概述
深度优先搜索和广度优先搜索是两种最常见的优先搜索方法,它们被广泛地运用在图和树等结构中进行搜索。
深度优先搜索
深度优先搜索(depth-first seach,DFS)在搜索到一个新的节点时,立即对该新节点进行遍历;因此遍历需要用先入后出的栈来实现,也可以通过与栈等价的递归来实现。对于树结构而言,由于总是对新节点调用遍历,因此看起来是向着“深”的方向前进。
深度优先搜索也可以用来检测环路:记录每个遍历过的节点的父节点,若一个节点被再次遍历且父节点不同,则说明有环。我们也可以用之后会讲到的拓扑排序判断是否有环路,若最后存在入度不为零的点,则说明有环。
有时我们可能会需要对已经搜索过的节点进行标记,以防止在遍历时重复搜索某个节点,这种做法叫做状态记录或记忆化(memoization)。
695.岛屿的最大面积


题解:
此题是十分标准的搜索题,我们可以拿来练手深度优先搜索。一般来说,深度优先搜索类型的题可以分为主函数和辅函数,主函数用于遍历所有的搜索位置,判断是否可以开始搜索,如果可以即在辅函数进行搜索。辅函数则负责深度优先搜索的递归调用。当然,我们也可以使用栈(stack)实现深度优先搜索,但因为栈与递归的调用原理相同,而递归相对便于实现,因此刷题时笔者推荐使用递归式写法,同时也方便进行回溯。不过在实际工程上,直接使用栈可能才是最好的选择,一是因为便于理解,二是更不易出现递归栈满的情况。我们先展示使用栈的写法。
class Solution {
int[][] step ={{0,1},{1,0},{0,-1},{-1,0}};
int res = 0;
int count = 0;
public int maxAreaOfIsland(int[][] grid) {
int[][] arr = new int[grid.length][grid[0].length];
for(int i = 0;i<grid.length;++i){
for(int j = 0;j<grid[i].length;++j){
if(grid[i][j]==1&&arr[i][j]==0){
arr[i][j]=1;
count = 1;
dfs(grid,arr,i,j);
}
}
}
return res;
}
public void dfs(int[][] grid,int[][] arr,int x,int y){
res = Math.max(res,count);
for(int i = 0;i<step.length;++i){
int curX = x + step[i][0];
int curY = y + step[i][1];
if(check(grid,arr,curX,curY)){
arr[curX][curY]=1;
++count;
dfs(grid,arr,curX,curY);
}
}
}
public boolean check(int[][] grid,int[][] arr,int x,int y){
if(x>=0&&x<grid.length&&y>=0&&y<grid[x].length&&grid[x][y]==1&&arr[x][y]==0) return true;
return false;
}
}
547.省份数量

题解:
对于题目 695,图的表示方法是,每个位置代表一个节点,每个节点与上下左右四个节点相邻。而在这一道题里面,每一行(列)表示一个节点,它的每列(行)表示是否存在一个相邻节点。因此题目 695 拥有 m × n 个节点,每个节点有 4 条边;而本题拥有 n 个节点,每个节点最多有 n 条边,表示和所有人都是朋友,最少可以有 1 条边,表示自己与自己相连。当清楚了图的表示方法后,这道题与题目 695 本质上是同一道题:搜索朋友圈(岛屿)的个数(最大面积)。我们这里采用递归的第一种写法。
class Solution {
public int findCircleNum(int[][] isConnected) {
int m = isConnected.length;
int[] arr= new int[m]; //标记每个城市是否被访问过
int res = 0;
for(int i = 0;i<m;++i){
if(arr[i]==0){
++res;
arr[i]=1; //表示第i个城市已经被 访问过了
dfs(isConnected,arr,i);
}
}
return res;
}
public void dfs(int[][] isConnected,int[] arr,int j){
for(int i = 0;i<isConnected.length;++i){
if(isConnected[j][i]==1&&arr[i]==0){
arr[i]=1;
dfs(isConnected,arr,i);
}
}
}
}
417.太平洋大西洋水流问题
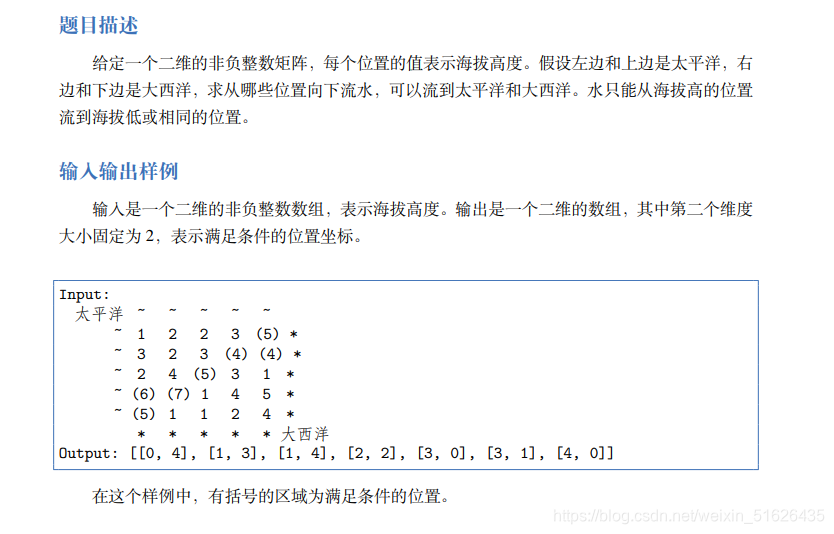
题解:
虽然题目要求的是满足向下流能到达两个大洋的位置,如果我们对所有的位置进行搜索,那么在不剪枝的情况下复杂度会很高。因此我们可以反过来想,从两个大洋开始向上流,这样我们只需要对矩形四条边进行搜索。搜索完成后,只需遍历一遍矩阵,满足条件的位置即为两个大洋向上流都能到达的位置。
class Solution {
int[][] step = {{0,-1},{-1,0},{0,1},{1,0}};
HashSet<String> setT = new HashSet<>();
HashSet<String> setD = new HashSet<>();
public List<List<Integer>> pacificAtlantic(int[][] heights) {
if(heights.length==0) return null;
List<List<Integer>> res = new ArrayList<>();
int row =heights.length,col = heights[0].length;
int[][] arr = new int[row][col];
for(int i = 0;i<col;++i){
dfs(heights,arr,0,i,10);
dfs(heights,arr,row-1,i,100);
}
for(int i = 0;i<row;++i){
dfs(heights,arr,i,0,10);
dfs(heights,arr,i,col-1,100);
}
for(int i = 0;i<row;++i){
for(int j =0;j<col;++j){
if(arr[i][j]==110){
res.add(List.of(i, j));
}
}
}
return res;
}
public void dfs(int[][] heights ,int[][] arr, int x,int y , int offset){
if(contains(x,y,offset)) return ;
else add(arr,x,y,offset);
for(int i = 0;i<step.length;++i){
int curX = x + step[i][0];
int curY = y + step[i][1];
if(check(arr,curX,curY)&&heights[curX][curY]>=heights[x][y]){
dfs(heights,arr,curX,curY,offset);
}
}
}
public boolean check(int[][] arr, int x,int y){
if(x>=0&&x<arr.length&&y>=0&&y<arr[0].length) return true;
return false;
}
public boolean contains(int x,int y,int offset){
if(offset==10){
return setT.contains(x+"@"+y);
}else{
return setD.contains(x+"@"+y);
}
}
public void add(int[][] arr,int x,int y,int offset){
if(offset==10) setT.add(x+"@"+y);
else setD.add(x+"@"+y);
arr[x][y] += offset;
}
}
回溯法
回溯法(backtracking)是优先搜索的一种特殊情况,又称为试探法,常用于需要记录节点状态的深度优先搜索。通常来说,排列、组合、选择类问题使用回溯法比较方便。
顾名思义,回溯法的核心是回溯。在搜索到某一节点的时候,如果我们发现目前的节点(及其子节点)并不是需求目标时,我们回退到原来的节点继续搜索,并且把在目前节点修改的状态还原。这样的好处是我们可以始终只对图的总状态进行修改,而非每次遍历时新建一个图来储存状态。在具体的写法上,它与普通的深度优先搜索一样,都有 [修改当前节点状态]→[递归子节点] 的步骤,只是多了回溯的步骤,变成了 [修改当前节点状态]→[递归子节点]→[回改当前节点状态]。
没有接触过回溯法的读者可能会不明白我在讲什么,这也完全正常,希望以下几道题可以让您理解回溯法。如果还是不明白,可以记住两个小诀窍,一是按引用传状态,二是所有的状态修改在递归完成后回改。
回溯法修改一般有两种情况,一种是修改最后一位输出,比如排列组合;一种是修改访问标记,比如矩阵里搜字符串

题解:
怎样输出所有的排列方式呢?对于每一个当前位置 i,我们可以将其于之后的任意位置交换,然后继续处理位置 i+1,直到处理到最后一位。为了防止我们每此遍历时都要新建一个子数组储存位置 i 之前已经交换好的数字,我们可以利用回溯法,只对原数组进行修改,在递归完成后再修改回来。
我们以样例[1,2,3]为例,按照这种方法,我们输出的数组顺序为[[1,2,3], [1,3,2], [2,1,3], [2,3,1],[3,1,2], [3,2,1]],可以看到所有的排列在这个算法中都被考虑到了。
class Solution {
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> permute(int[] nums) {
dfs(nums,0,new ArrayList<Integer>());
return res;
}
public void dfs(int[] nums, int n,ArrayList<Integer> list){
if(n==nums.length){
res.add(new ArrayList<>(list));
return ;
}
for(int i = n;i<nums.length;++i){
if(i!=n){
nums[i]^=nums[n];
nums[n]^=nums[i];
nums[i]^=nums[n];
}
list.add(nums[n]);
dfs(nums,n+1,list);
list.remove((Object)nums[n]);
if(i!=n){
nums[i]^=nums[n];
nums[n]^=nums[i];
nums[i]^=nums[n];
}
}
}
}


题解:
类似于排列问题,我们也可以进行回溯。排列回溯的是交换的位置,而组合回溯的是否把当前的数字加入结果中。
class Solution {
static List<List<Integer>> lists = new ArrayList<List<Integer>>();
static List list = new ArrayList<Integer>();
public List<List<Integer>> combine(int n, int k) {
lists = new ArrayList<List<Integer>>();
list = new ArrayList<Integer>();
int[] arr=new int[n];
for(int i=1;i<=n;++i){
arr[i-1]=i;
}
backStracking(arr,0,k);
return lists;
}
static void backStracking(int[] arr, int n, int k) {
if (list.size()==k){
lists.add(new ArrayList<>(list));
}
for (int i = n; i < arr.length; ++i) {
list.add(arr[i]);
backStracking(arr, i+1, k);
list.remove(list.size()-1);
}
}
}


题解:
不同于排列组合问题,本题采用的并不是修改输出方式,而是修改访问标记。在我们对任意位置进行深度优先搜索时,我们先标记当前位置为已访问,以避免重复遍历(如防止向右搜索后又向左返回);在所有的可能都搜索完成后,再回改当前位置为未访问,防止干扰其它位置搜索到当前位置。使用回溯法,我们可以只对一个二维的访问矩阵进行修改,而不用把每次的搜索状态作为一个新对象传入递归函数中。
class Solution {
int[][] step = {{-1,0},{0,1},{1,0},{0,-1}};
public boolean exist(char[][] board, String word) {
int[][] arr= new int[board.length][board[0].length];
boolean flag = false;
for(int i = 0;i<board.length;++i){
for(int j = 0;j<board[0].length;++j){
if(board[i][j]==word.charAt(0)){
arr[i][j]=1;
flag |= dfs(board,arr,word,i,j,1);
arr[i][j]=0;
if(flag) return flag;
}
}
}
return flag;
}
public boolean dfs(char[][] board,int[][] arr, String word,int x,int y,int index){
if(index==word.length()) return true;
boolean flag = false;
for(int i = 0;i<step.length;++i){
int curX = step[i][0]+x;
int curY = step[i][1]+y;
if(check(arr,curX,curY)&&board[curX][curY]==word.charAt(index)){
arr[curX][curY]=1;
flag |= dfs(board,arr,word,curX,curY,index+1);
arr[curX][curY]=0;
}
}
return flag;
}
public boolean check(int[][] arr,int x,int y){
if(x>=0&&x<arr.length&&y>=0&&y<arr[0].length&&arr[x][y]==0) return true;
return false;
}
}

题解:
类似于在矩阵中寻找字符串,本题也是通过修改状态矩阵来进行回溯。不同的是,我们需要对每一行、列、左斜、右斜建立访问数组,来记录它们是否存在皇后。
本题有一个隐藏的条件,即满足条件的结果中每一行或列有且仅有一个皇后。这是因为我们一共只有 n 行和 n 列。所以如果我们通过对每一行遍历来插入皇后,我们就不需要对行建立访问数组了。
class Solution {
List<List<String>> res = new ArrayList<>();
public List<List<String>> solveNQueens(int n) {
dfs(n,0,new ArrayList<Integer>());
return res;
}
public void dfs(int n,int index,ArrayList<Integer> list){
if(list.size()==n){
add(list);
return ;
}
for(int i = 0;i < n; ++i){
if(check(list,index,i)){
list.add(i);
dfs(n,index+1,list);
list.remove((Object)i);
}
}
}
public boolean check(ArrayList<Integer> list,int index,int n){
for(int i =0;i<list.size() ; ++i) if(n==list.get(i)||(Math.abs(n-list.get(i))*1.0/(index-i))==1.0) return false;
return true;
}
public void add(ArrayList<Integer> list){
ArrayList<String> ans = new ArrayList<>(list.size());
StringBuilder s = new StringBuilder();
for(int i = 1;i<list.size();++i) s.append(".");
for(int i = 0;i<list.size();++i){
s.insert(list.get(i),"Q");
ans.add(s.toString());
s.deleteCharAt(list.get(i));
}
res.add(ans);
}
}
广度优先搜索
广度优先搜索(breadth-first search,BFS)不同与深度优先搜索,它是一层层进行遍历的,因此需要用先入先出的队列而非先入后出的栈进行遍历。由于是按层次进行遍历,广度优先搜索时按照“广”的方向进行遍历的,也常常用来处理最短路径等问题。
这里要注意,深度优先搜索和广度优先搜索都可以处理可达性问题,即从一个节点开始是否能达到另一个节点。因为深度优先搜索可以利用递归快速实现,很多人会习惯使用深度优先搜索刷此类题目。实际软件工程中,笔者很少见到递归的写法,因为一方面难以理解,另一方面可能产生栈溢出的情况;而用栈实现的深度优先搜索和用队列实现的广度优先搜索在写法上并没有太大差异,因此使用哪一种搜索方式需要根据实际的功能需求来判断。
934.最短的桥

题解:
本题实际上是求两个岛屿间的最短距离,因此我们可以先通过任意搜索方法找到其中一个岛屿,然后利用广度优先搜索,查找其与另一个岛屿的最短距离。
class Solution {
//搜索的路径
int[][] step = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
public int shortestBridge(int[][] grid) {
return bfs(grid);
}
//用bfs广度优先搜索,来寻找最短路径
public int bfs(int[][] arr) {
boolean flag = true;
LinkedList<Node> queue = new LinkedList<Node>();
//这个for循环中的dfs主要是用于 一块岛屿(即连着的1)
for (int i = 0; flag && i < arr.length; ++i) {
for (int j = 0; flag && j < arr[0].length; ++j) {
if (arr[i][j] == 1) {
queue.add(new Node(i, j));
arr[i][j] = -1;
dfs(arr, i, j, queue);
flag = false;
}
}
}
//标志是否已经找到了另一个岛屿
flag = true;
//循环遍历队列中的每一个元素 广度的寻找另一个岛屿
while (flag && queue.size() > 0) {
Node cur = queue.poll();
int x = cur.x;
int y = cur.y;
//每一个点都可以上下左右走
for (int i = 0; flag && i < step.length; ++i) {
int newX = x + step[i][0];
int newY = y + step[i][1];
if (check(arr, newX, newY) && arr[newX][newY] != -1) {
Node newN = new Node(newX, newY);
//设置新结点的上一个结点为当前结点
newN.pre = cur;
//将新节点加入到队列中~~~
queue.add(newN);
//判断是否找到另一个岛屿,找到的话就退出循环
if (arr[newX][newY] == 1) flag = false;
//每一个用过的岛屿都标记成-1,防止以后再次使用
arr[newX][newY] = -1;
}
}
}
return count(queue.pollLast(), 0)-1;
}
//计算路径长度
public int count(Node node, int count) {
if (node.pre == null) return count;
else return count(node.pre, count + 1);
}
//dfs用于搜索一个连在一起的一整块岛屿
public void dfs(int[][] arr, int x, int y, LinkedList<Node> queue) {
for (int i = 0; i < step.length; ++i) {
int curX = x + step[i][0];
int curY = y + step[i][1];
if (check(arr, curX, curY) && arr[curX][curY] == 1) {
queue.add(new Node(curX, curY));
arr[curX][curY] = -1;
dfs(arr, curX, curY, queue);
}
}
}
//判断每个x,y是否符合越界
public boolean check(int[][] arr, int x, int y) {
if (x >= 0 && x < arr.length && y >= 0 && y < arr[0].length) return true;
return false;
}
}
//每个队列中的结点,重要的是 pre,记录上一个几点是谁。将来用于判断最短路径长度有用。
class Node {
int x;
int y;
Node pre = null;
public Node(int x, int y) {
this.x = x;
this.y = y;
}
}
练习:
基础难度
130.Surrounded Regions (Medium)
先从最外侧填充,然后再考虑里侧。
257.Binary Tree Paths (Easy)
输出二叉树中所有从根到叶子的路径,回溯法使用与否有什么区别?
进阶难度
47.Permutations II (Medium)
排列题的 follow-up,如何处理重复元素?
40.Combination Sum II (Medium)
组合题的 follow-up,如何处理重复元素?
37.Sudoku Solver (Hard)
十分经典的数独题,可以利用回溯法求解。事实上对于数独类型的题,有很多进阶的搜索方 法和剪枝策略可以提高速度,如启发式搜索。
126.Word Ladder II (Hard)
我们可以使用广度优先搜索,求得起始节点到终止节点的最短距离。
310.Minimum Height Trees (Medium)
如何将这道题转为搜索类型题?是使用深度优先还是广度优先呢?