1. Linux ������������ yum
ǰ��
??��Linux�°�װ����,�����ַ�����
Դ�� ���ص������Դ����,�����б���,�õ���ִ�г���
rmp��
yum������ ȫ��:Yellowdog Updater Modified,��ҪӦ����Fedora, RedHat, Centos�ȷ��а��ϡ�
??��������̫�鷳��,������Щ�˰�һЩ���õ�������ǰ�����,����������(��windows�� .exe ��װ�ļ�һ��,�����ļ��Ѿ������,�����˰�,�ĸ��ļ��÷ŵ��ĸ��ļ���,��ָ������,��װ�dz�����)����һ����������,ͨ�������������Ժܷ���Ļ�ȡ���������õ�������,,ֱ�ӽ��а�װ��
??��������������������,�ͺñ� ��App�� �� ��Ӧ���̵ꡱ �����Ĺ�ϵ��
�
yum [options] command [package ...]
����
��װ
���������ϵ
-
�鿴������
??ͨ�� yum list ����������г���ǰһ������Щ�����������ڰ�����Ŀ���ܷdz�֮��,����������Ҫʹ�� grep ����ֻ
ɸѡ�����ǹ�ע�İ�������:yum list | grep lrzsz??�������:
lrzsz.x86_64 0.12.20-36.el7 @base??ע������:

-
��װ����
����:
sudo yum install lrzszyum ���Զ��ҵ�������Щ��������Ҫ����,���� -y ������ʱ���� ��y�� ȷ�ϰ�װ��Ҳ����ֱ�Ӽ��� -y ѡ�
ע������:
- ��װ����ʱ������Ҫ��ϵͳĿ¼��д������, һ����Ҫ sudo �����е� root �˻��²�����ɡ�
- yum��װ����ֻ��һ��װ������װ��һ���� ����yum��װһ�������Ĺ�����,����ٳ�����yum��װ����
һ������,yum�ᱨ����
-
�����
sudo yum remove lrzsz -
����
����ѡ��:-h:��ʾ������Ϣ; -y:�����е����ʶ��ش� [yes]; -c:ָ�������ļ�; -q:����ģʽ; -v:��ϸģʽ; -d:���õ��Եȼ�(0-10); -e:���ô���ȼ�(0-10); -R:����yum����һ����������ȴ�ʱ��; -C:��ȫ�ӻ���������,����ȥ���ػ��߸����κ�ͷ�ļ�����������:
install ��װrpm�������� ȫ����װ yum install ��װָ���İ�װ�� yum install package update ����rpm�������� ȫ������ yum update �����ƶ��ij���� yum update package check-update ����Ƿ��п��õĸ���rpm�������� ���ɸ��µij��� yum check-update remove ɾ���ƶ���rpm�������� ɾ������� yum remove package list �г���Դ�������п���װ����µ�rpm���� ��ʾ�����Ѿ���װ�Ϳ���װ�ij���� yum list ��ʾָ��package��װ���İ�װ��� yum list package ��ʾ��Դ�������п��Ը��µ�rpm�� yum list updates ��ʾ�Ѿ���װ������rpm�� yum list installed ��ʾ�Ѿ���װ��,������������Դ���е�rpm�� yum list extras search ��������������Ϣ; ����ƥ��package�ַ���rpm��,�������ơ����� yum search package info ��ʾ�ƶ���rpm��������������Ϣ��Ҫ��Ϣ; ��ʾ��Դ�������п���װ����µ�rpm������Ϣ yum info ��ʾ��װ��package����Ϣ yum info package ��ʾpack��ͷ�����а�����Ϣ yum info pack* ��ʾ��Դ�������п��Ը��µ�rpm������Ϣ yum info updates ��ʾ�����Ѿ���װrpm������Ϣ yum info installed ��ʾ�Ѿ���װ��,������������Դ���е�rpm������Ϣ yum info extras clean ����yum���ڵĻ��档 �������Ŀ¼�µ������� yum: clean packages �������Ŀ¼�µ�headers: yum clean headers �������Ŀ¼�¾ɵ�headers: yum clean headers ��������е������ļ� yum clean all shell ����yum��shell��ʾ���� resolvedep ��ʾrpm��������������ϵ�� localinstall ��װ���ص�rpm�������� localupdate ���ص�rpm���������и��¡� alias �г������������ autoremove ɾ������ԭ����Ϊ������ϵ��װ�IJ���Ҫ�����������鿴 yum Դ
���鲻Ҫ������!!!ls /etc/yum.conf /etc/yum.conf [xcs101@VM-4-6-centos ~]$ vim /etc/yum.conf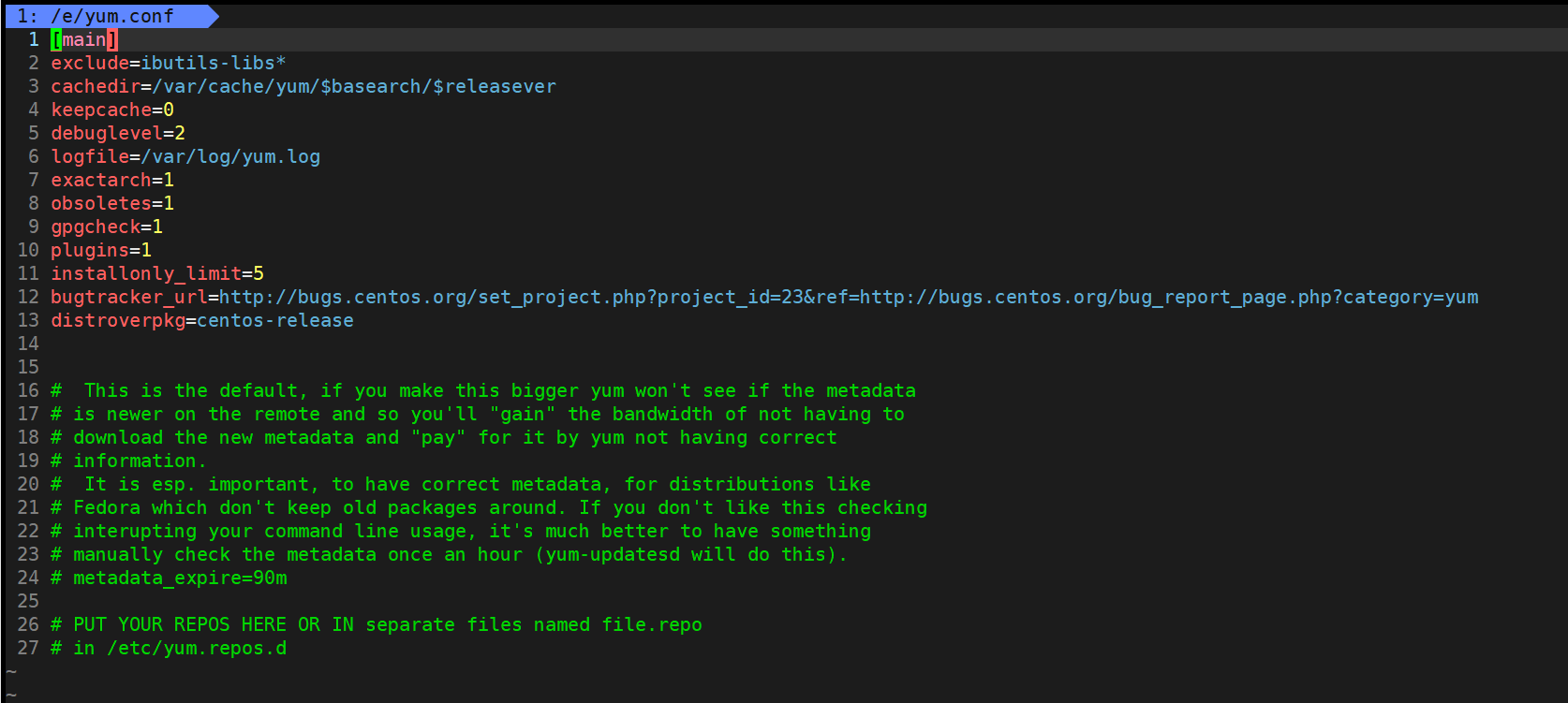
yum ����
������
vim /etc/yum.repos.d/CentOS-Base.repo��Ȼ,�ҵ���û�����ù��ġ�
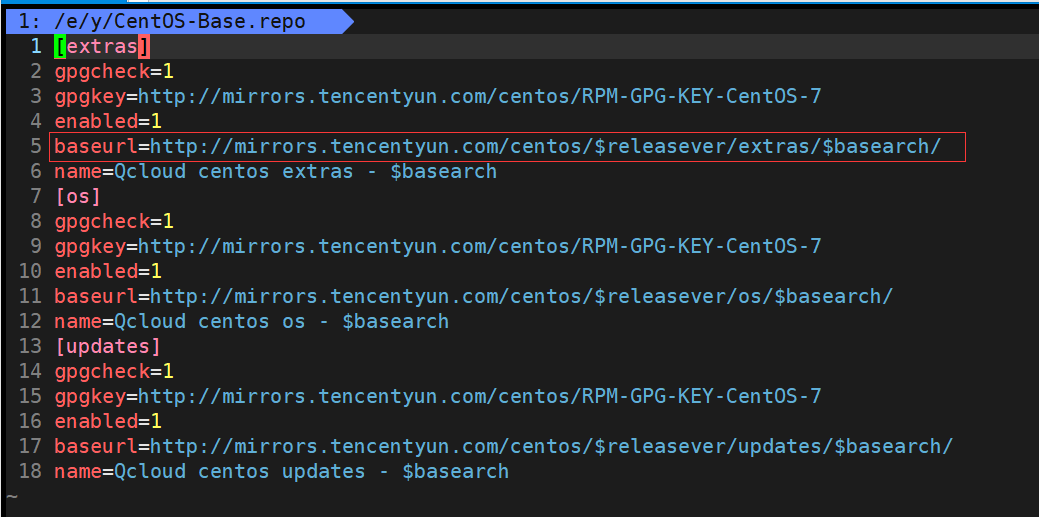
���� rzsz
����������� windows ������Զ�˵� Linux ����ͨ�� XShell �����ļ���
��װ���֮�����ͨ����ק�ķ�ʽ���ļ��ϴ���ȥ���ӿͻ����ϴ��ļ��������:
rz [ѡ��] ѡ��˵��: -+, --append :���ļ������ӵ��Ѵ��ڵ�ͬ���ļ� -a,--ascii :���ı���ʽ���� -b, --binary :�Զ����Ʒ�ʽ����,�Ƽ�ʹ�� --delay-startup N:�ȴ�N�� -e, --escape :�����п����ַ�ת��,����ʹ�� -E, --rename :�Ѵ���ͬ���ļ������������ϴ����ļ�,�Ե��������Ϊ�� -p, --protect :��ZMODEMЭ����Ч,���Ŀ���ļ��Ѵ��������� - -q, --quiet :����ִ��,�������ʾ��Ϣ -v, --verbose :�����������е���ʾ��Ϣ -y, --overwrite :����ͬ���ļ����滻 -X, --xmodem :ʹ��XMODEMЭ�� --ymodem :ʹ��YMODEMЭ�� -Z, --zmodem :ʹ��ZMODEMЭ�� --version :��ʾ�汾��Ϣ --h, --help :��ʾ������Ϣ�ӷ���˷����ļ����ͻ���:ֻ�����ļ�,��ΪĿ¼(�ļ���)����������
sz filename
2. Linux�༭�� - vim ʹ��
���� vim �İ�װ������,��ҿ�������������װ��
2.1 vim�Ļ�������
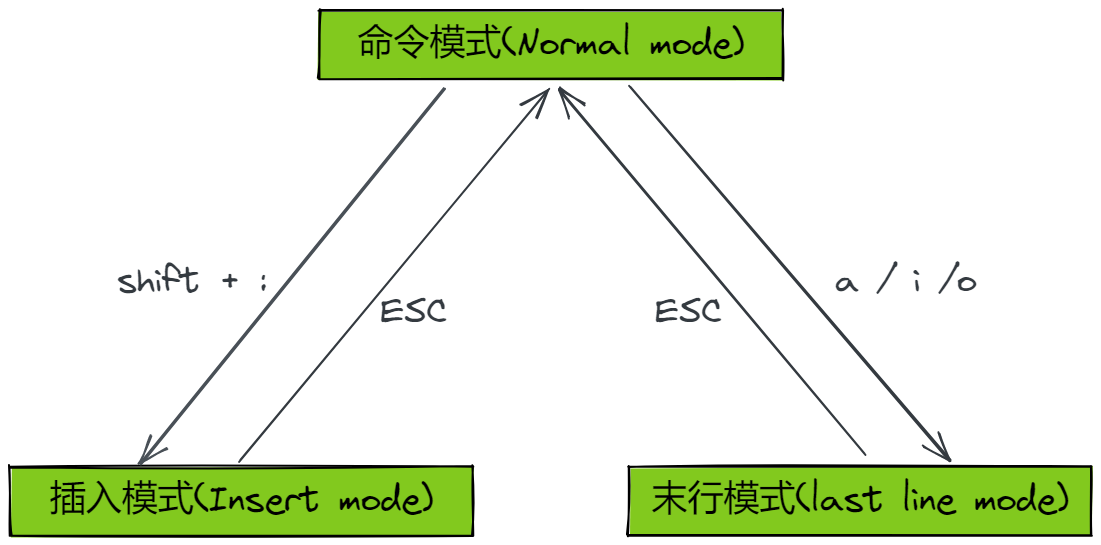
vim ��12��ģʽ,����ֻ������ ����ģʽ(command mode)������ģʽ(Insert mode)�͵���ģʽ(last line mode)��
����/��ͨ/����ģʽ(Normal mode)
������Ļ�����ƶ�,�ַ����ֻ��е�ɾ�����滻,�ƶ�����ij���μ�����Insert mode��,���ߵ� last line mode
����ģʽ(Insert mode)
ֻ����Insert mode��,�ſ�������������,����ESC�����ɻص�������ģʽ��
����ģʽ(last line mode)
�ļ�������˳�,Ҳ���Խ����ļ��滻,���ַ���,�г��кŵȲ�����
������ģʽ��,**shift + : **���ɽ����ģʽ��ע��:������Ӣ�ĵ� :
Ҫ�鿴�������ģʽ:��vim,����ģʽֱ������: help vim-modes
2.2 vim�Ļ�������
����vim
vim �ļ���
ע: ����vim֮��,�Ǵ���[ ����ģʽ ],��Ҫ�л��� [ ����ģʽ ] ���ܹ��������֡�
[ ����ģʽ ] �л��� [ ����ģʽ ]
���� a �������ƶ�
���� i ��겻��
���� o ����һ��
[ ����ģʽ ] �л��� [ ����ģʽ ]
Ŀǰ����[ ����ģʽ ],��ֻ��һֱ��������,��������������,���ù��������ƶ�,������ɾ����
�����Ȱ�һ�¡�ESC����ת�� [ ����ģʽ ]��ɾ�����֡���Ȼ,Ҳ����ֱ��ɾ����
[ ����ģʽ ] �л��� [ ĩ��ģʽ ]
��shift + ;��, ��ʵ�������롸 : ��
**ע:**������Ӣ������״̬�²ſ��ԡ�
2.3 vim ����ģʽ���
����ģʽ
����i�� �л��������ģʽ��insert mode��,�� �� i �� �������ģʽ���Ǵӹ�굱ǰλ�ÿ�ʼ�����ļ�;
����a�� �������ģʽ��,�Ǵ�Ŀǰ�������λ�õ���һ��λ�ÿ�ʼ��������;
����o�� �������ģʽ��,�Dz����µ�һ��,������ʼ�������֡�
�Ӳ���ģʽ�л�Ϊ����ģʽ
����ESC������
��궨λ
����h/j/k/l��: �������/��/��/���ƶ�,�����ʹ�ü�ͷ�ƶ�
����G��: �ƶ������µ����
����$��: �ƶ�����������еġ���β��
����^��: �ƶ�����������еġ����ס�
����w��: �Ե���Ϊ��λ,��������¸��ֵĿ�ͷ
����e��: �Ե���Ϊ��λ,��������¸��ֵ���β
����b��: �Ե���Ϊ��λ,���ص��ϸ��ֵĿ�ͷ
����#l��: ����Ƶ����еĵ�#��λ��,��:5l,56l
����gg��: ��궨λ���ı���ʼ
����shift��+��g����G��: ��궨λ���ı�ĩ��
�� n +��shift��+��g����G��: ��궨λ������һ��
����ctrl��+��b��: ��Ļ�������ƶ�һҳ
����ctrl��+��f��: ��Ļ����ǰ���ƶ�һҳ
����ctrl��+��u��: ��Ļ�������ƶ���ҳ
����ctrl��+��d��: ��Ļ����ǰ���ƶ���ҳ
���ơ����й���
��yw��: ���������֮������β���ַ����Ƶ��������С�
��#yw��: ����#���ֵ�������
��yy��: ���ƹ�������е���������
��#yy��: ����,��6yy����ʾ�����ӹ�����ڵĸ��С���������6�����֡�
��dd��: ɾ��(����)���������
��#dd��: �ӹ�������п�ʼɾ��(����)#��
��p��: ���������ڵ��ַ������������λ�á�
n + ��p��: ճ�� n ��
ע��:������ ��y�� �йصĸ������������ ��p�� ��ϲ�����ɸ�����ճ�����ܡ�
�ı���
��r��: �滻������ڴ����ַ���
n +��r��: �滻������ڴ���n���ַ���
��shift��+��r����R��: �滻�������֮�����ַ�,ֱ�����¡�ESC����Ϊֹ��
��cw��: ���Ĺ�����ڴ����ֵ���β��
��c#w��: ����,��c3w����ʾ����3����
��shift��+��~��: ���ı���Сдת��
��x��: ÿ��һ��,ɾ���������λ�õ�һ���ַ�
��#x��: ����,��6x����ʾɾ���������λ�õġ�����(�����Լ�����)��6���ַ�
��X��: ��д��X,ÿ��һ��,ɾ���������λ�õġ�ǰ�桱һ���ַ�
��#X��: ����,��20X����ʾɾ���������λ�õġ�ǰ�桱20���ַ�
��������
��ctrl��+��g��: �г���������е��к�
��u��: �������ִ��һ������,�������ϰ��¡�u��,�ص���һ������������� ��u�� ����ִ�ж�λָ���
��ctrl��+��r��: �����Ļָ�
2.4 vim ĩ��ģʽ���
��ʹ��ĩ��ģʽ֮ǰ,���ס�Ȱ���ESC����ȷ�����Ѿ���������ģʽ,�ٰ���:��ð�ż��ɽ���ĩ��ģʽ��
�г��к�
��set nu��: ���롸set nu����,�����ļ��е�ÿһ��ǰ���г��кš�
�����ļ��е�ijһ��
��#��: ��#���ű�ʾ����,��ð�ź�����һ������,�ٰ��س����ͻ����������ˡ�
�����ַ�
��/�ؼ��֡�: �Ȱ���/����,����������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�������Ҫ��,����һֱ����n��������Ѱ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
��?�ؼ��֡�:�Ȱ���?����,����������Ѱ�ҵ��ַ�,�����һ���ҵĹؼ��ֲ�������Ҫ��,����һֱ����n������ǰѰ�ҵ���Ҫ�Ĺؼ���Ϊֹ��
�˳� vim �������ļ�
q �˳�
q! ǿ���˳�
w ����
w! ǿ�Ʊ���
wq! ǿ�Ʊ��沢�˳�
�滻
%s/���滻�ؼ���/���ı�/g
ִ��bash����
!bash����
������ʾ
vs ���ļ�
Ȼ��ctrl��+��w�������μ���ʵ���ĵ����л���
���䡪����ע��
���Ȱ���[Ctrl] + [V],ͨ��[h / j / k/ l]����ѡ��ָ����,�ٰ���[Shift] + [i],����[ //] ���� [Esc] ����ʵ�ֶ���ע�͡�
3. Linux������ - gcc/g++ ʹ��
��ʽ
gcc [ѡ��] Ҫ������ļ� [ѡ��] [Ŀ���ļ�]
�
gcc [-c|-S|-E] [-std=standard]
[-g] [-pg] [-Olevel]
[-Wwarn...] [-Wpedantic]
[-Idir...] [-Ldir...]
[-Dmacro[=defn]...] [-Umacro]
[-foption...] [-mmachine-option...]
[-o outfile] [@file] infile...
Ԥ����
���к��滻
Ԥ����������Ҫ�����궨��,�ļ�����,��������,ȥע�͵���
Ԥ����ָ������ # �ſ�ͷ�Ĵ����С�
ʵ��:
gcc �CE test.c �Co test.i
ѡ�-E��,��ѡ����������� gcc ��Ԥ����������ֹͣ������̡�
ѡ�-o����ָĿ���ļ�,��.i���ļ�Ϊ�Ѿ���Ԥ������Cԭʼ����
����
���ɻ��
���������,gcc ����Ҫ������Ĺ淶�ԡ��Ƿ���������,��ȷ�������ʵ��Ҫ���Ĺ���,�ڼ�������,gcc �Ѵ��뷭��ɻ�����ԡ�
�û�����ʹ�� ��-S�� ѡ�������в鿴,��ѡ��ֻ���б���������л��,���ɻ����롣
ʵ��:
gcc �CS test.i �Co test.s
���
�����ɻ�����ʶ����롣
�����ǰѱ�������ɵġ�.s���ļ�ת��Ŀ���ļ�
�����ڴ˿�ʹ��ѡ�-c���Ϳɿ�����������ת��Ϊ��.o���Ķ�����Ŀ�������
ʵ��:
gcc �Cc test.s �Co test.o
����
�����ɿ�ִ���ļ�����ļ���
�ڳɹ�����֮��,�ͽ��������ӽ�,�γɿ�ִ�г���
ʵ��:
gcc test.o �Co test
ldd
����:��ʾ����������������
�:
ldd [-vVdr] program ...
ʵ��
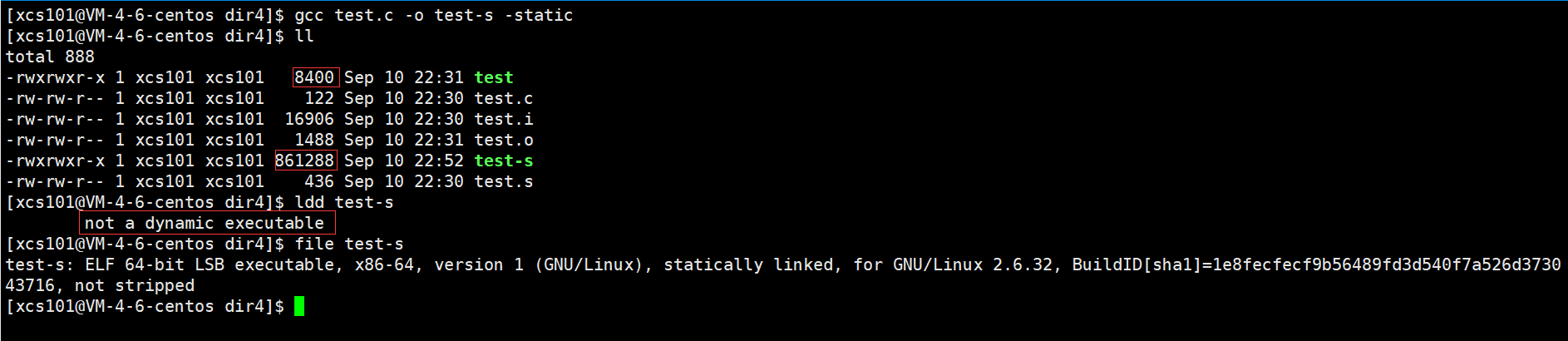
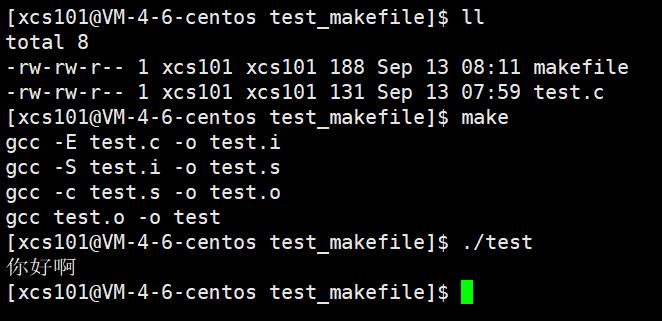
[xcs101@VM-4-6-centos dir4]$ ll
total 4
-rw-rw-r-- 1 xcs101 xcs101 122 Sep 10 22:30 test.c
[xcs101@VM-4-6-centos dir4]$ gcc -E test.c -o test.i
[xcs101@VM-4-6-centos dir4]$ gcc -S test.i -o test.s
[xcs101@VM-4-6-centos dir4]$ gcc -c test.s -o test.o
[xcs101@VM-4-6-centos dir4]$ gcc test.o -o test
[xcs101@VM-4-6-centos dir4]$ ll
total 44
-rwxrwxr-x 1 xcs101 xcs101 8400 Sep 10 22:31 test
-rw-rw-r-- 1 xcs101 xcs101 122 Sep 10 22:30 test.c
-rw-rw-r-- 1 xcs101 xcs101 16906 Sep 10 22:30 test.i
-rw-rw-r-- 1 xcs101 xcs101 1488 Sep 10 22:31 test.o
-rw-rw-r-- 1 xcs101 xcs101 436 Sep 10 22:30 test.s
[xcs101@VM-4-6-centos dir4]$ ldd test
linux-vdso.so.1 => (0x00007ffce4145000)
/$LIB/libonion.so => /lib64/libonion.so (0x00007f5715e9e000)
libc.so.6 => /lib64/libc.so.6 (0x00007f57159b7000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f57157b3000)
/lib64/ld-linux-x86-64.so.2 (0x00007f5715d85000)
[xcs101@VM-4-6-centos dir4]$ file test
test: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=47029e098e3c6f571c6dcbd4d4b8ec7a615e0ef6, not stripped
[xcs101@VM-4-6-centos dir4]$
��ͼ��ʾ��
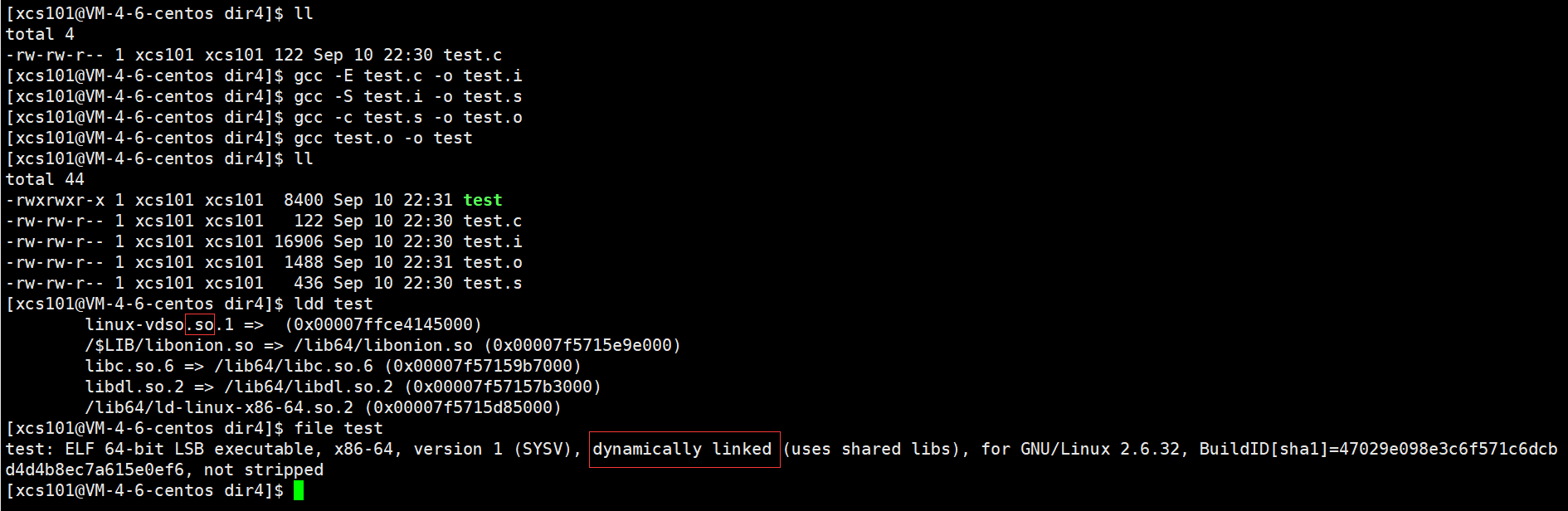
�����漰���������ĸ�����,���к�����һ���Ϊ��̬������̬�����֡�
��̬����ָ��������ʱ,�ѿ��ļ��Ĵ���ȫ�����뵽��ִ���ļ���,������ɵ��ļ��Ƚϴ�,��������ʱҲ�Ͳ�����Ҫ���ļ��ˡ������һ��Ϊ ��.a��
��̬����֮�෴,�ڱ�������ʱ��û�аѿ��ļ��Ĵ�����뵽��ִ���ļ���,�����ڳ���ִ��ʱ������ʱ�����ļ����ؿ�,�������Խ�ʡϵͳ�Ŀ�������̬��һ�����Ϊ ��.so��,��ǰ�������� libc.so.6 ���Ƕ�̬�⡣gcc �ڱ���ʱĬ��ʹ�ö�̬�⡣���������֮��,gcc �Ϳ������ɿ�ִ���ļ�,������ʾ��
gccĬ�����ɵĶ����Ƴ���,�Ƕ�̬���ӵ�,������ͨ�� file ������֤��
���ǿ���ʹ�� -static ѡ��ʵ�־�̬���ӡ��Աȷ���,���ɵ��ļ�����������
�����û����ܻ������������:
/usr/bin/ld: cannot find -lc
collect2: error: ld returned 1 exit status
ֻ��Ҫ��װ glibc-static ���ɡ�
sudo yum install -y glibc-static
gcc ѡ��
-E ֻ����Ԥ����,����������ļ�,����Ҫ�����ض���һ������ļ�����
-S ���뵽������Բ����л�������
-c ���뵽Ŀ�����
-o �ļ�������ļ�
-static ��ѡ������ɵ��ļ����þ�̬����
-g ���ɵ�����Ϣ��GNU �����������ø���Ϣ��
-shared ��ѡ�����ʹ�ö�̬��,���������ļ��Ƚ�С,������Ҫϵͳ�ɶ�̬��.
-O0
-O1
-O2
-O3 ���������Ż�ѡ���4������,-O0��ʾû���Ż�,-O1Ϊȱʡֵ,-O3�Ż��������
-w �������κξ�����Ϣ��
-Wall �������о�����Ϣ��
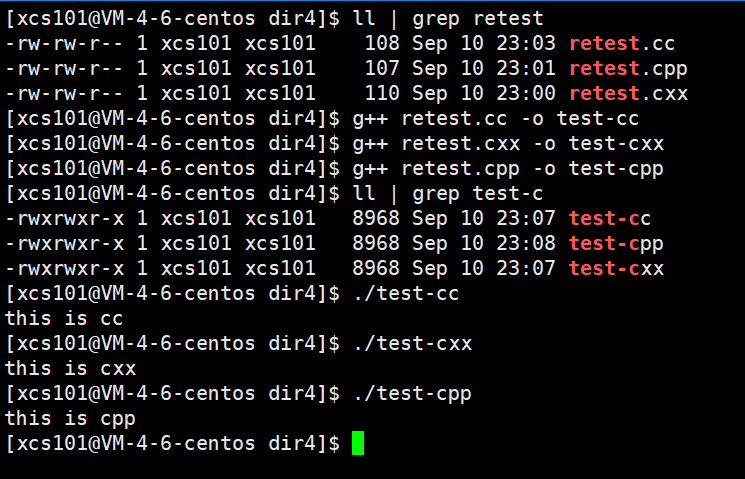
g++
g++ �� gcc ���ơ�����,C++��3����,�ֱ�Ϊ .cc / .cpp / .cxx ����ɼ���ͼ:
4. Linux������ - gdbʹ��
4.1 ����֪ʶ
����ķ�����ʽ������,debug ģʽ�� release ģʽ��
debug ģʽ�ǿɵ�ʽ��,release ģʽ�Dz��ɵ��Եġ�
Debug ͨ����Ϊ���汾,������������Ϣ,���Ҳ����κ��Ż�,���ڳ���Ա���Գ������������Ա�ġ�
Release ��Ϊ�����汾,�������ǽ����˸����Ż�,ʹ�ó����ڴ����С�������ٶ��϶������ŵ�,�Ա��û��ܺõ�ʹ�á��������û��ġ�
Linux �� gcc / g++ ��������ʱ��,Ĭ���Ƕ�̬����,ʹ�ö�̬�⡣���ɳ����Ķ����Ƴ���,Ĭ����releaseģʽ��
Ҫʹ�� gdb ����,������Դ�������ɶ����Ƴ����ʱ��,���� -g ѡ��,�ſ��Ա� gdb ���ԡ�
readelf
readelf <option(s)> elf-file(s)
����: ��ʾ�й� ELF �ļ�����Ϣ��
ѡ��
-a
--all ��ʾȫ����Ϣ,�ȼ��� -h -l -S -s -r -d -V -A -I
-h
--file-header ��ʾELF�ļ���ʼ���ļ�ͷ��Ϣ
-l
--program-headers
--segments ��ʾ����ͷ(��ͷ)��Ϣ
-S
--section-headers
--sections ��ʾ��ͷ��Ϣ
-g
--section-groups ��ʾ������Ϣ
-t
--section-details ��ʾ�ڵ���ϸ��Ϣ
-e
--headers ��ʾȫ��ͷ��Ϣ,�ȼ���: -h -l -S
-s
--syms
--symbols ��ʾ���ű��ڵ���Ϣ,������̬���ű�(.symtab)�Ͷ�̬���ű�(.dynsym)
���ֻ���Ķ�̬���ű�����ֱ��ʹ��--dyn-syms
�����������Ӧ�İ汾��Ϣ,�����ʾ�ð汾��Ϣ
�汾�ַ�����ʾΪ�������Ƶĺ�,����@�ַ���ͷ,����foo@VER_1��
�ڽ���δ�汾�����õķ���ʱ,����ð汾��Ҫʹ�õ�Ĭ�ϰ汾,����ʾΪ��,��������@�ַ�,����foo@@VER_2
-n
--notes ��ʾnote��/�ڵ���Ϣ
-r
--relocs ��ʾ���ض�λ�ڵ���Ϣ
-u
--unwind ��ʾunwind����Ϣ
-d
--dynamic ��ʾ��̬�ڵ���Ϣ
-V
--version-info ��ʾ�汾�ε���Ϣ
-A
--arch-specific ��ʾ�ض��ṹ��ϵ��Ϣ
-c
--archive-index ��ʾ�������ĵ��ı�ͷ�����а������ļ�����������Ϣ
-D
--use-dynamic ��ʾ����ʱ,ʹ�ö�̬���еķ��Ź�ϣ��,�����Ƿ��ű��ڡ���ʾ�ض�λʱ,ʹ��ʾ��̬�ض�λ�����Ǿ�̬�ض�λ
-x <number or name>
--hex-dump=<number or name>
��ʾָ���ڵ�����Ϊʮ�������ֽ�
-p <number or name>
--string-dump=<number or name>
��ʾָ���ڵ�����Ϊ�ɴ�ӡ���ַ���
-R <number or name>
--relocated-dump=<number or name>
��ʾָ���ڵ�����Ϊʮ�������ֽ�,������ʾ֮ǰ���¶�λ
-z
--decompress Ҫ��x,R��pѡ��洢�Ľ�����ʾ֮ǰ�Ƚ�ѹ�������δѹ��,��ԭ����ʾ
-w[lLiaprmfFsOoRtUuTgAckK]
--debug-dump[=rawline,=decodedline,=info,=abbrev,=pubnames,=aranges,=macro,=frames,=frames-interp,=str,=str-offsets,=loc,=Ranges,=pubtypes,=trace_info,=trace_abbrev,=trace_aranges,=gdb_index,=addr,=cu_index,=links,=follow-links]
��ʾ�ļ���DWARF���Խڵ�����
-I
--histogram ��ʾ���ű�ʱ,��ʾbucket list���ȵ���״ͼ
-W
--wide ����������ȳ���80���ַ���ʾ��һ����
-H
--help ��ʾreadelf�������������ѡ��
-v
--version ��ʾreadelf�İ汾��Ϣ
@file ��<file>�л�ȡ������ѡ��
ʹ������
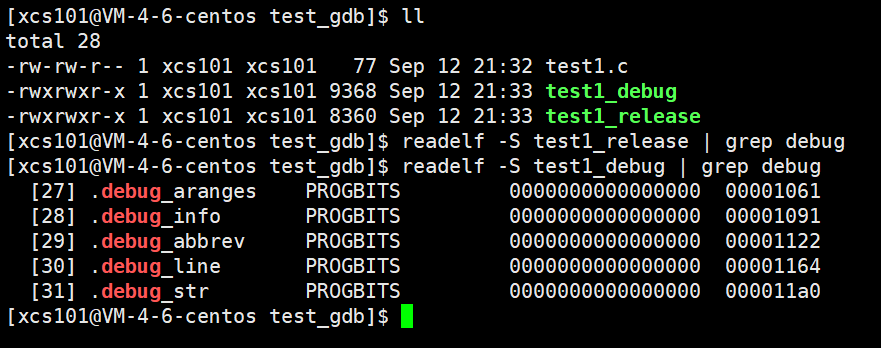
4.2 ʹ��
gdb [-help] [-nh] [-nx] [-q] [-batch] [-cd=dir] [-f] [-b bps]
[-tty=dev] [-s symfile] [-e prog] [-se prog] [-c core] [-p procID]
[-x cmds] [-d dir] [prog|prog procID|prog core]
ѡ��
list/l �к�: ��ʾbinFileԴ����,�����ϴε�λ��������,ÿ����10�С�
list/l ������: �г�ij��������Դ���롣
r �� run: �����
n �� next: ����ִ�С�--���� Visual Studio �е�F10
s��step: ���뺯������--���� Visual Studio �е�F11
break(b) �к�: ��ijһ�����öϵ�
break ������: ��ij��������ͷ���öϵ�
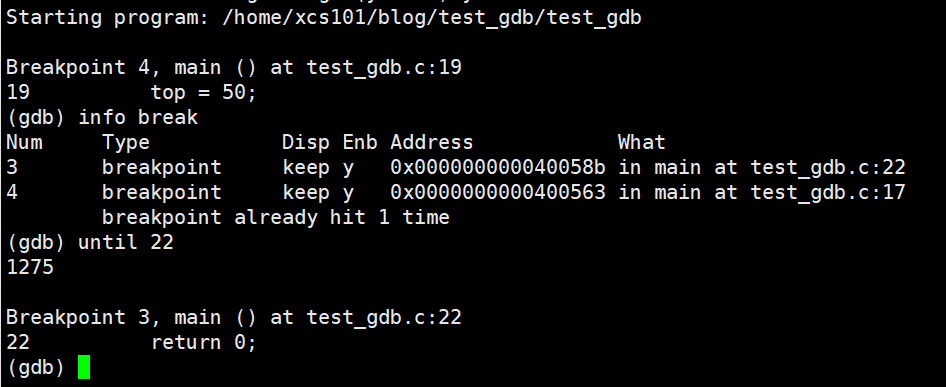
info break : �鿴�ϵ���Ϣ��
finish: ִ�е���ǰ��������,Ȼ��ͦ�����ȴ�����
print(p): ��ӡ����ʽ��ֵ,ͨ������ʽ�����ı�����ֵ���ߵ��ú���p ����:��ӡ����ֵ��
set var: �ı�����ֵ
continue(��c): �ӵ�ǰλ�ÿ�ʼ�������ǵ���ִ�г���
run(��r): �ӿ�ʼ�������ǵ���ִ�г���--���� Visual Studio �е�F5
delete breakpoints: ɾ�����жϵ�
delete breakpoints n: ɾ�����Ϊn�Ķϵ�
disable breakpoints: ���öϵ�
enable breakpoints: ���öϵ�
info(��i) breakpoints: �ο���ǰ��������Щ�ϵ�
display ������: ���ٲ鿴һ������,ÿ��ͣ��������ʾ����ֵ
undisplay: ȡ������ǰ���õ���Щ�����ĸ���
until X�к�: ����X��
breaktrace(��bt): �鿴�����������ü�����(���ö�ջ)
info(i) locals: �鿴��ǰջ֡�ֲ�������ֵ
quit: �˳�gdb
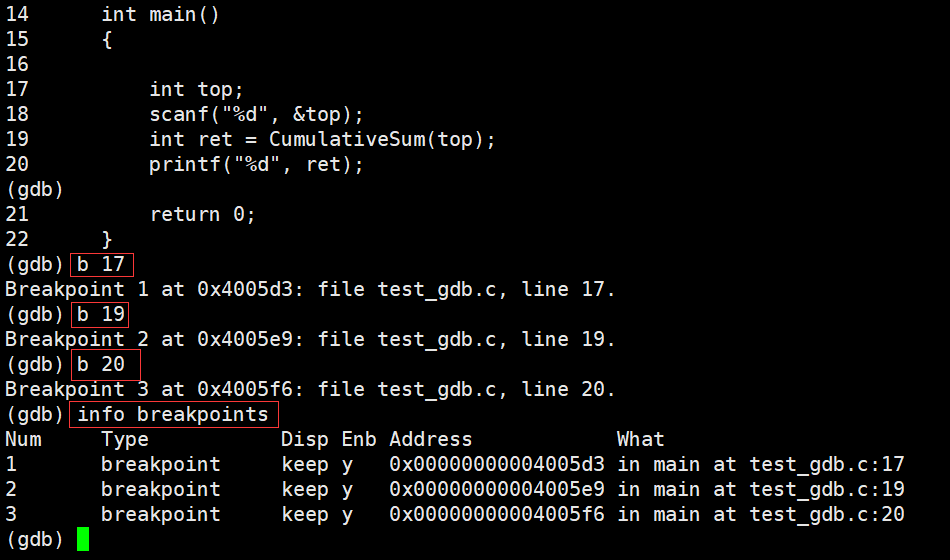
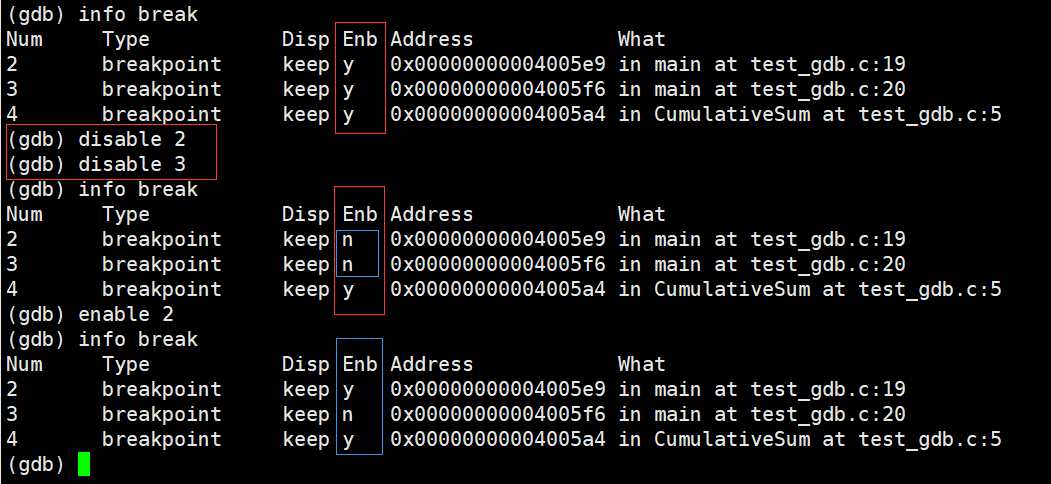
���Ӷϵ�,�鿴�ϵ���Ϣ:
ɾ���ϵ�,��ɾ�����š�ɾ����,�µĶϵ����ǵ����ġ�
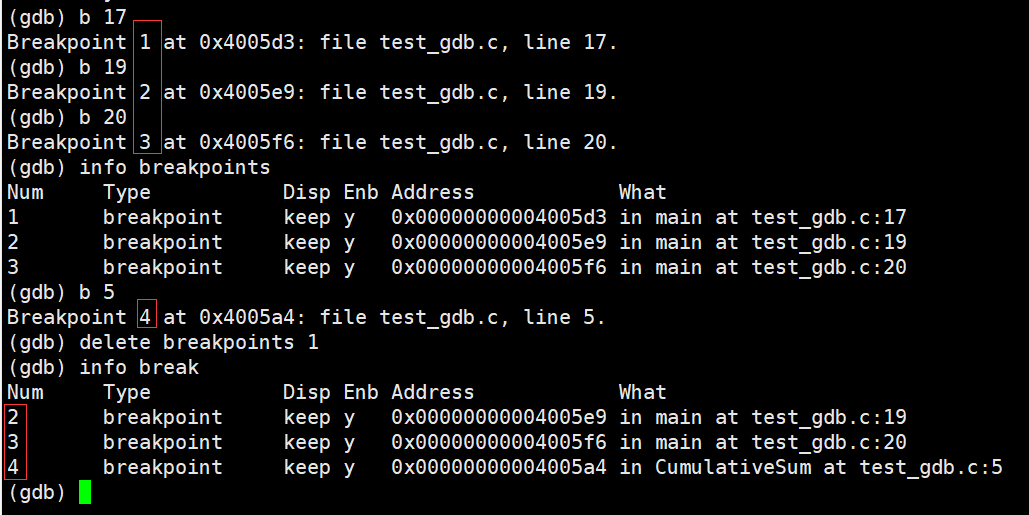
���� / ʹ�ܶϵ�
Ŀ��:���µ��Ժۼ���
�������Ը��ļ�����չʾ:
#include <stdio.h>
int CumulativeSum(int top)
{
int sum = 0;
int i = 0;
for(; i <= top; i++)
{
sum += i;
}
return sum;
}
int main()
{
int top;
//scanf("%d", &top);
top = 50;
int ret = CumulativeSum(top);
printf("%d", ret);
return 0;
}
�ڵ� 11 �� 20 �����öϵ㡣
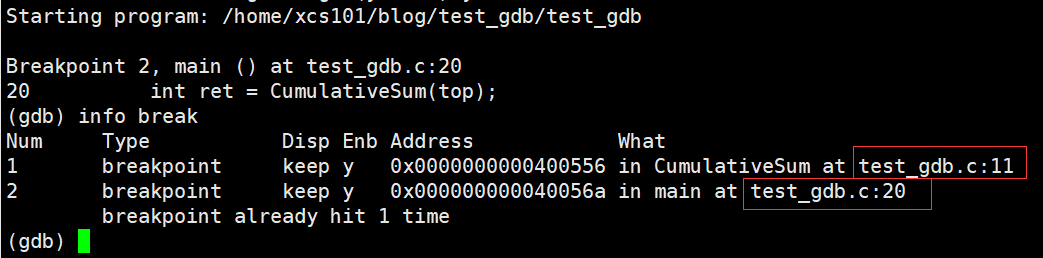
��������,��һ��ִ�е�20�С�
-
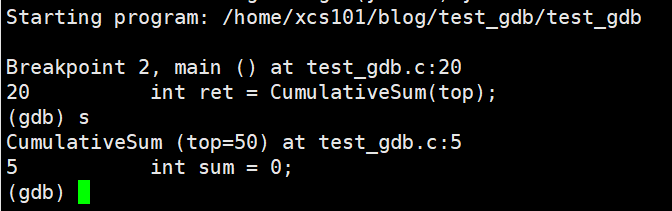
���� s
? �˹������� Visual Studio �е� F11,���뺯���ڲ���
-
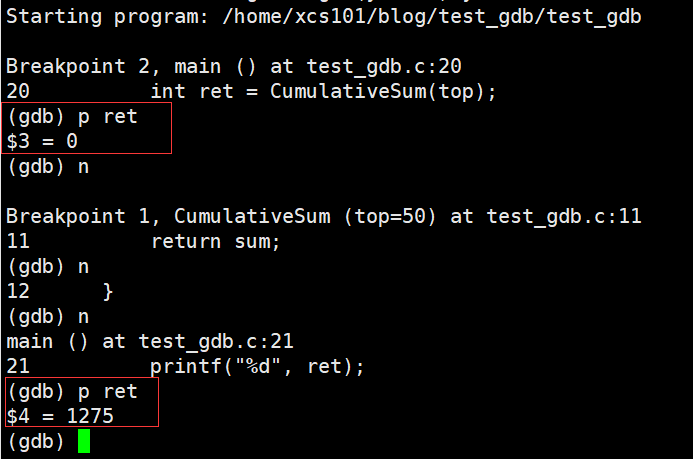
���� n
�˹������� Visual Studio �е� F10,����ִ�С��Ա�ִ��ǰ�� ret ֵ�ı仯��
-
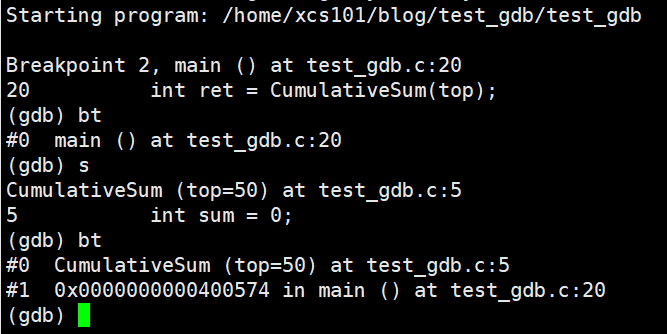
���ö�ջ �� bt
-
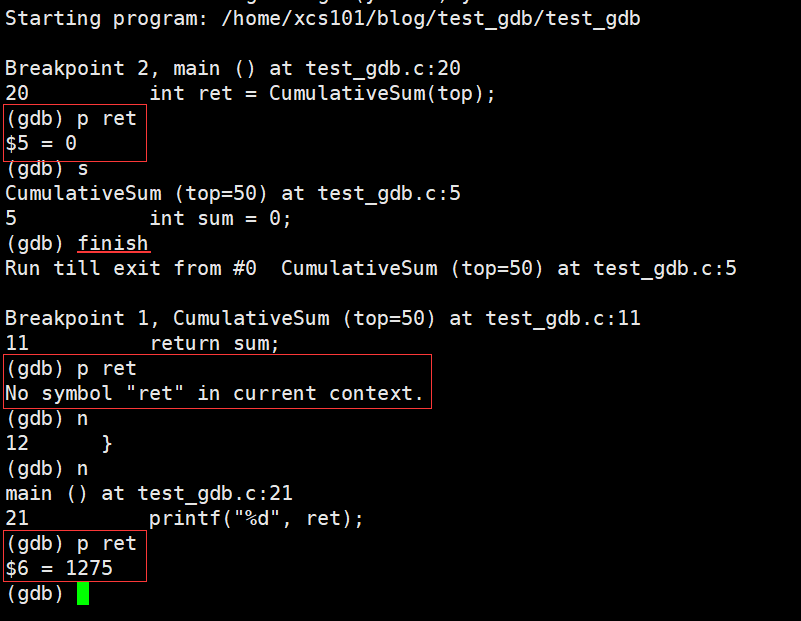
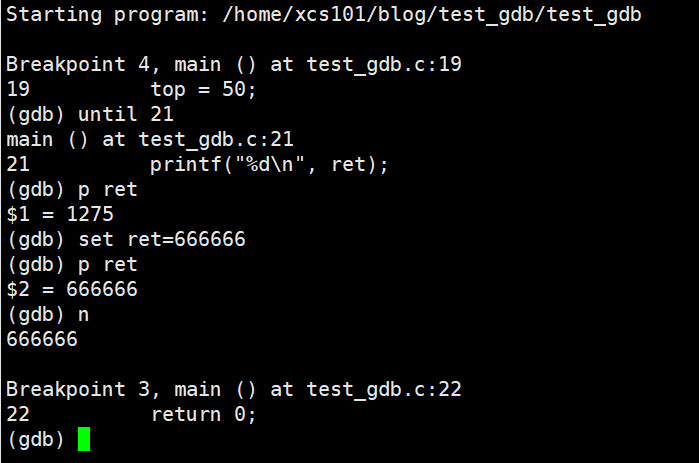
finish
finish ִ�е���ǰ��������,Ȼ��ͣ�����ȴ����ע�� ret ֵ�仯��
-
until
ע:����ת·�����жϵ�,����ִ�е���Ӧ�ϵ㴦��
-
set var
�����ı�����ֵ,���Ƽ���,�����ڵ����ɺ���/ֵ ����Ĵ�����ת���⡣
������ gdb һЩ��ʹ�ó�����
5. �Զ����������� - make/Makefile
5.1 ����
һ�������е�Դ�ļ�������,�䰴���͡����ܡ�ģ��ֱ�������ɸ�Ŀ¼��,makefile������һϵ�еĹ�����ָ��,��Щ�ļ���Ҫ�ȱ���,��Щ�ļ���Ҫ�����,��Щ�ļ���Ҫ���±���,�����ڽ��и����ӵĹ��ܲ�����
��Visual Studio �����д���,����Զ��������ǽ������������ϵ��
makefile �����ĺô����ǡ������Զ������롱,һ��д��,ֻ��Ҫһ��make����,����������ȫ�Զ�����,��������������������Ч�ʡ�
make ��һ�������,��һ������makefile��ָ��������,һ����˵,�������IDE�����������,����:Delphi��make,Visual C++��nmake,Linux��GNU��make���ɼ�,makefile����Ϊ��һ���ڹ��̷���ı��뷽����
make ��һ������,makefile��һ���ļ�,��������ʹ��,�����Ŀ�Զ���������
5.2 ʵ������
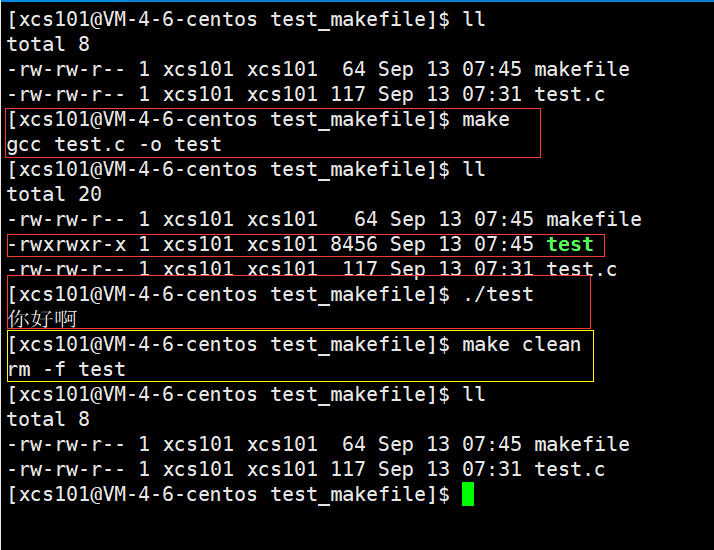
makefile ����:
test:test.c
gcc test.c -o test
.PHONY:clean
clean:
rm -f test
test.c ����:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("��ð�\n");
fflush(stdout);
sleep(5);
return 0;
}
���������� make / make clean ʱ,���Զ�ִ�в��ִ���,���ұ���������ļ�Ҳ�ǿ�ִ�еġ�
5.3 ���
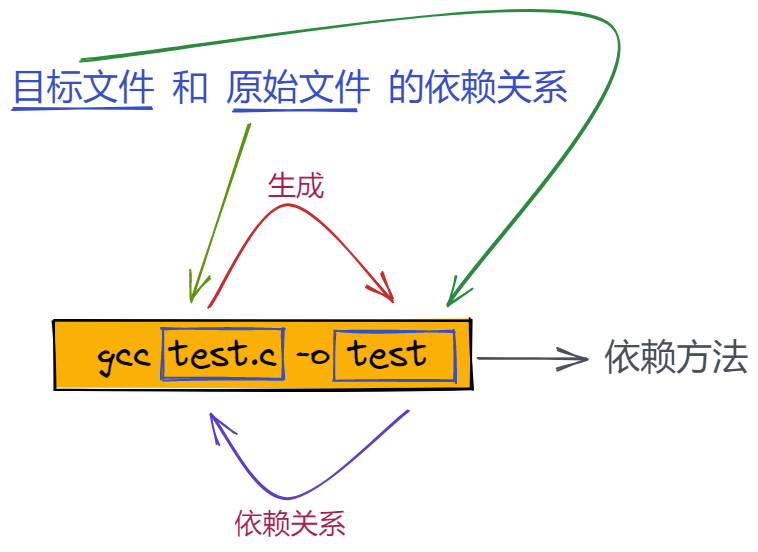
����������Ҫ֪������,make ��һ������,makefile ��һ���ļ�,���ļ������� Ŀ���ļ���ԭʼ�ļ���������ϵ,�Լ�����������Ȼ������������ϵ������,����������������
�����
���(target): Ŀ���ļ�1 Ŀ���ļ�2
gcc -o �������Ŀ�ִ���ļ� Ŀ���ļ�1 Ŀ���ļ�2
�Ǹ���� ( target) ����������Ҫ��������Ϣ,��Ŀ���ļ����Ǿ�������Ե� object files, �Ǵ�����ִ���ļ���������� tab ������ͷ����һ��!�ر���������, �������б���Ҫ�� tab ������Ϊ��ͷ������!���Ĺ����������������:
�� makefile ���е� # ����ע��;
tab ��Ҫ�������� (���� gcc ���������ָ��) �ĵ�һ���ַ�;
��� (target) �������ļ�(����Ŀ���ļ�)֮������ ��:�� ����
����
���������Ѵ����������������Ѵ�绰˵,������������,�Ⲣ���ܴﵽ�����Ѵ�����Ŀ��,��仰����ȷ������������ϵ����������˵,�����Ҵ�һ�ݷ���,��ʹﵽ������������
ԭ��
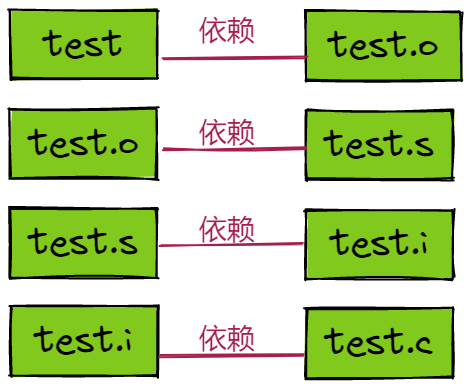
���ǽ����ɹ���������������
test:test.o gcc test.o -o test
test.o:test.s
gcc -c test.s -o test.o
test.s:test.i
gcc -S test.i -o test.s
test.i:test.c
gcc -E test.c -o test.i
.PHONY:clean
clean:
rm -f test
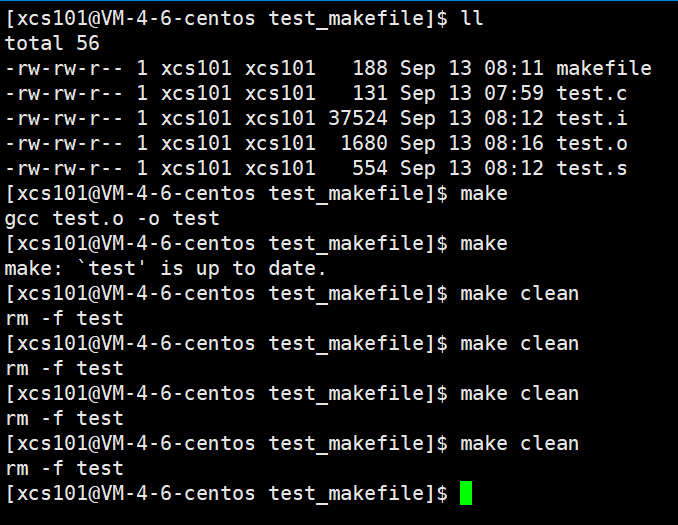
��������:
-
make���ڵ�ǰĿ¼�������ֽ� ��Makefile�� �� ��makefile�� ���ļ���
-
����ҵ�,�������ļ��еĵ�һ��Ŀ���ļ�(target),�������������,�����ҵ� ��test�� ����ļ�,��������ļ���Ϊ���յ�Ŀ���ļ���
-
��� test �ļ�������,���� test �������ĺ���� test.o �ļ����ļ���ʱ��Ҫ�� test ����ļ���(������ touch ����),��ô,���ͻ�ִ�к�������������������� test ����ļ���
�������:

-
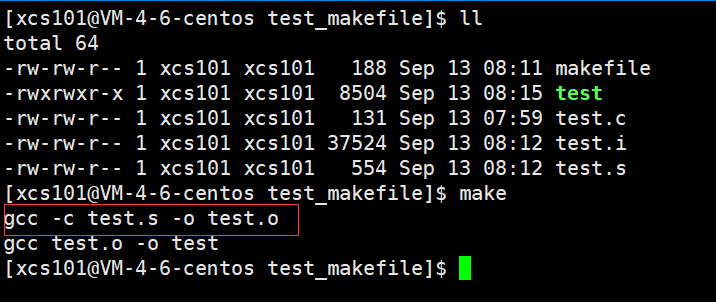
���hello�������� test.o �ļ�������,��ômake���ڵ�ǰ�ļ�����Ŀ��Ϊ test.o �ļ���������,����ҵ����ٸ�����һ����������test.o �ļ���(���е���һ����ջ�Ĺ���)
ɾ���� test.o �ļ�,���Խ������:
-
��Ȼ,����ļ����Ǵ��ڵ���,����make������ test.o �ļ�,Ȼ������ test.o �ļ����� make ���ռ�����,Ҳ����ִ���ļ� test�ˡ�
-
���������make��������,make ��һ����һ���ȥ���ļ���������ϵ,ֱ�����ձ������һ��Ŀ���ļ���
-
����Ѱ�Ĺ�����,������ִ���,��������������ļ��Ҳ���,��ômake�ͻ�ֱ���˳�,������,�����������������Ĵ���,���DZ��벻�ɹ�,make ����������
-
makeֻ���ļ���������,��,�����������������ϵ֮��,ð�ź�����ļ����Dz���,��ô�Բ���,�ҾͲ���������
ע��
test:test.o gcc test.o -o test
����, gcc ǰ�����Ϊ [ Tab ]����,�������ǿո� !!!
.PHONY
����:���� �� αĿ�� ��,���ǿ�ִ�еġ�
make ��Ŀ��,���������ļ�����ʱ���Ŀ���ļ�������Ŀ���ļ��������ſ���ִ�С�
����
����ʹ��������Ŵ���,Ч��һ�¡�����:
gcc $^ -o $@
6. Linux ���� - ������
6.1 /r �� /n ����
�س����ͻ��з�����
�������ı�ʱ,�س���һ��,�Ϳ�ʼ���µ�һ��,���ϰ�����÷����������Ƕ� �س���(CR, Carriage Return)��\r�� �� ���з�(LF, Linefeed)��\n�� �����⡣
�� C/C++ ��ԭ��ԭζ�ر����˶Ի��з�������,�س��� ��\r�� ����ʾ�ص�����,��û�а������еĶ���,�������� ��\n�� ����ɵġ�
��֮���Ƶ�ת���ַ�:�˸�(BS, Backspace)��\b��,����˼��,����ַ�����������ǰ��һ��,ֵ��ע�����:�˸� ��\b�� �ͻس� ��\r�� ��ֻ�ǹ����ƶ�,����ɾ��ǰ����ı�!
ִ�����д���:
printf("abc\r\ncba\rrr\bz\n");
�������:
abc
rza
����: ����� abc �� \r ʹ�س����ص���ǰ�м���һ�е�����,����ɾ���ַ�,���Ե�һ��������ʾ abc,Ȼ�� \n ʹ����Ƶ���һ��,������� cba,\r �ٴ��ù��ص�����,��β�����,ֱ�ӽ������ rr,�����ﵽ��Ч�������������ַ� cb ���滻Ϊ rr,���� \b ʹ�����ǰһλ,��� z,�����ڶ��� r �ͱ������� z,Ȼ����,���յڶ�����ʾ������� rza��
6.2 ����������
��������ִ�����д���:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("��ð�");
sleep(5);
return 0;
}
����Ϊ�����ʲô��?
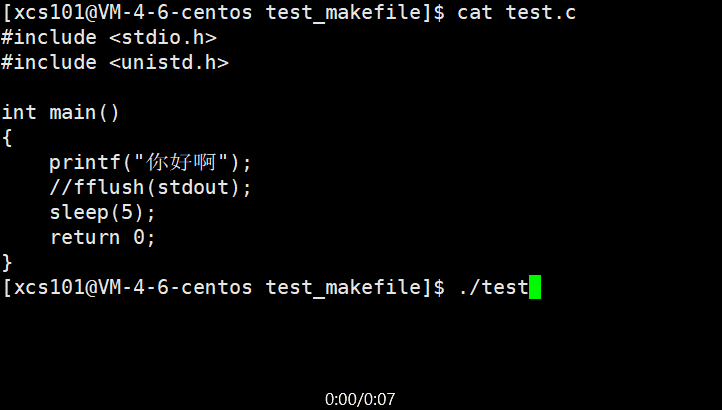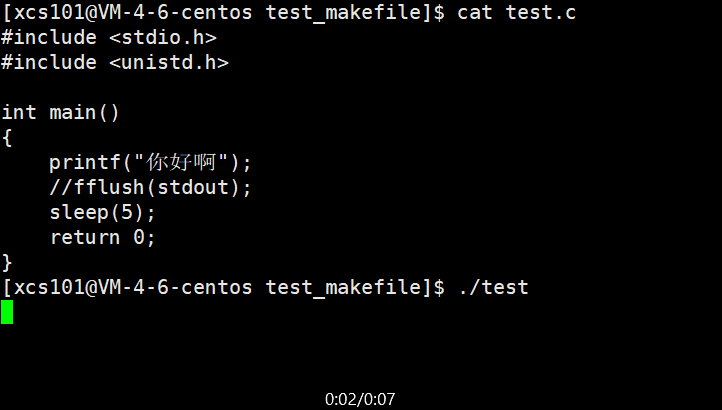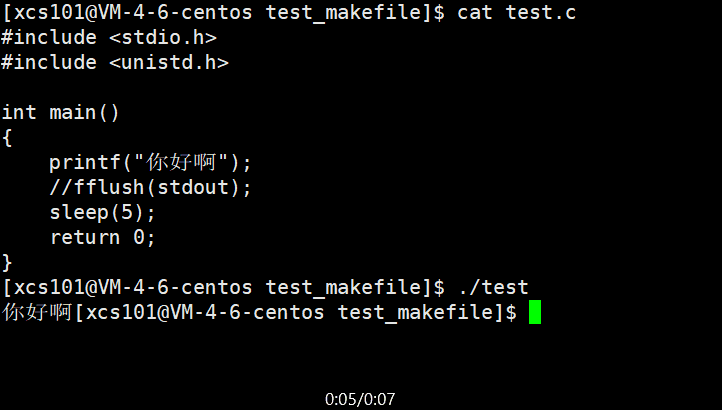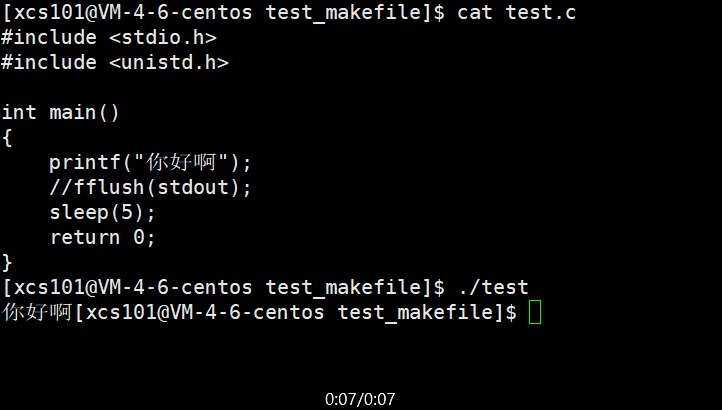
ʵ�������п��Է���,����ð��� �ǹ���5��ų��ֵġ�����ڡ���ð���������� ��\n��,����������֡���ô,��printf ִ����,�ַ���ȥ�Ķ�����?ʵ���ϴ������������С��䱾�ʾ���һ���ڴ�ռ�,�ں��ʵ�ʱ��ˢ�³�ȥ����ô,Ϊʲô�Ӳ��� ��\n��Ч����һ����?����漰��ˢ�²�����
һ����˵,�����¼���ˢ�²���:
ֱ��ˢ��,������
������д��,��ˢ��-ȫ����
���� '\n' ��ˢ��-��ˢ��
ǿ��ˢ��
���ڴ�,���ǿ��Խ������Լ���,�Ϳ��Կ���Ԥ��Ч����
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("��ð�");
sleep(5);
fflush(stdout);
return 0;
}
6.3 ����������
������������,���ǿ��Ժ����ɵ�д�����д���:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define NUM 102
int main()
{
const char* op = "-/\\|";
char bar[NUM + 2];
memset(bar, 0, sizeof(bar));
int count = 0;
while(count <= 100)
{
bar[count] = '#';
printf("[%-100s][%d%%][%c]\r", bar, count, op[count % 4]);
count++;
usleep(100000);
fflush(stdout);
}
printf("\n");
return 0;
}
ע��:
%-100s ��������롣
������:

7. ʹ�� git ������
��װ git
sudo yum install git
������Ŀ������
git clone [url]
�ύ1- git add
������ŵ��ղ����غõ�Ŀ¼�� ��
git add [�ļ���]
�ύ2- git commit
�ύ�Ķ������� ��
git commit .
���� ��.�� ��ʾ��ǰĿ¼��
�ύ��ʱ��Ӧ��ע���ύ��־,�����Ķ�����ϸ���� ,�в���������д��
�ύ3 - git push
git push
��Ҫ�����û������롣ͬ���ɹ���,ˢ�²ֿ�ҳ����ܿ�������Ķ��ˡ�
��������������ύ,��ҿ�������������
���Ͼ��DZ��� Linux �����������������ߵļ��ܽ�,��ӭ��λ����ָ��!