1 数据科学概念
数据科学是一个发现、解释数据中的模式并用于解决问题的过程。数据科学可以从数据中获取知识,为行动提出建议的方法、技术和流程,以完成商业或工业上的目标。
下图所示流程为数据科学的工作范式。反过来即为建模步骤。
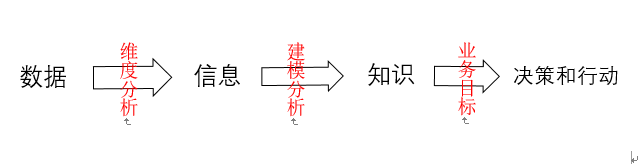
数据学是数据科学的基础。数据学研究数据本身,研究数据的各种类型、状态、属性及变化规律;数据科学是为科学研究的数据方法。
2 数理统计技术
2.1 描述性统计分析
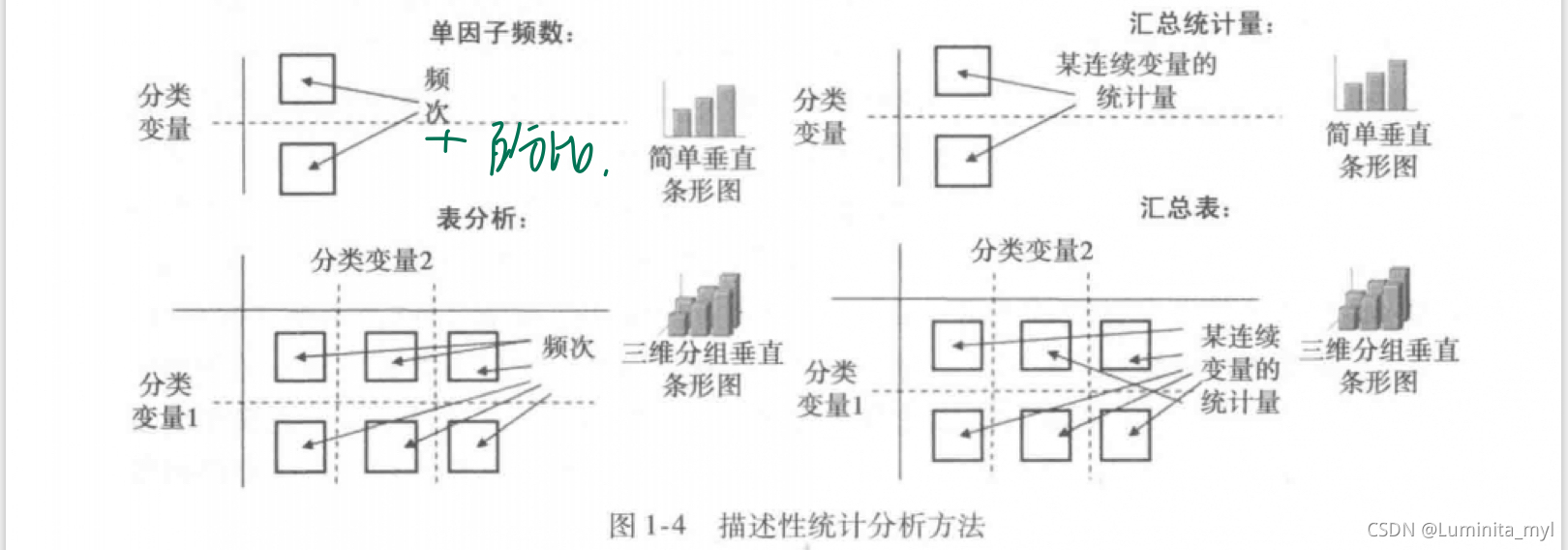
描述性统计分析就是从总体数据种提炼变量的主要信息,即统计量。可以反映出业务发展状况及影响因素,是商业智能和数据可视化的基础。
数据分为分类变量和连续变量。分类变量是维度指标,用于分组;连续变量是度量指标。
2.2 统计推断与统计建模
通过描述性统计发现的影响因素是否为规律,需要进行统计检验。统计推断与统计建模是建立解释变量与被解释变量之间可解释的、稳定的、有因果关系的表达式。

3 数据挖掘的技术与方法
根据业务运用场景,将数据挖掘算法分为5类:预测模型、聚类模型、推荐算法、复杂网络、时间序列。
- 预测模型
根据被解释变量Y的度量类型,预测模型分为分类模型、估计模型。
Y ―> 分类变量 ―> 分类模型
Y ―> 连续变量 ―> 估计模型
- 分类模型
分类模型可分为排序类模型(评分卡)和决策类模型(分类器)。
如果Y为主观的人为定义变量,如信用评分、流失预测、营销响应等,则为排序类模型,输出的结果是类别的概率,常采用逻辑回归建立排序类模型;
如果Y为客观的精确变量,如交易欺诈、人脸识别、声音识别等,则为决策类模型,在进行预测时将会输出准确的类别而非类别的概率,常见方法有贝叶斯网络、最近邻域(KNN算法)、支持向量机(SVM)。
分类模型的评估方法:
分为样本内评估和样本外评估。样本内评估用于检验的数据与建模数据属于同源数据;样本外评估使用下一期的滚动数据。
| 分类模型类型 | 统计指标 |
|---|---|
| 决策(Decisions) | 准确度、召回率、命中率、利润、成本等 |
| 排序(Rankings) | ROC曲线、K-S统计量、提升度等 |
- 估计模型
线性回归、回归树、神经网络
其中决策树、神经网络、组合算法(集成学习)均可适用。
- 聚类模型
聚类模型有两种运用场景:客户细分、识别异常。客户细分可以发现数量客观模式;识别异常用于寻找有差异的个体。
4 实例――构建促销营销策略数据模型
import pandas as pd
import numpy as npp
1. 导入数据
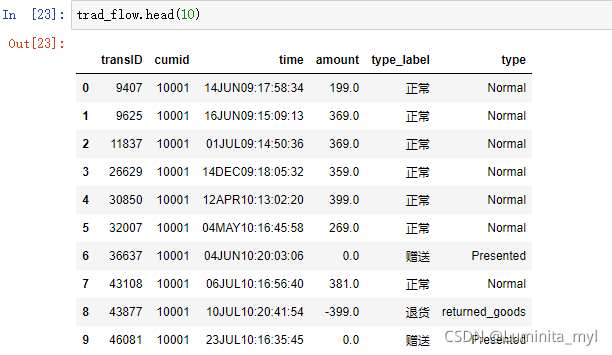
trad_flow=pd.read_csv(r'D:\案例\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\《Python数据科学技术详解与商业实践》PDF+源代码+八大案例\源代码\Python_book\1Introduction\RFM_TRAD_FLOW.csv',encoding='gbk')
F_trans.head()
2. 通过 RFM方法* 建立模型
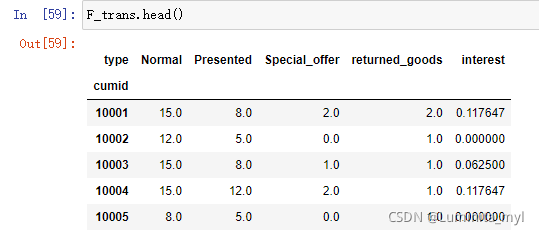
通过计算F(所消费产品中打折产品的占比),反映客户对打折产品的偏好。
F=trad_flow.groupby(['cumid','type'])[['transID']].count()
F_trans=pd.pivot_table(F,index='cumid',columns='type',values='transID')
F_trans['Special_offer']=F_trans['Special_offer'].fillna(0)
F_trans['interest']=F_trans['Special_offer']/(F_trans['Special_offer']+F_trans['Normal'])
F_trans.head()
同样的,计算M(客户消费总量和):反应客户的价值信息
M=trad_flow.groupby(['cumid','type'])[['amount']].sum()
M_trans=pd.pivot_table(M,index='cumid',columns='type',values='amount')
M_trans['Special_offer']=M_trans['Special_offer'].fillna(0)
M_trans['returned_goods']=M_trans['returned_goods'].fillna(0)
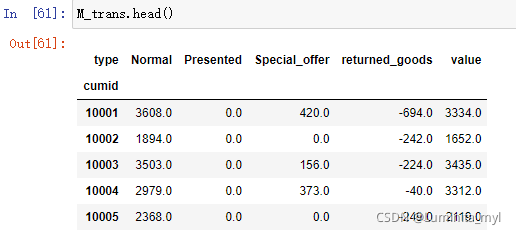
M_trans['value']=M_trans['Normal']+M_trans['Special_offer']+M_trans['returned_goods']
M_trans.head()
!!通过计算R,提取出最新消费时间,反应客户是否为沉默客户
#定义一个从文本转化为时间的函数
from datetime import datetime
import time
def to_time(t):
out_t=time.mktime(time.strptime(t, '%d%b%y:%H:%M:%S')) ########此处修改为时间戳方便后面qcut函数分箱
return out_t
a="14JUN09:17:58:34"
print(to_time(a))
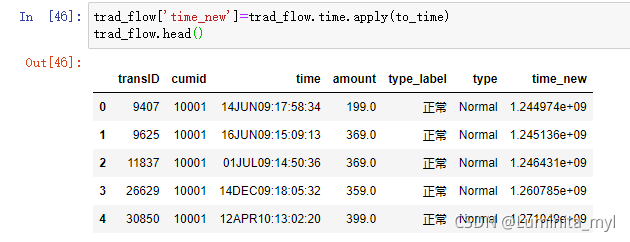
trad_flow['time_new']=trad_flow.time.apply(to_time)
trad_flow.head()
#选择最近的消费时间
R=trad_flow.groupby(['cumid'])[['time_new']].max()
R.head()
3. 构建模型,筛选目标客户 (???)
from sklearn import preprocessing
threshold = pd.qcut(F_trans['interest'], 2, retbins=True)[1][1]
binarizer = preprocessing.Binarizer(threshold=threshold)
interest_q = pd.DataFrame(binarizer.transform(F_trans['interest'].values.reshape(-1, 1)))
interest_q.index=F_trans.index
interest_q.columns=['interest']
threshold = pd.qcut(M_trans['value'], 2, retbins=True)[1][1]
binarizer = preprocessing.Binarizer(threshold=threshold)
value_q = pd.DataFrame(binarizer.transform(M_trans['value'].values.reshape(-1, 1)))
value_q.index=M_trans.index
value_q.columns=['value']
threshold = pd.qcut(R['time_new'], 2, retbins=True)[1][1]
binarizer = preprocessing.Binarizer(threshold=threshold)
time_new_q = pd.DataFrame(binarizer.transform(R['time_new'].values.reshape(-1, 1)))
time_new_q.index=R.index
time_new_q.columns=['time']
analysis=pd.concat([interest_q,value_q,time_new_q],axis=1)
#analysis['rank']=analysis.interest_q+analysis.interest_q
analysis = analysis[['interest','value','time']]
analysis.head()
label = {
(0,0,0):'无兴趣-低价值-沉默',
(1,0,0):'有兴趣-低价值-沉默',
(1,0,1):'有兴趣-低价值-活跃',
(0,0,1):'无兴趣-低价值-活跃',
(0,1,0):'无兴趣-高价值-沉默',
(1,1,0):'有兴趣-高价值-沉默',
(1,1,1):'有兴趣-高价值-活跃',
(0,1,1):'无兴趣-高价值-活跃'
}
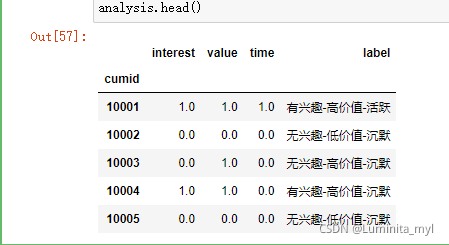
analysis['label'] = analysis[['interest','value','time']].apply(lambda x: label[(x[0],x[1],x[2])], axis = 1)
analysis.head()
*RFM模型:从交易流水数据中获取信息的最简单而通用的方法称为RFM模型。R代表最后一次消费时间,F代表一段时期内消费的频次,M代表一段时期内消费总金额。通过交易流水数据通过RFM模型得到信息后,将每个信息进行二分类,得到客户分群。