grep awk sed��Linux���ı��������õ�����,��ƪ�ʼǾ�����ϸ�����ı������͵��÷���
���ܸ���:
����
grep:�ı�������,�����ǹ����ı�,û�б༭����
sed:Stream EDitor,���༭��,�������ض������б༭����(sed�Dz�����ԭ���ݵ�,�༭�����Ĭ���Ǵ�ӡ����Ļ,����sed������ԭ�ļ������Dz����)
awk:����������,���Ը����ض��ַ��ָ���(��ո�ð�š��ٺŵ�),Ȼ�������趨�ĸ�ʽ��ʾ��(����Դ�����������Ҫ���ɱ���֮�����Ϣ,�����㴦���������ǰ��н��д�����,���ʹ�� awk)
�ʺϳ���:
grep ���ʺϵ����IJ��һ�ƥ���ı�
sed ���ʺϱ༭ƥ�䵽���ı�(�����ó��滻)
awk ���ʺϸ�ʽ���ı�,���ı����нϸ��Ӹ�ʽ����(�ó�ȡ��)
������ϸ�̳�:
һ��grep
grep (global search regular expression(RE) and print out the line,ȫ�������������ʽ����ƥ�䵽���д�ӡ����)
��һ��ǿ����ı���������,����ʹ���������ʽ�����ı�,����ƥ����д�ӡ���������ڹ���/�������ض��ַ���
��ʽ:
grep [options] [regex] [file]
- options�Ǵ�-��ѡ��
- regex���������ʽ
- file����Ҫgrep���ļ���
optionsѡ��:
-i : ���Դ�Сд���������ִ�Сд�ַ���Ҳ���èCignore-case ��ָ����
-v : ��ƥ�䡣ͨ��,grep ������ӡ����ƥ������ı��С����ѡ��� grep ����ֻ���ӡ������ƥ������ı��С�Ҳ���èCinvert-match ��ָ����
-c : ��ӡƥ�������(�����Dz�ƥ�����Ŀ,��ָ����-v ѡ��),�������ı��б����� Ҳ���èCcount ѡ����ָ����
-l : ��ӡ����ƥ������ļ���,�������ı��б���,Ҳ���èCfiles-with-matches ѡ����ָ����
-L : ������-l ѡ��,����ֻ�Ǵ�ӡ������ƥ������ļ�����Ҳ���èCfiles-without-match ��ָ����
-n : ��ÿ��ƥ����֮ǰ��ӡ����λ���ļ��е���Ӧ�кš�Ҳ���èCline-number ѡ����ָ����
-h : Ӧ���ڶ��ļ�����,������ļ�����Ҳ���èCno-filename ѡ����ָ����
Tips:
1��regexΪ�������ʽ,���������չ�������ʽ������egrep ����grep -E
2��grep���Խ��չܵ������������ı�,���������[file]����Ҫд��
eg: cat test.txt | grep "#tzq"
����sed
sed ��һ�����༭��,�����ı������зdz���Ҫ�Ĺ���,�ܹ�����������������ʽʹ��,���ܲ�ͬ���졣����ʱ,�ѵ�ǰ�������д洢����ʱ��������,��Ϊ��ģʽ�ռ䡱(pattern space),������sed������������е�����,������ɺ�,�ѻ�����������������Ļ�����Ŵ�����һ��,���������ظ�,ֱ���ļ�ĩβ���ļ����ݲ�û�� �ı�,������ʹ���ض���洢�����
��ʽ:
sed [options] [commands] [file(s)]
optionsѡ��:
| ѡ�� | ���� |
|---|---|
| -n | �������Դ�ļ�����,��ֻ�о���sedƥ�����һ�вŻᱻ��ӡ���� |
| -i | ��Դ�ļ�,sedĬ���Dz�����ԭ�ļ���,����-iѡ���ֱ����Դ�ļ� |
| -e | ��ѡ��������ͬһ����ִ�ж������ |
#-e������:
#��������ʾ,��һ������ɾ�� 1 �� 5 ��,�ڶ���������check�滻test�������ִ��˳��Խ����Ӱ�졣�������������滻����,��ô��һ���滻���Ӱ��ڶ����滻����Ľ����
sed -e '1,5d' -e 's/test/check/'
commandsѡ��(�ص�):
����������µ�����:
| ��� | ���� | ���� |
|---|---|---|
| 1 | p | ��ӡ |
| 2 | s | �滻ƥ�䵽�Ĺؼ��� |
| 3 | c | �滻�� |
| 4 | i | ����ǰ����һ������ |
| 5 | a | ���к����һ������ |
| 6 | d | ɾ���� |
1����ӡ����:p
-
��ӡ��1�е����һ��:
sed -n "1,$"p test.txt����Ϊ��˫���Ŷ���,�����p���������������
-
��ӡƥ�䵽�ؼ��֡������桿����
sed -n "/������/p" test.txt�����p��������������涼����
-
�ӵ�1�д�ӡ, ֱ��ƥ�京�йؼ��֡������桿����(������)
sed -n "1,/������/"p test.txt�����p��������������涼����
-
��ӡ��ʼƥ�䵽�ؼ��֡������桿����, ��ƥ�䵽�ؼ��֡�������������:
sed -n "/������/,/������/"p taoge.txt
2���滻����:s
-
�����滻
echo "i love you, you love me" | sed "s/love/like/"Ĭ��ֻ�滻��һ��love
ʹ��s����,����-n,�滻����һ��Ҳ�����ظ����
-
ȫ���滻
echo "i love you, you love me" | sed "s/love/like/g"����g��ʾ�滻���ֵ����йؼ���
-
���ijһ�н����滻
sed "2s/so/very/g" test.txt��test.txt�ļ��е�2���г��ֵ����С�so�����滻Ϊ��very��
-
��Զ��н����滻
sed "1,2,5s/so/very/g" test.txt
��test.txt�ļ��е�1��2��5���г��ֵ����С�so�����滻Ϊ��very��
-
�滻ָ����ŵĹؼ���
#ֻ�滻test.txt�ļ��г��ֵĵ�1����love�� sed "s/love/like/1" test.txt #ֻ�滻test.txt�ļ��г��ֵĵ�2����love�� sed "s/love/like/2" test.txt #�滻test.txt�ļ��г��ֵĵ�2�������һ����love�� sed "s/love/like/2g" test.txt -
��ģʽƥ��
#ͬʱ�滻���ֹؼ���,�����м��÷ֺ�,����һ���滻���ֹؼ��� sed "1,4s/I/i/g; 5,6s/I/you/g" taoge.txt -
����&��ʾƥ�䵽�Ĺؼ���
sed "s/so/{&}/g" taoge.txt�������Ǹ����йؼ��֡�so�����ϴ�����,�����&��ʾƥ�䵽������
3�����滻����:c
-
�滻�ڶ���
sed "2 c hahaha" test.txt�ѵڶ��������滻Ϊhahaha��
-
�����滻���йؼ��֡�It������
sed "/It/ c tzq" test.text�Ѻ��йؼ��֡�It�����������滻Ϊ��tzq��
4����ǰ��������:i
-
�ڵ�2��ǰ�����µ�һ��:��oh, my god��
- sed "2 i oh, my god" test.txt -
��1��3��,ÿһ��ǰ������һ��:��oh, my god��
- sed "1,3 i oh, my god" test.txt
5����������:a
-
�����һ�к�������µ�һ��:��oh, my god��
sed "$ a oh, my god" test.text
6��ɾ������:d
-
ɾ����һ��
sed "1d" test.txt -
ɾ��2��4��
sed "2,4d" test.txt -
ɾ��2�����һ��
sed "2,$"d test.txt�����d���������������,���ܸ�$дһ��
-
ɾ�����йؼ��֡�love������
sed "/love/"d taoge.txtd���Է�����������,Ҳ���Է�������
sed�Tips
1���������ſ����ǵ�����,Ҳ������˫����
2��$�������һ��,^������һ��,�е������������ʽ
3��������Է���������,Ҳ���Է�����������(���˵�4��tips)
4��$���ܸ���������д,������Ҫ,Ӧ�ð����������������,����:
#��ӡ��1�е����һ�� sed -n "1,$"p test.txt #ɾ��2�����һ�� sed "2,$"d test.txt5��-n�������Զ����,sedĬ��ִ�����Զ�������������ı�,����-n�������Զ������
����awk
awk, ��Ҳ��һ���ı�������, ��linux�µ�һ������, ��sed��ǿ�� ��linux����, �����Ǻ�̨����, ������������Ҫ�õ��� awk��������ĸ�ֱ��������λ���ߵ�����, ������ij��/ijЩ�����嵥�ʵ���д��
awk��ԭ��:�����С�\n�����з��ָ��һ����¼,����¼��ָ������ָ���������,$0��ʾ������, $1��ʾ��һ����, $n��ʾ��n���� Ĭ����ָ����ǿո����tab����
awk֧��c��c++�,���ܺ�ǿ��,��������Ҳ�ܶ�,���ʼ�����ֻ��¼�˼����ŵ��÷�
��ʽ:
awk [option] 'pattern {action}' [file(s)]
Tips:
1��pattern {action}��������õ�����
2��[option]��Ҫ��-F��ָ���ָ���,�����д,��Ĭ�Ϸָ���Ϊ�հ�(�ո���Ʊ���),��:
#��ð��Ϊ�ָ�� awk -F ��:�� '{print $2}' test.txt3��patternһ��Ϊ�������ʽ(Ҳ�������������,��NR>2),ƥ���������ϵ��н���awk����
4��awk����ָ��ͬʱ��ȡ����ļ�,����ָ�����Ⱥ�˳��,�����ȡ��
����:
| ���� | ���� |
|---|---|
| NR | ��ȡ�����м�¼(��������ļ�)������ |
| NF | ��ǰ���е��ֶθ���(����) |
| FS | �����ֶηָ���(Ĭ��ֵΪ�ո�) |
| OFS | ����ֶηָ���(Ĭ��ֵΪ�ո�) |
����FS��OFSһ����BEGIN{ }��������
�����:
�����������ʽ
0�������ı�����
�������ʽ��ʾ��,�����Ը��ļ����������Ե�:
test.text
Hello! / Hi!
Good-bye, "Mike".
See you tomorrow.
It��s time for class.
Open your books and turn to page 20.
Could you say it again?
Where��s the company?
Which is the right size?
Do you know where I��ve put my glasses?
Is this your pen? I found it under the desk.
Which is your bag?
The one on your right.
Are these books all yours?
She must be a model, isn��t she?
I really don��t known.
#I have no idea about it.
What��s your family name?
Rose, let me introduce my friend to you.
Nice to meet you, too.
toooooot
What day is it today?
It��s January the 15th, 1999.
It��s the year of 1999.
However, this dress is about $ 3183 dollars.
1���������
| ��� | RE�ַ� | �����ĺ��� |
|---|---|---|
| 1 | [:alnum:] | �������еĴ�СдӢ���ַ�������,��0-9��A - Z��a-z |
| 2 | [:alpha:] | ��������Ӣ�Ĵ�Сд�ַ�,��A-Z a-z |
| 3 | [:lower:] | ����СдӢ���ַ�,��a-z |
| 4 | [:upper:] | ������дӢ���ַ� ,��A-Z |
| 5 | [:digit:] | ��������,��0-9 |
ʾ��:
[root@localhost tmp]# grep "[:alnum:]" test.text #������仰������ʾ
grep: �ַ������� [[:space:]],���� [:space:]
[root@localhost tmp]# grep "[[:alnum:]]" test.text #���Dz���ֱ��ʹ����Щ�������,�������ȫ����Ҫ��[]����������

2���������ʽ��RE�ַ�
| ��� | RE�ַ� | ���� |
|---|---|---|
| 1 | ^ | ƥ�������ַ� |
| 2 | $ | ƥ����β�ַ� |
| 3 | . | һ�������ַ�(����Ϊ1��,�������ַ���) |
| 4 | \ | ת���,ȥ��������ŵ��������� |
| 5 | * | ǰ���һ���ַ��ظ�0�ε������� |
| 6 | [] | ��ʾƥ�䵽��������һ���ַ�([123]��ʾƥ��1��2��3������һ��) |
| 7 | [^] | ��ʾƥ�䵽���������ַ�֮������������ַ� |
| 8 | {n,m} | һ���ַ��ظ�n��m��(m��n����) |
ʾ��(ͼƬ���������������һ��):
1��

2��

3��

4��

5��
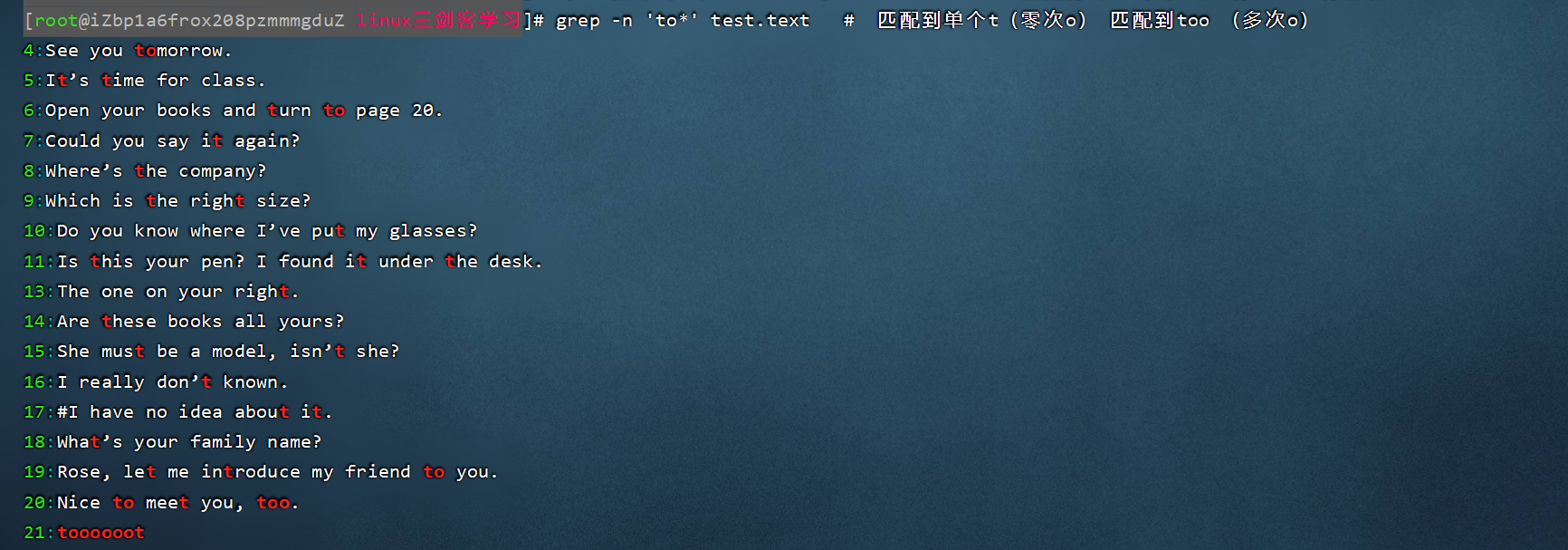
6��

7��

8��
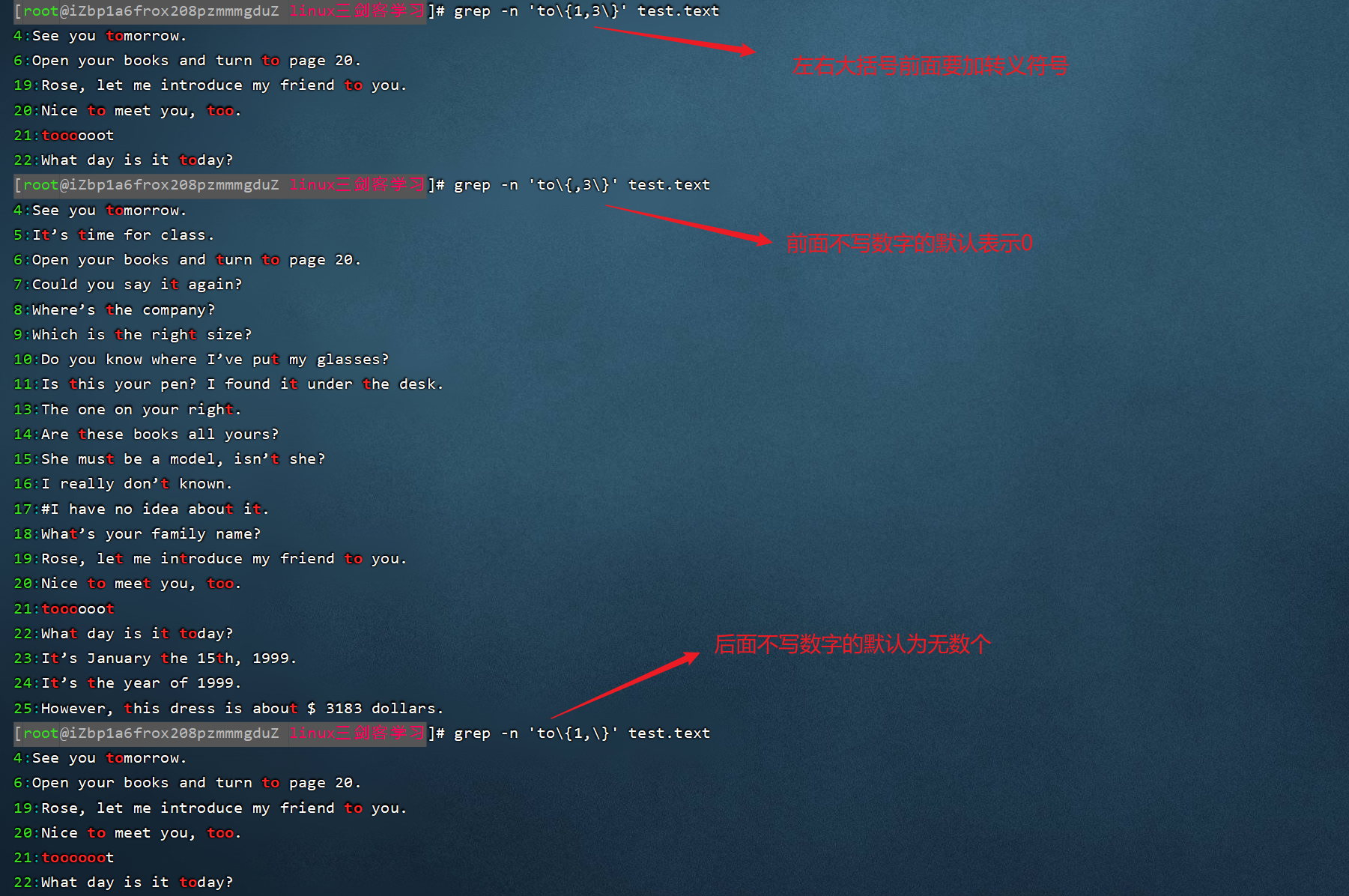
3��grep����չ�������ʽ
����չ���������egrep ����grep -E
| ��� | ��չRE�ַ� | ���� |
|---|---|---|
| 1 | + | ǰһ���ַ��ظ�1+�� |
| 2 | ? | ǰһ���ַ��ظ�0�λ�1�� |
| 3 | | | ��ʾ���� |
| 4 | () | Ⱥ���ִ� |
| 5 | ()+ | ǰһ��Ⱥ���ִ��ظ�1+�� |
#ʾ��
[root@localhost tmp]# echo "tooooabsdsadooo" | grep -E 'too|ab' #��ʾƥ��too����ab
tooooabsdsadooo #too �� ab �������
[root@localhost tmp]# echo "goodaaaglad" | grep -E 'g(oo|la)d' #��ʾƥ�䵽good����glad
goodaaaglad #good��glad�������
[root@localhost tmp]# echo "goodgabcabcabcglad" | grep -E 'g(abc)+g' #��ƥ�䵽gabcabcabcg
goodgabcabcabcglad #�ҵ�����g��ͷg��β,�м���һ�����ϵ�abc