目录
1.yum:软件包管理工具
查看搜索软件包:yum?list? ? ? ? ? yum?search?keyword
安装软件包:yum?install?package? ? ? ? ?
卸载软件包:yum?remove package
软件工具如非必要尽量不要使用源码安装,使用yum工具安装,因为yum是有一套完整的依赖关系
2.vim:linux下最受欢迎的命令行下的编辑器
有多种操作模式:12种,常用/必用3种(普通模式,插入模式,底行模式)
普通模式:针对文本进行命令操作的模式,也是所有模式之间进行切换的基础模式
插入模式:开始进行文本编辑
底行模式:当前所学的只有保存与退出
模式切换:vim打开一个文件默认处于普通模式
? ? 普通模式 ->插入模式:i? ?a,o,I, A, O
? ? 任意模式->普通模式:ESC
? ? 普通模式->底行模式:英文冒号
底行模式下的常见操作:
:w保存? ?:q?退出? ? :wq?保存并退出? ? :q! 强制退出不保存? ? ? ? ?:num?跳转到第num行
普通模式下的常见操作:
光标移动:hjkl-上下左右,ctrl+f/b--上下翻页? ? ? gg/G(shift+g) --文档首尾,
w/b--以单词为单位前后移动
文本操作:
复制:yy--复制光标所在行,nyy--从光标所在行开始复制n行
剪切/删除(剪切后不粘贴就行):dd/ndd-删除(剪切)光标所在行,清空文本内容--ggdG
dw-删除单词? ? ? ?D-删除本行光标以后的内容
?粘贴:p? ? ? ? np--向下降剪切板的内容粘贴n遍
其他操作:
撤销上一次操作:u; 还原撤销:ctrl+r
不要使用?ctirl+z退出vim,因为这并不是真正的退出
3.gcc/g++:编译器
gcc对应的C语言,g++对应的时C++语言
编程语言分类:
编译型语言(C/C++):将高级语言代码解释成为机器指令,然后再执行(运行速度快)
解释型语言(js/python)直接编写直接运行,通过解释器,逐行解释(封装程度高,编写代码简单)
我们写的C语言程序为什么能够被执行,完成指定的功能
我们写的C语言代码其实并不能直接被执行,因为C语言是一个高级语言(无法被机器直接识别)
写完代码后,需要使用编译器,将我们的C语言代码编译成为一个可执行程序,然后运行可执行程序才可以在右图中,就是把我们写的main.c的C语言代码进行编译,编译的目的就是把C语言代码解释成为二进制机器指令 ,因为我们的计算机硬件,只能识别二进制机器指令而更早期的语言,像汇编,写出来的代码效率是真高,但是开发代码复杂,以及跨平台移植性差(指定的硬件只能用指定的指令进行操作)
编译器可以将相同的C语言代码,在不同的硬件平台上解释出不同的机器指令,最主要的原因就是C语言有一个强大的编译器。
不同的语言有不同的编译器:c语言有qcc,clang,msvc…C++原因有q++,c++lang;Linux下常用的是qcc编译器。
?gcc编译器在编译的C语言的过程中都做了什么:
预处理:?gcc -E main.c -o main.i
-E 选项功能就表示只进行预处理,-o 选项是指定要生成的文件名称
功能:去除注释,宏替换,引入头文件,根据条件编译去掉无用代码.
编译:根据C语言语法语义规则,构建语法树,进行语法语义的错误检查,没有错误则将C语言代码解释成为汇编指令
gcc?-S?main.i?-o?main.s? ? ?
-S表示只进行到编译
语法:比如for后边就必须有个0;
语义:int?func();? ? ?表示一个函数必须有个int返回值,要是没有就属于语义错误
汇编:将汇编指令解释成为二进制的机器指令
gcc-c?main.s-o?main.o
链接:将所有c的二进制机器指令,以库中用到的指令,打包到一起生成一个可执行程序
gcc?main.o?-o?main
库
一个大量函数进行编译后生成的二进制机器指令打包到一起的文件(但是不是可执行程序,而是里边的代码供外界使用)
大佬们针对常用功能,封装好的接口编译后打包的文件生成可执行程序的时候需要链接所用到的库文件链接方式:
动态链接:链接时,将库中使用到的函数符号表记录到可执行程序中(并非把具体函数实现指令拿过来)
优点:生成可执行程序比较小,多个程序可以在内存中使用同一份库代码(节省资源)
缺点:运行时库,也就是运行时需要加载库到内存中,如果库被删除了,程序就没法运行
静态链接:链接时,真接将库中使用到的函数具体实现的指令,拷贝一份到可执行程序中
缺点:生成的可执行程序比较大,库中代码可能会在内存中存在多份冗余优点:无运行依赖
4.gdb:调试器
--调试一个程序的运行过程,查找程序出问题的位置
程序必须是一个debug版本的程序才能被调试
debug版本程序:调试版本,不对代码进行任何优化,并且会加入调试符号信息
release版本程序:发布版本,会对代码进行一些优化,更利于程序的运行效率-…--无法调试
gcc编译器默认生成的是release版本程序,如果想要生成debug版本程序需要在编译程序的时候,加上 -g 选项 如:gcc?-g?main.c?-o?main
调试过程:
1.使用gdb加载程序:?gdb?./main
2.开始调试:
退出调试:quit
start--开始逐步调试:
run--直接运行
3.逐行调试:
next--下一步--逐过程(遇到函数,则把函数直接运行完);
step--下一步--逐语句(遇到函数,则进入函数进行调试)
untilmainc:18--直接运行到指定文件的指定行
4.查看代码:
list--默认是查看调试行附近的代码
list?main.c:18? ? --查看指定文件指定行附近的代码
5.断点操作
一个项目上万行代码,稀松平常,逐步调试是一件非常恐怖的事情,则这时候断点就尤为重要设置好断点,则程序运行到断点位置就会停下来
break?main.c:18? ? ? -给指定文件指定行打断点
break?print_child? ? ? ?--给函数打断点
continue从当前调试位置开始继续向下运行(注意,不是逐步调试,而是直接向下运行)
?info?break--查看所有断点信息
delete?break_id 删除指定断点
6.内存操作
变量的数据的查看与设置:
print variable? ? ?--查看指定变量的数据;
print variable=10? ? 设置变量的数据查看函数调用栈:
backtrace程序当前的运行位置肯定是调用栈的栈顶函数,因为函数都是逐个压栈的
当程序崩溃了,则栈顶函数就是出错的函数,程序崩溃肯定是在某个函数中进行了不当操作的时候而崩溃的时候,函数还没来得及出栈
5.项目的自动化构建工具
项目的自动化构建工具如何知道一个项目该如何构建呢?---是程序员告诉这个构建工具的
Makefile:普通的文本文件,在这个文件中可以记录项目的规则
make:是一个程序,叫做Makefile解释器,及时Makefile中的项目构建规则,进行执行,完成项目的构建因此我们学习的是Makefile的编写
1.Makefile的文件名是固定,不能随便起名字,因为执行make令的时候就会在当前目录下找Makefile文件1
#在Makefile中#符号是注释,类似于C语言中的?//2?#?编写规则
1.必须有目标对象,就是我们要生成的文件名称,或者说要完成的操作名称
2,可以有依赖对象--要生成目标对象文件,需要依毂哪些文件,目标对象和依赖对象之间以冒号间隔
3、目标生成规划中的指令..要生成一个文件或者完成一个操作所需执行的指令(注意,指令前边必须有个TAB制表符了
?make的解释执行规则:
1.执行make的时候,会在当前目录下找寻Makefile文件进行解释
2.找到Makefile后,在Makefile中,找到第一个目标对象,作为要生成的终极目标对象
3.检测目标对象是否需要重新生成(检测目标与依赖的时间关系,在上一次目标对象被生成之后,依赖对象是否被修改过)
? ? ?1.目标对象不存在,肯定要重新生成
? ? ?2.依赖对象被修改过,肯定要重新生成
? ? ?3.依赖对象不存在,则要查找依赖对象的生成规则,先把依赖对象生成了(这是一个递归的过程,可能存在多层递归)
4.所有的依赖对象都更新生成之后,然后再执行指令,生成终极目标对象
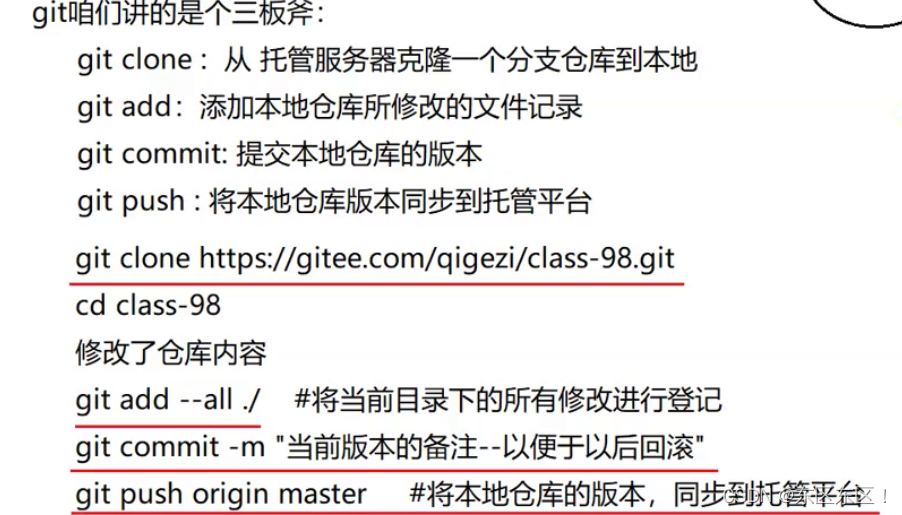
6.git 项目的版本管理工具
对代码进行托管,并进行版本管理
优点:
1.托管备份,容灾性强
2.版本管理,随时可以进行版本回滚
?