���ڷ��������ǵ�����
1.����ģ�͵�ָ��
�ж������ж��ԵĴ��۲�ͬ
����:���ǽ���֢���ߴ���Ԥ��Ϊ�ް�֢���ް�֢���ߴ���Ԥ��Ϊ��֢����,��ҽԺ���˵Ĵ��۶��Dz�ͬ��,ǰ��ʹ�û������õ���ʱ�ľ��ζ��������������ʱ���������������Ĵ���,������ֻ��Ҫ�ں��������ƹ����м���ȡ֤�ͺ���,������Ǻܲ�ϣ������ǰ��,�����Ƿ�����ǰ�������Ĵ����ʱ�����Ϊ������ģ���Ǻܲ�ġ�Ϊ�˽����Щ����,���DZ��뽫��������ֿ�����,Ȼ���������ָ�ꡣ
������TP:Ԥ��ֵ����ʵֵ��Ϊ����;
������TN:Ԥ��ֵ����ʵֵ��Ϊ����;
������FP:Ԥ��ֵΪ��,ʵ��ֵΪ��;
������FN:Ԥ��ֵΪ��,ʵ��ֵΪ��;

����ģ�͵�ָ��:����
ȷ��:������ȷ��������ռ�������ı���,��: 𝐴𝐶𝐶=𝑇𝑃+𝑇𝑁𝐹𝑃+𝐹𝑁+𝑇𝑃+𝑇𝑁 .
����:Ԥ��Ϊ���ҷ�����ȷ������ռԤ��ֵΪ���ı���,��: 𝑃𝑅𝐸=𝑇𝑃𝑇𝑃+𝐹𝑃 .
�ٻ���:Ԥ��Ϊ���ҷ�����ȷ������ռ���Ϊ���ı���,��: 𝑅𝐸𝐶=𝑇𝑃𝑇𝑃+𝐹𝑁 .
F1ֵ:�ۺϺ������Ⱥ��ٻ���,��: 𝐹1=2𝑃𝑅𝐸��𝑅𝐸𝐶𝑃𝑅𝐸+𝑅𝐸𝐶 .
ROC����:�Լ�����Ϊ����,������Ϊ���ử����������,�����·����Խ��Խ�á�
2.ģ��
���ع�logistic regression:
˵������������ع����������,���ڻع����������������ҪԤ����������һ����
�ڻع�������,������������Ա���,������ҪԤ�� 𝐸(𝑌|𝑋) ��һ��������ʵ��,�����ڷ���������,����������ͨ����֪X����ϢԤ��Y�����,������һ����ɢ�����е�ij��Ԫ�ء�
�����������Իع鴦��������������ʲô��,������ϸ����������Իع������,
����������Ҫ��ij���˵�ծ��(Balance)������(Income)ȥԤ���Ƿ�����ÿ�ΥԼ(default):
d
e
f
a
u
l
t
=
��
0
+
��
1
B
a
l
a
n
c
e
+
��
2
I
n
c
o
m
e
{default = \beta_0 + \beta_1 Balance + \beta_2 Income}
default=��0?+��1?Balance+��2?Income,ֻҪ����Balance �� Income �Լ�default�����ݾ�������С���˷����Ƴ�
��
0
,
��
1
{\beta_0,\beta_1}
��0?,��1?,�趨Ԥ���default>0.5����ΥԼ��֮��ΥԼ,�о�������������,����ʵ�����������?
���Ǽ�����һ������Lisa,����Balance��Income����С,��ô�п��ܻᵼ��default��ֵΪ����,��ô�����������ʲô������?��Ȼ��û���κ�����ġ�

�����ǵķ�������Ƕ����ʱ��,��0.5Ϊ�����ַ���Ͳ�������,��ô����Ӧ����ô�ҵ�һ���������������?
������ģ�Ͳ����ʵ�ʱ��,�Ƿ���Խ����Իع�Ľ��defaultת��Ϊ����[0:1]��,��defaultת���һ��ΥԼ�ĸ�����?
����,���Ǽ������ǵ����Իع�ģ��Ϊ
Y
=
��
0
+
��
1
X
{Y=\beta_0+\beta_1 X}
Y=��0?+��1?X,��ô�����������ν����Իع�Ľ��ת��Ϊ������?�����������logistic ����,�������ʽΪ
p
(
X
)
=
e
��
0
+
��
1
X
1
+
e
��
0
+
��
1
X
{p(X) = \dfrac{e^{\beta_0 + \beta_1X}}{1+e^{\beta_0 + \beta_1X}}}
p(X)=1+e��0?+��1?Xe��0?+��1?X?,���ĺ���ͼ������ͼ:(��������Իع�,�ұ���������)

���,���Ǽ������ع�ģ��Ϊ:
p
(
y
=
1
�O
x
)
=
1
1
+
e
?
w
T
x
p(y = 1|x) = \frac{1}{1+e^{-w^Tx}}
p(y=1�Ox)=1+e?wTx1? .
���������������Ƶ������ع�ģ��:
��������Data
{
(
x
i
,
y
i
)
}
,
????
i
=
1
,
2
,
.
.
.
,
N
,
????
x
i
��
R
p
,
y
i
��
{
0
,
1
}
\{(x_i,y_i) \},\;\;i = 1,2,...,N,\;\;x_i \in R^p,y_i \in \{0,1 \}
{(xi?,yi?)},i=1,2,...,N,xi?��Rp,yi?��{0,1},��
p
1
=
p
(
y
=
1
�O
x
)
=
��
(
w
T
)
=
1
1
+
e
?
w
T
x
p_1 = p(y=1|x) = \sigma(w^T) = \frac{1}{1+e^{-w^Tx}}
p1?=p(y=1�Ox)=��(wT)=1+e?wTx1?����Ϊyֻ����ȡ0����1,��˼������ݷ���0-1�ֲ�,Ҳ�в�Ŭ���ֲ�,��:��y=1ʱ,
p
(
y
�O
x
)
=
p
1
p(y|x)=p_1
p(y�Ox)=p1?,��y=0ʱ,
p
(
y
�O
x
)
=
1
?
p
1
p(y|x)=1-p_1
p(y�Ox)=1?p1?,�����
p
(
y
�O
x
)
=
p
1
y
(
1
?
p
1
)
1
?
y
p(y|x) = p_1^y(1-p_1)^{1-y}
p(y�Ox)=p1y?(1?p1?)1?y,���Դ���y=0��y=1��ȥ��֤,�����ǰ��Ľ���һģһ����
����ʹ�ü�����Ȼ����MLE,��:
w
^
=
a
r
g
m
a
x
w
????
l
o
g
??
P
(
Y
�O
X
)
=
a
r
g
m
a
x
x
????
l
o
g
??
��
i
=
1
N
P
(
y
i
�O
x
i
)
=
a
r
g
m
a
x
w
��
i
=
1
N
l
o
g
??
P
(
y
i
�O
x
i
)
??????
=
a
r
g
m
a
x
w
��
i
=
1
N
(
y
i
l
o
g
??
p
1
+
(
1
?
y
i
)
l
o
g
(
1
?
p
1
)
)
��
:
L
(
w
)
=
��
i
=
1
N
(
y
i
l
o
g
??
p
1
+
(
1
?
y
i
)
l
o
g
(
1
?
p
1
)
)
??????
?
L
?
w
k
=
��
i
=
1
N
y
i
1
p
1
?
p
1
?
z
?
z
?
w
k
+
(
1
?
y
i
)
1
1
?
p
1
(
?
?
p
1
?
z
?
z
?
w
k
)
??????
=
��
i
=
1
N
y
i
1
��
(
z
)
(
��
(
z
i
)
?
��
(
z
i
)
2
)
x
i
+
(
1
?
y
i
)
1
1
?
��
(
z
i
)
[
?
(
��
(
z
i
)
?
��
(
z
i
)
2
)
x
i
]
??????
=
��
i
=
1
N
[
(
y
i
?
y
i
��
(
z
i
)
)
x
i
+
(
1
?
y
i
)
(
?
��
(
z
i
)
)
x
i
]
??????
=
��
i
=
1
N
y
i
x
i
?
��
(
z
i
)
x
i
=
��
i
=
1
N
(
y
i
?
��
(
z
i
)
)
x
i
\hat{w} = argmax_w\;\;log\;P(Y|X) = argmax_x\;\;log\;\prod_{i=1}^N P(y_i|x_i) = argmax_w \sum\limits_{i=1}^{N} log\;P(y_i|x_i)\\ \;\;\; = argmax_w \sum\limits_{i=1}^{N}(y_ilog\;p_1 + (1-y_i)log(1-p_1)) \\ ��:L(w) = \sum\limits_{i=1}^{N}(y_ilog\;p_1 + (1-y_i)log(1-p_1))\\ \;\;\; \frac{\partial L}{\partial w_k} = \sum\limits_{i=1}^{N} y_i\frac{1}{p_1}\frac{\partial p_1}{\partial z}\frac{\partial z}{\partial w_k} + (1-y_i)\frac{1}{1-p_1}(-\frac{\partial p_1}{\partial z}\frac{\partial z}{\partial w_k})\\ \;\;\;=\sum\limits_{i=1}^{N}y_i\frac{1}{\sigma(z)}(\sigma(z_i)-\sigma(z_i)^2)x_i + (1-y_i)\frac{1}{1-\sigma(z_i)}[-(\sigma(z_i)-\sigma(z_i)^2)x_i]\\ \;\;\; =\sum\limits_{i=1}^{N}[(y_i-y_i\sigma(z_i))x_i + (1-y_i)(-\sigma(z_i))x_i]\\ \;\;\; = \sum\limits_{i=1}^{N}y_ix_i-\sigma(z_i)x_i = \sum\limits_{i=1}^{N}(y_i-\sigma(z_i))x_i
w^=argmaxw?logP(Y�OX)=argmaxx?logi=1��N?P(yi?�Oxi?)=argmaxw?i=1��N?logP(yi?�Oxi?)=argmaxw?i=1��N?(yi?logp1?+(1?yi?)log(1?p1?))��:L(w)=i=1��N?(yi?logp1?+(1?yi?)log(1?p1?))?wk??L?=i=1��N?yi?p1?1??z?p1???wk??z?+(1?yi?)1?p1?1?(??z?p1???wk??z?)=i=1��N?yi?��(z)1?(��(zi?)?��(zi?)2)xi?+(1?yi?)1?��(zi?)1?[?(��(zi?)?��(zi?)2)xi?]=i=1��N?[(yi??yi?��(zi?))xi?+(1?yi?)(?��(zi?))xi?]=i=1��N?yi?xi??��(zi?)xi?=i=1��N?(yi??��(zi?))xi?
���,
?
L
?
w
k
=
��
i
=
1
N
(
y
i
?
��
(
z
i
)
)
x
i
\frac{\partial L}{\partial w_k} = \sum\limits_{i=1}^{N}(y_i-\sigma(z_i))x_i
?wk??L?=i=1��N?(yi??��(zi?))xi?,���������漰�ĺ����������Իع�һ���ܼ����������,�������ʹ�õ������Ż��㷨:�ݶ��½���,��:
w
k
(
t
+
1
)
��
w
k
(
t
)
?
��
��
i
=
1
N
(
y
i
?
��
(
z
i
)
)
x
i
(
k
)
,
??????
��
��
,
x
i
(
k
)
Ϊ
��
i
��
��
��
��
k
��
��
��
w_k^{(t+1)}\leftarrow w_k^{(t)} - \eta \sum\limits_{i=1}^{N}(y_i-\sigma(z_i))x_i^{(k)},\;\;\;����,x_i^{(k)}��i��������k������
wk(t+1)?��wk(t)??��i=1��N?(yi??��(zi?))xi(k)?,����,xi(k)?��i��������k������
��������(2),����ֵ��ע�����,���ع���ʵ���в�̫���ڶ��������,��Ϊʵ��Ч�����Ǻܺ�
�����б�
- ���ڱ�Ҷ˹��ʽ�������б����������:
�ڸ���ͳ�Ƶ���������һ������Ĺ�ʽ�б�Ҷ˹����,�������ʽ��: P ( Y = k �O X = x ) = �� k f k ( x ) �� l = 1 K �� l f l ( x ) {P(Y=k|X=x) = \dfrac{{\pi}_kf_k(x)}{\sum\limits_{l=1}^K{\pi}_lf_l(x)}} P(Y=k�OX=x)=l=1��K?��l?fl?(x)��k?fk?(x)? �����Ǽ���۲��� K {K} K��, �� k {\pi_k} ��k?Ϊ���ѡ��Ĺ۲����Ե� k {k} k��� �������,Ҳ������������� k {k} k����������������������ĸ���: �� k = n k n {\pi_k = \dfrac{n_k}{n}} ��k?=nnk??������ f k ( x ) = P ( X = x �O Y = k ) {f_k(x) =P(X=x|Y=k)} fk?(x)=P(X=x�OY=k),��ʾ�� k {k} k��۲��X���ܶȺ���,˵��ֱ��һ������� Y = k {Y=k} Y=k�������� X = x {X=x} X=x����������,�� f k ( x ) = P ( X = x �O Y = k ) = n ( X = x , Y = k ) n ( Y = k ) {f_k(x) = P(X=x|Y=k) = \dfrac{n_{(X=x,Y=k)}}{n_{(Y=k)}}} fk?(x)=P(X=x�OY=k)=n(Y=k)?n(X=x,Y=k)??,���, �� l = 1 K �� l f l ( x ) = P ( X = x ) = n ( X = x ) n {\sum\limits_{l=1}^K{\pi}_lf_l(x)}=P(X=x)=\dfrac{n_{(X=x)}}{n} l=1��K?��l?fl?(x)=P(X=x)=nn(X=x)??,Ҳ���������� X = x {X=x} X=x�ĸ��ʡ�
�����۱�Ҷ˹������,���ǻص���������,������������ǵķ���������ʲô������?û��,�����ʽ P ( Y = k �O X = x ) = �� k f k ( x ) �� l = 1 K �� l f l ( x ) {P(Y=k|X=x) = \dfrac{{\pi}_kf_k(x)}{\sum\limits_{l=1}^K{\pi}_lf_l(x)}} P(Y=k�OX=x)=l=1��K?��l?fl?(x)��k?fk?(x)?�����˸�������������, Y = k {Y=k} Y=k�������µĸ���,������������ṩ��һ��˼·,�Ǿ��Ǽ������ P ( Y = k �O X = x ) {P(Y=k|X=x)} P(Y=k�OX=x),�������ǵ����ع������ô�ɵ�,������ P ( Y = k �O X = x ) = �� k f k ( x ) �� l = 1 K �� l f l ( x ) {P(Y=k|X=x) = \dfrac{{\pi}_kf_k(x)}{\sum\limits_{l=1}^K{\pi}_lf_l(x)}} P(Y=k�OX=x)=l=1��K?��l?fl?(x)��k?fk?(x)?�����ʽ��,��ĸ �� l = 1 K �� l f l ( x ) = P ( X = x ) {{\sum\limits_{l=1}^K{\pi}_lf_l(x)} = P(X=x)} l=1��K?��l?fl?(x)=P(X=x)������������ʱ����һ������� k {k} k�صij���,�������ǵ�������Լ�Ϊֻ��Ҫ������� �� k f k ( x ) {{\pi}_kf_k(x)} ��k?fk?(x),�����Ƚ��ĸ����ĸ�������֪�������ĸ������,������ǵķ���˼·�ͳ�����,���˼·��ͬ�����ع�,���ع���Ҫ�������� P ( Y = k �O X = x ) {P(Y=k|X=x)} P(Y=k�OX=x)����ֵ,���������ڵ�˼·��ͨ����Ҷ˹�������㱴Ҷ˹�����ķ���,�ȽϷ��������Ǹ����Ϊ�������
�������Ƶ������㷨֮ǰ,�������Ƶ��¼ĵ��Ա�������ֻ��һ����ģ��,�� p = 1 {p=1} p=1�ļ�ģ�͡����Ǽ� P ( Y = k �O X = x ) = �� k f k ( x ) �� l = 1 K �� l f l ( x ) {P(Y=k|X=x) = \dfrac{{\pi}_kf_k(x)}{\sum\limits_{l=1}^K{\pi}_lf_l(x)}} P(Y=k�OX=x)=l=1��K?��l?fl?(x)��k?fk?(x)? �ķ���Ϊ g k ( x ) = �� k f k ( x ) {g_k(x) = {\pi}_kf_k(x)} gk?(x)=��k?fk?(x)��������,��������ģ�ͼ���:���� f k ( x ) {f_k(x) } fk?(x)������̬�ֲ�,�� f k ( x ) �� N ( �� , �� k 2 ) {f_k(x) \sim N(\mu,\sigma_k^2)} fk?(x)��N(��,��k2?),����ÿ�� �� k 2 = �� 2 {\sigma_k^2 = \sigma^2} ��k2?=��2,ͬ������衣��� f k ( x ) = 1 2 �� �� k e ? 1 2 �� 2 ( x ? �� k ) 2 {f_k(x) = \dfrac{1}{\sqrt{2\pi}\sigma_k}e^{-\dfrac{1}{2\sigma^2}(x-\mu_k)^2}} fk?(x)=2��?��k?1?e?2��21?(x?��k?)2,�������ǵ� g k ( x ) = �� k 1 2 �� �� k e ? 1 2 �� 2 ( x ? �� k ) 2 {g_k(x) = \pi_k\dfrac{1}{\sqrt{2\pi}\sigma_k}e^{-\dfrac{1}{2\sigma^2}(x-\mu_k)^2}} gk?(x)=��k?2��?��k?1?e?2��21?(x?��k?)2,����������������ʽ�Ӳ��Ǻܺü���,���Ƕ� g k ( x ) {g_k(x)} gk?(x)ȡ������,�� �� k ( x ) = l n ( g k ( x ) ) = l n �� k + �� �� 2 x ? �� 2 2 �� 2 {\delta_k(x) = ln(g_k(x))=ln\pi_k+\dfrac{\mu}{\sigma^2}x-\dfrac{\mu^2}{2\sigma^2}} ��k?(x)=ln(gk?(x))=ln��k?+��2��?x?2��2��2?,���������ǵ�ģ�ͽ���ģ��,����ֻ��Ҫ��λ�õ� �� k {\mu_k} ��k?�� �� 2 {\sigma^2} ��2���Ƴ����ͺ��ˡ� �� ^ k = 1 n k �� i : y i = k x i {\hat{\mu}_k =\dfrac{1}{n_k}\sum\limits_{i:y_i=k}x_i} ��^?k?=nk?1?i:yi?=k��?xi?,Ҳ���ǵ� y = k {y=k} y=k��һ���� x {x} x��ƽ��ֵ; �� ^ 2 = 1 n ? K �� k = 1 K �� i : y i = k ( x i ? �� ^ k ) 2 {\hat{\sigma}^2 =\dfrac{1}{n-K}\sum\limits_{k=1}^K\sum\limits_{i:y_i=k}(x_i-\hat{\mu}_k)^2 } ��^2=n?K1?k=1��K?i:yi?=k��?(xi??��^?k?)2,˵���˾��Ǽ���ÿһ��ķ���,����ƽ��ֵ���ܽ�������Ĺ�ʽ����:
{ �� k ( x ) = l n ( g k ( x ) ) = l n �� k + �� �� 2 x ? �� 2 2 �� 2 �� ^ k = 1 n k �� i : y i = k x i �� ^ 2 = 1 n ? K �� k = 1 K �� i : y i = k ( x i ? �� ^ k ) 2 {\begin{cases}\delta_k(x) = ln(g_k(x))=ln\pi_k+\dfrac{\mu}{\sigma^2}x-\dfrac{\mu^2}{2\sigma^2}\\{\hat{\mu}_k =\dfrac{1}{n_k}\sum\limits_{i:y_i=k}x_i}\\{\hat{\sigma}^2 =\dfrac{1}{n-K}\sum\limits_{k=1}^K\sum\limits_{i:y_i=k}(x_i-\hat{\mu}_k)^2}\end{cases}} ????????????????��k?(x)=ln(gk?(x))=ln��k?+��2��?x?2��2��2?��^?k?=nk?1?i:yi?=k��?xi?��^2=n?K1?k=1��K?i:yi?=k��?(xi??��^?k?)2?
����,���ǵ�ģ�;ͽ��������,����ֻ��Ҫ����������� �� k ( x ) {\delta_k(x)} ��k?(x),�ĸ� k {k} k��Ӧ�� �� k ( x ) {\delta_k(x)} ��k?(x)��,������һ�ࡣ
(��ͼ�����������б�����ľ��߽߱�,��̬�����ı߸�����������һ��)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-lqGikLQQ-1629813682644)(./1.25.png)]](https://img-blog.csdnimg.cn/d99ee4246e9f41bfbd725c470364c89c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_Q1NETiBAemFwcmlseQ==,size_42,color_FFFFFF,t_70,g_se,x_16) �����Ƶ�����һ���Ա����ļ�ģ��,��Ҫ����Ϊ����Ա����������б������,��
p
>
1
{p>1}
p>1����ʵԭ��һ����,ֻ�ǽ�һԪ��̬�ֲ���չΪ��Ԫ��̬�ֲ�:
f
k
(
x
)
=
1
(
2
��
)
p
2
�O
��
�O
1
2
e
[
?
1
2
(
x
?
��
k
)
T
��
?
1
(
x
?
��
k
)
]
{f_k(x)=\dfrac{1}{(2\pi)^{\tfrac{p}{2}}|\Sigma|^\tfrac{1}{2}}e^{[-\tfrac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k)]}}
fk?(x)=(2��)2p?�O���O21?1?e[?21?(x?��k?)T��?1(x?��k?)]
��
k
^
=
(
��
k
1
,
��
k
2
,
.
.
.
.
.
.
,
��
k
p
)
,
��
^
=
1
p
?
1
��
j
=
1
p
(
x
j
?
x
��
)
(
x
j
?
x
��
)
T
{\hat{\mu_k}=(\mu_{k1},\mu_{k2},......,\mu_{kp}) , \hat{\Sigma}=\dfrac{1}{p-1}\sum\limits_{j=1}^p(x_j-\overline{x})(x_j-\overline{x})^T}
��k?^?=(��k1?,��k2?,......,��kp?),��^=p?11?j=1��p?(xj??x)(xj??x)T
�����Ƶ�����һ���Ա����ļ�ģ��,��Ҫ����Ϊ����Ա����������б������,��
p
>
1
{p>1}
p>1����ʵԭ��һ����,ֻ�ǽ�һԪ��̬�ֲ���չΪ��Ԫ��̬�ֲ�:
f
k
(
x
)
=
1
(
2
��
)
p
2
�O
��
�O
1
2
e
[
?
1
2
(
x
?
��
k
)
T
��
?
1
(
x
?
��
k
)
]
{f_k(x)=\dfrac{1}{(2\pi)^{\tfrac{p}{2}}|\Sigma|^\tfrac{1}{2}}e^{[-\tfrac{1}{2}(x-\mu_k)^T\Sigma^{-1}(x-\mu_k)]}}
fk?(x)=(2��)2p?�O���O21?1?e[?21?(x?��k?)T��?1(x?��k?)]
��
k
^
=
(
��
k
1
,
��
k
2
,
.
.
.
.
.
.
,
��
k
p
)
,
��
^
=
1
p
?
1
��
j
=
1
p
(
x
j
?
x
��
)
(
x
j
?
x
��
)
T
{\hat{\mu_k}=(\mu_{k1},\mu_{k2},......,\mu_{kp}) , \hat{\Sigma}=\dfrac{1}{p-1}\sum\limits_{j=1}^p(x_j-\overline{x})(x_j-\overline{x})^T}
��k?^?=(��k1?,��k2?,......,��kp?),��^=p?11?j=1��p?(xj??x)(xj??x)T
�� k ( x ) = l n ( �� k f k ( x ) ) = l n ( �� k ) ? ( p 2 l n ( 2 �� ) + 1 2 l n ( �O �� �O ) ) ? 1 2 ( x ? �� k ) T �� ? 1 ( x ? �� k ) = x T �� ^ �� ^ k ? 1 2 �� ^ k T �� ^ ? 1 �� ^ k + l n �� ^ k {\delta_k(x) = ln(\pi_kf_k(x))=ln(\pi_k)-(\dfrac{p}{2}ln(2\pi)+\dfrac{1}{2}ln(|\Sigma|))-\dfrac{1}{2}(x-\mu_k)^T\Sigma^-1(x-\mu_k)=x^T\hat{\Sigma}\hat{\mu}_k-\dfrac{1} {2}\hat{\mu}_k^T\hat{\Sigma}^{-1}\hat{\mu}_k+ln\hat{\pi}_k} ��k?(x)=ln(��k?fk?(x))=ln(��k?)?(2p?ln(2��)+21?ln(�O���O))?21?(x?��k?)T��?1(x?��k?)=xT��^��^?k??21?��^?kT?��^?1��^?k?+ln��^k? - ��ά�����˼�����������б����:
��������P60~63�Ƚ����,������
���ر�Ҷ˹
�������б������,���Ǽ���ÿ�ַ�������µ�������ѭͬһ��Э�������,ÿ��������֮���Ǵ���Э�����,����������б�����и��������Dz��Ƕ����ġ�����,���ر�Ҷ˹�㷨�������б��������һ����ģ�ͼ�,���������б�����е�Э��������е�Э����ȫ�����0,ֻ�������������ķ���,Ҳ�������ر�Ҷ˹�����������֮���Dz���صġ���֮ǰ��������ƫ��-����������,����֪��ģ�͵ļ��Դ�������ļ��ٵ�������ƫ��,������ر�Ҷ˹Ҳ������,���������б����ģ�͵ķ���С,ƫ�����Ȼ����ģ��,ʵ����ʹ�����ر�Ҷ˹�İ����dz���,�������������б����,���綦�����������ŷ���,�����ʼ�����ȡ�
������ :
��ǰ�����������ľ������ع������һ����,ֻ���ڻع�������,ѡ��ָ��ı��Ǿ������,�����ڷ���������,�������������������������������,����þ��������Ȼ�����ʡ�����������ʲô��Ϊѡ��ָ��ı���?���������������������:
�ڻع�����,��һ�������Ĺ۲�ֵ,�������Ԥ��ֵȡ���������ն˽����ѵ������ƽ�����������֮���Ӧ,���ڷ�������˵,����һ���۲�ֵ,�������Ԥ��ֵΪ���������ն˽����ѵ����������ֵ������������Ĺ��������ع���Ҳ������,��ع���һ��,������Ҳ�Dz��õݹ������ѡ������ڷ�������,�����������Ϊȷ�����ѽڵ����,һ������Ȼ�����ָ���Ƿ�������ʡ���������ʾ���:�������ڵ�ѵ�����зdz�������ռ�����,��:
E
=
1
?
m
a
x
k
(
p
^
m
k
)
E = 1-max_k(\hat{p}_{mk})
E=1?maxk?(p^?mk?) ��ʽ�е�
p
^
m
k
\hat{p}_{mk}
p^?mk?������m�������ѵ�����е�k����ռ�ı����������ڴ�������ʵ֤��:����������ڹ���������ʱ��������,һ����ʵ��������������ָ�����:
(1) ����ϵ��:
G
=
��
k
=
1
K
p
^
m
k
(
1
?
p
^
m
k
)
G = \sum\limits_{k=1}^{K} \hat{p}_{mk}(1-\hat{p}_{mk})
G=k=1��K?p^?mk?(1?p^?mk?) �ڻ���ϵ���Ķ�����,���Ƿ������ָ���������K�������ܷ�����ѷ���,������е�
p
^
m
k
\hat{p}_{mk}
p^?mk?��ȡֵ���ӽ�0����1,����ϵ�����С����˻���ϵ������Ϊ������㴿�ȵ�ָ��----�������ȡֵС,�Ǿ���ζ��ij���ڵ�����Ĺ۲�ֵ��������ͬһ�����
�ɻ���ϵ����Ϊָ��õ��ķ���������:CART��
(2) ������:
�����������ϵ����ָ���ǽ�����,��������:
D
=
?
��
k
=
1
K
p
^
m
k
l
o
g
??
p
^
m
k
D = -\sum\limits_{k=1}^{K} \hat{p}_{mk}log\;\hat{p}_{mk}
D=?k=1��K?p^?mk?logp^?mk? ��Ȼ,������е�
p
^
m
k
\hat{p}_{mk}
p^?mk?���ӽ���0����1,��ô�����ؾͻ�ӽ�0�����,�ͻ���ϵ��һ��,�����m�����Ĵ���Խ��,����ԽС����ʵ֤��,����ϵ���ͽ���������ֵ��ʱ�ܽӽ��ġ� ![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-MnPiVRt8-1629814577551)(./1.27.png)]](https://img-blog.csdnimg.cn/2bc434ffeddb444d84eb62599acff82c.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_Q1NETiBAemFwcmlseQ==,size_17,color_FFFFFF,t_70,g_se,x_16)
�����������㷨����������:
a. ѡ�������з�����j�Լ��������ϵ����ŵ�s:
��������j�Լ��̶�j������зֵ�s,ѡ��ʹ�û���ϵ�����߽�������С��(j,s)
b. ����(j,s)���������ռ�,ÿ�������ڵ����Ϊ�����������������������
c. �������ò���1,2ֱ������ֹͣ����,����ÿ�������������С�ڵ���5��
d. �������ռ仮��ΪJ����ͬ������,���ɷ�������
֧��������
֧��������SVM��20����90����ڼ�����緢չ������һ�ַ����㷨,�����������ж���֤���нϺõ�Ч��,����Ϊ����Ӧ�������㷨֮һ��
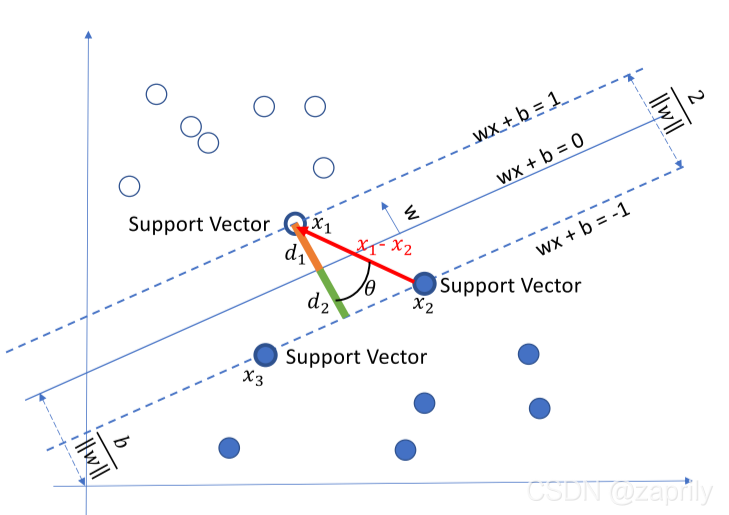
֧���������Ļ���ԭ���dz���,��ͼ����,��ɫ����ɫ�ĵ��Ϊһ��,���ǵ�Ŀ�����ҵ�һ���ָ�ƽ�潫�������ֿ���ͨ����˵,������ݱ��������Կɷֵ�,��ô��ʵ�ϴ��������������ij�ƽ�档������Ϊ����һ���ָ�ƽ�����������ƻ���ת�����ƽ��,ֻҪ���Ӵ���Щ�۲��,��Ȼ���Խ����ݷֿ���һ������Ȼ���뷨�����ҵ��������ƽ��,���ҵ�һ���ָ�ƽ���������Ĺ۲����Զ�������������ϸ��Ƶ�:
���Ǹ��ݾ��볬ƽ��������ĵ�,ֻҪͬʱ����w��b���Եõ�:
w
T
x
1
+
b
=
1
w^Tx_1 + b = 1
wTx1?+b=1��
w
T
x
2
+
b
=
?
1
w^Tx_2+b = -1
wTx2?+b=?1,���:
w
T
x
1
+
b
=
1
w
T
x
2
+
b
=
?
1
(
w
T
x
1
+
b
)
?
(
w
T
x
2
+
b
)
=
2
w
T
(
x
1
?
x
2
)
=
2
w
T
(
x
1
?
x
2
)
=
��
w
��
2
��
x
1
?
x
2
��
2
cos
?
��
=
2
��
x
1
?
x
2
��
2
cos
?
��
=
2
��
w
��
2
d
1
=
d
2
=
��
x
1
?
x
2
��
2
cos
?
��
2
=
2
��
w
��
2
2
=
1
��
w
��
2
d
1
+
d
2
=
2
��
w
��
2
\begin{array}{l} w^{T} x_{1}+b=1 \\ w^{T} x_{2}+b=-1 \\ \left(w^{T} x_{1}+b\right)-\left(w^{T} x_{2}+b\right)=2 \\ w^{T}\left(x_{1}-x_{2}\right)=2 \\ \qquad \begin{array}{l} w^{T}\left(x_{1}-x_{2}\right)=\|w\|_{2}\left\|x_{1}-x_{2}\right\|_{2} \cos \theta=2 \\ \left\|x_{1}-x_{2}\right\|_{2} \cos \theta=\frac{2}{\|w\|_{2}} \end{array} \\ \qquad \begin{array}{l} d_{1}=d_{2}=\frac{\left\|x_{1}-x_{2}\right\|_{2} \cos \theta}{2}=\frac{\frac{2}{\|w\|_{2}}}{2}=\frac{1}{\|w\|_{2}} \\ d_{1}+d_{2}=\frac{2}{\|w\|_{2}} \end{array} \end{array}
wTx1?+b=1wTx2?+b=?1(wTx1?+b)?(wTx2?+b)=2wT(x1??x2?)=2wT(x1??x2?)=��w��2?��x1??x2?��2?cos��=2��x1??x2?��2?cos��=��w��2?2??d1?=d2?=2��x1??x2?��2?cos��?=2��w��2?2??=��w��2?1?d1?+d2?=��w��2?2??? �ɴ˿�֪��SVMģ�͵ľ�����ʽ:
min
?
w
,
b
1
2
��
w
��
2
?s.t.?
y
(
i
)
(
w
T
x
(
i
)
+
b
)
��
1
,
i
=
1
,
��
,
n
\begin{aligned} \min _{w, b} & \frac{1}{2}\|w\|^{2} \\ \text { s.t. } & y^{(i)}\left(w^{T} x^{(i)}+b\right) \geq 1, \quad i=1, \ldots, n \end{aligned}
w,bmin??s.t.??21?��w��2y(i)(wTx(i)+b)��1,i=1,��,n? ���Խ�Լ������дΪ:
g
i
(
w
)
=
?
y
(
i
)
(
w
T
x
(
i
)
+
b
)
+
1
��
0
g_{i}(w)=-y^{(i)}\left(w^{T} x^{(i)}+b\right)+1 \leq 0
gi?(w)=?y(i)(wTx(i)+b)+1��0
���Խ��Ż������������ջ�
L
(
w
,
b
,
��
)
=
1
2
��
w
��
2
?
��
i
=
1
n
��
i
[
y
(
i
)
(
w
T
x
(
i
)
+
b
)
?
1
]
\mathcal{L}(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum_{i=1}^{n} \alpha_{i}\left[y^{(i)}\left(w^{T} x^{(i)}+b\right)-1\right]
L(w,b,��)=21?��w��2?i=1��n?��i?[y(i)(wTx(i)+b)?1]
���:
L
(
w
,
b
,
��
)
=
1
2
��
w
��
2
?
��
i
=
1
n
��
i
[
y
(
i
)
(
w
T
x
(
i
)
+
b
)
?
1
]
\mathcal{L}(w, b, \alpha)=\frac{1}{2}\|w\|^{2}-\sum_{i=1}^{n} \alpha_{i}\left[y^{(i)}\left(w^{T} x^{(i)}+b\right)-1\right]
L(w,b,��)=21?��w��2?i=1��n?��i?[y(i)(wTx(i)+b)?1]
������ dual ����, �������������ջ���������
w
\mathrm{w}
w ��
b
\mathrm{b}
b ��ֵ, ��
w
\mathrm{w}
w ���ݶ�, ���ݶ�Ϊ 0, ����� w:
�� b ���ݶ�, ���ݶ�Ϊ 0, �ɵ�:
?
?
b
L
(
w
,
b
,
��
)
=
��
i
=
1
n
��
i
y
(
i
)
=
0
\frac{\partial}{\partial b} \mathcal{L}(w, b, \alpha)=\sum_{i=1}^{n} \alpha_{i} y^{(i)}=0
?b??L(w,b,��)=i=1��n?��i?y(i)=0 ��
w
\mathrm{w}
w �����������ջ���ԭ����ɵ�
L
(
w
,
b
,
��
)
=
��
i
=
1
n
��
i
?
1
2
��
i
,
j
=
1
n
y
(
i
)
y
(
j
)
��
i
��
j
(
x
(
i
)
)
T
x
(
j
)
?
b
��
i
=
1
n
��
i
y
(
i
)
L
(
w
,
b
,
��
)
=
��
i
=
1
n
��
i
?
1
2
��
i
,
j
=
1
n
y
(
i
)
y
(
j
)
��
i
��
j
(
x
(
i
)
)
T
x
(
j
)
\begin{array}{l} \mathcal{L}(w, b, \alpha)=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} y^{(i)} y^{(j)} \alpha_{i} \alpha_{j}\left(x^{(i)}\right)^{T} x^{(j)}-b \sum_{i=1}^{n} \alpha_{i} y^{(i)} \\ \mathcal{L}(w, b, \alpha)=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} y^{(i)} y^{(j)} \alpha_{i} \alpha_{j}\left(x^{(i)}\right)^{T} x^{(j)} \end{array}
L(w,b,��)=��i=1n?��i??21?��i,j=1n?y(i)y(j)��i?��j?(x(i))Tx(j)?b��i=1n?��i?y(i)L(w,b,��)=��i=1n?��i??21?��i,j=1n?y(i)y(j)��i?��j?(x(i))Tx(j)?
���:
?���������ջ���ԭ��������Сֵ,?�õ���?
w
?,?���ڿ��Թ���?dual?���}?
max
?
��
W
(
��
)
=
��
i
=
1
n
��
i
?
1
2
��
i
,
j
=
1
n
y
(
i
)
y
(
j
)
��
i
��
j
?
x
(
i
)
,
x
(
j
)
?
?s.t.?
��
i
��
0
,
i
=
1
,
��
,
n
��
i
=
1
n
��
i
y
(
i
)
=
0
?�����Ƶ���?b��ֵΪ:?
b
?
=
?
max
?
i
:
y
(
i
)
=
?
1
w
?
T
x
(
i
)
+
min
?
i
:
y
(
i
)
=
1
w
?
T
x
(
i
)
2
?SVM�ľ���������,ֵ�ķ���Ϊ���.?
w
T
x
+
b
=
(
��
i
=
1
n
��
i
y
(
i
)
x
(
i
)
)
T
x
+
b
=
��
i
=
1
n
��
i
y
(
i
)
?
x
(
i
)
,
x
?
+
b
\begin{aligned} &\text { ���������ջ���ԭ��������Сֵ, �õ��� } \mathrm{w} \text { , ���ڿ��Թ��� dual ���} }\\ &\begin{aligned} \max _{\alpha} & W(\alpha)=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i, j=1}^{n} y^{(i)} y^{(j)} \alpha_{i} \alpha_{j}\left\langle x^{(i)}, x^{(j)}\right\rangle \\ \text { s.t. } & \alpha_{i} \geq 0, \quad i=1, \ldots, n \\ & \sum_{i=1}^{n} \alpha_{i} y^{(i)}=0 \end{aligned}\\ &\text { �����Ƶ��� b��ֵΪ: } b^{*}=-\frac{\max _{i: y^{(i)}=-1} w^{* T} x^{(i)}+\min _{i: y^{(i)}=1} w^{* T} x^{(i)}}{2}\\ &\begin{array}{r} \text { SVM�ľ���������,ֵ�ķ���Ϊ���. } \\ \qquad w^{T} x+b=\left(\sum_{i=1}^{n} \alpha_{i} y^{(i)} x^{(i)}\right)^{T} x+b=\sum_{i=1}^{n} \alpha_{i} y^{(i)}\left\langle x^{(i)}, x\right\rangle+b \end{array} \end{aligned}
??���������ջ���ԭ��������Сֵ,?�õ���?w?,?���ڿ��Թ���?dual?���}?��max??s.t.??W(��)=i=1��n?��i??21?i,j=1��n?y(i)y(j)��i?��j??x(i),x(j)?��i?��0,i=1,��,ni=1��n?��i?y(i)=0??�����Ƶ���?b��ֵΪ:?b?=?2maxi:y(i)=?1?w?Tx(i)+mini:y(i)=1?w?Tx(i)??SVM�ľ���������,ֵ�ķ���Ϊ���.?wTx+b=(��i=1n?��i?y(i)x(i))Tx+b=��i=1n?��i?y(i)?x(i),x?+b??
������֧��������
������Ӧ����δ���������������?�𰸾��ǽ�����ͶӰ�����Ӹߵ�ά��!
��
:
X
?
X
^
=
��
(
x
)
��
(
[
x
i
1
,
x
i
2
]
)
=
[
x
i
1
,
x
i
2
,
x
i
1
x
i
2
,
x
i
1
2
,
x
i
2
2
]
\begin{array}{l} \Phi: \mathcal{X} \mapsto \hat{\mathcal{X}}=\Phi(\mathbf{x}) \\ \Phi\left(\left[x_{i 1}, x_{i 2}\right]\right)=\left[x_{i 1}, x_{i 2}, x_{i 1} x_{i 2}, x_{i 1}^{2}, x_{i 2}^{2}\right] \end{array}
��:X?X^=��(x)��([xi1?,xi2?])=[xi1?,xi2?,xi1?xi2?,xi12?,xi22?]? �������ʹ�����湫ʽ����ʽ����ά������չ����ά����,���������һ���ܴ������,�Ǿ���:ά�ȱ�ը���µļ�����̫������⡣������һ��2ά����������,���ǿ��Խ���ӳ�䵽5ά�����������ڻ�,���ԭʼ�ռ�����ά,����ӳ�䵽��19ά�ռ�,�ƺ������Դ���������������ǵĵ�ά������100��ά��,1000��ά����?��ô����Ҫ����ӳ�䵽�����ߵ�ά���������������ڻ�����ʱ��ӳ��ɵĸ�άά���DZ�ը��������,���������ʵ����̫����,���������������ά�����,�����Ӽ����ˡ��ܲ����ظ��������������?�˺���¡�صdz�:
�ع����Կɷ�SVM���Ż�Ŀ�꺯��:
m
i
n
?
��
1
2
��
i
=
1
,
j
=
1
m
��
i
��
j
y
i
y
j
x
i
?
x
j
?
��
i
=
1
m
��
i
s
.
t
.
??
��
i
=
1
m
��
i
y
i
=
0
0
��
��
i
��
C
\underbrace{ min }_{\alpha} \frac{1}{2}\sum\limits_{i=1,j=1}^{m}\alpha_i\alpha_jy_iy_jx_i \bullet x_j - \sum\limits_{i=1}^{m}\alpha_i\\ s.t. \; \sum\limits_{i=1}^{m}\alpha_iy_i = 0\\ 0 \leq \alpha_i \leq C
��
min??21?i=1,j=1��m?��i?��j?yi?yj?xi??xj??i=1��m?��i?s.t.i=1��m?��i?yi?=00����i?��C ע���ʽ��ά�����������ڻ�
x
i
?
x
j
x_i \bullet x_j
xi??xj? ����ʽ����,������Ƕ���һ����ά�����ռ䵽��ά�����ռ��ӳ��
?
\phi
?,����������ӳ�䵽һ�����ߵ�ά��,���������Կɷ�,���ǾͿ��Լ�����ǰ��ƪ�ķ������Ż�Ŀ�꺯��,������볬ƽ��ͷ�����ߺ����ˡ�Ҳ����˵���ڵ�SVM���Ż�Ŀ�꺯�����:
min
?
?
��
1
2
��
i
=
1
,
j
=
1
m
��
i
��
j
y
i
y
j
?
(
x
i
)
?
?
(
x
j
)
?
��
i
=
1
m
��
i
?s.?
t
.
��
i
=
1
m
��
i
y
i
=
0
0
��
��
i
��
C
\begin{array}{c} \underbrace{\min }_{\alpha} \frac{1}{2} \sum_{i=1, j=1}^{m} \alpha_{i} \alpha_{j} y_{i} y_{j} \phi\left(x_{i}\right) \bullet \phi\left(x_{j}\right)-\sum_{i=1}^{m} \alpha_{i} \\ \text { s. } t . \sum_{i=1}^{m} \alpha_{i} y_{i}=0 \\ 0 \leq \alpha_{i} \leq C \end{array}
��
min??21?��i=1,j=1m?��i?��j?yi?yj??(xi?)??(xj?)?��i=1m?��i??s.?t.��i=1m?��i?yi?=00����i?��C?
���Կ���,�����Կɷ�SVM���Ż�Ŀ�꺯������������ǽ��ڻ�
x
i
?
x
j
x_i \bullet x_j
xi??xj?�滻Ϊ
?
(
x
i
)
?
?
(
x
j
)
\phi(x_i) \bullet \phi(x_j)
?(xi?)??(xj?)������Ҫ����ӳ�䵽�����ߵ�ά���������������ڻ�����ʱ��ӳ��ɵĸ�άά���DZ�ը��������,���������ʵ����̫����,���������������ά�����,�����Ӽ����ˡ���������˺���:
����
?
\phi
?��һ���ӵ�ά������ռ�
��
\chi
��(ŷʽ�ռ���Ӽ�������ɢ����)����ά��ϣ�����ؿռ��
H
\mathcal{H}
Hӳ�䡣��ô������ں���
K
(
x
,
z
)
K(x,z)
K(x,z),��������
x
,
z
��
��
x, z \in \chi
x,z����,����:
K
(
x
,
z
)
=
?
(
x
)
?
?
(
z
)
K(x, z) = \phi(x) \bullet \phi(z)
K(x,z)=?(x)??(z)
��ô���Ǿͳ�
K
(
x
,
z
)
K(x, z)
K(x,z)Ϊ�˺�����
��ϸ����,
K
(
x
,
z
)
K(x, z)
K(x,z)�ļ������ڵ�ά�����ռ��������,���������ڸղ������ᵽ���ڸ�άά�ȿռ�����ڻ��Ŀֲ���������Ҳ����˵,���ǿ��Ժú������ڸ�ά�����ռ����Կɷֵ�����,ȴ�����˸�ά�����ռ�ֲ����ڻ���������������ܼ��ֳ��õĺ˺���:
(1) ����ʽ�˺���:
����ʽ�˺���(Polynomial Kernel)�����Բ��ɷ�SVM���õĺ˺���֮һ,����ʽΪ:
K
(
x
i
,
x
j
)
=
(
?
x
i
,
x
j
?
+
c
)
d
K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\left(\left\langle\mathbf{x}_{i}, \mathbf{x}_{j}\right\rangle+c\right)^{d}
K(xi?,xj?)=(?xi?,xj??+c)d
C�������Ƶͽ����ǿ��,C=0,d=1�����˺�����
(2) ��˹�˺���:
��˹�˺���(Gaussian Kernel),��SVM��Ҳ��Ϊ������˺���(Radial Basis Function,RBF),���Ƿ����Է���SVM�������ĺ˺�����libsvmĬ�ϵĺ˺���������������ʽΪ:
K
(
x
i
,
x
j
)
=
exp
?
(
?
��
x
i
?
x
j
��
2
2
2
��
2
)
K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\exp \left(-\frac{\left\|\mathbf{x}_{i}-\mathbf{x}_{j}\right\|_{2}^{2}}{2 \sigma^{2}}\right)
K(xi?,xj?)=exp(?2��2��xi??xj?��22??)
ʹ�ø�˹�˺���֮ǰ��Ҫ����������,������������������֮������ƶȡ�
(3) Sigmoid�˺���:
Sigmoid�˺���(Sigmoid Kernel)Ҳ�����Բ��ɷ�SVM���õĺ˺���֮һ,����ʽΪ:
K
(
x
i
,
x
j
)
=
tanh
?
(
��
x
i
?
x
j
+
c
)
K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\tanh \left(\alpha \mathbf{x}_{i}^{\top} \mathbf{x}_{j}+c\right)
K(xi?,xj?)=tanh(��xi??xj?+c) ��ʱ��SVM�൱��û�����ز�ļ������硣
(4) �������ƶȺ�:
�����ں����������ֵ��������ƶ�,����ʽΪ:
K
(
x
i
,
x
j
)
=
x
i
?
x
j
��
x
i
��
��
x
j
��
K\left(\mathbf{x}_{i}, \mathbf{x}_{j}\right)=\frac{\mathbf{x}_{i}^{\top} \mathbf{x}_{j}}{\left\|\mathbf{x}_{i}\right\|\left\|\mathbf{x}_{j}\right\|}
K(xi?,xj?)=��xi?����xj?��xi??xj??
����ģ�͵����ܲ�����:
����ϸ�Ŀ��Բ鿴���ߵ�֪��
�ڶ����������滹�л��ƻ��������ROC���ߵ�ʵ�����ڴ�չʾ
���������ͼ
��������ʵ��
ROC������
��ҵ
- �ع�����ͷ����������ϵ������,������ûع����������������?
- Ϊʲô�����������ʧ���������ǽ�����,�����Ǿ������?
- �����б���������ع��ڹ��Ʋ���������ʲô��ͬ��?
- ���Դ�0�Ƶ�SVM
- �����б����,�����б����,���ر�Ҷ˹֮�����ϵ������?
- ʹ��python+numpyʵ�����ع�
�����
from sklearn import datasets
import pandas as pd
iris = datasets.load_iris()
X = iris.data
Y = iris.target
X = X[Y!=2]
Y=Y[Y!=2]
import numpy as np
import math
class myLogstic():
def fun_lamda(self,beta):
result=0
for i in range(self.Y.shape[0]):
# result+=self.Y[i]*np.dot(beta.T,self.Xb[i])-math.log(1+math.exp(np.dot(beta.T,self.Xb[i])))
p0=1/(1+np.exp(np.dot(beta.T,self.Xb[i])))
result+=self.Y[i]*math.log(1-p0)+(1-self.Y[i])*math.log(p0)
return -1/self.Y.shape[0]*result
def sigmod(self,beta):
result=0
for i in range(self.Y.shape[0]):
gamma=1/(1+np.exp(-np.dot(beta.T,self.Xb[i])))
result+=(self.Y[i]-gamma)*self.Xb[i]
return -result
def Logic_fit(self,learning,interation,X,Y,accuracy = 0.00001):
sample=X.shape[0]
feature=X.shape[1]
self.Xb=np.c_[X,np.ones(sample)]
beta=np.ones(feature+1)*0.5
self.Y=Y
inter=0
while True:
lamda1=self.fun_lamda(beta)
beta1=beta-learning*self.sigmod(beta)
lamda2=self.fun_lamda(beta1)
if lamda1==lamda2 or (math.fabs(lamda1-lamda2)<accuracy):
self.w=beta
break
if interation==inter:
print("������")
beta=beta1
inter+=1
def predict(self,Xtest):
Xb_test=np.c_[Xtest,np.ones(Xtest.shape[0])]
y_pre=np.zeros(Xtest.shape[0])
y_pre_probe=np.zeros((Xtest.shape[0],2))
for i in range(Xtest.shape[0]):
rate=1/(1+np.exp(np.dot(self.w.T,Xb_test[i])))
y_pre_probe[i,0]=rate
y_pre_probe[i,1]=1-rate
if rate <=0.5:
y_pre[i] = 1
else:
y_pre[i] = 0
return y_pre,y_pre_probe
def score(self,X_test,y_test):
y_predict,y_p = self.predict(X_test)
re = (y_test==y_predict)
re1 = Counter(re)
a = re1[True] / (re1[True]+re1[False])
return a
l=myLogstic()
l.Logic_fit(0.01,1000,X,Y)
l.predict(X)
l.score(X,Y)
