stream是用于集合使用的流式操作,可使用collection.stream获取流
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
本文对stream的所有接口的功能使用方法做挨个分析。
Stream接口
public interface Stream<T> extends BaseStream<T, Stream<T>> {
Stream<T> filter(Predicate<? super T> predicate);
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
IntStream mapToInt(ToIntFunction<? super T> mapper);
LongStream mapToLong(ToLongFunction<? super T> mapper);
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
IntStream flatMapToInt(Function<? super T, ? extends IntStream> mapper);
LongStream flatMapToLong(Function<? super T, ? extends LongStream> mapper);
DoubleStream flatMapToDouble(Function<? super T, ? extends DoubleStream> mapper);
Stream<T> distinct();
Stream<T> sorted();
Stream<T> sorted(Comparator<? super T> comparator);
Stream<T> peek(Consumer<? super T> action);
Stream<T> limit(long maxSize);
Stream<T> skip(long n);
void forEach(Consumer<? super T> action);
void forEachOrdered(Consumer<? super T> action);
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
Optional<T> reduce(BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
Optional<T> max(Comparator<? super T> comparator);
long count();
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
Optional<T> findFirst();
Optional<T> findAny();
public static<T> Builder<T> builder() {
return new Streams.StreamBuilderImpl<>();
}
public static<T> Stream<T> empty() {
return StreamSupport.stream(Spliterators.<T>emptySpliterator(), false);
}
public static<T> Stream<T> of(T t) {
return StreamSupport.stream(new Streams.StreamBuilderImpl<>(t), false);
}
@SafeVarargs
@SuppressWarnings("varargs") // Creating a stream from an array is safe
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f) {
Objects.requireNonNull(f);
final Iterator<T> iterator = new Iterator<T>() {
@SuppressWarnings("unchecked")
T t = (T) Streams.NONE;
@Override
public boolean hasNext() {
return true;
}
@Override
public T next() {
return t = (t == Streams.NONE) ? seed : f.apply(t);
}
};
return StreamSupport.stream(Spliterators.spliteratorUnknownSize(
iterator,
Spliterator.ORDERED | Spliterator.IMMUTABLE), false);
}
public static<T> Stream<T> generate(Supplier<T> s) {
Objects.requireNonNull(s);
return StreamSupport.stream(
new StreamSpliterators.InfiniteSupplyingSpliterator.OfRef<>(Long.MAX_VALUE, s), false);
}
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}
public interface Builder<T> extends Consumer<T> {
@Override
void accept(T t);
default Builder<T> add(T t) {
accept(t);
return this;
}
Stream<T> build();
}
}
接口就是stream支持的所有方法了。
我们挨个看用法
filter
Stream<T> filter(Predicate<? super T> predicate);
传入predict接口,泛型要求 Predicate是当前流中类型,或者是其父类
public interface Predicate<T> {
boolean test(T t);
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
default Predicate<T> negate() {
return (t) -> !test(t);
}
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
看到这个接口就可以使用花样用法了。
直接使用lamda
List<String> names = Arrays.asList("Adam", "Alexander", "John", "Tom");
List<String> result = names.stream()
.filter(name -> name.startsWith("A"))
.collect(Collectors.toList());
相当于实现了test方法,根据lamda条件返回true或者false
组合使用
Predicate.and()
两个条件都要满足
@Test
public void whenFilterListWithCombinedPredicatesUsingAnd_thenSuccess(){
Predicate<String> predicate1 = str -> str.startsWith("A");
Predicate<String> predicate2 = str -> str.length() < 5;
List<String> result = names.stream()
.filter(predicate1.and(predicate2))
.collect(Collectors.toList());
assertEquals(1, result.size());
assertThat(result, contains("Adam"));
}
Predicate.or()
满足其中一个即可
@Test
public void whenFilterListWithCombinedPredicatesUsingOr_thenSuccess(){
Predicate<String> predicate1 = str -> str.startsWith("J");
Predicate<String> predicate2 = str -> str.length() < 4;
List<String> result = names.stream()
.filter(predicate1.or(predicate2))
.collect(Collectors.toList());
assertEquals(2, result.size());
assertThat(result, contains("John","Tom"));
}
Predicate.negate()
将此条件取反
@Test
public void whenFilterListWithCombinedPredicatesUsingOrAndNegate_thenSuccess(){
Predicate<String> predicate1 = str -> str.startsWith("J");
Predicate<String> predicate2 = str -> str.length() < 4;
List<String> result = names.stream()
.filter(predicate1.or(predicate2.negate()))
.collect(Collectors.toList());
assertEquals(3, result.size());
assertThat(result, contains("Adam","Alexander","John"));
}
map
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
可以看出来
可以看出来 map是将当前类型的流转换成另一种类型
function接口
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
static <T> Function<T, T> identity() {
return t -> t;
}
}
lamda
也就是直接实现lamda方法
list.stream().map(it-> Arrays.stream(it.split(""))).forEach(
it->it.forEach(
s-> System.out.println(s)
)
);
组合使用
Function<ErpDecorationCostClassification,String> function = ErpDecorationCostClassification::getSecondClassificationNo;
Function<String,Integer> function1 = Integer::parseInt;
List<Integer> list = costClassificationList.stream().map(function.andThen(function1)).collect(Collectors.toList());
一个function作为另一个funcion的执行入参,
该方法同样用于“先做什么,再做什么”的场景
compose:入参处理当前返回值
andThen: 入参作为返回的类型
这里讲下双冒号::的用法
把上面两个lamda等同改写下
Function<ErpDecorationCostClassification,String> function2 = it->it.getThirdClassificationNo();
Function<String,Integer> function1 = it->Integer.valueOf(it);
如果是非静态方法使用::形式。相当于lamda it->getThirdClassificationNo
如果是静态方法使用::形式。相当于lamda it->Integer.valueOf(it);
flatMap
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
与mao不同,
Function返回值R要求是Stream类型的
Stream<? extends R>zhe
这里有一个有意思的现象,入参要求为指定类型的父类,反参要求为为指定类型的子类
所以一般用于,将集合中的元素的集合返回
示例
将字符串分割成字符
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
list.stream().flatMap(it-> Arrays.stream(it.split(""))).forEach(it-> System.out.println(it));
list.stream().map(it-> Arrays.stream(it.split(""))).forEach(
it->it.forEach(
s-> System.out.println(s)
)
);
获取Map<String, List> 中的list整合成一个list
Map<String, List<ErpDictionary>> collect = dictionaryList.stream().collect(Collectors.groupingBy(ErpDictionary::getDataKey));
List<ErpDictionary> dictionaries = collect.values().stream().flatMap(it->it.stream()).collect(Collectors.toList());
distinct
* Returns a stream consisting of the distinct elements (according to
* {@link Object#equals(Object)}) of this stream.
看注释就是用equals判断,去除相同的,很简单
sorted
Stream<T> sorted(Comparator<? super T> comparator);
compare
int compare(T o1, T o2);
int compare(T o1, T o2) 是“比较o1和o2的大小”,其中o1指的就是第一个要比较的对象, o2指的就是第二要比的对象。 比较之后会根据大小返回值。 返回“负数”, 意味着“o1比o2小”;返回“零”,意味着“o1等于o2”;返回“正数”,意味着“o1大于o2。
最终的结果按照"从小到大"
reversed
顺序反转
用法示例
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
Comparator<String> stringComparator = (o1,o2)->o1.compareTo(o2);
list.stream().sorted(stringComparator.reversed()).collect(Collectors.toList());
实现
public static <T> Comparator<T> reverseOrder(Comparator<T> cmp) {
if (cmp == null)
return reverseOrder();
if (cmp instanceof ReverseComparator2)
return ((ReverseComparator2<T>)cmp).cmp;
return new ReverseComparator2<>(cmp);
}
private static class ReverseComparator2<T> implements Comparator<T>,
Serializable
{
private static final long serialVersionUID = 4374092139857L;
/**
* The comparator specified in the static factory. This will never
* be null, as the static factory returns a ReverseComparator
* instance if its argument is null.
*
* @serial
*/
final Comparator<T> cmp;
ReverseComparator2(Comparator<T> cmp) {
assert cmp != null;
this.cmp = cmp;
}
public int compare(T t1, T t2) {
return cmp.compare(t2, t1);
}
public boolean equals(Object o) {
return (o == this) ||
(o instanceof ReverseComparator2 &&
cmp.equals(((ReverseComparator2)o).cmp));
}
public int hashCode() {
return cmp.hashCode() ^ Integer.MIN_VALUE;
}
@Override
public Comparator<T> reversed() {
return cmp;
}
}
在之前定的cmp上再包一层,调换入参位置,实现反转
thenComparing
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res != 0) ? res : other.compare(c1, c2);
};
}
示例
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
Comparator<String> stringComparator = (o1,o2)->o1.compareTo(o2);
stringComparator.thenComparing((o1, o2) -> o1.hashCode() - o2.hashCode());
也很简单,就是创建一个Comparator
如果当前比较器比较结果为0.就再thenComparing中的比较器进行比较
版本2
default <U> Comparator<T> thenComparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
return thenComparing(comparing(keyExtractor, keyComparator));
}
入参多了一个keyExtractor,可以另外比较别的值
用法如下
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
Comparator<String> stringComparator = (o1,o2)->o1.compareTo(o2);
stringComparator.thenComparing(it->it.length(),(o1,o2)->o1-o2);
comparing
public static <T, U> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor,
Comparator<? super U> keyComparator)
{
Objects.requireNonNull(keyExtractor);
Objects.requireNonNull(keyComparator);
return (Comparator<T> & Serializable)
(c1, c2) -> keyComparator.compare(keyExtractor.apply(c1),
keyExtractor.apply(c2));
}
根据前面的铺垫,这个方法也很简单,传入 一个funcion获取真正比较的值,然后在通过Comparator进行数据比较
其他几个比较,int,double用法上大同小异,就不再详细讲了。
nullsFirst
final static class NullComparator<T> implements Comparator<T>, Serializable {
private static final long serialVersionUID = -7569533591570686392L;
private final boolean nullFirst;
// if null, non-null Ts are considered equal
private final Comparator<T> real;
@SuppressWarnings("unchecked")
NullComparator(boolean nullFirst, Comparator<? super T> real) {
this.nullFirst = nullFirst;
this.real = (Comparator<T>) real;
}
@Override
public int compare(T a, T b) {
if (a == null) {
return (b == null) ? 0 : (nullFirst ? -1 : 1);
} else if (b == null) {
return nullFirst ? 1: -1;
} else {
return (real == null) ? 0 : real.compare(a, b);
}
}
@Override
public Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return new NullComparator<>(nullFirst, real == null ? other : real.thenComparing(other));
}
@Override
public Comparator<T> reversed() {
return new NullComparator<>(!nullFirst, real == null ? null : real.reversed());
}
}
}
看其compare方法,其实也就是把null最为比较器的小数返回
peek() vs forEach()
Stream<T> peek(Consumer<? super T> action);
void forEach(Consumer<? super T> action);
forEach() 则是一个最终操作。除此之外,peek() 和 forEach() 再无其他不同。
执行完毕后peek还可以返回Stream,forEach是没用返回值,整个流式运算结束。
Consumer
@FunctionalInterface
public interface Consumer<T> {
void accept(T t);
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
accept是处理每一个元素,例如打印每个元素
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
list.stream().forEach(it-> System.out.println(it));
andThen,是消费完毕一个元素之后,再继续处理
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
Consumer<String> consumer1 = it -> System.out.println(it+"Y");
Consumer<String> consumer2 = it -> System.out.println(it);
list.stream().forEach(consumer1.andThen(consumer2));
tomY
tom
jameY
jame
jerryY
jerry
helloY
hello
forEachOrdered
forEachOrdered()和forEach()方法的区别在于forEachOrdered()将始终按照流(stream)中元素的遇到顺序执行给定的操作,而forEach()方法是不确定的。
在并行流(parallel stream)中,forEach()方法可能不一定遵循顺序,而forEachOrdered()将始终遵循顺序。
在序列流(sequential stream)中,两种方法都遵循顺序。
如果我们希望在每种情况下,不管流(stream)是连续的还是并行的,都要按照遵循顺序执行操作,那么我们应该使用forEachOrdered()方法。
如果流(stream)是连续的,我们可以使用任何方法来维护顺序。
但是如果流(stream)也可以并行,那么我们应该使用forEachOrdered()方法来维护顺序。
toArray
Object[] toArray();
<A> A[] toArray(IntFunction<A[]> generator);
stream的两个toArray方法,一个是直接将流中的元素转成对象数组另一个是,转换成数组数组,数组中每个字符串的长度。
toArray放回的是Object类型数据,而带参数toArray返回,指定类型的数组。
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
list.stream().toArray(String[]::new);
reduce[
](https://blog.csdn.net/qq_31635851/article/details/111035328)
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
T reduce(T identity, BinaryOperator<T> accumulator);
Optional<T> reduce(BinaryOperator<T> accumulator);
reduce一共有三个版本
先看接口参数
BinaryOperator
@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {
/**
* Returns a {@link BinaryOperator} which returns the lesser of two elements
* according to the specified {@code Comparator}.
*
* @param <T> the type of the input arguments of the comparator
* @param comparator a {@code Comparator} for comparing the two values
* @return a {@code BinaryOperator} which returns the lesser of its operands,
* according to the supplied {@code Comparator}
* @throws NullPointerException if the argument is null
*/
public static <T> BinaryOperator<T> minBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) <= 0 ? a : b;
}
/**
* Returns a {@link BinaryOperator} which returns the greater of two elements
* according to the specified {@code Comparator}.
*
* @param <T> the type of the input arguments of the comparator
* @param comparator a {@code Comparator} for comparing the two values
* @return a {@code BinaryOperator} which returns the greater of its operands,
* according to the supplied {@code Comparator}
* @throws NullPointerException if the argument is null
*/
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
}
@FunctionalInterface
public interface BiFunction<T, U, R> {
/**
* Applies this function to the given arguments.
*
* @param t the first function argument
* @param u the second function argument
* @return the function result
*/
R apply(T t, U u);
/**
* Returns a composed function that first applies this function to
* its input, and then applies the {@code after} function to the result.
* If evaluation of either function throws an exception, it is relayed to
* the caller of the composed function.
*
* @param <V> the type of output of the {@code after} function, and of the
* composed function
* @param after the function to apply after this function is applied
* @return a composed function that first applies this function and then
* applies the {@code after} function
* @throws NullPointerException if after is null
*/
default <V> BiFunction<T, U, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t, U u) -> after.apply(apply(t, u));
}
}
先看父接口,
apply方法,传入两个类型,返回一个类型的数据
如果调用andThen方法是将apply的结果进行进一步的处理
传递一个BinaryOperator 入参为两个类型

这样看要求,apply入参, 反参,三个必须为同一类型
BinaryOperator还实现了两个方法
minBy和maxBy分别根据传入的comparator进行比较大小
reduce一个参数用法
单参数的返回值是被Option包裹起来的
求最大最小
List<Integer> integers = Arrays.asList(1,2,3,5);
integers.stream().sorted(Comparator.comparing(Integer::intValue));
integers.stream().reduce(BinaryOperator.maxBy(Comparator.comparing(Integer::intValue)));
求和
List<Integer> integers = Arrays.asList(1,2,3,5);
integers.stream().sorted(Comparator.comparing(Integer::intValue));
Integer maxVal = integers.stream().reduce(BinaryOperator.maxBy(Comparator.comparing(Integer::intValue))).get();
System.out.println(maxVal);
System.out.println(integers.stream().reduce((o1,o2)->o1+o2).get());
reduce两个参数用法
两个参数和一个餐宿没什么区别
都是通过BinaryOperator来实现的
无非是两个参数的可以指定一个初始值,并且返回值不带Option包裹
同样
要求,初始值,apply入参, 反参,三个必须为同一类型
recude三个参数用法
第二个参数由BinaryOperator改为了BiFunction
这样就可以自定义入参和返回值了。这样就可以做更多的事情了。
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
要求初始值,和返回值,还有apply方法第一个入参,类型需要相同。
这样就可以根据对象某个字段进行求和了,比较最大/最小值了
例如。求和
List<NcContractDataVo> vos = getContractData(companyCode, startTime, endTime);
return vos.stream().reduce(BigDecimal.ZERO, (o1, o2) -> o1.add(NumberUtil.getNumber(o2.getTotal())), (o1, o2) -> o.add(o2));
第三个参数的是代表再并行流parallelStream的情况下,需要集合元素分组进行计算,组与组之间也进行计算最终得到结果,第三个BinaryOperator中是组与组之间的结果聚合的计算逻辑
为什么三个参数的reduce才需要实现combiner方法
顺序实现很简单。标识值I与第零个流元素“累加”以给出结果。该结果与第一个流元素累加以给出另一个结果,该结果又与第二个流元素累加,依此类推。最后一个元素累加后,返回最终结果。
并行实现首先将流拆分为段。每个段都由它自己的线程以我上面描述的顺序方式处理。现在,如果我们有 N 个线程,我们就有 N 个中间结果。这些需要减少到一个结果。由于每个中间结果都是 T 类型,并且我们有多个,因此我们可以使用相同的累加器函数将这 N 个中间结果减少为单个结果
如果identity,accumulator的参数类型都一致。那么即使分段,段与段的计算逻辑也可以确定。但如果类型不一致,就需要自己编写段与段之间的合并逻辑
collect
stream最复杂,也最灵活的一个用法
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
<R, A> R collect(Collector<? super T, A, R> collector);
用法1比较简单。很像reduce
Supplier接口
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
与reduce不同的是,reduce第一个参数是已经定义好的一个实例,而collect是获取实例的一个接口,
在并行流里这两个区别十分巨大,因为数据会分段例如收集到集合的写法
collect
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
list.stream().collect(ArrayList::new,(o1,o2)->o1.add(o2),(o1,o2)->o1.add(o2));
reduce
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
list.stream().reduce(new ArrayList<>(), (o1, o2) -> {
o1.add(o2);
return o1;
}, (o1, o2) -> {
o1.addAll(o2);
return o1;
});
可以看出来,reduce中得处理之后,需要返回处理结果,而colect不用,所以明细collect更适合集合收集,而reduce更适合用于计算,返回无状态得结果,后续再参与计算。而且,reduce进行数据收集如果在并行流中由于数据分段后都共享得同一个identity,线程安全难以保证,并且在combinder会出现数据重复得问题
BiConsumer
@FunctionalInterface
public interface BiConsumer<T, U> {
void accept(T t, U u);
default BiConsumer<T, U> andThen(BiConsumer<? super T, ? super U> after) {
Objects.requireNonNull(after);
return (l, r) -> {
accept(l, r);
after.accept(l, r);
};
}
}
与reduce的BiFunction相比无返回值,只能通过引用类型不断收集数据
字符串拼接
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
System.out.println( list.stream().collect(()->new StringBuffer(),(o1,o2)->o1.append(o2),(o1,o2)->o1.append(o2)));
收集到集合中
List<String> list = Arrays.asList("tom", "jame", "jerry", "hello");
list.stream().collect(ArrayList::new,(o1,o2)->o1.add(o2),(o1,o2)->o1.add(o2));
Collector接口
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = (characteristics.length == 0)
? Collectors.CH_ID
: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,
characteristics));
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);
}
public static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A, R> finisher,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(finisher);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = Collectors.CH_NOID;
if (characteristics.length > 0) {
cs = EnumSet.noneOf(Characteristics.class);
Collections.addAll(cs, characteristics);
cs = Collections.unmodifiableSet(cs);
}
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, finisher, cs);
}
enum Characteristics {
CONCURRENT,
UNORDERED,
IDENTITY_FINISH
}
}
Collector 的组成
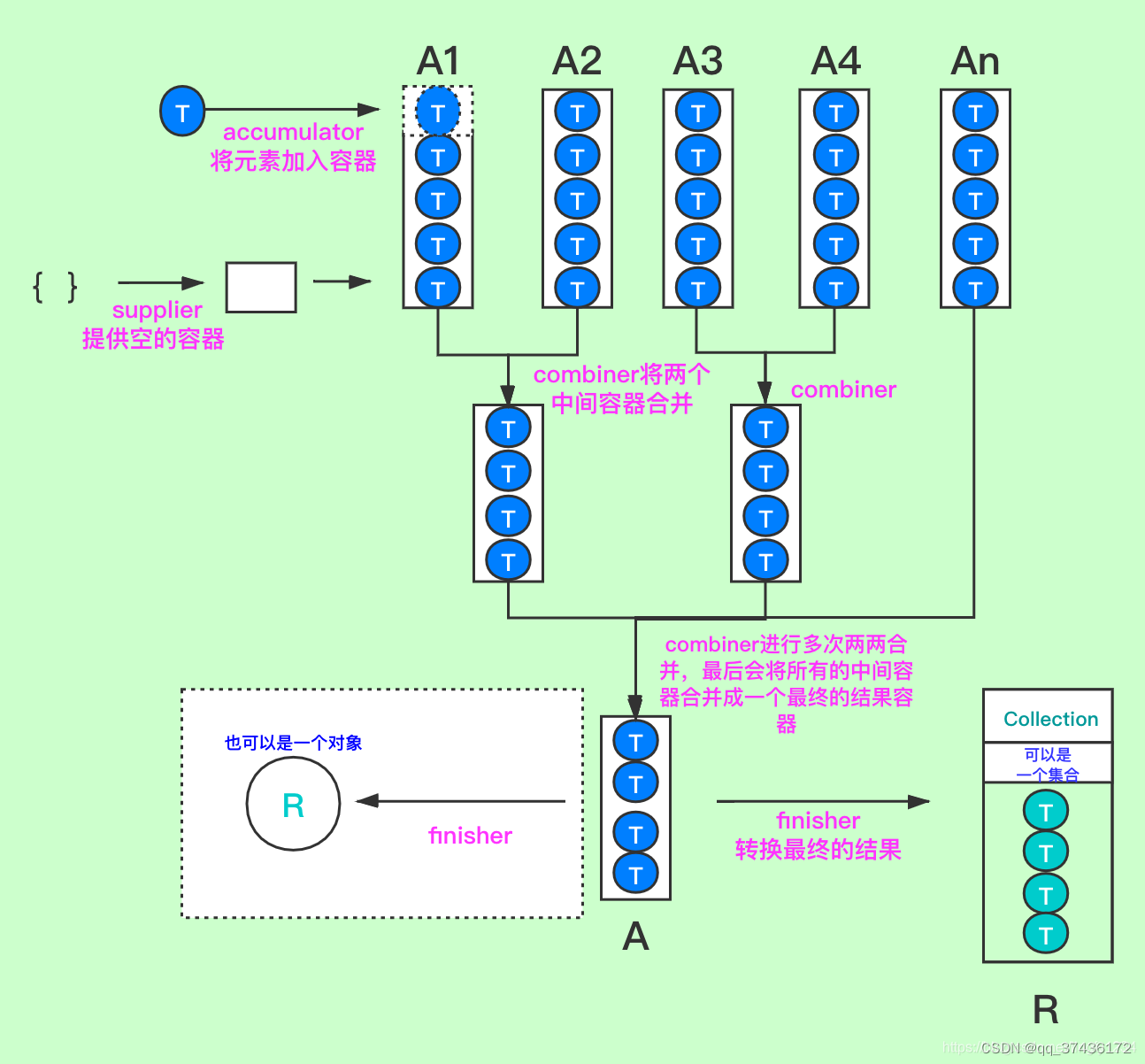
collector由四个方法组成和一个特性组成
| 组成 | 作用 |
|---|---|
| Supplier | 创建一个新的结果容器 |
| accumulator | 将一个新的元素(流中的元素)加入到结果容器中 |
| combiner | 接受两个中间的结果容器,将它们合并成一个(并行流的时候) |
| finisher | 将结果容器转换成另一个类型(可选的) |
characteristics 是一个枚举特性集合,决定某些操作过程的特性,比如是否是并行的,是否需要转换结果容器,是否是有序的,这些特性用来进行简化操作,提供更好的性能。
一共有三个特性,在定义的时候可以选几个来组成这个集合,它们是:
IDENTITY_FINISH 表明 finisher 就是 identity 函数,可以省略。如果设置,则必须是从A(中间结果类型)到R(最终结果类型)的未经检查的强制转换成功,不然就会报类型转换错误,一般如果A和R的类型一致,就可以设置,此时设置之后,就不会调用finisher,java自己进行强转
CONCURRENT 表示此收集器是并发的,简单点说,加CONCURRENT ,意味着使用 parallelStream,产生多少个线程了,都只有一个中间容器, accumulator 在执行时,由于中间容器在只有一个的情况下,要求不能有一边查询和一边修改的操作,不然会抛 ConcurrentModificationException 异常,且由于只有一个中间容器,所以不调用 combiner 定义的回调方法的。不加上CONCURRENT ,就是产生的多个线程多个容器,执行combiner合并容器。
ConcurrentModificationException:异常原因, it is not generally permissible for one thread to modify a Collection while another thread is iterating over it. 简单点说,多线程时,并发调同一对象,有的在执行添加,有的在执行查询,所以就会抛出异常。
UNORDERED 指示集合操作不承诺保留输入元素的遭遇顺序。 (如果结果容器没有内在顺序,例如Set,则可能是这样。)
关于Collector的四个方法,这里用一个流程图来解释这个过程
Collectors提供自带得几个collect
CollectorImpl
static class CollectorImpl<T, A, R> implements Collector<T, A, R> {
private final Supplier<A> supplier;
private final BiConsumer<A, T> accumulator;
private final BinaryOperator<A> combiner;
private final Function<A, R> finisher;
private final Set<Characteristics> characteristics;
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Function<A,R> finisher,
Set<Characteristics> characteristics) {
this.supplier = supplier;
this.accumulator = accumulator;
this.combiner = combiner;
this.finisher = finisher;
this.characteristics = characteristics;
}
CollectorImpl(Supplier<A> supplier,
BiConsumer<A, T> accumulator,
BinaryOperator<A> combiner,
Set<Characteristics> characteristics) {
this(supplier, accumulator, combiner, castingIdentity(), characteristics);
}
@Override
public BiConsumer<A, T> accumulator() {
return accumulator;
}
@Override
public Supplier<A> supplier() {
return supplier;
}
@Override
public BinaryOperator<A> combiner() {
return combiner;
}
@Override
public Function<A, R> finisher() {
return finisher;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
}
toList
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
对于这个方法实现来说
- supplier是 () -> ArrayList::new,提供的容器类型(A)是ArrayList
- accumulator是List::add,将元素item加入到arrayList容器中,即
(intermediateCollector, item) -> intermediateCollector.add(item)
- combiner是将两个容器arrayList合并
(left, right) -> { left.addAll(right); return left;}
- finisher是啥也不做,combiner之后的结果就直接返回来,所以R也是ArrayList的类型
- characteristic是
Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
IDENTITY_FINISH这个特性是说,不执行finisher函数,直接返回combiner之后的结果容器
toSet
public static <T>
Collector<T, ?, Set<T>> toSet() {
return new CollectorImpl<>((Supplier<Set<T>>) HashSet::new, Set::add,
(left, right) -> { left.addAll(right); return left; },
CH_UNORDERED_ID);
}
基本上跟toList没什么区别。supplier传得是HashSet
static final Set<Collector.Characteristics> CH_UNORDERED_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.UNORDERED,
Collector.Characteristics.IDENTITY_FINISH));
_CH_UNORDERED_ID_这个特性是说,不执行finisher函数,直接返回combiner之后的结果容器
_UNORDERED_这个特性是说,不要求有序。意味着这个聚合操作不会保留元素的出现顺序,一般是来说最后的结果容器是无序的(比如Set)才会使用
joining
public static Collector<CharSequence, ?, String> joining() {
return new CollectorImpl<CharSequence, StringBuilder, String>(
StringBuilder::new, StringBuilder::append,
(r1, r2) -> { r1.append(r2); return r1; },
StringBuilder::toString, CH_NOID);
}
看起来也很简单,使用StringBuilder拼接字符串,最后通过finisher转成String
带参数
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}
如果不知道prefix和sufferfix得含义看一个例子就知道了
StringJoiner sj = new StringJoiner(":", "[", "]");
sj.add("George").add("Sally").add("Fred");
String desiredString = sj.toString();
System.out.println(desiredString); // [George:Sally:Fred]
mapping
public static <T, U, A, R>
Collector<T, ?, R> mapping(Function<? super T, ? extends U> mapper,
Collector<? super U, A, R> downstream) {
BiConsumer<A, ? super U> downstreamAccumulator = downstream.accumulator();
return new CollectorImpl<>(downstream.supplier(),
(r, t) -> downstreamAccumulator.accept(r, mapper.apply(t)),
downstream.combiner(), downstream.finisher(),
downstream.characteristics());
}
先看demo
List<Student> students = new ArrayList<>();
students.stream().collect(Collectors.mapping(Student::getNo,Collectors.toList()));
泛型解释
可以看到mapping接口放行有T,U,A,R四种泛型
,T为当前Stream类型。U,为T通过mapper转换成的类型。A为收集器类型,R为最终返回值类型(finisherl返回类型),
T与?的区别
- T:如果一个类中的方法、参数使用了T来做泛型,那么类上边也必须要写T泛型。也就是说如果使用了T来做泛型,就必须在使用这个类的时刻,确定这个泛型的类型。
- ?:如果想要使用?来做泛型。我们可以在写代码的时候,也不指定类型。也就是说,在使用类的时候不必确定这个泛型。
这个实现原理也比较简单j就是通过Function接口进行数据转换,然后再通过downstream的accpet进行对数据进行收集。
collectingAndThen
public static<T,A,R,RR> Collector<T,A,RR> collectingAndThen(Collector<T,A,R> downstream,
Function<R,RR> finisher) {
Set<Collector.Characteristics> characteristics = downstream.characteristics();
if (characteristics.contains(Collector.Characteristics.IDENTITY_FINISH)) {
if (characteristics.size() == 1)
characteristics = Collectors.CH_NOID;
else {
characteristics = EnumSet.copyOf(characteristics);
characteristics.remove(Collector.Characteristics.IDENTITY_FINISH);
characteristics = Collections.unmodifiableSet(characteristics);
}
}
return new CollectorImpl<>(downstream.supplier(),
downstream.accumulator(),
downstream.combiner(),
downstream.finisher().andThen(finisher),
characteristics);
}
实际上就是对finisher的类型进一步转换,这里要求characteristics不能含有IDENTITY_FINISH,即要求finisher一定会执行。
reducing
public static <T, U>
Collector<T, ?, U> reducing(U identity,
Function<? super T, ? extends U> mapper,
BinaryOperator<U> op) {
return new CollectorImpl<>(
boxSupplier(identity),
(a, t) -> { a[0] = op.apply(a[0], mapper.apply(t)); },
(a, b) -> { a[0] = op.apply(a[0], b[0]); return a; },
a -> a[0], CH_NOID);
}
private static <T> Supplier<T[]> boxSupplier(T identity) {
return () -> (T[]) new Object[] { identity };
}
实际上就是通过collect实现reduce,由于collect不带返回值,因此必须使用引用类型。所所以reduceing这里使用数组包裹,实现数据的处理。
counting
public static <T> Collector<T, ?, Long>
counting() {
return reducing(0L, e -> 1L, Long::sum);
}
利用reduce进行计数,逻辑也十分简单。
minBy maxBy
public static <T> Collector<T, ?, Optional<T>>
maxBy(Comparator<? super T> comparator) {
return reducing(BinaryOperator.maxBy(comparator));
}
利用reduce进行计数,逻辑简单,返回Option包裹的数据
sum,average
public static <T> Collector<T, ?, Integer>
summingInt(ToIntFunction<? super T> mapper) {
return new CollectorImpl<>(
() -> new int[1],
(a, t) -> { a[0] += mapper.applyAsInt(t); },
(a, b) -> { a[0] += b[0]; return a; },
a -> a[0], CH_NOID);
}
都是通过转成数组,通过collect挨个计算,最终输出为Integer
groupingBy
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
return groupingBy(classifier, HashMap::new, downstream);
}
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A container = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(container, t);
};
BinaryOperator<Map<K, A>> merger = Collectors.<K, A, Map<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<Map<K, A>> mangledFactory = (Supplier<Map<K, A>>) mapFactory;
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<Map<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_NOID);
}
}
private static <K, V, M extends Map<K,V>>
BinaryOperator<M> mapMerger(BinaryOperator<V> mergeFunction) {
return (m1, m2) -> {
for (Map.Entry<K,V> e : m2.entrySet())
m1.merge(e.getKey(), e.getValue(), mergeFunction);
return m1;
};
}
classifier为获取mapKey值得一个function,
Supplier mapFactory, 就是创建map得supplier HashMap::new
downstream为map一个key下value得collect
重写accumulator
要求classifier得到得key不能为空。
调用map得computeIfAbsent如果为空,利用downstreamSupplier创建downstream得收集器
然后利用downstream的downstreamAccumulator收集数据到收集器
重写combinder
利用map的merge方法
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
要求key和value都不能为空。remappingFunction就是downstream的combinder
这样 map在合并的时候,不用的key合并到一个map,相同的key采用remappingFunction进行合并
创建新的collect,返回
groupingBy花式求和
List<Student> students = new ArrayList<>();
students.stream().collect(Collectors.groupingBy(Student::getNo, Collectors.reducing(BigDecimal.ZERO, Student::getMoney, BigDecimal::add)));
students.stream().collect(Collectors.groupingBy(Student::getNo, Collectors.mapping(Student::getMoney, Collectors.reducing(BigDecimal::add))));
groupingByConcurrent
public static <T, K>
Collector<T, ?, ConcurrentMap<K, List<T>>>
groupingByConcurrent(Function<? super T, ? extends K> classifier) {
return groupingByConcurrent(classifier, ConcurrentHashMap::new, toList());
}
public static <T, K, A, D, M extends ConcurrentMap<K, D>>
Collector<T, ?, M> groupingByConcurrent(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BinaryOperator<ConcurrentMap<K, A>> merger = Collectors.<K, A, ConcurrentMap<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<ConcurrentMap<K, A>> mangledFactory = (Supplier<ConcurrentMap<K, A>>) mapFactory;
BiConsumer<ConcurrentMap<K, A>, T> accumulator;
if (downstream.characteristics().contains(Collector.Characteristics.CONCURRENT)) {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(resultContainer, t);
};
}
else {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
synchronized (resultContainer) {
downstreamAccumulator.accept(resultContainer, t);
}
};
}
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_CONCURRENT_ID);
}
else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<ConcurrentMap<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_CONCURRENT_NOID);
}
}
gengroupBy大同小异,区别在于
groupingByConcurrent需要设置Collector.Characteristics._CONCURRENT_属性,这样,就不再需要combinder。也不会分多段就创建多个ConcurrentHashMap,从头到尾只使用一个实例
注意,如果grouyBy相同key的值 聚合的collect不是_CONCURRENT_的话,需要加锁执行
else {
accumulator = (m, t) -> {
K key = Objects.requireNonNull(classifier.apply(t), "element cannot be mapped to a null key");
A resultContainer = m.computeIfAbsent(key, k -> downstreamSupplier.get());
synchronized (resultContainer) {
downstreamAccumulator.accept(resultContainer, t);
}
};
}
至于为什么这么做是因为,如果没有_CONCURRENT_,那么认为collect不具备多线程安全的能力,如果多个线程不分别创建实例,分段执行,那么就会有线程安全问题,groupingByConcurrent只采用一个实例,因此需要加锁保证线程安全
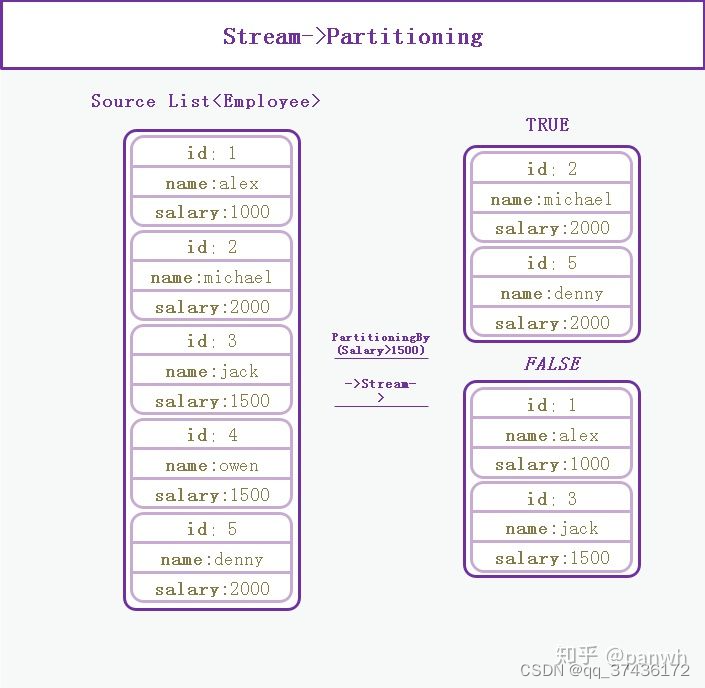
partitioningBy
这个比较陌生,先了解用法
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {
return partitioningBy(predicate, toList());
}
public static <T, D, A>
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,
Collector<? super T, A, D> downstream) {
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Partition<A>, T> accumulator = (result, t) ->
downstreamAccumulator.accept(predicate.test(t) ? result.forTrue : result.forFalse, t);
BinaryOperator<A> op = downstream.combiner();
BinaryOperator<Partition<A>> merger = (left, right) ->
new Partition<>(op.apply(left.forTrue, right.forTrue),
op.apply(left.forFalse, right.forFalse));
Supplier<Partition<A>> supplier = () ->
new Partition<>(downstream.supplier().get(),
downstream.supplier().get());
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(supplier, accumulator, merger, CH_ID);
}
else {
Function<Partition<A>, Map<Boolean, D>> finisher = par ->
new Partition<>(downstream.finisher().apply(par.forTrue),
downstream.finisher().apply(par.forFalse));
return new CollectorImpl<>(supplier, accumulator, merger, finisher, CH_NOID);
}
}
Partition
private static final class Partition<T>
extends AbstractMap<Boolean, T>
implements Map<Boolean, T> {
final T forTrue;
final T forFalse;
Partition(T forTrue, T forFalse) {
this.forTrue = forTrue;
this.forFalse = forFalse;
}
@Override
public Set<Map.Entry<Boolean, T>> entrySet() {
return new AbstractSet<Map.Entry<Boolean, T>>() {
@Override
public Iterator<Map.Entry<Boolean, T>> iterator() {
Map.Entry<Boolean, T> falseEntry = new SimpleImmutableEntry<>(false, forFalse);
Map.Entry<Boolean, T> trueEntry = new SimpleImmutableEntry<>(true, forTrue);
return Arrays.asList(falseEntry, trueEntry).iterator();
}
@Override
public int size() {
return 2;
}
};
}
}
Partition中有forTrue和forFalse相当于是两个分区
partitioningBy大致工作过程为
如果通过predicate判断为true,将元素放入forTrue,否则放入forFalse中
新建combinder,多线程数据合并时,forTrue。forFalse分别合并各自元素
forTrue,forFalse创建逻辑次采用,传入collect的supplier
用法示例
Map<Boolean, List<Employee>> map = list.stream().collect(Collectors.partitioningBy(employee -> {
return employee.getSalary() > 1500;
}));
log.info("true:{}",map.get(Boolean.TRUE));
log.info("false:{}",map.get(Boolean.FALSE));
toMap
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
private static <T> BinaryOperator<T> throwingMerger() {
return (u,v) -> { throw new IllegalStateException(String.format("Duplicate key %s", u)); };
}
toMap的逻辑十分简单
就是定义了两个Function分别获取key和value,
这里使用merget方法,如果key已经存在value则使用mergeFunction合并,但是mergeFunction直接抛出异常,因此toMap不允许key值重复,combinder也是如此。
toConcurrentMap
public static <T, K, U>
Collector<T, ?, ConcurrentMap<K,U>> toConcurrentMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toConcurrentMap(keyMapper, valueMapper, throwingMerger(), ConcurrentHashMap::new);
}
public static <T, K, U, M extends ConcurrentMap<K, U>>
Collector<T, ?, M> toConcurrentMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_CONCURRENT_ID);
}
toConcurrentMap与toMap基本相同,只不过。toConcurrentMap采用ConcurrentHashMap,并且使用CH_CONCURRENT_ID
max/min
Optional<T> max(Comparator<? super T> comparator);
都是传入比较器,比较出大小。
anyMatch/allMatch/noneMatch
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
传入Predicate接口,逻辑十分简单如果满足,分别是任何一个满足,全部满足,没有一个满足
findFirst/findAny
Optional<T> findFirst();
返回一个Option接口
builder
该方法的作用就是创建一个Stream构建器,创建后就可以使用其build方法构建一个Stream。
大多数情况下我们都是使用集合的stram方法创建一个Stream,例如:
List.of(“I”,”love”,”you”).Stream()
或者是使用Stream的of方法创建Stream,例如:
Stream.of(“I”,“love”,“you”);
看下面完整的例子:
void stream_builder() {
// 方法一
Stream<String> stream1 = List.of("I","love","you","\n").stream();
stream1.forEach(System.out::print);
// 方法二
Stream<String> stream2 = Stream.of("I","love","you","too","\n");
stream2.forEach(System.out::print);
// 方法三
Stream.Builder<String> builder = Stream.builder();
builder.add("I");
builder.add("love");
builder.add("you");
builder.add("tootoo");
Stream<String> stream3 = builder.build();
stream3.forEach(System.out::print);
}
empty
创建一个空流
执行结果什么也没有输出,因为这是一个空的steam。下面例子我们往这个空的Stream中添加几个元素(实际上是生成一个新的stream):
void stream_empty() {
Stream<String> stream = Stream.empty();
List<String> list = List.of("I","love","you","and","you","love","me");
//stream.forEach(System.out::print);
Stream<String> stream1 = Stream.concat(stream, list.stream());
stream1.forEach(System.out::print);
}
of
初始化一个stream流
Stream.of("I","love","you","and","you","love","me");
concat
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
两个流合并为一个流并返回
iterate
static <T> Stream<T> iterate(T seed,
Predicate<T> hasNext,
UnaryOperator<T> next)
此方法接受三个参数:
- seed:这是初始元素,
- hasNext:谓词适用于确定流何时必须终止的元素,以及
- next:这是应用于上一个元素以产生新元素的函数。
**返回值:**此方法返回一个新的顺序Stream。
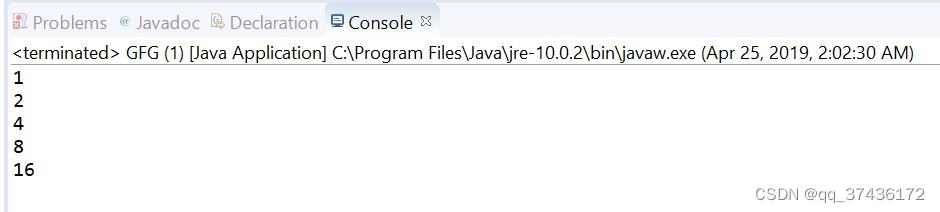
import java.util.stream.Stream;
public class GFG {
public static void main(String[] args)
{
// create a stream using iterate
Stream<Integer> stream
= Stream.iterate(1,
i -> i <= 20, i -> i * 2);
// print Values
stream.forEach(System.out::println);
}
}
输出结果
// Java program to demonstrate
// Stream.iterate method
import java.util.stream.Stream;
public class GFG {
public static void main(String[] args)
{
// create a stream using iterate
Stream<Double> stream
= Stream.iterate(2.0,
decimal -> decimal > 0.25, decimal -> decimal / 2);
// print Values
stream.forEach(System.out::println);
}
}
输出结果

generate
generate方法返回一个无限连续的无序流,其中每个元素由提供的供应商(Supplier)生成。generate方法用于生成常量流和随机元素流。
从javadoc找到generate方法声明。
static <T> Stream<T> generate(Supplier<? extends T> s)
参数:传递生成流元素的供应商(Supplier)。
返回:它返回一个新的无限顺序无序的流(Stream)。
示例1:
下面是生成随机整数流的例子
Stream<Integer> stream = Stream.generate(() -> new Random().nextInt(10));
stream.forEach(e -> System.out.println(e));
输出
2
5
1
--- #略
下面是生成常量流的示例
Stream.generate(() -> "Hello World!")
.forEach(e -> System.out.println(e));
示例2
众所周知,generate返回无限连续流,为了限制流中元素的数量,我们可以使用Stream.limit方法
package com.concretepage;
import java.util.Random;
import java.util.stream.Stream;
public class LimitGenerateDemo {
public static void main(String[] args) {
Stream.generate(() -> new Random().nextInt(10)).limit(3)
.forEach(e -> System.out.println(e));
Stream.generate(() -> new Random().nextBoolean()).limit(3)
.forEach(e -> System.out.println(e));
Stream.generate(() -> "Hello World!").limit(3)
.forEach(e -> System.out.println(e));
}
}
输出
3
1
3
true
false
false
Hello World!
Hello World!
Hello World!