гаМрЖНбЇЯАЈCЯпадЛиЙщ
вЛ:ЫуЗЈдРэ
ЖрдЊЯпадЛиЙщ:УПИі x ДњБэвЛИіЬиеї
ФЃаЭ:
[
y
1
y
2
.
.
.
y
p
]
=
[
1
,
x
11
,
x
12
,
.
.
.
,
x
1
p
1
,
x
21
,
x
22
,
.
.
.
,
x
2
p
.
.
.
1
,
x
n
1
,
x
n
2
,
.
.
.
,
x
n
p
]
?
[
w
0
w
1
.
.
.
w
p
]
=
w
0
+
X
W
\left[ \begin{matrix} y_1 \\ y_2 \\ ... \\ y_p \end{matrix} \right] = \left[ \begin{matrix} 1,x_{11},x_{12},...,x_{1p} \\ 1,x_{21},x_{22},...,x_{2p} \\ ... \\ 1,x_{n1},x_{n2},...,x_{np} \end{matrix} \right] * \left[ \begin{matrix} w_0 \\ w_1 \\ ... \\ w_p \end{matrix} \right] = w_0+XW
?????y1?y2?...yp???????=?????1,x11?,x12?,...,x1p?1,x21?,x22?,...,x2p?...1,xn1?,xn2?,...,xnp?????????????w0?w1?...wp???????=w0?+XW
ФПЕФ:евЕНзюКУЕФ W
ЗНЗЈ:зюаЁЖўГЫЗЈ
ЙиМќИХФю:Ы№ЪЇКЏЪ§
Ы№ЪЇКЏЪ§:ФЃаЭБэЯждНВЛКУ,дђЫ№ЪЇЕФаХЯЂдНЖр,жЕДњБэЮѓВюЦНЗНКЭSSE,МДдЄВтжЕКЭЙлВтжЕЕФЮѓВюЦНЗНКЭ
ДњТыЪЕЯжвЛдЊЯпадЛиЙщ:
#вЛдЊЯпадЛиЙщ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#ЩшМЦЪ§Он
#МгЫцЛњжжзг,ИЩШХЪ§Он
np.random.seed(100)
x = np.random.rand(50)*10
np.random.seed(120)
y = 2*x - 5 + np.random.randn(50)
#ЛЭМ
plt.plot(x,y,'.')
#########################################################################
#skleanЪЕЯжЯпадЛиЙщ
#1.ЕМАќ
from sklearn.linear_model import LinearRegression
#2.ЪЕР§ЛЏФЃаЭ
lr = LinearRegression(fit_intercept=True) #fit_intercept=True етИіДњБэФЌШЯФЃаЭжаДцдкНиОр
#3.бЕСЗФЃаЭ
#3.1 зЂвтЩЯУцxЪ§ОнЪЧвЛЮЌЕФ,ашвЊзЊЛЏГЩЖўЮЌ
x_x = x.reshape(-1,1)
#3.2бЕСЗ
lr = lr.fit(x_x,y)
#############################################################
#ВщПДФЃаЭаЇЙћ
#1.ПДаБТЪ
lr.coef_ # array([2.1022037])
#2.ПДНиОр
lr.intercept_ # -5.310986089436093
#ЫљвдФЃаЭ y = 2.1*x - 5.31
###############################################################
#НЋФЃаЭЕФжБЯпЛцжЦЕНЩЂЕуЭМжа
#1.ЩњГЩ x Ъ§Он
x_prt= np.linspace(0,10,100) #БэЪОДг 0 ЕН 10 ,ЩњГЩ100ИіОљдШЕФЪ§Он
#2.зЊЛЛ x_prt ЕФЮЌЖШ
x_prt = x_prt.reshape(-1,1)
#3.ЪЙгУФЃаЭНјаадЄВт yЕФжЕ
y_prt = lr.predict(x_prt)
#ЛЭМ
plt.plot(x_prt,y_prt) #ФЃаЭжБЯп
plt.plot(x,y,'.') #бЕСЗЪ§Он
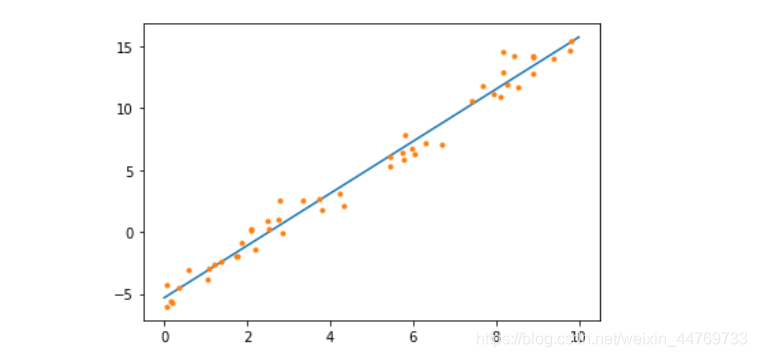
Жў:ЗПМлдЄВтDemo
ФЃаЭФтКЯГЬЖШ:
- MSE:ЦНОљВаВю , (SSEЪЧЮѓВюЦНЗНКЭ, MSE=SSE/ m)
- RЗН:
#ЗПМлдЄВт
#ЕМАќ
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression #ЯпадЛиЙщ
from sklearn.model_selection import train_test_split #ЛЎЗжЪ§ОнМЏ
from sklearn.model_selection import cross_val_score #НЛВцбщжЄ
from sklearn.datasets import fetch_california_housing #МгРћИЃФсбЧЗПЮнМлжЕЪ§Он
#1.Ъ§ОнДІРэ
house_data = fetch_california_housing()
x_house = pd.DataFrame(house_data.data,columns=house_data.feature_names)
print(df_house.head())
y_house = house_data.target
print(y_house)
#2.В№ЗжЪ§ОнМЏ
Xtrain,Xtest,Ytrain,Ytest = train_test_split(x_house,y_house,test_size=0.3,random_state=420)
#3.НЈФЃ,ЪЕР§ЛЏ
lr = LinearRegression()
#4.бЕСЗФЃаЭ
lr = lr.fit(Xtrain,Ytrain)
Ш§:ФЃаЭЦРЙР
3.1 MSEОљЗНЮѓВю
MSEжИБъ:
#5.ФЃаЭЦРЙР
#5.1 бЕСЗМЏЕФ MSE(ОљЗНЮѓВю)
from sklearn.metrics import mean_absolute_error
#ЪЙгУбЕСЗжЕНјаадЄВт
y_yuce = lr.predict(Xtrain) #дЄВтжЕ
#ЪЙгУдЄВтжЕ КЭ ецЪЕжЕНјааЖдБШ,МЦЫуОљЗНЮѓВю
mse = mean_absolute_error(Ytrain,y_yuce) # Ytrain ецЪЕжЕ,y_yuceдЄВтжЕ
print('ОљЗНЮѓВю=',mse) #ОљЗНЮѓВю= 0.530942761735602 , mseдНаЁдНКУ
#5.2 ВтЪдМЏЕФMSE(ОљЗНЮѓВю)
y_test_yuce = lr.predict(Xtest)
mse_test = mean_absolute_error(Ytest,y_test_yuce)
print('ВтЪдМЏmse=',mse_test) #ВтЪдМЏmse= 0.5307069814636152
MSEНЛВцбщжЄ:
#НЛВцбщжЄ
#1.MSE ОљЗНЮѓВю
ls2 = LinearRegression()
mse = cross_val_score(ls2,Xtrain,Ytrain,cv=10,scoring='neg_mean_squared_error')
#cv=10 ДњБэел10ДЮ
#scoring='neg_mean_squared_error'ДњБэЪЙгУИКЕФОљЗНЮѓВюзіНЛВцбщжЄЕФВЮЪ§,вђЮЊУЛгае§ЕФОљЗНЮѓВю
mse.mean()
ШчКЮВщбЏ scoring ВЮЪ§:
import sklearn
sorted(sklearn.metrics.SCORERS.keys())
3.2 MAE ОјЖдОљжЕЮѓВю(КЭMSEВюВЛЖр,ЖўепШЁЦфвЛМДПЩ)
#2.ОјЖдОљжЕЮѓВю MAE , гы MSEВюВЛЖр,ЖўепШЁЦфвЛМДПЩ
from sklearn.metrics import mean_absolute_error
mean_absolute_error(Ytrain,y_yuce)
#ЪЙгУ MAEзіНЛВцбщжЄЕФВЮЪ§ scoring='neg_mean_absolute_error'
3.3 RЗН
RЗН-ЗНВю,гУгкКтСПsЪ§ОнМЏАќКЌЖрЩйаХЯЂСП
RЗНдНЧїНќгк1,ДњБэФЃаЭФтКЯаЇЙћдНКУ
ЗНЪНвЛ:
from sklearn.metrics import r2_score
r2 = r2_score(Ytrain,y_yuce)
print('бЕСЗМЏRЗНжЕ=',r2) #бЕСЗМЏRЗНжЕ= 0.6067440341875014
r2_test = r2_score(Ytest,y_test_yuce)
print('ВтЪдМЏRЗНжЕ=',r2_test) #ВтЪдМЏRЗНжЕ= 0.6043668160178817
ЗНЪНЖў:
#етИіscoreЗНЗЈЗЕЛиЕФОЭЪЧ RЗНжЕ
lr.score(Xtrain,Ytrain) #0.6067440341875014
lr.score(Xtest,Ytest) #0.6043668160178817
НЛВцбщжЄ:
#НЛВцбщжЄ,ЧѓЦНОљЕУЗж
lr2 = LinearRegression()
cross_val_score(lr2,Xtrain,Ytrain,cv=10,scoring='r2').mean() #0.6039238235546339
3.4 ВщПДФЃаЭЯЕЪ§
wЯЕЪ§
lr.coef_
list(zip(x_house.columns,lr.coef_))
#ЯЕЪ§НсЙћ :
# [('MedInc', 0.4373589305968403), ДњБэ:етИіЬиадЕФw = 0.4373589305968403
# ('HouseAge', 0.010211268294494038),
# ('AveRooms', -0.10780721617317715),
# ('AveBedrms', 0.6264338275363783),
# ('Population', 5.216125353178735e-07),
# ('AveOccup', -0.0033485096463336094),
# ('Latitude', -0.4130959378947711),
# ('Longitude', -0.4262109536208467)]
НиОр
lr.intercept_ #-36.25689322920386
#ДњБэ w0 = -36.25689322920386
3.5 ФЃаЭЙЋЪН
ИљОн3.4ФЃаЭЯЕЪ§ЕУГі:
y = 0.43ЁСMedInc+0.01ЁСHouseAge-0.1ЁСAveRooms+0.62ЁСAveBedrms+0.0000005ЁСPopulation-0.003ЁСAveOccup-0.41ЁСLatitude-0.42ЁСLongitude-36.25
ЫФ:НЋЪ§ОнМЏБъзМЛЏжЎКѓдйбЕСЗ
БъзМЛЏ: ЯћГ§СПИйЕФгАЯь
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
#1.ЖдбЕСЗМЏНјааБъзМЛЏ
Xtrain_std = std.fit_transform(Xtrain)
#2.ЪЕР§ЛЏаТЕФФЃаЭ
lr_std = LinearRegression()
#3.ЪЙгУБъзМЛЏжЎКѓЕФбЕСЗМЏНјаабЕСЗ
lr_std = lr_std.fit(Xtrain_std,Ytrain)
#4.ВщПДrЗНжЕ
lr_std.score(Xtrain_std,Ytrain) #0.6067440341875014
Юх:ЛцжЦФтКЯЭМЯё
#ЛцжЦФтКЯЭМЯё
#1.ЛцжЦЙлВтжЕ
plt.scatter(range(len(Ytest)),sorted(Ytest),s=2,label='True') #ХХађжЎКѓдйЛЭМ,ЗёдђЕуОЭЬЋТвСЫ,ЕЋЪЧзЂвтЦЅХфдЄВтжЕКЭецЪЕжЕЕФЮЛжУ,вђЮЊецЪЕжЕХХађСЫ
#ЛёШЁХХађжЎКѓЕФЫїв§жЕ
index_sort = np.argsort(Ytest)
#дЄВтжЕ
y2 = lr.predict(Xtest)
#ЭЈЙ§Ыїв§евЕНдЄВтжЕЕФЫГађ
y3 = y2[index_sort]
#2.ЛцжЦдЄВтжЕ
plt.scatter(range(len(Ytest)),y3,s=1,label='Predict',alpha=0.3)
plt.legend()
plt.show()
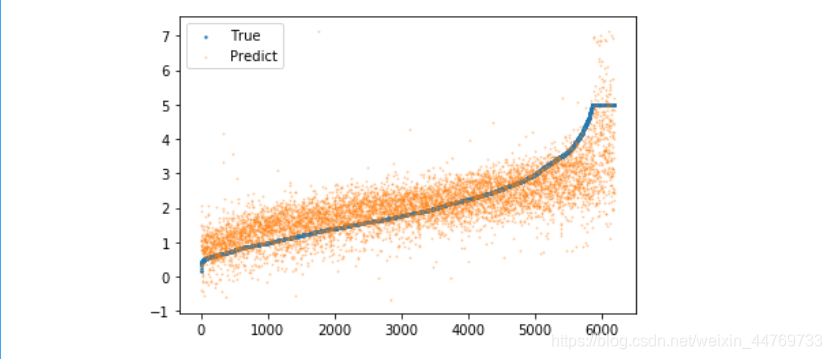
Сљ:ЖржиЙВЯпад
МДЬиеїКЭЬиеїжЎМфДцдкИпЖШЯрЙиад
from sklearn.preprocessing import PolynomialFeatures
#1.ЪЕР§ЛЏ
pl = PolynomialFeatures(degree=4).fit(x_house,y_house) #degree=2 етИіжЕдНДѓ,МЦЫуЫйЖШдНТ§
pl.get_feature_names() #ЭЈЙ§ЖрЯюЪНЙЙдьСа
#2.Ъ§ОнзЊЛЏ
x_trans = pl.transform(x_house)
#3.ЪЙгУзЊЛЏКѓЕФЪ§ОнНјааЛЎЗжЪ§ОнМЏ
Xtrain,Xtest,Ytrain,Ytest = train_test_split(x_trans,y_house,test_size=0.3,random_state=420)
#4.бЕСЗЪ§Он
result = LinearRegression().fit(Xtrain,Ytrain)
#5.ВщПДЬиеїКЭЯрЙиЯЕЪ§
result.coef_
[*zip(pl.get_feature_names(x_house.columns),result.coef_)]
#6.ВщПДБфЛЏжЎКѓЕФ RЗНжЕ
result.score(Xtrain,Ytrain) #0.7705009887940618 , Абdegree=4 ЕїИпЕФФтКЯаЇЙћИќКУ