����Ŀ¼
һ��Linux ������������ yum
1. yum��ʲô
��Linux�°�װ����, һ��ͨ���İ취�����ص������Դ����, �����б���, �õ���ִ�г�������������̫�鷳��, ������Щ�˰�һЩ���õ�������ǰ�����, ����������(���������windows�ϵİ�װ����)����һ����������, ͨ�������������Ժܷ���Ļ�ȡ���������õ�������, ֱ�ӽ��а�װ��
��������������������, �ͺñ� ��App�� �� ��Ӧ���̵ꡱ �����Ĺ�ϵ
yum(Yellow dog Updater, Modified)��Linux�·dz����õ�һ�ְ�������. ��ҪӦ����Fedora, RedHat, Centos�ȷ��а��ϡ�
2. ��ΰ�װ����
ͨ�� yum, ���ǿ���ͨ���ܼ�һ��������� gcc �İ�װ:
sudo yum install lrzsz
yum ���Զ��ҵ�������Щ��������Ҫ����, ��ʱ���� ��y�� ȷ�ϰ�װ,������complete,��ʾ��װ���!
��װ����ʱ������Ҫ��ϵͳĿ¼��д������, һ����Ҫ sudo �����е� root �˻��²�����ɡ�
yum��װ����ֻ��һ��װ������װ��һ��. ����yum��װһ�������Ĺ�����, ����ٳ�����yum��װ����һ������, yum�ᱨ����
3. �鿴������
ͨ�� yum list ����������г���ǰһ������Щ������. ���ڰ�����Ŀ���ܷdz�֮��, ����������Ҫʹ�� grep ����ֻɸѡ�����ǹ�ע�İ�. ����:
yum list | grep lrzsz

����������: ���汾��.�ΰ汾��.Դ�����к�-�������ķ��к�.����ƽ̨.cpu�ܹ���
��x86_64�� ����ʾ64λϵͳ�İ�װ��, ��i686�� ����ʾ32λϵͳ��װ��. ѡ���ʱҪ��ϵͳƥ�䡣
��el7�� ��ʾ����ϵͳ���а�İ汾. ��el7�� ��ʾ���� centos7/redhat7. ��el6�� ��ʾ centos6/redhat6��
���һ��, base ��ʾ���� ������Դ�� ������, ������ ��С��Ӧ���̵ꡱ, ����ΪӦ���̵ꡱ �����ĸ��
4. ����
ͨ������ָ���ж����Ӧ����:
sudo yum remove lrzsz(������)
����rzsz:
����������� windows ������Զ�˵� Linux ����ͨ�� XShell �����ļ�,��װ���֮�����ͨ����ק�ķ�ʽ���ļ��ϴ���ȥ.
����vim��ʹ��
vi/vim���������˵,���Ƕ��Ƕ�ģʽ�༭��,��ͬ����vim��vi�������汾,����������vi������ָ��,���һ���һЩ�µ����������档
1.vim�Ļ�������
vim�����ֻ���ģʽ,�ֱ�������ģʽ(command mode)������ģʽ(Insert mode)�͵���ģʽ(last line mode),��ģʽ�Ĺ�����������:
����/��ͨ/����ģʽ(Normal mode):
������Ļ�����ƶ�,�ַ����ֻ��е�ɾ��,�ƶ�����ij���μ�����Insert mode��,���ߵ� last line mode
����ģʽ(Insert mode):
ֻ����Insert mode��,�ſ�������������,����ESC�����ɻص�������ģʽ��
ĩ��ģʽ(last line mode):
�ļ�������˳�,Ҳ���Խ����ļ��滻,���ַ���,�г��кŵȲ����� ������ģʽ��,shift+: ���ɽ����ģʽ��Ҫ�鿴�������ģʽ:��vim,����ģʽֱ������.
2.vim��������
����vim,��ϵͳ��ʾ��������vim���ļ����ƺ�,�ͽ���vimȫ��Ļ�༭����:
vim file1.txt

����vim��,������ͨģʽ,���Ҫ�༭,����Ҫ�л����༭ģʽ��
[����ģʽ]�л���[����ģʽ],��������a,i��o
�Ӳ���ģʽ�л�������ģʽֻ��Ҫ����ESC
������ģʽ�༭������,Ҫ�����ļ�,����shift + :,��������w���ɱ���
����wq,���沢�˳�,ֻ����q,ֱ���˳�,������
3.vim����ģʽ�������
�ƶ����:
vim����ֱ���ü����ϵĹ�������������ƶ�,�������vim����СдӢ����ĸ��h������j������k������l��,�ֱ���ƹ�����¡��ϡ�����һ��
����G��:�ƶ������µ����
���� $ ��:�ƶ�����������еġ���β��
����^��:�ƶ�����������еġ����ס�
����w��:��������¸��ֵĿ�ͷ
����e��:��������¸��ֵ���β
����b��:���ص��ϸ��ֵĿ�ͷ
����#l��:����Ƶ����еĵ�#��λ��
��[gg]:���뵽�ı���ʼ
��[shift+g]:�����ı�ĩ��
����ctrl��+��b��:��Ļ�������ƶ�һҳ
����ctrl��+��f��:��Ļ����ǰ���ƶ�һҳ
����ctrl��+��u��:��Ļ�������ƶ���ҳ
����ctrl��+��d��:��Ļ����ǰ���ƶ���ҳ
ɾ������:
��x��:ÿ��һ��,ɾ���������λ�õ�һ���ַ�
��#x��:����,��6x����ʾɾ���������λ�õġ�����(�����Լ�����)��6���ַ�
��X��:��д��X,ÿ��һ��,ɾ���������λ�õġ�ǰ�桱һ���ַ�
��#X��:����,��20X����ʾɾ���������λ�õġ�ǰ�桱20���ַ�
��dd��:ɾ�����������
��#dd��:�ӹ�������п�ʼɾ��#��
����:
��yw��:���������֮������β���ַ����Ƶ���������
��#yw��:����#���ֵ�������
��yy��:���ƹ�������е�������
��#yy��:����,��6yy����ʾ�����ӹ�����ڵĸ��С���������6������
��p��:���������ڵ��ַ������������λ�á�ע��:�����롰y���йصĸ�����������롰p����ϲ�����ɸ�����ճ������
�滻:
��r��:�滻������ڴ����ַ�
��R��:�滻�������֮�����ַ�,ֱ�����¡�ESC����Ϊֹ
������һ�β���:
��u��:�������ִ��һ������,�������ϰ��¡�u��,�ص���һ������������Ρ�u������ִ�ж�λظ���
��ctrl + r��: �����Ļָ�
����:
��cw��:���Ĺ�����ڴ����ֵ���β��
��c#w��:����,��c3w����ʾ����3����
����ָ������:
��ctrl��+��g���г���������е��к�
��#G��:����,��15G��,��ʾ�ƶ���������µĵ�15������
4.vimĩ��ģʽ���
��ʹ��ĩ��ģʽ֮ǰ,���ס�Ȱ���ESC����ȷ�����Ѿ���������ģʽ,�ٰ���:��ð�ż��ɽ���ĩ��ģʽ��
�г��к�:
��set nu��: ���롸set nu����,�����ļ��е�ÿһ��ǰ���г��кš�
�����ļ��е�ijһ��:
��#��:��#���ű�ʾһ������,��ð�ź�����һ������,�ٰ��س����ͻ�����������,����������15,�ٻس�,�ͻ��������µĵ�15�С�
�����ַ�:
��/�ؼ��֡�: �Ȱ���/����,����������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�������Ҫ��,����һֱ����n��������Ѱ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
��?�ؼ��֡�:�Ȱ���?����,����������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�������Ҫ��,����һֱ����n������ǰѰ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
�����ļ�:
��w��: ��ð��������ĸ��w���Ϳ��Խ��ļ���������
�뿪vim:
��q��:����q�������˳�,������뿪vim,�����ڡ�q�����һ����!��ǿ���뿪vim��
��wq��:һ�㽨���뿪ʱ,���䡸w��һ��ʹ��,�������˳���ʱ���Ա����ļ���
����Linux������
1.gcc��g++�ı��벽��
�����Ѿ�֪��,һ��Դ����Ҫ��ɿ�ִ���ļ�Ҫ�������¼�������:Ԥ���������롢�������ӡ�
ͨ��gcc���������ǽ����⼸������IJ���:
gcc [ѡ��] Ҫ������ļ� [ѡ��] [Ŀ���ļ�]
Ԥ����:
Ԥ����������Ҫ�����궨��,�ļ�����,��������,ȥע�͵�,ͨ�������ָ����ñ�������Ԥ������ɺ�ֹͣ�������:
gcc �CE hello.c �Co hello.i
ѡ�-E��,��ѡ����������� gcc ��Ԥ����������ֹͣ������̡�ѡ�-o����ָĿ���ļ�,��.i���ļ�Ϊ�Ѿ���Ԥ������Cԭʼ����
����:
���������,gcc ����Ҫ������Ĺ淶�ԡ��Ƿ���������,��ȷ�������ʵ��Ҫ���Ĺ���,�ڼ��
�����,gcc �Ѵ��뷭��ɻ�����ԡ�����ʹ�á�-S��ѡ�������в鿴,��ѡ��ֻ���б���������л��,���ɻ����롣
gcc �CS hello.i �Co hello.s
���:
�����ǰѱ�������ɵġ�.s���ļ�ת��Ŀ���ļ�,�ڴ˿�ʹ��ѡ�-c���Ϳɿ�����������ת��Ϊ��.o���Ķ�����Ŀ�����:
gcc �Cc hello.s �Co hello.o
����((���ɿ�ִ���ļ�����ļ�):
gcc hello.o �Co hello
2.������
���ǵ�C������,��û�ж��塰printf���ĺ���ʵ��,����Ԥ�����а����ġ�stdio.h����Ҳֻ�иú���������,��û�ж��庯����ʵ��,ϵͳ����Щ����ʵ�ֶ���������Ϊ libc.so.6 �Ŀ��ļ���ȥ��,��û���ر�ָ��ʱ,gcc �ᵽϵͳĬ�ϵ�����·����/usr/lib���½��в���,Ҳ�������ӵ� libc.so.6 �⺯����ȥ,��������ʵ�ֺ�����printf����,����Ҳ�������ӵ����á�
��̬��:
��̬����ָ��������ʱ,�ѿ��ļ��Ĵ���ȫ�����뵽��ִ���ļ���,������ɵ��ļ��Ƚϴ�,��������ʱҲ�Ͳ�����Ҫ���ļ��ˡ������һ��Ϊ��.a��
��̬��:
��̬����֮�෴,�ڱ�������ʱ��û�аѿ��ļ��Ĵ�����뵽��ִ���ļ���,�����ڳ���ִ��ʱ������ʱ�����ļ����ؿ�,�������Խ�ʡϵͳ�Ŀ�������̬��һ�����Ϊ��.so��,��ǰ�������� libc.so.6 ���Ƕ�̬�⡣gcc �ڱ���ʱĬ��ʹ�ö�̬�⡣���������֮��,gcc �Ϳ������ɿ�ִ���ļ�
��gccĬ�����ɵĶ����Ƴ���,�Ƕ�̬���ӵ�,������ͨ�� file ������֤��
�ġ�Linux������
1.gdb����
����ķ�����ʽ������,debugģʽ��releaseģʽ,Linux gcc/g++��������Ķ����Ƴ���,Ĭ����releaseģʽ,Ҫʹ��gdb����,������Դ�������ɶ����Ƴ����ʱ��, ���� -g ѡ�
2.gdb��ʹ��
list/l �к�:��ʾbinFileԴ����,�����ϴε�λ��������,ÿ����10�С�
list/l ������:�г�ij��������Դ���롣
r��run:�����
n �� next:����ִ�С�
s��step:���뺯������
break(b) �к�:��ijһ�����öϵ�
break ������:��ij��������ͷ���öϵ�
info break :�鿴�ϵ���Ϣ��
finish:ִ�е���ǰ��������,Ȼ��ͦ�����ȴ�����
print(p):��ӡ����ʽ��ֵ,ͨ������ʽ�����ı�����ֵ���ߵ��ú���
p ����:��ӡ����ֵ��
set var:�ı�����ֵ
continue(��c):�ӵ�ǰλ�ÿ�ʼ�������ǵ���ִ�г���
run(��r):�ӿ�ʼ�������ǵ���ִ�г���
delete breakpoints:ɾ�����жϵ�
delete breakpoints n:ɾ�����Ϊn�Ķϵ�
disable breakpoints:���öϵ�
enable breakpoints:���öϵ�
info(��i) breakpoints:�ο���ǰ��������Щ�ϵ�
display ������:���ٲ鿴һ������,ÿ��ͣ��������ʾ����ֵ
undisplay:ȡ������ǰ���õ���Щ�����ĸ���
until X�к�:����X��
breaktrace(��bt):�鿴�����������ü�����
info(i) locals:�鿴��ǰջ֡�ֲ�������ֵ
quit:�˳�gdb
�塢�Զ�����������
һ�������е�Դ�ļ�������,�䰴���͡����ܡ�ģ��ֱ�������ɸ�Ŀ¼��,makefile������һϵ�еĹ�����ָ��,��Щ�ļ���Ҫ�ȱ���,��Щ�ļ���Ҫ�����,��Щ�ļ���Ҫ���±���,�����ڽ��и����ӵĹ��ܲ�����
makefile�����ĺô����ǡ������Զ������롱,һ��д��,ֻ��Ҫһ��make����,����������ȫ�Զ�����,��������������������Ч�ʡ�
make��һ�������,��һ������makefile��ָ��������,һ����˵,�������IDE�����������,����:Delphi��make,Visual C++��nmake,Linux��GNU��make���ɼ�,makefile����Ϊ��һ���ڹ��̷���ı��뷽����
make��һ������,makefile��һ���ļ�,��������ʹ��,�����Ŀ�Զ���������
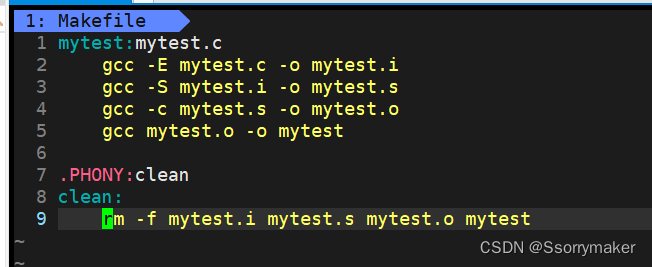
������ϵ:mytest������mytest.o,mytest.o������mytest.s,mytest.s������mytest.i,mytest.i������mytest.c
1.make/makefileԭ��
make���ڵ�ǰĿ¼�������ֽС�Makefile����makefile�����ļ�������ҵ�,�������ļ��еĵ�һ��Ŀ���ļ�(target),�������������,�����ҵ���mytest������ļ�,��������ļ���Ϊ���յ�Ŀ���ļ��� ���mytest�ļ�������,����mytest�������ĺ����mytest.o�ļ����ļ���ʱ��Ҫ��mytest����ļ���(������ touch ����),��ô,���ͻ�ִ�к��������������������mytest����ļ���
���mytest��������mytest.o�ļ�������,��ômake���ڵ�ǰ�ļ�����Ŀ��Ϊmytest.o�ļ���������,����ҵ����ٸ�����һ����������mytest.o�ļ���(���е���һ����ջ�Ĺ���)
���������make��������,make��һ����һ���ȥ���ļ���������ϵ,ֱ�����ձ������һ��Ŀ���ļ�
2.��Ŀ����
��clean����,û�б���һ��Ŀ���ļ�ֱ�ӻ��ӹ���,��ô�������������������ᱻ�Զ�ִ��,����,���ǿ�����ʾҪmakeִ�С����������make clean��,�Դ���������е�Ŀ���ļ�,�Ա��ر��롣����һ����������clean��Ŀ���ļ�,���ǽ�������ΪαĿ��,�� .PHONY ����,αĿ���������,���DZ�ִ�еġ�