1��Stringԭ����ʵ��
string������ģ����basic_string<class _CharT,class _traits,class _alloc>ʵ�������ɵ�һ���ࡣbasic_tring����_String_base�̳ж����ġ�
typedef basic_string<char> string��ʵ����������ʱ���ϵ,һ�㲻��Ҫ�����ϸ��string�Ĺ���,һ��Ҫ����ʵ�ֹ��캯��,�������캯��,��ֵ����,���������Ȳ���,��Ϊstring�����漰��̬�ڴ����,Ĭ�ϵĿ������캯��������ֻ�����dz����,�����������������ָ��һ�������ڴ�Ķ������һ����������,���������һ���������г���,��ʱҪ���������
#pragma once
// Ϊ�˱���ͬһ��ͷ�ļ�������(include)���,C/C++�������ֺ�ʵ�ַ�ʽ:һ����#ifndef��ʽ;
// ��һ����#pragma once��ʽ��
#include<iostream>
class String
{
private:
char* data; //�ַ�������
size_t length; //�ַ�������
public:
String(const char* str = nullptr); //ͨ�ù��캯��
String(const String& str); //�������캯��
~String(); //��������
// const������java��static final
String operator+(const String &str) const; //����+
String& operator=(const String &str); //����=
String& operator+=(const String &str); //����+=
bool operator==(const String &str) const; //����==
friend std::istream& operator>>(std::istream &is, String &str);//����>>
friend std::ostream& operator<<(std::ostream &os, String &str);//����<<
char& operator[](int n)const; //����[]
size_t size() const; //��ȡ����
const char* c_str() const; //��ȡC�ַ���
};#include"String.h"
//ͨ�ù��캯��
String::String(const char *str)
{
if (!str)
{
length = 0;
data = new char[1]; //һ��Ҫ��new�����ڴ�,����ͱ����dz����;
*data = '\0';
}
else
{
length = strlen(str); //
data = new char[length + 1];
strcpy(data,str);
}
}
//�������캯��
String::String(const String& str)
{
length = str.size();
data = new char[length + 1]; //һ��Ҫ��new,��������dz����
strcpy(data,str.c_str());
}
//��������
String::~String()
{
delete[]data;
length = 0;
}
//����+
String String::operator+(const String &str) const
{
String StringNew;
StringNew.length = length + str.size();
StringNew = new char[length + 1];
strcpy(StringNew.data, data);
strcat(StringNew.data, str.data); //�ַ���ƴ�Ӻ���,����str���ݸ��Ƶ�StringNew���ݺ���
return StringNew;
}
//����=
String& String::operator=(const String &str)
{
if (this == &str)
{
return *this;
}
delete []data; //�ͷ��ڴ�
length = str.length;
data = new char[length + 1];
strcpy(data,str.c_str());
return *this;
}
//����+=
String& String::operator+=(const String &str)
{
length += str.size();
char *dataNew = new char[length + 1];
strcpy(dataNew, data);
delete[]data;
strcat(dataNew, str.c_str());
data = dataNew;
return *this;
}
//����==
bool String::operator==(const String &str) const
{
if (length != str.length)
{
return false;
}
return strcmp(data, str.data) ? false : true;
}
//����[]
char& String::operator[](int n) const //str[n]��ʾ��n+1��Ԫ��
{
if (n >= length)
{
return data[length - 1]; //������
}
else
{
return data[n];
}
}
//��ȡ����
size_t String::size() const
{
return this->length;
}
//��ȡC�ַ���
const char* String::c_str() const
{
return data;
}
//����>>
std::istream& operator>>(std::istream &is, String &str)
{
char tem[1000];
is >> tem;
str.length = strlen(tem);
str.data = new char[str.length + 1];
strcpy(str.data, tem);
return is;
}
//����<<
std::ostream& operator<<(std::ostream &os, String &str)
{
os << str.c_str();
return os;
}����operator>>��operator<<���������,��������Ƴ���Ԫ����(�dz�Ա����),��û����Ƴɳ�Ա������
ԭ������:����һ�����������ض����Ϊ��ij�Ա����,��>>��<<ȴ���������,��Ϊ��Ϊһ����Ա����,��������������������ͬһ����֮�µĶ���,�����Ƴ�Ա����,���Ϊ ����>>cout >> endl;(Essential C++)������ϰ�ߡ�
һ�������:
- ��˫Ŀ���������Ϊ��Ԫ����,�����Ϳ���ʹ�ý�����,�ȽϷ���
- ��Ŀ�����һ������Ϊ��Ա����,��Ϊֱ�Ӷ�����������в���
- ��������غ���������Ϊ��Ա����,��Ԫ����,��ͨ������
- ��ͨ����:һ�㲻��,ͨ����Ĺ����ӿڼ�ӷ���˽�г�Ա��
- ��Ա����:��ͨ��thisָ����ʱ���ij�Ա,������дһ������,���DZ���ʽ��ߵĵ�һ�����������������,ͨ��������������ó�Ա������
- ��Ԫ����:���һ�㲻�Ƕ���<< >>�����һ�㶼Ҫ����Ϊ��Ԫ���غ���
2��������ʵ��
2.1��˳������
������ݽṹ,����һ�������Ĵ洢�ռ�,������ʵ�֡�
#pragma once
#ifndef SQLIST_H
#define SQLIST_H
#define MaxSize 50
typedef int DataType;
struct SqList //˳����൱��һ������,����ṹ����Ѿ���ʾ������˳���
{
DataType data[MaxSize];
int length; //��ʾ˳���ʵ�ʳ���
};//˳������Ͷ���
void InitSqList(SqList * &L);
//�ͷ�˳���
void DestroySqList(SqList * L);
//�ж��Ƿ�Ϊ�ձ�
int isSqListEmpty(SqList * L);
//����˳�����ʵ�ʳ���
int SqListLength(SqList * L);
//��ȡ˳����е�i��Ԫ��ֵ
DataType SqListGetElem(SqList * L, int i);
//��˳����в���Ԫ��e,��������˳����ĸ�λ��
int GetElemLocate(SqList * L, const DataType e);
//�ڵ�i��λ�ò���Ԫ��
int SqListInsert(SqList *&L, int i, DataType e);
//ɾ����i��λ��Ԫ��,�����ظ�Ԫ�ص�ֵ
DataType SqListElem(SqList* L, int i);
#endif#include<iostream>
#include"SqList.h"
using namespace std;
//��ʼ��˳���
void InitSqList(SqList * &L)
{
L = (SqList*)malloc(sizeof(SqList)); // �����ڴ�
L->length = 0;
}
//�ͷ�˳���
void DestroySqList(SqList * L)
{
if (L == NULL)
{
return;
}
free(L);
}
//�ж��Ƿ�Ϊ�ձ�
int isSqListEmpty(SqList * L)
{
if (L == NULL)
{
return 0;
}
return (L->length == 0);
}
//����˳�����ʵ�ʳ���
int SqListLength(SqList * L)
{
if (L == NULL)
{
cout << "˳��������ڴ�ʧ��" << endl;
return 0;
}
return L->length;
}
//��ȡ˳����е�i��Ԫ��ֵ
DataType SqListGetElem(SqList * L,int i)
{
if (L == NULL)
{
cout << "No Data in SqList" << endl;
return 0;
}
return L->data[i - 1];
}
//��˳����в���Ԫ��e,��������˳����ĸ�λ��
int GetElemLocate(SqList * L, const DataType e)
{
if( L == NULL)
{
cout << "Empty SqList" << endl;
return 0;
}
int i = 0;
while(i < L->length && L->data[i] != e)
{
i++;
}
if (i > L->length)
return 0;
return i + 1;
}
//�ڵ�i��λ�ò���Ԫ��
int SqListInsert(SqList *&L, int i, DataType e)
{
if(L == NULL)
{
cout << "error" << endl;
return 0;
}
if (i > L->length + 1 || i < 1)
{
cout << "error" << endl;
return 0;
}
for (int j = L->length; j>=i - 1; j--) //��i֮���Ԫ�غ���,�ڳ��ռ�
{
L->data[j] = L->data[j - 1];
}
L->data[i] = e;
L->length++;
return 1;
}
//ɾ����i��λ��Ԫ��,�����ظ�Ԫ�ص�ֵ
DataType SqListElem(SqList* L, int i)
{
if (L == NULL)
{
cout << "error" << endl;
return 0;
}
if (i < 0 || i > L->length)
{
cout << "error" << endl;
return 0;
}
DataType e = L->data[i - 1];
for (int j = i; j < L->length;j++)
{
L->data[j] = L->data[j + 1];
}
L->length--;
return e;
}2.2����ʽ��
#pragma once
#ifndef LINKLIST_H
#define LINKLIST_H
typedef int DataType;
//������:��������һ���ڵ�һ���ڵ㹹��,
//�ȶ���һ���ڵ�,�ڵ�Ϊһ���ṹ��,����Щ�ڵ�����һ��,
// ����Ϊָ��ͷ���Ľṹ����ָ��,����LinkList��ָ��
typedef struct LNode //������ǽڵ������
{
DataType data;
struct LNode *next; //ָ���̽ڵ�
}LinkList;
void InitLinkList(LinkList * &L); //��ʼ������
void DestroyLinkList(LinkList * L); //���ٵ�����
int isEmptyLinkList(LinkList * L); //�ж������Ƿ�Ϊ��
int LinkListLength(LinkList * L); //����������
void DisplayLinkList(LinkList * L); //�������Ԫ��
DataType LinkListGetElem(LinkList * L,int i);//��ȡ��i��λ�õ�Ԫ��ֵ
int LinkListLocate(LinkList * L,DataType e); //Ԫ��e��������λ��
int LinkListInsert(LinkList * &L,int i,DataType e);//�ڵ�i������Ԫ��e
DataType LinkListDelete(LinkList * &L,int i); //ɾ��������i����Ԫ��
#endif#include<iostream>
#include"LinkList.h"
using namespace std;
void InitLinkList(LinkList * &L) //��ʼ������
{
L = (LinkList*)malloc(sizeof(LinkList)); //����ͷ���
L->next = NULL;
}
void DestroyLinkList(LinkList * L) //���ٵ�����
{
LinkList *p = L, *q = p->next;//���������ڵ�ָ��
if(L == NULL)
{
return;
}
while (q != NULL) //����һ������,����һ���ڵ�һ���ڵ������
{
free(p);
p = q;
q = p->next;
}
free(p);
}
int isEmptyLinkList(LinkList * L) //�ж������Ƿ�Ϊ��
{
return (L->next == NULL);// 1:��;0:�ǿ�
}
int LinkListLength(LinkList * L) //����������,�����ij��ȱ���һ���ڵ�һ���ڵ�ı���
{
LinkList *p = L;
if (L == NULL)
{
return 0;
}
int i = 0;
while (p->next != NULL)
{
i++;
p = p->next;
}
return i;
}
void DisplayLinkList(LinkList * L)//�������Ԫ��
{
LinkList * p = L->next; //�˴�һ��Ҫָ��next,�����ǵ�һ���ڵ�,������ͷ���
while (p != NULL)
{
cout << p->data << " ";
p = p->next;
}
cout << endl;
}
DataType LinkListGetElem(LinkList * L, int i)//��ȡ��i��λ�õ�Ԫ��ֵ
{
LinkList *p = L;
if (L == NULL || i < 0)
{
return 0;
}
int j = 0;
while (j < i && p->next != NULL)
{
j++; p = p->next;
}
if (p == NULL)
{
return 0;
}
else
{
return p->data;
}
}
int LinkListLocate(LinkList * L, DataType e) //Ԫ��e��������λ��
{
LinkList *p = L;
if (L == NULL)
{
return 0;
}
int j = 0;
while (p->next != NULL && p->data == e)
{
j++;
}
return j+1;
}
int LinkListInsert(LinkList * &L, int i, DataType e)//�ڵ�i������Ԫ��e
{
LinkList *p = L,*s;
int j = 0;
if (L == NULL )
{
return 0;
}
while (j < i-1 && p != NULL) //�Ƚ�ָ���Ƶ��ô�
{
j++;
p = p->next;
}
s = (LinkList*)malloc(sizeof(LinkList)); //����һ���ڵ�,�迪��һ���µ��ڴ�
s->data = e;
s->next = p->next; //�Ƚ���һ��ַ���½ڵ�
p->next = s; //��ԭ����ָ��ָ���½ڵ�
return 1;
}
DataType LinkListDelete(LinkList * &L, int i) //ɾ��������i����Ԫ��
{
LinkList *p = L,*q; //p�����洢��ʱ�ڵ�
DataType e; //�����汻ɾ�����Ԫ��
int j = 0;
while (j < i - 1 && p != NULL) //��pָ���i-1�ڵ�
{
j++;
p = p->next;
}
if (p == NULL)
{
return 0;
}
else
{
q = p->next; //qָ���i���ڵ�*p
e = q->data; //
p->next = q->next;//��������ɾ��p�ڵ�,����p->next = p->next->next,����i���ڵ���Ϣ��ȡ����
free(q); //�ͷ�p���ڴ�
return e;
}
}2.3��˫����
#pragma once
#ifndef DLINKLIST_H
#define DLINKLIST_H
typedef int DataType;
typedef struct DLNode
{
DataType Elem;
DLNode *prior;
DLNode *next;
}DLinkList;
void DLinkListInit(DLinkList *&L);//��ʼ��˫����
void DLinkListDestroy(DLinkList * L); //˫��������
bool isDLinkListEmpty(DLinkList * L);//�ж������Ƿ�Ϊ��
int DLinkListLength(DLinkList * L); //��˫�����ij���
void DLinkListDisplay(DLinkList * L); //���˫����
DataType DLinkListGetElem(DLinkList * L, int i); //��ȡ��i��λ�õ�Ԫ��
bool DLinkListInsert(DLinkList * &L, int i, DataType e);//�ڵ�i��λ�ò���Ԫ��e
DataType DLinkListDelete(DLinkList * &L, int i);//ɾ����i��λ���ϵ�ֵ,��������ֵ
#endif#include<iostream>
#include"DLinkList.h"
using namespace std;
void DLinkListInit(DLinkList *&L)//��ʼ��˫����
{
L = (DLinkList *)malloc(sizeof(DLinkList)); //����ͷ���
L->prior = L->next = NULL;
}
void DLinkListDestroy(DLinkList * L) //˫��������
{
if (L == NULL)
{
return;
}
DLinkList *p = L, *q = p->next;//���������ڵ�,��һ����ʾ��ǰ�ڵ�,�ڶ�����ʾ�ڶ����ڵ�
while (q != NULL) //���ڶ����ڵ�ָ��null,˵��p�����һ���ڵ�,�������,��
{ //�ͷŵ�p,q��Ϊ��һ���ڵ�,��q����p,p->��q,��������
free(p);
p = q;
q = p->next;
}
free(p);
}
bool isDLinkListEmpty(DLinkList * L)//�ж������Ƿ�Ϊ��
{
return L->next == NULL;
}
int DLinkListLength(DLinkList * L) //��˫�����ij���
{
DLinkList *p = L;
if (L == NULL)
{
return 0;
}
int i = 0;
while (p->next != NULL)
{
i++;
p = p->next;
}
return i;
}
void DLinkListDisplay(DLinkList * L) //���˫����
{
DLinkList *p = L->next; //����ͷ���,ָ���һ���ڵ�
while (p != NULL)
{
cout << p->Elem << " ";
p = p->next;
}
}
DataType DLinkListGetElem(DLinkList * L, int i) //��ȡ��i��λ�õ�Ԫ��
{
DLinkList *p = L;//ָ��ͷ���
if (L == NULL)
{
cout << "Function DLinkListGetElem" << "����Ϊ�ձ�" << endl;
return 0;
}
int j = 0;
while (p != NULL && j < i) //��ָ��ָ���i��λ�ô�
{
j++;
p = p->next;
}
if (p == NULL)
{
return 0;
}
else
{
return p->Elem;
}
}
bool DLinkListInsert(DLinkList * &L, int i, DataType e)//�ڵ�i��λ�ò���Ԫ��e
{
int j = 0;
DLinkList *p = L, *s;//����s�ڵ��DZ�ʾ������Ǹ��ڵ�,����Ҫ���������ڴ�
while (p != NULL && j < i - 1) //����ڵ�ǰ,���ҵ���i-1���ڵ�
{
j++;
p = p->next;
}
if( p == NULL)
{
return 0;
}
else
{
s = (DLinkList *)malloc(sizeof(DLinkList));
s->Elem = e;
s->next = p->next;//������̵�ָ��
if (p->next != NULL)
{
p->next->prior = s; //�����ĺ�̵�ǰ��ָ��
}
s->prior = p; //�����ǰ����ǰ��ָ��
p->next = s; //������ǰ���ĺ��ָ��
}
}
DataType DLinkListDelete(DLinkList * &L, int i)//ɾ����i��λ���ϵ�ֵ,��������ֵ
{
DLinkList *p = L, *s;
int j = 0;
if (L == NULL)
{
cout << "Function DLinkListDelete" << "ɾ������" << endl;
return 0;
}
while (j < i - 1 && p != NULL)
{
j++;
p = p->next;
}
if (p == NULL)
{
return 0;
}
else
{
s = p->next;
if (s == NULL)
{
return 0;
}
DataType e = p->Elem;
p->next = s->next;
if (p->next != NULL)
{
p->next->prior = p;
}
free(s);
return e;
}
}3������
3.1��˳�����
#pragma once
#ifndef SQQUEUE_H
#define SQQUEUE_H
#define MaxSize 50
typedef int DataType;
typedef struct SQueue //����һ���ṹ��,�����������Ͷ�ͷ�Ͷ�β
{
DataType data[MaxSize];
int front, rear; //front��ʾ��ͷ,rear��ʾ��β,���ͷ����β��,����β����ͷ��
}SqQueue;
void SqQueueInit(SqQueue *&Q); //���г�ʼ��
void SqQueueClear(SqQueue *$Q); //��ն���
bool isSqQueueEmpty(SqQueue *Q); //�ж϶��г���
int SqQueueLength(SqQueue *Q); //����еij���
void SqQueueDisplay(SqQueue *Q); //�������
void EnSqQueue(SqQueue *& Q,DataType e); //����
DataType DeSqQueue(SqQueue *& Q); //����
#endif#include<iostream>
#include"SqQueue.h"
using namespace std;
void SqQueueInit(SqQueue *&Q) //���г�ʼ��
{
Q = (SqQueue *)malloc(sizeof(Q));
Q->front = Q->rear = 0;
}
void SqQueueClear(SqQueue *&Q) //��ն���
{
free(Q); //����˳��ջ,ֱ���ͷ��ڴ漴��
}
bool isSqQueueEmpty(SqQueue *Q) //�ж϶��г���
{
return (Q->front == Q->rear);
}
int SqQueueLength(SqQueue *Q) //����еij���
{
return Q->rear - Q->front; //�˴�������
}
void EnSqQueue(SqQueue *& Q,DataType e) //����
{
if (Q == NULL)
{
cout << "�����ڴ�ʧ��!" << endl;
return;
}
if (Q->rear >= MaxSize) //���ǰ���ж����ж�
{
cout << "The Queue is Full!" << endl;
return;
}
Q->rear++;
Q->data[Q->rear] = e;
}
DataType DeSqQueue(SqQueue *& Q) //��ջ
{
if (Q == NULL)
{
return 0;
}
if (Q->front == Q->rear) //����ǰ���пն��ж�
{
cout << "This is an Empty Queue!" << endl;
return 0;
}
Q->front--;
return Q->data[Q->front];
}
void SqQueueDisplay(SqQueue *Q) //�������
{
if (Q == NULL)
{
return;
}
if (Q->front == Q->rear)
{
return;
}
int i = Q->front + 1;
while (i <= Q->rear)
{
cout << Q->data[i] << " ";
i++;
}
}3.2����ʽ����
#pragma once
#ifndef LINKQUEUE_H
#define LINKQUEUE_H
typedef int DataType;
/*
���е���ʽ�洢��,������Ҫָ��ֱ�ָ��
��ͷ�Ͷ�β,�����������ӽڵ������ݽڵ㲻ͬ
���ӽڵ�:��������ָ���ͷ��β��ָ��
���ݽڵ�:һ��ָ����һ�����ݽڵ��ָ�������
*/
//�������ݽڵ�ṹ��
typedef struct qnode
{
DataType Elem;
struct qnode *next;
}QDataNode;
//�������ӽڵ�ṹ��
typedef struct
{
QDataNode *front;
QDataNode *rear;
}LinkQueue;
void LinkQueueInit(LinkQueue *&LQ); //��ʼ������
void LinkQueueClear(LinkQueue *&LQ); //�������
bool isLinkQueueEmpty(LinkQueue *LQ); //�ж������Ƿ�Ϊ��
int LinkQueueLength(LinkQueue *LQ); //�����ӳ���
bool EnLinkQueue(LinkQueue *&LQ,DataType e); //����
DataType DeLinkQueue(LinkQueue *&LQ); //����
#endif#include<iostream>
#include"LinkQueue.h"
using namespace std;
void LinkQueueInit(LinkQueue *&LQ) //��ʼ������
{
LQ = (LinkQueue*)malloc(sizeof(LQ));
LQ->front = LQ->rear = NULL;
}
void LinkQueueClear(LinkQueue *&LQ) //�������,��ն��е�һ��:�������ݽڵ�
// �ڶ���:�������ӽڵ�
{
QDataNode *p = LQ->front, *r;
if (p != NULL)
{
r = p->next;
while (r != NULL)
{
free(p);
p = r;
r = p->next;
}
}
free(LQ);
}
bool isLinkQueueEmpty(LinkQueue *LQ) //�ж������Ƿ�Ϊ��
{
return LQ->rear == NULL; //1:�ǿ�;0:��
}
int LinkQueueLength(LinkQueue *LQ) //�����ӳ���
{
QDataNode *p = LQ->front;
int i = 0;
while (p != NULL)
{
i++;
p = p->next;
}
return i;
}
bool EnLinkQueue(LinkQueue *&LQ, DataType e) //����
{
QDataNode *p;
if (LQ == NULL)
{
return 0;
}
p = (QDataNode*)malloc(sizeof(QDataNode));
p->Elem = e;
p->next = NULL; //β�巨
if (LQ->front == NULL)//��������л�û������ʱ
{
LQ->front = LQ->rear = p; //pΪ��ͷҲΪ��β
}
else
{
LQ->rear->next = p;
LQ->rear = p;
}
}
DataType DeLinkQueue(LinkQueue *&LQ) //����
{
QDataNode *p;
DataType e;
if (LQ->rear == NULL)
{
cout << "This is an Empty queue!" << endl;
return 0;
}
if (LQ->front == LQ->rear)
{
p = LQ->front;
LQ->rear = LQ->front = NULL;
}
else
{
p = LQ->front;
LQ->front = p->next;
e = p->Elem;
}
free(p);
return e;
}4��ջ
4.1��˳��ջ
#pragma once
#ifndef SQSTACK_H
#define SQSTACK_H
#define MaxSize 50//����ʵ��������ô�С
typedef int DataType;
//˳��ջҲ��һ�������˳���,����һ��
//�ṹ��,�������һ������,�洢����
//˳��ջ��ʵ�ǽ�������нṹ���װ
typedef struct Stack
{
DataType Elem[MaxSize];
int top; //ջָ��
}SqStack;
void SqStackInit(SqStack *&S); //��ʼ��ջ
void SqStackClear(SqStack *&S); //���ջ
int SqStackLength(SqStack *S); //��ջ�ij���
bool isSqStackEmpty(SqStack *S); //�ж�ջ�Ƿ�Ϊ��
void SqStackDisplay(SqStack *S); //���ջԪ��
bool SqStackPush(SqStack *&S, DataType e);//Ԫ��e��ջ
DataType SqStackPop(SqStack *&S);//��ջһ��Ԫ��
DataType SqStackGetPop(SqStack *S);//ȡջ��Ԫ��
#endif#include<iostream>
#include"SqStack.h"
using namespace std;
void SqStackInit(SqStack *&S) //��ʼ��ջ
{
S = (SqStack*)malloc(sizeof(SqStack)); //�����ڴ�,����ջ
S->top = -1;
}
void SqStackClear(SqStack *&S) //���ջ
{
free(S);
}
int SqStackLength(SqStack *S) //��ջ�ij���
{
return S->top + 1;
}
bool isSqStackEmpty(SqStack *S) //�ж�ջ�Ƿ�Ϊ��
{
return (S->top == -1);
}
void SqStackDisplay(SqStack *S) //���ջԪ��
{
for (int i = S->top; i > -1; i--)
{
cout << S->Elem[i] << " ";
}
}
bool SqStackPush(SqStack *&S, DataType e)//Ԫ��e��ջ
{
if ( S->top == MaxSize - 1)
{
cout << "The Stack Full!" << endl; //��ջ�ж�
return 0;
}
S->top++;
S->Elem[S->top] = e;
return 1;
}
DataType SqStackPop(SqStack *&S)//��ջһ��Ԫ��
{
DataType e;
if(S->top== -1) //��ջ�ж�
{
cout << "The Stack is Empty!" << endl;
return 0;
}
e = S->Elem[S->top];//��ջԪ�ش洢
S->top--;
return e;
}
DataType SqStackGetPop(SqStack *S)//ȡջ��Ԫ��
{
if (S->top == -1) //��ջ�ж�
{
cout << "The Stack is Empty" << endl;
return 0;
}
return S->Elem[S->top];
}4.2����ʽջ
#pragma once
#ifndef LINKSTACK_H
#define LINKSTACK_H
typedef int DataType;
typedef struct LinkNode //��ʽջ�Ľ�㶨��������Ľ�㶨����һ����
{
DataType Elem; //������
struct LinkNode *next; //ָ����
}LinkStack;
void LinkStackInit(LinkStack *& S); //��ʼ���б�
void LinkStackClear(LinkStack*&S); //���ջ
int LinkStackLength(LinkStack * S); //�������ij���
bool isLinkStackEmpty(LinkStack *S); //�ж������Ƿ�Ϊ��
bool LinkStackPush(LinkStack *S, DataType e);//Ԫ��e��ջ
DataType LinkStackPop(LinkStack *S); //��ջ
DataType LinkStackGetPop(LinkStack *S); //���ջ��Ԫ��
void LinkStackDisplay(LinkStack *S); //���ϵ������ջ����Ԫ��
#endif#include<iostream>
#include"LinkStack.h"
using namespace std;
void LinkStackInit(LinkStack *& S) //��ʼ���б�
{
S = (LinkStack *)malloc(sizeof(LinkStack)); //�����ڴ�
S->next = NULL;
}
void LinkStackClear(LinkStack*&S) //���ջ
{
LinkStack *p = S,*q = S->next;
if (S == NULL)
{
return;
}
while (p != NULL) //ע��:�������е㲻ͬ,���������ڵ�,һ����ǰ�ڵ�,һ����һ���ڵ�
{
free(p);
p = q;
q = p->next;
}
}
int LinkStackLength(LinkStack * S)//�������ij���
{
int i = 0;
LinkStack *p = S->next; //����ͷ���
while (p != NULL)
{
i++;
p = p->next;
}
return i;
}
bool isLinkStackEmpty(LinkStack *S)//�ж������Ƿ�Ϊ��
{
return S->next == NULL; //1:��;0:�ǿ�
}
bool LinkStackPush(LinkStack *S, DataType e)//Ԫ��e��ջ
{
LinkStack *p;
p = (LinkStack*)malloc(sizeof(LinkStack)); //�������
if (p == NULL)
{
return 0;
}
p->Elem = e; //��Ԫ�ظ�ֵ
p->next = S->next; //���½�����p->nextָ��ԭ����ջ��Ԫ��
S->next = p; //������ջ����ʼ��ָ���½����
return 1;
}
DataType LinkStackPop(LinkStack *S)//��ջ
{
LinkStack *p;
DataType e;
if (S->next == NULL)
{
cout << "The Stack is Empty!" << endl;
return 0;
}
p = S->next; //����ͷ���
e = p->Elem;
S->next = p->next;
return e;
}
DataType LinkStackGetPop(LinkStack *S)//���ջ��Ԫ��
{
if (S->next == NULL)
{
cout << "The Stack is Empty!" << endl;
return 0;
}
return S->next->Elem; //ͷ���
}
void LinkStackDisplay(LinkStack *S)//���ϵ������ջ����Ԫ��
{
LinkStack *p = S->next;
while(p != NULL)
{
cout << p->Elem << " ";
p = p->next;
}
cout << endl;
}5��������
5.1������������ʽ�洢
#pragma once
#ifndef LINKBTREE_H
#define LINKBTREE_H
#define MaxSize 100 //�������
typedef char DataType;
typedef struct BTNode //����һ���������ڵ�
{
DataType Elem;
BTNode *Lchild;
BTNode *Rchild;
}LinkBTree;
void LinkBTreeCreate(LinkBTree *& BT, char *str);//��str����������
LinkBTree* LinkBTreeFindNode(LinkBTree * BT, DataType e); //����e��ָ��
LinkBTree *LinkBTreeLchild(LinkBTree *p);//����*p�ڵ�����ӽڵ�ָ��
LinkBTree* LinkBTreeRight(LinkBTree *p);//����*p�ڵ���Һ��ӽڵ�ָ��
int LinkBTreeDepth(LinkBTree *BT);//������������
void LinkBTreeDisplay(LinkBTree * BT);//�����ŷ����������
int LinkBTreeWidth(LinkBTree *BT);//��������Ŀ���
int LinkBTreeNodes(LinkBTree * BT);//��ڵ����
int LinkBTreeLeafNodes(LinkBTree *BT);//���������Ҷ�ӽڵ����
void LinkBTreeProOeder(LinkBTree *BT); //ǰ��ݹ����
void LinkBTreeProOederRecursion(LinkBTree *BT);//ǰ��ǵݹ����
void LinkBTreeInOeder(LinkBTree *BT);//����ݹ����
void LinkBTreeInOederRecursion(LinkBTree *BT);//����ǵݹ����
void LinkBTreePostOeder(LinkBTree *BT);//����ݹ����
void LinkBTreePostOederRecursion(LinkBTree *BT);//����ǵݹ����
#endif#include<iostream>
#include"LinkBTree.h"
using namespace std;
void LinkBTreeCreate(LinkBTree *& BT, char *str)//��str����������
{
LinkBTree *St[MaxSize], *p = NULL;
int top = -1, k, j = 0;
char ch;
BT = NULL;
ch = str[j];
while (ch != '\0')
{
switch (ch)
{
case '(':top++; St[top] = p; k = 1; break;//Ϊ��ڵ�,top��ʾ����,k��ʾ���ҽڵ�,����һ��'('��������һ��,����һ��',',���������
case ')':top--; break;
case ',':k = 2; break; //Ϊ�ҽڵ�
default: p = (LinkBTree *)malloc(sizeof(LinkBTree));
p->Elem = ch;
p->Lchild = p->Rchild = NULL;
if (BT == NULL)
{
BT = p; //���ڵ�
}
else
{
switch (k)
{
case 1:St[top]->Lchild = p; break;
case 2:St[top]->Rchild = p; break;
}
}
}
j++;
ch = str[j];
}
}
LinkBTree *LinkBTreeFindNode(LinkBTree * BT, DataType e) //����Ԫ��e��ָ��
{
LinkBTree *p;
if (BT == NULL)
{
return NULL;
}
else if (BT->Elem == e)
{
return BT;
}
else
{
p = LinkBTreeFindNode(BT->Lchild, e); //�ݹ�
if (p != NULL)
{
return p;
}
else
{
return LinkBTreeFindNode(BT->Lchild, e);
}
}
}
LinkBTree *LinkBTreeLchild(LinkBTree *p)//����*p�ڵ�����ӽڵ�ָ��
{
return p->Lchild;
}
LinkBTree *LinkBTreeRight(LinkBTree *p)//����*p�ڵ���Һ��ӽڵ�ָ��{
{
return p->Rchild;
}
int LinkBTreeDepth(LinkBTree *BT)//������������
{
int LchildDep, RchildDep;
if (BT == NULL)
{
return 0;
}
else
{
LchildDep = LinkBTreeDepth(BT->Lchild);
RchildDep = LinkBTreeDepth(BT->Rchild);
}
return (LchildDep > RchildDep) ? (LchildDep + 1) : (RchildDep + 1);
}
void LinkBTreeDisplay(LinkBTree * BT)//�����ŷ����������
{
if (BT != NULL)
{
cout << BT->Elem;
if (BT->Lchild != NULL || BT->Rchild != NULL)
{
cout << '(';
LinkBTreeDisplay(BT->Lchild);
if (BT->Rchild != NULL)
{
cout << ',';
}
LinkBTreeDisplay(BT->Rchild);
cout << ')';
}
}
}
int LinkBTreeWidth(LinkBTree *BT)//��������Ŀ���
{
return 0;
}
int LinkBTreeNodes(LinkBTree * BT)//��ڵ����
{
if (BT == NULL)
{
return 0;
}
else if (BT->Lchild == NULL && BT->Rchild == NULL) //ΪҶ�ӽڵ�����
{
return 1;
}
else
{
return (LinkBTreeNodes(BT->Lchild) + LinkBTreeNodes(BT->Rchild) + 1);
}
}
int LinkBTreeLeafNodes(LinkBTree *BT)//���������Ҷ�ӽڵ����
{
if (BT == NULL)
{
return 0;
}
else if (BT->Lchild == NULL && BT->Rchild == NULL) //ΪҶ�ӽڵ�����
{
return 1;
}
else
{
return (LinkBTreeLeafNodes(BT->Lchild) + LinkBTreeLeafNodes(BT->Rchild));
}
}
void LinkBTreeProOeder(LinkBTree *BT) //ǰ��ǵݹ����
{
LinkBTree *St[MaxSize], *p;
int top = -1;
if (BT != NULL)
{
top++;
St[top] = BT; //����һ��ָ����ڵ�
while (top > -1)
{
p = St[top]; //��һ��
top--; //��ջ�����ʸýڵ�
cout << p->Elem << " ";
if (p->Rchild != NULL)
{
top++;
St[top] = p->Rchild;
}
if (p->Lchild != NULL)
{
top++;
St[top] = p->Lchild;
}
}
cout << endl;
}
}
void LinkBTreeProOederRecursion(LinkBTree *BT)//ǰ��ݹ����
{
if (BT != NULL)
{
cout << BT->Elem<<" ";
LinkBTreeProOeder(BT->Lchild);
LinkBTreeProOeder(BT->Rchild);
}
}
void LinkBTreeInOeder(LinkBTree *BT)//����ǵݹ����
{
LinkBTree *St[MaxSize], *p;
int top = -1;
if (BT != NULL)
{
p = BT;
while (top > -1 || p != NULL)
{
while (p != NULL)
{
top++;
St[top] = p;
p = p->Lchild;
}
if (top> -1)
{
p = St[top];
top--;
cout << p->Elem <<" ";
p = p->Rchild;
}
}
cout << endl;
}
}
void LinkBTreeInOederRecursion(LinkBTree *BT)//����ݹ����
{
if (BT != NULL)
{
LinkBTreeProOeder(BT->Lchild);
cout << BT->Elem << " ";
LinkBTreeProOeder(BT->Rchild);
}
}
void LinkBTreePostOeder(LinkBTree *BT)//����ǵݹ����
{
LinkBTree *St[MaxSize], *p;
int top = -1,flag;
if (BT != NULL)
{
do
{
while (BT != NULL)
{
top++;
St[top] = BT;
BT = BT->Lchild;
}
p = NULL;
flag = 1;
while (top != -1 && flag)
{
BT = St[top];
if (BT->Rchild == p)
{
cout << BT->Elem << " ";
top--;
p = BT;
}
else
{
BT = BT->Lchild;
flag = 0;
}
}
} while (top != -1);
cout << endl;
}
}
void LinkBTreePostOederRecursion(LinkBTree *BT)//����ݹ����
{
if (BT != NULL)
{
LinkBTreeProOeder(BT->Lchild);
LinkBTreeProOeder(BT->Rchild);
cout << BT->Elem << " ";
}
}5.2����������
������Ӧ����,���������еĽڵ㸽��һ������ij���������ֵ,�ƴ���ֵΪ�ýڵ��Ȩ,�������ڵ㵽�ýڵ��·��������ýڵ�Ȩֵ֮����Ϊ��Ȩ·�����ȡ���������Ҷ�ӽڵ�Ĵ�Ȩ·������֮�ͳ�Ϊ�����Ĵ�Ȩ·������,����:
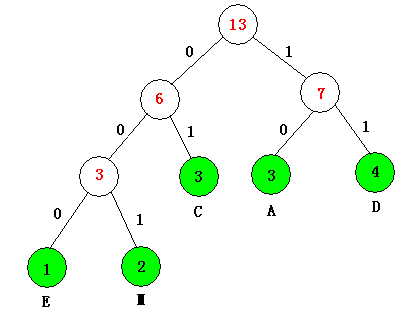
?���й���n��Ҷ�ӽڵ����Ŀ,Wi��ʾҶ�ӽڵ�i��Ȩֵ,Li��ʾ���ڵ㵽Ҷ�ӽڵ��·�����ȡ�
��n������Ȩֵ��㹹�ɵĶ�������,��Ȩ·������WPL��С�Ķ�������Ϊ�����������ֳ����Ŷ�������
���������㷨:
(1)���ݸ�����n��Ȩֵ,ʹ��Ӧ�ڵ㹹��n�Ŷ�������ɭ��T,����ÿ�Ŷ������ж�ֻ��һ����Ȩֵ��Wi�ĸ��ڵ�,�����ҽڵ��Ϊ��
(2)��ɭ����ѡȡ���Ÿ��ڵ�Ȩֵ��С�������ֱ���Ϊ������������һ���¶�����,�����µĶ������ĸ��ڵ��ȨֵΪ�����������ϸ��ڵ��Ȩֵ֮�͡�
(3)��ɭ����,���µõ��Ķ���������ѡȡ��������
(4)�ظ�(2)��(3),ֱ��Tֻ��һ����Ϊֹ
����:���ھ���n��Ҷ�ӽڵ�Ĺ�������,����2n-1���ڵ�
��������:
#pragma once
typedef double Wi; //����ȨֵΪ˫����
struct HTNode //ÿһ���ڵ�Ľṹ����,
{
Wi weight; //�ڵ��Ȩֵ
HTNode *left; //������
HTNode *right; //������
};
void PrintHuffman(HTNode * HuffmanTree); //�����������
HTNode * CreateHuffman(Wi a[], int n); //������������#include"Huffman.h"
#include<iostream>
/*
�������㷨:
(1)���ݸ�����n��Ȩֵ����n����������ɭ��,����n��������������������Ϊ��
(2)��ɭ����ѡ��Ȩֵ��С������Ϊ������������һ������,���ڵ�
ΪȨֵ��С��֮��
(3)��ɭ����,���µ�������ѡȡ��������
(4)�ظ�(2)��(3)
����:n��Ҷ�ӽڵ�Ĺ�����������2n-1���ڵ�
*/
/*
a[] I ��ŵ���Ҷ�ӽڵ��Ȩֵ
n I Ҷ�ӽڵ����
return O ����һ�ù�������
*/
HTNode* CreateHuffman(Wi a[], int n) //������������
{
int i, j;
HTNode **Tree, *HuffmanTree; //����n��Ȩֵ����n����������ɭ��,����ָ���ʾɭ��(�������ļ���)
Tree = (HTNode**)malloc(n * sizeof(HTNode)); //����n��Ҷ�ڵ�,Ϊn���������ڴ�ռ�
HuffmanTree = (HTNode*)malloc(sizeof(HTNode));
//ʵ�ֵ�һ��:����n�ö�����,��������Ϊ��
for (i = 0; i < n; i++)
{
Tree[i] = (HTNode*)malloc(sizeof(HTNode));
Tree[i]->weight = a[i];
Tree[i]->left = Tree[i]->right = nullptr;
}
//���IJ�:�ظ��ڶ��͵�����
for (i = 1; i < n; i++) //z�����ʾ��i������
{
//�ڶ���:����Ȩֵ��С�ĸ��ڵ�������±�Ϊ��һ���͵ڶ���
//����̨ѡ����С���������ڵ���
int k1 = 0, k2 = 1;
for (j = k2; j < n; j++)
{
if (Tree[j] != NULL)
{
if (Tree[j]->weight < Tree[k1]->weight) //��ʾj��k1��k2��Ȩֵ��С,�������ֵ����Ҫ����
{
k2 = k1;
k1 = j;
}
else if(Tree[j]->weight < Tree[k2]->weight) //k1 < j < k2,��Ҫ����k2����
{
k2 = j;
}
}
}
//������:һ��ѡ�������,������һ����
HuffmanTree = (HTNode*)malloc(sizeof(HTNode)); //ÿ��һ�ֽ���,����һ�����ڵ�
HuffmanTree->weight = Tree[k1]->weight + Tree[k2]->weight; //���º�ĸ��ڵ�ȨֵΪ��������Ȩֵ֮��
HuffmanTree->left = Tree[k1]; //��Сֵ��Ϊ������
HuffmanTree->right = Tree[k2]; //�ڶ�С��Ϊ������
Tree[k1] = HuffmanTree;
Tree[k2] = nullptr;
}
free(Tree);
return HuffmanTree;
}
//���������������
void PrintHuffman(HTNode * HuffmanTree) //�����������
{
if (HuffmanTree == nullptr)
{
return;
}
std::cout << HuffmanTree->weight;
if (HuffmanTree->left != nullptr || HuffmanTree->right != nullptr)
{
std::cout << "(";
PrintHuffman(HuffmanTree->left);
if (HuffmanTree->right != nullptr)
{
std::cout << ",";
}
PrintHuffman(HuffmanTree->right);
std::cout << ")";
}
}6�������㷨
6.1�����Ա�����(˳����ҡ��۰����)
˳�����
#include<iostream>
using namespace std;
#define Max 100
typedef int KeyType;
typedef char InfoType[10];
typedef struct
{
KeyType key; //��ʾλ��
InfoType data; //data�Ǿ���10��Ԫ�ص�char����
}NodeType;
typedef NodeType SeqList[Max]; //SeqList�Ǿ���Max��Ԫ�صĽṹ������
int SeqSearch(SeqList R, int n, KeyType k)
{
int i = 0;
while (i < n && R[i].key != k)
{
cout << R[i].key;//������ҹ���Ԫ��
i++;
}
if (i >= n)
{
return -1;
}
else
{
cout << R[i].key << endl;
return i;
}
}
int main()
{
SeqList R;
int n = 10;
KeyType k = 5;
int a[] = { 3,6,8,4,5,6,7,2,3,10 },i;
for (int i = 0; i < n; i++)
{
R[i].key = a[i];
}
cout << endl;
if ((i = SeqSearch(R, n, k)) != -1)
cout << "Ԫ��" << k << "��λ����" << i << endl;
system("pause");
return 0;
}�۰����
#include<iostream>
using namespace std;
#define Max 100
typedef int KeyType;
typedef char InfoType[10];
typedef struct
{
KeyType key;
InfoType data;
}NodeType;
typedef NodeType SeqList[Max];
int BinSeqList(SeqList R, int n, KeyType k)
{
int low = 0, high = n - 1, mid, cout = 0;
while (low <= high)
{
mid = (low + high) / 2;
//cout << "��" << ++cout << "�β���:" << "��" << "[" << low << "," << high << "]" << "�в��ҵ�Ԫ��:" << R[mid].key << endl;
if (R[mid].key == k)
{
return mid;
}
if (R[mid].key > k)
high = mid - 1;
else
low = mid + 1;
}
}
int main()
{
SeqList R;
KeyType k = 9;
int a[] = { 1,2,3,4,5,6,7,8,9,10 },i,n = 10;
for (i = 0; i < n; i++)
{
R[i].key = a[i];
}
cout << endl;
if ((i = BinSeqList(R, n, k)) != -1)
{
cout << "Ԫ��" << k << "��λ����:" << i << endl;
}
system("pause");
return 0;
}6.2����������(������������ƽ���������B-����B+��)
����������(B��)
#pragma once
#ifndef BSTREE_H
#define BSTREE_H
#define Max 100
typedef int KeyType;
typedef char InfoType[10];
typedef struct node
{
KeyType key; //�ؼ�����
InfoType data; //����������
struct node *Lchild, *Rchild;
}BSTNode;
BSTNode *BSTreeCreat(KeyType A[], int n); //������A(����n���ؼ���)�еĹؼ��ִ���һ������������
int BSTreeInsert(BSTNode *& BST, KeyType k); //����*BSTΪ���ڵ�Ķ����������в���һ���ؼ���Ϊk�Ľ��
int BSTreeDelete(BSTNode *& BST, KeyType k); //��bst��ɾ���ؼ���Ϊk�Ľ��
void BSTreeDisplay(BSTNode * BST); //�����ŷ��������������
int BSTreeJudge(BSTNode * BST); //�ж�BST�Ƿ�Ϊ����������
#endif#include<iostream>
#include"BSTree.h"
using namespace std;
BSTNode *BSTreeCreat(KeyType A[], int n) //������A(����n���ؼ���)�еĹؼ��ִ���һ������������
{
BSTNode *BST = NULL;
int i = 0;
while (i < n)
{
if(BSTreeInsert(BST,A[i]) == 1)
{
cout << "��" << i + 1 << "��,����" << A[i] << endl;
BSTreeDisplay(BST);
cout << endl;
i++;
}
}
return BST;
}
int BSTreeInsert(BSTNode *& BST, KeyType k) //����*BSTΪ���ڵ�Ķ����������в���һ���ؼ���Ϊk�Ľ��
{
if (BST == NULL)
{
BST = (BSTNode *)malloc(sizeof(BSTNode));
BST->key = k;
BST->Lchild = BST->Rchild = NULL;
return 1;
}
else if(k == BST->key)
{
return 0;
}
else if(k > BST->key)
{
return BSTreeInsert(BST->Rchild, k);
}
else
{
return BSTreeInsert(BST->Lchild, k);
}
}
int BSTreeDelete(BSTNode *& BST, KeyType k) //��bst��ɾ���ؼ���Ϊk�Ľ��
{
if (BST == NULL)
{
return 0;
}
else
{
if (k < BST->key)
{
return BSTreeDelete(BST->Lchild, k);
}
else if (k>BST->key)
{
return BSTreeDelete(BST->Rchild, k);
}
else
{
Delete(BST)
}
}
}
void BSTreeDisplay(BSTNode * BST) //�����ŷ��������������
{
if (BST != NULL)
{
cout << BST->key;
if (BST->Lchild != NULL || BST->Rchild != NULL)
{
cout << '(';
BSTreeDisplay(BST->Lchild);
if (BST->Rchild != NULL)
{
cout << ',';
}
BSTreeDisplay(BST->Rchild);
cout << ')';
}
}
}
KeyType predt = -32767;
int BSTreeJudge(BSTNode * BST) //�ж�BST�Ƿ�Ϊ����������
{
int b1, b2;
if (BST == NULL)
{
return 1;
}
else
{
b1 = BSTreeJudge(BST->Lchild);
if (b1 == 0 || predt >= BST->key)
{
return 0;
}
predt = BST->key;
b2 = BSTreeJudge(BST->Rchild);
return b2;
}
}
void Delete(BSTNode*& p) //ɾ������������*p�ڵ�
{
BSTNode* q;
if (p->Rchild == nullptr) //��ɾ���Ľڵ�û��������,ֻ��������ʱ,���ݶ��������ص�,
{ //ֱ�ӽ����������ڵ���ڱ�ɾ�ڵ��λ�á�
q = p;
p = p->Lchild;
free(p);
}
else if (p->Lchild == nullptr) //��ɾ���Ľ��û��������,ֻ��������ʱ,���ݶ��������ص�,
{ //ֱ�ӽ������������ڱ�ɾ���λ�á�
q = p;
p = p->Rchild;
free(p);
}
else
{
Delete1(p, p->Lchild); //����ɾ���������������ʱ
}
}
void Delete1(BSTNode* p, BSTNode* &r) //��ɾ���Ķ���������*P�ڵ�������������ɾ������
{
BSTNode *q;
if (p->Lchild != nullptr)
{
Delete1(p, p->Rchild); //�ݹ�Ѱ�������½ڵ�
} //�ҵ��������½ڵ�*r
else //��*r�Ĺؼ��ָ�ֵ��*p
{
p->key = r->key;
q = r;
r = r->Lchild;
free(q);
}
}ƽ�������:��һ�ö������е�ÿ���ڵ�����������߶��������1,��ƴ˶�����Ϊƽ�������������ƽ�����ӵĶ���Ϊ:ƽ���������ÿ���ڵ���һ��ƽ������,ÿ���ڵ��ƽ�������Ǹýڵ��������߶ȼ�ȥ�������ĸ߶�,��ÿ��ƽ�����ӵ�ȡֵΪ0,-1,1�����Ϊƽ���������
B-��
�����ⲿ���ҵ����ݽṹ,���е����ݴ���������,��һ�ֶ�·��������
1�����е�Ҷ�ӽڵ����ͬһ��,���Ҳ�����Ϣ
2������ÿ���ڵ�������m������
3�������ڵ㲻���ն˽ڵ�,����ڵ���������������
4�������ڵ���ķ�Ҷ�ӽڵ�������m/2������
5��ÿ���ڵ����ٴ��m/2-1������m-1���ؼ���
6����Ҷ�ӽڵ�Ĺؼ�����=ָ�����ָ��ĸ���-1
7����Ҷ�ӽڵ�Ĺؼ������ε���
8����Ҷ�ӽڵ�ָ��:P[1],P[2],...P[m];����P[i]ָ��ؼ���С��K[1]������,P[i]ָ��ؼ�������(K[i-1],K[i])������
6.3����ϣ������
�Ӹ�����˵,һ����ϣ������һ������,ͨ�����������ֵ(��)�����������е�Ԫ�ء�
��ϣ������Ҫ˼����ͨ��һ����ϣ����,�����п��ܵļ����λ֮�佨��һ��ӳ�������ϣ����ÿ�ν���һ���������������Ӧ�Ĺ�ϣ������߹�ϣֵ�������������Ϳ��ܶ��ֶ���,����ϣֵֻ�������͡�
�����ϣֵ���������н���������ֻ���Ĺ̶���ʱ��,��˹�ϣ�������������������һ������ʱ���ڳ������ļ�������������ϣ�����ܹ���֤��ͬ�ļ����ɵĹ�ϣֵ������ͬʱ,��˵��ϣֵ��ֱ��Ѱַ��Ҫ�Ľ����
ɢ�б�(Hash table,Ҳ�й�ϣ��),�Ǹ��ݹؼ���ֵ(Key value)��ֱ�ӽ��з��ʵ����ݽṹ��Ҳ����˵,��ͨ���ѹؼ���ֵӳ�䵽����һ��λ�������ʼ�¼,�Լӿ���ҵ��ٶȡ����ӳ�亯������ɢ�к���,��ż�¼����������ɢ�б���
������M,���ں���f(key),����������Ĺؼ���ֵkey,���뺯�������ܵõ������ùؼ��ֵļ�¼�ڱ��еĵ�ַ,��Ʊ�MΪ��ϣ(Hash)��,����f(key)Ϊ��ϣ(Hash) ������
ɢ�к�����ʹ��һ���������еķ��ʹ��̸���Ѹ����Ч,ͨ��ɢ�к���,����Ԫ�ؽ�������ض�λ��
ʵ�ʹ��������Ӳ�ͬ��������ò�ͬ�Ĺ�ϣ����,ͨ�����ǵ�������:
- �����ϣ��������ʱ��
- �ؼ��ֵij���
- ��ϣ���Ĵ�С
- �ؼ��ֵķֲ����
- ��¼�IJ���Ƶ��
1. ֱ��Ѱַ��:ȡ�ؼ��ֻ�ؼ��ֵ�ij�����Ժ���ֵΪɢ�е�ַ����H(key)=key��H(key) = a��key + b,����a��bΪ����(����ɢ�к���������������)��������H(key)���Ѿ���ֵ��,������һ����,ֱ��H(key)��û��ֵ��,�ͷŽ�ȥ�����ֹ�ϣ���������,���Ҳ������г�ͻ����,���ؼ�������ʱ,����ֱ��Ѱַ��;����ؼ��ֵIJ�����������ڴ浥Ԫ�Ĵ����˷ѡ�
2. ���ַ�����:����һ������,����һ��Ա���ij���������,��ʱ���Ƿ��ֳ��������յ�ǰ��λ���ִ�����ͬ,�����Ļ�,���ֳ�ͻ�ļ��ʾͻ�ܴ�,�������Ƿ��������յĺ�λ��ʾ�·ݺ;������ڵ����ֲ��ܴ�,����ú��������������ɢ�е�ַ,���ͻ�ļ��ʻ����Խ��͡�������ַ����������ҳ����ֵĹ���,������������Щ�����������ͻ���ʽϵ͵�ɢ�е�ַ��
3. ƽ��ȡ�з�:����ȷ���ؼ������ļ�λ�ֲ��Ͼ���ʱ,����������ؼ��ֵ�ƽ��ֵ,Ȼ����Ҫȡƽ��ֵ���м伸λ��Ϊ��ϣ��ַ��������Ϊ:ƽ�����м伸λ�ؼ�����ÿһλ�����,�ʲ�ͬ�ؼ��ֻ��Խϸߵĸ��ʲ�����ͬ�Ĺ�ϣ��ַ��
4������ȡ�෨:�ùؼ���k����ij�������ڹ�ϣ������m����p,�����õ�������Ϊ��ϣ��ַ�ķ�����h(k) = k mod p,����pȡ������m���������
#pragma once
#define MaxSize 20 //�˴���ʾ��ϣ������m
#define NULLKEY -1 //��ʾ�ýڵ�Ϊ�սڵ�,δ�������
#define DELEKEY -2 //��ʾ�ýڵ����ݱ�ɾ��,
typedef int Key; //�ؼ�������
typedef struct
{
Key key; //�ؼ���ֵ
int count; //̽�����
}HashTable[MaxSize];
void HTInsert(HashTable HT,int &n,Key k,int p); //���ؼ��ֲ����ϣ����
void HTCreate(HashTable HT, Key x[], int n, int m, int p); //������ϣ��
int HTSearch(HashTable HT, int p, Key k); //�ڹ�ϣ���в��ҹؼ���
int HTDelete(HashTable HT, int p, Key k, int &n); //ɾ����ϣ���йؼ���k
void HTDisplay(HashTable HT,int n,int m);#include"HT.h"
#include<iostream>
/*�����ͻ�ÿ���ַ������̽�鷨*/
void HTInsert(HashTable HT, int &n, Key k, int p) //���ؼ���k�����ϣ����
{
int i,addr; //i:��¼̽����;adddr:��¼��ϣ���±�
addr = k % p;
if (HT[addr].key == NULLKEY || HT[addr].key == DELEKEY) //��ʾ�ó�Ϊ��,���Դ洢ֵ
{
HT[addr].key = k;
HT[addr].count = 1;
}
else //��ʾ���ڹ�ϣ��ͻ
{
i = 1;
do
{
addr = (addr + 1) % p; //��ϣ��ͻ����취:����ַ���е�����̽�鷨,�ӵ�ǰ��ͻ��ַ��ʼ���������Ų�
i++;
} while (HT[addr].key != NULLKEY || HT[addr].key != DELEKEY);
}
n++;//��ʾ����һ��Ԫ�غ��ϣ�����洢��Ԫ������
}
/*
HT I/O ��ϣ��
x[] I �ؼ�������
n I �ؼ��ָ���
m I ��ϣ������
p I ΪС��m����p,ȡ������m���������
*/
void HTCreate(HashTable HT, Key x[], int n, int m, int p)//������ϣ��
{
for (int i = 0; i < m; i++) //����һ���յĹ�ϣ��
{
HT[i].key = NULLKEY;
HT[i].count = 0;
}
int n1 = 0;
for (int i = 0; i < n; i++)
{
HTInsert(HT, n1, x[i], p);
}
}
int HTSearch(HashTable HT, int p, Key k) //�ڹ�ϣ���в��ҹؼ���
{
int addr; //��������ؼ���k�ڹ�ϣ���е��±�
addr = k % p;
while(HT[addr].key != NULLKEY || HT[addr].key != k)
{
addr = (addr + 1) % p; //�����Ź�ϣ��ͻ
}
if (HT[addr].key == k)
return addr;
else
return -1;
}
/*
ע:ɾ������������ɾ��,���DZ��
*/
int HTDelete(HashTable HT, int p, Key k, int &n)//ɾ����ϣ���йؼ���k
{
int addr;
addr = HTSearch(HT, p, k);
if (addr != -1)
{
HT[addr].key = DELEKEY;
n--;
return 1;
}
else
{
return 0;
}
}
void HTDisplay(HashTable HT, int n, int m) //�����ϣ��
{
std::cout << " �±�:";
for (int i = 0; i < m; i++)
{
std::cout<< i << " ";
}
std::cout << std::endl;
std::cout << " �ؼ���:";
for (int i = 0; i < m; i++)
{
std::cout << HT[i].key << " ";
}
std::cout << std::endl;
std::cout << "̽�����:";
for (int i = 0; i < m; i++)
{
std::cout << HT[i].key << " ";
}
std::cout << std::endl;
}7�������㷨
7.1��ֱ�Ӳ�������
//������˳�����ֱ�Ӳ�������
/*
����������Ԫ�ش��������R[0...n-1]��,��������е�ijһʱ��
R������Ϊ����������R[0..i-1]��R[i..n-1],����,ǰһ��������
�����ź������������,��һ������δ����ֱ�Ӳ��������һ�˲�
���ǽ���ǰ��������Ŀ�ͷԪ��R[i]���뵽��������R[0..i-1]���ʵ�
��λ����,ʹR[0..i]����µ�����
*/
void InsertSort(RecType R[], int n)
{
int i, j, k;
RecType temp;
for (i = 1; i < n; i++)
{
temp = R[i]; //
j = i - 1;
while (j>=0 && temp.key <R[j].key) //�����������ֵ����������С,��������ֵ����Ų
{
R[j + 1] = R[j];
j--;
}
R[j + 1] = temp;
cout << "i:" << i << " ";
for (k = 0; k < n; k++)
{
cout << R[k].key << " ";
}
cout << endl;
}
}7.2���۰��������
7.3��ϣ������
//ϣ������
/*
��ȡ��һ��С��n������d1��Ϊ��һ������,
�ѱ���ȫ��Ԫ�طֳ�d1����,�����֮��
����Ϊd1�ı�����Ԫ�ط���ͬһ������,��
�����ڽ���ֱ�Ӳ�������;Ȼ��,ȡ�ڶ���
����d2,�ظ������ķ�����̺��������,
ֱ����ȡ������dt=1,������Ԫ�ط���ͬһ
���н���ֱ�Ӳ�������
*/
void ShellInsert(RecType R[], int n)
{
int i, j, d,k;
RecType temp;
d = n / 2;
while (d > 0)
{
for (i = d; i < n; i++)
{
j = i - d;
while (j >= 0 && R[j].key < R[j+d].key)
{
temp = R[j];
R[j] = R[j + d];
R[j + d] = temp;
j = j - d;
}
}
cout << d<<" ";
for (k = 0; k < n; k++)
{
cout << R[k].key << " ";
}
cout << endl;
d = d / 2; //��������
}
}7.4������
/****************************************
* function ���� *
* param a[] ����������� *
* param n ���鳤�� *
* return �� *
* good time O(n) *
* avg time O(n^2) *
* bad time O(n^2) *
* space O(1) *
* stable yes *
*****************************************/
void BubbleSort(int a[],int n)
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (a[i] < a[j])
swap(a[i], a[j]);
}
}
}7.5����������
void Quick_Sort(int a[], int left, int right)
{
if (left < right)
{
//1.���ȡ��ֵ,Ȼ����left����
// srand(GetTickCount());
// int m = (rand() % (right - left)) + left;
//2.ȡǰ�к����ֵ,Ȼ����left����
// int m = Mid(left, (left + right / 2), right);
// swap(a[m], a[left]);
int midIndex = Partition(a, left, right); //��ȡ�µĻ�keyindex
Quick_Sort(a, left, midIndex - 1); //��벿������
Quick_Sort(a, midIndex + 1, right); //�Ұ벿������
}
}
void QuickSort(int a[], int n)
{
Quick_Sort(a, 0, n - 1);
}7.6��ֱ��ѡ������
/****************************************
* function ѡ������ *
* param a[] ����������� *
* param n ���鳤�� *
* return �� *
* good time O(n^2) *
* avg time O(n^2) *
* bad time O(n^2) *
* space O(1) *
* stable no *
*****************************************/
void SelectSort(int a[], int n)
{
int min = 0;
for (int i = 0; i < n; i++)
{
min = i;
for (int j = i + 1; j < n; j++)
{
if (a[j] < a[min])
min = j;
}
if (min != i)
swap(a[min], a[i]);
}
}7.7��������
#include<iostream>
using namespace std;
#define Max 20
typedef int KeyType;
typedef struct
{
KeyType key;
}RecType;
void HeapDisplay(RecType R[], int i, int n) //���ŷ������
{
if (i < n)
{
cout << R[i].key << " ";
}
if (2 * i <= n || 2 * i + 1 < n)
{
cout << "(";
if (2 * i <= n)
{
HeapDisplay(R, 2 * i, n);
}
cout << ",";
if (2 * i + 1 <= n)
{
HeapDisplay(R, 2 * i + 1, n);
}
cout << ")";
}
}
void HeapSift(RecType R[], int low, int high) //������
{
int i = low, j = 2 * i; //R[j]��R[i]������
RecType temp = R[i];
while (j <= high)
{
if (j < high && R[j].key < R[j + 1].key)
{
j++;
}
if (temp.key < R[j].key)
{
R[i] = R[j];
i = j;
j = 2 * i;
}
else break;
}
R[i] = temp;
}
/* ������:�����������,��R[1..n]
������һ��˳��洢����ȫ������,
������ȫ��������˫�ڵ�ͺ��ӽ�
��֮������ڹ�ϵ,�ڵ�ǰ��������
ѡ��ؼ�����С������Ԫ��
*/
void HeapSort(RecType R[], int n)
{
int i;
RecType temp;
for (i = n / 2; i >= 1; i--)
{
HeapSift(R, i, n);
}
cout << "��ʼ��Ϊ:";
HeapDisplay(R,1,n); //�����ʼ��
cout << endl;
for (i = n; i >= 2; i--)
{
temp = R[1];
R[1] = R[i];
R[i] = temp;
HeapSift(R, 1, i - 1); //ˢѡR[1]���,�õ�i-1�����Ķ�
cout << "ɸѡ�����õ��Ķ�:";
HeapDisplay(R, 1, i - 1);
}
}
int main()
{
int i, k, n = 10;
KeyType a[] = { 6,8,9,7,0,1,3,2,4,5 };
RecType R[Max];
for (i = 1; i <= n; i++)
{
R[i].key = a[i - 1];
}
cout << endl;
cout << " ��ʼ�ؼ���:";
for (k = 1; k <= n; k++)
{
cout << R[k].key << " ";
}
cout << endl;
for (i = n / 2; i >= 1; i--)
{
HeapSift(R, i, n);
}
HeapSort(R, n);
cout << " ���ս��:";
for (k = 1; k <= n; k++)
{
cout << R[k].key << " ";
}
cout << endl;
system("pause");
return 0;
}7.8���鲢����
7.9����������
8��ͼ
8.1��ͼ�Ļ�������
��ͼ�νṹ��,ÿһ��Ԫ�ؿ���������Ͷ��ǰ��,Ҳ����������Ͷ�����,Ҳ����˵,Ԫ��֮��Ĺ�ϵ������ġ����۶�ô���ӵ�ͼ�����ɶ���ͱ߹��ɡ�
·������:ָһ��·���Ͼ����ıߵ���Ŀ
��ͨ:ͼ���������㶼��ͨ,��Ϊ��ͨͼ,����Ϊ����ͨͼ
ǿ��ͨ:����ͼ��,ͼ���������㶼��ͨ,��Ϊǿ��ͨͼ
Ȩ:ͼ��ÿһ���߶����Ը���һ����ֵ,���������ص���ֵ��ΪȨ
����Ķ�:������ͼ��,ij������еı���Ϊ�ö���Ķȡ�������ͼ���ַ�Ϊ��Ⱥͳ���,�Զ���iΪ�յ����ߵ���Ŀ,��Ϊ���,�Զ���iΪ���ij��ߵ���Ŀ,��Ϊ�ö���ij���,����֮��Ϊ�ö���Ķȡ�
ͼ�Ĵ洢�ṹ:�ڽӾ���
ͼ���ڽӾ���ı�ʾ��ʽ��Ҫһ����ά��������ʾ��
�ŵ�:ֱ�ۡ���������,�����жϳ��������������Ƿ��б�,�������������Ķȡ�
ȱ��:�������ȫͼʱ,�ڽӾ�������õķ���,���Ƕ���ϡ�����,�������߽���,���Ƕ����,�����ͻ���ɿռ��˷ѡ�
ͼ�Ĵ洢�ṹ:�ڽӱ�
�ڽӱ���ͼ��һ����ʽ�洢�ṹ��
8.2��ͼ�ı���
������ȱ�������(DFS):��ͼ��ij����ʼ�������,���ȷ��ʳ�ʼ��,Ȼ��ѡ��һ���붥��������û�б����ʵĶ���wΪ��ʼ����,�ڼ����Ӷ���w��������������ȱ���,ֱ�������˶��㱻���ʡ���Ȼ�ñ���������һ���ݹ���̡�(һ�η���һ����)
������ȱ�������(BFS):���ȷ��ʳ�ʼ��v,���ŷ��ʶ���v������δ�����ʹ��������ڽӵ�v1,v2,v3,,,vt,����ÿһ�����������δ�����ʹ����ڽӵ�,�������ơ�(һ�η��������ڽӵ�)
8.3������������������
���ڼ�����һ����ʵ�ʵ�����:����Ҫ��n�������н���һ��ͨ������,����ͨ��n��������Ҫ����n-1һ��ͨ����·,���ʱ��������Ҫ��������ڳɱ���͵�����½������ͨ����??
�������ǾͿ���������ͨͼ�������������������,n�����о���ͼ�ϵ�n������,Ȼ��,�߱�ʾ�������е�ͨ����·,ÿ�����ϵ�Ȩ�ؾ������Ǵ������·����Ҫ�ijɱ�,��������������n���������ͨ�����Խ�����ͬ��������,ÿһ����������������Ϊһ��ͨ����,�����ǹ��������ͨ�������ijɱ���Сʱ,�����ͨ����������,�ͳ�Ϊ��С��������
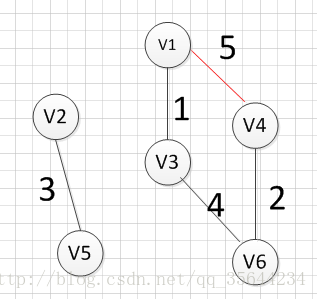
����ķ(Prim)�㷨:
���Ⱦ��Ǵ�ͼ�е�һ�����a��ʼ,��a����U����,Ȼ��,Ѱ�Ҵ���a�й����ı���,Ȩ����С�������߲��Ҹñߵ��յ�b�ڶ��㼯��:(V-U)��,����Ҳ��b���뵽����U��,���������(a,b)����Ϣ,�������ǵļ���U����:{a,b},Ȼ��,����Ѱ����a������b�����ı���,Ȩ����С�������߲��Ҹñߵ��յ��ڼ���:(V-U)��,���ǰ�c���뵽����U��,���������Ӧ�������ߵ���Ϣ,�������ǵļ���U����:{a,b,c}������Ԫ����,һ������,ֱ�����ж��㶼���뵽�˼���U�����㷨�ĺ�����һ�μ���һ����,Ȼ�����Ӹõ��Ȩֵ��С������,ֱ�����е㶼���ӽ�ȥ��
�������Ƕ��������ͼ������С������:
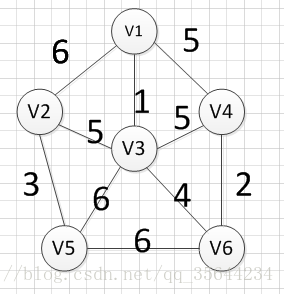
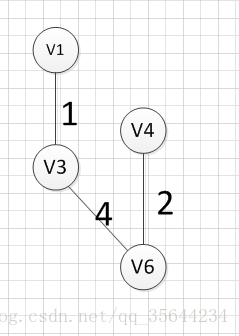
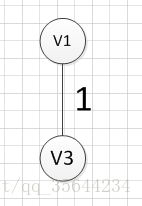
?�������ǴӶ���v1��ʼ,�������ǿ��Է���(v1,v3)�ߵ�Ȩ����С,���Ե�һ������ı߾���:v1��v3=1;Ȼ��,����Ҫ��v1��v3��Ϊ���ı���Ѱ��Ȩ����С�ı�,������(v1,v3)�Ѿ����ʹ���,�������Ǵ���������Ѱ��,����(v3,v6)��������С,��������߾���:v3��-v6=4��
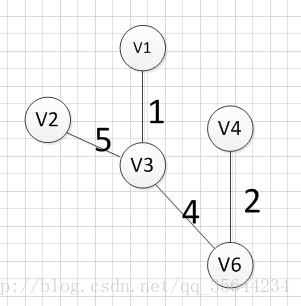
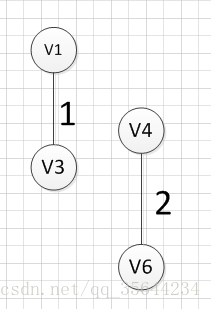
 |  |
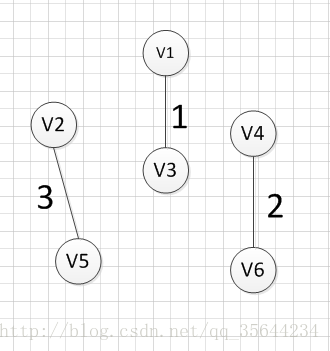
?Ȼ��,����Ҫ��v1��v3��v6��������������ı���Ѱ��һ��Ȩ����С�ı�,���ǿ��Է��ֱ�(v6,v4)Ȩ����С,��������߾���:v6��-v4=2��Ȼ��,���Ǿʹ�v1��v3��v6��v4���ĸ�����������ı���Ѱ��Ȩ����С�ı�,���ֱ�(v3,v2)��Ȩ����С,���������:v3���Cv2=5 :
 |  |
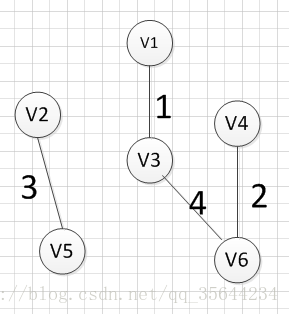
?Ȼ��,���Ǿʹ�v1��v3��v6��v4,v2��2�������������ı���Ѱ��Ȩ����С�ı�,���ֱ�(v2,v5)��Ȩ����С,���������:v2���Cv5=3?
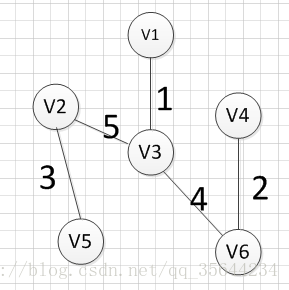
?���,���Ƿ��������㶼�Ѿ����뵽����U��,���ǵ���С������������ɡ�
����ʵ��:
#include<iostream>
#include<string>
#define MAXSIZE 100
using namespace std;
struct M_g //�����ڽӾ���
{
string *Head; //�����
int **arc; //�ڽӾ�����Կ��ɱ߱�
int N_v, N_e; //��¼�������ͱ���
};
//����һ���ڽӾ����ʾͼ
void OnCreateM_g(M_g *&x)
{
int i, j, k, w;
cout << "���붥������ͱ���" << endl;
cin >> x->N_v >> x->N_e; //�������붥�����ͱ���
cout << "������Ϊ:" << x->N_v << ";" << "����Ϊ:" << x->N_e << endl;
for (int i = 0; i < x->N_v; i++)
{
cin >> x->Head[i]; //�������붥��
}
for (int i = 0; i < x->N_v; i++) //����ÿ�������Ƿ�����
{
for (int j = 0; j < x->N_v; j++)
{
x->arc[i][j] = INT_MAX;
}
}
cout << "����(Vi,Vj)���ϱ�i,�±�j��Ȩw" << endl;
for (k = 0; k < x->N_e; k++) //
{
cin >> i >> j >> w;
x->arc[i][j] = w;
x->arc[j][i] = x->arc[i][j]; //����ͼ�ǶԳƾ���
}
}
//��ӡͼ
void Print(M_g x)
{
int i;
for (i = 0; i < x.N_v; i++)
{
for (int j = 0; j < x.N_v; j++)
{
if (x.arc[i][j] == INT_MAX)
{
cout << "��" << " ";
}
else
{
cout << x.arc[i][j] << " ";
}
}
cout << endl;
}
}
//��¼�ߵ���Ϣ,��Щ�߶��Ǵﵽend�����б���,Ȩ����С���Ǹ�
struct Assis_array
{
int start; //�ߵ����
int end; //�ߵ��յ�
int weight;//�ߵ�Ȩ��
};
//Prim�㷨ʵ��,ͼ�Ĵ洢��ʽΪ�ڽӾ���
void Prim(M_g *x, int begin)
{
//����һ�����浽��ij������ĸ�������Ȩ�������Ǹ��ߵĽṹ������
Assis_array *edge = new Assis_array[x->N_v];
int j;
//edge��ʼ��,��ʼ��ʱ�ö���0���õ�ı�ΪȨֵ����
for (j = 0; j < x->N_v; j++)
{
if (j != begin - 1)
{
edge[j].start = begin - 1;
edge[j].end = j;
edge[j].weight = x->arc[begin - 1][j];
}
}
//������edge��Ȩֵ����Ϊ-1,��ʾ�Ѿ����뵽����U��
edge[begin - 1].weight = -1;
//b����ʣ�µĶ���,�����μ��뵽����U
for (j = 1; j < x->N_v; j++)
{
int min = INT_MAX;
int k;
int index;
//Ѱ������Ȩ����С���DZ�����
for (k = 0; k < x->N_v; k++)
{
if (edge[k].weight != -1)
{
if (edge[k].weight < min)
{
min = edge[k].weight;
index = k;
}
}
}
//��Ȩ����С�������ߵ��յ�Ҳ���뼯��U
edge[index].weight = -1;
//�����Ӧ�ıߵ���Ϣ
cout << edge[index].start
<< "-----"
<< edge[index].end
<< "="
<< x->arc[edge[index].start][edge[index].end] << endl;
//�������ǵ�edge����
for (k = 0; k < x->N_v; k++)
{
if (x->arc[edge[index].end][k] < edge[k].weight)
{
edge[k].weight = x->arc[edge[index].end][k];
edge[k].start = edge[index].end;
edge[k].end = k;
}
}
}
}
int main() {
M_g *p;
p = (M_g*)malloc(sizeof(M_g));
OnCreateM_g(p);
Prim(p,1);
system("pause");
return 0;
}��³˹��(Kruskal)�㷨:
(1)��ͼ�е����б߶�ȥ����
(2)���߰���Ȩֵ��С�����˳�����ӵ�ͼ��,��֤���ӵĹ����в����γɻ�
(3)�ظ�����һ������ֱ���������ж���,��ʱ����������С������������һ��̰�IJ��ԡ�
ģ���³˹���㷨������С����������ϸ�Ĺ���:
����������ͼ����ͼ:?
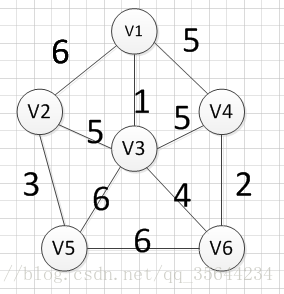
?Ȼ��,������Ҫ����Щ�����ҳ�Ȩ����С��������,���Է��ֱ�(v1,v3)�����ߵ�Ȩ������С��,�������������:v1��-v3=1��Ȼ��,������Ҫ��ʣ��ı���,�ٴ�Ѱ��һ��Ȩ����С�ı�,���Է��ֱ�(v4,v6)�����ߵ�Ȩ����С,���������:v4��v6=2 ��
 |  |
?Ȼ��,�����ٴδ�ʣ�����Ѱ��Ȩ����С�ı�,���ֱ�(v2,v5)��Ȩ����С,���Կ��������:v2��-v5=3,?Ȼ��,����ʹ��ͬ���ķ�ʽ�ҳ���Ȩ����С�ı�:(v3,v6),�������������:v3��-v6=4 :
 |  |
?����,�������ǻ���Ҫ�ҳ����һ���߾Ϳ��Թ����һ����С������,�������ʱ������������ѡ��:(v1,V4),(v2,v3),(v3,v4),�������ߵ�Ȩ�ض���5,�����������ѡ(v1,v4)�Ļ�,�õ���ͼ����:?���Ƿ���,��϶��Dz����������㷨Ҫ���,��Ϊ��������һ����,����������ʹ�õڶ���(v2,v3)����,�õ�ͼ������:?
 | 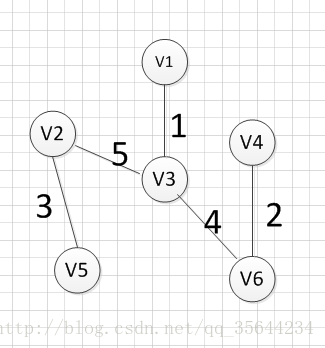 |
?���Ƿ���,���ͼ��û�л�����,���Ұ����еĶ��㶼���뵽�����������,����(v2,v3)������������Ҫ�ı�,�������һ������ı߾���:v2��-v3=5,���,���ǵ���С��������ɡ�
8.4�����·��
���·��:��һ�����㵽��һ��������ܴ��ڶ���·��,ÿ��·�����������ı������ܲ�ͬ,��·�����Ȳ�ͬ,��·��������̵�����·���������·�������ڴ�Ȩ��ͼ,Ӧ�ÿ���·���ϸ��ߵ�Ȩֵ,ͨ����һ��·�����������ıߵ�Ȩֵ֮�Ͷ�Ϊ��·���ij��Ȼ��ߴ�Ȩ·�����ȡ�
1����һ�����㵽���������������·��:�ҿ�˹����(Dijkstra)�㷨
Dijkstra�㷨�ǵ������·���㷨,���ڼ���һ���ڵ㵽�����ڵ�����·����?
������Ҫ�ص�������ʼ��Ϊ������������չ(�����������˼��(BFS)),ֱ����չ���յ�Ϊֹ��
����˼��
ͨ��Dijkstra����ͼG�е����·��ʱ,��Ҫָ�����s(���Ӷ���s��ʼ����)��
����,������������S��U��S�������Ǽ�¼��������·���Ķ���(�Լ���Ӧ�����·������),��U���Ǽ�¼��δ������·���Ķ���(�Լ��ö��㵽���s�ľ���)��?��ʼʱ,S��ֻ�����s;U���dz�s֮��Ķ���,����U�ж����·����"���s���ö����·��"��Ȼ��,��U���ҳ�·����̵Ķ���,��������뵽S��;����,����U�еĶ���Ͷ����Ӧ��·���� Ȼ��,�ٴ�U���ҳ�·����̵Ķ���,��������뵽S��;����,����U�еĶ���Ͷ����Ӧ��·����... �ظ��ò���,ֱ�����������ж��㡣
��������
(1)?��ʼʱ,Sֻ�������s;U������s�����������,��U�ж���ľ���Ϊ"���s���ö���ľ���"[����,U�ж���v�ľ���Ϊ(s,v)�ij���,Ȼ��s��v������,��v�ľ���Ϊ��]��
(2)?��U��ѡ��"������̵Ķ���k",��������k���뵽S��;ͬʱ,��U���Ƴ�����k��
(3)?����U�и������㵽���s�ľ��롣֮���Ը���U�ж���ľ���,��������һ����ȷ����k��������·���Ķ���,�Ӷ���������k��������������ľ���;����,(s,v)�ľ�����ܴ���(s,k)+(k,v)�ľ��롣
(4)?�ظ�����(2)��(3),ֱ�����������ж��㡣
�ҿ�˹�����㷨ͼ��
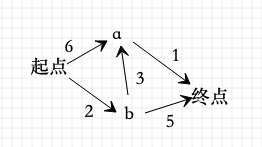
# ����һ��ɢ�б�
# ����ӳ�䵽ֵ,������ϵ��
graph = {}
# ���
graph["start"] = {}
# �����ھ�
graph["start"]["a"] = 6
graph["start"]["b"] = 2
# a��b���ھ�
graph["a"] = {}
graph["a"]["finish"] = 1
graph["b"] = {}
graph["b"]["finish"] = 5
graph["b"]["a"] = 3
# �յ���ھ�
graph["finish"] = {}
# ����������ɢ�б�
costs = {}
costs["a"] = 6
costs["b"] = 2
# �����յ�Ϊ�����
costs["finish"] = float("inf")
# ����һ���洢���ڵ��ɢ�б� :Ҫ������Ȩ��,���ڵ���һ�����ɽ�,��¼֮ǰ��Ȩ��
parents = {}
parents["a"] = "start"
parents["b"] = "start"
parents["finish"] = None
# ��¼�������Ľڵ�
processed = []
# �ҳ��������е���С�ڵ�
def find_lowcosts_node(costs):
# �����
lowcost = float("inf")
lowcost_node = None
# �������нڵ�
for node in costs:
cost = costs[node]
if cost < lowcost and node not in processed:
# ��lowcost��ÿ�ε���Сֵ
lowcost = cost
# ���¿�����С�Ľڵ�
lowcost_node = node
return lowcost_node
# ��δ�����Ŀ��������ҿ���(Ȩ��)��С�Ľڵ�
node = find_lowcosts_node(costs)
# ���нڵ㶼�������������
while node is not None:
# �ҳ��ýڵ��Ȩ��ֵ
cost = costs[node]
# �ҵ��ýڵ���ھ�
neighbors = graph[node]
# �����ýڵ�������ھ�
for n in neighbors.keys():
# ��㵽�ýڵ��ٵ����ھӽڵ��Ȩ��ֵ��
new_costs = cost + neighbors[n]
# �����㵽���ھӵ�Ȩ��ֵ������㵽�ýڵ��ٵ����ھӵ�Ȩ��ֵ(����ǰ�ڵ�ǰ�����ھӸ���)
if costs[n] > new_costs:
# ���¸��ھӿ���
costs[n] = new_costs
# �����ھӵĸ��ڵ�����Ϊ��ǰ�ڵ�,(��Ϊ����ǰ�ڵ�ǰ�����ھӸ���)
parents[n] = node
print(new_costs) # 7 5 6
print(node) # b b a
# ����ǰ�ڵ���Ϊ������
processed.append(node)
# �ݹ鴦��ʣ�µĽڵ�
node = find_lowcosts_node(costs)
9������ģʽƥ��
9.1��BF�㷨
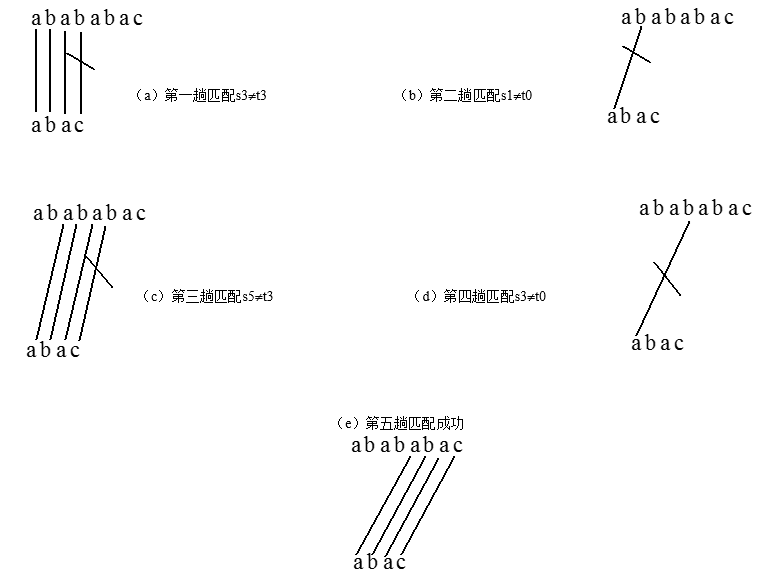
�㷨�Ļ���˼��:�������ĵ�1���ַ����ģʽ���ĵ�һ���ַ��Ƚ�,�����,���������ȽϺ����ַ�,����������ĵ�2�ַ������º�ģʽ�����ַ��Ƚϡ���������,ֱ��ģʽ��t�е�ÿ���ַ����κ�����s�е�һ���������ַ��������,��ƥ��ɹ�������ƥ�䲻�ɹ���
#include<stdio.h>
//���Ķ���˳��洢��ʾ
#define MAXSTRLEN 50 // // �û�����50���ڶ������
typedef unsigned char SString[MAXSTRLEN + 1];//0�ŵ�Ԫ��Ŵ��ij���
//�����Ӵ�T������S�е�pos���ַ�֮���λ�á���������,����ֵΪ0������,T�ǿ�,1<=pos<=StrLength(S)��
int indexBF(SString S, SString T, int pos){
int i = pos, j = 1;
while(i <= len(S) && j <= len(T)){
if(S[i] == T[j]){
i++;
j++;
}else{
i = i - j + 2;//i�ص�ԭλ����i - j + 1 ,����i�˵�Զλ�õ���һ��λ����i - j + 1 + 1
j = 1;
}
}
if(j > len(T)){//���j > len(T),˵��ģʽ��T��S��ij�Ӵ���ȫƥ��
return i - T[0];//��Ϊi���Ѿ�������һ����,������i-len(T)������i-len(T)+1
}else
return 0;
}
void init(SString &S, char str[]){
int i = 0;
while(str[i]!='\0'){
S[i+1] = str[i];
i++;
}
S[i+1] = '\0';
S[0] = i;
}
void printStr(SString Str){
for(int i = 1; i <= Str[0]; i++){
printf("%c", Str[i]);
}
printf("\n");
}
void main(){
SString S ;
init(S, "ababcabcacbab");
printStr(S);
SString T;
init(T, "abcac");
printStr(T);
int index = indexBF(S, T, 1);
printf("index is %d\n", index);
}9.2��KMP�㷨
�����㷨��˳�����,�Ƚϵ�һ�ε�ʱ��p[0]��ʧ��,Ȼ������ƶ�����ƥ�䡣���������ʱ����ô���϶��Dz����еġ���������ͻ���KMP�㷨!��һ��ʧ��֮��,KMP�㷨��Ϊ�����Ѿ�ʧ����,�Ͳ����ڱȽ�һ����,���ǽ��ַ���P��ǰ�ƶ�(��ƥ�䳤��-�������)λ,���ż����Ƚ���һ��λ�á�������ƥ�䳤�Ⱥ�����,�������������ʲô��?����ͳ�����next����,next����:next[i]��ʾ����P[0-i]���ǰ���������ȡ�����϶�������Ҫ����,next������ô����Ķ���,Ϊʲô����������ַ�����Ҫ���ƽ�Ƽ�λ�Ų����ظ��Ƚ���?
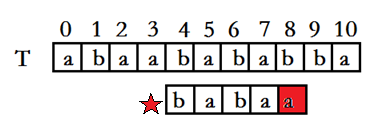
��ͼ�к��DZ��Ϊ��,��ʱ��p[4]��ʧ��,��ƥ�䳤��Ϊ4,��next[3]=2(Ҳ����babaa��ǰ���������Ϊ0),��ʱ�����ƽ����ƥ�䳤��-�������=2λ,P[0]����ԭ����P[2]��λ��,���ֻƽ��һλ,P[0]����p[1]��λ�����λ��û��ƥ����β����������ù������˷ѵ���ʱ�䡣��֪ǰ���е��������,�´�λ�Ƶ�ʱ��ֱ�Ӱ�ǰλ�Ƶ�������ֱ�Ӳ���ƥ��,����ֱ�ӴӺ��ĺ�һλ��ʼ�ȽϾͿ����ˡ�������һ���������λ�ƹ��˵�ʣȥ�˲��ٵ�ʱ�䡣
void makeNext(const char P[],int next[])
{
int q,k;
int m=strlen(P);
next[0]=0;
for (q=1,k=0;q<m;++q)
{
while(k>0&&P[q]!=P[k])
k = next[k-1];
/*
�����whileѭ���ܲ�������!
������һ��ѭ�������ǰ���������;
���ȱȽ�P[q]��P[K]�Ƿ���������ȵĻ�˵���Ѿ�K����ֵ������ƥ�䵽�ij���;
�������ȵĻ�,��ônext[k-1]��P[q]�ij���,Ϊʲô��?��Ϊ��ǰ���Ȳ�����
��,��������ģ����,����С����next[k-1]
�ij����ܹ����ܺ�P[q]ƥ��,��ôһֱ�ݹ���ȥֱ���ҵ�
*/
if(P[q]==P[k])//�����ǰλ��Ҳ��ƥ����,��ô���ȿ���+1
{
k++;
}
next[q]=k;
}
}int kmp(const char T[],const char P[],int next[])
{
int n,m;
int i,q;
n = strlen(T);
m = strlen(P);
makeNext(P,next);
for (i=0,q=0;i<n;++i)
{
while(q>0&&P[q]!= T[i])
q = next[q-1];
/*
�����ѭ������λ��֮��P��ǰ�����ַ��ܸ�Tģ��ƥ��
*/
if(P[q]==T[i])
{
q++;
}
if(q==m)//�����ƥ��ij��ȸպ���T�ij�����ô�����ҵ���һ����ƥ��ɹ���λ��
{
printf("Pattern occurs with shift:%d\n",(i-m+1));
}
}
}