����Ŀ¼
1. ���ۻ���
1.1 ������
���������ģ���DZ�ʾ����������ʵ�����з�������νṹ������������ת����һ��if-then����ļ���,Ҳ���Կ����Ƕ����������ռ仮���ϵ�����������ʷֲ���
������ѧϰּ�ڹ���һ����ѵ��������Ϻܺ�,���Ҹ��Ӷ�С�ľ���������Ϊ�ӿ��ܵľ�������ֱ��ѡȡ���ž�������NP��ȫ���⡣��ʵ�в�������ʽ����ѧϰ���ŵľ�������
������ѧϰ�㷨����3����:����ѡ���������ɺ����ļ�֦�����õ��㷨��ID3��C4.5��CART��
1.2 ����ѡ��
����ѡ���Ŀ������ѡȡ��ѵ�������ܹ����������������ѡ��Ĺؼ��������õ�������:
��Ϣ����
�������� D D D������ A A A����Ϣ����(ID3)
g ( D , A ) = H ( D ) ? H ( D �O A ) g(D, A)=H(D)-H(D|A) g(D,A)=H(D)?H(D�OA)
H ( D ) = ? �� k = 1 K �O C k �O �O D �O log ? 2 �O C k �O �O D �O H(D)=-\sum_{k=1}^{K} \frac{\left|C_{k}\right|}{|D|} \log _{2} \frac{\left|C_{k}\right|}{|D|} H(D)=?k=1��K?�OD�O�OCk?�O?log2?�OD�O�OCk?�O?
H ( D �O A ) = �� i = 1 n �O D i �O �O D �O H ( D i ) H(D | A)=\sum_{i=1}^{n} \frac{\left|D_{i}\right|}{|D|} H\left(D_{i}\right) H(D�OA)=i=1��n?�OD�O�ODi?�O?H(Di?)
����, H ( D ) H(D) H(D)�����ݼ� D D D����, H ( D i ) H(D_i) H(Di?)�����ݼ� D i D_i Di?����, H ( D �O A ) H(D|A) H(D�OA)�����ݼ� D D D������ A A A�������ء� D i D_i Di?�� D D D������ A A Aȡ�� i i i��ֵ�������Ӽ�, C k C_k Ck?�� D D D�����ڵ� k k k��������Ӽ��� n n n������ A A Aȡ ֵ�ĸ���, K K K����ĸ�����
��Ϣ�����
�������� D D D������ A A A����Ϣ�����(C4.5)
g R ( D , A ) = g ( D , A ) H ( D ) g_R(D, A)=\frac{g(D, A)}{H(D)} gR?(D,A)=H(D)g(D,A)?
����, g ( D , A ) g(D,A) g(D,A)����Ϣ����, H ( D ) H(D) H(D)�����ݼ� D D D�������� A ���ء�
ʹ����Ϣ����ȵ�Ŀ��:����ѡ��������ѡ������ȡֵ�϶������,�� ID
����ָ��
�������� D D D�Ļ���ָ��(CART)
Gini ? ( D ) = 1 ? �� k = 1 K ( �O C k �O �O D �O ) 2 \operatorname{Gini}(D)=1-\sum_{k=1}^{K}\left(\frac{\left|C_{k}\right|}{|D|}\right)^{2} Gini(D)=1?k=1��K?(�OD�O�OCk?�O?)2
���� A A A�����¼��� D D D�Ļ���ָ��:
Gini ? ( D , A ) = �O D 1 �O �O D �O Gini ? ( D 1 ) + �O D 2 �O �O D �O Gini ? ( D 2 ) \operatorname{Gini}(D, A)=\frac{\left|D_{1}\right|}{|D|} \operatorname{Gini}\left(D_{1}\right)+\frac{\left|D_{2}\right|}{|D|} \operatorname{Gini}\left(D_{2}\right) Gini(D,A)=�OD�O�OD1?�O?Gini(D1?)+�OD�O�OD2?�O?Gini(D2?)
1.3 ������������
ͨ��ʹ�� ��Ϣ���������Ϣ������������ָ����С ��Ϊ����ѡ�������������������ͨ��������Ϣ���������ָ��,�Ӹ���㿪ʼ,�ݹ�ز��������������൱������Ϣ����������ϵ�ѡȡ�ֲ����ŵ�����,��ѵ�����ָ�Ϊ�ܹ�������ȷ������Ӽ���
1.4 ��֦
�������ɵľ��������ڹ��������,��Ҫ�������м�֦,�Լ�ѧ���ľ��������������ļ�֦,�����������ɵ����ϼ���һЩҶ����Ҷ������ϵ�����,�����丸����������Ϊ�µ�Ҷ���,�Ӷ������ɵľ�������
2. ���� C4.5 �㷨����������
2.1 ���ݼ�
������������ݼ�,ͨ�����䡢�������������Ӻ��Ŵ�������о��Ƿ���Դ���:
def create_data():
datasets = [['����', '��', '��', 'һ��', '��'],
['����', '��', '��', '��', '��'],
['����', '��', '��', '��', '��'],
['����', '��', '��', 'һ��', '��'],
['����', '��', '��', 'һ��', '��'],
['����', '��', '��', 'һ��', '��'],
['����', '��', '��', '��', '��'],
['����', '��', '��', '��', '��'],
['����', '��', '��', '�dz���', '��'],
['����', '��', '��', '�dz���', '��'],
['����', '��', '��', '�dz���', '��'],
['����', '��', '��', '��', '��'],
['����', '��', '��', '��', '��'],
['����', '��', '��', '�dz���', '��'],
['����', '��', '��', 'һ��', '��'],
]
labels = [u'����', u'�й���', u'���Լ��ķ���', u'�Ŵ����', u'���']
# �������ݼ���ÿ��ά�ȵ�����
return datasets, labels
2.2 ������
C4.5 �㷨������Ϣ�����,�����Ҫ�����غ�������,�Ӷ�������Ϣ����,��������Ϣ�����:
# ������Ϣ��
def calculate_entropy(datasets):
datasets = np.array(datasets)
sample_number = len(datasets)
freq = Counter(datasets[:, -1]).most_common()
probabilities = [item[1] / sample_number for item in freq]
ent = - sum([p * math.log(p, 2) for p in probabilities])
return ent
# ������
def calculate_cond_entropy(datasets, axis):
feature_sets = {}
for data in datasets:
feature = data[axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(data)
cond_ent = sum([len(d) / len(datasets) * calculate_entropy(d) for d in feature_sets.values()])
return cond_ent
# ��Ϣ����
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gains(datasets):
axises = [i for i in range(len(datasets[0])-1)]
ent = calculate_entropy(datasets)
best_feature = []
for axis in axises:
info_gain_axis = info_gain(ent, calculate_cond_entropy(datasets, axis))
best_feature.append((axis, info_gain_axis))
print(f'feature: {labels[axis]}\tinfo_gain: {info_gain_axis}')
best_feature = max(best_feature, key=lambda x: x[-1])
return best_feature
best_feature = info_gains(datasets)
print(labels[best_feature[0]])
�������:
feature: ���� info_gain: 0.08300749985576883
feature: ��� info_gain: 0.32365019815155627
feature: ���Լ��ķ��� info_gain: 0.4199730940219749
feature: �Ŵ���� info_gain: 0.36298956253708536
���Լ��ķ���
2.3 ����ģ��
2.3.1 �ڵ� Node
root Ϊ True ������ǰ�ڵ�Ϊ��ײ�Ҷ�ڵ�,tree �洢������,�ڹ��� DT(Decision Tree) ʱͨ���ݹ齫�� tree ����:
# ����ڵ��� ������
class Node:
def __init__(self, root=True, label=None, feature_name=None, feature=None):
self.root = root
self.label = label
self.feature_name = feature_name
self.feature = feature
self.tree = {}
self.result = {
'label:': self.label,
'feature': self.feature,
'tree': self.tree
}
def __repr__(self):
return '{}'.format(self.result)
def add_node(self, val, node):
self.tree[val] = node
def predict(self, features):
if self.root is True:
return self.label
return self.tree[features[self.feature]].predict(features)
2.3.2 Decision Tree
����,�������صĺ������ӵ��� DTree ��,����ͨ�� �ݹ� �ķ�ʽ���� DTree:
class DTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon
self._tree = {}
# ��
@staticmethod
def calc_ent(datasets):
data_length = len(datasets)
label_count = {}
for i in range(data_length):
label = datasets[i][-1]
if label not in label_count:
label_count[label] = 0
label_count[label] += 1
ent = -sum([(p / data_length) * log(p / data_length, 2)
for p in label_count.values()])
return ent
# ����������
def cond_ent(self, datasets, axis=0):
data_length = len(datasets)
feature_sets = {}
for i in range(data_length):
feature = datasets[i][axis]
if feature not in feature_sets:
feature_sets[feature] = []
feature_sets[feature].append(datasets[i])
cond_ent = sum([(len(p) / data_length) * self.calc_ent(p)
for p in feature_sets.values()])
return cond_ent
# ��Ϣ����
@staticmethod
def info_gain(ent, cond_ent):
return ent - cond_ent
def info_gain_train(self, datasets):
count = len(datasets[0]) - 1
ent = self.calc_ent(datasets)
best_feature = []
for c in range(count):
c_info_gain = self.info_gain(ent, self.cond_ent(datasets, axis=c))
best_feature.append((c, c_info_gain))
# �Ƚϴ�С
best_ = max(best_feature, key=lambda x: x[-1])
return best_
def train(self, train_data):
"""
input:���ݼ�D(DataFrame��ʽ),������A,��ֵeta
output:������T
"""
_, y_train, features = train_data.iloc[:, :
-1], train_data.iloc[:,
-1], train_data.columns[:
-1]
# 1,��D��ʵ������ͬһ��Ck,��TΪ���ڵ���,������Ck��Ϊ��������,����T
if len(y_train.value_counts()) == 1:
return Node(root=True, label=y_train.iloc[0])
# 2, ��AΪ��,��TΪ���ڵ���,��D��ʵ����������Ck��Ϊ�ýڵ������,����T
if len(features) == 0:
return Node(
root=True,
label=y_train.value_counts().sort_values(
ascending=False).index[0])
# 3,���������Ϣ���� ͬ5.1,AgΪ��Ϣ������������
max_feature, max_info_gain = self.info_gain_train(np.array(train_data))
max_feature_name = features[max_feature]
# 4,Ag����Ϣ����С����ֵeta,����TΪ���ڵ���,����D����ʵ����������Ck��Ϊ�ýڵ������,����T
if max_info_gain < self.epsilon:
return Node(
root=True,
label=y_train.value_counts().sort_values(
ascending=False).index[0])
# 5,����Ag�Ӽ�
node_tree = Node(
root=False, feature_name=max_feature_name, feature=max_feature)
feature_list = train_data[max_feature_name].value_counts().index
for f in feature_list:
sub_train_df = train_data.loc[train_data[max_feature_name] ==
f].drop([max_feature_name], axis=1)
# 6, �ݹ�������
sub_tree = self.train(sub_train_df)
node_tree.add_node(f, sub_tree)
# pprint.pprint(node_tree.tree)
return node_tree
def fit(self, train_data):
self._tree = self.train(train_data)
return self._tree
def predict(self, X_test):
return self._tree.predict(X_test)
2.4 ����
datasets, labels = create_data()
data_df = pd.DataFrame(datasets, columns=labels)
dt = DTree()
tree = dt.fit(data_df)
print(tree)
print(dt.predict(['����', '��', '��', 'һ��'])) # ��
�������(�õ�һ�����ֵ��ʾ����):
{'label:': None, 'feature': 2, 'tree': {'��': {'label:': None, 'feature': 1, 'tree': {'��': {'label:': '��', 'feature': None, 'tree': {}}, '��': {'label:': '��', 'feature': None, 'tree': {}}}}, '��': {'label:': '��', 'feature': None, 'tree': {}}}}
3. sklearn ʵ��
�� sklearn.tree ģ������ DecisionTreeClassifier ģ��:

Python ��������:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def create_data():
iris = load_iris()
df = pd.DataFrame(
data=iris.data,
columns=iris.feature_names)
df['label'] = iris.target
df.columns = [
'sepal length', 'sepal width',
'petal length' ,'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
return data[:, [0, 1]], data[:, -1], df
X, y, df = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = DecisionTreeClassifier(criterion='gini')
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print(score)
DecisionTreeClassifier ��Ĭ��ѡ���������� gini ��С,����������:
0.933333
�ɹ��� 93.3% 🍻
����,���ǿ���ʹ�� sklearn.tree.plot_tree ���Ƴ�������:
from sklearn import tree
import matplotlib.pyplot as plt
feature_names = load_iris().feature_names
plt.figure(figsize=(10, 8))
tree.plot_tree(clf, filled = True, feature_names=df.columns)
plt.savefig('./tree.png')
plt.show()
�������:
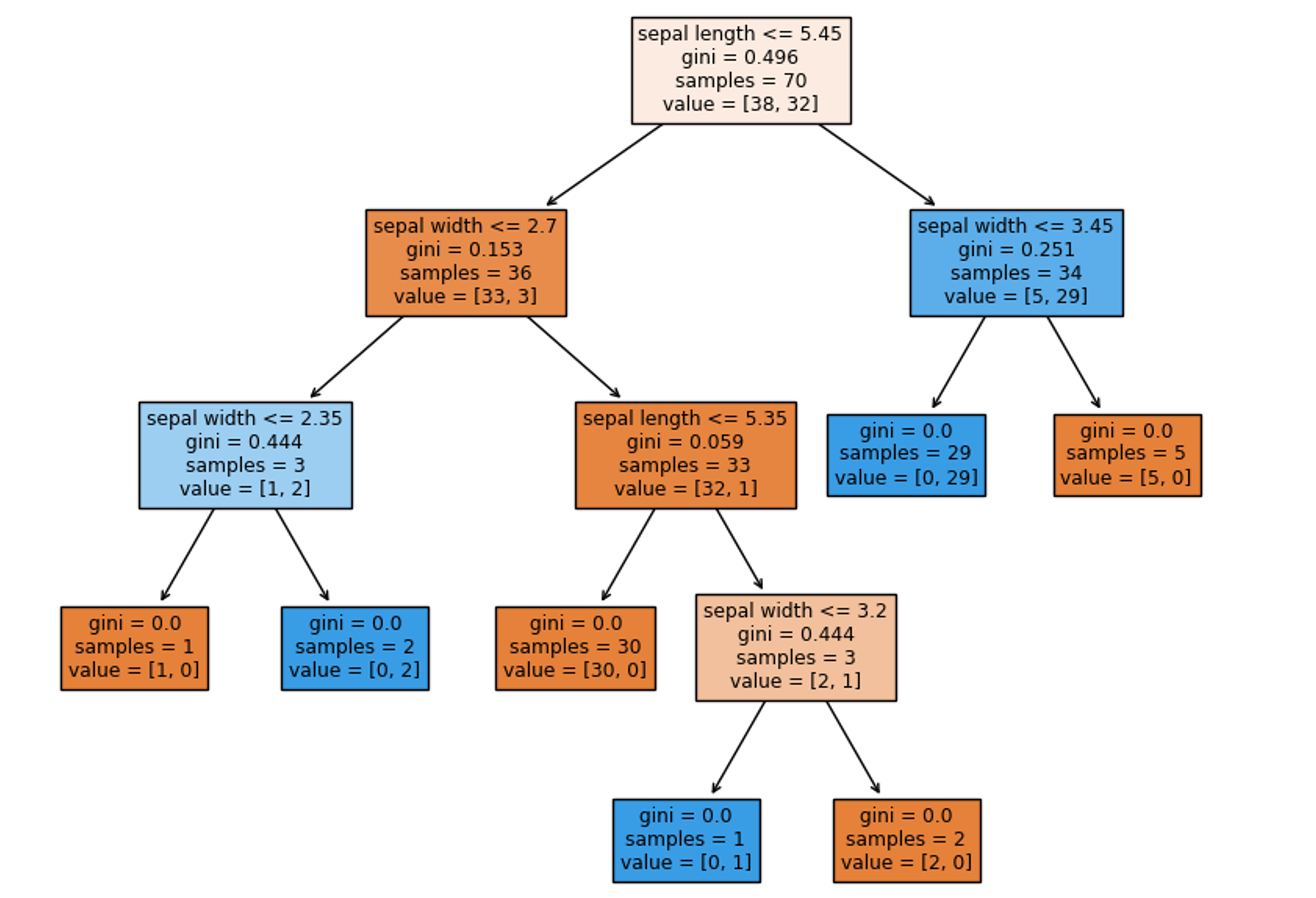
���Ͼ�������������,��������ѧ�������������ܼ�;
���Լ����������������˺ö��,������ѡ�����ݽṹ�Ͳ�������,����Ŭ��ѽ 🍻
REFERENCE:
- �ͳ��ѧϰ����
- sklearn.tree.DecisionTreeClassifier
- Introduction to Machine Learning with Python