,���ǾͰ������е�һ��url��ַ����ȡ�����ˡ�
4����������
Ȼ���Ҫ�����ǵ�����ҳ��������
��Щ�Ļ���ǰ��ķ�������һ����,�Ͳ���ϸȥ˵�ˡ�
response_1 = requests.get(url=index, headers=headers)
5����ȡ����
6�� ��������
�������Ļ���ȡ����һ������
selector_1 = parsel.Selector(response_1.text)
���Ǹ��ո�һ����,ȥ�ҵ�������ϸ��Ϣ
ȡ����
```powershell
title = selector_1.css('div.title .main::text').get()
ȡ�۸�
price = selector_1.css('.price .total::text').get() + '��Ԫ'
��ӡһ�¿���
print(title,price)
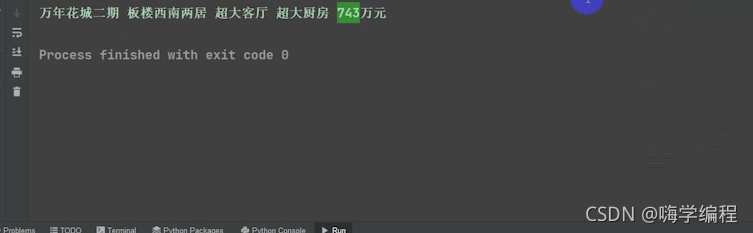 Ȼ�������ı�ǩҲ�Dz���,�Ҿ�ֱ�Ӹ�����,��һһ˵�ˡ�
Ȼ�������ı�ǩҲ�Dz���,�Ҿ�ֱ�Ӹ�����,��һһ˵�ˡ�
area = selector_1.css('.areaName .info a:nth-child(1)::text').get() # ����
community_name = selector_1.css('.communityName .info::text').get() # ��
room = selector_1.css('.room .mainInfo::text').get() # ����
room_type = selector_1.css('.type .mainInfo::text').get() # ����
height = selector_1.css('.room .subInfo::text').get() # ¥��
height = re.findall('��(\d+)��', height)[0]
sub_info = selector_1.css('.type .subInfo::text').get().split('/')[-1] # װ��
Elevator = selector_1.css('.content li:nth-child(12)::text').get() + '����' # ����
if Elevator == '�������ݵ���':
Elevator = '����'
house_area = selector_1.css('.content li:nth-child(3)::text').get().replace('�O', '') # ���
price = selector_1.css('.price .total::text').get() # �۸�(��Ԫ)
date = selector_1.css('.area .subInfo::text').get().replace('�꽨', '') # ���
dit = {
'����': area,
'��': community_name,
'����': room,
'����': room_type,
'¥��': height,
'װ�����': sub_info,
'����': Elevator,
'���(�O)': house_area,
'�۸�(��Ԫ)': price,
'���': date,
'����ҳ': index,
}
print(area, community_name, room, room_type, height, sub_info, Elevator, house_area, price, date, index, sep='|')
����
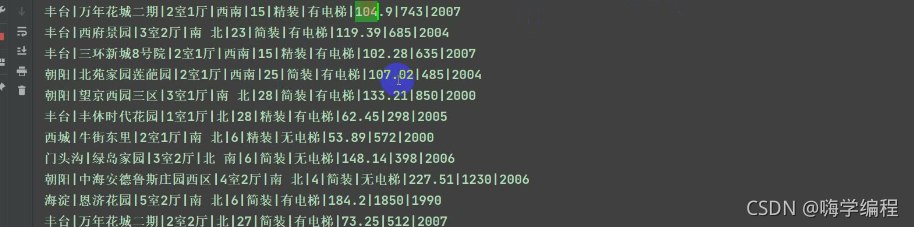 ���߰˰˵��������Ƕ���ȡ������,
���߰˰˵��������Ƕ���ȡ������,
7����������
�������ǵ���CSV���ݱ���ģ��
import csv
Ȼ��opn����һ���ļ�,���������ƺá�
ȡ���������ַ�����.csv,mode���淽ʽ a ,�ӱ��档
encoding����utf-8,newline����һ�С�
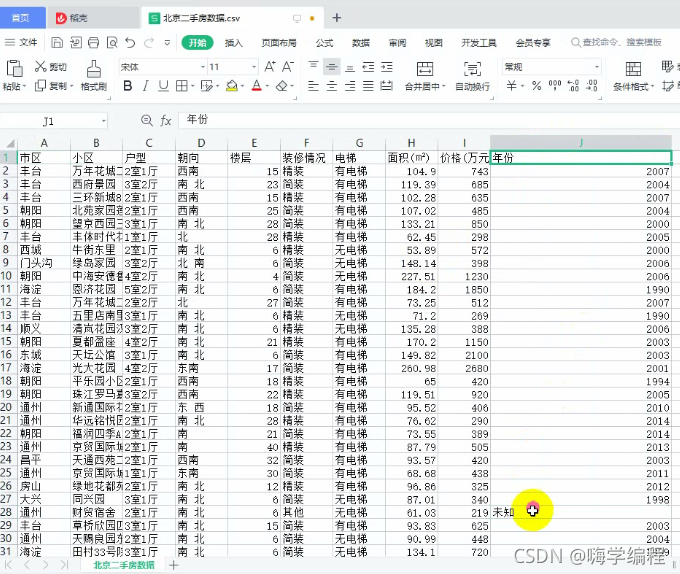
f = open('�������ַ�����.csv', mode='a', encoding='utf-8', newline='')
Ȼ����CSVģ�������DictWriter������f, fieldnames����ȥ��fieldnames��д���ֵ���������ݡ�
����Щ��ǩ���ֺ���Ķ������滻�ɶ���,��csv_writer��������һ��,�����д���ͷ��
csv_writer = csv.DictWriter(f, fieldnames=[
'����',
'��',
'����',
'����',
'¥��',
'װ�����',
'����',
'���(�O)',
'�۸�(��Ԫ)',
'���',
'����ҳ'
])
csv_writer.writeheader() # д���ͷ
����
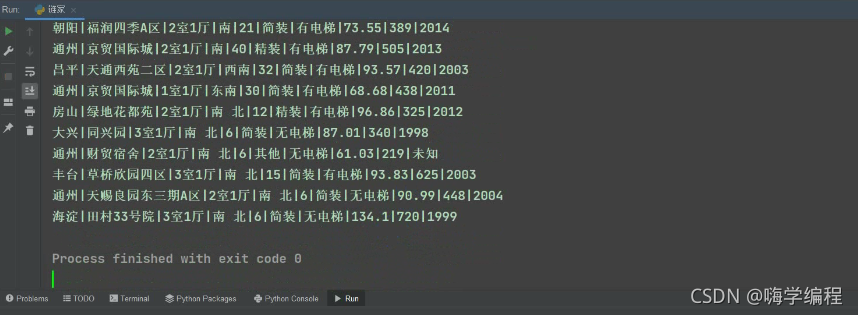 ���ʱ��͵�ǰҳ�����ݶ�������,��ǰֻ����ѡ��һЩ,���������߰˰˵Ĵ��Ҳ�����Լ���һ�¡�
���ʱ��͵�ǰҳ�����ݶ�������,��ǰֻ����ѡ��һЩ,���������߰˰˵Ĵ��Ҳ�����Լ���һ�¡�
8����ҳ���ݲɼ�
��ҳ��ʵ�ܼ�,���Ƿ����ڶ�ҳ,�����Ǹ�pg2,��������ҳ����pg3��

�Ǿ�ֻҪ������ͺ���,���Ǽ�һ��forѭ��,��������ҳ�Ķ���,������������11ҳ��
for page in range(1, 11):
Ȼ������page����ȥ,��Ȼ��Զ������һҳ��
url = f'https://bj.lianjia.com/ershoufang/pg{page}/'
Ȼ���ټ�һ��,������ȡ����ҳ��
print(f'������ȡ��{page}ҳ����������')
����
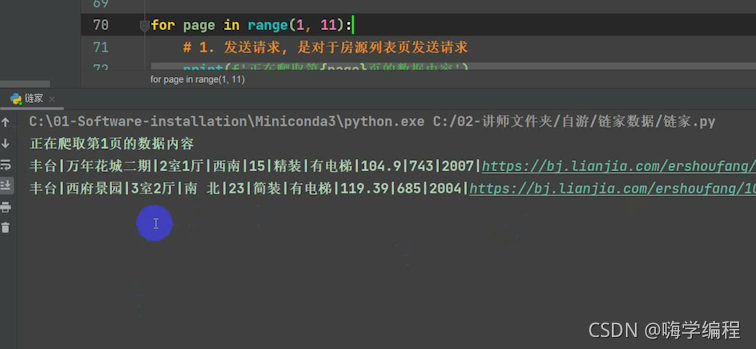 ������Ļ��ͽ�����,��ҿ���ȥ���ԡ�
������Ļ��ͽ�����,��ҿ���ȥ���ԡ�
��ε��е㳤,��֪���ж��ټ�ֿ����,�ֵ���ѧ������?
�ǵõ�������������!
