最近看深度遍历和广度遍历看到了一篇很好的文章,在此记录一下, 原文地址点这。什么是深度遍历和广度遍历呢?简单来说,深度遍历和广度遍历都是针对树进行遍历的,不同的是深度优先从上到下进行遍历,而广度遍历则是逐层遍历的
1.图解
-
深度优先
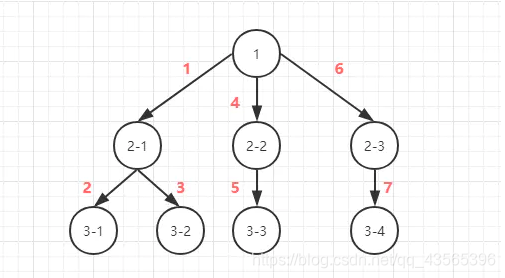
-
广度优先
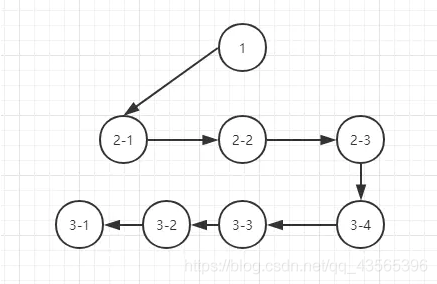
2.区别
对于算法来说 无非就是时间换空间 空间换时间
深度优先不需要记住所有的节点, 所以占用空间小, 而广度优先需要先记录所有的节点占用空间大
- 深度优先有回溯的操作(没有路走了需要回头)所以相对而言时间会长一点
- 深度优先采用的是堆栈的形式, 即先进后出
- 广度优先则采用的是队列的形式, 即先进先出
通常 深度优先不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。
所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。
但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些
3.代码
const data = [
{
name: 'a',
children: [
{ name: 'b', children: [{ name: 'e' }] },
{ name: 'c', children: [{ name: 'f' }] },
{ name: 'd', children: [{ name: 'g' }] },
],
},
{
name: 'a2',
children: [
{ name: 'b2', children: [{ name: 'e2' }] },
{ name: 'c2', children: [{ name: 'f2' }] },
{ name: 'd2', children: [{ name: 'g2' }] },
],
}
]
// 深度遍历, 使用递归
function getName(data) {
const result = [];
data.forEach(item => {
const map = data => {
result.push(data.name);
data.children && data.children.forEach(child => map(child));
}
map(item);
})
return result.join(',');
}
// 广度遍历, 创建一个执行队列, 当队列为空的时候则结束
function getName2(data) {
let result = [];
let queue = data;
while (queue.length > 0) {
[...queue].forEach(child => {
queue.shift();
result.push(child.name);
child.children && (queue.push(...child.children));
});
}
return result.join(',');
}
console.log(getName(data))
console.log(getName2(data))