一些笔记
- 逻辑回归,SVM,决策树都是分类模型,那么面对一个分类问题,应该怎么选择?
- 逻辑回归优点:便利的观测样本概率分数,有高效的工具实现,广泛应用于工业问题,缺点:特征空间大,大量多类特征效果不好
- 支持向量机:能处理大型特征空间,能处理非线性特征之间的相互作用。缺点当观测样本很多时,效率不高,有时候合适的核函数比较难找
- 决策树:优点直观的决策规则,可以处理非线性数据,考虑到了变量间的相互作用。缺点容易过拟合(随机森林克服了这个缺点),无法输出分数只能输出类别
- 选择:数出现据特征多可以选择svm,样本多可以选择LR,如果数据缺失值比较多可以选择决策树
- 常见的优化器及其优缺点
- 梯度下降,包括随机,mini-batch的缺点:1、都容易出现震荡2、学习率很难选择,太小,收敛变慢,太大会阻碍收敛,导致损失函数在最小值附近波动甚至发散3、所有参数都是同一个学习率,我们希望对那些出现频率低的特征更新更快 4、逃不出鞍点,因为鞍点处梯度为0
- momentum:可以累加之前的梯度,如果两次梯度方向一样,可以增强,不一样,则会减弱,减缓震荡
- NAG:遇到山谷不会自动减弱更新的梯度,可能会跳过山谷,所以先根据之前累积的梯度方向模拟下一步的更新值,然后用模拟后位置的梯度与之前累计的梯度和矢量相加
- adagrad:解决参数学习率的问题,引入了二阶动量,也就是梯度平方累加,将二阶动量放在分母的位置,对于训练数据少的特征,对应的参数更新慢,也就是说它累加的梯度平方和小,对应的更新就会变快,为了防止分母为零,加了一个平滑参数
- 缺点:分母随着训练数据增加,会越变越大,导致学习速率越来越小,最终无限小,从而无法有效更新参数
- adadelta:改进ada,二阶动量变为变为之前所有梯度的加权平均
- adam:将动量与adadelta结合,引入了一阶动量与二阶动量,adam是用时间窗口里的累积,随着时间窗口的变化,遇到的数据可能发生巨变,使得二阶时大时小,不是单调变化,后期会引起学习率的震荡,导致无法收敛
- 交叉熵为什么可以做损失函数?
- 信息量:概率小的事件发生了,信息量大,L(x) = -log(p(x))
- 熵:表示所有信息量的期望
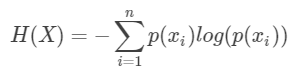 - 相对熵:KL散度,队同一个随机变量有两个单独的概率分布,用KL散度衡量这两个分布的差异,KL散度越小,表示分布越接近
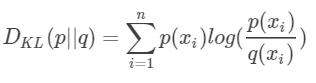 - 交叉熵:将KL散度公式变形
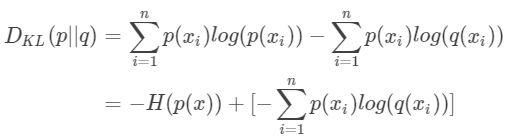
p是标签真实分布,q是我们预测的分布,等式的前一部分就是p的熵,后部分就是交叉熵,在机器学习中,我们需要评估label和predicts之间的差距,使用KL散度刚刚好,即,由于KL散度中的前一部分?H(y)不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用用交叉熵做loss
|