�ԹϽ̳�ML--�ʼ���--������
ʲô�Ǿ�����
decision tree��������һ�ֻ����ķ���ͻع鷽��������˼��,������ģ�ͳ����νṹ,�������ݽṹ�е���,��һ�����ڵ㡢���ɸ��ڲ��ڵ㡢���ɸ�Ҷ�ӽڵ�(���߽��)��
�ڷ���������: ������������Ϊ��if-then����ļ���;Ҳ������Ϊ�Ƕ����������ռ�����ռ��ϵ��������ʷֲ���
�ڻع�������: �������ɿ������ռ��ó�ƽ����л���,ÿ�ڲ��ڵ㶼����ǰ�Ŀռ�һ��Ϊ��, ʹ��ÿ��Ҷ�ӽڵ㶼�ǿռ��е�һ�����ཻ������
ģ���ŵ�: ���пɶ��ԡ�������ȿ졢���Դ�����ֵ�ͷ���ֵ�ֶ�
ģ��ȱ��: ������ϡ���ѧϰ����֮��������
������ѧϰ����3������:
������ѡ��
�ھ�����������
�۾���������
3�־�����
����ID3��������C4.5��������CART������
ID3������(Iterative Dichotomiser)
��(entropy)
������Ϣ���б�ʾ���������ȷ���ԵĶ�����
��Խ��,��������IJ�ȷ���Ծ�Խ��
��Ϣ�صĶ���:
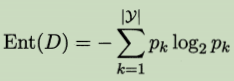
�������е�p=0��p=1ʱ��Ϣ�ص���0,��ʱû�в�ȷ���ԡ�����p=0.5ʱ,��Ϣ��ȡֵ������1,���������ȷ�������
��Ϣ����
�������Ϣ�غ�,�ٿ��ǵ���ͬ�ķ�֧�ڵ�����������������ͬ,����֧�ڵ㸳��Ȩ��|Dv|/|D|,��������Խ��ķ�֧�ڵ��Ӱ��Խ��
��Ϣ���涨������:
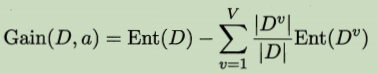
������ѧϰ�е���Ϣ����ȼ���ѵ�����ݼ������������Ļ���Ϣ(���������صIJ�)
��Ϣ����Խ��,��ζ��ʹ������a�����л�������õġ�����������Խ����˿�������Ϣ�����������������о������Ļ��֡�ID3��������������Ϣ����Ϊ����ѧϰ�ġ�
C4.5������
������
������Ϣ����Կ�ȡֵ��Ŀ�϶����������ƫ��,�Ӵ���������Ӱ�졣������롰�����ʡ�:
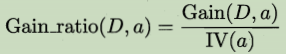
����

(�����IV(a)�Ҿ�������һ��),������a�Ŀ���ȡֵ��ĿԽ��,IV(a)Խ��
������������Կ�ȡֵ��Ŀ���ٵ���������ƫ��,���C4.5�㷨������ֱ��ѡ�����������ĺ�ѡ��������,����ʹ����һ������ʽ:�ȴӺ�ѡ�����������ҳ���Ϣ��������ƽ��ˮƽ������,�ٴ���ѡ����������ߵ�
CART������(Classification And Regression Tree)
����ָ��(Gini index)
����ָ���������ڶ������ݼ�D�Ĵ���,��������:
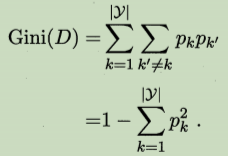
Gini(D)��ӳ�˴����ݼ�D�������ȡ��������,������Dz�һ�µĸ���,Gini(D)ԽС,����Խ�ߡ�
����a�Ļ���ָ���Ķ���:
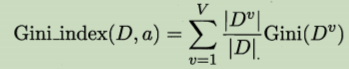
ѡ�ֺ�,����ָ����С��������Ϊ���Ż������ԡ�
ѵ������
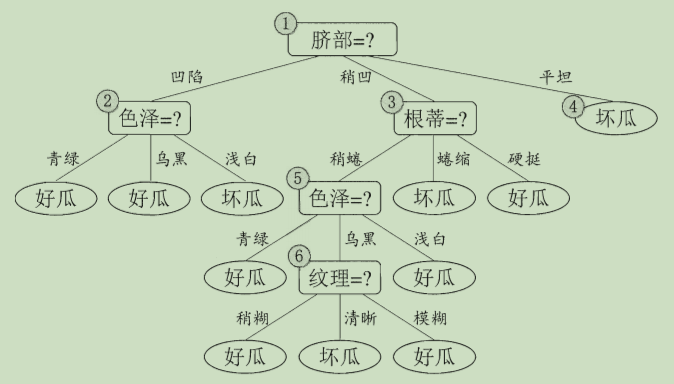
�Ӹ��ڵ㿪ʼ���еݹ����,�������������:
����ڵ��ѵ�����ݼ�ΪD,�������������Ը����ݼ��Ļ���ָ��,��ÿ������A�Ŀ���ȡֵa���в���,���Ƿ����a���ֳ�D1��D2�������ݼ�,����A=aʱ�Ļ���ָ����
�������п��ܵ�����A�Լ��������п��ܵ��зֵ�a��,ѡ�����ָ����С������������Ӧ���зֵ���Ϊ���������������зֵ�,���ýڵ�������ݼ����䵽�����ӽڵ��С�
�۶������ӽڵ�ݹ���â٢�ֱ������ֹͣ����:�ڵ��е��ñ�����С��Ԥ����ֵ �� ��ǰ���ݼ��Ļ���ָ��С��Ԥ����ֵ �� û����������
��֦
��֦(pruning)ʱ������Ӧ�Թ���ϵķ���,��Ҫ��Ԥ��֦(prepruning)�ͺ��֦(post-pruning)�������������ϵ�����:
����֦:
��Ԥ��֦: �پ��������ɹ�����,��ÿ���ڵ�Ļ���ǰ�Ƚ��й���,����ǰ�ڵ�Ļ��ֲ��ܴ�����������������������,��ֹͣ���ֲ�����ǰ�ڵ���ΪҶ�ӽڵ㡣
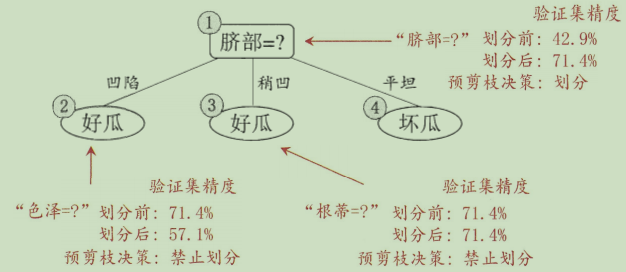
�ŵ�:�����ܽ�����ϵķ���,�����������˾�������ѵ��ʱ���Ԥ��ʱ�䡣
ȱ��:һЩ��֧�ٵ�ǰ���ܲ���������������,���Ǻ�������Ҳ�п����÷���������������,���Ԥ��֦����Ƿ��ϵķ��ա�
�ں��֦: �ȴ�ѵ�����������������ľ�����,Ȼ���Ե����϶Է�Ҷ�ӽڵ���п���,�����ýڵ��Ӧ�������滻ΪҶ�ڵ��ܴ�����������������������,�������滻ΪҶ�ڵ㡣
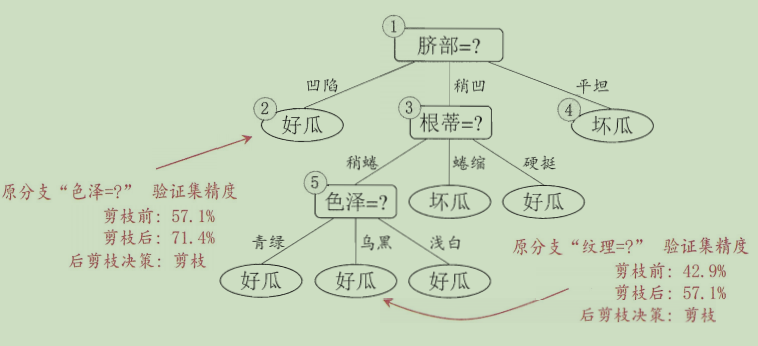
�ŵ�:���֦��Ƿ��Ϸ��պ�С,����������������Ԥ��֦�ľ�������
ȱ��:���֦ʱ����ȫչ�������������Ե����Ͻ��п���,ѵ��ʱ���Ԥ��֦��ܶࡣ
sklearn����
��
##���������ӻ�
��
�����
������ѧϰ��ʽ��⡷�Cл��� ����
������ѧϰ���C��־��
��ͳ��ѧϰ�������C�
������ѧϰ��ʽ��⡷(�Ϲ���)�������鹫ʽ�Ƶ�ֱ���ϼ�:https://www.bilibili.com/video/BV1Mh411e7VU?from=search&seid=5668978625426231562
Regression Tree �ع���:https://blog.csdn.net/weixin_40604987/article/details/79296427