Ŀ��
�˽�ConcurrentHashMap ����ԭ�����ص���ConcurrentHashMap�Ķ��߳��µ����ݻ���,TreeBin ��ForwardingNode ���ܵ���ʶ,�Լ�CAS��LockSupport��ʹ�á�
Ԥ��֪ʶ
��Ҫ����

Դ�뽲��
put ����
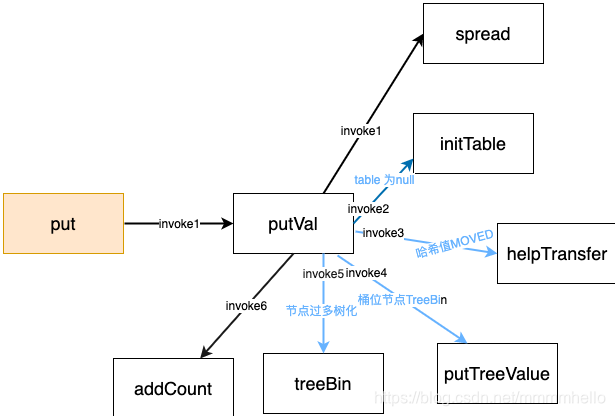
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());//���� hashֵ
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
putTreeVal
����ܹ��ҵ���Ҫput����Ԫ�ص�key "���"�Ľڵ�ͷ���,���ŵ�������ϡ���֮ǰHashMap1.8 ��ͬ����banlanceInsertion ֮ǰ��Ҫ������
/**
* Finds or adds a node.
* @return null if added
*/
final TreeNode<K,V> putTreeVal(int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if (p == null) {
first = root = new TreeNode<K,V>(h, k, v, null, null);
break;
}
else if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.findTreeNode(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.findTreeNode(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
TreeNode<K,V> x, f = first;
first = x = new TreeNode<K,V>(h, k, v, f, xp);
if (f != null)
f.prev = x;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
if (!xp.red)
x.red = true;
else {
lockRoot();
try {
root = balanceInsertion(root, x);
} finally {
unlockRoot();
}
}
break;
}
}
assert checkInvariants(root);
return null;
}
treeBin����
treeBin������Ҫ�ǽ���ͨNode�ڵ�ת��ΪTreeNode�ڵ�,ͬʱת��Ϊ�������ת��Ϊ������IJ�����������TreeBin ����Ĺ������̡�
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
TreeBin ���캯��
TreeBin ��̳���Node��,hashֵΪ-2,������Ͱλ�Ϸŵ���һ�ź���������������洢�� ��ֵ,ֻ��ָ��root,���ά��һ����д��,ʹ��д�̵߳ȴ����̶߳�����,ʹ�����ع������֮ǰ��ɶ�������
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null);
this.first = b;
TreeNode<K,V> r = null;
for (TreeNode<K,V> x = b, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (r == null) {
x.parent = null;
x.red = false;
r = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = r;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
r = balanceInsertion(r, x);
break;
}
}
}
}
this.root = r;
assert checkInvariants(root);
}
addCount����
��Ԫ���Ѿ��Ž�table��,����Ҫ��������size�IJ���,���Dz���������cas��baseCount ����1,��Ȼ��ʹ�ô������߲�casʧ��,���´����߳̿�ת,һ��ֻ��һ���߳����óɹ�������doug lea �����LongAdder ��˼��,ʹ�ò�ͬ�߳̾����ֲܷ�����ͬ��CounterCell�н��м��������Ժ�������ͳ������������size��ʱ��,�ͷ�Ϊ������ baseCount + CounterCells .
����һ�����ܾ�������,��check < 0��ʱ�� ���������,�� check <= 1 ʱ ֻ����Ƿ��� δ������״̬��check �C if <0, don��t check resize, if <= 1 only check if uncontended
resizeStamp
/**
* Returns the stamp bits for resizing a table of size n.
* Must be negative when shifted left by RESIZE_STAMP_SHIFT.
*/
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1));
}
�ú���ʱ��resizeʱ�� ������,���ص���һ�� stamp bits .����Ӧ�����2��
1������ table�Ĵ�С n ��ǰ0���� tmpResult
2��ʹ��tmpResult �ĵ�16��bitΪ1(ע��RESIZE_STAMP_BITS Ϊ����16)
����resizeStamp���ص�ֵ������16λʱ��Ϊnegative��
����ΪʲôҪ��ô����?
���������33 - 34 �� ���� �� Ϊ��ȷ����ִ��U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)�� sizeCtl ������Ϊ����,����sizeCtlǰ16λ�������������ڶԴ�СΪ���ٵ�table����������������Ϣ��
���Ե���һ���߳����ݵ�ʱ����ߵ�����33- 34 �д���,ʹ��sizeCtl����Ϊһ������,�������߳�������.
�����������26 - 29�е����� ,(sc >>> RESIZE_STAMP_SHIFT) != rs ָ���� ��ǰsizeCtl ֵ ����16 λ�� ����� resizeStamp()���صIJ��� ˵�����ݲ��Ƕ�ͬһ��table����,ֱ�ӷ�����
sc == rs + 1 ָ���� ��������Ѿ�����
sc == rs + MAX_RESIZERS ָ���� ��������Ѿ��ﵽ����߳��� ����������
(nt = nextTable == null) nt == null ˵����������ʱ��,����ֹͣ���� ֱ��break
transferindex <= 0 Ҳ�����������ݰ�����
���ڴ˴���bug ������ ��ο�https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8214427
addCount check ������������ʵ�ǿ��Կ������ݵ�,���統����ɾ��Ԫ�ص�ʱ��ͻ����addCount(-1,-1),�����Ͳ���Ҫ���ݲ����ˡ�
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
//s = (baseCount + x )or sumCount()
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
fullAddCount ����
�˺������� CounterCells Ϊ�� �����̶߳�Ӧ��counterCell Ϊ�� ���� cas����baseCount ʧ�ܵ�ʱ�� �����õ�,������Ҫ����CounterCells�ij�ʼ�� �� ������ +x�IJ���������������ڶ��̻߳����²�����baseCount�����������37-61�д���,��ʾ�ڸ��̶߳�Ӧ��CounterCell ����ʱ��Ӧ��λ���Ѿ���Ϊ����,��ô����rehash ��cas ����������CounterCell ��һϵ�д�ʩ ��߲���,ע��CounterCells �����������ݵ�,���ƾ���collide����,ֻ���ڸñ���Ϊtrueʱ���ݲſ��ܷ���,Ȼ�����Թ۲�41�д����е�����,���д������ �����߳��Ѿ���CounterCells������ߵ�ʱ���������Ѿ����ڵ��ڻ���CPU�������� ��ô��û��Ҫ���ݡ�62-77 ����CounterCells ��ʼ���Ĺ��̡�78-79 �����д��� �ǵ����̷߳����Ѿ����߳��ڳ�ʼ����,��ô��Ҳ��������,���ǻ�fall back����cas����baseCount.
// See LongAdder version for explanation
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
boolean collide = false; // True if last slot nonempty
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
if ((as = counterCells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
CounterCell r = new CounterCell(x); // Optimistic create
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try { // Recheck under lock
CounterCell[] rs; int m, j;
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
else if (counterCells != as || n >= NCPU)
collide = false; // At max size or stale
else if (!collide)
collide = true;
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
if (counterCells == as) {// Expand table unless stale
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = ThreadLocalRandom.advanceProbe(h);
}
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
CounterCell[] rs = new CounterCell[2];
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break; // Fall back on using base
}
}
transfer ���� �����ݺ���
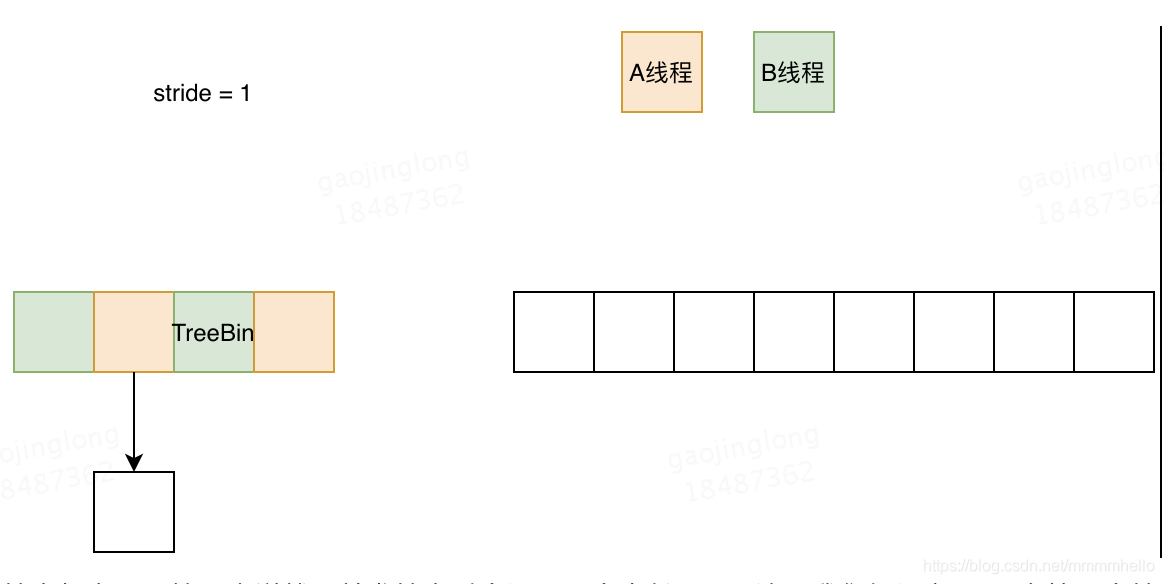
��������ͼ,��Ҫ��˵���Dz�������ʱ������һ������stride,�������Ǽ���Ϊ1,��ô��һ�����ݵ��߳�A������������Ԫ�ص��ƶ�,���������̱߳���B��ʱ,�������Լ�����������,Ȼ���������,ֱ������Ԫ��������ɡ�
������� ����ȫ�ֱ���transferIndex = n (�������С),Ȼ�����һ���߳���˵,�ھ���23 - 40 �д���,һ������������Ͱ���ᱻ���߳��ƶ�,�����߳�ִ�д˶δ���Ҳ��õ��Լ�Ӧ��ִ�е� �ֶ�,ֱ�����е�Ͱ�����ƶ���,����ʱtransferIndex <= 0,��ʱ���ߵ�����50 - 55 ��,ִ�д˴���Ŀ��������а������ݵĴ���,�����ܻ���һ��ִ�����ݵ��̻߳������β���� ,��β������Ӧ�����44 - 49 �� ,��Ҫ������table ����,��ô��������������?��Ҫ��ͨ��sizeCtl ��һ���������ݵ��̻߳�����sizeCtl Ϊ һ����,֮��ÿ���������̶߳��Ὣ�����+1,���ڰ������֮��-1,���������ɵ�һ�����ǽ�sizeCtl ����Ϊԭ���������Ǹ��߳�,��������������
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating ˵���ǵ�һ����ʼ���ݵ��߳�
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;//���ô��ҿ�ʼ���� �ƶ�Ͱ
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {//��fwhileѭ�� ������Ҫ��Ϊÿ���߳� ����һ�ξ�table �� (bound,i�����������ת�ƹ���,
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
// ��ʱ�Ѿ�����ø��߳�Ӧ��ת�Ƶ�ͰλΪ(bound,i]
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//����Ͱλ�ϵ�Ԫ�ط���fwd,��ʶ��table��������,��Ҫ�������
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;//ln ���� ��λ �ڵ� hn������λ�ڵ�
if (fh >= 0) {//������Ͱλ�ϵĽڵ��� Node�ڵ� ������TreeBin
int runBit = fh & n;//ֻ���� 0 ����1 ��˼�Ǽ����²��������λ �����1 �Ǿ�Ϊ1 ���Ϊ 0 �Ǿ���0
Node<K,V> lastRun = f;
//����forѭ�� ��Ҫ���ҵ���ͬһ��Ͱλ�����һ��
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//���� ln hn ��ֵ
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//ǰ����Ȼ�൱����һ���Ż�, HashMap 1.8 ͬ�����Կ���ͬ��������Ȼ���ÿ���ڵ� һ�������õ���ͬ��λ����
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {//��forѭ����ʹ����Ͱλ�ϵ�����ȫ������ʼ��Ϊһ����,����֮ǰ˵����TreeNode ���ǵô������Ƕ� ��һ���Ƕ��Ǻ���� �ڶ��Ƕ���˫���� ���˲������
//��˫�����ṹ��ص�ָ�������Ӻ�
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;//hc ������� 0 ˵����������ṹt ֱ�ӿ��������Ƶ���Ӧ��table��Ͱλ�ϡ�
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;//lc ������� 0 ˵����������ṹ ����ֱ�������Ƶ���Ӧ��table��Ͱλ�ϡ�
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);//���þ�Ͱλ Ϊ fwd ˵���������� ��Ҫ������
advance = true;
}
}
}
}
}
}
helpTransfer ����
�ú������ڶ�������µ���,��Ҫ������ ɾ�� ʱ�����ж�Ҫ������Ͱλ�ϵĵ�һ��Ԫ�ص�hash ���Ϊ����MOVED(-1),��ô������ʱ������,��ʱ����������ִ�� �˺������ú����ķ���ֵΪNode<K,V>[] ����table ,�������������֮�����Խ����Լ�����е����ӻ���ɾ�������ˡ�
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) &&
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
get ����
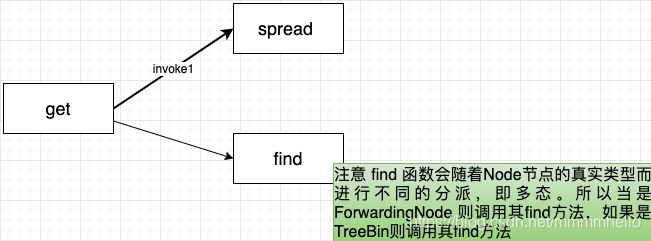
TreeBin �е�find����
���
TreeBin�ڲ�ά����һ��������д��,lockstate ��һ��bit ��дbit ,�ڶ���bit�ǵȴ� bit,������������ ������,���ڶ�����,���������Dz������,��д�����ǻ���ġ�����д��,������putTreeVal ��balanceInsertion ֮ǰ lockRoot() ����д��,���Խ�TreeBin ������lockstate��д bit����Ϊ1��
// Acquires write lock for tree restructuring
private final void lockRoot() {
if (!U.compareAndSwapInt(this, LOCKSTATE, 0, WRITER))
contendedLock(); // offload to separate method
}
private final void contendedLock() {
boolean waiting = false;
for (int s;;) {
if (((s = lockState) & ~WAITER) == 0) {//���lockstate Ϊ0 ���� lockstate Ϊ WATITER (2)
if (U.compareAndSwapInt(this, LOCKSTATE, s, WRITER)) {//���Ի�ȡд��
if (waiting)
waiter = null;
return;
}
}
else if ((s & WAITER) == 0) {//���û���߳��ڵȴ�д�� ���Լ�����Ϊ�ȴ����߳�
if (U.compareAndSwapInt(this, LOCKSTATE, s, s | WAITER)) {
waiting = true;
waiter = Thread.currentThread();
}
}
else if (waiting)//���Լ�park
LockSupport.park(this);
}
}
����5-10�д�����Կ��������̳߳���TreeBin ��д�����ߵȴ�ʱ,�ж���������ʱ,��������˻�Ϊ�������б�����,�����lockstate ����READER,�������߳��ڶ�,�ں��������֮��,����������ȥ,���ҷ������߳��ڵȴ�д�Ļ�����л��Ѳ���(17-22��)��
final Node<K,V> find(int h, Object k) {
if (k != null) {
for (Node<K,V> e = first; e != null; ) {
int s; K ek;
if (((s = lockState) & (WAITER|WRITER)) != 0) {//˵���������߳��ڵȴ�д�����߳���д��,���ں��������ƽ����� ��ô�Ͳ�Ҫ�ú�������� �˻�Ϊ��ͨ����
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
e = e.next;
}
else if (U.compareAndSwapInt(this, LOCKSTATE, s,
s + READER)) {// == 0 ˵��û���̳߳���д�����ߵȴ�д��,�������Ե���, ���ý�s ���� READER �ɹ�˵�����̳߳��ж���,
TreeNode<K,V> r, p;
try {
p = ((r = root) == null ? null :
r.findTreeNode(h, k, null));//�����������
} finally {
Thread w;
if (U.getAndAddInt(this, LOCKSTATE, -READER) ==
(READER|WAITER) && (w = waiter) != null)//ע��������getAndAddInt ���ǽ���˴�����ʱ����û��д�������ǵȴ����߳�,��ʱ����еȴ��Ļ���Ҫ���л���
LockSupport.unpark(w);
}
return p;
}
}
}
return null;
}
ForwardingNode ��find����
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes ʹ��ѭ�� ����������ForwardingNode �γ���ݹ�
outer: for (Node<K,V>[] tab = nextTable;;) {//���������ϲ���
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;;) {
int eh; K ek;
//����һ���ڵ�
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
//����ForwardingNode �൱��һ�εݹ�
continue outer;
}
else
//treeBin �ڵ����
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
�ܽ�
����ṹ��ʹ��������+����+�����,������1.7Segment �ֶ���,����ʱֱ�Ӷ�����������С�
��ʼ��ʱ,�����loadFactorԤ�������Ӻ����ij�ʼ����,���ⲻ��Ҫ�����ݡ�
�������ȸ�ϸ,��Ͱλ�ϵĵ�һ���ڵ������
����Ԫ������ʹ��CounterCell����,���м�������µ��Ż���
����ʱ,�����߳̿��������ݡ�
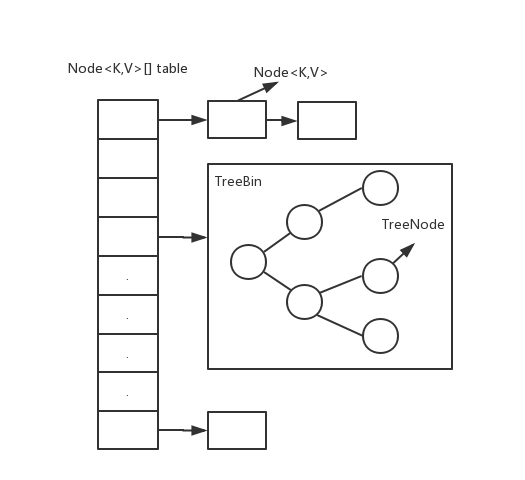
�ڵ�ɷ�Ϊ��ͨ�ڵ㡢TreeBin�ڵ㡢ForwardingNode.
ForwardingNode ��ʶ�����ƶ�Ԫ��,�ڲ���find����,������ʱ�Կɽ���get,ֻ���������±��ϲ�ѯ��
TreeBin ��ʶͰλ����,���������,������롢ɾ�������ҵȡ��ڲ�ά��lockstate �����ƺ�����Ķ�д������
ConcurrentHashMap put Ϊβ�巨,�������ƶ�Ͱλ�ϵ�Ԫ��ʱ��ʱͷ�巨,��Ϊ�ƶ���ʱ����������Ͱλ�ϵ����һ���ܷ�������������ͬλ�õĽڵ�,֮���ִӴӿ�ʼ������
ConcurrentHashMap1.8 ��ʼ��ʹ���������ط�ʽ,�ı���1.7��ʼ��ʱ�ʹ���Segment����ȱ��,��Ч�����ʼ��������