����Ŀ¼
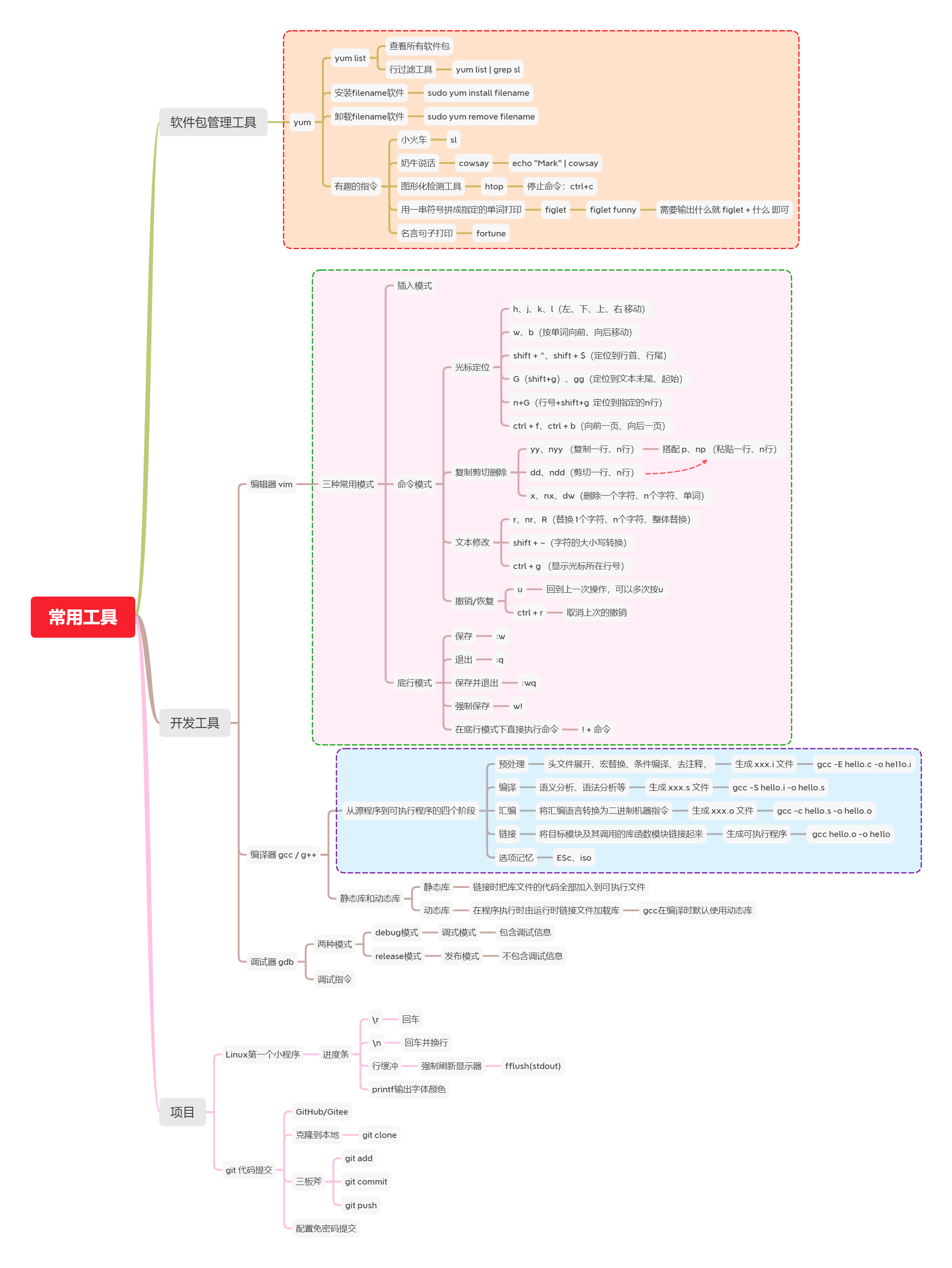
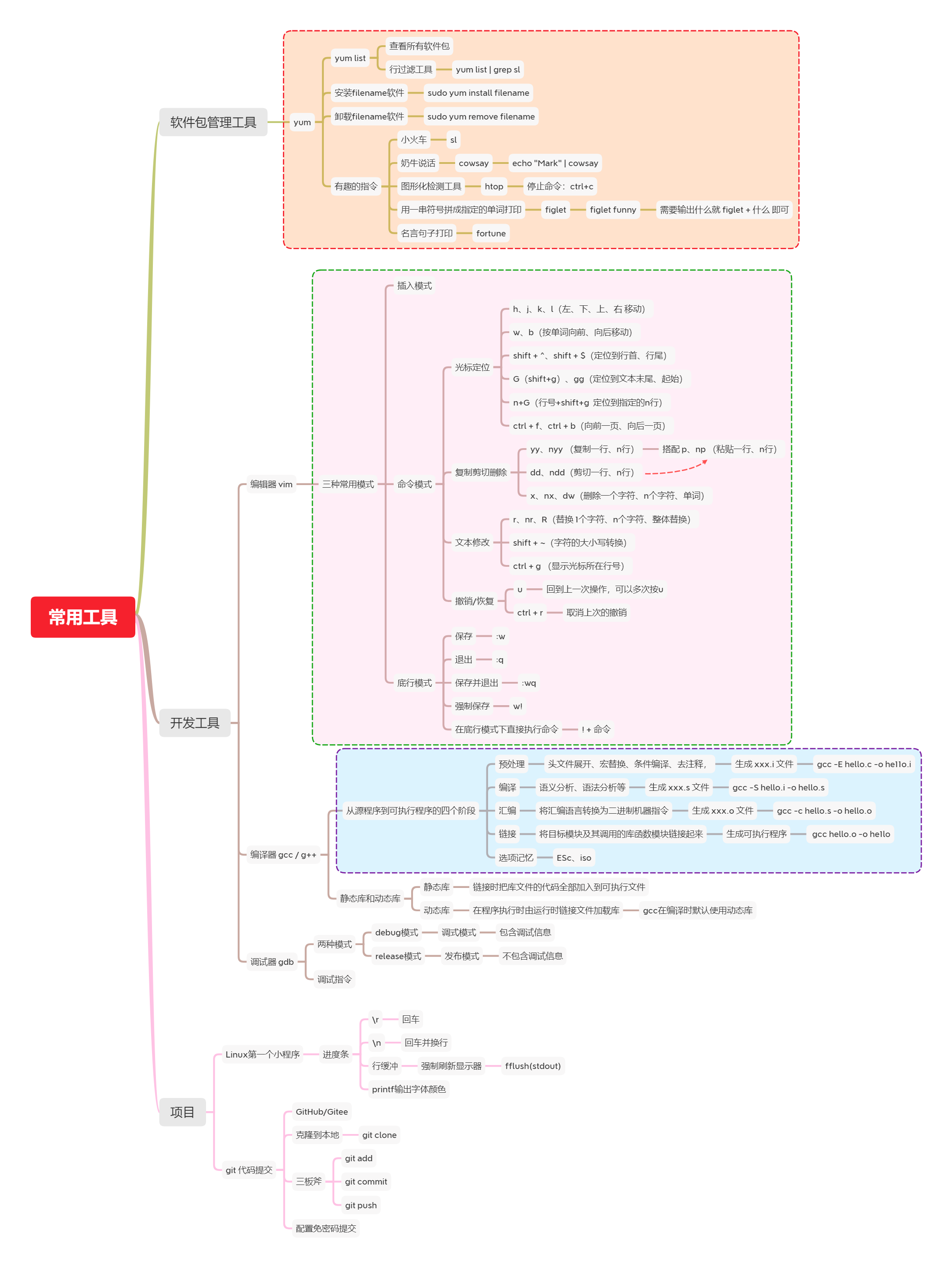
˼ά��ͼԤ��
| �����ݸ����� |
|---|
| 1)ѧϰyum����,����������װ |
| 2)����vim�༭��ʹ��,ѧ��vim�ļ����� |
| 3)����gcc/g++��������ʹ��,���˽������,ԭ�� |
| 4)���ռ�gdbʹ���ڵ��� |
| 5)���ռ�Makefile��д,�˽�������˼�� |
| 6)��д�Լ��ĵ�һ��Linux����:������ |
| 7)ѧϰgit�����еļ���,�ܹ��������ϴ���Github �� |
| ���ù��� | ���� |
|---|---|
| �������������� | ��װ���������Ĺ��� |
| �༭�� | ����д����ĵط� |
| ������ | �������Դ���ת���ɻ�������(���ͳɻ���ָ�) |
| ������ | ���Գ������й��� |
| ��Ŀ�Զ����������� | �Զ����Ľ�ij����Ŀ�����ɹ� |
| ��Ŀ�汾�������� | ����ʵ����Ŀ�Ļع����ϲ�����Ŀ�������� |
Linux �������������� yum
ʲô��������?
1)��Linux�°�װ����,һ��ͨ���İ취�����س����Դ����,�����б���,�õ���ִ�г���
2)��������̫�鷳��,������Щ�˾Ͱ�һЩ���õ�������ǰ���������������(���������Windows�ϵ�.exe��װ����)����һ����������,ͨ�������������ǾͿ��Ժܷ���Ļ�ȡ���������õ�������,�Ӷ�ֱ�ӽ��������İ�װ��
3)��������������������֮��Ĺ�ϵ,�ͺñ�"App"��"Ӧ���̵�"�����Ĺ�ϵ��
4)yum(Yellow dog Updater,Modified)��Linux�·dz����õ�һ�ְ�����������ҪӦ����Fedora��RedHat��Centos�ȷ��а��ϡ�
�ܽ�:yum�� Yellow dog Updater,Modified ������ĸ��д,������ֱ���ɵ���yum (�óԵ�)������,yum�������������ֻ��ϵ�Ӧ���̵�
����rzsz
�����������Windows������Զ�˵�Linux����ͨ��XShell�����ļ���
��װ���֮�����ͨ����ק�ķ�ʽ���ļ��ϴ���ȥ��
ע������
����yum�����в������뱣֤������������糩ͨ!���ǿ���ͨ��ping ָ������֤��������״̬��(������Ʒ������Ļ�,�Ͳ��ÿ������������,��Ϊ�Ʒ���һ����������,��Ȼ��զ��¼����~)
ping www.baidu.com//����������Windows/Linux ������ֱ�����������������
��Windows������(�������ǿ�����¼���һ�ۿ����Ľ���,�л���վ�Ǹ�)��סwin + R �������������,����cmd(��ʾcommand������)
����С�ڿ��,����ping www.baidu.com
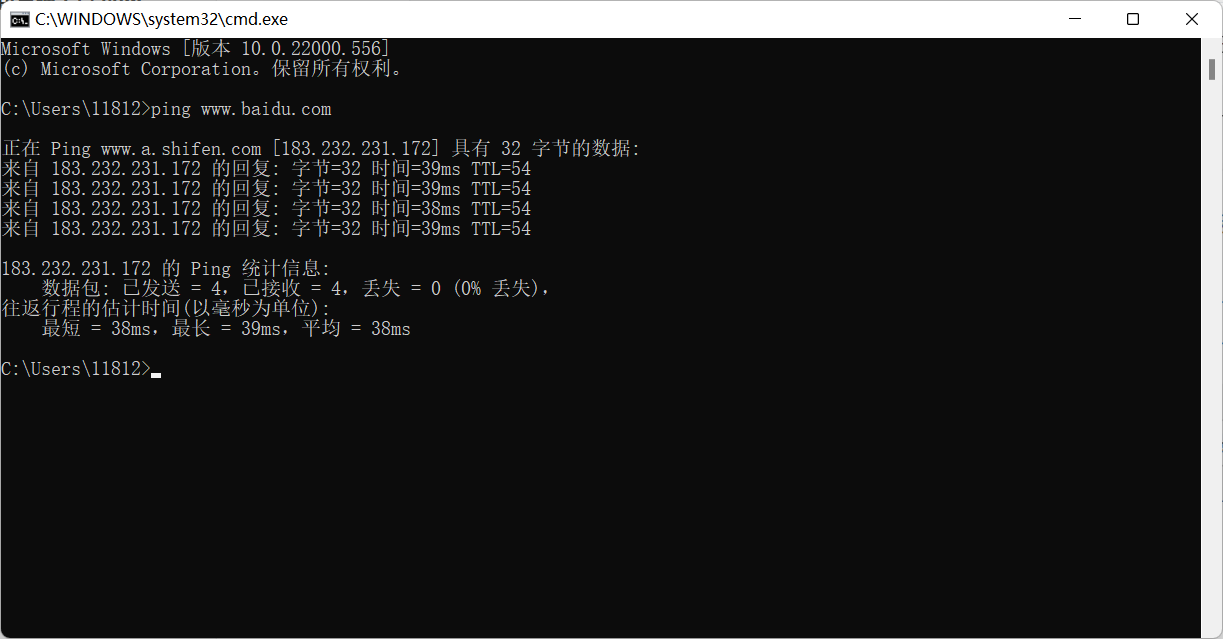
�������������,�������û����ġ�
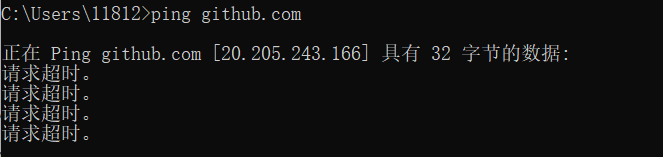
���������,��������������,�����������Լ�������û������,�����Ƿ���������������ܲ
��Linux����ʾ��
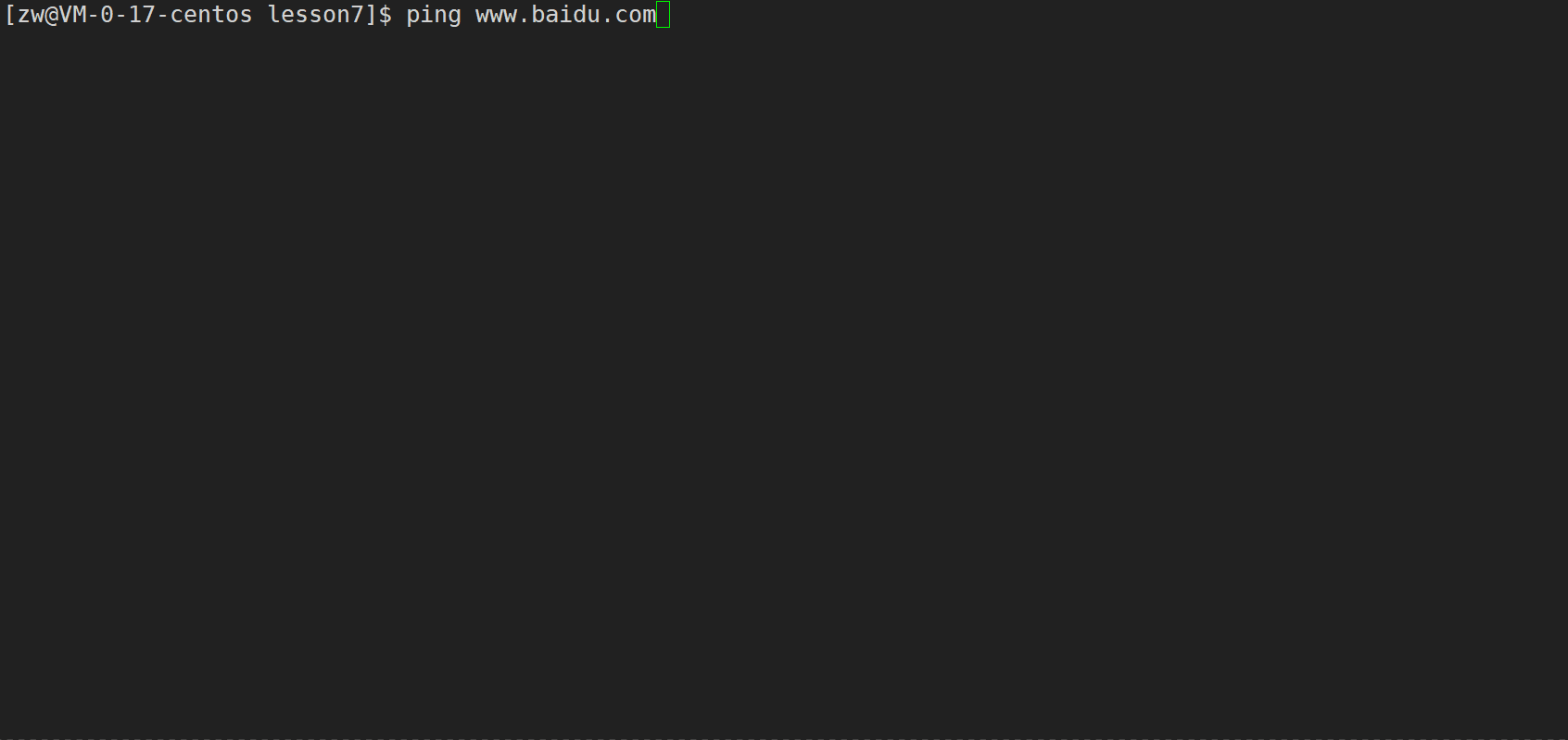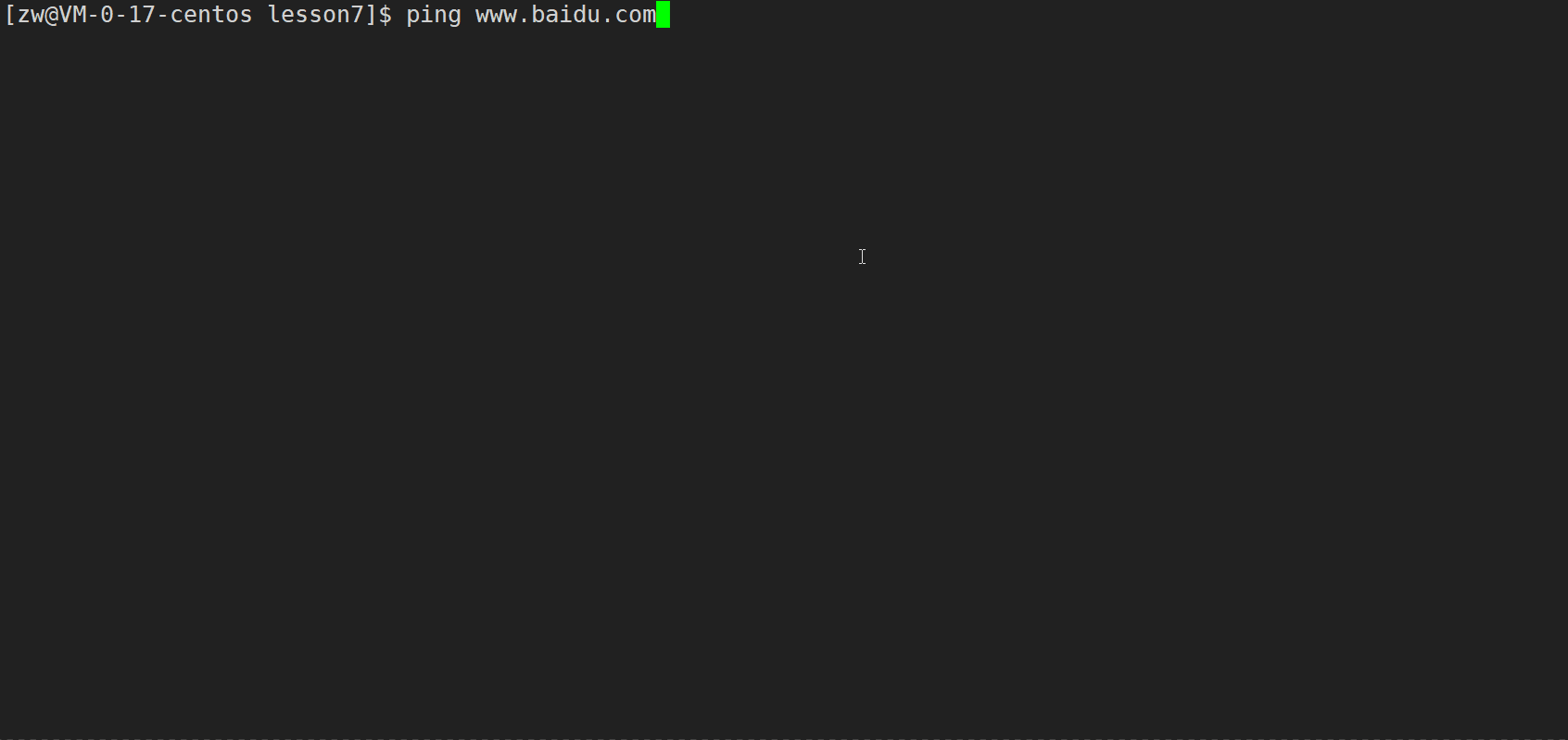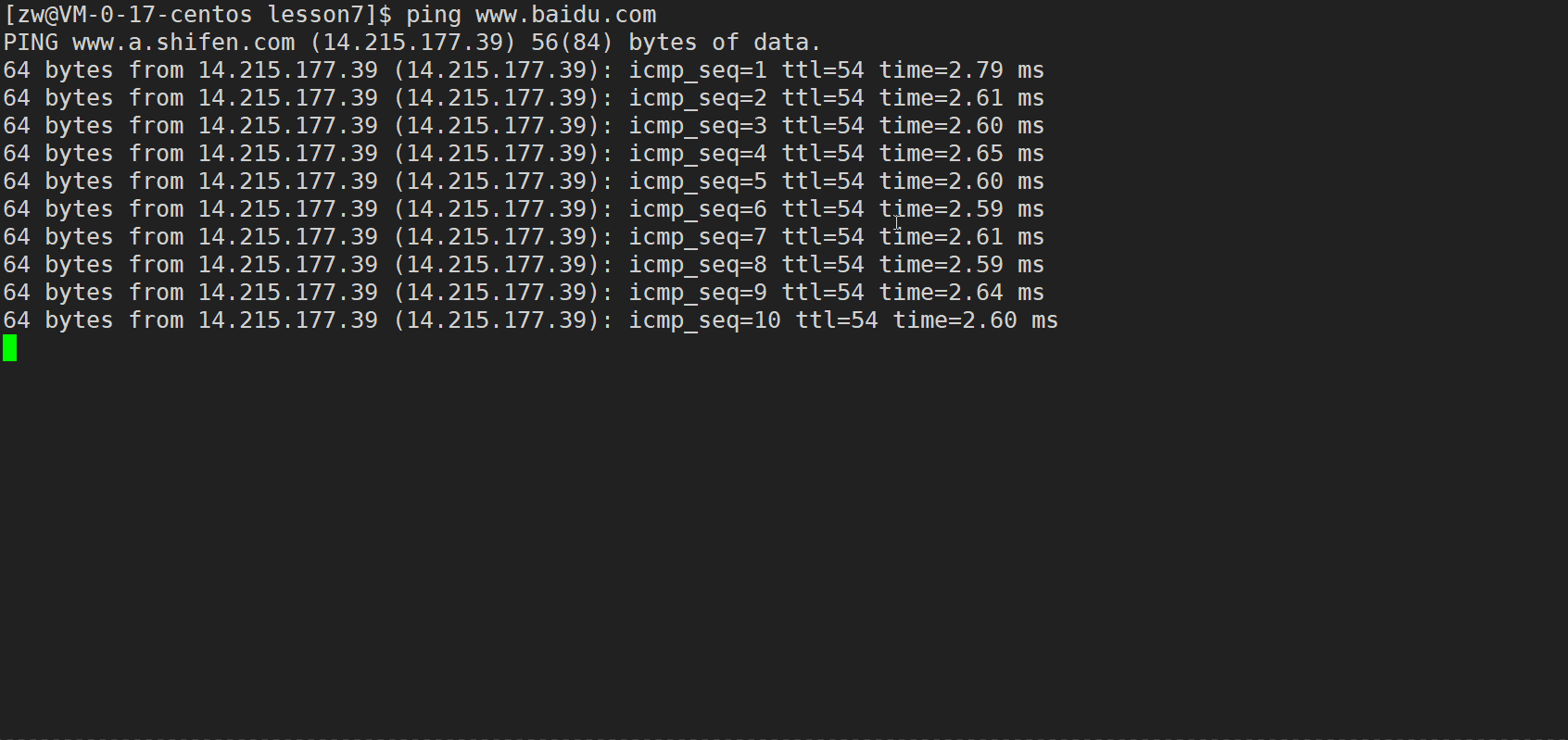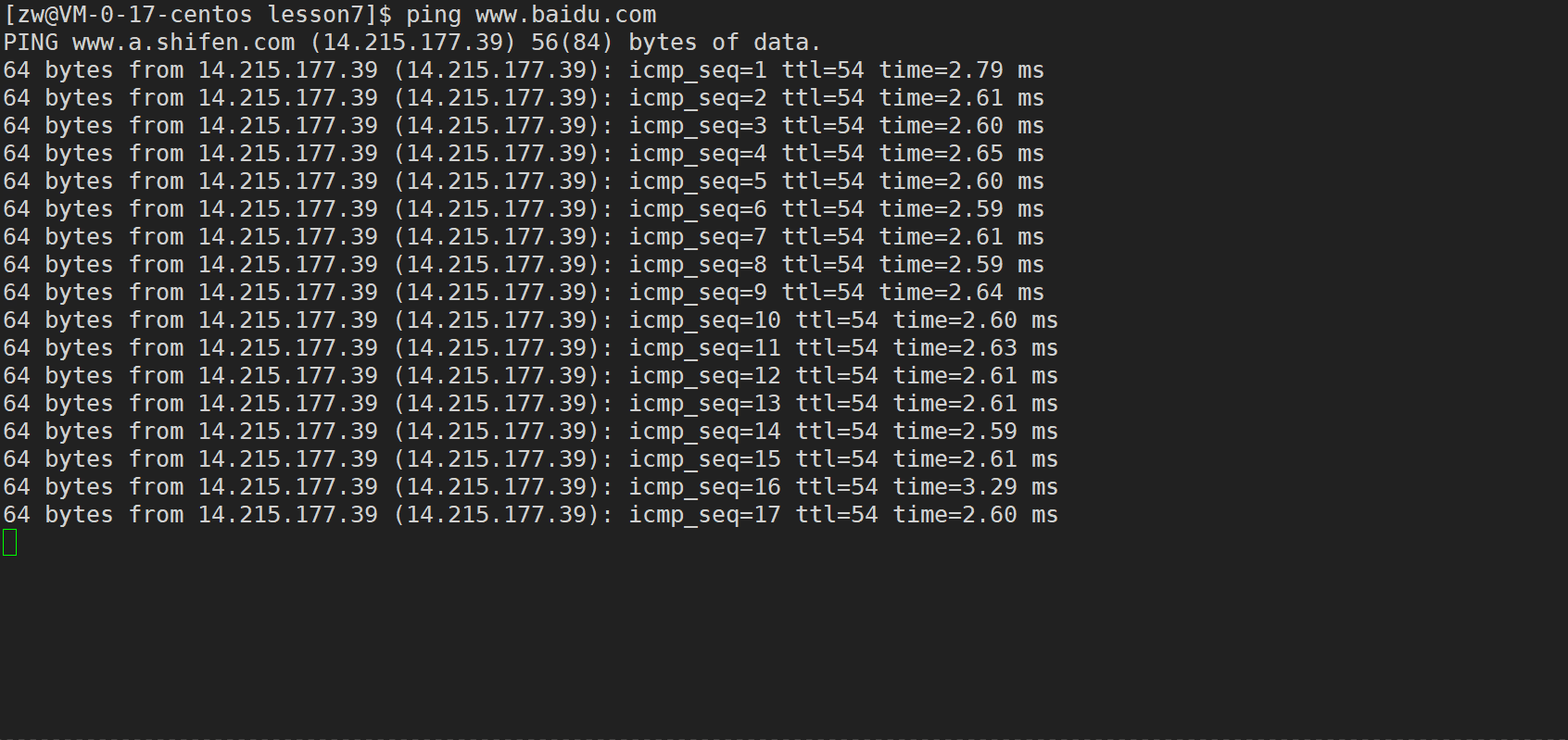
���Կ���Linux�²��Ե�ʱ����ͨ��4���������̽��,���Dz�ͣ�ķ���
Ϊ����������Կ���ͣ����,���ǿ���ָ��ִ�еĴ���,Ҳ������������packet��̽��������
ping -c6 www.baidu.com//-c6 ��ʾָ��ִ��6��̽��
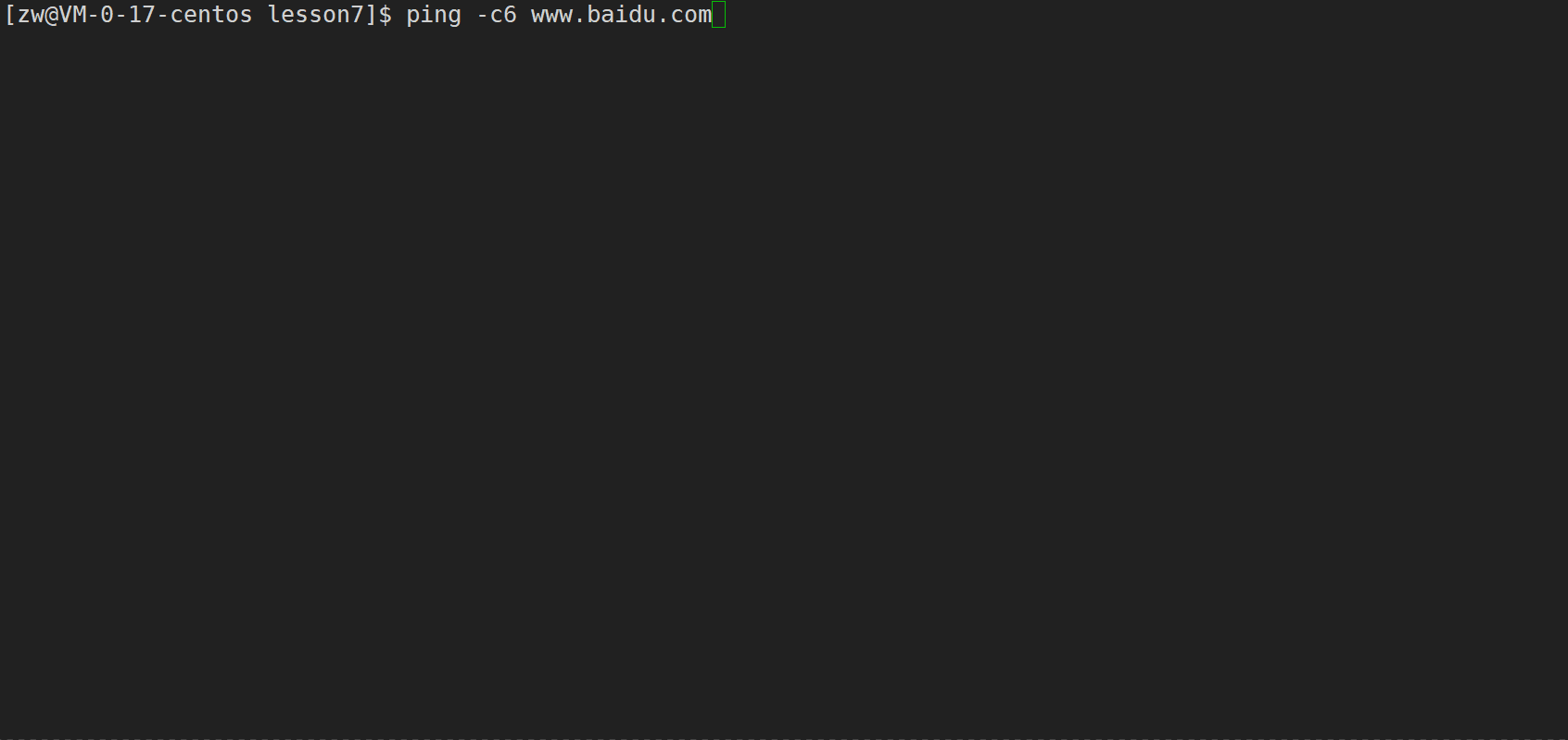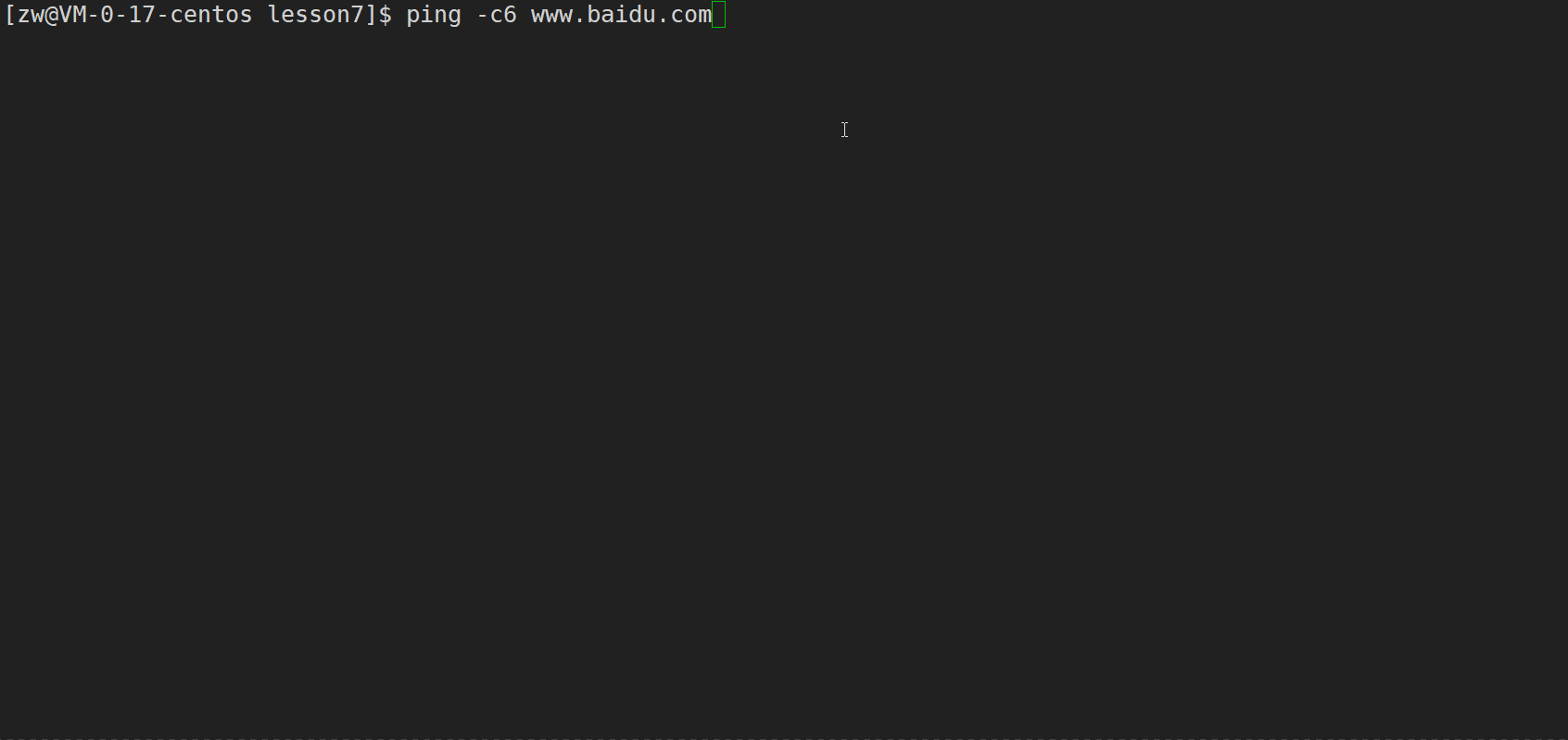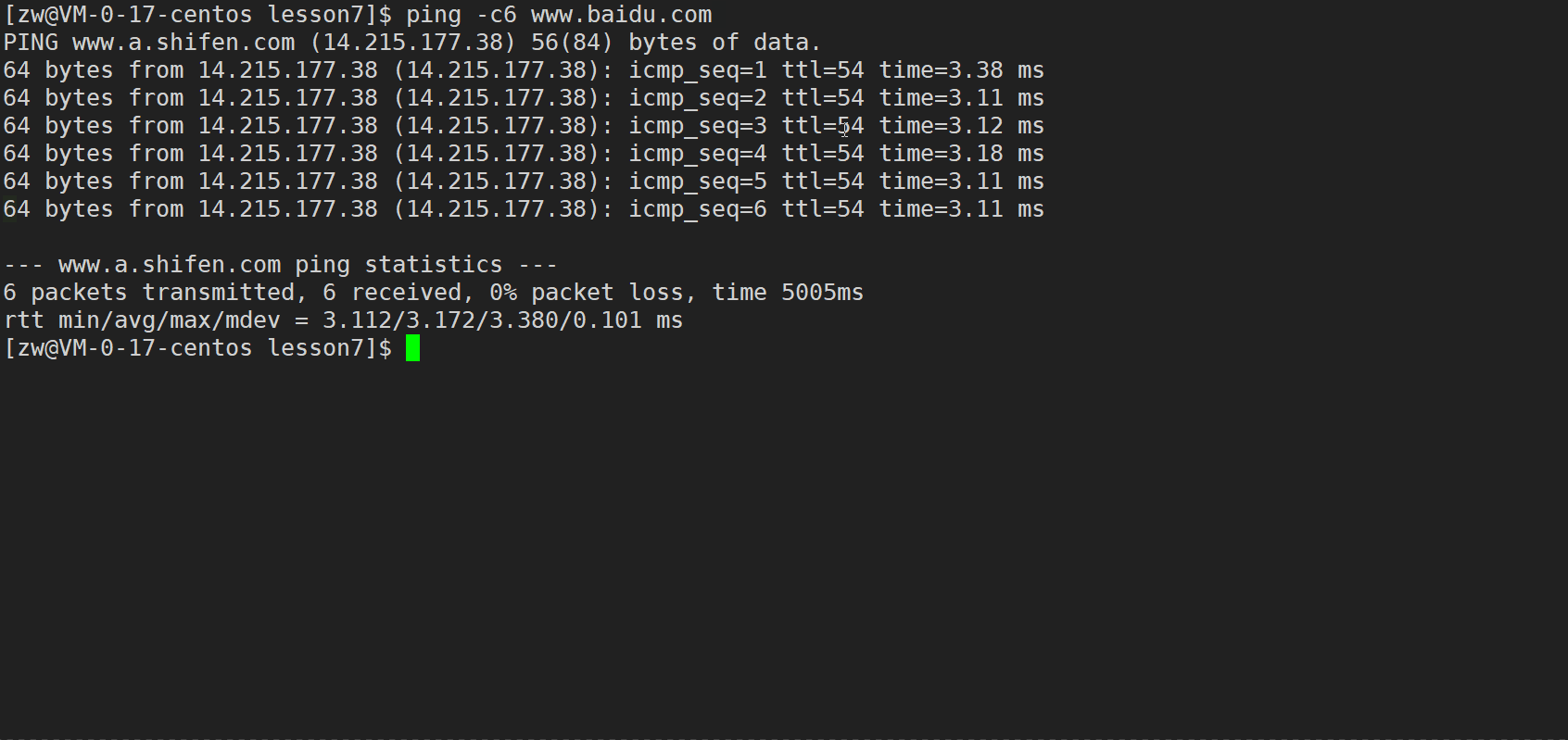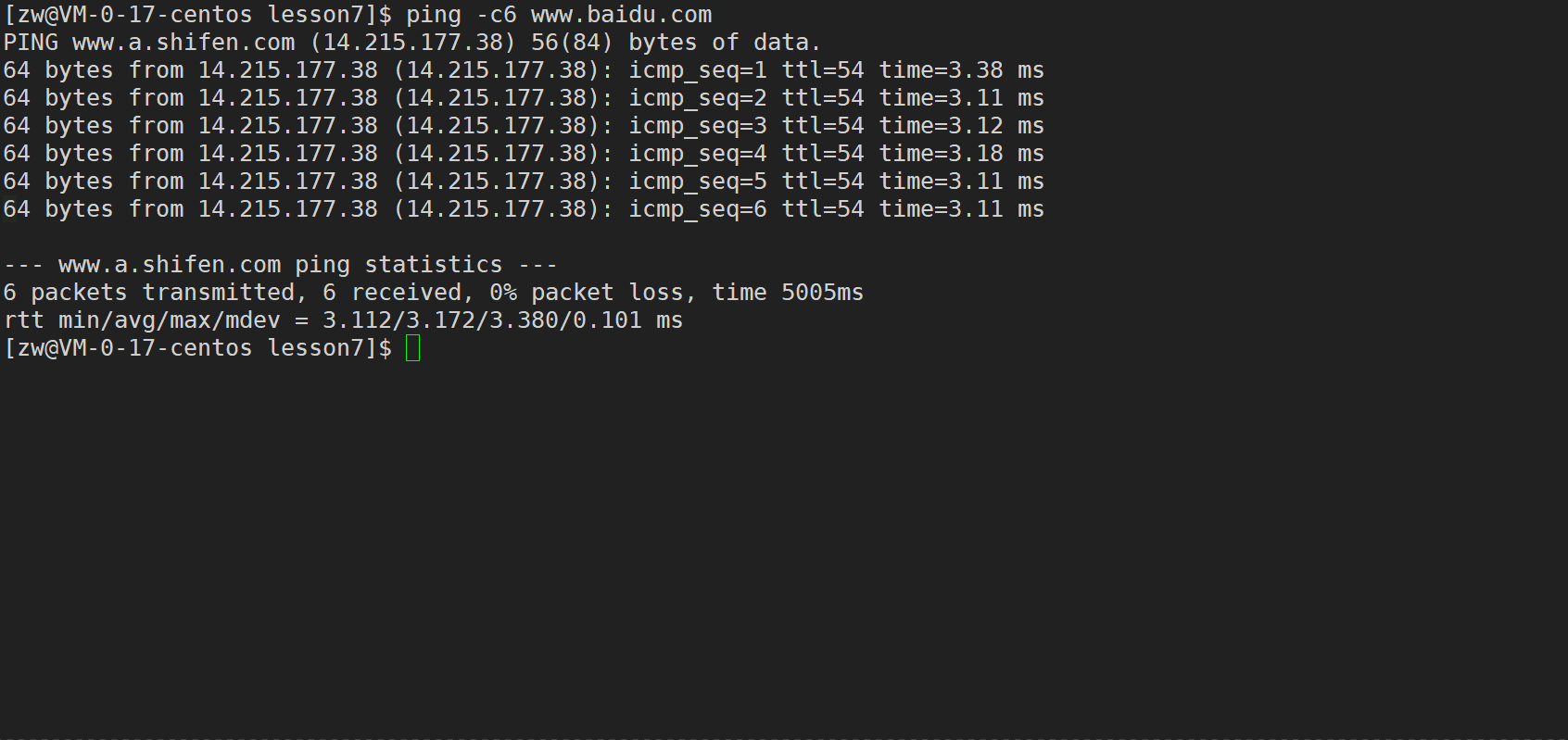
��ֱ�ʾ:������6�������,6������(�ٶȷ�����)�ɹ�������,��������0%,��ʱ 5005ms(5.005s)
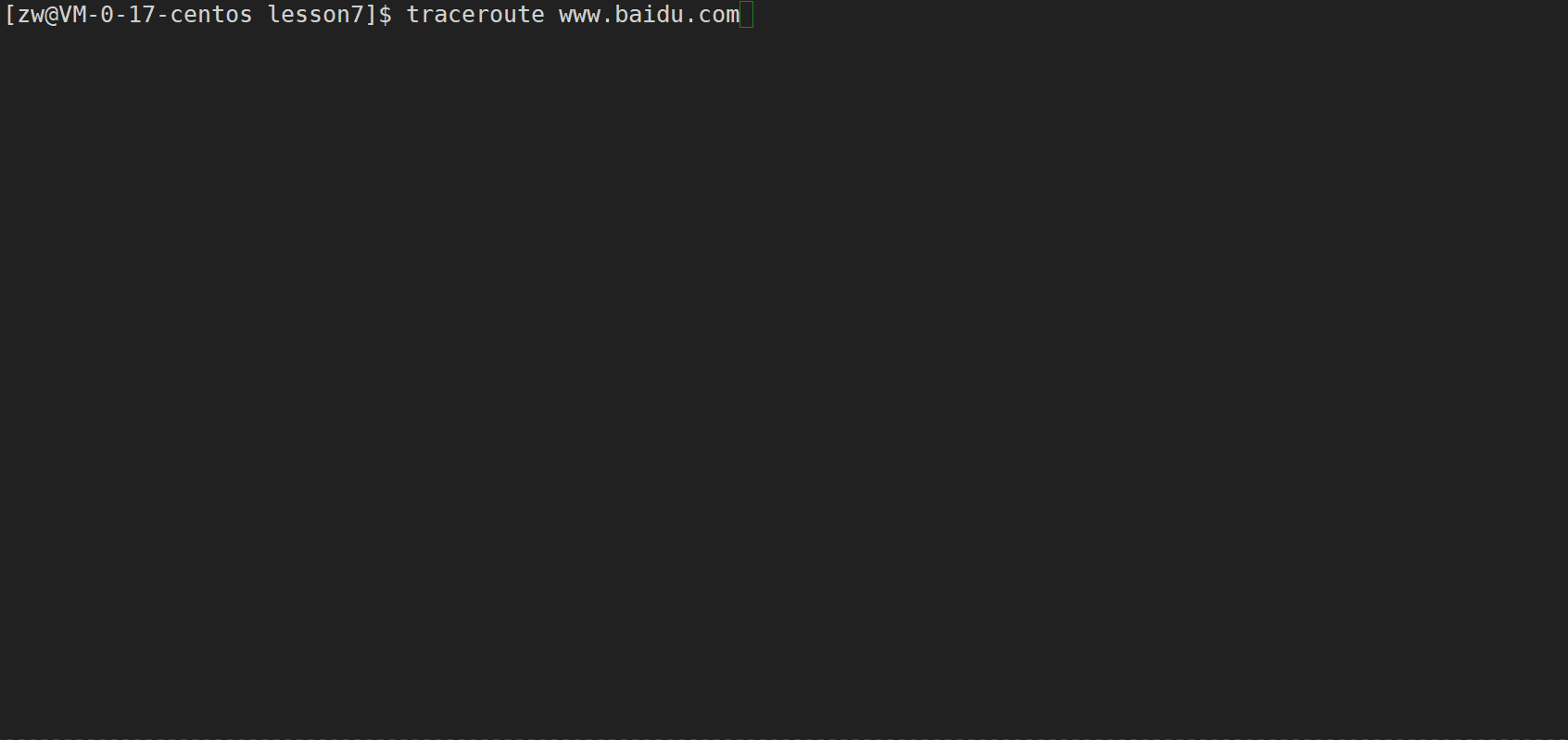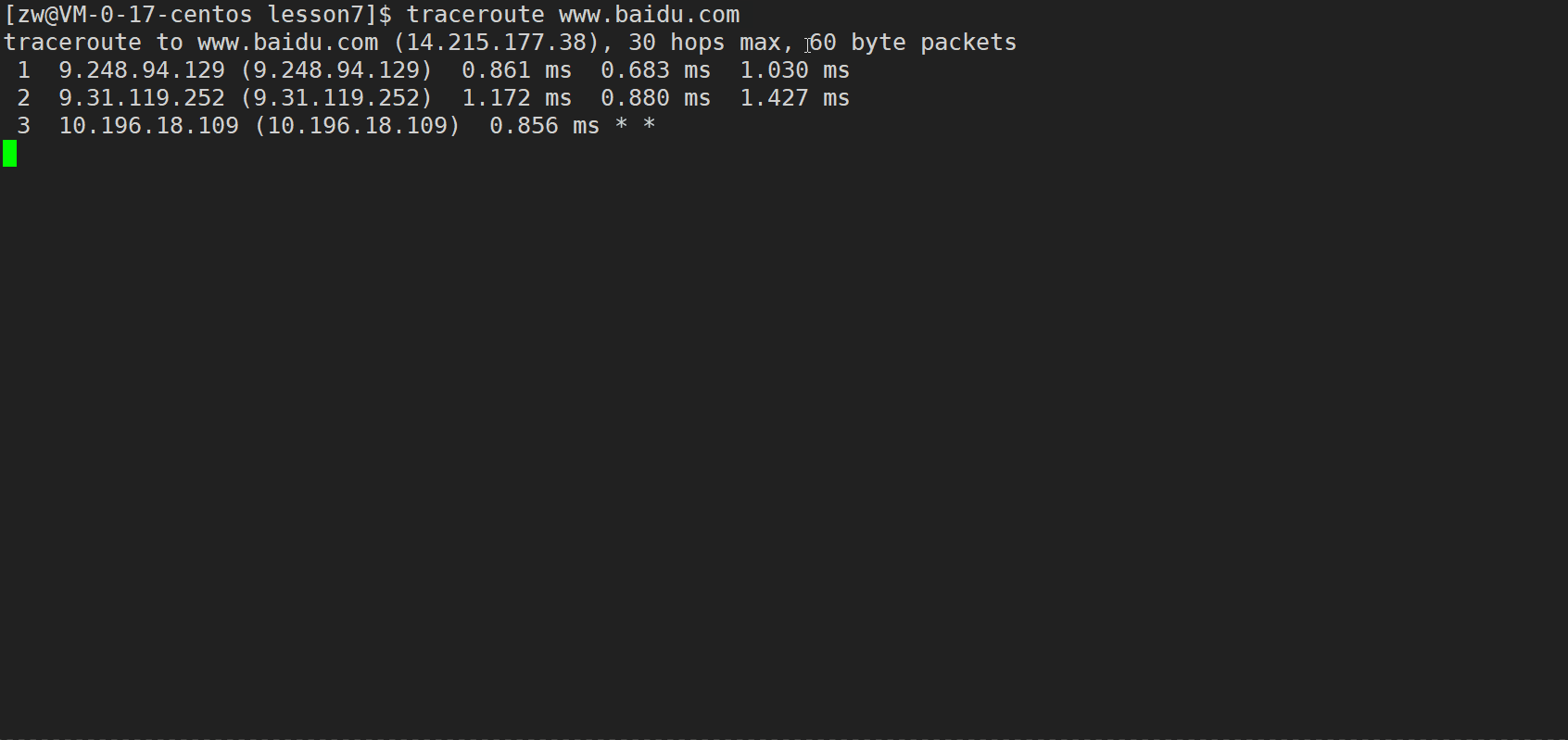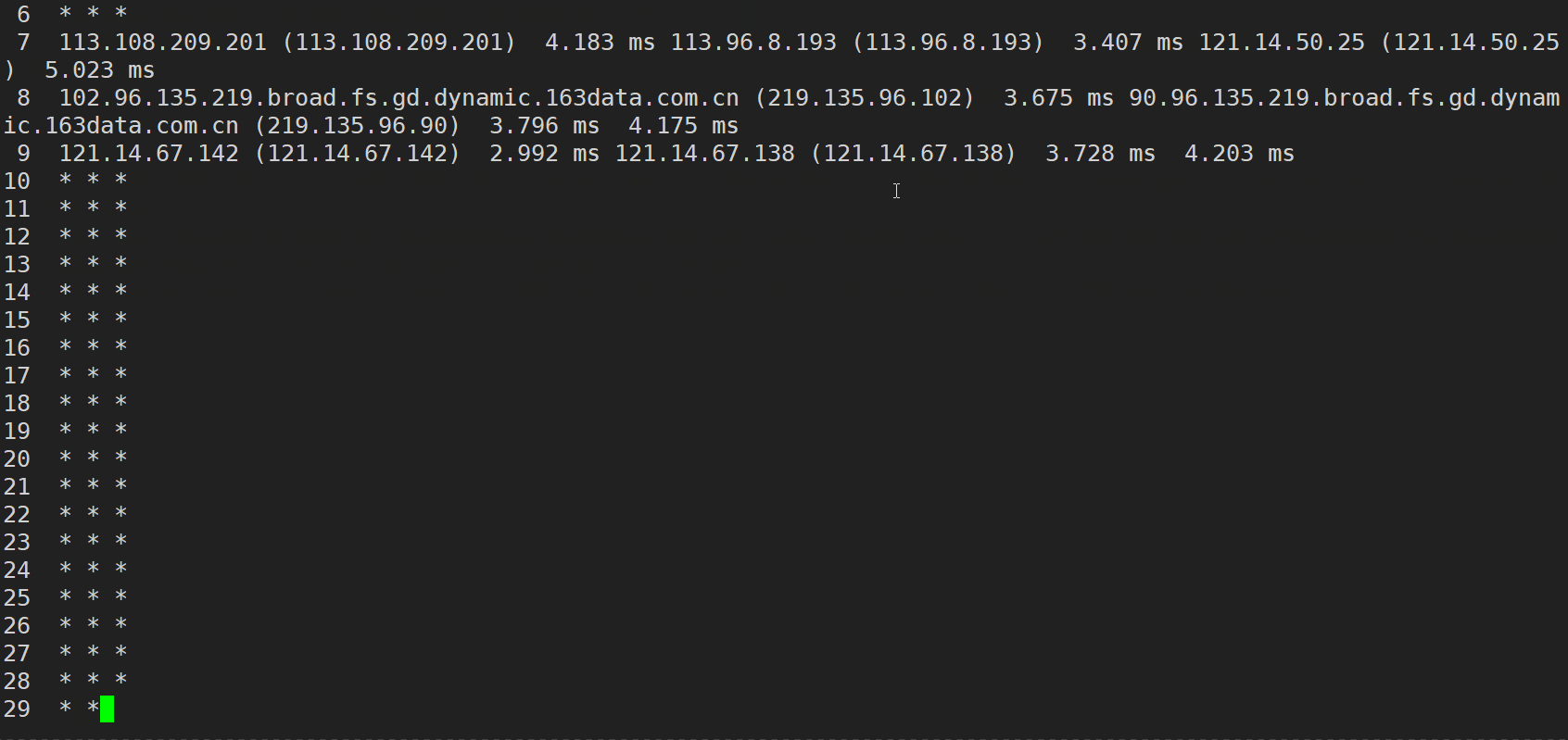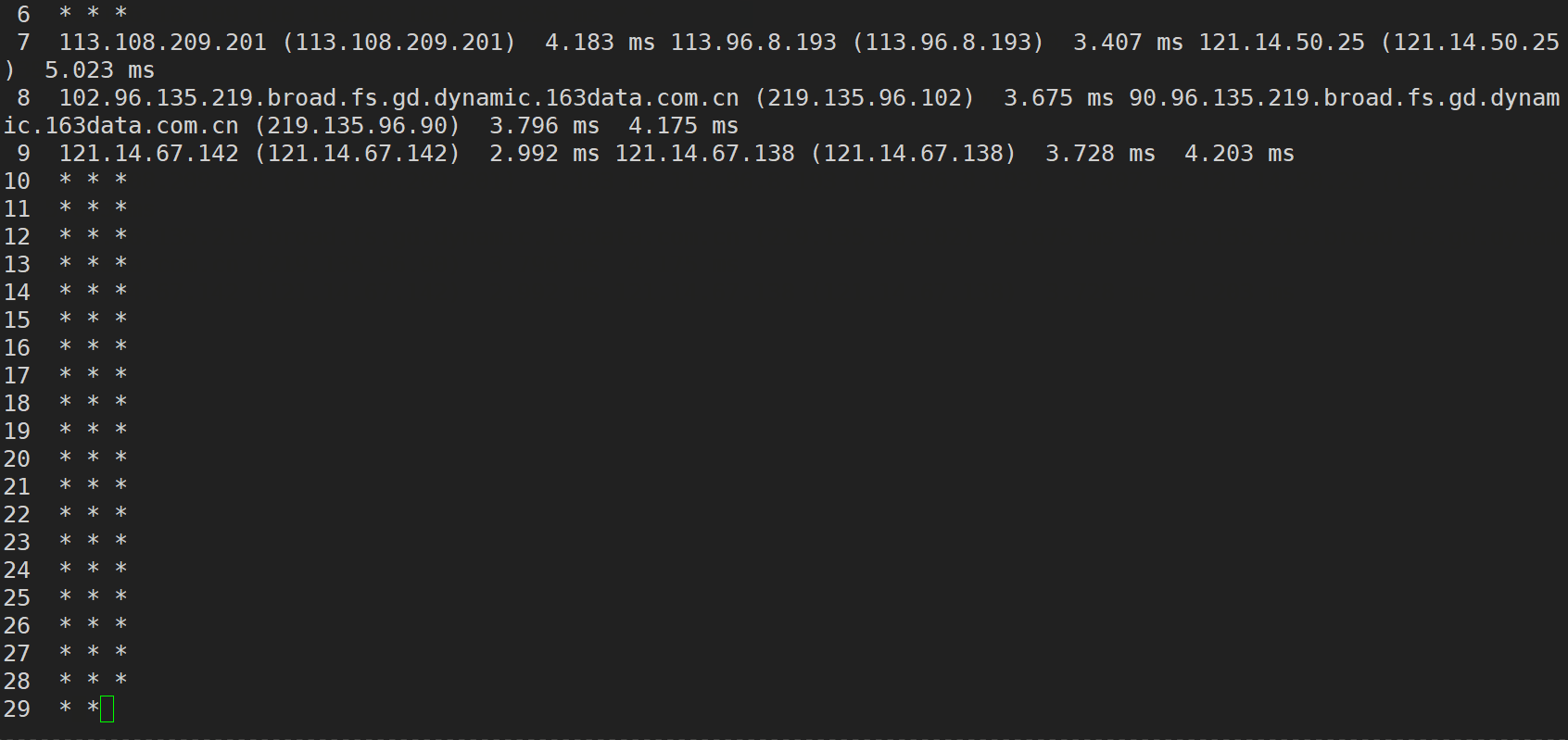
����,���ǻ��������� traceroute(·����)�������������
traceroute (Windowsϵͳ���� tracert) �������� ICMP Э�� (���������Ʊ���Э��,��������ip���鴫��IJ�����)��λ���ǵļ������Ŀ������֮�������·������TTL (Time To Live,����ʱ��,ʵ���Ͼ�������,ÿ����һ��·����,����-1,��Ϊ0��ʱ��Ͳ��ܼ����������д�����,�ᱻ·����ֱ�Ӷ���)ֵ���Է�ӳ���ݰ�������·���������ص�����,ͨ�����ݶ���ICMP ���б��ĵ�TTL ֵ�۲�ñ��ı������ķ�����Ϣ,traceroute�����ܹ����������ݰ�����·���ϵ�����·������
�鿴������
ͨ��yum list����������г���ǰһ������Щ�����������ڰ�����Ŀ���ܷdz�֮��,����������Ҫʹ��grep����(�й���)ɸѡ�����ǹ�ע�İ���
�������ֱ���� yum list ���鿴��Щ������,Ȼ��ȥ��������Ҫ��װ��������,�������Ҳ���!
yum list
����������Ҫ�鿴 lrzsz������,��ô���ǿ����Ƚ�yum list �����ݷ����ܵ� | ��,Ȼ����grep �й��˹��߸����ؼ��� lrzsz ���й��˲鿴�����Ժܷ�����ҵ�!
yum list | grep lrzsz

1)����������:���汾�š��ΰ汾�š�Դ�����кš��������ķ��к�����ƽ̨��cpu�ܹ���
2)"x86_64"����ʾ64λϵͳ�İ�װ��,"i686"�����ʾ32λϵͳ��װ��,ѡ���ʱҪ��ϵͳƥ�䡣
3)"el7��"��ʾ����ϵͳ���а�İ汾, "el7����ʾ����centos7/redhat7�� ��el6����ʾcentos6/redhat6��
4)���һ��,os/base/epel ��ʾ����"����Դ��������,������"С��Ӧ���̵ꡱ,"��ΪӦ���̵�"�����ĸ���
����չ��
yum search lrzsz//����Ҳ������yum search ������������

��ΰ�װ����
���ǿ���ͨ�� yum install �����ܼ�һ����������� lrzsz �İ�װ,lrzsz��һ����linux��ɴ���ftp�ϴ������صij���(��ʹ�� **yum install / remove ** ������������װ/ж��ʱ,Ҫע�ǰ�û���Ȩ��)
sudo yum install lrzsz//��װ������Ҫ�Ƚϸߵ�Ȩ��,����Ҫ��sodu����ʱ����Ȩ��
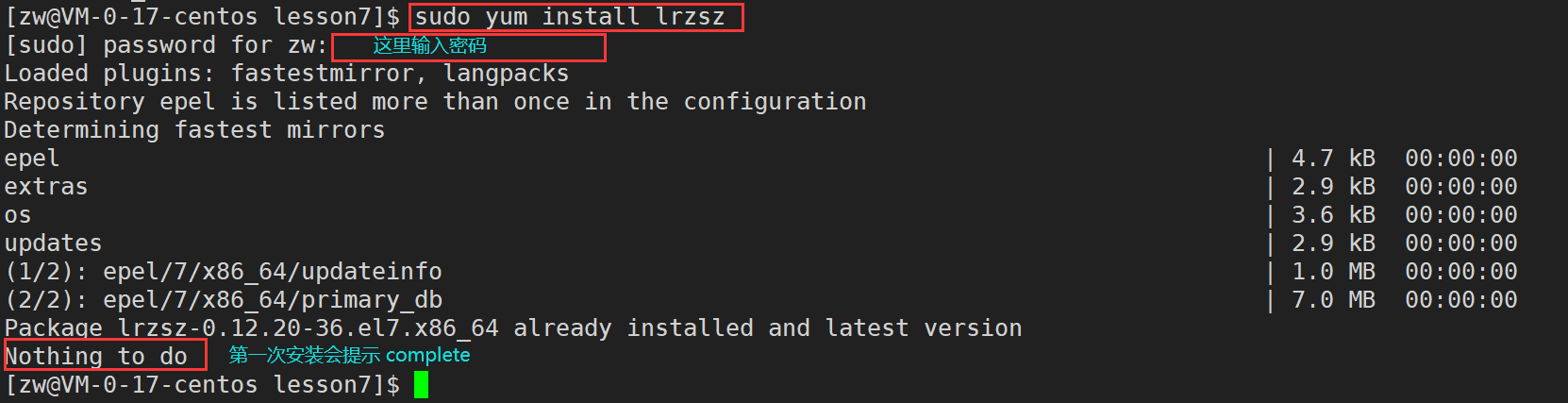
yum���Զ��ҵ�������Щ��������Ҫ����,��ʱ����"y"ȷ�ϰ�װ������"complete"����,˵����װ��ɡ�
��ע�����
1)��װ����ʱ,������Ҫ��ϵͳĿ¼��д������,һ����Ҫsudo��Ȩ�����е�root�˻��²�����ɡ�
2)yum��װ����ֻ��һ����װ�����ٰ�װ��һ����
3)yum���ڰ�װһ�������Ĺ�����,����ٳ�����yum��װ���⡪������,yum�ᱨ����
�������yum ����,���ʶ������Googleһ�¡�
��������
ͨ��������������ж��
sudo yum remove lrzsz //ж������Ҳ��Ҫ�Ƚϸߵ�Ȩ��,����Ҫ��sodu����ʱ����Ȩ��
�ܽ�:���師����
1)ͨ�� yum list �鿴����������
yum list | grep lrzsz ���˳�ָ���ؼ��ֵ�������,���� ����ָ�������� ����:yum search gcc ����gcc��������,��Ȼ,����Ҳ������yum makecache ����������Ϣ���浽����(�ӿ��������鿴�ٶ�)
2)��װ ��sudo��Ȩ(����su root�л��ɳ����û�/����Ա) ��װ����������й���ԱȨ�� yum install �� ��װ������ ����:yum install lrzsz
3)ж�� ��sudo��Ȩ(����su root�л��ɳ����û�/����Ա) ж������������й���ԱȨ�� yum remove �� ж�������� ����: yum remove lrzsz
��yum����װ��������Ķ���
ǰ����
�Ȱ�װ������epel-release,epel (Extra Packages for Enterprise Linux)�ǻ���Fedora��һ����Ŀ,Ϊ����ñϵ���IJ���ϵͳ�ṩ�����������,������RHEL��CentOS��Scientific Linux���൱�ڰ�װ��һ������������չ������װӦ���̳�~,������Ҫ��װ�ļ���������������չԴ����ġ�
��˵�������°�װĬ�϶���ʹ�÷�root�û�,����yumǰ�涼������sudo������ʱ��Ȩ,�����������root�û���װ,ֱ�Ӻ���sudo���ɡ�
sudo yum install epel-release
���� Complete��ʾ��װ��ɡ�
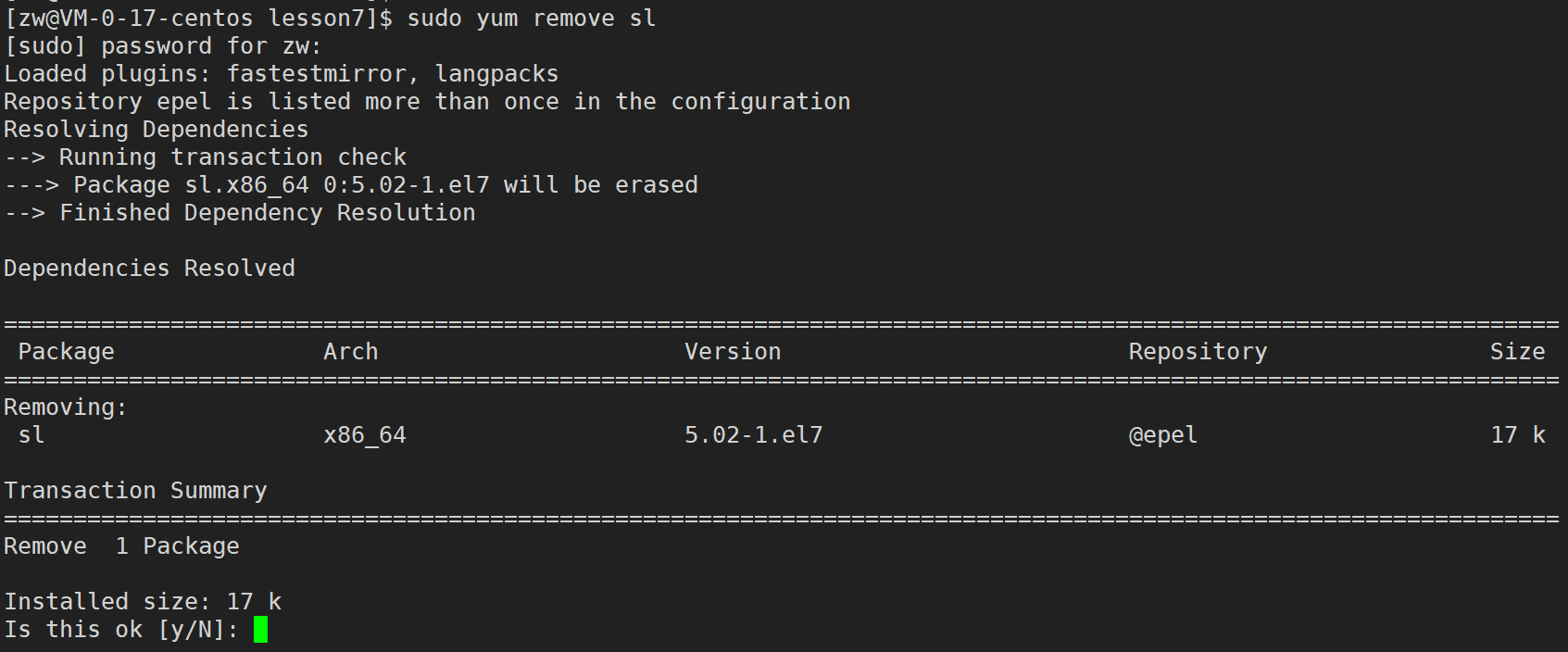
��װС��
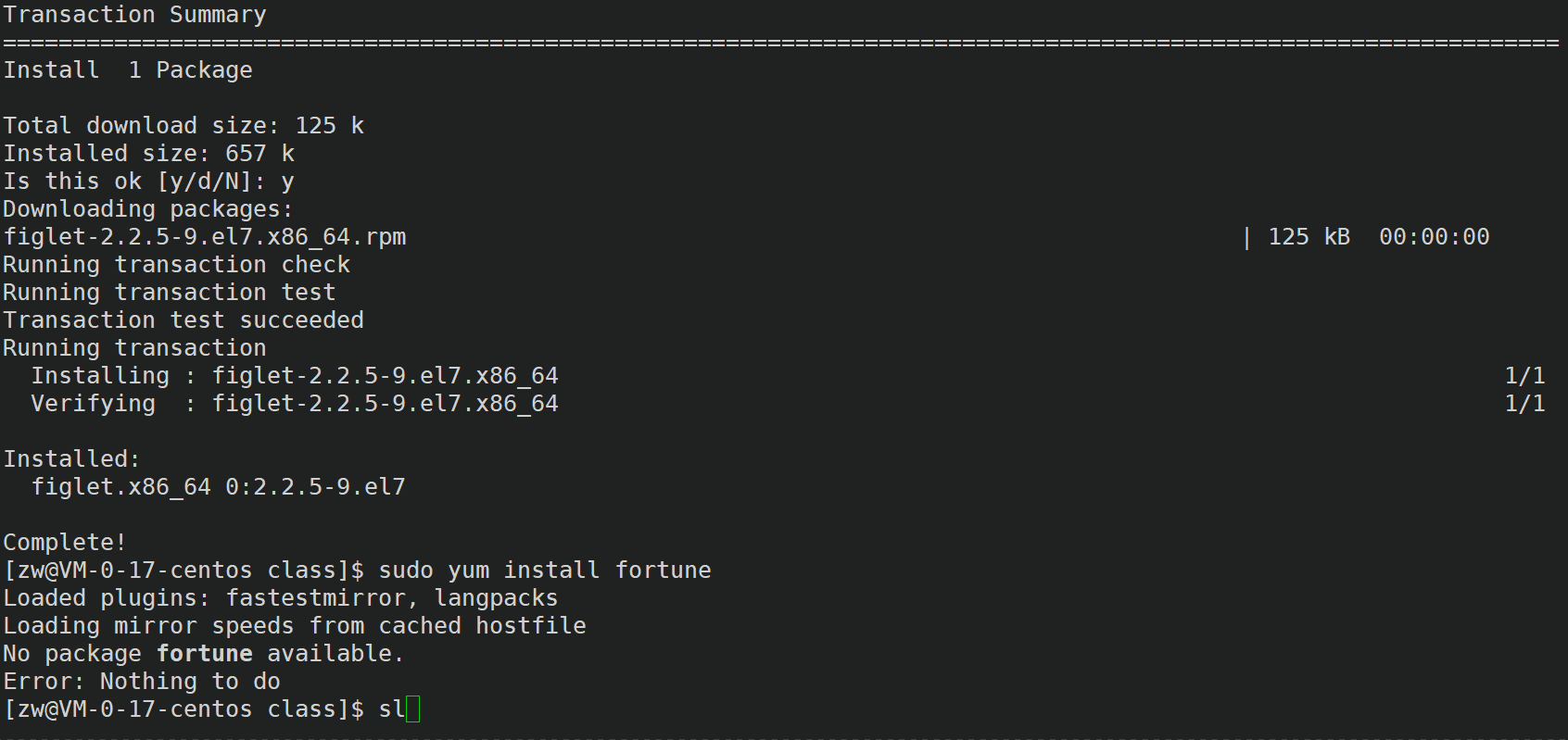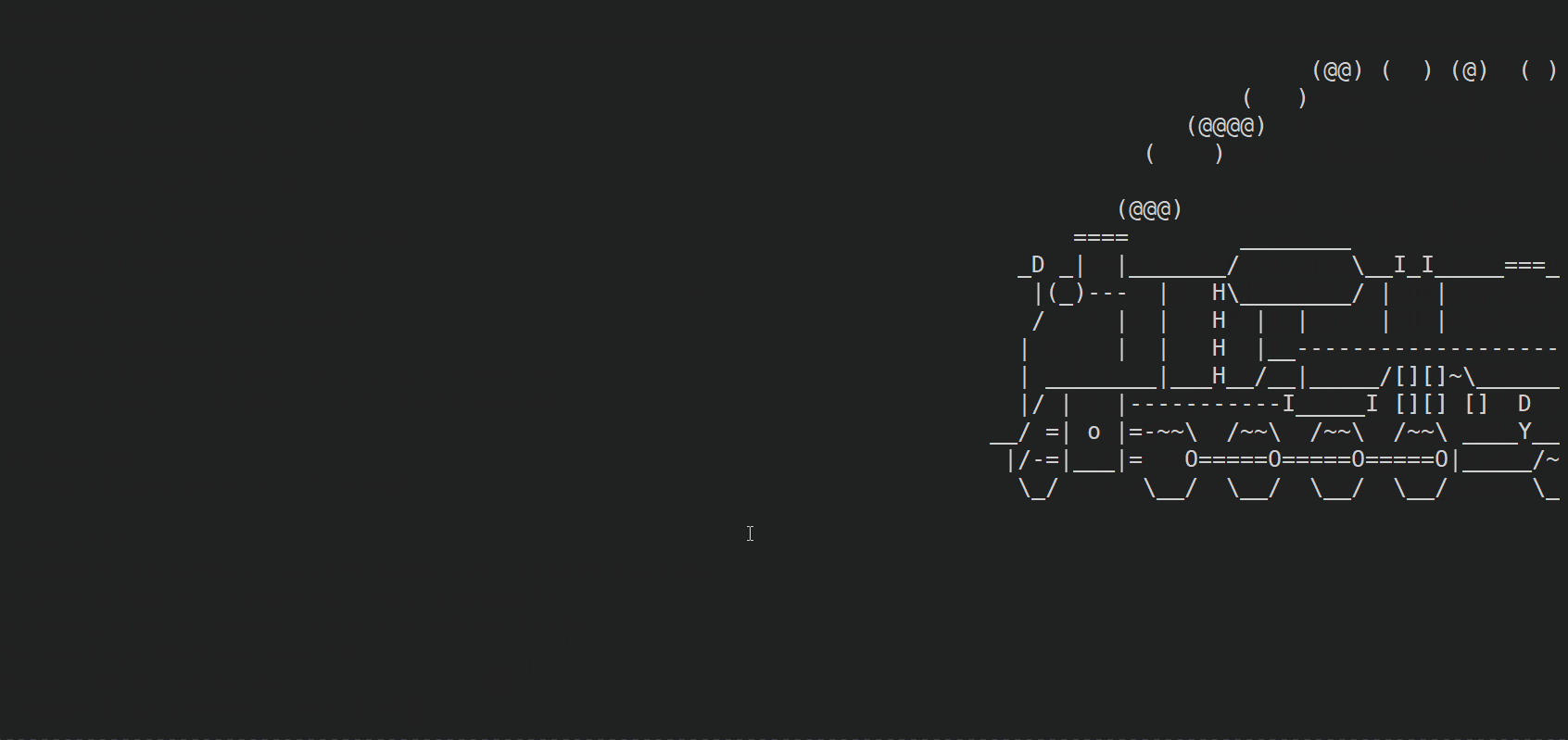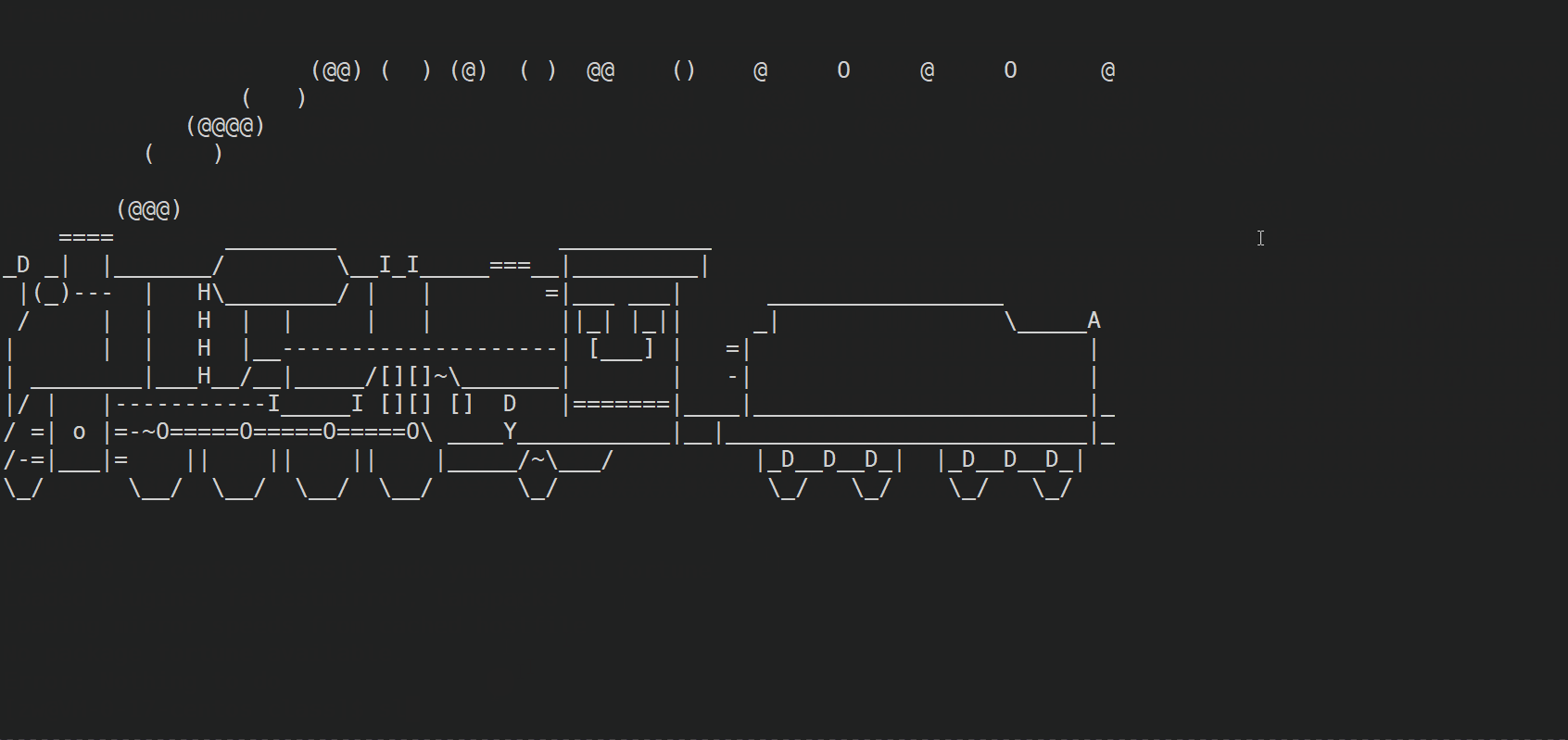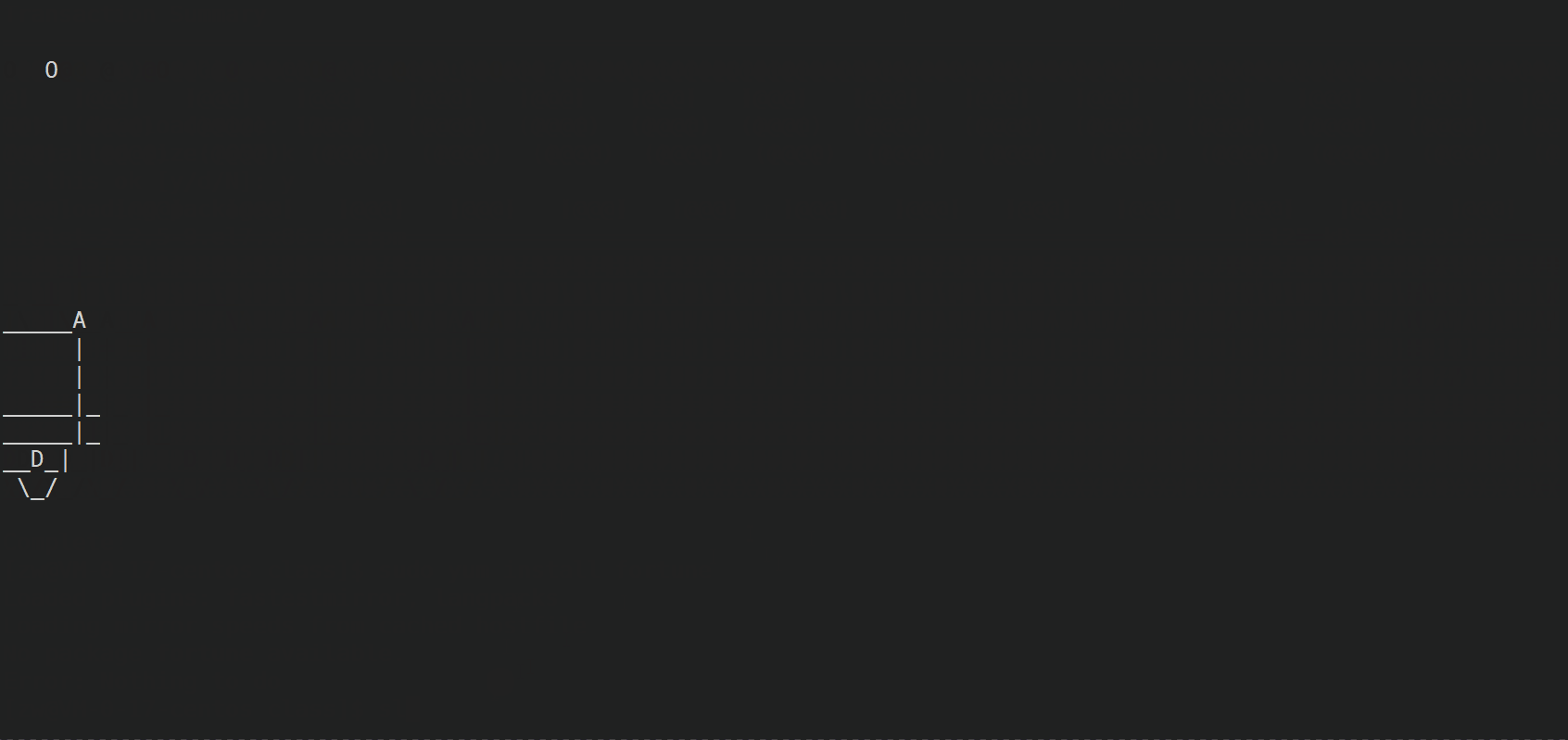
sudo yum install sl
��Ч��չʾ��
��� sudo yum remove sl
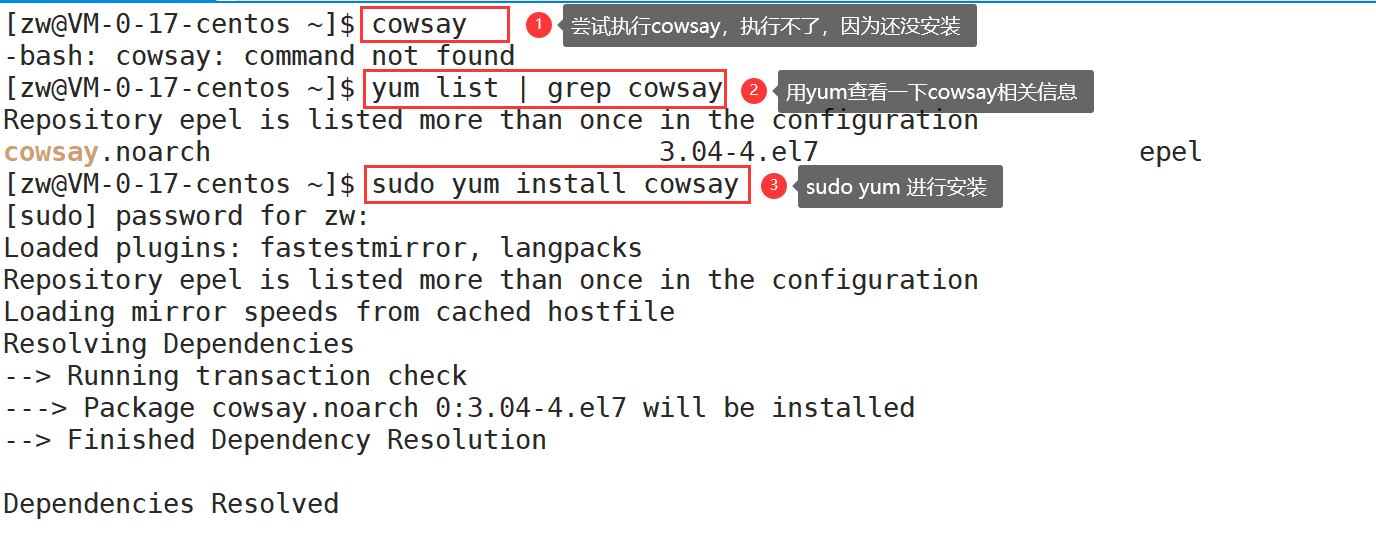
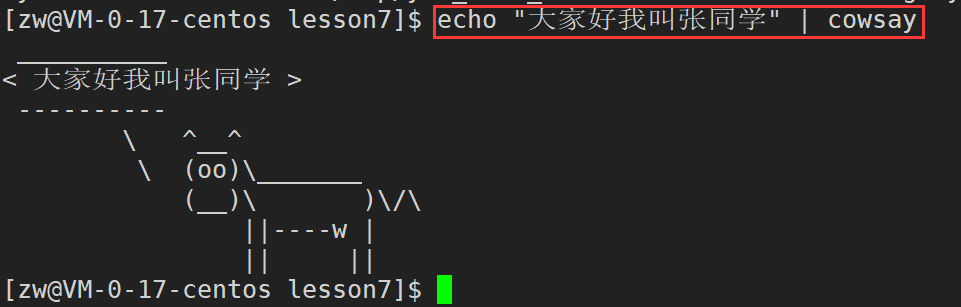
��װcowsay(��ţ˵��)
sudo yum install cowsay
echo "xxxx" | cowsay//ʹ�÷�ʽ:��xxxx�滻������Ҫ˵�����ݼ���
��Ч��չʾ��
ͼ�λ�����
1)��װepel-releaseԴ
yum install -y epel-release
2)��װ
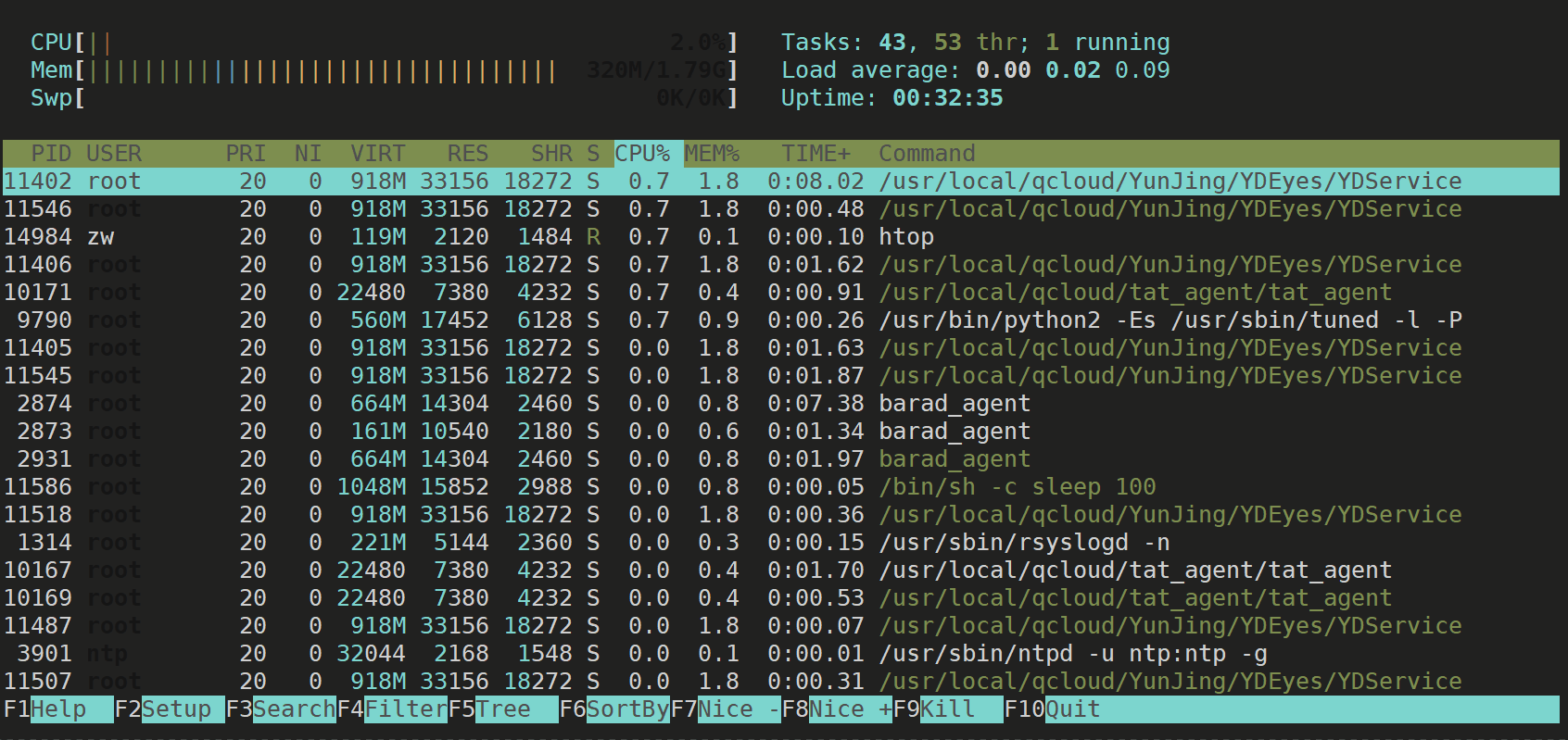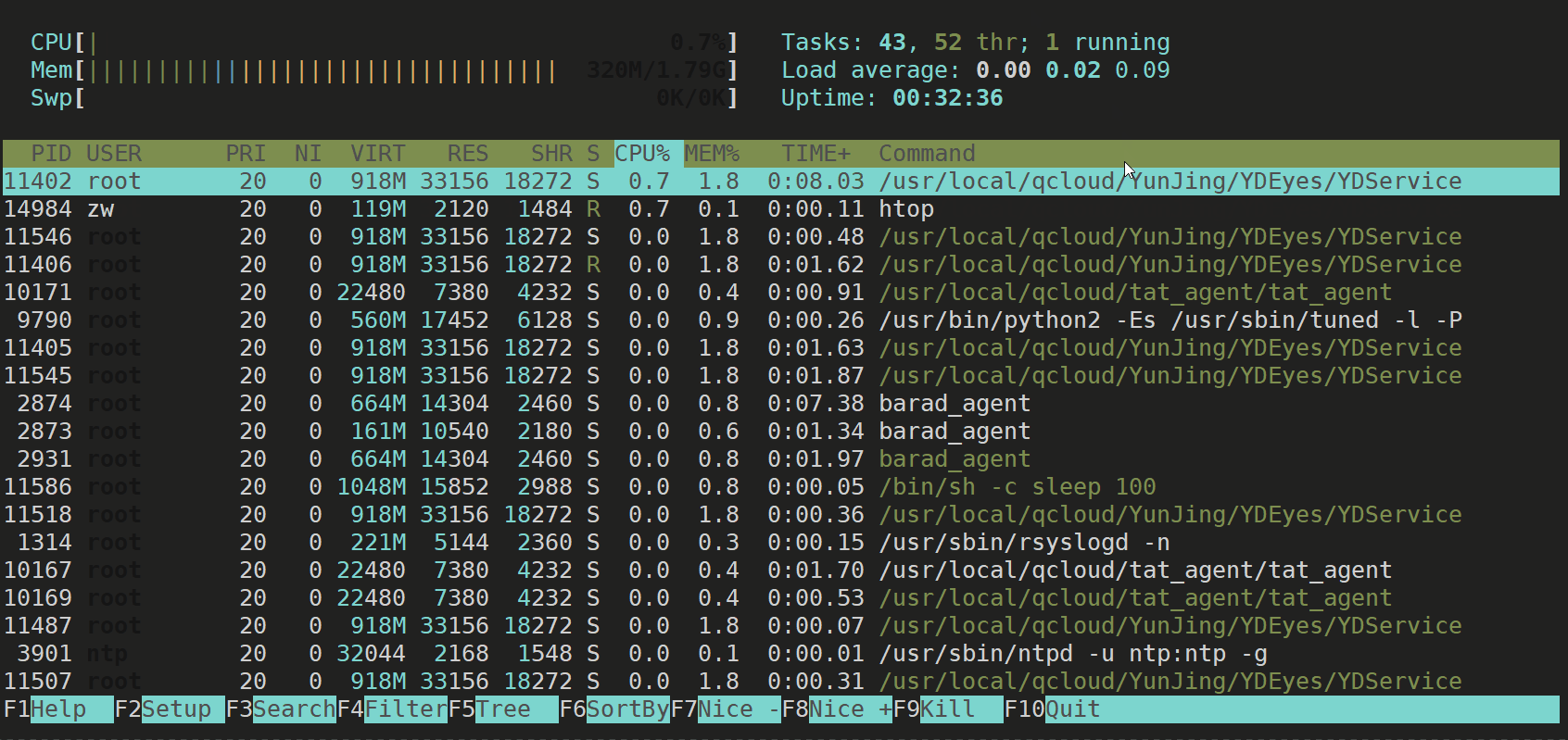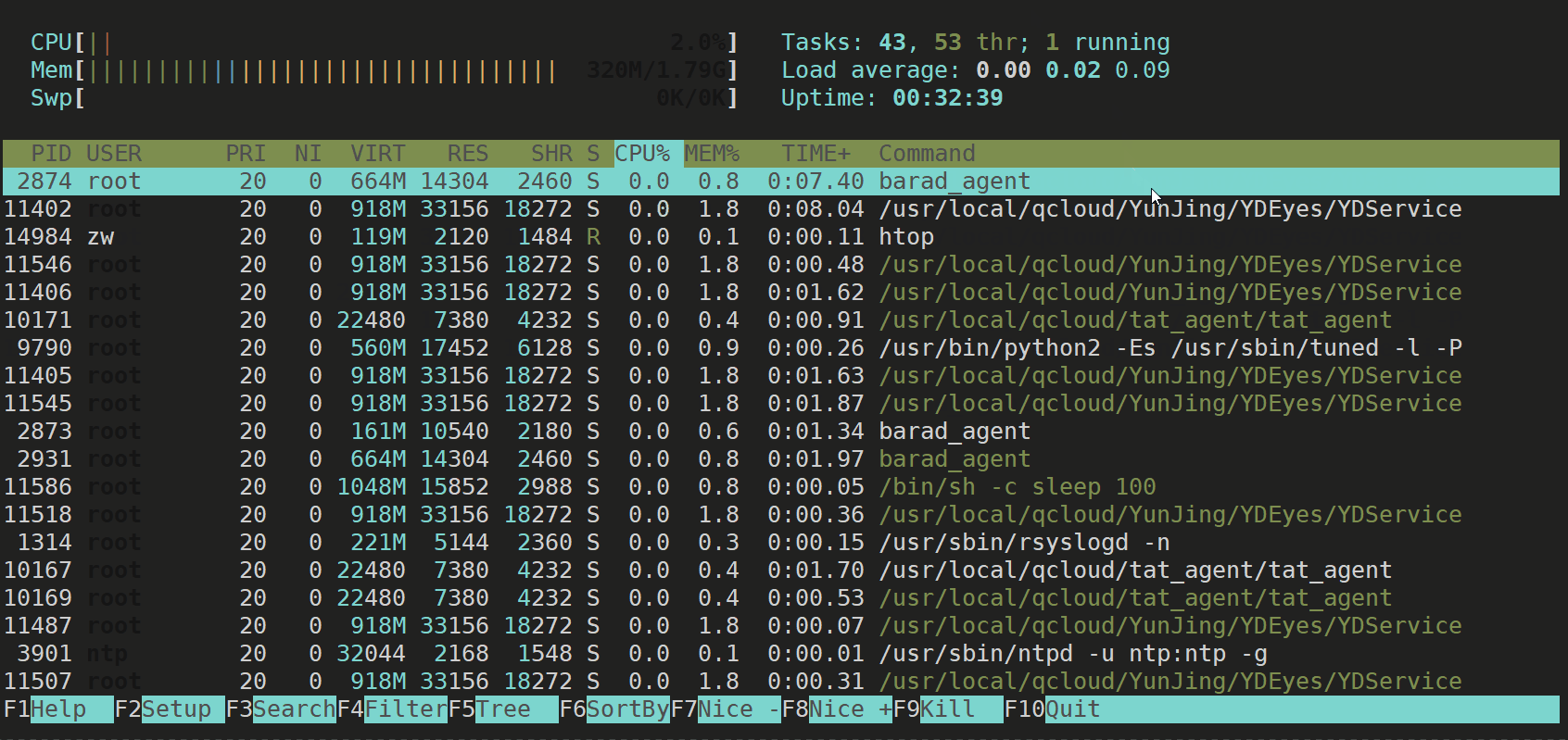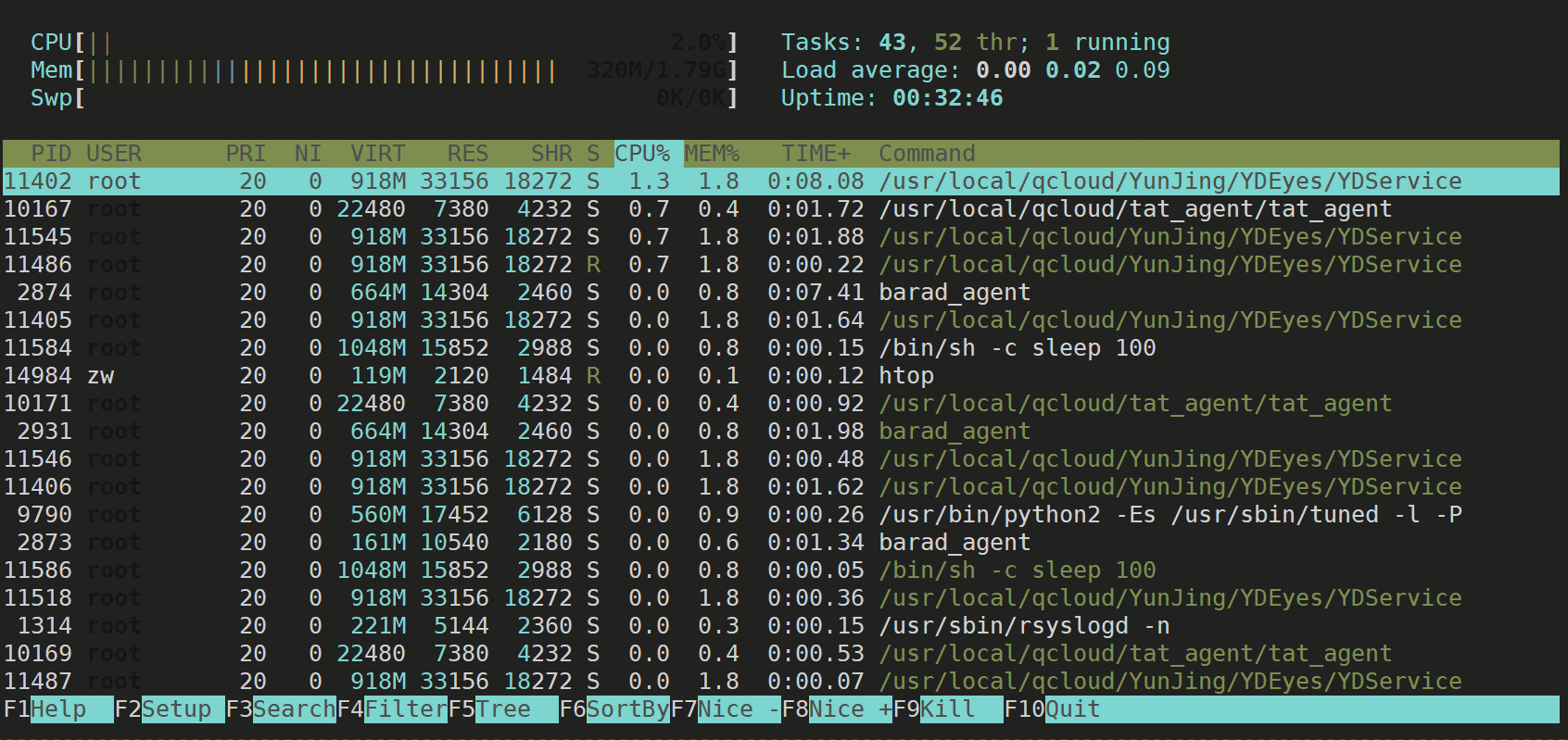
sudo yum install htop
��ע:�������ʾ���� y ���ɡ�
3)��װ�ɹ�
ִ�з�ʽ:ֱ������htop,��enterִ�м��ɡ�
htop
ֹͣ����:ctrl+c
��Ч��չʾ��
��һ������ƴ��ָ���ĵ��ʴ�ӡ
1)��װepel-releaseԴ
yum install -y epel-release
2)��װ
sudo yum install figlet
��ע:�������ʾ���� y ���ɡ�
3)��װ�ɹ�
ִ������:
figlet funny
��ע:��Ҫ���ʲô�� figlet + ʲô ���ɡ�
��Ч��չʾ��
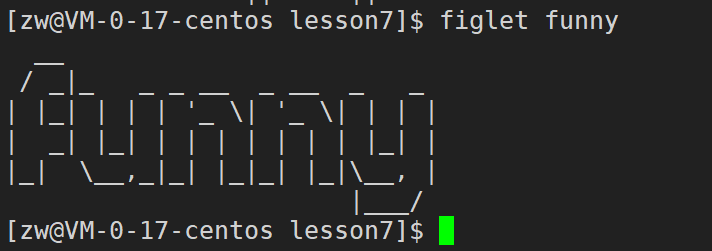
���Ծ��Ӵ�ӡ
1)��װepel-releaseԴ
yum install -y epel-release
2)��װ
sudo yum install fortune-mod
����ע���������ʾ���� y ���ɡ�
3)��װ�ɹ�
ִ������:
fortune
��Ч��չʾ��
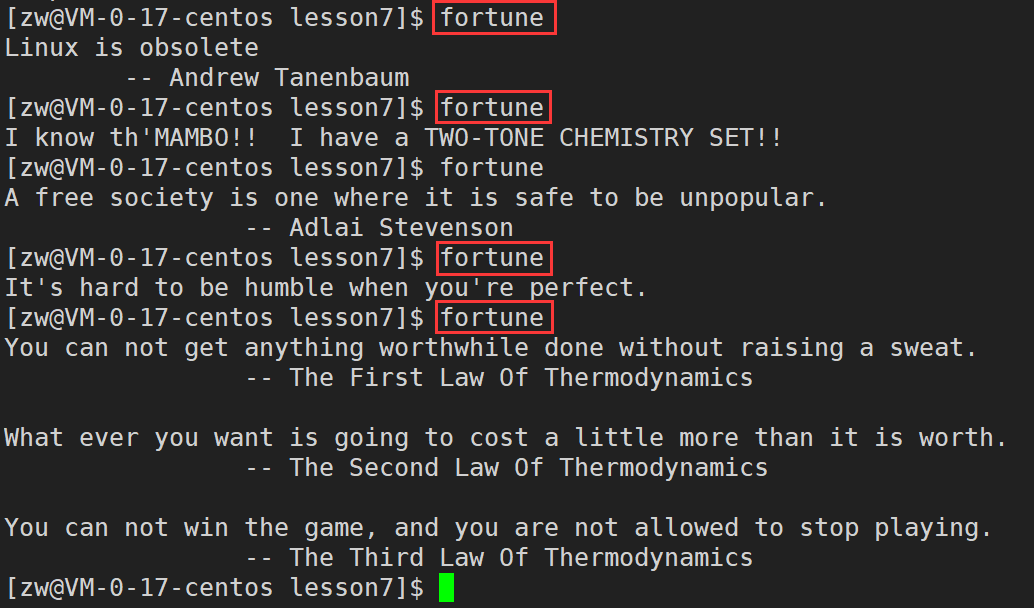
Linux ��������
Linux�³��õ���������:
| ���� | ���� |
|---|---|
| ������ | gcc / g++ |
| �༭�� | vim��vi��nano |
| ������ | gdb |
| �汾�������� | git |
�鿴���ù����Ƿ��Ѿ���װ:�鿴ÿ�������Ƿ��а汾��Ϣ
gcc --version :�鿴gcc�汾��Ϣ(ע��Ҫ��2�� - )

git --version :�鿴git�汾��Ϣ

����ܿ����汾��Ϣ,�ͱ����Ѿ���װ��,����鿴����,�ͱ�ʾ��û��װ,��װ��ʽ
sudo yum install git
Linux�༭��-vim��ʹ��
vim��ʲô?
Vim��һ��������Vi�������Ĺ���ǿ�߶ȿɶ��Ƶ��ı��༭��,��Vi�Ļ����ϸĽ��������˺ܶ����ԡ�VIM������������Vim�ձ鱻�Ƴ�Ϊ��Vi�༭������õ�һ��,��ʵ�������ľ�������Emacs�IJ�ͬ���塣1999 ��Emacs��ѡΪLinuxworld�ı��༭�������ʤ��,Vim���ӵڶ�������2000��2��VimӮ����Slashdot Beanie����ѿ���Դ�����ı��༭����,�ֽ�Emacs��������, �ܵ�����, Vim��Emacs���ı��༭���涼�Ƿdz�����ġ�

vim�Ļ�������
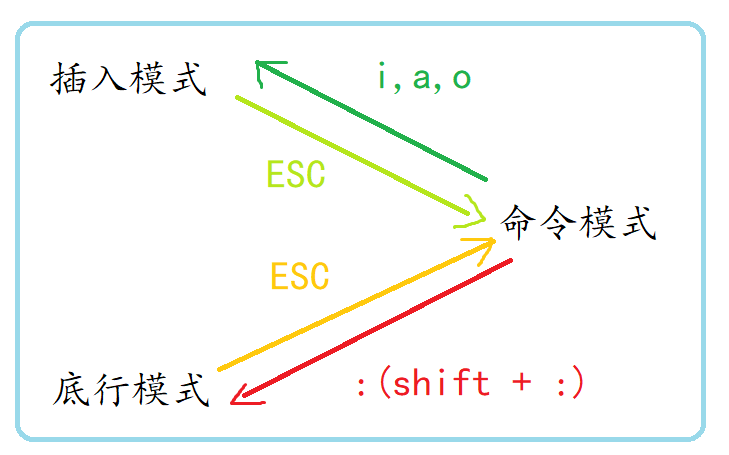
��Ȼvim�кܶ���ģʽ,��������ֻ��Ҫ��������ģʽ������,�ֱ�������ģʽ(command mode)����
��ģʽ(Insert mode)�͵���ģʽ(last line mode),��ģʽ�Ĺ�����������:
1)����/��ͨ/����ģʽ(Normal mode)
������Ļ�����ƶ�,�ַ����ֻ��е�ɾ��,�ƶ�����ij���μ�����Insert mode��,���ߵ�last line mode��
2)����ģʽ(Insert mode)
ֻ����Insert mode��,�ſ�������������,����ESC�����ɿڵ�������ģʽ����ģʽ�����Ǻ����õ���Ƶ���ı༭ģʽ��
3)����ģʽ(last line mode)
�ļ�������˳�,Ҳ���Խ����ļ��滻,���ַ���,�г��кŵȲ�����������ģʽ��,shift+: ���ɽ����ģʽ��Ҫ�鿴�������ģʽ:��vim,����ģʽֱ������
:help vim-modes
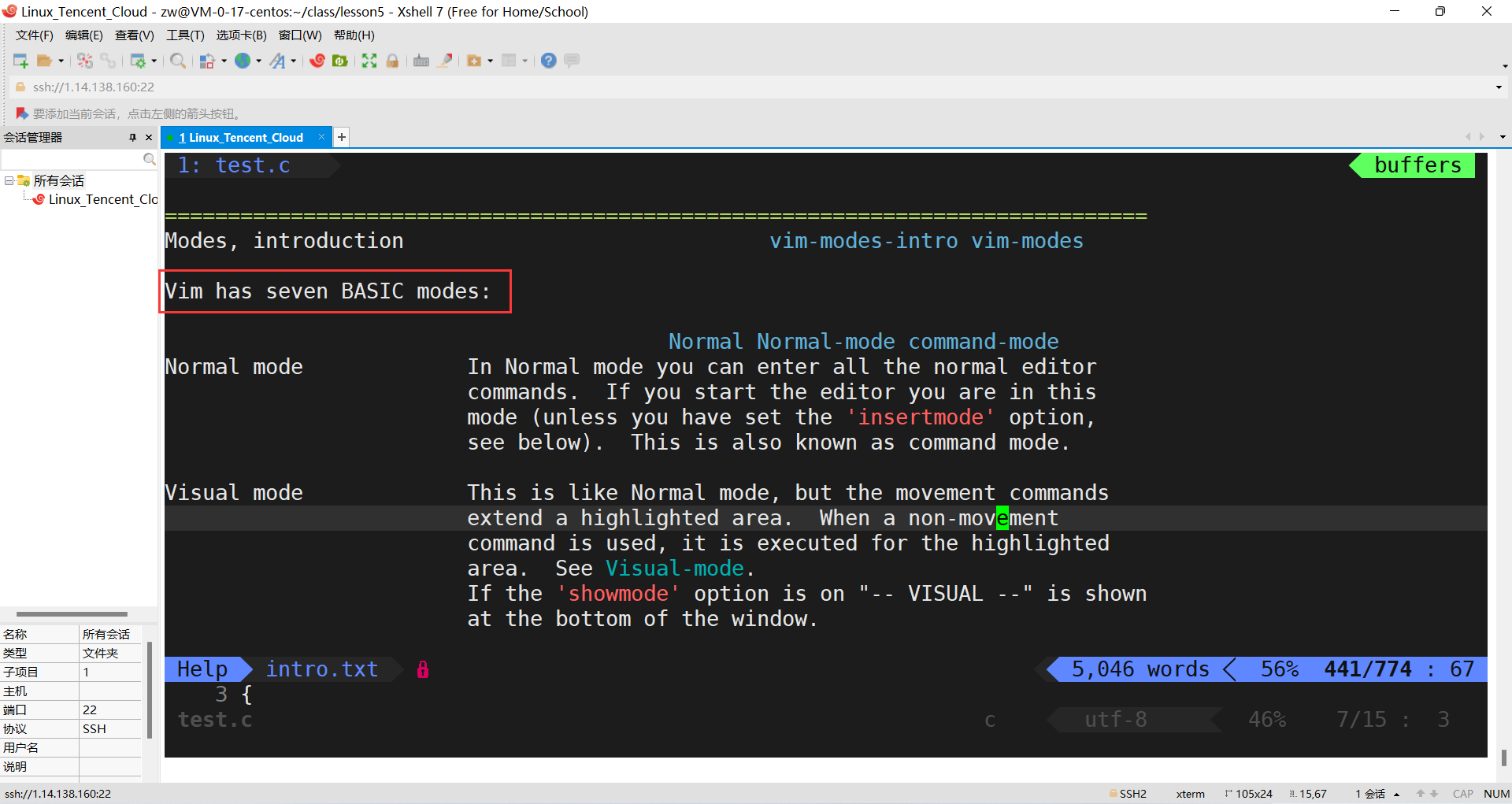
������һ����13��ģʽ:seven BASIC modes �� six ADDITIONAL modes(7�ֻ���ģʽ��6�ָ���ģʽ)
��������ʵ����ʹ�õĽ���3��,��Ҫ���Ի���!
vim�Ļ�������
1)����vim,��ϵͳ��ʾ��������vim���ļ����ƺ�,�ͽ���vimȫ��Ļ�༭����:
vim test.c
������һ��Ҫ�ر�ע��,���ǵ����ǽ���vim֮��,�Ǵ���[����ģʽ],Ҫ�л���[����ģʽ]���ܹ��������֡�
2)[����ģʽ]�л���[����ģʽ]
������a
������i
������o
3)[����ģʽ]�л���[����ģʽ]
Ŀǰ����[����ģʽ],��ֻ��һֱ��������,��������������,���ù��������ƶ�,������ɾ��,��
���Ȱ�һ�¡�ESC����ת��[����ģʽ]��ɾ�����֡���Ȼ,Ҳ����ֱ��ɾ����
4)[����ģʽ]�л���[����ģʽ]��
��shift +;��,��ʵ�������롸:��
5)�˳�vim�������ļ�,��[����ģʽ]��,��һ�¡�:��ð�ż�(��shift +;��)���롸Last line mode��
����:
:w//(���浱ǰ�ļ�)
:wq//(���롸wq�� ,���̲��˳�vim):q!(����q!,������ǿ���˳�vim)
�Dz��ǿ����е���,�ҸսӴ���ʱ��Ҳ����,���Ծͻ���һ��ͼ,Ȼ����Xshell������ü��ξͲ����ˡ�
����ͼ��ʾ��

vim����ģʽ���
��ϰ��ʾ:����������Ƚ϶�,����Ҫȫ��������,ֻ��Ҫ����ʵ��ʹ�ü�סһЩ���õľ�ok��,����ο�˼ά��ͼ,�����г����ľ��dz��õĺ��ص�ġ�
����ģʽ
1)����i���л��������ģʽ��insert mode��,��"I"�������ģʽ���Ǵӹ�굱ǰλ�ÿ�ʼ�����ļ���
2)����a���������ģʽ��,�Ǵ�Ŀǰ�������λ�õ���һ��λ�ÿ�ʼ�������֡�
3)����o���������ģʽ��,�Dz����µ�һ��,������ʼ�������֡�
�Ӳ���ģʽ�л�Ϊ����ģʽ
����ESC����
�ƶ����
1)vim����ֱ���ü����ϵĹ�������������ƶ�,�������vim����СдӢ����ĸ[h]��[j] ��[k��[l](��������)
�ֱ���ƹ�����¡��ϡ�����һ���䷽��:h������߱�ʾ��,l�����ұ߱�ʾ��,j(jump��,����ȥ,��ʾ��)k(king,��������һ���߸����ϵ�����,��ʾ��)��
2)����G��:�ƶ������µ����
3)����$��:�ƶ�����������еġ���β����
4)����^��:�ƶ�����������еġ����ס���
5)����w���U��������¸��ֵĿ�ͷ��
6)����e�� :��������¸��ֵ���β��
7)����b��:���ص��ϸ��ֵĿ�ͷ��
8)����#l��:����Ƶ����еĵ�#��λ��,��:5l,56I��
9)��[gg]:���뵽�ı���ʼ��
10)��[shift +g]�U�����ı�ĩ�ˡ�
11)����ctrl] +��b��:��Ļ��"����ƶ�һҳ��
12)����ctrl]+[f�U��Ļ����ǰ"�ƶ�һҳ��
13)����ctrl�� +��u���U��Ļ��"���ƶ�ҳ��
14)����ctrl�� + ��d�� :��Ļ��ǰ"�ƶ���ҳ��
ɾ������
1)��x��:ÿ��һ��,ɾ���������λ�õ�һ���ַ���
��#x���U����,��6x����ʾɾ���������λ�õ�"����(�����Լ�����)"6���ַ���
2)��X��:��д��X,ÿ��һ��,ɾ���������λ�õġ�ǰ��"һ���ַ���
��#X���U����,��20X]��ʾɾ���������λ�õġ�ǰ��"20���ַ���
3)[dd]:ɾ����������С�
[#dd]:�ӹ�������п�ʼɾ��#�С�
����
1) [yw��:���������֮������β���ַ����Ƶ��������С�
��#yw��:����#���ֵ���������
2)[yy]:���ƹ�������е���������
��#yy|:����,��6yy����ʾ�����ӹ�����ڵĸ���"������"6�����֡�
3)[p]:���������ڵ��ַ������������λ�á�
ע��:�����롯y"�йصĸ������������"p"��ϲ�����ɸ�����ճ�����ܡ�
�滻
1)[r]:�滻������ڴ����ַ���
2)[R]:�滻�������֮�����ַ�,ֱ�����¡�ESC����Ϊֹ��
�����ϡ��β���
1)[u]:���������ִ��һ��������,�������ϰ��¡�u��,�ص���һ��������
�����"u"����ִ�ж�λظ���
2)[ctrl+ r]�U�����Ļָ�,Ҳ�ͶԳ����ij�����
����
1)��cw�� :���Ĺ�����ڴ����ֵ���β��
��c#w��:����,��c3w����ʾ����3����
����ָ������
1)[ctrl+g]�г���������е��кš�[��Ҫ]
2)��#G��:����,��15G��,��ʾ�ƶ���������µĵ�15�����ס�
vim����ģʽ���
��ʹ�õ���ģʽ֮ǰ,���ס�Ȱ���ESC����ȷ�����Ѿ���������ģʽ,�ٰ���:��ð�ż��ɽ������ģʽ��
�г��к�
1)��[set nu��:���롸set nu����,�����ļ��е�ÿ����ǰ���г��кš�
�����ļ��е�ijһ��
1)��#���U��#���ű�ʾһ������,��ð�ź�����һ������,�ٰ��س����ͻ�����������,����������15,
�ٻس�,�ͻ��������µĵ�15�С�
�����ַ�
1)��/�ؼ��֡��U�Ȱ�������,������������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�����Ҫ��,����һֱ��
��n��������Ѱ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
2)��?�ؼ��֡��U�Ȱ�����?����,������������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�����Ҫ��,����һֱ����n������ǰѰ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
3)����:/��?�����к�����?����Ȥ��С�������Լ����ֲ���ʵ��һ�¡�
�����ļ�
1)��w��:��ð�ź���������ĸ��w���Ϳ��Խ��ļ���������
�뿪vim
1)��q��:��[q](quit)�����˳�,������뿪vim,�����ڡ�q�����һ����!��ǿ���뿪vim,Ҳ����[q!]��
2)��wq��:һ�㽨���뿪ʱ,���䡸w��һ��ʹ��,�������˳���ʱ���Ա����ļ���
vim�����ܽ�
����ģʽ
����ģʽ������ģʽ������ģʽ
����һ����13��ģʽ,��Ҹ���Ȥ�����Լ��о�һ��
vim����
��,�ر�,�鿴,��ѯ,����,ɾ��,�滻,����,���ƵȲ�����
��vim����[��չ]
����ܰ��ʾ��
������������Ȥ��ͬѧ���Կ�һ��,û����Ȥ��ͬѧ����ֱ������һ������vim������,��������ģʽ~
�����ļ���λ��
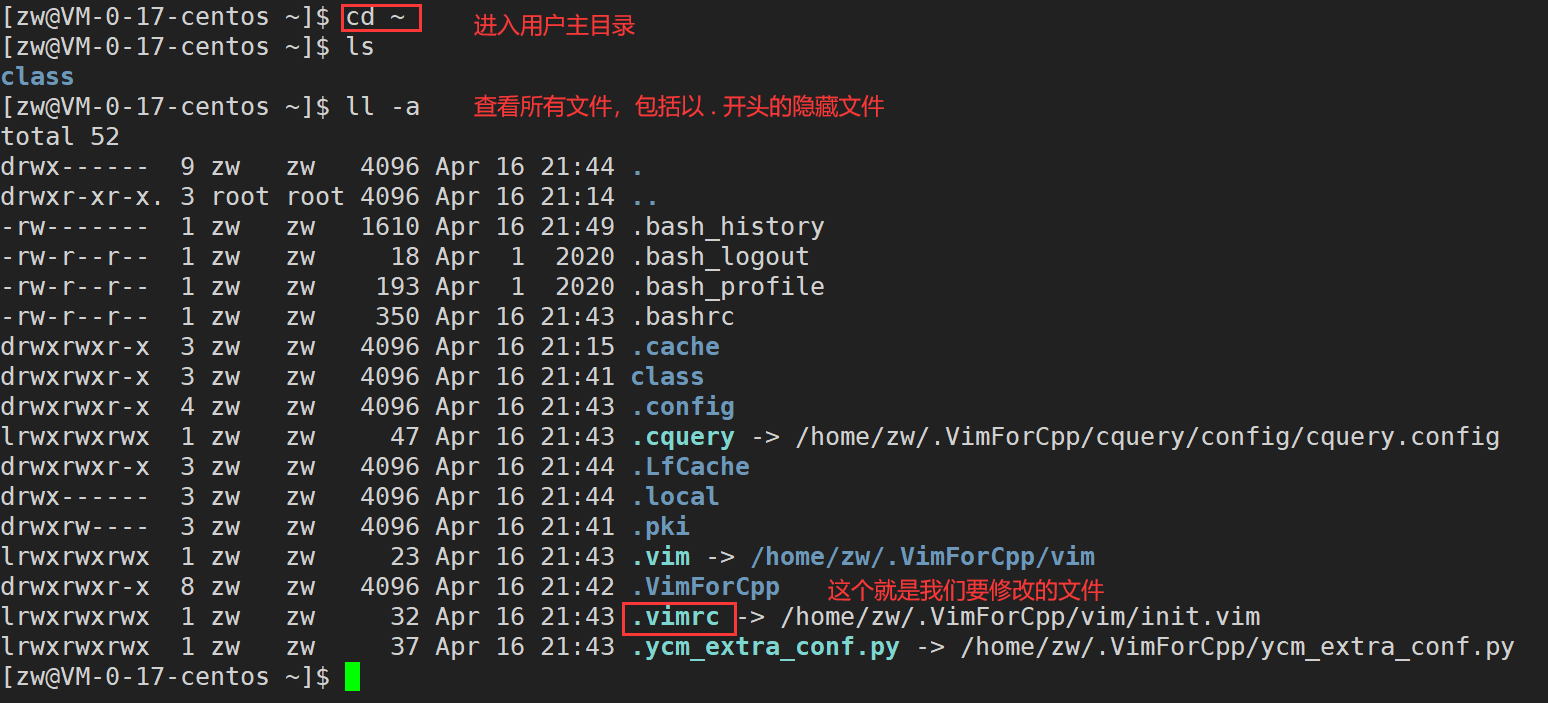
1)��Ŀ¼/etc/����,�и���Ϊvimrc���ļ�,����ϵͳ�й�����vim�����ļ�,�������û�����Ч��
2)����ÿ���û�����Ŀ¼��,�������Լ�����˽�е������ļ�,����Ϊ:��.vimrc��������:./rootĿ¼��,ͨ���Ѿ�����һ��.vimrc�ļ������������,��ô������Ҫ�Լ���������(������IJ���)
3)�����Լ���������Ŀ¼,ִ��cd~(ע�ⲻҪʹ��root�û�)
4)���Լ�Ŀ¼�µ�.vimrc�ļ�,ִ��vim .vimrc
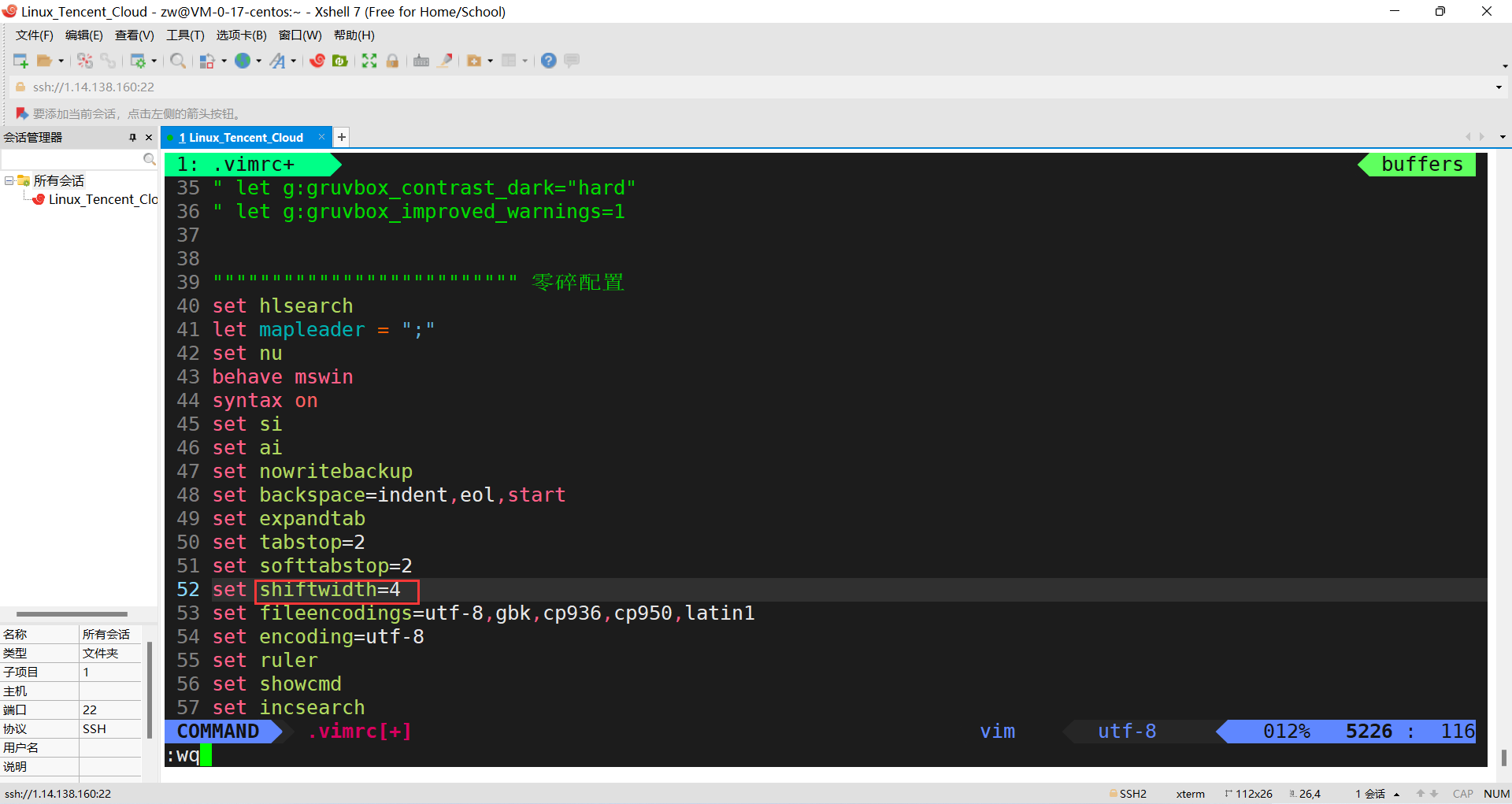
��������ѡ��,��������
1)���������: syntax on
2)��ʾ�к�: set nu
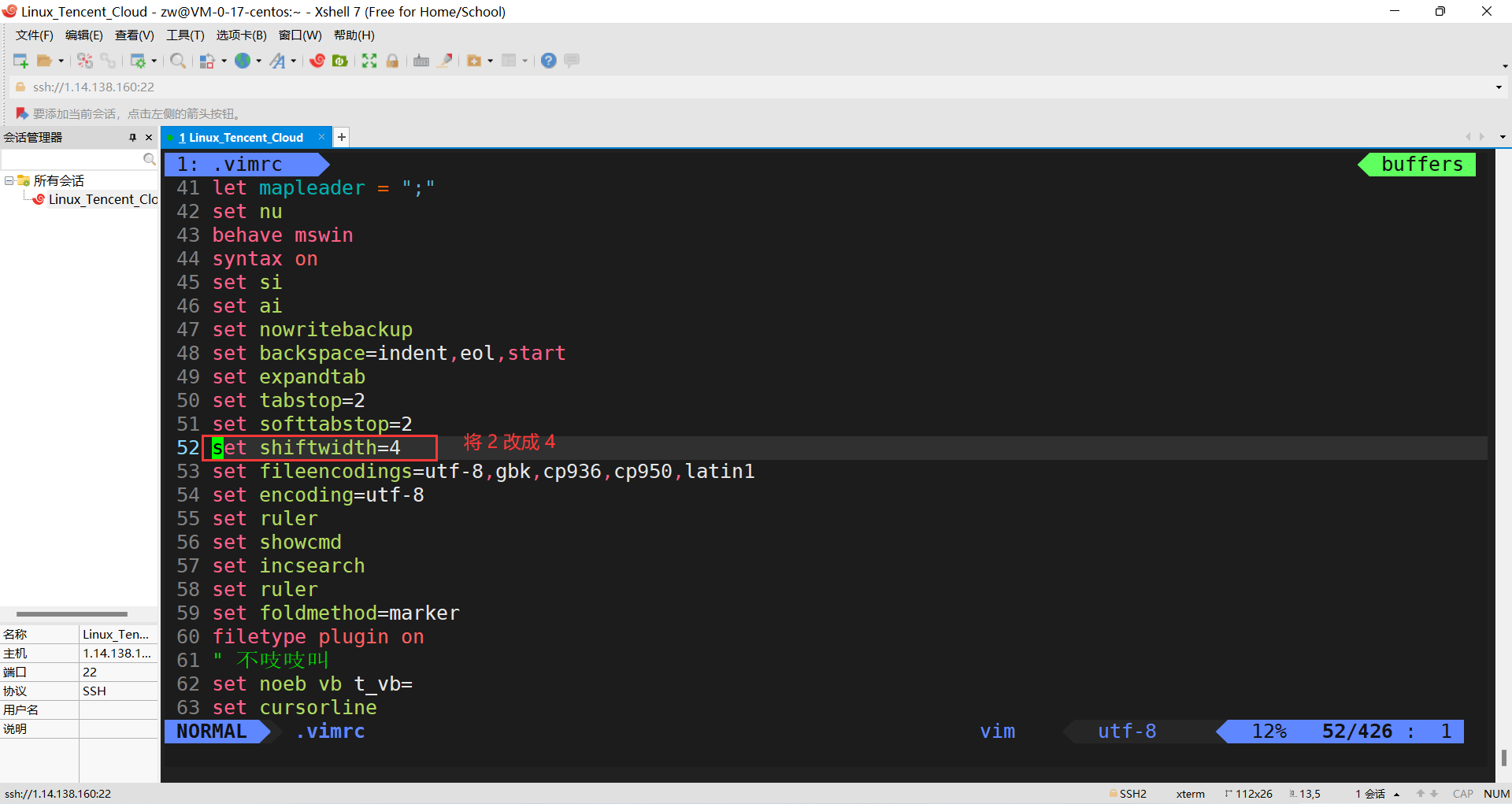
3)���������Ŀո���Ϊ4: set shiftwidth=4
ʹ�ò��
Ҫ���úÿ���vim,ԭ�������ÿ��ܹ��ܲ�ȫ,����ѡ��װ�������������,��֤�û�������Ҫ���õ��û�,������:
1)��װTagList���,����taglist_xx.zip ,��ѹ���,����ѹ������doc�����ݷŵ�/.vim/doc,����ѹ������plugin�µ����ݿ�����/.vim/plugin
2)��~ .vimrc������:let Tlist show_one_Fjte 1 let Tlist_Exit_onlywindow=1 letTlist_use_Right_window=1
3)��װ�ļ�������ʹ��ڹ��������: WinManager
4)����winmanager.zip,2.X�汾���ϵ�
5)��ѹwinmanager.zip,����ѹ������do c�����ݷŵ�~l.vim/doc,����ѹ������plugin�µ����ݿ�����~/.vim/plugin
6)��~ /.vimrc������let g :winManagerwindowLayout='FileExplorer|TagList nmap wm: wMToggle<cf
Ȼ������vim,��XXX.c��/XXX.cpp,��normal״̬������"wm",�㽫������ͼ��Ч����
�������Ʋ�:����,�����ֲ�,��ִ��vimtutor���
��������Щ�������ǿ��Կ���,���Ҫ���ǰ����Ͱ��Լ�ȥ����vim�����Ƿdz��dz��鷳��,û�м���Ĺ���������ò�����������Ҫ��Ч��,�����п�Դ�Ĵ���,����������������н���ķ���~
vim�������á�һ������ר��(����ʡ,ǿ���Ƽ�)
gitee������Դvimforcpp
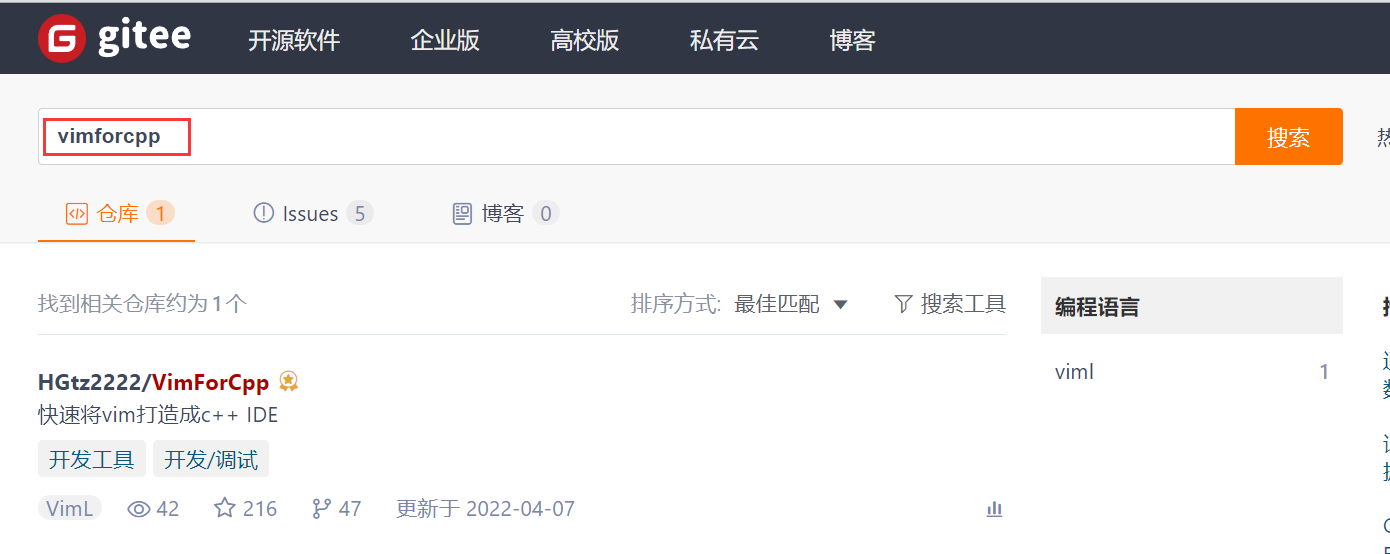
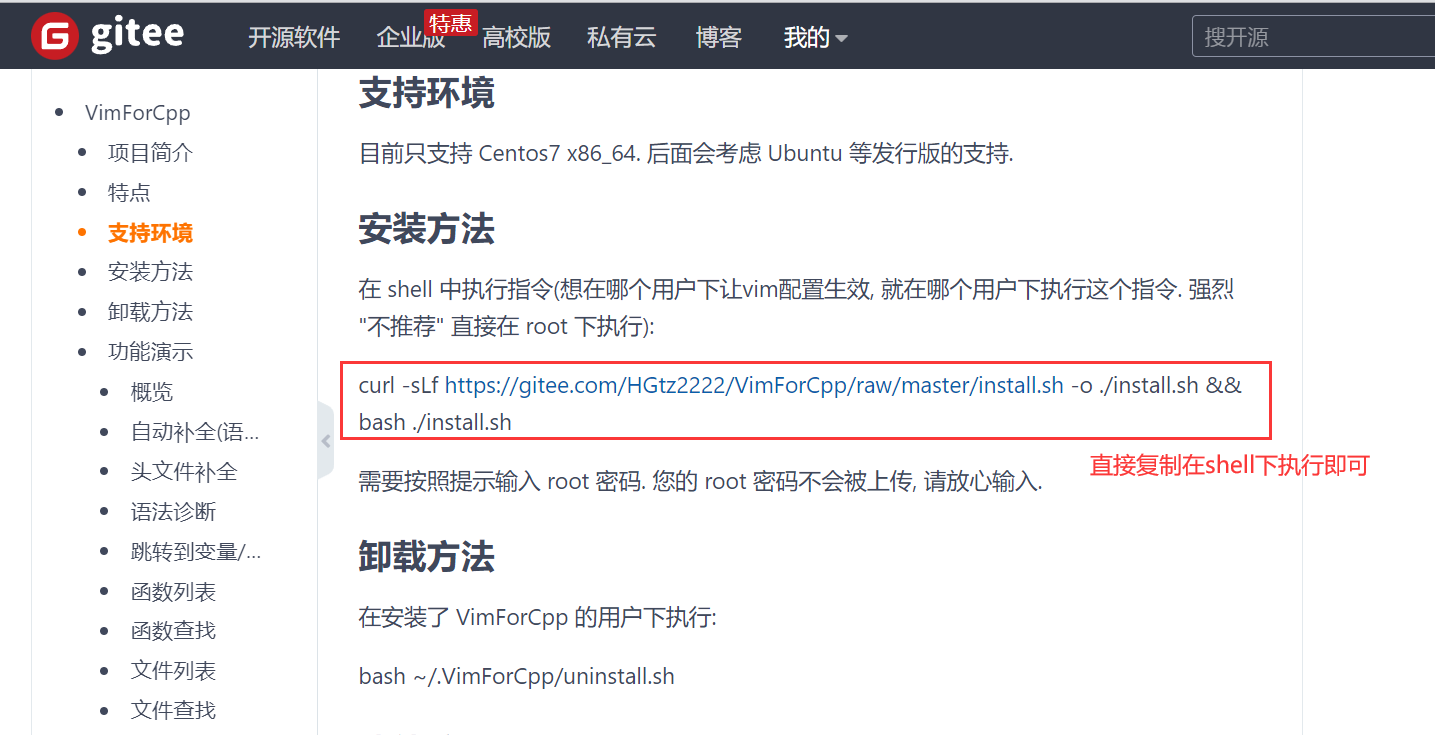
��ʾ:������粻��,���ص�ʱ����Ҫ��һС��,���ؽ�����,����ʾ�������سɹ�����Ҫ���ǽ����ֶ���������������vim
��ʼ����:
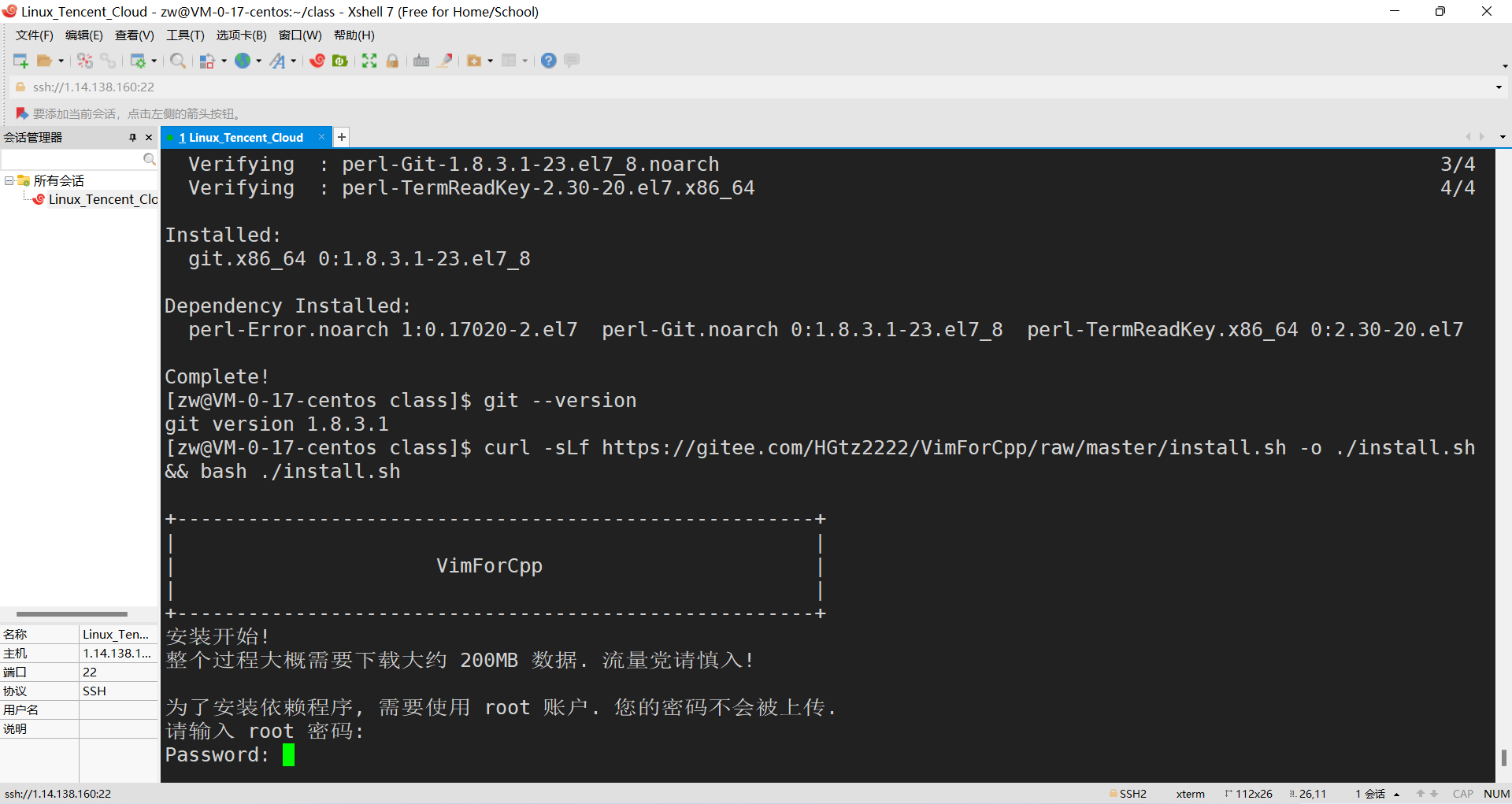
�������:
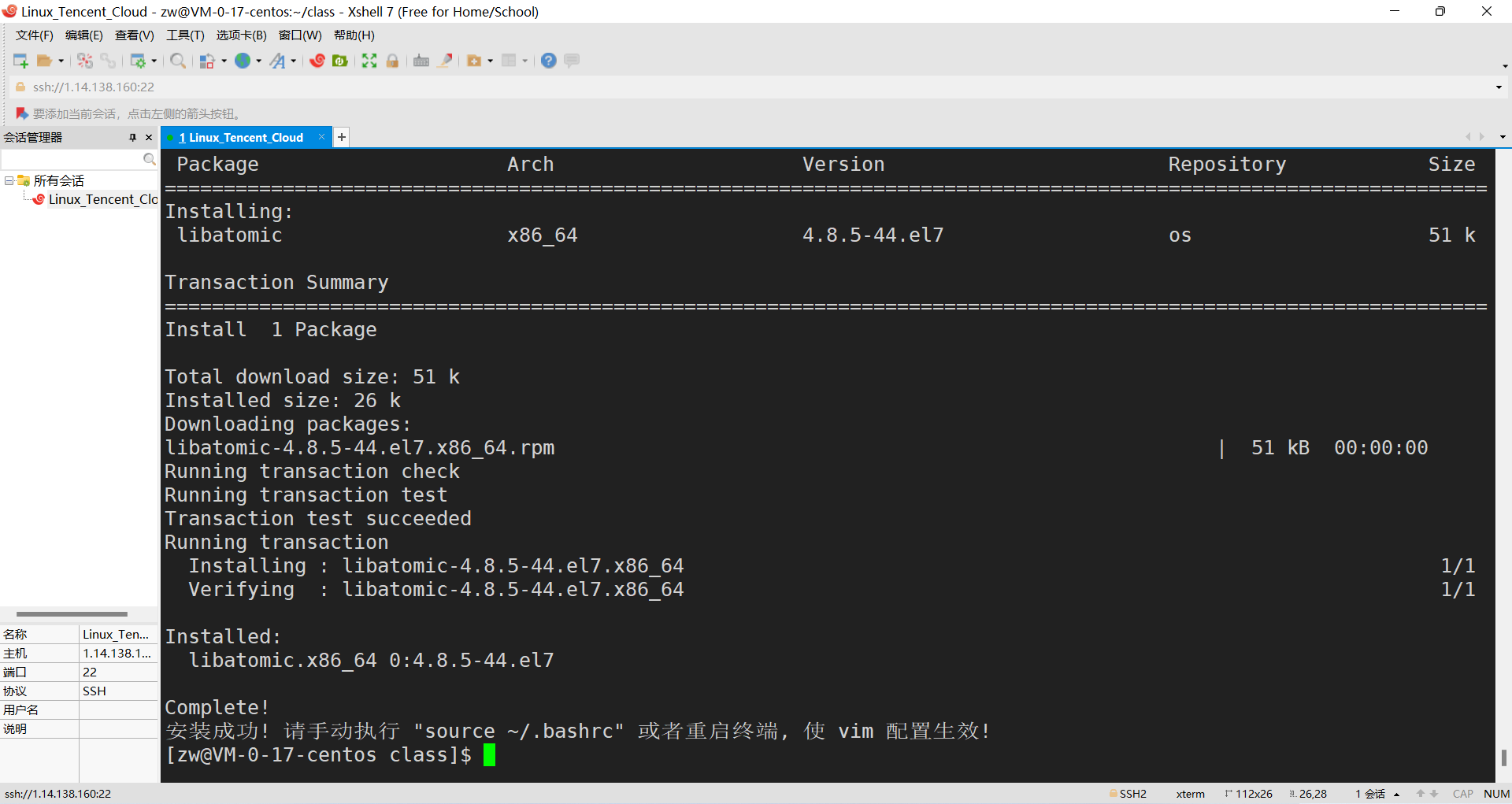
���ijЩ���ò�ϲ��,�ȷ�˵�оϲ��(VS��Ĭ����4���ո�,������2��),���ǿ����Լ�ͨ����.vimrc������Ӧ�����á�
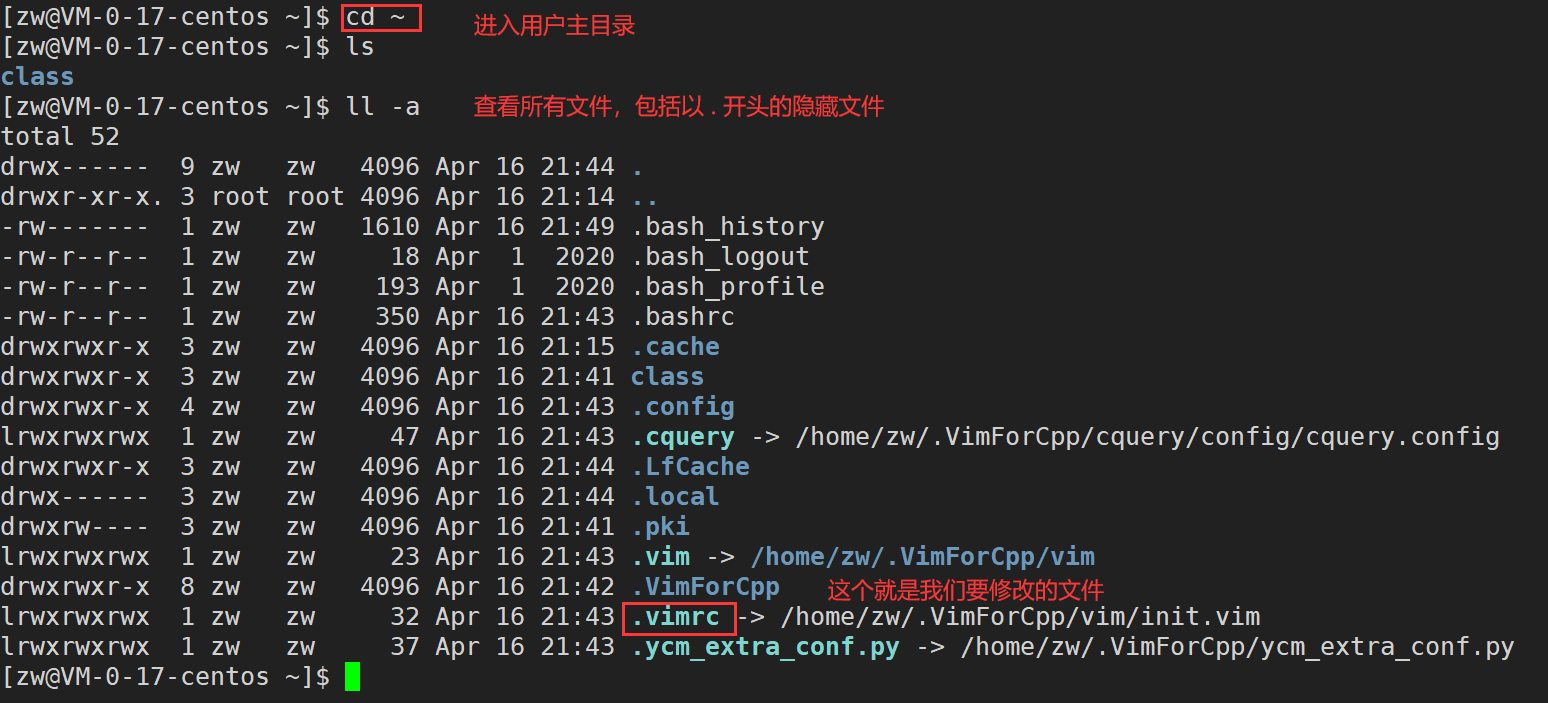
��Ч��չʾ��
vim������ⲹ��
vim ���ļ�����
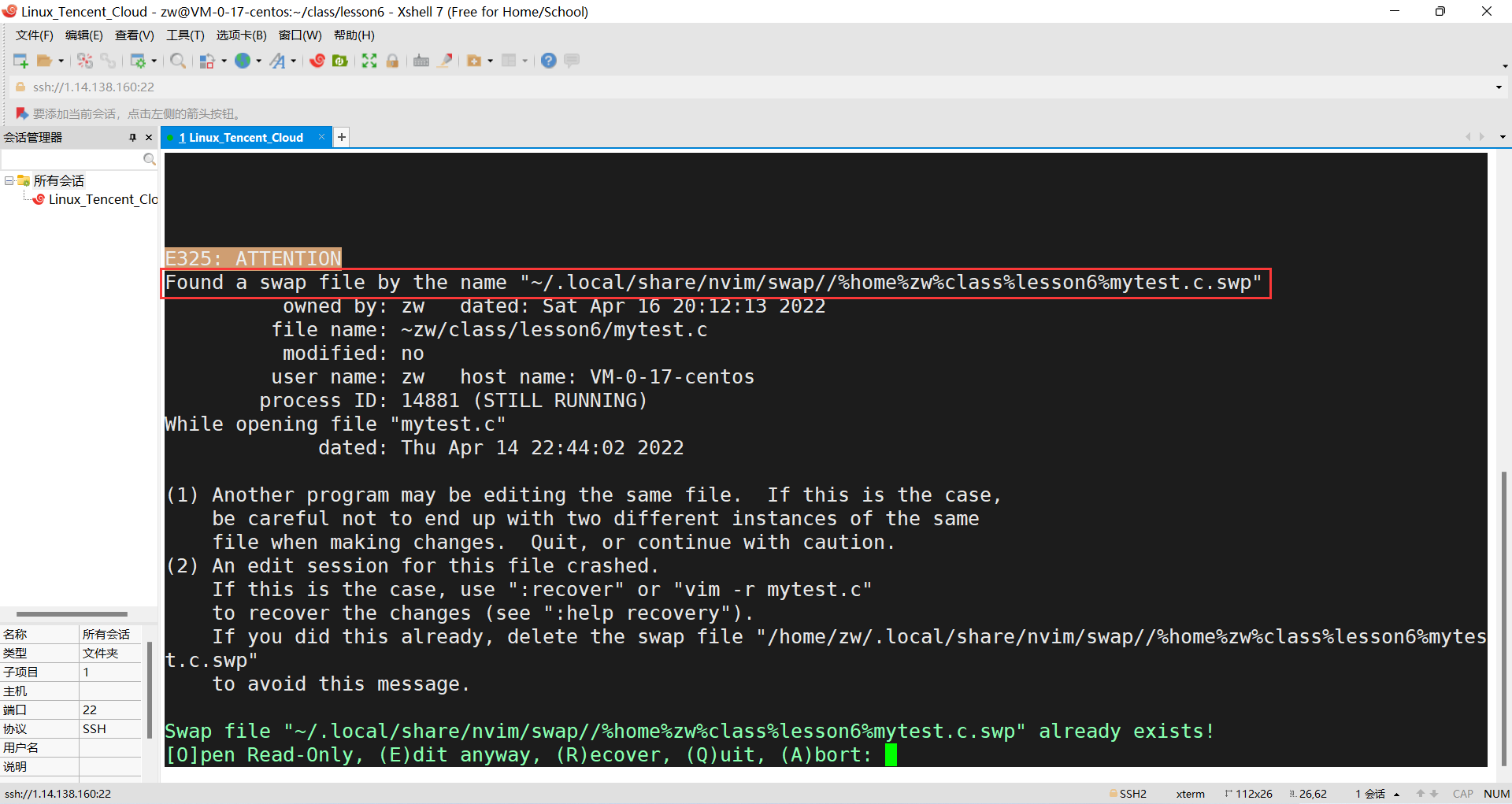
vim���ļ�,��ʵÿ�ζ��Ǵ�һ����ʱ�ļ�,��Ϊ�м佻���ļ�,Ȼ��ر�Դ�ļ�,�༭�IJ����������м��ļ�����ɵ�,ֻ�������˳���:wq����ʱ��ŻὫ�ı������д�뵽Դ�ļ���,����ɾ���м��ļ�,�����м��ļ����ڵ������,�´�vim���ļ���ʱ��ͻᱨ�����档������ctrl+z�˳�mytest.c�ļ�,������.mytest.c.swp(��.��ͷ���ļ��������ļ�,��ls -a�鿴),��.mytest.c.swapɾ����,����������mytest.c�ļ�(��ʱ��,��������ļ����ܻ���.cԴ�ļ����ڵ��ļ�������,����ֱ����ls -a�鿴����rmɾ��)��
��������ļ����ڵ�ǰ�ļ�����,����Բ�ȡ�������ַ�ʽ,��·����Ϣ�ӱ�����Ϣ�и��Ƴ���,����rmɾ����

vim����ͼ

��������
Linux������-gcc/g++ʹ��
����֪ʶ
| �� | ���� |
|---|---|
| Ԥ���� | ͷ�ļ�չ�������滻���������롢ȥע��,���� xxx.i �ļ� |
| ���� | ����������������,���� xxx.s �ļ� |
| ��� | ���������ת��Ϊ�����ƻ���ָ��,���� xxx.o �ļ� |
| ���� | ��Ŀ��ģ�鼰����õĿ⺯��ģ����������,���ɿ�ִ�г���(Windows�� xxx.exe�ļ�) |
gcc ִ�и�ʽ
��ʽ:gcc [ѡ��] Ҫ������ļ���ѡ��]��Ŀ���ļ�]
Ԥ����
1)Ԥ����������Ҫ����:���滻��ͷ�ļ��������������롢ȥע�͵ȡ�
2)Ԥ����ָ������#�ſ�ͷ�Ĵ����С�eg:#include<stdio.h>
3)ʵ��:
gcc -E hello.c -o he11o.i
4)ѡ��"-E,��������gcc��Ԥ����������ֹͣ������̡�
5)ѡ��"-o"��ָҪ���ɵ�Ŀ���ļ�,��.i"�ļ�Ϊ�Ѿ���Ԥ������Cԭʼ����
����(���ɻ��)
1)���������,gcc����������Ҫ������Ĺ淶�ԡ��Ƿ���������,��ȷ�������ʵ��Ҫ���Ĺ���,�ڼ�������,gc������c��Ѵ��뷭��ɻ�����ԡ�
2)�û�����ʹ�á�-S"ѡ�������в鿴,��ѡ��ֻ���б���������л��,���ɻ����롣
3)ʵ��:
gcc -S hello.i -o hello.s
���(���ɻ�����ʶ�����)
1)�����ǰѱ�������ɵ�".s"�ļ�ת��Ŀ���ļ�
2)�����ڴ˿�ʹ��ѡ��"-c"�Ϳɿ�����������ת��Ϊ".o"�Ķ�����Ŀ�������
3)ʵ��:
gcc -c hello.s -o hello.o
����(���ɿ�ִ���ļ�����ļ�)
1)�ڳɹ�����֮��,�ͽ��������ӽΡ�
2)ʵ��:
gcc hello.o -o he1lo
�������漰��һ����Ҫ�ĸ���:������
1)���ǵ�C������,��û�ж���"printf"���ĺ���ʵ��,����Ԥ�����а�����"stdio.h"��Ҳֻ�иú���������,��û�ж��庯����ʵ��,��ô,��������ʵ"printf"��������?
2)���Ĵ���:ϵͳ����Щ����ʵ�ֶ���������Ϊ libc.so.6 �Ŀ��ļ���ȥ��,��û���ر�ָ��ʱ,gcc �ᵽϵͳĬ�ϵ�����·��**��/usr/lib"�½��в���,Ҳ�������ӵ� libc.so.6 �⺯����ȥ,��������ʵ�ֺ���"printf"��,����Ҳ�������ӵ����á�
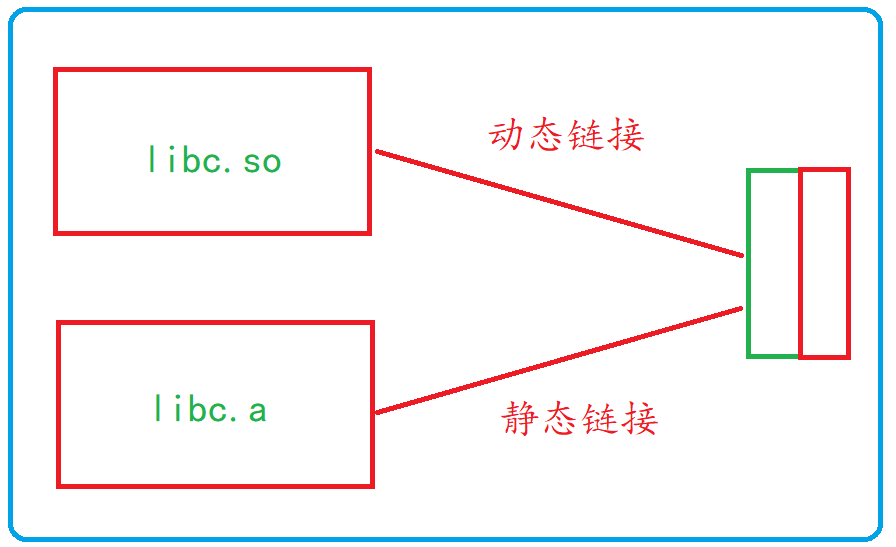
������һ���Ϊ��̬��Ͷ�̬�����֡�
1)��̬����ָ��������ʱ,�ѿ��ļ��Ĵ���ȫ�����뵽��ִ���ļ���,������ɵ��ļ��Ƚϴ�,��������ʱҲ�Ͳ�����Ҫ���ļ��ˡ������һ��Ϊ.a**��
2)��̬����֮�෴,�ڱ�������ʱ��û�аѿ��ļ��Ĵ�����뵽��ִ���ļ���,�����ڳ���ִ��ʱ������ʱ�����ļ����ؿ�,�������Խ�ʡϵͳ�Ŀ�������̬��һ�����Ϊ**.so**,��ǰ��������libc.so.6���Ƕ�̬�⡣gcc�ڱ���ʱĬ��ʹ�ö�̬�������������֮��,gcc�Ϳ������ɿ�ִ���ļ�,������ʾ��
gcc hello.o -o hello
3)gccĬ�����ɵĶ����Ƴ���,�Ƕ�̬���ӵ�,������ͨ��filee������֤��

gccѡ��
| ѡ�� | ���� |
|---|---|
| -E | ֻ����Ԥ����,�������ļ�,������Ҫ�����ض���һ������ļ�����,���� xxx.i �ļ� |
| -S | ���뵽������Բ����л������� |
| -c | ���뵽Ŀ����� |
| -o | �ļ�������ļ� |
| -static | ��ѡ������ɵ��ļ����þ�̬���� |
| -g | ���ɵ�����Ϣ��GNU�����������ø���Ϣ�� |
| -shared | ��ѡ�����ʹ�ö�̬��,���������ļ��Ƚ�С,������Ҫϵͳ�ɶ�̬��. |
| -O0 | ���������Ż�ѡ���4������,-O0��ʾû���Ż�,-O1Ϊȱʡֵ,-O3�Ż�������� |
| -O1 | |
| -O2 | |
| -O3 | |
| -w | �������κξ�����Ϣ�� |
| -Wall | �������о�����Ϣ�� |
gcc ѡ�����
Ԥ���������롢����Ӧ���� ESc(�������Ǽ��������Ͻǵļ���ʲô),���ɵ��ļ����ֱ��� iso ��(���ʱ�����֯ (International Organization for Standardization)
Linux������-gdbʹ��
����
1)����ķ�����ʽ������,debugģʽ��releaseģʽ
2)Linux gcc/g++�����Ķ����Ƴ���,Ĭ����releaseģʽ
3)Ҫʹ��gdb����,������Դ�������ɶ����Ƴ����ʱ��,���� ��-g�� ѡ��
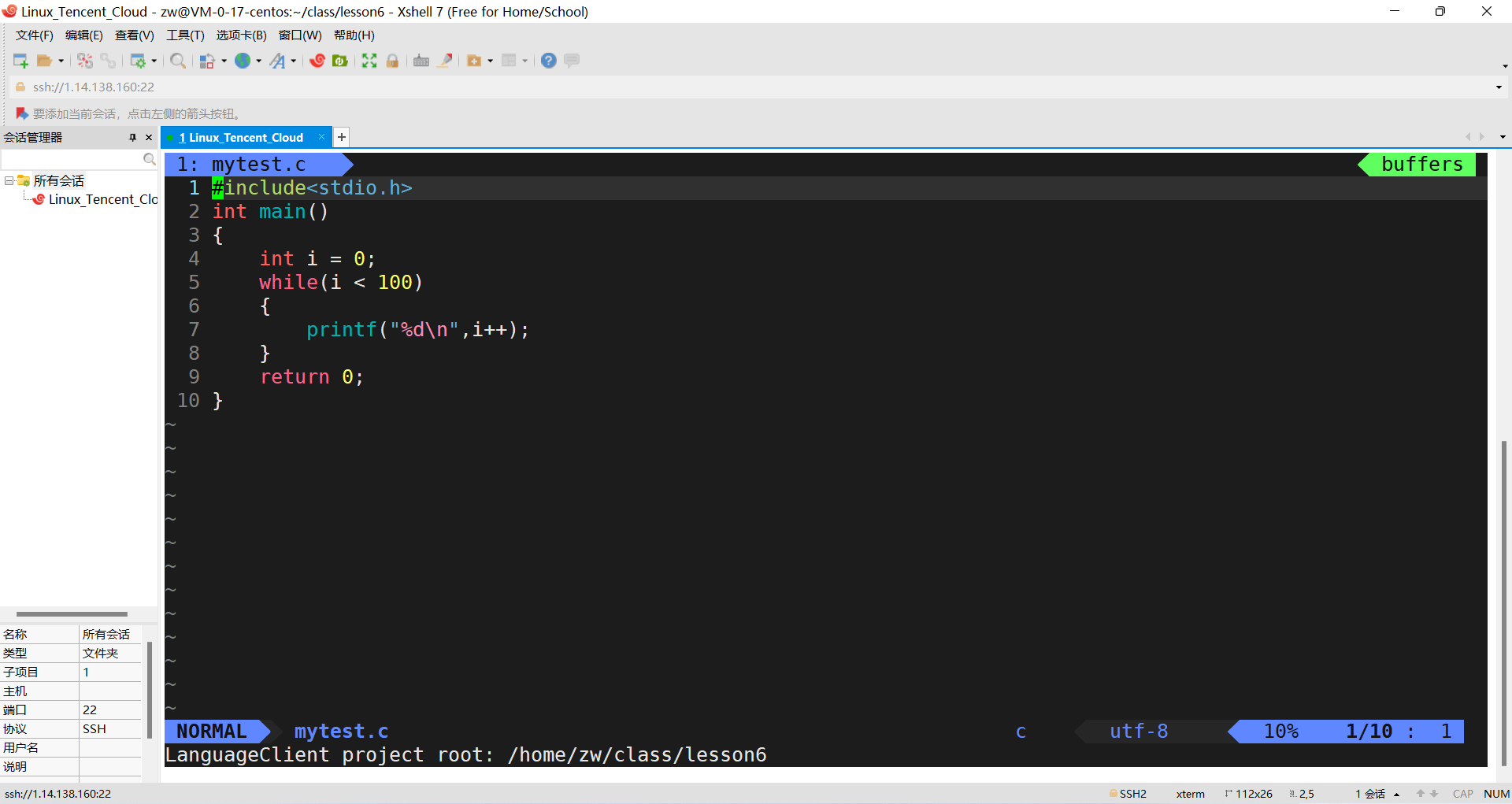
gcc -g mytest.c -o mytest.exe
���ӡ�-g��ѡ�����ɵij���,��gdb���е���,�ᷢ�������ԡ�(no debugging symbols found)
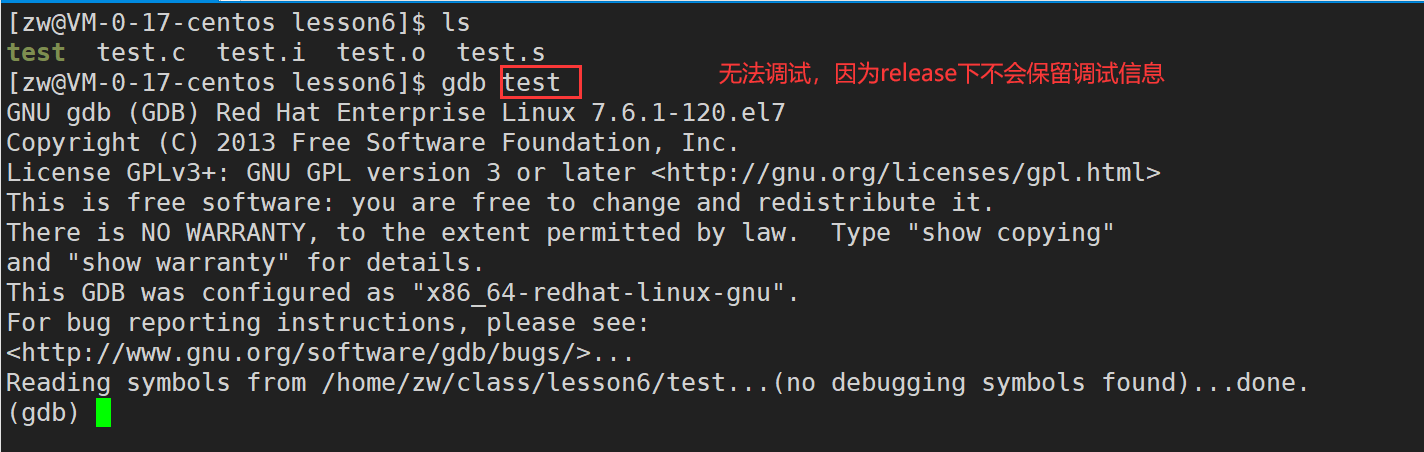
���ϡ�-g��ѡ�����ɵij���,��gdb���е���
��ʼʹ��
��������ԡ�
gdb filename //gdb + �ļ����������
//����:
gdb test_gdb//test_gdb �� gcc -g test.c -o test_gdb ���ɵ�
���˳����ԡ�
ctrl + d // �������� quit ����
list / l �к�(list���Լ�д��l):��ʾԴ�ļ���Դ������Ϣ,�����ϴε�λ��������,ÿ���г�10��
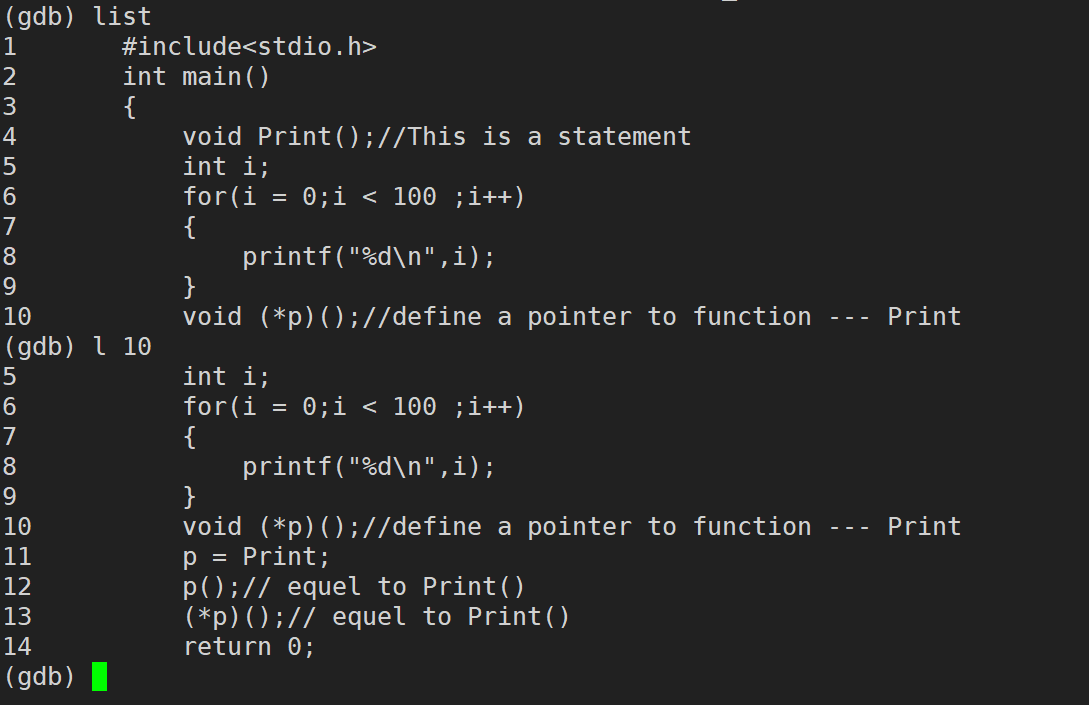
list / I ������(list���Լ�д��l):�г�ij��������Դ����
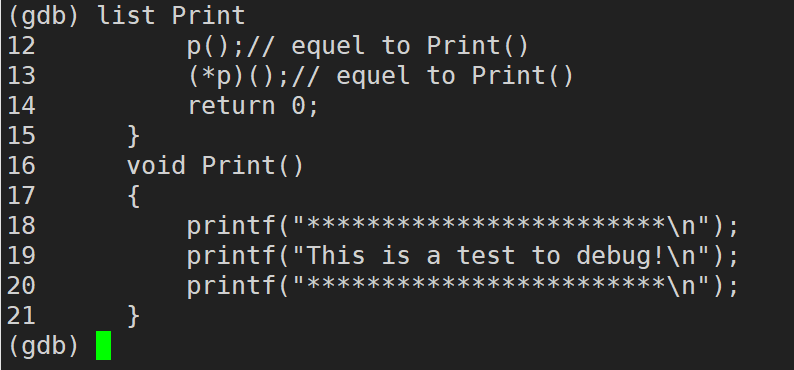
run / r (run���Լ�д��r):���г���

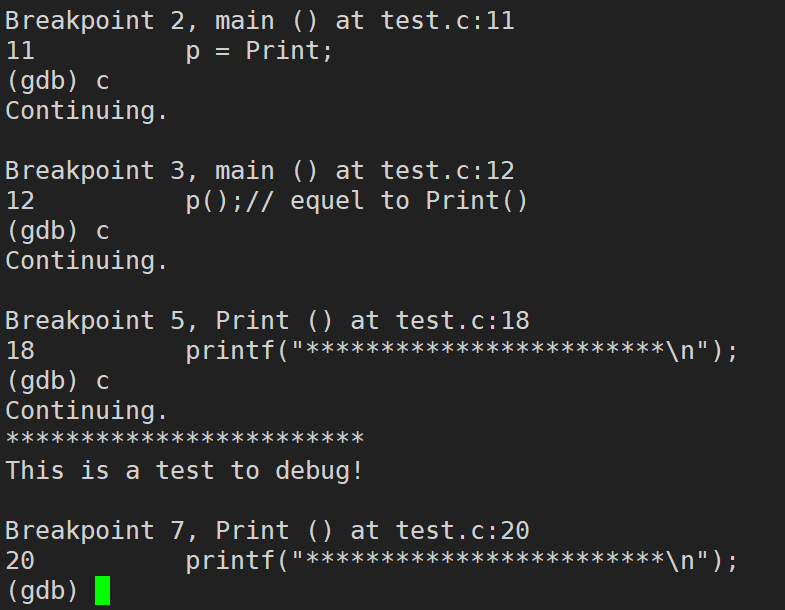
break / b �к�(break���Լ�д�� b):��ijһ�����öϵ�
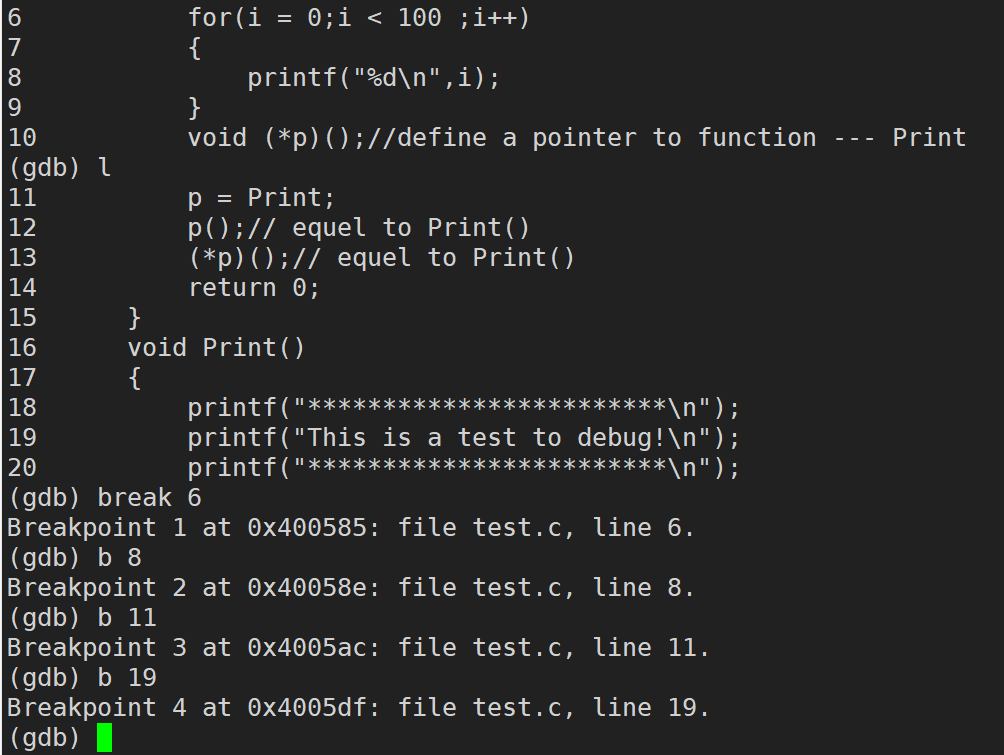
break / b ������(break���Լ�д�� b):��ij��������ͷ(��ڵ�ַ)���öϵ�
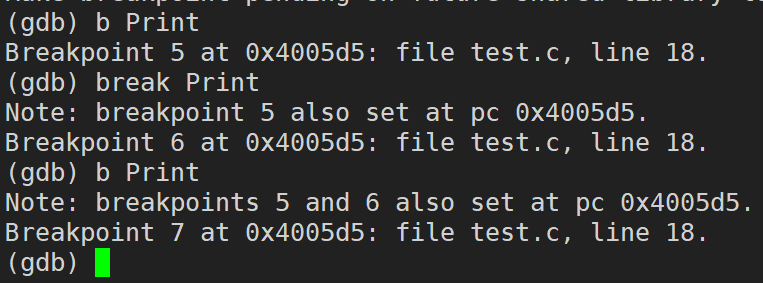
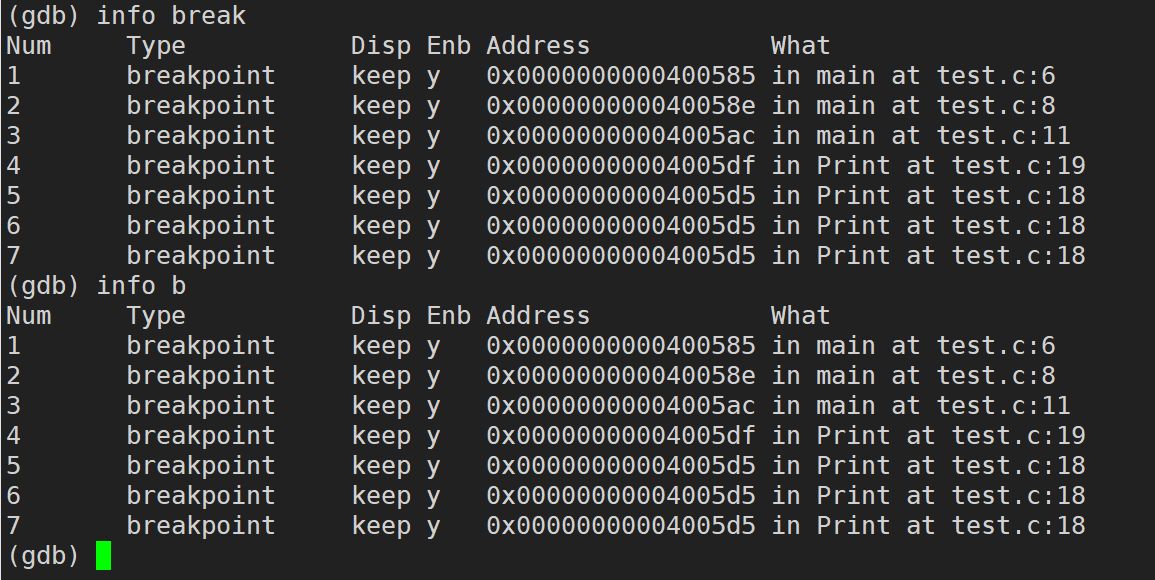
info break / b(break���Լ�д�� b) :�鿴�ϵ���Ϣ
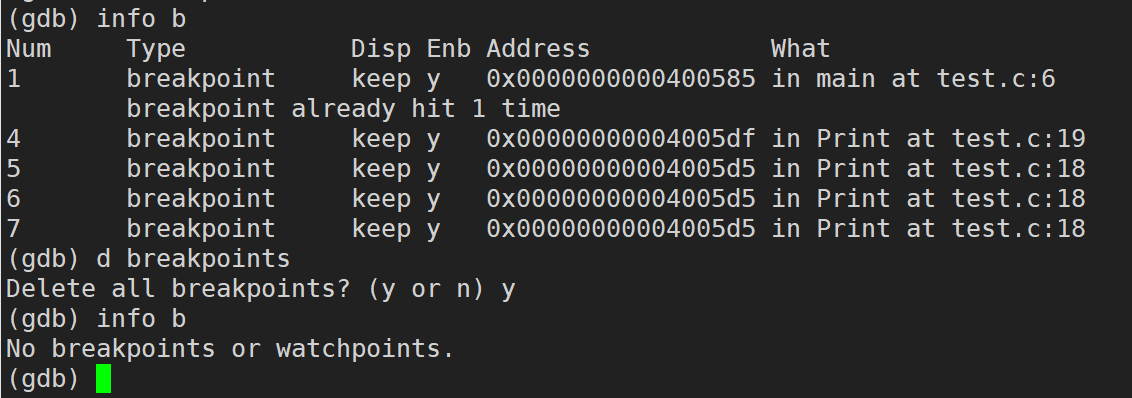
delete / d breakpoints(delete ���Լ�д�� d,breakpoints���Լ�д��break):ɾ�����жϵ�
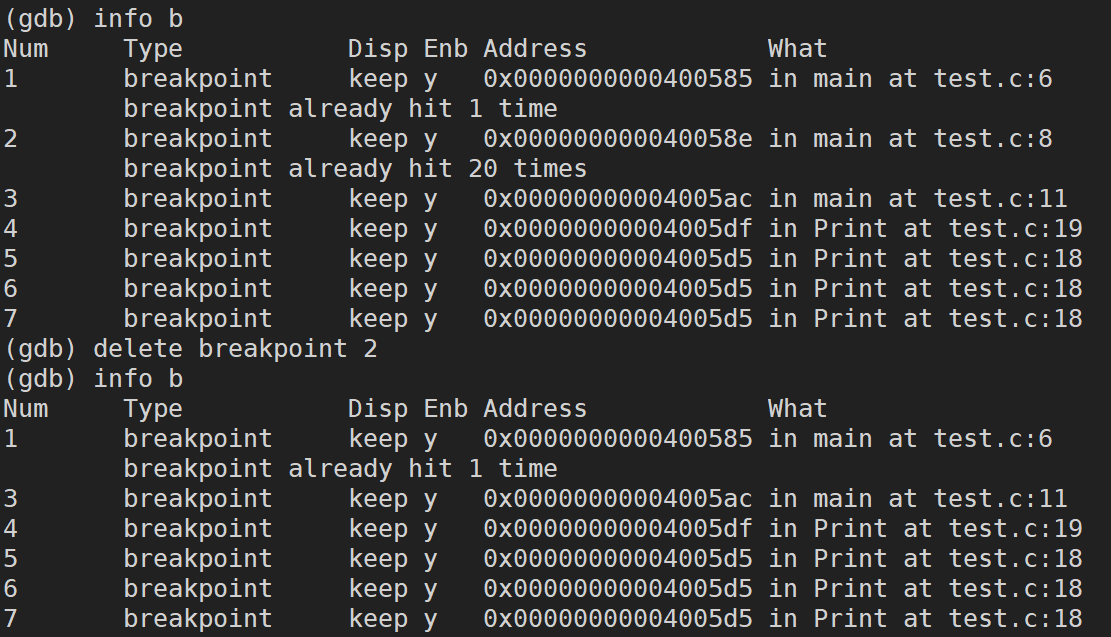
delete / d breakpoints n(delete ���Լ�д�� d,breakpoints���Լ�д��break):ɾ�����Ϊn�Ķϵ�
disable breakpoints(breakpoints���Լ�д��break):���öϵ�
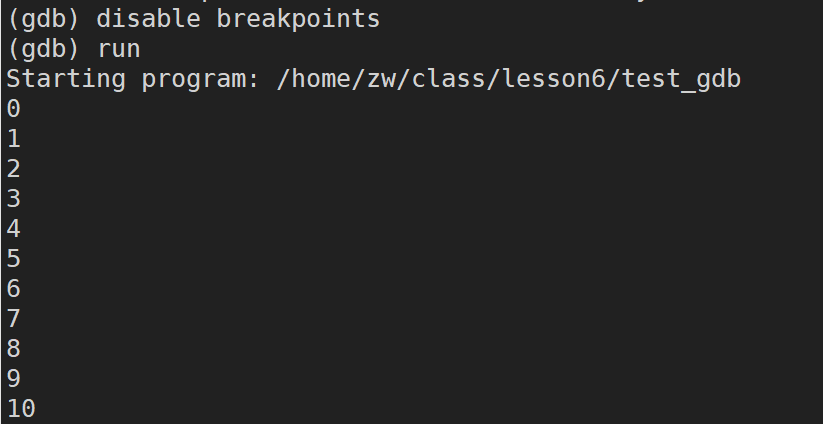
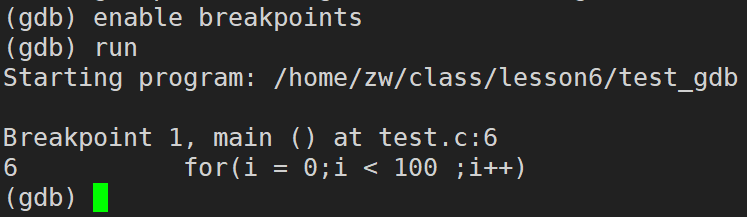
enable breakpoints(breakpoints���Լ�д��break):���öϵ�
next / n (next ���Լ�д�� n):��������,������������,�����뺯�������С�(�൱��Windows��VS�е� F10 ���� Fn + F10,��������)
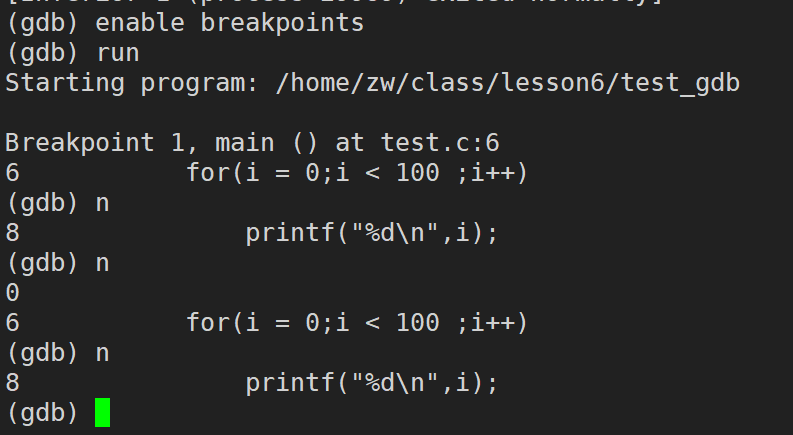
step / s (step���Լ�д��s):����̵���,������������,���뺯��������(�൱��Windows��VS�е� F11 ���� Fn + F11,����̵���)
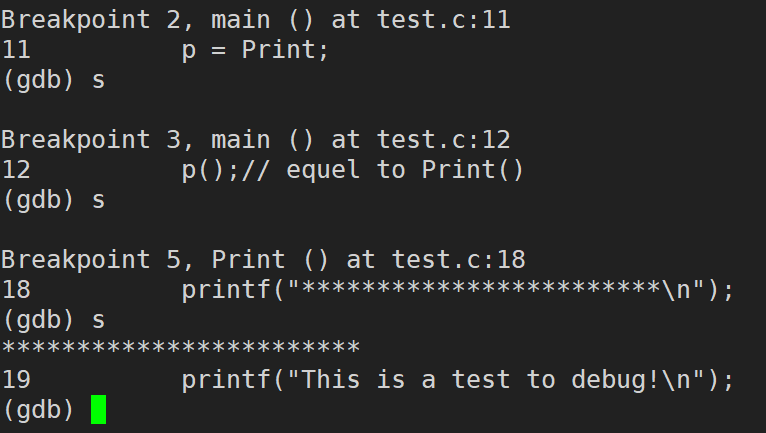
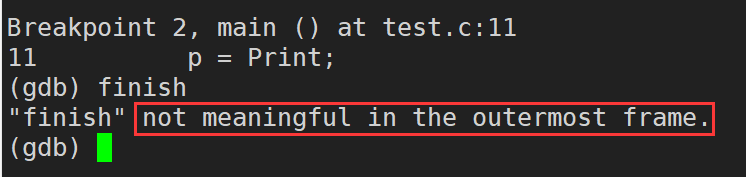
finish:ִ�е���ǰ��������,Ȼ��ȴ����finishֻ�ں��������ڲ�ִ��,��main�����в���ִ��
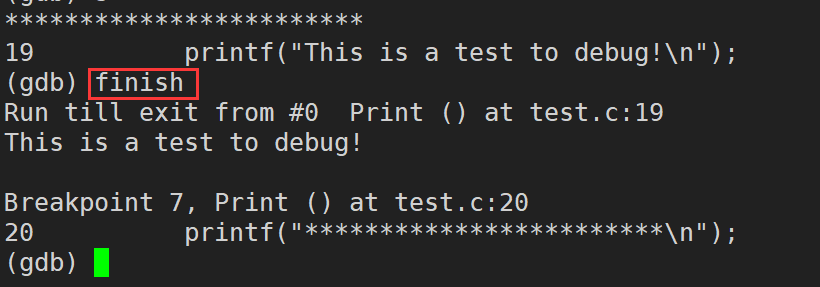
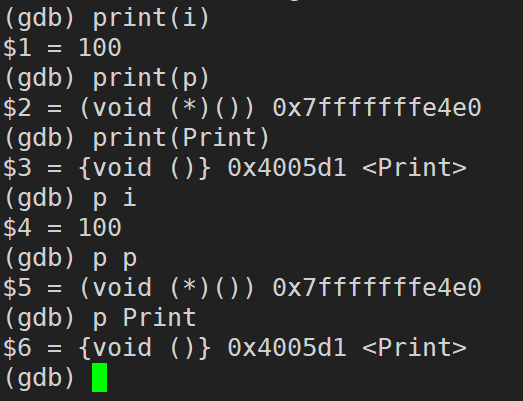
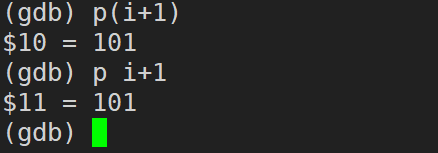
print / p (����/����ʽ) (print ���Լ�д�� p):��ӡ����/����ʽ��ֵ,ͨ������ʽ�����ı�����ֵ���ߵ��ú���
print / p ���� / ����ʽ(print ���Լ�д�� p):��ӡ����/����ʽ��ֵ,ͨ������ʽ�����ı�����ֵ���ߵ��ú���
set var ����ʽ:��(����)������ֵ
continue / c(continue���Լ�д�� c):�ӵ�ǰλ�ÿ�ʼ�������ǵ���ִ�г���(�����ϵ��ͣ��)
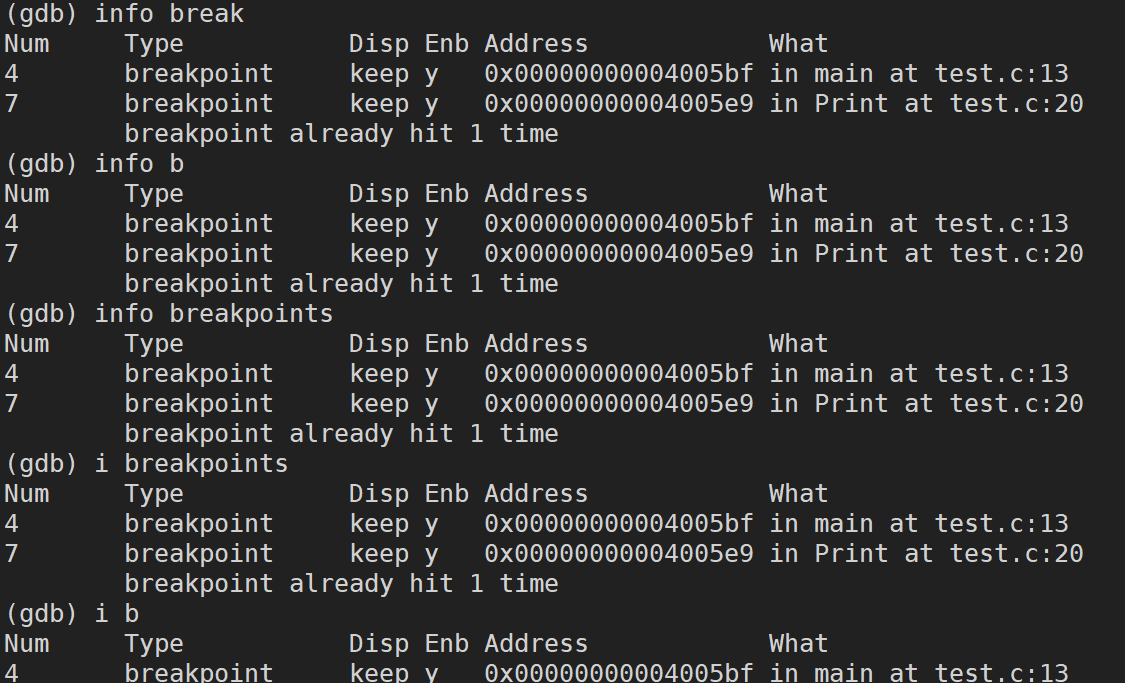
info / i (info���Լ�д�� i)breakpoint / break / b:�鿴�ϵ���Ϣ
//���¼���ָ���ǵȼ۵�
info breakpoints
info break
info b
i breakpoints
i break
i b
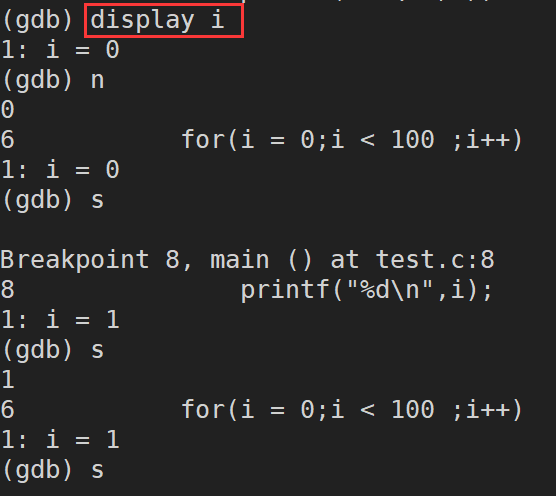
display ������:���ٲ鿴һ������,ÿ��ͣ��������ʾ����ֵ
undisplay:ȡ����ǰ���õĸ��ٲ鿴һ������
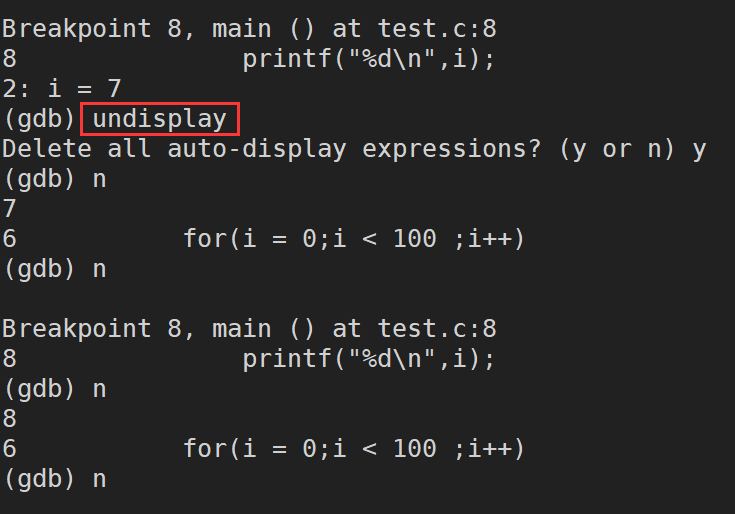
until n(��)(until ���Լ�д�� u):������n��
���������� until ����,����ʹ GDB ���������������굱ǰ��ѭ����,��������ѭ������ֹͣ��ע��,until ������κ�����¶��ᷢ���������,ֻ�е�ִ����ѭ����β��(���һ�д���)ʱ,until ����Żᷢ��������;��֮,until ����� next ����Ĺ���һ��,ֻ�ǵ���ִ�г���
(gdb) until/u
(gdb) until/u location
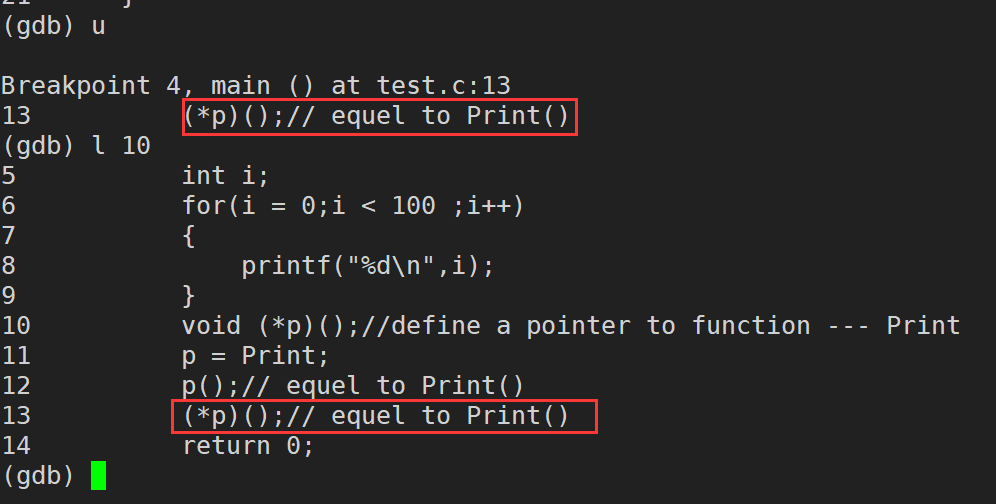
bt:�鿴�����������ü�������(ע��:bt��breaktrace�ļ��,����ֱ��ʹ��breaktraceȴ��ʶ��,���˶�����ʱûŪ��զ����~)


info / i locals(info���Լ�д��i):�鿴��ǰջ֡�ֲ�������ֵ
//ʹ�÷�ʽ
info locals//
i locals//���ַ�ʽ����
quit:�˳�gdb,Ҳ�ɰ���ݼ�ctrl + d,ʵ���ϻ�ת��Ϊquit
��������
���Ժ�Windows�����VS��������IDE(���ɿ�������)���Ա�,���м����ѧϰ
Linux��Ŀ�Զ�����������-make/Makefile
����
1)���дmakefile,��һ������˵����һ�����Ƿ�߱���ɴ����̵�����
2)һ�������е�Դ�ļ�������,�䰴���͡����ܡ�ģ��ֱ�������ɸ�Ŀ¼��,makefile������һϵ�еĹ�����ָ����Щ�ļ���Ҫ�ȱ���,��Щ�ļ���Ҫ�����,��Щ�ļ���Ҫ���±��롣�����ڽ��и����ӵĹ��ܲ���
3)makefile�����ĺô����ǨD�D���Զ���������,һ��д��,ֻ��Ҫһ��make����,����������ȫ�Զ�����,��������������������Ч��
4)make��һ�������,��һ������makefile��ָ��������,һ����˵,�������IDE��������������: Delphi��make,Visual C++��nmake,Linux��GNU��make���ɼ�,makefile����Ϊ��һ���ڹ��̷���ı��뷽����
5)make��һ������,makefile��һ���ļ�,��������ʹ��,�����Ŀ�Զ�������
��������
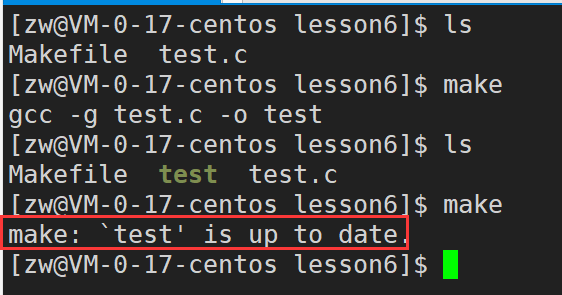
makefile�����ڴ��Ŀ���ļ���Դ�ļ�֮��������ϵ,�Լ����������������
�ȷ�˵������gcc��test.c�ļ�����Ϊtest�ļ�����ôtest.c����Դ�ļ�,test��������Ҫ���ɵ�Ŀ���ļ���
gcc test.c -o test
Ŀ���ļ�testҪ������Ҫ��������Դ�ļ�test.c,���test.c������,��ô��������Ŀ���ļ�test�������Ŀ���ļ���Դ�ļ���һ��������ϵ(����˵:�������������)
����,����������ϵ���Dz�����,������ָ�����������������ʲô,�����������������:
gcc test.c -o test //������䱾��������������,ͨ��gcc����test.c �� -o ����test�ļ�

ʵ������
��test.c�ļ���
#include<stdio.h>
int main()
{
void Print();//This is a statement
int i;
for (i = 0; i < 100; i++)
{
printf("%d\n", i);
}
void (*p)();//define a pointer to function --- Print
p = Print;
p();// equel to Print()
(*p)();// equel to Print()
return 0;
}
void Print()
{
printf("************************\n");
printf("This is a test to debug!\n");
printf("************************\n");
}
��Makefile�ļ���
touch Makefile // �ȴ���Makefile�ļ�,Ҳ��������Ϊmakefile
vim Makefile //����Makefile�ļ��н��б༭
test:test.c//��ʾtestĿ���ļ�������test.cԴ�ļ�
gcc -g test.c -o test//�������������,ʵ���Ͼ���Ŀ���ļ�test�����ɷ�ʽ,����tab����ͷ
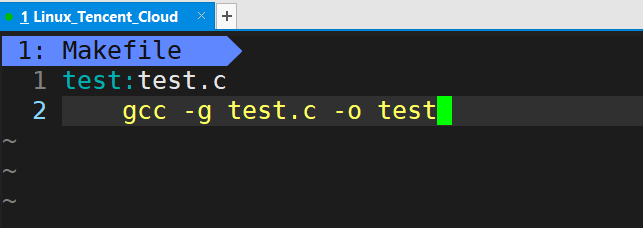
ע��:��Makefile���������������,���ױ���Ҫ��tab������������,�������ĸ��ո�������,��Ȼ���߿��������ı�Ч����һ����,���DZ������Dz�ͬ��,tab�ᱻ����Ϊ��\t�������˲²�:��Ϊ������ϵȷ����������ʱ,��ȥ��������ϵ����ġ�\t��,�ҵ���,�����һ������������������
���������Ҫɾ��test�ļ�,��ô������Makefile����������һ�����
.PHONY:clean //Phony:α���,������.PHoNY:clean������һ��αĿ��clean
clean:
rm -f test //ע����tab����ͷ
ע��:
Ŀ���ļ�:֮ǰ���� test.c ���ɵ� test �ļ���һ��Ŀ���ļ�,��һ���������ļ�,����Ŀ���ļ�,�����ǰĿ¼���Ѿ�������Ϊ����ʱ,�ٴ�ִ�н��������κ�����(����ʾ���Ǹ��ļ��Ѿ������µ�)��
αĿ��:��ναĿ�������������һ���������ļ���,��ִ��makeʱ,����ֻ�����Ŀ��������ִ������������һ������,��ʱ������Ҳ�Ὣһ��αĿ���Ϊһ����ǩ������αĿ��,���ǿ���ִ�е�,����ȥ�����Dz�������
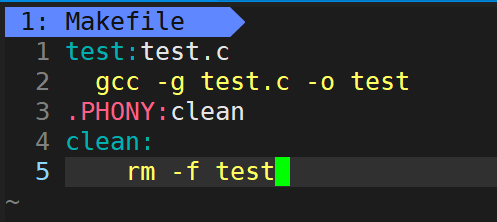
αĿ���ļ����巽��:
.PHONY: Ŀ����1 Ŀ����2 ...
Ŀ����1:
�������1
Ŀ����2:
�������2
......
//��ʹ�ö�������Ŀ����,���۵�ǰ�ļ������Ƿ����ͬ�����ļ�����ִ�и�Ŀ���µ���������
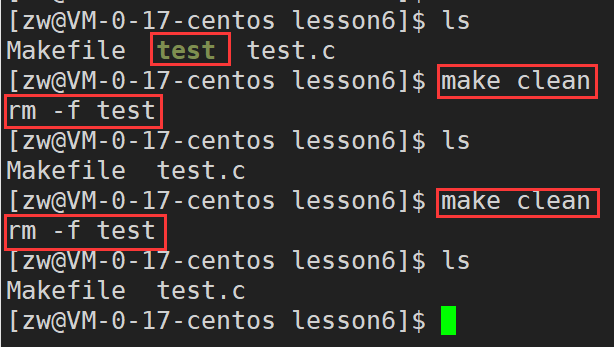
αĿ���ļ�ִ�з�ʽ
make αĿ����/α��ǩ//��make����αĿ����,��ʾִ�и�αĿ������Ӧ�Ĺ���
���������Ҫ��make�����ν���Ԥ���������롢��ࡢ����,���ɶ�Ӧ��Ŀ���ļ�,��ôMakefile�пɸ�д��
test:test.o//��ʾtest�ļ�������test.s�ļ�,Ҫ������test�ļ�,��������test.o�ļ�
gcc test.o -o test
test.o:test.s//��ʾtest.o�ļ�������test.s�ļ�,Ҫ������test.o�ļ�,��������test.s�ļ�
gcc -c test.s -o test.c
test.s:test.i//��ʾtest.s�ļ�������test.i�ļ�,Ҫ������test.s�ļ�,��������test.i�ļ�
gcc -S test.i -o test.s
test.i:test.c//��ʾtest.i�ļ�������test.c�ļ�,Ҫ������test.i�ļ�,��������test.c�ļ�
gcc -E test.c -O test.i
.PHONY:clean
clean:
rm -f test.i test.s test.o test //ɾ������������ɵ������ļ�
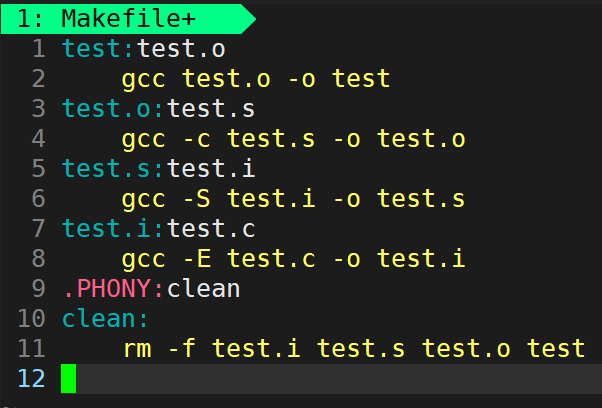
ִ�� make �� make clean :
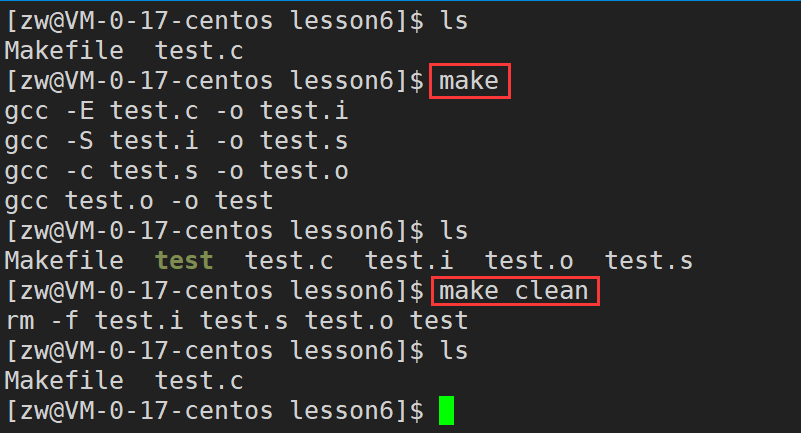
������ϵ
1)test�ļ�������test.o�ļ�
2)test.o�ļ�������test.s�ļ�
3)test.s�ļ�������test.i�ļ�
4)test.i�ļ�������test.c�ļ�
��������
gcc test.* -option test.* //���������֮��Ӧ����������
ԭ��
make����ι�����,��Ĭ�ϵķ�ʽ��,Ҳ��������ֻ����make�����ô,
1)make���ڵ�ǰĿ¼�������ֽ�"Makefile"��"makefile"���ļ���
2)����ҵ�,�������ļ��еĵ�һ��Ŀ���ļ�(target),�������������,�����ҵ�"test"����ļ�,��������ļ���Ϊ���յ�Ŀ���ļ���(make Ĭ�����ɵ�һ������)
3)���test�ļ�������,����test�������ĺ����test.o�ļ����ļ���ʱ��Ҫ��test����ļ���(������touch ����),��ô,���ͻ�ִ�к��������������������test����ļ���(make���������µ�Ŀ���ļ�,������Ŀ���ļ��Ѿ�����,��ִ��)
4)���test��������test.o�ļ�������,��ômake���ڵ�ǰ�ļ�����Ŀ��Ϊtest.o�ļ���������,����ҵ����ٸ�����һ����������test.o�ļ���(���е���һ����ջ��ݹ�Ĺ���)
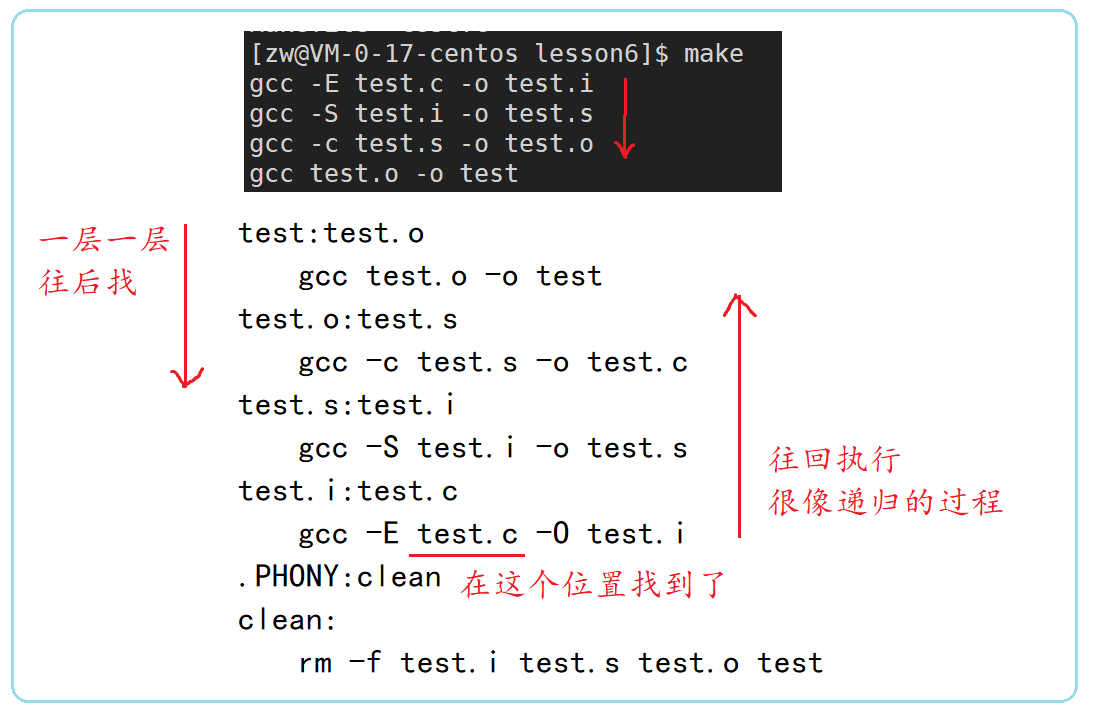
5)��Ȼ,���ǵ�.cԴ�ļ�(��.hͷ�ļ�)�Ǵ��ڵ�,����make������test.o�ļ�,Ȼ������test.o�ļ�����make���ռ�����,Ҳ����ִ���ļ�test�ˡ�
6)���������make��������,make��һ����һ���ȥ���ļ���������ϵ,ֱ�����ձ������һ��Ŀ���ļ���
7)����Ѱ�Ĺ�����,������ִ���,��������������ļ��Ҳ���,��ômake�ͻ�ֱ���˳�,������,�����������������Ĵ���,���DZ��벻�ɹ�,make����������
8)makeֻ���ļ���������,��,���������������ϵ֮��,ð�ź�����ļ����Dz���,��ô�Բ���,���Ͳ������������
��Ŀ����
1)��������Ҫ��������
2)��clean����,û�б���һ��Ŀ���ļ�ֱ�ӻ��ӹ���,��ô�������������������ᱻ�Զ�ִ��,����,���ǿ�����ʾҪmakeִ�С������һ"make clean��,�Դ���������е�Ŀ���ļ�,�Ա����±���
3)����һ����������clean��Ŀ���ļ�,���ǽ�������ΪαĿ��,�� ��.PHONY������,αĿ���������,���ǿ��Ա�ִ��(αĿ�겻�������ļ�,���Բ�����������ļ����������ͻ)
Linux��һ��С���� ������
ǰ����
��һ��enter������ķ����ͷ��ʲô?(���µ�ͬʱ����,����ζ��ʲô��?)

\r��\n
�س�(\r):�ص����п�ʼ��λ��
����:���浱ǰλ�ò���,�����ƶ�һ��,���ص����п�ʼ��λ��
�س�������(\n):�����ƶ�һ��,���Ӹ�����ʼλ�ÿ�ʼ

�л������ĸ���
#include<stdio.h>
#include<unistd.h>//Linux�µ�ͷ�ļ�
//#include <windows.h>//Windows�µ�ͷ�ļ�
int main()
{
printf("Hello Linux,Hello Makeflie\n");
//Sleep(3000);//Windows�µ�Sleep����,����ĸ��д,��λ�Ǻ���,1000ms = 1s
sleep(3);//Linux�µ�sleep����,����ĸСд,��λ����
return 0;
}
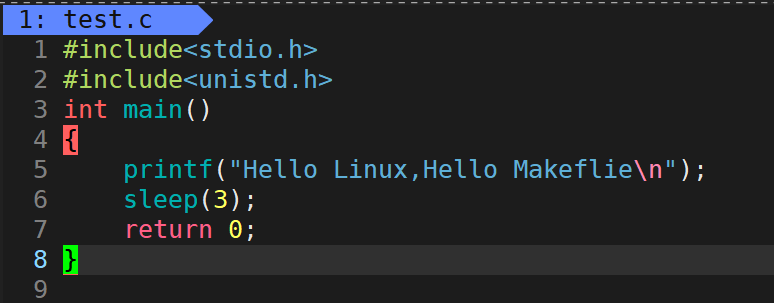
��������:���ȴ�ӡ Hello Linux,Hello Makeflie,Ȼ��ȴ�3s
����ͼ��ʾ��

������ǽ� printf �����\nȥ���ᷢ��ʲô����?
#include<stdio.h>
#include<unistd.h>//Linux�µ�ͷ�ļ�
int main()
{
printf("Hello Linux,Hello Makeflie");//����û��\n
sleep(3);//Linux�µ�sleep����,����ĸСд,��λ����
return 0;
}
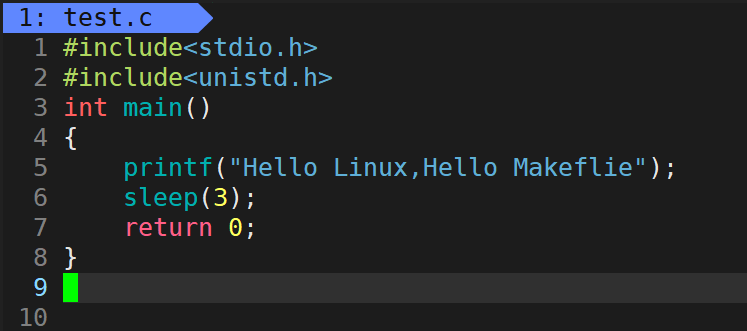
��������:���ȵȴ�3s,Ȼ���ӡ Hello Linux,Hello Makeflie
����ͼ��ʾ��

������:�����Ͼ���һ���ڴ�ռ�,�ݴ���ʱ����,�ں��ʵ�ʱ��ˢ�³�ȥ
��ˢ�²��ԡ�
1)ֱ��ˢ��,������
2)������д��,��ˢ��,ȫ����
3)����\n��ˢ��,��ˢ��
4)ǿ��ˢ��,������ֱ��д����̡��ļ�����ʾ����������豸�����ļ�
�κ�һ��C����,������ʱ��,��Ĭ�ϴ��������������(�ļ�)
stdin:����
stdout:��ʾ��
stderr:��ʾ��
�������:
Ϊʲô��\nȥ����,printf����ӡ������?
������,������õ�ˢ�²�����:3)����\n��ˢ��,��ˢ��
1)printfִ������,ֻ�Ǵ����ַ��������뻺������,����һ������ʾ����,ֻ�е������������ݱ���ʾ����ȡ������Ż�����Ļ����ʾ����
2)������ַ��������\n��ʾ�س�������,��ʱ��,print���ַ����͵�������,�������Ὣ���������͵���ʾ��
3)������ַ�������û��\n,��ôprintf���Ƚ��ַ������뻺����,�������������̽������͵���ʾ��
���������Ҫǿ��ˢ��,����ô����?

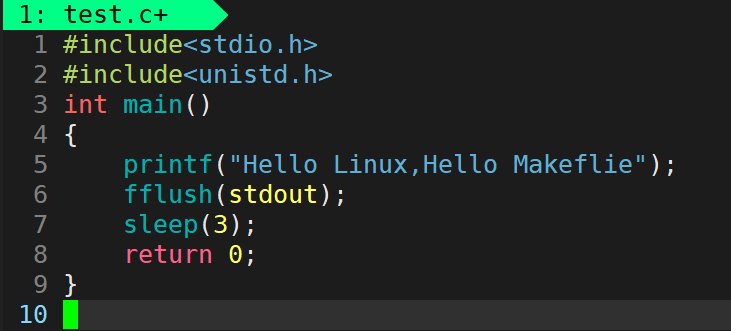
#include<stdio.h>
#include<unistd.h>//Linux�µ�ͷ�ļ�
int main()
{
printf("Hello Linux,Hello Makeflie");//����û��\n
fflush(stdout);//��fflush��ǿ��ˢ��stdout--��ʾ��
sleep(3);//Linux�µ�sleep����,����ĸСд,��λ����
return 0;
}
����ͼ��ʾ��

����ʱ����
ʵ������������Ļ�Ͽ���������,�������ַ�����ʽչʾ��,�ȷ�˵:��int������ 10 ��printf ��%d��ӡ����,��Ļ����ʾ����10,�������10���ַ�(������������)��printf��ʽ������Ὣ����10ת�����ַ�10(�ַ�1���ַ�0),Ȼ���͵���Ļ��ʾ������
#include<stdio.h>
#include<unistd.h>
int main()
{
int i;
for(i = 10; i >= 0; i--)
{
printf("%2d\r",i);//\r��ʾ�س�,��ԭ���ַ����ǵ�,%2dָ�����Ϊ2,��Ϊ10��2���ַ���ʾ
fflush(stdout);//ǿ��ˢ��
sleep(1);//˯��1s
}
}
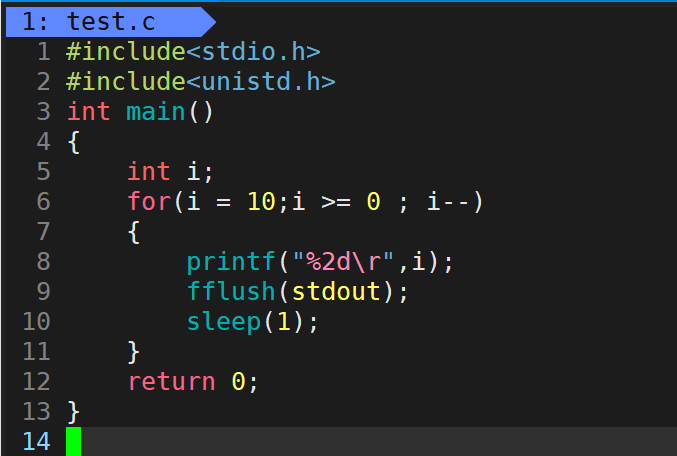
����ͼ��ʾ��

������
Ԥ��Ч��
������Linux�°�װ������ʱ��,�������Կ���ijһ����������װ�Ľ�����,�������������Ѿ���װ�˶���,�����ж���û�а�װ��
//printf���塢������ɫ��,ֻ������Linux,Windows����Ч
#include<stdio.h>
#include<string.h>
#include<unistd.h>//Unix stand library Unixϵͳ����
int main()
{
char str[101];
int i;
memset(str, 0, 101);
char lable[4] = { '|','/','-','\\' };//\\ת���ַ�
for (i = 0; i < 101; i++)
{
printf("\033[44;31m [%-100s][%d%%][%c]\033[0m\r", str, i, lable[i % 4]);
fflush(stdout);
str[i] = '#';
usleep(40000);//400ms/0.4s
}
printf("\n");
return 0;
}
����ͼ��ʾ��
�ڸ�printf��ӡ���ַ�������purpleɫ��(�ۺ�ɫ)��,���д�ӡ,��ʾЧ������

�����ϲ���ۺ�ɫ,����Ҳ�����ijɻ���ɫ��

��Ȼ,���ǻ����Լ�������ı���,�����Ҹо�������ϱ������ܻ�û���Ӻÿ���

����printf�������ɫ������ͱ������Բο�����Ĵ���
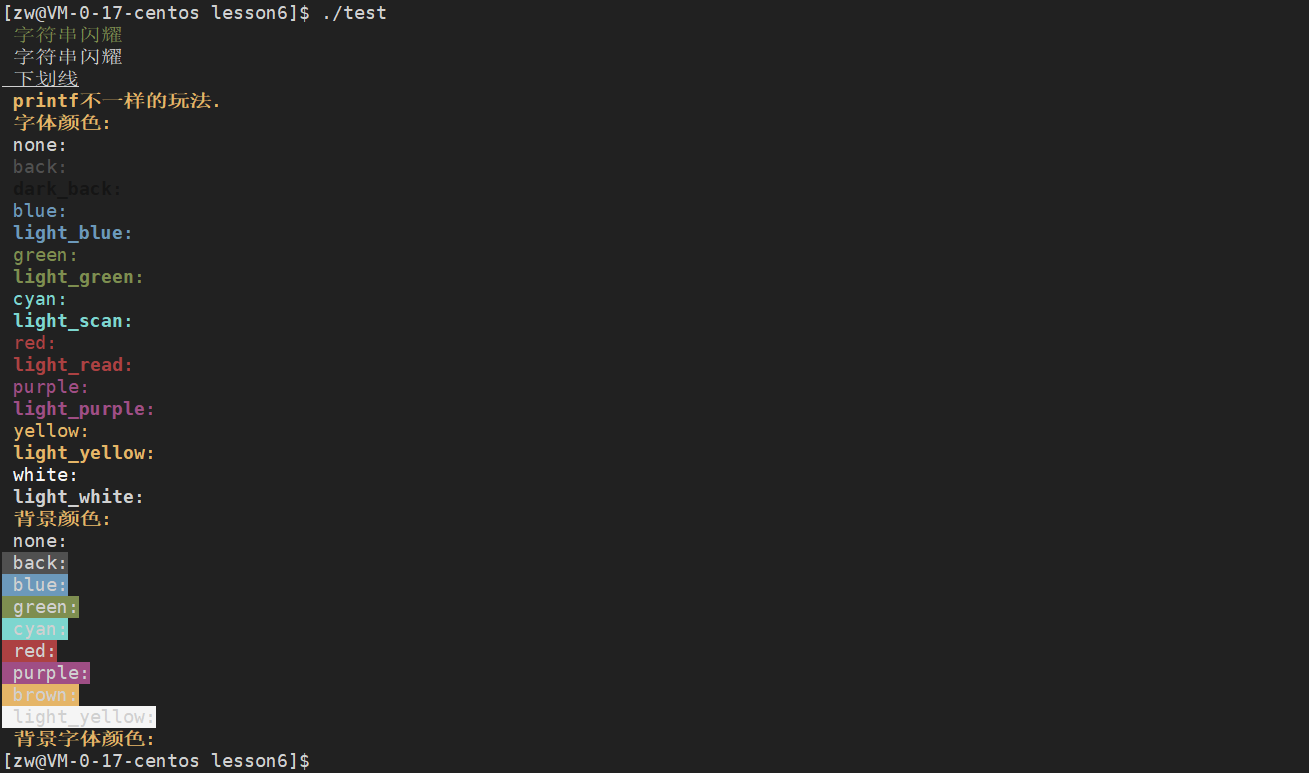
//printf���塢������ɫ��,ֻ������Linux,Windows����Ч
#include<stdio.h>
int main()
{
printf("\033[32;5m �ַ�����ҫ\033[0m\r\n");
printf("\033[5m �ַ�����ҫ\033[0m\n");
printf("\033[4m �»���\033[0m\n");
printf("\033[1;33m printf��һ�����淨. \033[0m \n"); //
printf("\033[1;33m ������ɫ:\n");
printf("\033[0m none:\n");
printf("\033[0;30m back:\n");
printf("\033[1;30m dark_back:\n");
printf("\033[0;34m blue:\n");
printf("\033[1;34m light_blue:\n");
printf("\033[0;32m green:\n");
printf("\033[1;32m light_green:\n");
printf("\033[0;36m cyan:\n");
printf("\033[1;36m light_scan:\n");
printf("\033[0;31m red:\n");
printf("\033[1;31m light_read:\n");
printf("\033[0;35m purple:\n");
printf("\033[1;35m light_purple:\n");
printf("\033[0;33m yellow:\n");
printf("\033[1;33m light_yellow:\n");
printf("\033[0;37m white:\n");
printf("\033[1;37m light_white:\n");
printf("\033[1;33m ������ɫ:\n");
printf("\033[0m none:\033[0m\n");
printf("\033[0;40m back:\033[0m\n");
printf("\033[0;44m blue:\033[0m\n");
printf("\033[0;42m green:\033[0m\n");
printf("\033[0;46m cyan:\033[0m\n");
printf("\033[0;41m red:\033[0m\n");
printf("\033[0;45m purple:\033[0m\n");
printf("\033[0;43m brown:\033[0m\n");
printf("\033[0;47m light_yellow:\033[0m\n");
printf("\033[1;33m ����������ɫ:\033[0m\n");
printf("\033[47;31m Hello Linux\033[?25l");
//47���ֱ�����ɫ, 31���������ɫ, Hello Linux���ַ���. �����\033[?25l�ǿ�����:�������ع��.
printf("\033[0m");
return 0;
}
����ͼ��ʾ��

����ͼЧ��������鿴
Linux�����й�/��Դ��Ŀ
ʹ��git������
��װgit
���Linux������û�а�װgit,����ʹ�����淽�����а�װ(��֪����û�а�װ�Ŀ���ֱ��ִ����������)
sudo yum install git

��Github�ϴ�����Ŀ
���ǵ��ڹ��ڷ���Github�����ٶȻ�Ƚ���,������Gitee(����)�����档Gitee�ǹ��ڵĿ�Դƽ̨,���ܺ�Github����,�����ڹ���ʹ���ٶȻ�ȽϿ�һЩ��
ע��Github�˺�
https://github.com
����Ƚϼ�,�ο�������ʾһ����ִ�о���,������������֤,ע����ɡ�
������Ŀ
��¼Github,����һ���µĴ���ֿ⡣
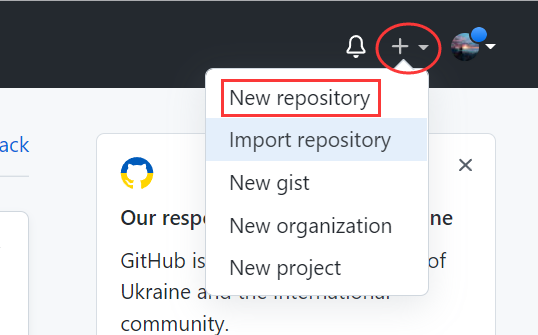
������ɺ�,�ڴ����õ���Ŀҳ���и�����Ŀ������,�������������Linux�н���clone(��¡)������
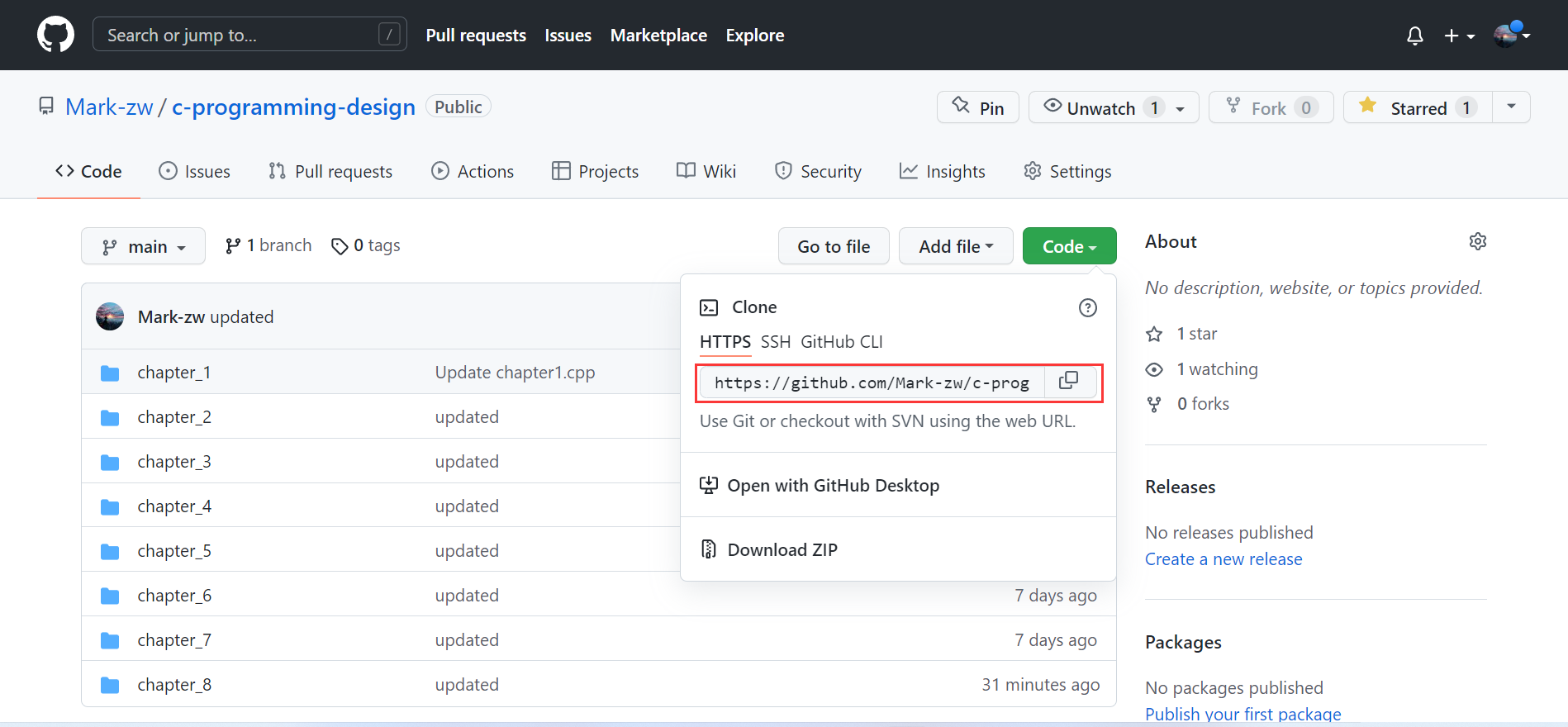
������Ŀ������
�ȴ�����һ�����ô����Ŀ¼,Ȼ��GitHub�Ĵ���ֿ��¡�����Ŀ¼�С�
git clone url //clone ����Ӹոո��Ƶ�����,
Git���������師
1)git add:������ŵ������غõ�Ŀ¼��,����Ҫ��git�������ļ�����git
git add filename
2)git commit:�������ύ������
git commit . // . ��ʾ��ǰĿ¼,�ύ��ʱ��Ҫע���ύ��־����Ϣ,�����Ժ����
3)git push:���Ѿ��ύ�����صĴ���ͬ����Զ�̷�������(�����������GitHub����С�̵����Դ)
git push
��Ҫ��д�û�������,ͬ���ɹ���,ˢ��GitHubҳ����ܿ���������ύ����ˡ�
�����������ύ
git������������˺�pull��push_CamilleZJ�IJ���-CSDN����
git remote set-url origin https://<your_token>@github.com//.git
*<your_token>*:�������Լ��õ���token
**:�����Լ�github���û���
**:����IJֿ�����**
����:(�����token�Ǹ������Լ���token�����,����,�ܿ�������),����ֱ���滻�����������ط���
git remote set-url origin https://ghp_97cOHR7dnX4M4yyzbHwdA5eN5F77OW3y9Eg0@github.com/Mark-zw/c-programming-design
�����С��������������������,Ī��,�ܺý��
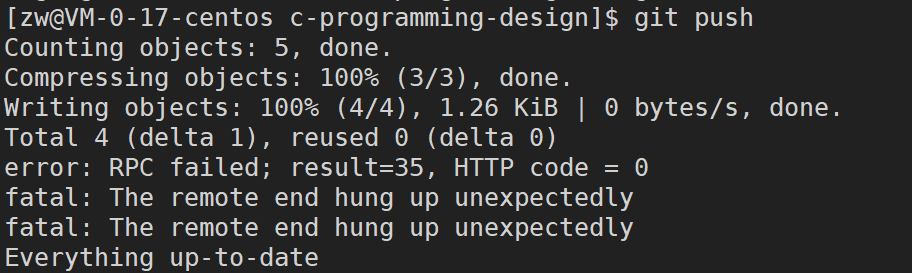
error: RPC failed; result=35, HTTP code = 0
ԭ��:The problem is most likely because your git buffer is too low.
���:You will need to increase Git��s HTTP buffer by setting.
ͨ�� Git ��� http.postBuffer ֵ��ߵ� 50M(���������Ŀ�趨,��֪������������)
git config --global http.postBuffer 50M
˼ά��ͼ�ܽ�