决策树是一种树形分类结构,利用数据集构建一棵高效的分类树,决策树的基本思想很简单,在后面的发展被很多学者进行了优化升级,其衍生物有CART,ID3,C4.5,RF,XGBoost和LightGBM。其中RF、XGBoost和LightGBM都是集成学习模型,其中包含了很多弱学习器(比如单一的一棵决策树),进行模型融合,将每棵决策树表现最优的地方进行融合,得到了一个综合表示最优的模型。不同于朴素贝叶斯模型,朴素贝叶斯模型大多用于解决分类问题,但是决策树既可以用于分类,也可以用于回归问题。
本文先介绍决策树的基本构成思想,在后面会简单介绍一下如何做回归问题,其中XGBoost和LightGBM是经典的用于回归的强大模型,包括在现在很多的大型算法比赛中其效果性能都非常显著,很有必要了解掌握。
一、一棵简单的决策树
还是拿朴素贝叶斯分类里面用的分西瓜数据来做说明。
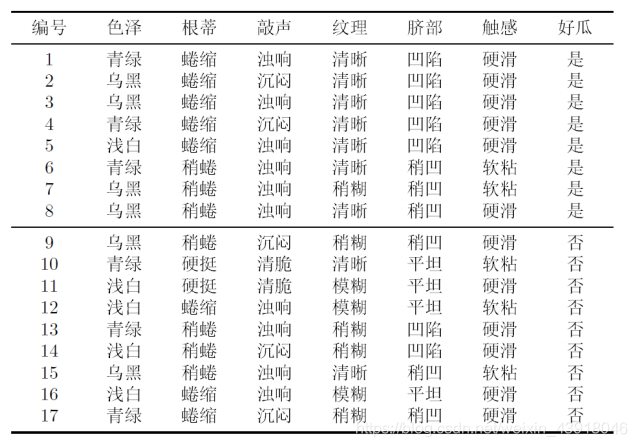
现在西瓜有6个特征:色泽、根蒂、敲声、纹理,脐部,触感。2个结果:好瓜和坏瓜。
于是我们构建一个树节点,特征为色泽,参数为:青绿、乌黑、浅白。
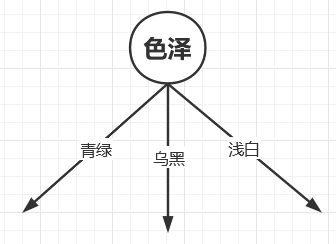
我们注意到色泽为青绿的西瓜中根蒂参数为:蜷缩、稍蜷、硬挺。色泽为乌黑的西瓜中根蒂参数为:蜷缩、稍蜷。色泽为浅白的西瓜中根蒂参数为:蜷缩、稍蜷、硬挺。
于是继续构建树节点。
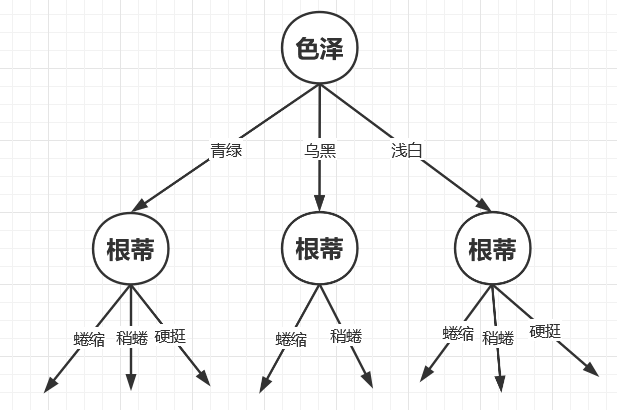
所以这样一说的话就非常简单了,就是这样不断的构建下去,直到我们的标签好瓜和坏瓜作为叶子节点。但是通过上面的我这样简单的构建你们也注意到一个问题了吧,那就是上面的这棵决策树的结构太冗余了,因为我们考虑哪个节点先做决策节点再继续往下分裂,得到的树的结构肯定不一样,所以为了让我们的决策树结构更加简洁直观,这样模型预测的时候也会更加高效,相关学者在后面的学习中便提出了一些改进。
二、ID3决策树
为了解决上面我们提到的决策树结构太过复杂冗余的问题,相关学者提出了ID3决策树,ID3采用了信息增益的方法来优先选择特征节点构建决策树。
2.1 信息熵
信息熵来源于通信工程,其计算过程为假设某个变量X取值为{x1,x2,x3,…,xn},每种取值取到的概率为{p1,p2,p3,…,pn}。
那么信息熵计算公式为
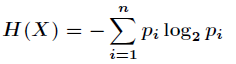 信息熵数值越大,说明一个变量的变化情况可能越多,那么它携带的信息量就越大,该系统越不稳定,存在的不确定性因素就越多。
信息熵数值越大,说明一个变量的变化情况可能越多,那么它携带的信息量就越大,该系统越不稳定,存在的不确定性因素就越多。
比如我们的某个特征拥有的数据为:1,2,1,1,2,3,4,5。
其取值为:1,2,3,4,5。
每个数值取到的概率为:1:3/8,2:2/8,3:1/8,4:1/8,5:1/8。
于是这个特征的信息熵为
-(3/8*log(3/8) + 2/8*log(2/8) + 1/8*log(1/8) + 1/8*log(1/8) + 1/8*log(1/8))=2.1556390622295662
定义:如果某个取值的概率为0,那么定义0*log0=0
2.2 信息增益
信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。可以理解为当前节点开始往下分裂,某个特征可以使得当前的信息熵减小最多,使得后面的结构更加简洁,于是我们选择当前节点信息增益最大的那个特征作为分裂节点。
抛出公式如下:
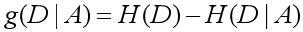
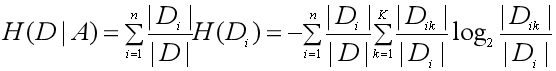
假设A取值为A1,A2,A3,…,An。Di为Ai的数目,Di表示在特征A取值为Ai的情况下D的集合。
举例如下,回到西瓜问题,那么一开始选择分裂的特征节点,我们先计算H(D),此时我们的D为类别:好瓜或坏瓜。
于是
好瓜数目=8
坏瓜数目=9
H(D)=-(8/17*log(8/17) + (9/17)*log(9/17))=0.9975025463691153
以特征色泽进行计算说明,特征色泽取值为:青绿、乌黑、浅白。数目分别是:青绿=6、乌黑=6、浅白=5。
于是当特征色泽=青绿时,D1={是,是,是,否,否,否};->是:3,否:3
当特征色泽=乌黑时,D2={是,是,是,是,否,否};->是:4,否:2
当特征色泽=浅白时,D3={是,否,否,否,否}.->是:1,否:4
于是
H(D|A)=-(6/17*(3/6*log(3/6) + 3/6*log(3/6)) + 6/17*(4/6*log(4/6) + 2/6*log(2/6)) + 5/17*(1/5*log(1/5) + 4/5*log(4/5)))
g(D|A)=H(D)-H(D|A)
于是我们按照这样的方法一直计算,把当前的每个特征都算出对应的信息增益,把信息增益最大的特征作为当前分裂的节点。然后往下,此时得到一个特征X后,现在的特征X作为上一次的D,继续上面重复的计算一直把所有的特征节点找出来。
于是得到了一棵ID3构建的决策树。
三、C4.5决策树
C4.5是对ID3决策树的一种改进,因为当每个属性中每种类别都只有一个样本时,那这样的属性信息熵就等于零,根据信息增益就无法选择出有效的分类特征。
C4.5采用信息增益比,其计算方式很简单,仅仅是在ID3的基础上,除以对应特征的信息熵。那么:
信息增益比=g(D|A)/H(A)
比如我们上面已经算出了g(类别|色泽),那么此时的
H(色泽)=-(6/17*log(6/17) + 6/17*log(6/17) + 5/17*log(5/17))
最后色泽的信息增益比=g(类别|色泽)/H(色泽)
同样的,哪个特征的信息增益比最高,就选择哪个特征作为当前的分裂节点。
四、CART决策树
上面我们提到的ID3和C4.5都是针对分类问题,不能处理回归问题,我们就会想,决策树可以用来做回归问题吗?答案肯定是可以的,于是CART树问世。
ID3和C4.5模型是用较为复杂的信息熵来度量,使用了相对较为复杂的多叉树,只能处理分类不能处理回归。因此CART(Classification And Regression Tree)做了改进,可以处理分类问题,也可以处理回归问题。
CART树采用了基尼系数,不同于ID3和C4.5的信息熵,基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好。这恰好和信息增益(比)相反。CART分类树算法每次仅对某个特征的值进行二分,而不是多分,这样CART分类树算法建立起来的是二叉树,而不是多叉树。
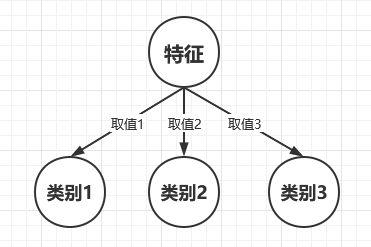
比如C4.5构建的一棵树如下
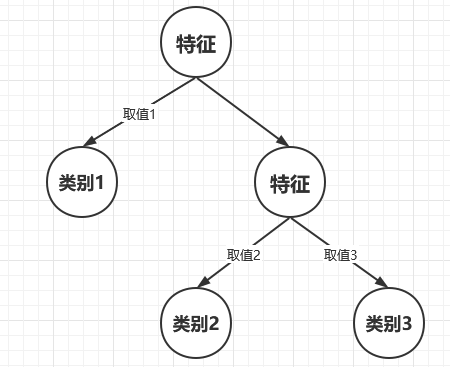
而CART构建的树是这样的,如下:
后续待更新。。。。。