ФПТМ
Part1-ДгgitгыgithubПЊЪМ
GitHub ЪЧвЛИігУгкАцБОПижЦКЭазїЕФДњТыЭаЙмЦНЬЈ,taФмЙЛШУФуКЭШЮКЮЕиЗНЕФЦфЫћЙЄзїепвЛЦ№зіЯюФПЁЃ
GitЪЧФПЧАЪРНчЩЯзюЯШНјЕФЗжВМЪНАцБОПижЦЯЕЭГ
git clone
гУгкДгgithubЩЯЯТдидДТы

?
git init
ШчЙћЪЧздМКаТДДНЈвЛИіЮФМўМа,ОЭдкРяБпgit
ШЛКѓИцЫпgitЙмРэетИіЮФМўМаЯТЕФДњТы
ОЭЪЧЪфШыgit init
дкЙЄзїЧјаДЭъЮФМўМаЪБ,ЬсНЛ
git add .(ШчЙћВЛЪЧЬсНЛетИіЮФМўМаЯТЫљгаЕФ,ОЭАбЕуИФГЩвЊЬсНЛЕФЮФМўУћОЭаа)
ДЫЪБ,ФЧИіЮФМўОЭЛсНјШызМБИЬсНЛЕФзДЬЌ(АбЮФМўМгШыднДцЧј)
git comit -m "етРяаДБИзЂ"
етбљ,gitЛсвдЪ§ОнПтЕФаЮЪНАбДњТыБЃДцдкgitВжПтжа
гУgit log РДВщПДЬсНЛЕФРњЪЗМЧТМ
git checkout HEAD вЊЛжИДЕФЮФМў
Part2-ЖдSTLЕФГѕВНИХРР
СљДѓзщМў
- ЗжХфЦї:гУРДЙмРэФкДцЁЃ
- ЕќДњЦї:НЋШнЦїКЭЫуЗЈеГКЯдквЛЦ№,гУРДБщРњSTLШнЦїжаЕФВПЗжЛђШЋВПдЊЫиЁЃ
- ШнЦї:ЗтзАСЫДѓСПГЃгУЕФЪ§ОнНсЙЙЁЃ
- ЫуЗЈ:ЖЈвхСЫвЛаЉГЃгУЫуЗЈЁЃ
- ЗТКЏЪ§:ОпгаКЏЪ§ЬижЪЕФЖдЯѓЁЃ
- ЪЪХфЦї:жївЊгУРДаоИФНгПкЁЃ
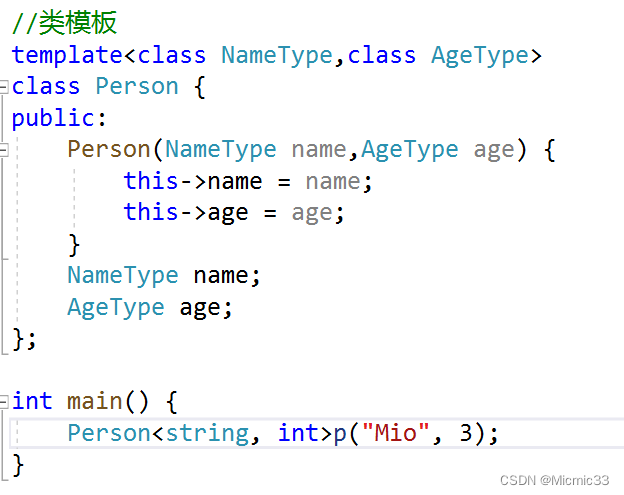
template
STLЖМгУЕНСЫtemplate!КмживЊ
дкC++жа,Г§СЫУцЯђЖдЯѓ,ЛЙгавЛжжБрГЬЫМЯы:ЗКаЭБрГЬ
жївЊЛљгкФЃАхРДЪЕЯж
ЁО1.КЏЪ§ФЃАхЁП



?
?
?ЁО2.РрФЃАхЁП

?
(C++аТЬиаджЇГжздЖЏРраЭЭЦЕМСЫ)?
?
?
?
?

?ШєвЊСщЛюжИЖЈ:

?

ДњТыИХРР

ЖЈвхСЫЪфГіЕФбеЩЋ

?
?Part3-дДТыдФЖСгыЦЪЮі
ЁОЗжХфЦїЁП
?ВЮПМЮФеТ2
?
C++жаЕФnew
new(new operator)зіСНМўЪТ
ЕїгУopeartor newЗжХфФкДц(operator newЛсМфНгЕїгУmalloc)
ЕїгУЙЙдьКЏЪ§ГѕЪМЛЏФкДцжаЕФЖдЯѓ(placement new)
ЭЌбљЕФ,deleteИКд№
ЕїгУЮіЙЙКЏЪ§
ЕїгУfreeЪЭЗХФкДц
ЗжХфЦїИХЪі
allocate()ЪЕЯжПеМфЕФЩъЧы
ЩъЧыФкДцЗжЮЊвЛМЖХфжУЦїКЭЖўМЖХфжУЦї, ЗжХфЕФПеМфаЁгк128зжНкЕФОЭЕїгУЖўМЖХфжУЦї, ДѓгкОЭжБНгЪЙгУвЛМЖХфжУЦї, вЛМЖХфжУЦїжБНгЕїгУmallocЩъЧы, ЖўМЖЪЙгУФкДцГи.
template<class T>
inline T* allocate(ptrdiff_t size, T*)
{
set_new_handler(0);
T* tmp = (T*)(::operator new(size)(size * sizeof(T)));
if(!tmp)
{
cerr << "out of memort" << endl;
exit(1);
}
return tmp;
}
construct()ЪЕЯждквбЛёЕУЕФФкДцРяНЈСЂвЛИіЖдЯѓ
// етРяЕФconstructЕїгУЕФЪЧplacement new, дквЛИівбОЛёЕУЕФФкДцРяНЈСЂвЛИіЖдЯѓ
template <class T1, class T2>
inline void construct(T1* p, const T2& value)
{
new (p) T1(value);
}
ЁАdeleteЁБЪЕЯж:
destory()ЪЕЯжЕїгУЮіЙЙКЏЪ§,гаСНИіАцБО
// ЕквЛАцБО, НгЪежИеы
template <class T> inline void destroy(T* pointer)
{
pointer->~T();
}
// ЕкЖўИіАцБОЕФ, НгЪмСНИіЕќДњЦї, ВЂЩшЗЈевГідЊЫиЕФРраЭ. ЭЈЙ§__type_trais<> евГізюМбДыЪЉ
template <class ForwardIterator>
inline void destroy(ForwardIterator first, ForwardIterator last)
{
__destroy(first, last, value_type(first));
}
// НгЪмСНИіЕќДњЦї, вд__type_trais<> ХаЖЯЪЧЗёгаtraival destructor
template <class ForwardIterator, class T>
inline void __destroy(ForwardIterator first, ForwardIterator last, T*)
{
typedef typename __type_traits<T>::has_trivial_destructor trivial_destructor;
__destroy_aux(first, last, trivial_destructor());
}
?__type_traitsЮЊ__false_typeЪБ
// УЛгаnon-travial destructor
template <class ForwardIterator>
inline void __destroy_aux(ForwardIterator first, ForwardIterator last, __false_type)
{
for ( ; first < last; ++first)
destroy(&*first);
}
__type_traitsЮЊ__true_typeЪБ
ЪВУДвВВЛзі,вђЮЊетбљаЇТЪКмИп,ВЛашвЊжДааЮіЙЙКЏЪ§
// гаtravial destructor
template <class ForwardIterator>
inline void __destroy_aux(ForwardIterator, ForwardIterator, __true_type) {}
АцБО2ЕФЬиЛЏАц?
inline void destroy(char*, char*) {}
inline void destroy(wchar_t*, wchar_t*) {}
вЛМЖЗжХфЦї(ЪЧвЛИіРр)
STLЖдmallocКЭfreeгУКЏЪ§жиаТНјааСЫЗтзА
allocate
// дкЗжХфКЭдйДЮЗжХфжа, ЖМЛсМьВщФкДцВЛзу, дкВЛзуЕФЪБКђжБНгЕїгУprivateжаЯргІЕФКЏЪ§
static void * allocate(size_t n)
{
void *result = malloc(n);
if (0 == result) result = oom_malloc(n);
return result;
}
deallocate
static void deallocate(void *p, size_t /* n */)
{
free(p); //вЛМЖХфжУЦїжБНгЕїгУfreeЪЭЗХФкДц
}
ЭГвЛЕФНгПк
// ЖЈвхЗћКЯSTLЙцИёЕФХфжУЦїНгПк, ВЛЙмЪЧвЛМЖХфжУЦїЛЙЪЧЖўМЖХфжУЦїЖМЪЧЪЙгУетИіНгПкНјааЗжХфЕФ
template<class T, class Alloc>
class simple_alloc {
public:
static T *allocate(size_t n)
{ return 0 == n? 0 : (T*) Alloc::allocate(n * sizeof (T)); }
static T *allocate(void)
{ return (T*) Alloc::allocate(sizeof (T)); }
static void deallocate(T *p, size_t n)
{ if (0 != n) Alloc::deallocate(p, n * sizeof (T)); }
static void deallocate(T *p)
{ Alloc::deallocate(p, sizeof (T)); }
};
ЕкЖўМЖЗжХфЦї?
ЕквЛМЖЪЧжБНгЕїгУmallocЗжХфПеМф, ЕїгУfreeЪЭЗХПеМф, ЕкЖўМЖОЭЪЧНЈСЂвЛИіФкДцГи
гУСДБэРДБЃДцВЛЭЌзжНкДѓаЁЕФФкДцПщ, ОЭКмШнвзЕФНјааЮЌЛЄ, ЖјЧвУПДЮЕФФкДцЗжХфЖМжБНгПЩвдДгСДБэЛђепФкДцГижаЛёЕУ, ЬсЩ§СЫЮвУЧЩъЧыФкДцЕФаЇТЪ, БЯОЙУПДЮЕїгУmallocКЭfreeгаПЊЯњ, ЬиБ№ЪЧКмаЁФкДцЕФЪБКђ
STLНЋЕкЖўМЖХфжУЦїЩшжУЮЊФЌШЯЕФ
3ИіГЃСП&вЛИіКъВйзї
// ЖўМЖХфжУЦї
enum {__ALIGN = 8}; // ЩшжУЖдЦывЊЧѓ. ЖдЦыЮЊ8зжНк, УЛга8зжНкздЖЏВЙЦы
enum {__MAX_BYTES = 128}; // ЕкЖўМЖХфжУЦїЕФзюДѓвЛДЮадЩъЧыДѓаЁ, Дѓгк128ОЭжБНгЕїгУЕквЛМЖХфжУЦї
enum {__NFREELISTS = __MAX_BYTES/__ALIGN}; // СДБэИіЪ§, ЗжБ№ДњБэ8, 16, 32....зжНкЕФСДБэ
static size_t FREELIST_INDEX(size_t bytes) \
{\
return (((bytes) + ALIGN-1) / __ALIGN - 1);\
}
allocate()
- ЯШХаЖЯЩъЧыЕФзжНкДѓаЁЪЧВЛЪЧДѓгк128зжНк, ЪЧ, дђНЛИјЕквЛМЖХфжУЦїРДДІРэ. Зё, МЬајЭљЯТжДаа
- евЕНЗжХфЕФЕижЗЖдЦыКѓЗжХфЕФЪЧЕкМИИіДѓаЁЕФСДБэ.
- ЛёЕУИУСДБэжИЯђЕФЪзЕижЗ, ШчЙћСДБэУЛгаЖргрЕФФкДц, ОЭЯШЬюГфСДБэ.
- ЗЕЛиСДБэЕФЪзЕижЗ, КЭвЛПщФмШнФЩвЛИіЖдЯѓЕФФкДц, ВЂИќаТСДБэЕФЪзЕижЗ
static void * allocate(size_t n)
{
obj * __VOLATILE * my_free_list;
obj * __RESTRICT result;
if (n > (size_t) __MAX_BYTES)
{
return(malloc_alloc::allocate(n));
}
my_free_list = free_list + FREELIST_INDEX(n);
result = *my_free_list;
if (result == 0) // УЛгаЖргрЕФФкДц, ОЭЯШЬюГфСДБэ.
{
void *r = refill(ROUND_UP(n));
return r;
}
*my_free_list = result -> free_list_link;
return (result);
};
refill()ФкДцЬюГф
- ЯђФкДцГиЩъЧыПеМфЕФЦ№ЪМЕижЗ
- ШчЙћжЛЩъЧыЕНвЛИіЖдЯѓЕФДѓаЁ, ОЭжБНгЗЕЛивЛИіФкДцЕФДѓаЁ, ШчЙћгаИќЖрЕФФкДц, ОЭМЬајжДаа
- ДгЕкЖўИіПщФкДцПЊЪМ, АбДгФкДцГиРяУцЗжХфЕФФкДцгУСДБэИјДЎЦ№РД, ВЂЗЕЛивЛИіПщФкДцЕФЕижЗИјгУЛЇ
// ФкДцЬюГф
template <bool threads, int inst>
void* __default_alloc_template<threads, inst>::refill(size_t n)
{
int nobjs = 20;
char * chunk = chunk_alloc(n, nobjs); // ЯђФкДцГиЩъЧыПеМфЕФЦ№ЪМЕижЗ
obj * __VOLATILE * my_free_list;
obj * result;
obj * current_obj, * next_obj;
int i;
// ШчЙћжЛЩъЧыЕНвЛИіЖдЯѓЕФДѓаЁ, ОЭжБНгЗЕЛивЛИіФкДцЕФДѓаЁ
if (1 == nobjs) return(chunk);
my_free_list = free_list + FREELIST_INDEX(n);
// ЩъЧыЕФДѓаЁВЛжЛвЛИіЖдЯѓЕФДѓаЁЕФЪБКђ
result = (obj *)chunk;
// my_free_listжИЯђФкДцГиЗЕЛиЕФЕижЗЕФЯТвЛИіЖдЦыКѓЕФЕижЗ
*my_free_list = next_obj = (obj *)(chunk + n);
// етРяДгЕкЖўИіПЊЪМЕФдвђжївЊЪЧЕквЛПщЕижЗЗЕЛиИјСЫгУЛЇ, ЯждкашвЊАбДгФкДцГиРяУцЗжХфЕФФкДцгУСДБэИјДЎЦ№РД
for (i = 1; ; i++)
{
current_obj = next_obj;
next_obj = (obj *)((char *)next_obj + n);
if (nobjs - 1 == i)
{
current_obj -> free_list_link = 0;
break;
}
else
{
current_obj -> free_list_link = next_obj;
}
}
return(result);
}
deallocate()
- ЪЭЗХЕФФкДцДѓгк128зжНкжБНгЕїгУвЛМЖХфжУЦїНјааЪЭЗХ
- НЋФкДцжБНгЛЙИјЖдгІДѓаЁЕФСДБэОЭааСЫ, ВЂВЛгУжБНгЪЭЗХФкДц, вдБуКѓУцЗжХфФкДц
static void deallocate(void *p, size_t n)
{
obj *q = (obj *)p;
obj * __VOLATILE * my_free_list;
// ЪЭЗХЕФФкДцДѓгк128зжНкжБНгЕїгУвЛМЖХфжУЦїНјааЪЭЗХ
if (n > (size_t) __MAX_BYTES)
{
malloc_alloc::deallocate(p, n);
return;
}
my_free_list = free_list + FREELIST_INDEX(n);
q -> free_list_link = *my_free_list;
*my_free_list = q;
}
ФкДцГи
// ФкДцГи
template <bool threads, int inst>
char* __default_alloc_template<threads, inst>::chunk_alloc(size_t size, int& nobjs)
{
char * result;
size_t total_bytes = size * nobjs; // СДБэашвЊЩъЧыЕФФкДцДѓаЁ
size_t bytes_left = end_free - start_free; // ФкДцГиРяУцзмЙВЛЙгаЖрЩйФкДцПеМф
// ФкДцГиЕФДѓаЁДѓгкашвЊЕФПеМф, жБНгЗЕЛиЦ№ЪМЕижЗ
if (bytes_left >= total_bytes)
{
result = start_free;
start_free += total_bytes; // ФкДцГиЕФЪзЕижЗЭљКѓвЦ
return(result);
}
// ФкДцГиЕФФкДцВЛзувдТэЩЯЗжХфФЧУДЖрФкДц, ЕЋЪЧЛЙФмТњзуЗжХфвЛИіМДвдЩЯЕФДѓаЁ, ФЧОЭАДЖдЦыЗНЪНШЋВПЗжХфГіШЅ
else if (bytes_left >= size)
{
nobjs = bytes_left/size;
total_bytes = size * nobjs;
result = start_free;
start_free += total_bytes; // ФкДцГиЕФЪзЕижЗЭљКѓвЦ
return(result);
}
else
{
// ШчЙћвЛИіЖдЯѓЕФДѓаЁЖМвбОЬсЙЉВЛСЫСЫ, ФЧОЭзМБИЕїгУmallocЩъЧыСНБЖ+ЖюЭтДѓаЁЕФФкДц
size_t bytes_to_get = 2 * total_bytes + ROUND_UP(heap_size >> 4);
// Try to make use of the left-over piece.
// ФкДцГиЛЙЪЃЯТЕФСуЭЗФкДцЗжИјИјЦфЫћФмРћгУЕФСДБэ, вВОЭЪЧОјВЛРЫЗбвЛЕу.
if (bytes_left > 0)
{
// СДБэжИЯђЩъЧыФкДцЕФЕижЗ
obj * __VOLATILE * my_free_list = free_list + FREELIST_INDEX(bytes_left);
((obj *)start_free) -> free_list_link = *my_free_list;
*my_free_list = (obj *)start_free;
}
start_free = (char *)malloc(bytes_to_get);
// ФкДцВЛзуСЫ
if (0 == start_free)
{
int i;
obj * __VOLATILE * my_free_list, *p;
// ГфЗжРћгУЪЃгрСДБэЕФФкДц, ЭЈЙ§ЕнЙщРДЩъЧы
for (i = size; i <= __MAX_BYTES; i += __ALIGN)
{
my_free_list = free_list + FREELIST_INDEX(i);
p = *my_free_list;
if (0 != p)
{
*my_free_list = p -> free_list_link;
start_free = (char *)p;
end_free = start_free + i;
return(chunk_alloc(size, nobjs));
}
}
// ШчЙћвЛЕуФкДцЖМУЛгаСЫЕФЛА, ОЭжЛгаЕїгУвЛМЖХфжУЦїРДЩъЧыФкДцСЫ, ВЂЧвгУЛЇУЛгаЩшжУДІРэР§ГЬОЭХзГівьГЃ
end_free = 0; // In case of exception.
start_free = (char *)malloc_alloc::allocate(bytes_to_get);
}
// ЩъЧыФкДцГЩЙІКѓжиаТаоИФФкДцЦ№ЪМЕижЗКЭНсЪјЕижЗ, жиаТЕїгУchunk_allocЗжХфФкДц
heap_size += bytes_to_get;
end_free = start_free + bytes_to_get;
return(chunk_alloc(size, nobjs));
}
}
ЁОЕќДњЦїЁП
УПИізщМўЖМПЩФмЩцМАЕНЖддЊЫиЕФВйзї,УПИізщМўЕФЪ§ОнРраЭПЩФмВЛЭЌ,ЫљвдУПИізщМўПЩФмЖМвЊздМКЩшМЦЖдздМКЕФВйзїЁЃНЋУПИізщМўЕФЪЕЯжГЩЭГвЛЕФНгПкОЭЪЧЕќДњЦї
ЕќДњЦїЕФгХЕу
- ФмЦСБЮЕєЕзВуЪ§ОнРраЭВювьЕФ
- ЕќДњЦїНЋШнЦїКЭЫуЗЈеГКЯдквЛЦ№, ЪЙАцПщжЎМфИќМгЕФНєДе, ЭЌЪБЬсИпСЫжДаааЇТЪ, ШУЫуЗЈИќМгЕФЕУЕНгХЛЏ
етаЉЪЕЯжДѓЖМЭЈЙ§traitsБрГЬЪЕЯжЕФ. ЫќЕФЖЈвхСЫвЛИіРраЭУћЙцдђ, ТњзуtraitsБрГЬЙцдђОЭПЩвдздМКЪЕЯжЖдSTLЕФРЉеЙ, вВЬхЯжСЫSTLЕФСщЛюад. ЭЌЪБtraitsБрГЬШУГЬађИљОнВЛЭЌЕФВЮЪ§РраЭбЁдёжДааИќМгКЯЪЪВЮЪ§РраЭЕФДІРэКЏЪ§, вВОЭЬсИпСЫSTLЕФжДаааЇТЪ. ПЩМћЕќДњЦїЖдSTLЕФживЊад
ЕќДњЦїзюживЊЕФОЭЪЧЖдoperator*КЭoperator->Нјаажиди,ЪЙЫќБэЯжЕУЯёвЛИіжИеы
- input iterator(ЪфШыЕќДњЦї) : ЕќДњЦїЫљжИЕФФкШнВЛФмБЛаоИФ, жЛЖСЧвжЛФмжДаавЛДЮЖСВйзї.
- output iterator(ЪфГіЕќДњЦї) : жЛаДВЂЧввЛДЮжЛФмжДаавЛДЮаДВйзї.
- forward iterator(е§ЯђЕќДњЦї) : жЇГжЖСаДВйзїЧвжЇГжЖрДЮЖСаДВйзї.
- bidirectional iterator(ЫЋЯђЕќДњЦї) : жЇГжЫЋЯђЕФвЦЖЏЧвжЇГжЖрДЮЖСаДВйзї.
- random access iterator(ЫцМДЗУЮЪЕќДњЦї) : жЇГжЫЋЯђвЦЖЏЧвжЇГжЖрДЮЖСаДВйзї. p+n, p-nЕШ.
?ЮхжжЕќДњЦїКЭЦфМЬГаЙиЯЕ
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : public input_iterator_tag {};
struct bidirectional_iterator_tag : public forward_iterator_tag {};
struct random_access_iterator_tag : public bidirectional_iterator_tag {};
?ЖМЪЧПеРр,жЛЪЧЮЊСЫЕїгУЪБЭЈЙ§РрбЁдёВЛЭЌЕФжидиКЏЪ§,МЬГаЪЧЮЊСЫ,ЕБВЛДцдкФГжжЕќДњЦїРраЭЦЅХфЪББрвыЦїЛсИљОнМЬГаВуДЮЯђЩЯВщевНјааДЋЕн
гУdistance(МЦЫуСНИіЕќДњЦїжЎМфЕФОрРы)РДРэНтЁАШчКЮбЁдёзюгХЕїгУЁБ
template <class InputIterator, class Distance>
inline void distance(InputIterator first, InputIterator last, Distance& n)
{
__distance(first, last, n, iterator_category(first));
}
template <class InputIterator, class Distance>
inline void __distance(InputIterator first, InputIterator last, Distance& n,
input_iterator_tag)
{
while (first != last)
{ ++first; ++n; }
}
template <class RandomAccessIterator, class Distance>
inline void __distance(RandomAccessIterator first, RandomAccessIterator last,
Distance& n, random_access_iterator_tag)
{
n += last - first; //ВЛЭЌЕФЕќДњЦїгаздМКзюМбЕФаЇТЪ,ЭЈЙ§iterator_categoryНјаазюгХбЁдё
}
?ЮхРрЕќДњЦїдДТы
template <class T, class Distance> struct input_iterator
{
typedef input_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
struct output_iterator {
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
};
template <class T, class Distance> struct forward_iterator {
typedef forward_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template <class T, class Distance> struct bidirectional_iterator {
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template <class T, class Distance> struct random_access_iterator {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
дкетРяНщЩмвЛЯТtypenameЯрНЯгкclassЕФжївЊзїгУ:
- ЖдгкФЃАхВЮЪ§ЪЧРрЕФЪБКђ,?
typenameФмЙЛЬсШЁ(нЭШЁ)ГіИУРрЫљЖЈвхЕФВЮЪ§РраЭ
template<class T>
class people
{
public:
typedef T value_type;
typedef T* pointer;
typedef T& reference;
};
template<class T>
struct man
{
public:
typedef typename T::value_type value_type;
typedef typename T::pointer pointer;
typedef typename T::reference reference;
void print()
{
cout << "man" << endl;
}
};
int main()
{
man<people<int>> Man;
Man.print();
exit(0);
}
?
ЕќДњЦїЫљжИЯђЖдЯѓЕФаЭБ№БЛГЦЮЊvalue type. ДЋШыВЮЪ§ЕФРраЭПЩвдЭЈЙ§БрвыЦїздааЭЦЖЯГіРД, ЕЋЪЧШчЙћЪЧКЏЪ§ЕФЗЕЛижЕЕФЛА, ОЭЮоЗЈЭЈЙ§value typeШУБрвыЦїздааЭЦЖЯГіРДСЫ. ЖјtraitsОЭНтОіСЫКЏЪ§ЗЕЛижЕРраЭ. ЭЌбљдЩњжИеыВЛФмФкЧЖаЭБ№ЩљУї,ЫљвдФкЧЖаЭБ№дкетРяВЛЪЪгУ, ЕќДњЦїЮоЗЈБэЪОдЩњжИеы(int *, char *ЕШГЦЮЊдЩњжИеы)
---------->етаЉЮЪЬтШчКЮБЛНтОі
?iterator_traitsНсЙЙ
ЪЙгУtypenameЖдВЮЪ§РраЭНјаанЭШЁ,ВЂЧвЖдВЮЪ§РраЭдйНјаавЛДЮУќУћ
template <class Iterator>
struct iterator_traits {
typedef typename Iterator::iterator_category iterator_category; //ЕќДњЦїРраЭ
typedef typename Iterator::value_type value_type; // ЕќДњЦїЫљжИЖдЯѓЕФРраЭ
typedef typename Iterator::difference_type difference_type; // СНИіЕќДњЦїжЎМфЕФОрРы
typedef typename Iterator::pointer pointer; // ЕќДњЦїЫљжИЖдЯѓЕФРраЭжИеы
typedef typename Iterator::reference reference; // ЕќДњЦїЫљжИЖдЯѓЕФРраЭв§гУ
};
?ЩЯУцЕФtraitsНсЙЙЬхВЂУЛгаЖддЩњжИеызіДІРэ, ЫљвдЛЙвЊЮЊЬиЛЏ, ЦЋЬиЛЏАцБО(МДдЩњжИеы)зіЭГвЛ
// еыЖддЩњжИеы T* ЩњГЩЕФ traits ЦЋЬиЛЏ
template <class T>
struct iterator_traits<T*> {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
// еыЖддЩњжИеы const T* ЩњГЩЕФ traits ЦЋЬиЛЏ
template <class T>
struct iterator_traits<const T*> {
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};
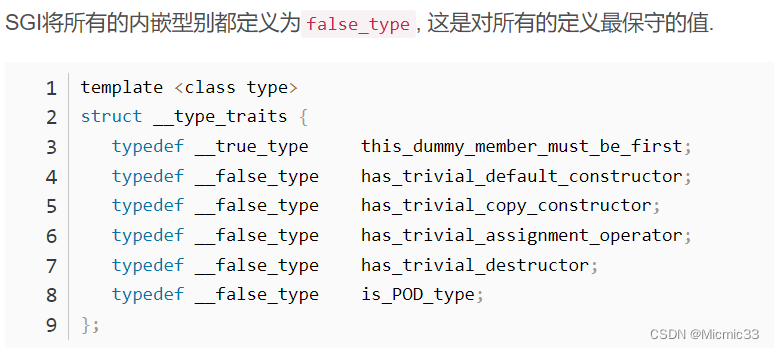
?__type_traits
iterator_traitsЪЧнЭШЁЕќДњЦїЕФЬиад,Жј__type_traitsЪЧнЭШЁаЭБ№ЕФЬиад
нЭШЁаЭБ№ШчЯТ:

?БрвыЦїЛсЮЊУПИіРрЙЙдьвдЩЯЫФжжФЌШЯЕФКЏЪ§,ШчЙћУЛгаЖЈвхздМКЕФ,ОЭЛсгУБрвыЦїФЌШЯКЏЪ§,ШчЙћЪЙгУФЌШЯЕФКЏЪ§,ЮвУЧПЩвдЪЙгУmemcpy(),memmove(),malloc()ЕШКЏЪ§РДМгПьЫйЖШ,ЬсИпаЇТЪ
__iterator_traitsдЪаэеыЖдВЛЭЌЕФаЭБ№ЪєаддкБрвыЦкМфОіЖЈжДааФФИіжидиКЏЪ§ЖјВЛЪЧдкдЫааЪБВХДІРэ, етДѓДѓЬсЩ§СЫдЫаааЇТЪ. етОЭашвЊSTLЬсЧАзіКУбЁдёЕФзМБИ. ЪЧЗёЮЊPOD, non-trivialаЭБ№гУ__true_typeКЭ__false_type?РДЧјЗж
(жЎЧАЕФПеМфХфжУЦїОЭЬсЙ§)
__true_typeКЭ__false_typeВЛЪЧboolжЕ,вђЮЊашвЊдкБрвыЦкМфОЭОіЖЈЪЙгУФФИіКЏЪ§ЁЃ
НЋЫќУЧБэЯжЮЊПеРрЁЊЁЊЮоЖюЭтИКЕЃ,ФмБэЪОецМй,ЛЙФмдкБрвыЪБРраЭЭЦЕМШЗЖЈжДааЯргІЕФКЏЪ§
struct __true_type {};
struct __false_type {};
?__type_traitsдДТы
__STL_TEMPLATE_NULL struct __type_traits<char> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
__STL_TEMPLATE_NULL struct __type_traits<signed char> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
...
вдЩЯЪЧНЋЛљДЁЕФРраЭЖМЩшжУЮЊ__true_typeаЭБ№
?етРяНЋжИеыНјааЬиЛЏДІРэ, ЭЌбљЪЧ__true_typeаЭБ№
#ifdef __STL_CLASS_PARTIAL_SPECIALIZATION
template <class T>
struct __type_traits<T*> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
#else /* __STL_CLASS_PARTIAL_SPECIALIZATION */
struct __type_traits<char*> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
struct __type_traits<signed char*> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
struct __type_traits<unsigned char*> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type;
};
?
?SGIЖдtraitsНјааРЉеЙ,ЪЙЕУЫљгаРраЭЖМТњзуtraitsБрГЬЙцЗЖ, етбљSGI STLЫуЗЈПЩвдЭЈЙ§__type_traitsЛёШЁРраЭаХЯЂдкБрвыЦкМфОЭФмОіЖЈГіЪЙгУФФвЛИіжидиКЏЪ§, НтОіСЫtemplateЪЧдкдЫааЪБОіЖЈжидибЁдёЕФЮЪЬт. ВЂЧвЭЈЙ§trueКЭfalseРДШЗЖЈPODКЭtravial destructor, ШУГЬађФмбЁдёИќМгЗћКЯЦфРраЭЕФДІРэКЏЪ§, ДѓДѓЬсИпСЫЖдЛљБОРраЭЕФПьЫйДІРэФмСІВЂБЃжЄСЫаЇТЪзюИп
ЁОШнЦїЁП
ШнЦїЗтзАСЫДѓСПГЃгУЕФЪ§ОнНсЙЙ
ШнЦїЗжЮЊађСаЪНКЭЙиСЊЪН
ађСаЪН:vector list dequeЕШ,ађСаШнЦїгаЭЗЛђЮВ,ЩѕжСгаЭЗгаЮВ
ЙиСЊЪН:map set hashtableЕШ,УЛгаЫљЮНЭЗЮВ,жЛгазюДѓжЕ,зюаЁжЕ
?uninitializedЯЕСаКЏЪ§
uninitialized_copyЙІФм : ДгfirstЕНlastЗЖЮЇФкЕФдЊЫиИДжЦЕНДг resultЕижЗПЊЪМЕФФкДц
template <class InputIterator, class ForwardIterator>
inline ForwardIterator uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result) {
return __uninitialized_copy(first, last, result, value_type(result));
}
inline char* uninitialized_copy(const char* first, const char* last,
char* result) {
memmove(result, first, last - first);
return result + (last - first);
}
inline wchar_t* uninitialized_copy(const wchar_t* first, const wchar_t* last,
wchar_t* result) {
memmove(result, first, sizeof(wchar_t) * (last - first));
return result + (last - first);
}
?__uninitialized_copyКЏЪ§
template <class InputIterator, class ForwardIterator, class T>
inline ForwardIterator __uninitialized_copy(InputIterator first, InputIterator last,
ForwardIterator result, T*) {
typedef typename __type_traits<T>::is_POD_type is_POD;
return __uninitialized_copy_aux(first, last, result, is_POD());
}
?__uninitialized_copyЪЙгУСЫtypenameНјаанЭШЁ, ВЂЧвнЭШЁЕФРраЭЪЧPOD, ПДРДетРязМБИЖд__uninitialized_copy?НјаазюгХЛЏДІРэСЫ, ЮвУЧНгзХРДЗжЮіЫќЪЧдѕУДЪЕЯжгХЛЏДІРэЕФ
template <class InputIterator, class ForwardIterator>
inline ForwardIterator __uninitialized_copy_aux(InputIterator first, InputIterator last,
ForwardIterator result,
__true_type) {
return copy(first, last, result);
}
template <class InputIterator, class ForwardIterator>
ForwardIterator __uninitialized_copy_aux(InputIterator first, InputIterator last,
ForwardIterator result,
__false_type) {
ForwardIterator cur = result;
__STL_TRY {
for ( ; first != last; ++first, ++cur)
construct(&*cur, *first);
return cur;
}
__STL_UNWIND(destroy(result, cur));
}
?uninitialized_copy_nвВзіСЫИњuninitialized_copyРрЫЦЕФДІРэ, жЛЪЧЫќЪЧВЩгУtratisБрГЬРяiterator_categoryЕќДњЦїЕФРраЭРДбЁдёзюгХЕФДІРэКЏЪ§.
template <class InputIterator, class Size, class ForwardIterator>
inline pair<InputIterator, ForwardIterator>
uninitialized_copy_n(InputIterator first, Size count,
ForwardIterator result) {
return __uninitialized_copy_n(first, count, result, iterator_category(first)); // ИљОнiterator_categoryбЁдёзюгХКЏЪ§
}
template <class InputIterator, class Size, class ForwardIterator>
pair<InputIterator, ForwardIterator>
__uninitialized_copy_n(InputIterator first, Size count, ForwardIterator result,
input_iterator_tag) // input_iterator_tagРраЭЕФЕќДњЦї
{
ForwardIterator cur = result;
__STL_TRY {
for ( ; count > 0 ; --count, ++first, ++cur)
construct(&*cur, *first);
return pair<InputIterator, ForwardIterator>(first, cur);
}
__STL_UNWIND(destroy(result, cur));
}
template <class RandomAccessIterator, class Size, class ForwardIterator>
inline pair<RandomAccessIterator, ForwardIterator>
__uninitialized_copy_n(RandomAccessIterator first, Size count, ForwardIterator result,
random_access_iterator_tag) // random_access_iterator_tagРраЭЕФЕќДњЦї
{
RandomAccessIterator last = first + count;
return make_pair(last, uninitialized_copy(first, last, result));
}
uninitialized_fillЙІФм : ДгfirstЕНlastЗЖЮЇФкЕФЖМЬюГфЮЊ x ЕФжЕ.
uninitialized_fillВЩгУСЫгыuninitialized_copyвЛбљЕФДІРэЗНЗЈбЁдёзюгХДІРэКЏЪ§, етРяОЭВЛЙ§ЖрЕФЗжЮіСЫ
template <class ForwardIterator, class T>
inline void uninitialized_fill(ForwardIterator first, ForwardIterator last, const T& x)
{
__uninitialized_fill(first, last, x, value_type(first));
}
template <class ForwardIterator, class T, class T1>
inline void __uninitialized_fill(ForwardIterator first, ForwardIterator last, const T& x, T1*)
{
typedef typename __type_traits<T1>::is_POD_type is_POD;
__uninitialized_fill_aux(first, last, x, is_POD());
}
template <class ForwardIterator, class T>
inline void
__uninitialized_fill_aux(ForwardIterator first, ForwardIterator last, const T& x, __true_type)
{
fill(first, last, x);
}
template <class ForwardIterator, class T>
void
__uninitialized_fill_aux(ForwardIterator first, ForwardIterator last, const T& x, __false_type)
{
ForwardIterator cur = first;
__STL_TRY {
for ( ; cur != last; ++cur)
construct(&*cur, x);
}
__STL_UNWIND(destroy(first, cur));
}
?uninitialized_fill_nЙІФм : ДгfirstПЊЪМn ИідЊЫиЬюГфГЩ x жЕ
template <class ForwardIterator, class Size, class T>
inline ForwardIterator uninitialized_fill_n(ForwardIterator first, Size n, const T& x)
{
return __uninitialized_fill_n(first, n, x, value_type(first));
}
template <class ForwardIterator, class Size, class T, class T1>
inline ForwardIterator __uninitialized_fill_n(ForwardIterator first, Size n, const T& x, T1*)
{
typedef typename __type_traits<T1>::is_POD_type is_POD;
return __uninitialized_fill_n_aux(first, n, x, is_POD());
}
template <class ForwardIterator, class Size, class T>
inline ForwardIterator __uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, __true_type)
{
return fill_n(first, n, x);
}
template <class ForwardIterator, class Size, class T>
ForwardIterator __uninitialized_fill_n_aux(ForwardIterator first, Size n, const T& x, __false_type)
{
ForwardIterator cur = first;
__STL_TRY
{
for ( ; n > 0; --n, ++cur)
construct(&*cur, x);
return cur;
}
__STL_UNWIND(destroy(first, cur));
}
?uninitialized_copyЪЧЮЊСНЖЮФкДцНјааИДжЦЕФКЏЪ§, uninitialized_fillЪЧЮЊЖдвЛЖЮФкДцНјааГѕЪМЛЏвЛИіжЕЕФКЏЪ§. СНепЖМЖдСЫtraitsБрГЬжаЕФЕќДњЦїРраЭКЭ__type_traitsЖЈвхЕФ__false_typeКЭ__true_typeЕФВЛЭЌжДааВЛЭЌЕФДІРэКЏЪ§, вВЪЙаЇТЪзюгХЛЏ