[Alg]ХХађЫуЗЈжЎЗжВМХХађ
зїеп:ЪКПЧРЩ
ШеЦк:Aug 2021
АцДЮ:ГѕАц
МђНщ: ЗжВМХХађЪЧгыЙщВЂХХађНиШЛЯрЗДЕФДІРэЫМТЗ,ЙщВЂХХађЪЧж№ВНШкКЯЙщВЂ,ЖјЗжВМХХађЪЧЗжзщШЛКѓКЯВЂ,дйЗжзщдйКЯВЂ,ЫљвдЗжВМХХађгжГЦЮЊЁАЭАХХађЁБЁЂЁАЛљЪ§ХХађЁБЛђЁАЪ§ХХ ађЁБЁЃЫќЛљгкМќжЕЪ§зжЬиадзжЗжРр,ДгЖјБмУтСЫБШНЯВйзїЁЃ
1ЁЂв§бд
МйЩшвЊЖд52еХЦЫПЫХЦХХађ,ЖЈвхХЦУцМќжЕЫГађ:
A
<
2
<
3
<
4
<
5
<
6
<
7
<
8
<
9
<
10
<
J
<
Q
<
K
A<2<3<4<5<6<7<8<9<10<J<Q<K
A<2<3<4<5<6<7<8<9<10<J<Q<K
ЖЈвхЛЈЩЋМќжЕЫГађ:
?
<
?
<
?
<
?
\clubsuit<\diamondsuit<\heartsuit<\spadesuit
?<?<?<?
СНеХХЦШЗЖЈЯШКѓЫГађЕФЬѕМўЮЊ(i)ЫќЕФЛЈЩЋаЁгкСэвЛеХ,Лђеп(ii)СНИіЛЈЩЋЯрЭЌ,ЕЋХЦУцжЕаЁгкСэвЛеХЁЃЭЈГЃЕФХХађЗНЗЈРрЫЦгкЛљЪ§НЛЛЛХХађ(МћЁЖ[Alg]ХХађЫуЗЈжЎНЛЛЛХХађЁЗ,ЯШИљОнЛЈЩЋЗжГЩЫФЖб,ШЛКѓдйИљОнХЦУцжЕЕїећУПвЛЖбжаХЦЕФЫГађЁЃ
ЛЙгавЛжжИќПьЕФЗНЗЈДІРэетРрХХађ!ЪзЯШИљОнХЦУцжЕЗжГЩ13Жб,ЯШЖдет13ЖбХХКУађ,МД A < 2 < ? < K A<2<\cdots<K A<2<?<K;ШЛКѓдйИљОнЛЈЩЋЗжЮЊ4ЖбЁЃШЛКѓКЯВЂЕНвЛЦ№ОЭЕУЕНХХКУађЕФНсЙћЁЃетИіЗНЗЈеЇвЛПДВЛЯдШЛЁЃдкЕкЖўВНАДЛЈЩЋЗжРрЪБ,ШчЙћСНеХХЦНјШыВЛЭЌЕФЖб,ЫЕУїЛЈЩЋВЛвЛбљ,ЛсИљОнЛЈЩЋХХађ;ШчЙћСНеХХЦОпгавЛбљЕФЛЈЩЋ,ФЧдкЕквЛВНЗжРрЪБвбОХХКУађЁЃЭЌбљЕФЫМЯывВПЩвдгІгУЕНЪ§зжЛђзжФИРраЭЕФШЮвтзжЕфађЕФХХађЩЯЁЃ
Щш N N NИіМЧТМ,ЗжГЩ M M MЖб,УПИіЖбЕФШнСПвЊБЃжЄФмШнФЩ N N NИіМЧТМ,етОЭашвЊ M ( N + 1 ) M(N+1) M(N+1)ЕФПеМф,етОЭЪЧДѓВПЗжШЫОмОјетИіЫуЗЈЕФдвђЁЃ
2ЁЂЛљЪ§ХХађ
ЯТУцНщЩмвЛжжЛљгкМќжЕЕФЛљЪ§,ВЩгУСДБэЗЈЕФХХађЫуЗЈ,ЙУЧвГЦжЎЮЊЛљЪ§ХХађЁЃЯТУцОйвЛИівд10НјжЦЮЊЛљЪ§ХХађЕФР§згЁЃ
503
??
087
??
512
??
061
??
908
??
170
??
897
??
275
??
653
??
426
??
154
??
509
??
612
??
677
??
765
??
703
503\;087\;512\;061\;908\;170\;897\;275\;653\;426\;154\;509\;612\;677\;765\;703
503087512061908170897275653426154509612677765703
ЕквЛЬЫБщРњ,вдИіЮЛЪ§ЮЊЛљзМЗжЖб,НсЙћШчЯТ:
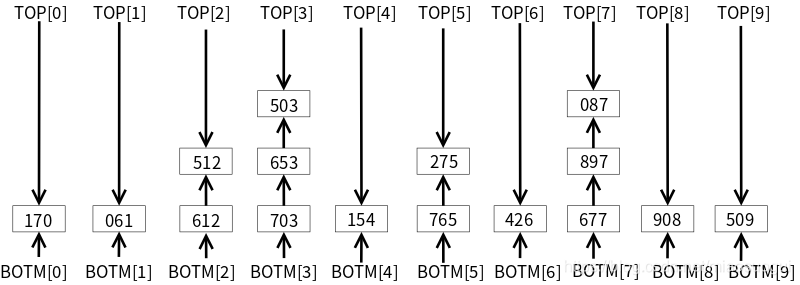
ЭъГЩКѓжиаТДЎСЌЦ№РД,МћЭМжаКьЩЋЯп(ЫуЗЈH):
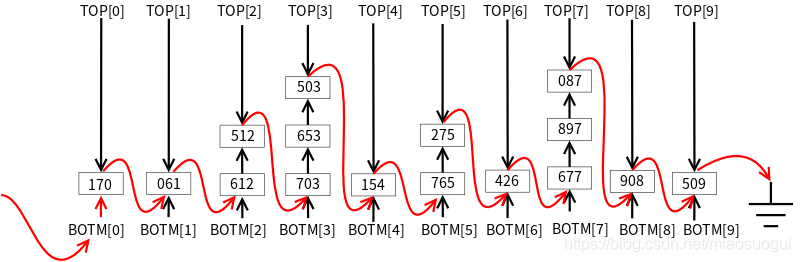
ЕкЖўЬЫБщРњ,вдЪЎЮЛЪ§ЮЊЛљзМЗжЖб,НсЙћШчЯТ:
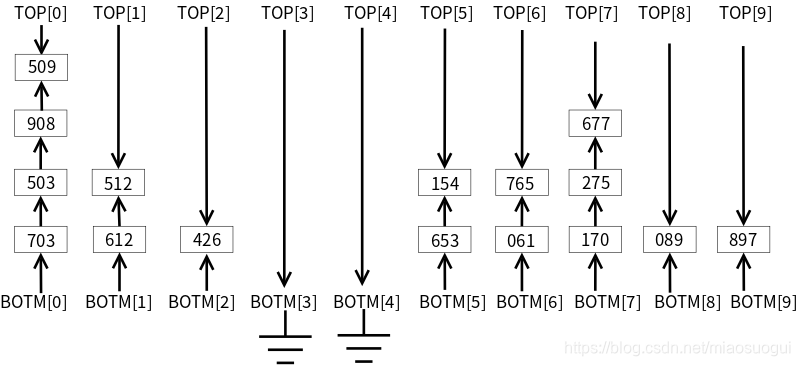
ЕкШ§ЬЫБщРњ,вдАйЮЛЪ§ЮЊЛљзМЗжЖб,НсЙћШчЯТ:
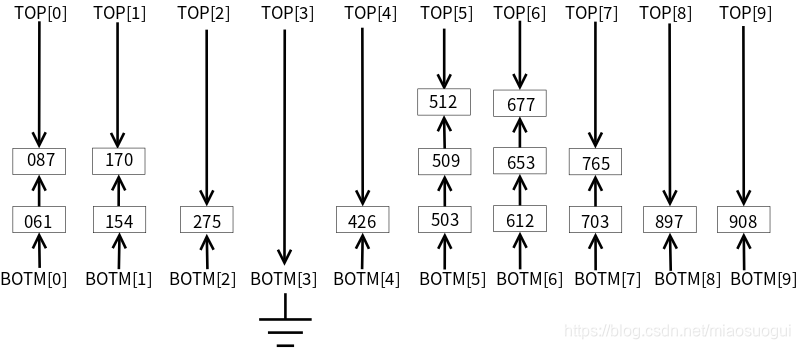
змНсЫуЗЈШчЯТ:
ЫуЗЈR:(ЛљЪ§ХХађ)
ЩшМЧТМ
R
1
,
R
2
,
Ё
,
R
N
R_1,R_2,\ldots,R_N
R1?,R2?,Ё,RN?,АќКЌСДНгЕижЗЁЃЦфЖдгІЕФМќжЕЮЊ:
(
a
1
,
a
2
,
Ё
,
a
p
)
,
0
Ём
a
i
<
M
.
(a_1,a_2,\ldots,a_p),\qquad 0\leq a_i<M.
(a1?,a2?,Ё,ap?),0Ёмai?<M.
M
M
MЮЊЛљЪ§,ЦфМќжЕПЩБэЪОЮЊ:
a
1
M
p
?
1
+
a
2
M
p
?
2
+
?
+
a
p
?
1
M
+
a
p
a_1M^{p-1}+a_2M^{p-2}+\cdots+a_{p-1}M+a_p
a1?Mp?1+a2?Mp?2+?+ap?1?M+ap?
- R1.[бЛЗk] дкПЊЪМНзЖЮ,жУ P Ёћ L O C ( R N ) P\gets LOC(R_N) PЁћLOC(RN?),АбжИеыжИЯђзюКѓвЛЯюЁЃШЛКѓ k = 1 , 2 , Ё , p k=1,2,\ldots,p k=1,2,Ё,p,жДааR2жСR6,МДЭъГЩвЛЬЫБщРњЁЃ
- R2.[ЧхПеЖб] жУ T O P [ i ] Ёћ L O C ( B O T M [ i ] ) TOP[i]\gets LOC(BOTM[i]) TOP[i]ЁћLOC(BOTM[i]), B O T M [ i ] Ёћ ІЋ BOTM[i]\gets \Lambda BOTM[i]ЁћІЋ for 0 Ём i < M 0\leq i<M 0Ёмi<MЁЃ
- R3.[НтЮіМќжЕ k k kЮЛ] жУ i Ёћ a p + 1 ? k i\gets a_{p+1-k} iЁћap+1?k?,МДШЁМќжЕ k k kгааЇЮЛЁЃ
- R4.[ЕїећСДНг] жУ L I N K ( T O P [ i ] ) Ёћ P LINK(TOP[i])\gets P LINK(TOP[i])ЁћP,ШЛКѓжУ T O P [ i ] Ёћ P TOP[i]\gets P TOP[i]ЁћPЁЃ
- R5.[вЦжСЯТвЛИі] ШчЙћ k = 1 k=1 k=1(ЕквЛЬЫ)ВЂЧв P = L O C ( R j ) P=LOC(R_j) P=LOC(Rj?)Чв j Ёй 1 j\neq1 jЊС?=1,жУ P Ёћ L O C ( R j ? 1 P\gets LOC(R_{j-1} PЁћLOC(Rj?1?ВЂЗЕЛиR3ЁЃШчЙћ k > 1 k>1 k>1,жУ P Ёћ L I N K ( p ) P\gets LINK(p) PЁћLINK(p)Чв P Ёй ІЋ P\neq\Lambda PЊС?=ІЋ,ЗЕЛиR3ЁЃ
- R6.[жДааДЎСЌГЬађ] жУ P Ёћ B O T M [ 0 ] P\gets BOTM[0] PЁћBOTM[0],зїЮЊСДБэЭЗ,жиаТДЎСЌСДБэЁЃ
ЫуЗЈH:(ДЎСЌСДБэ)
- H1.[ГѕЪМЛЏ] жУ i Ёћ 0 i\gets0 iЁћ0ЁЃ
- H2.[жИЯђЖбЕФЖЅЖЫ] жУ P Ёћ T O P [ i ] P\gets TOP[i] PЁћTOP[i]ЁЃ
- H3.[ЯТвЛЖб] i Ёћ i + 1 i\gets i+1 iЁћi+1ЁЃШчЙћ i = M i=M i=M,жУ L I N K ( P ) Ёћ ІЋ LINK(P)\gets\Lambda LINK(P)ЁћІЋВЂНсЪјЁЃ
- H4.[ЪЧПеЖбТ№?] ШчЙћ B O T M [ i ] = ІЋ BOTM[i]=\Lambda BOTM[i]=ІЋ,ЗЕЛиH3ЁЃ
- H5.[АбЖбСДЦ№РД] жУ L I N K ( P ) Ёћ B O T M [ i ] LINK(P)\gets BOTM[i] LINK(P)ЁћBOTM[i]ЁЃЗЕЛиH2ЁЃ
дкЁЖ[Alg]ХХађЫуЗЈжЎМЦЪ§ХХађЁЗжа,НВСЫвЛИіЗЧГЃЬьВХЕФЗжВМЭГМЦХХађ,ПЩвдНсКЯЩЯЪіЕФЛљЪ§ХХађЪЙгУ,ЕЋЧАЬсЪЧЛљЪ§ХХађБиаыДгзюИпгааЇЮЛЯђЕЭгааЇЮЛЗжРрЁЃвђЮЊЗжВМЭГМЦХХађВЛЪЧвЛИіЮШЖЈЕФХХађЫуЗЈ,ЖјЛљЪ§ХХађКѓајЕФЗжРрЛљгкЧАУцХХађЕФНсЙћЕФ,ЗжВМХХађЕФВЛЮШЖЈадЛсЦЦЛЕетИіЧАЬсЁЃЕЋДгзюИпгааЇЮЛПЊЪМ,ОЭПЩвдЯћГ§етжжвўЛМ,ДгзюИпЮЛПЊЪМЛЙгаСэвЛИіКУДІ,ОЭЪЧЮвУЧВЛгУЭъШЋЪЙгУЛљЪ§ХХађ,ПЩвджЛХЩЧА p p pЮЛ,ЪЃгрЕФПЩвдВЩШЁЦфЫќХХађЫуЗЈРДДІРэ,вдЬсИпаЇТЪЁЃ
ЯТУцЬИЬИЛљЪ§ХХађКЭЛљЪ§НЛЛЛХХађЕФЧјБ№:
- 1ЁЂЛљЪ§НЛЛЛХХађЪЧДгзюИпгааЇЮЛПЊЪМЕФ,ЛљЪ§ХХађЪЧДгЕЭЮЛЯђИпЮЛ(ЕБШЛДгИпЮЊЯђЕЭЮЛвВПЩвд);
- 2ЁЂСНжжХХађЫуЗЈЖМВЛашвЊБШНЯМќжЕ;
- 3ЁЂЛљЪ§НЛЛЛХХађЪЧЗжГЩСНзщ,ЖјЛљЪ§ХХађЗжзщЪЧПЩБфЕФ(ШЫЮЊбЁЖЈ,ПЩвд2,4,8,16ЖМаа);
- 4ЁЂЛљЪ§ХХађЕФдЫааЪБМфЪЧЙЬЖЈЕФ O ( N lg ? K ) O(N\lg K) O(NlgK),ЖјЛљЪ§НЛЛЛХХађвРРЕгкЛљЪ§ЕФЗжВМЧщПіЖјВЛвРРЕгкМќжЕ K K KЕФДѓаЁ O ( N lg ? N ) O(N\lg N) O(NlgN)ЁЃ
- 5ЁЂЛљЪ§НЛЛЛХХађВЛашвЊЖюЭтЕФСДНгЁЃ
ЛЙгавЛжжЧщПівЊЬиБ№зЂвт,ОЭЪЧМЦЫуЛњВЩШЁВЙТыЪБ,ШчЙћМќжЕВЛЪЧunsigned intРраЭ,дкзюКѓДІРэЪБЛсгаЫљВЛЭЌЁЃвд
M
=
256
M=256
M=256ЮЊР§,зюКѓДЎЦ№ИїЖбЕФЫГађгІИУЮЊ:
(
10000000
)
2
,
(
10000001
)
2
,
Ё
,
(
11111111
)
2
,
(
00000000
)
2
,
(
00000001
)
2
,
Ё
,
(
01111111
)
2
(10000000)_2,(10000001)_2,\ldots,(11111111)_2,(00000000)_2,(00000001)_2,\ldots,(01111111)_2
(10000000)2?,(10000001)2?,Ё,(11111111)2?,(00000000)2?,(00000001)2?,Ё,(01111111)2?