һ����������������
1����װ C���Ա����� MinGW-w64:
MinGW ��ȫ����:Minimalist GNU on Windows ,��ʵ�����ǽ�����Ŀ�Դ C���� ������ GCC ��ֲ���� Windows ƽ̨��
�ٷ����ص�ַ:https://sourceforge.net/projects/mingw-w64/files/
�����صİ汾:x86_64-posix-seh
2��CMake��һ����ƽ̨�ı���(Build)����:
cmake�ٷ����ص�ַ:https://cmake.org/download/
�����صİ汾:cmake-3.24.0-rc2-windows-x86_64.zip
(1)��Ч��������Щ�ļ�֮���������ϵ�Լ���������,�������ļ��Ķ����ִ�б�Ҫ�Ĵ���,�������ظ������������,���Դ���������������Ч��;
(2)��ܵ�ʹ������ֻ��Ҫ������Դ���ͬʱ���������ṩ��CMakeLists.txt,�Ϳ�������CMake,�ڡ�ԭ���ߵİ����¡����й��̵Ĵ;
(3)makefile������һϵ�еĹ�����ָ��,��Щ�ļ���Ҫ�ȱ���,��Щ�ļ���Ҫ�����,��Щ�ļ���Ҫ���±���,�����ڽ��и����ӵĹ��ܲ���;
(4)makefile�����ĺô����ǡ���"�Զ�������",һ��д��,ֻ��Ҫһ��make����,����������ȫ�Զ�����,��������������������Ч��;
3�����ӻ�������
����֮���ѹ,���Ƶ�D��,·������:
D
|__c
|___cmake-3.24.0-rc2-windows-x86_64
|___mingw64
ϵͳ���� -> path -> ������������
D:\c\mingw64\bin
D:\c\cmake-3.24.0-rc2-windows-x86_64\bin
4��vscode����,����Ŀʹ��vscode����
- c/c++
- cmake
- cmake tools
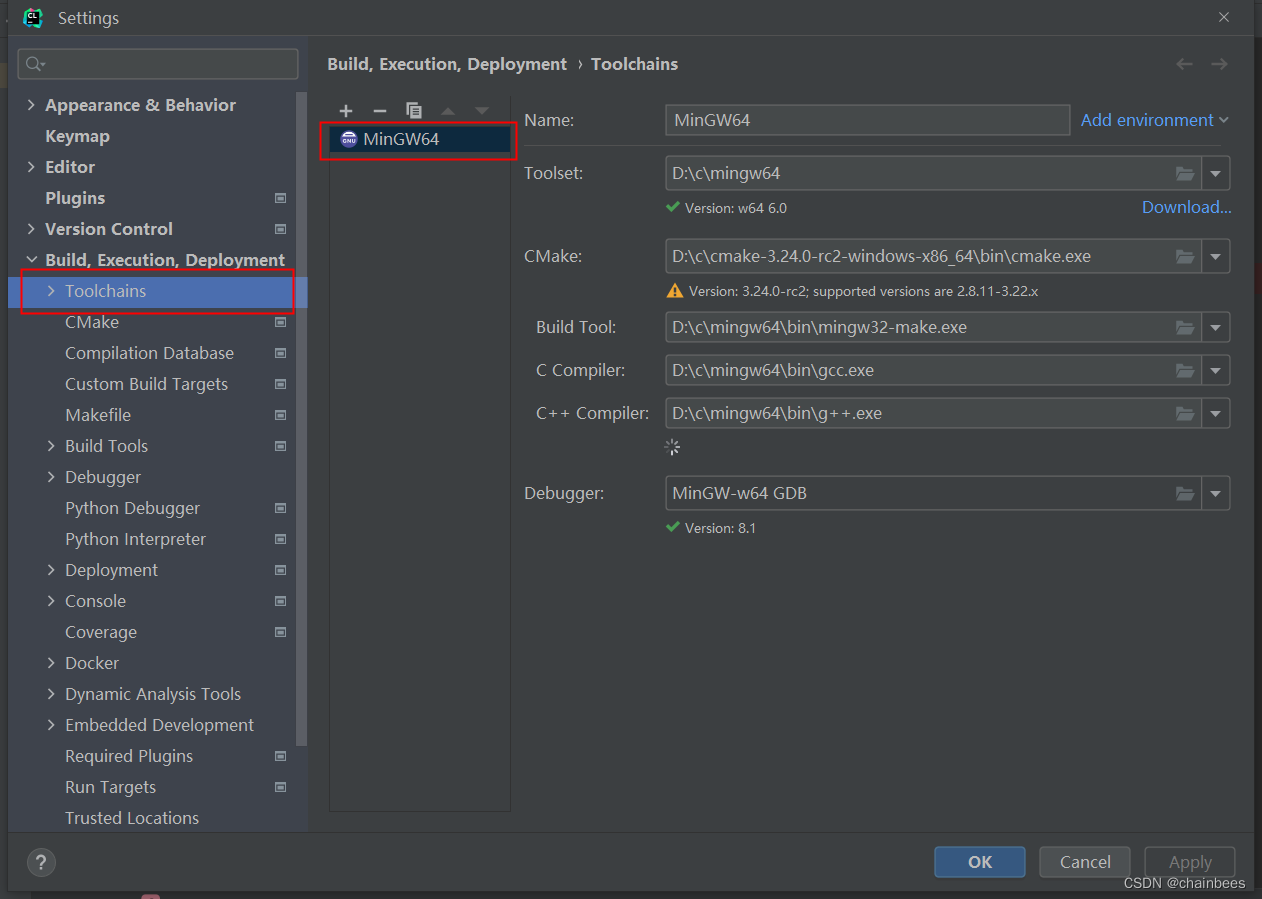
5��Clion����,������Ŀʹ��Clion����
������һ��c����
- ����g++����
? ����g++���뵥�ļ�,���ɴ�������Ϣ�Ŀ�ִ���ļ���������
g++ -g main.cpp -o my-single-swap
? ����g++������ļ�,���ɴ�������Ϣ�Ŀ�ִ���ļ���������
g++ -g main.cpp -o my-multi-swap
-
����cmake
����CMakeLists.txt
����������
#include <stdio.h>
int main()
{
return 0;
}
1�����
# \n ���з�
printf("Hello World! \n");
2������
��������
�������� ��������
int price
������ʼ��
�������� �������� = ��ʼֵ
int price = 0;
3������:�̶��������
const int AMOUNT = 100;
4����������
CPU�Ĺ���ԭ��:CPU�Ŀ��������ڴ��ȡһ��ָ�����Ĵ���
-
���ݷ�Χ:char < short < int < float < double
������˵һ����������ֳ���ʱ��,����ָ������̨�������cpu����ļĴ���һ�δ������ݵij���(32λ / 64λ),Ҳ��cpuͨ������ÿ�δ��ڴ���ȡ���ݵij���(32λ / 64λ),Ҳ������һ�ο��Դ�������ݳ���(32λ / 64λ);
# �ֽں��ַ������� �ֽ���һ����λ,��ʾ���ڴ浱�еĴ�С,1�ֽ���8�������Ƶ�λ,1���ֽڵ���8λ(bit,����); �ֽ���ָһС�����ڵĶ��������롣ͨ����8λ��Ϊһ���ֽڡ����ǹ�����Ϣ��һ��С��λ,����Ϊһ���������μӲ���; 1GB=1024MB 1MB=1024KB 1KB=1024bit �ַ���C���Ե�һ����������,ͨ����char,��ͬ����,ռ�ݲ�ͬ�ֽڴ�С;(1) ASCII��: 1��Ӣ����ĸ ռ 1���ֽ�; 1�����ĺ��� ռ 2���ֽ�; (2) UTF-8����: 1��Ӣ����ĸ ռ 1���ֽ�; 1�����ĺ��� ռ 3���ֽ�; (3) Unicode����: 1��Ӣ����ĸ ռ 2���ֽ�; 1�����ĺ��� ռ 2���ֽ�; -
��ռ�ڴ�Ĵ�С:1�ֽڵ�16�ֽ�,�ڼ�����ڲ�һ�ж��Ƕ�����
char ռ 1�ֽ� ������Χ -128 ~ 127 short ռ 2�ֽ� ������Χ -32768 ~ 32767 int ռ 4�ֽ� ��Сȡ���ڱ�����(cpu) ��C������ int �������һ���Ĵ����Ĵ�С(ѡ��������������ʱ,ѡ��int,���������ڼ�����д洢����Ҳ��int) long ռ 8�ֽ� ��Сȡ���ڱ�����(cpu) float ռ 4�ֽ� double ռ 8�ֽ� (ѡ����������ʱ,ѡ��double,�ڼ�����ڴ���cpuһ�δ����������պ���һ��double) -
�ڴ��еı���ʽ:��������(����)������
sizeof():����ij�����ͻ�������ڴ�����ռ�ݵ��ֽ���;
-
����
int ���� --> scanf("%d", ...) ��� --> printf("%d", ...) char ���� --> scanf("%c", ...) ��� --> printf("%c", ...) short long -
������
float ������ double ˫���� ���� --> scanf("%lf", ...) ��� --> printf("%f", ...) -
��
bool -
ָ��:�����ַ�ı���
int var = 20; & --> ȡ�����ĵ�ַ; ----> ��� printf("%p", &a) // ����ָ�� int *ip; // ip ��һ��ָ��,��ָ�����һ��int ip = &var; // ��ָ������д洢 var �ĵ�ַ printf("var �����ĵ�ַ: %p\n", &var ); printf("ip �����洢�ĵ�ַ: %p\n", ip ); // *�� + ָ�������,ȡָ��ָ���ֵ *ip == 20 printf("*ip ������ֵ: %d\n", *ip ); -
�Զ�������
˵��:
int a = 10;
(1) ����a �����ϴ���һ���洢��Ԫ;
(2) CPUͨ���ô洢��Ԫ�ĵ�ַ,���ʸô洢��Ԫ�е�����;
(3) ����a������������ֵ:�洢��Ԫ�ĵ�ַ�ʹ���Ԫ�е�����;
(4) ���Ǿ����˶����ԡ�Ϊ���������ֶ�����,C���Թ涨a��ʾ�洢��Ԫ�е�����,&a��ʾ�洢��Ԫ�ĵ�ַ;
(5) a�洢��Ԫ�е����ݿ�����һ����ͨ��ֵ,Ҳ��������һ���洢��Ԫ�ĵ�ַ,����:a = &b; �����ǽ�b�Ĵ洢��Ԫ�ĵ�ַ����a�洢��Ԫ��;
(6) C���Թ涨 *a���� a�д洢�ĵ�ַ��Ӧ�Ĵ洢��Ԫ�е�����,Ҳ���Ƿ���*a�͵��ڷ���b,����*a�ṩ��ͨ��a����b�е����ݵ��ֶΡ�
(7) ��C�������ַ��ָ��
(8) ��C�����е����鱾������ʵҲ��ָ��,��:*a ��ͬ�� a[]
a��ʾa��Ӧ�Ĵ洢��Ԫ�е����ݡ�
&a��ʾa��Ӧ�Ĵ洢��Ԫ�ĵ�ַ��
*a��ʾ:����,Ҫ��a��Ӧ�Ĵ洢��Ԫ�е�����һ������һ���洢��Ԫ�ĵ�ַ��
����,*a��ʾ��һ���洢��Ԫ�е����ݡ�
��a������������intʱ,a�д洢����һ��������ֵ,ͨ��a���Է���(��ȡ����)�����ֵ��
��a������������int*ʱ,a�д洢����һ���洢��Ԫ�ĵ�ַ,���ô洢��Ԫ�д洢��������һ��������ֵ;ͨ��*a���Է���(��ȡ����)�����ֵ��a == &*a ���Ǹô洢��Ԫ�ĵ�ַ��
��a������������int**ʱ,a�д洢����һ���洢��Ԫ�ĵ�ַ,���ô洢��Ԫ�д洢������������һ���洢��Ԫ�ĵ�ַ,��������洢��Ԫ�д洢����һ��������ֵ;ͨ��**a���Է���(��ȡ����)�����ֵ��
5�������
| ����ʽ | ���� | ����ʽ��ֵ |
|---|---|---|
| count++ | ��count��1 | countԭ����ֵ |
| ++count | ��count��1 | count+1�Ժ��ֵ |
| count�C | ��count��1 | countԭ����ֵ |
| �Ccount | ��count��1 | count-1�Ժ��ֵ |
��ȫ����ֻ��count++ �� count�C,��golang ����һ��
6��������
if ( a==0 ) {
x = 1;
} else if ( a==1 ) {
x = 2;
} else {
x = 3;
}
int type;
switch (type) {
case 1:
printf("���Ϻ�!");
break;
case 2:
printf("�����!");
break;
case 3:
printf("���Ϻ�!");
break;
default:
printf("�ټ�!");
break;
}
7��ѭ�����
int n = 6;
int i = 1;
int fact = 0;
for (i=1; i<=n; i++) {
fact += i;
}
printf("n = %d, fact = %d\n", n, fact);
8����������:������һ�����,���������������,��һ������,�����������һ��ֵ
void sum( int begin, int end ){
int i;
int sum = 0;
for ( i=begin; i<=end, i++ ){
sum+=i;
}
// return sum;
}
void ���ؽ��ռλ��(ʹ��void��ʾ�����ؽ��),����ָ�����ؽ����������:int,double,bool
C������ֵ���ݡ�ָ�봫�ݺ����ô���
| ���ݷ�ʽ | �������� | �������� | �����ڶ�a�ĵ�Ӱ�� |
|---|---|---|---|
| ֵ���� | fun(int a) | fun(x) | �ⲿx���� |
| ָ�봫�� | fun(int *a) | fun(&x) | �ⲿxͬ������ |
| ���ô��� | fun(int &a) | fun(x) | �ⲿxͬ������ |
9������
(1)��������
type arrayName [ arraySize ];
eg:
���ȹ̶�:double weight [ 3 ];
���Ȳ���:double height [];
type C��������
arrayName ��������
arraySize ���鳤��
������
// ����
int a[2][4];
// ��ʼ��
int a[2][4] = {
{1, 2, 3, 4},
{6, 7, 8, 9},
};
// ��ijԪ�ظ�ֵ
a[0][1]=20;
(2)�����ʼ��
double weight [3] = {46.2, 47.1, 49.6};
# ������weight ��2��Ԫ�ص�ֵ,��Ϊ 50.2
weight[2] = 50.2;
(3)��������Ԫ��,ͨ���±����
double yi = weight[2];
10��enum(ö��)
(1)����ö��
enum��ö������{ö��Ԫ��1,ö��Ԫ��2,����};
enum DAY
{
MON=1, TUE, WED, THU, FRI, SAT, SUN
};
// һ��ö�ٳ�Ա��Ĭ��ֵΪ���͵� 0,����ö�ٳ�Ա��ֵ��ǰһ����Ա�ϼ� 1
// ����һ��ö�ٱ���
enum DAY day;
day = WED;
printf("%d",day);
11��C �ַ���:
�� C ������,�ַ���ʵ������ʹ�ÿ��ַ� \0 ��β��һά�ַ����顣���,\0 �����ڱ���ַ����Ľ�����
���ַ�(Null character)�ֳƽ�����,��д null,��һ����ֵΪ 0 �Ŀ����ַ�,\0 ��ת���ַ�,��˼�Ǹ��߱�����,�ⲻ���ַ� 0,���ǿ��ַ���
(1)�����ַ���
// �����������ĩβ�洢�˿��ַ� \0,�����ַ�����Ĵ�С�ȵ��� RUNOOB ���ַ�����һ��
char [7] = {'R', 'U', 'N', 'O', 'O', 'B', '\0'};
// ���������ʼ������,��������������д���������,���Ҫ����һ���ַ��������������д��;
char site[] = "RUNOOB";
// ���Ҫ����һ���ַ���������ָ���д��;
char *str = "RUNOOB";
(2)C ���д��������ַ����ĺ���
| ��� | ���� & Ŀ�� |
|---|---|
| 1 | strcpy(s1, s2); �����ַ��� s2 ���ַ��� s1�� |
| 2 | strcat(s1, s2); �����ַ��� s2 ���ַ��� s1 ��ĩβ�� |
| 3 | strlen(s1); �����ַ��� s1 �ij��ȡ� |
| 4 | strcmp(s1, s2); ��� s1 �� s2 ����ͬ��,�� 0;��� s1<s2 ��С�� 0;��� s1>s2 �ش��� 0�� |
| 5 | strchr(s1, ch); ����һ��ָ��,ָ���ַ��� s1 ���ַ� ch �ĵ�һ�γ��ֵ�λ�á� |
| 6 | strstr(s1, s2); ����һ��ָ��,ָ���ַ��� s1 ���ַ��� s2 �ĵ�һ�γ��ֵ�λ�á� |
12��C �ṹ��
(1)����ṹ��
-
Books �ǽṹ���ǩ;
-
title ,author,book_id,�ṹ��ij�Ա;
-
book �ṹ����,�����ڽṹ��ĩβ,������ָ��һ�������ṹ����,���������� Book �ṹ�ķ�ʽ;
struct Books
{
char title[50];
char author[50];
int book_id;
} book;
(2)�ṹ������ij�ʼ��
#include <stdio.h>
struct Books
{
char title[50];
char author[50];
char subject[100];
int book_id;
} book = {"C ����", "RUNOOB", "�������", 123456};
int main()
{
printf("title : %s\nauthor: %s\nsubject: %s\nbook_id: %d\n", book.title, book.author, book.subject, book.book_id);
}