1、遍历文件夹的pdf文件
代码练习1:获取文件夹的所有文件名
import os#引用os库
file_dir=r'文件夹路径'#遍历的文件夹路径
for files in os.walk(file_dir):#用OS库的walk()函数遍历指定文件夹下的所有文件信息
print(files[2])#打印母文件和子文件里的各个文件信息(files[1]:子文件夹信息,files[0]:母文件夹信息)运行结果:

?代码练习2:进阶――仅获取pdf类型文件,并加入路径格式,方便下一步调取
import os#引用os库
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'文件夹路径'#指定即将遍历的文件夹路径
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
file_list.append(file_dir+'\\'+file)#给文件名加入文件夹路径
print(file_list)运行结果:
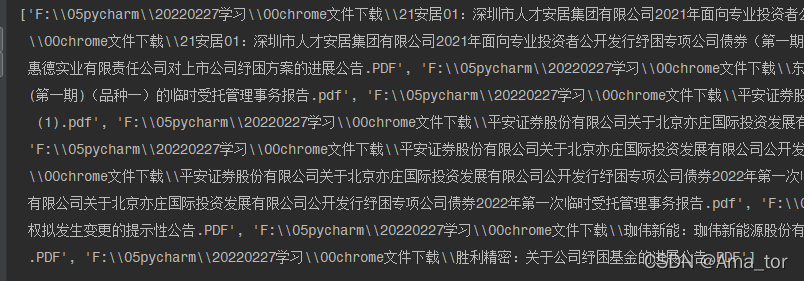
?2、批量解析每一个pdf文件
代码练习:
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'F:\05pycharm\20220227学习\00chrome文件下载'#遍历的文件夹路劲
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
file_list.append(file_dir+'\\'+file)#给文件名加入文件夹路径
#批量解析每一个pdf文件
for i in range(len(file_list)):#遍历所提取的文件地址
pdf=pdfplumber.open(file_list[i])#循环执行打开pdf文件命令
pages=pdf.pages#pages属性获取页数
text_all=[]#新建一个列表,存放PDF文件文本解析
print('-----------------------')#用来间隔每个文件之间的内容,好看
for page in pages:#遍历pages里面每一页的信息
text=page.extract_text()#提取当前页内容,赋值给text
text_all.append(text)#获取的内容存入列表text_all
print(text_all)
pdf.close()
运行结果:
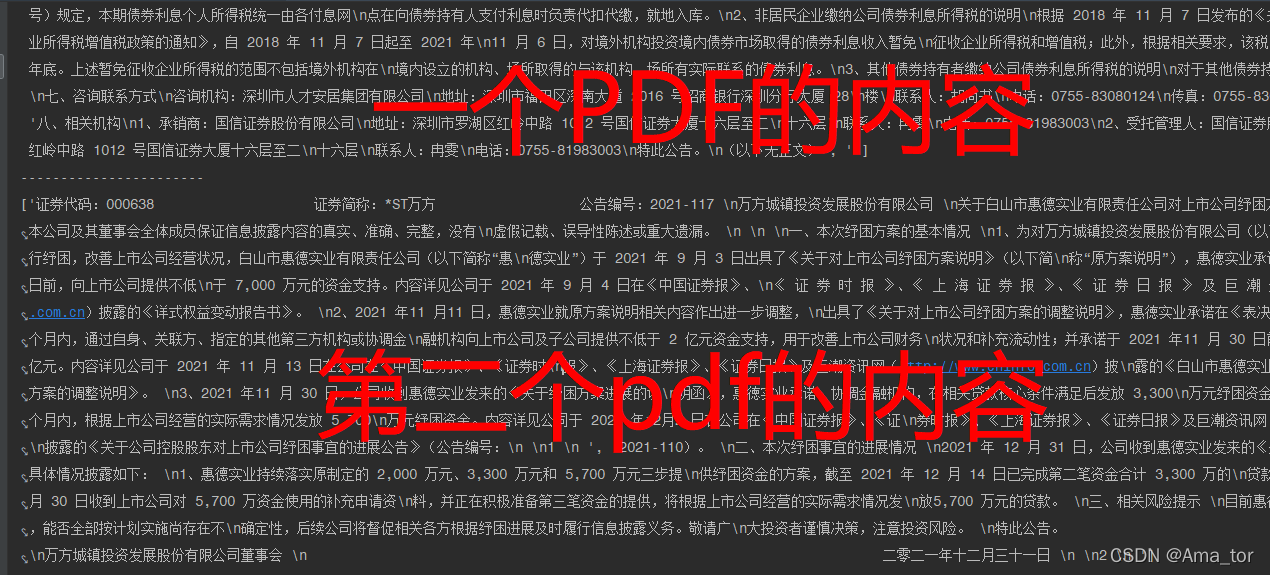
? 3、筛选pdf归档
代码练习:
import os#引用os库
import pdfplumber#引进pdfplumber库
#遍历文件夹的所有PDF文件
file_list=[]#新建一个空列表用于存放文件名
file_dir=r'pdf文件所在的文件夹'#遍历的文件夹路径
for files in os.walk(file_dir):#遍历指定文件夹及其下的所有子文件夹
for file in files[2]:#遍历每个文件夹里的所有文件,(files[2]:母文件夹和子文件夹下的所有文件信息,files[1]:子文件夹信息,files[0]:母文件夹信息)
if os.path.splitext(file)[1]=='.PDF' or os.path.splitext(file)[1]=='.pdf':#检查文件后缀名,逻辑判断用==
# file_list.append(file)#筛选后的文件名为字符串,将得到的文件名放进去列表,方便以后调用
file_list.append(file_dir+'\\'+file)#给文件名加入文件夹路径
#print(file_list)#打印获取的文件路径
pdf_all=[]#新建一个空列表存放筛选后的PDF文件
#批量解析每一个pdf文件
for i in range(len(file_list)):#遍历所提取的文件地址
pdf=pdfplumber.open(file_list[i])#循环执行打开pdf文件命令
pages=pdf.pages#pages属性获取页数
text_all=[]#新建一个列表,存放PDF文件文本解析
for page in pages:#遍历pages里面每一页的信息
text=page.extract_text()#提取当前页内容,赋值给text
text_all.append(text)#获取的内容存入列表text_all
text_all=''.join(text_all)#text_all列表内容转字符串
pdf.close()
#筛选所需文件,并把符合的元素添加到之前新建的pdf_all列表中
if('实业'in text_all)or('失信行为'in text_all):# 通过正文进行筛选
pdf_all.append(file_list[i])
print(pdf_all)#可在终端看到筛选的文件名
#将pdf_all列表中的PDF文件归档到指定文件夹
for pdf_i in pdf_all:
newpath='F:\\筛选后的文件夹\\'+pdf_i.split('\\')[-1]#定义指定文件夹路径+获取文件名
os.rename(pdf_i,newpath)#os.rename(旧路径,新路径)实现文件移动
结果运行:终端可以看到筛选后的文件名,并已实现文件移动
