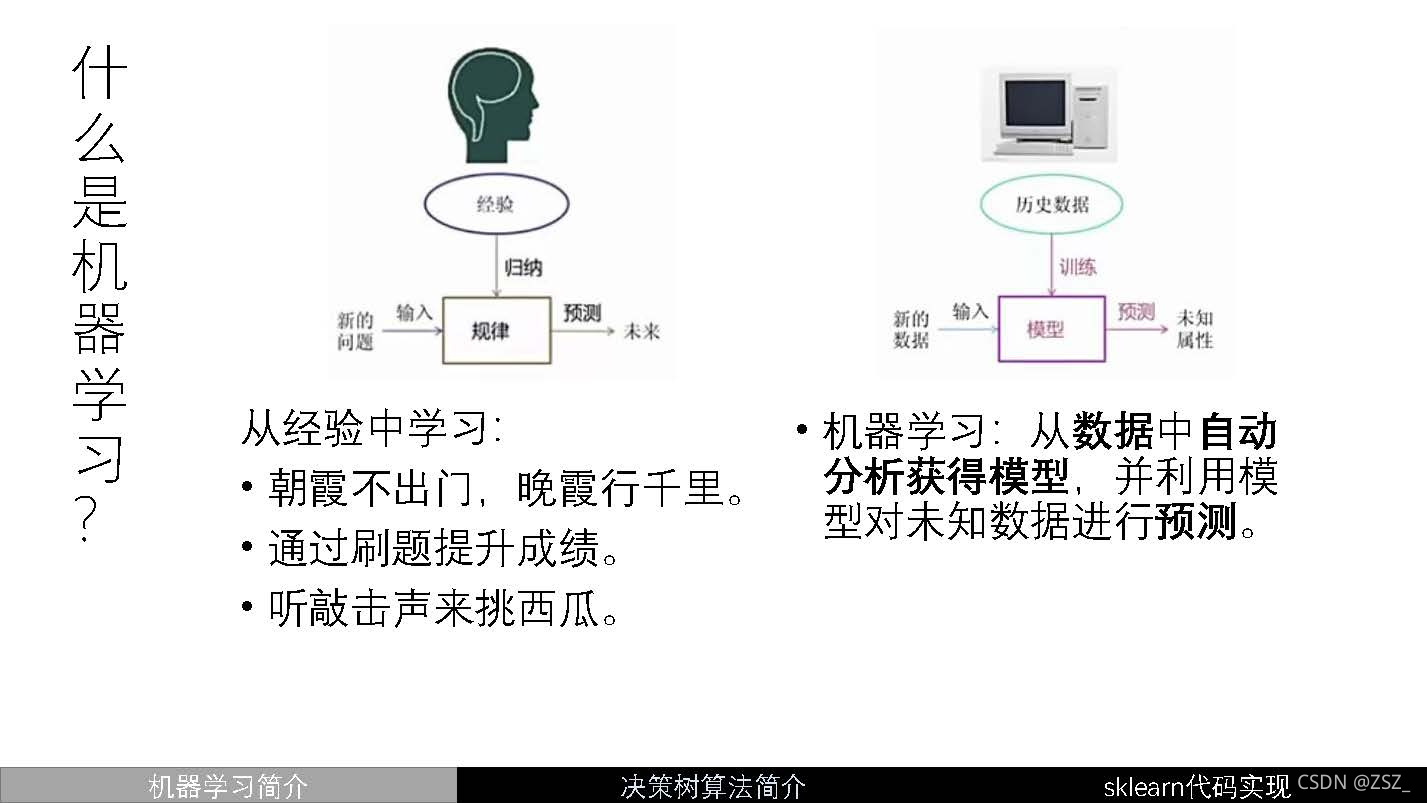
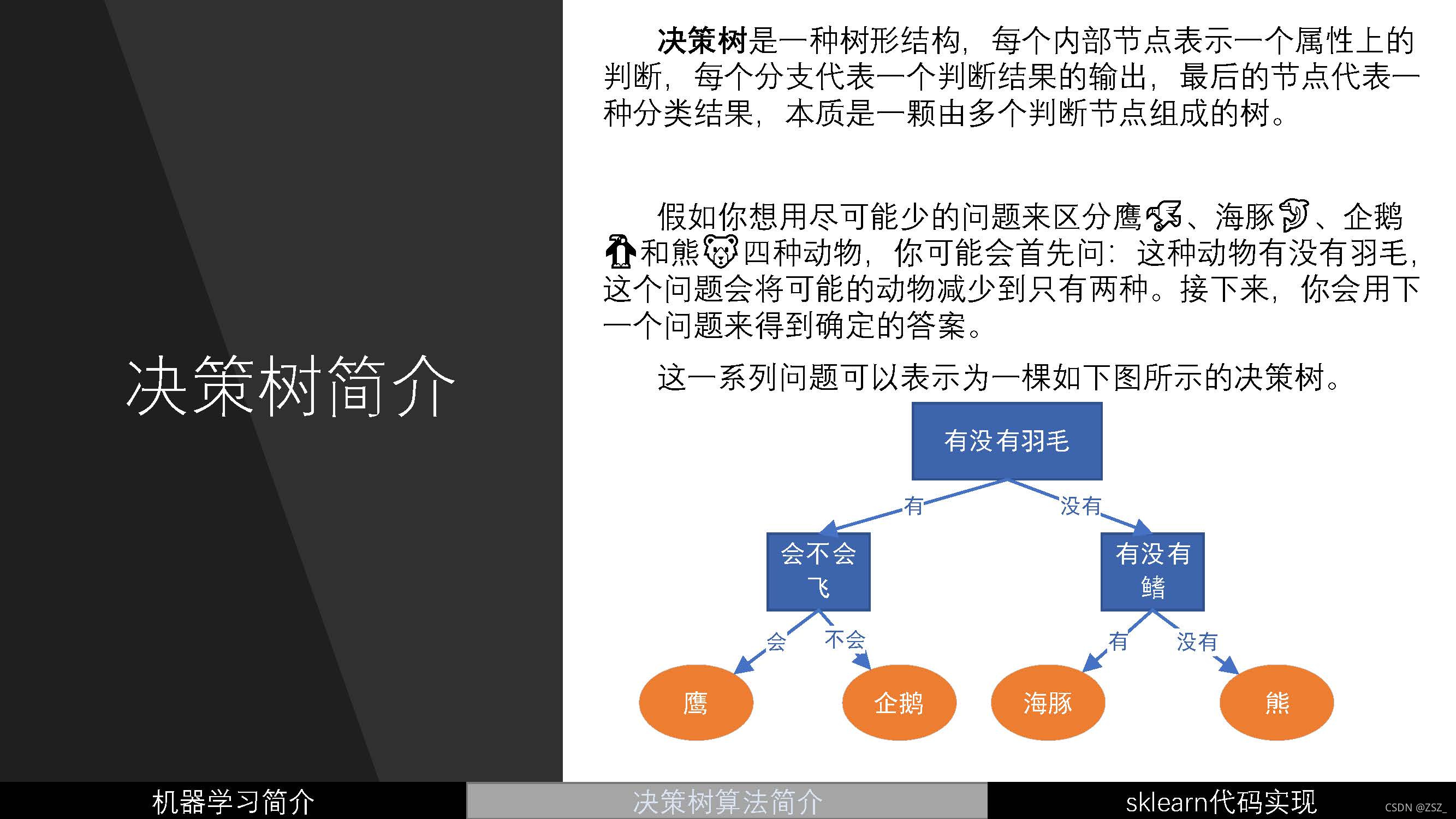
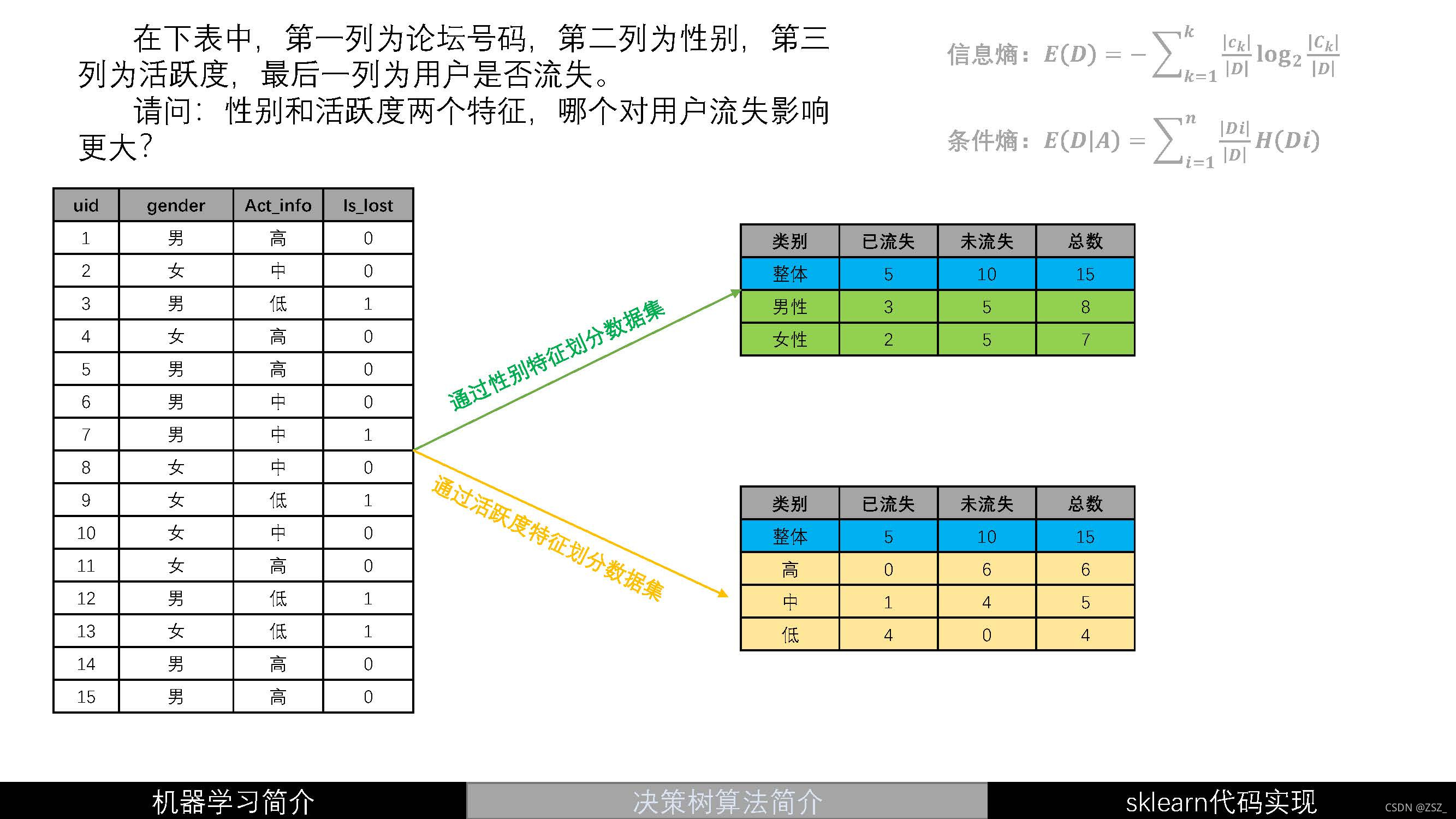
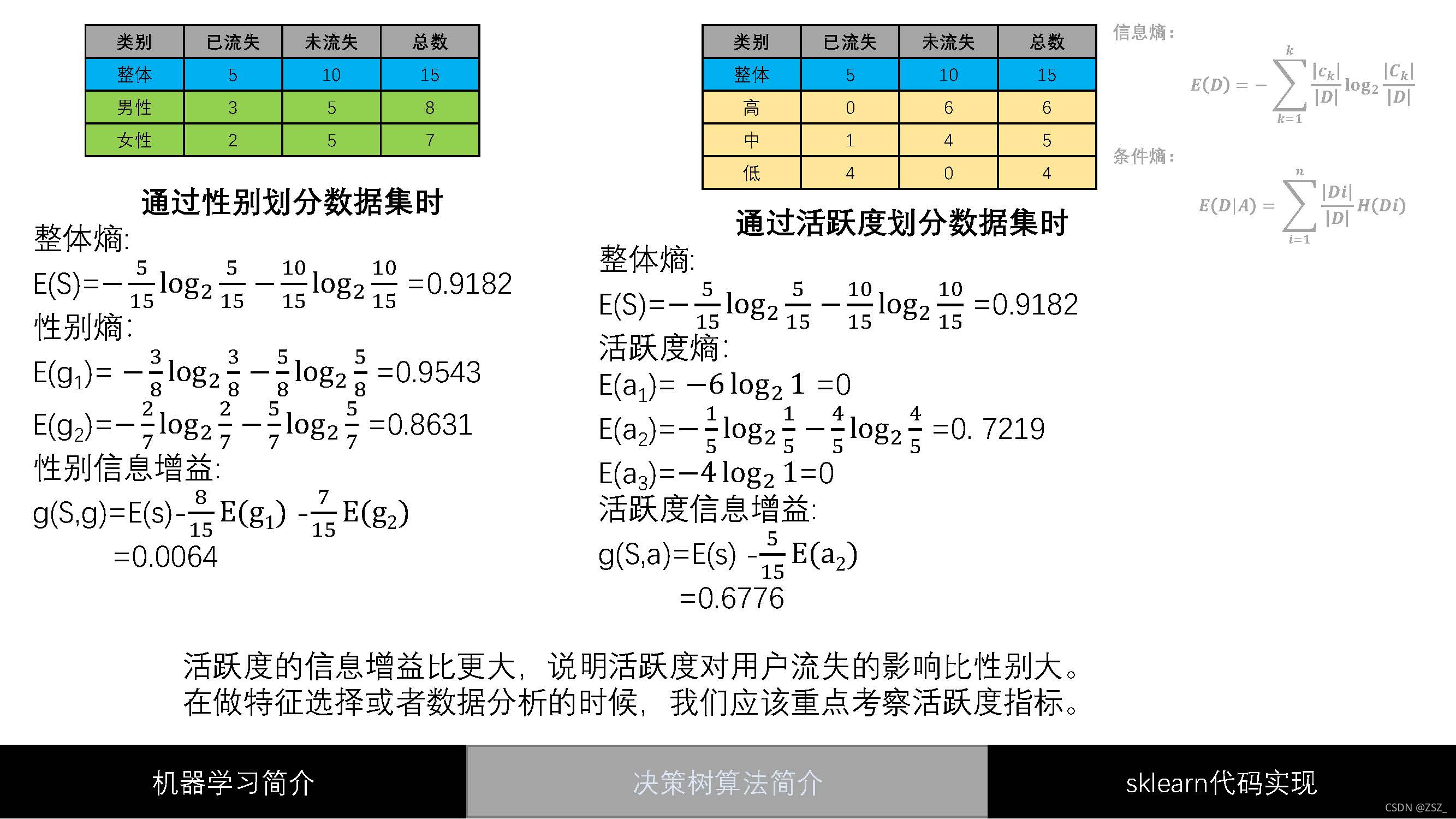
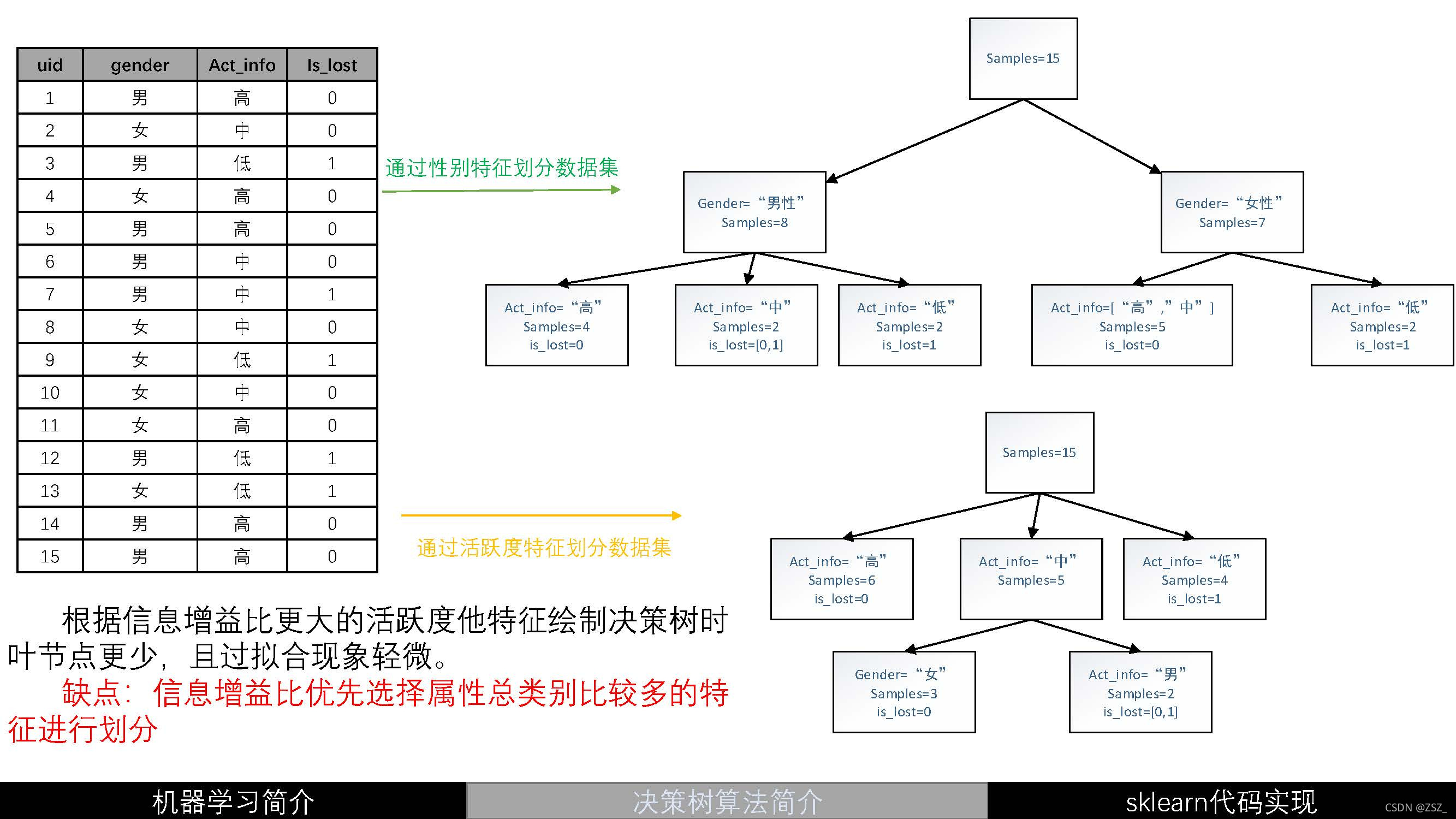
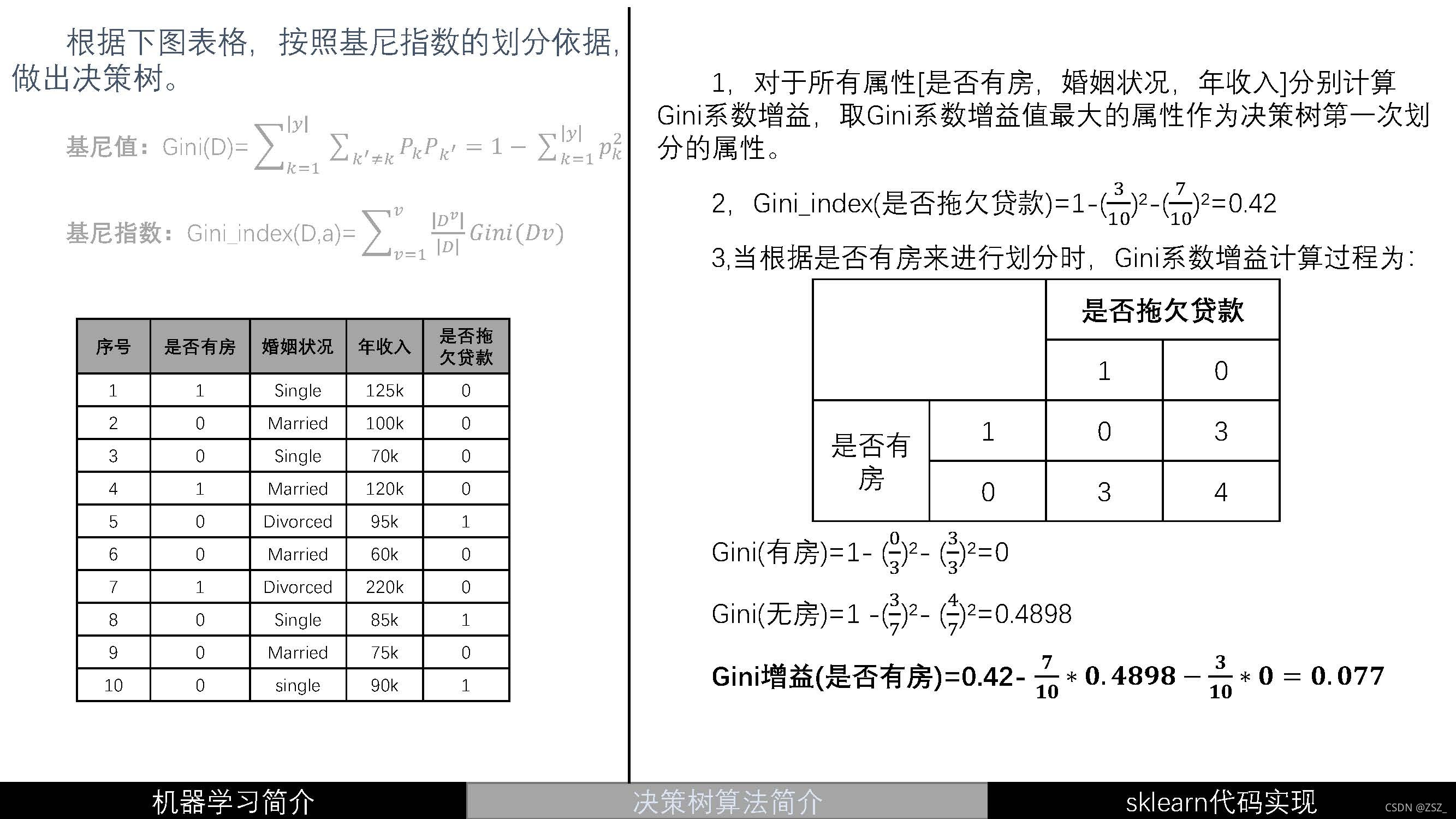
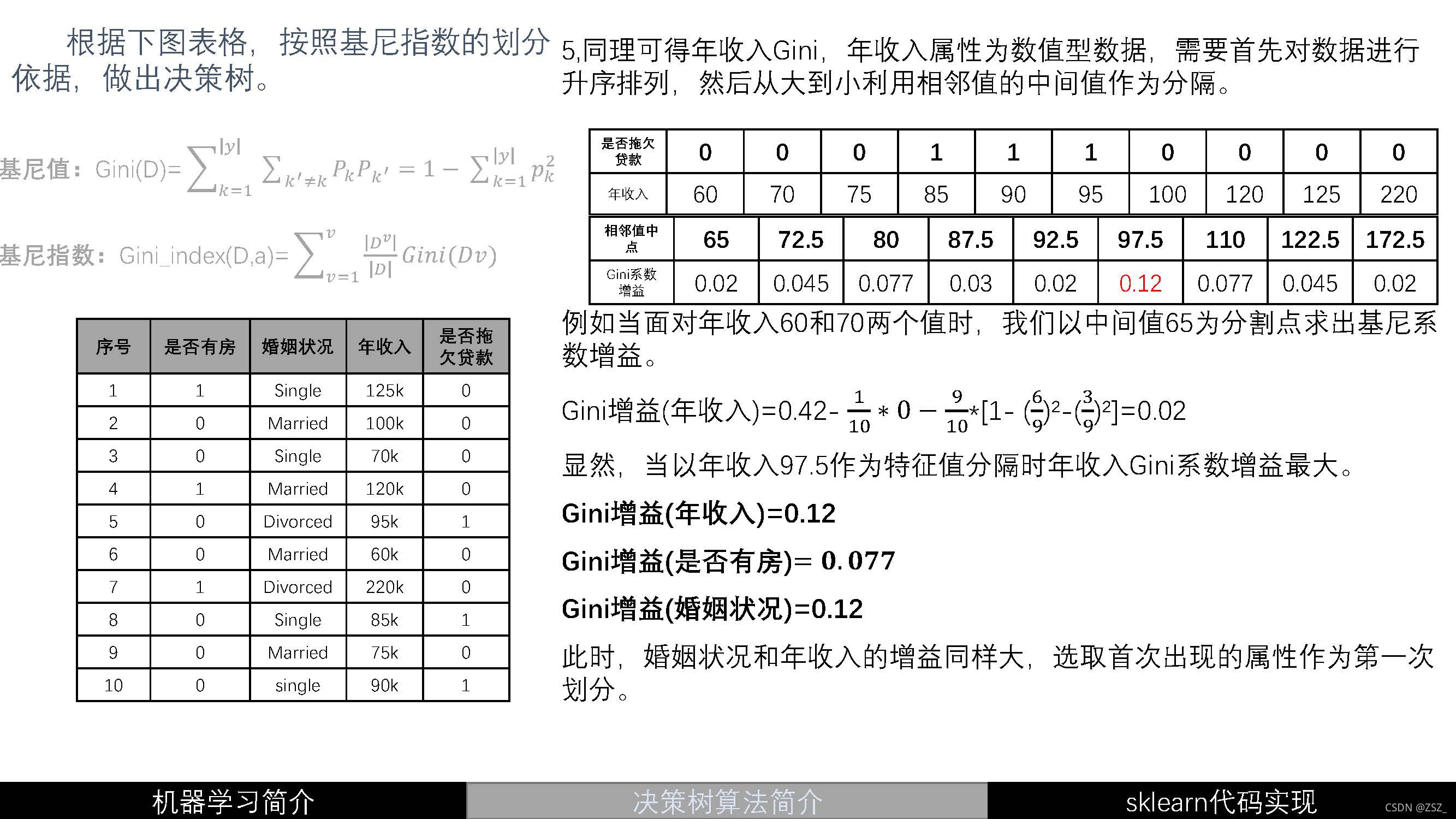
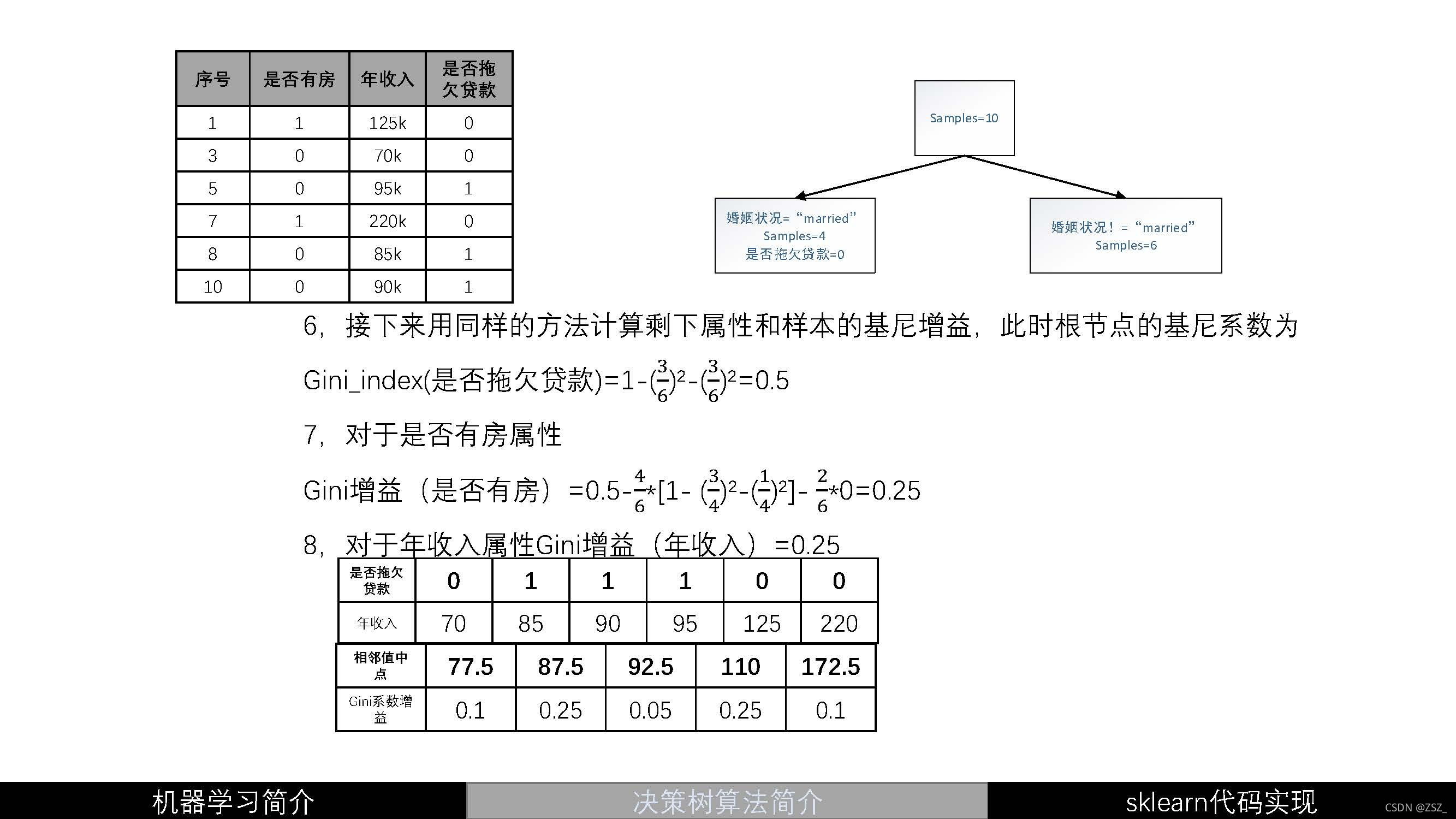
?
?












特征提取代码
#导入字典特征提取库
from sklearn.feature_extraction import DictVectorizer
#输入字典数据
data=[{"city":"北京","temperature":100},
{"city":"上海","temperature":60},
{"city":"深圳","temperature":30}]
#实例化一个转化器类
tranfer = DictVectorizer(sparse=False)
#进行特征提取
data = tranfer.fit_transform(data)
#输出结果
print("特征名字为:\n",tranfer.get_feature_names())
print("返回结果为:\n",data)
"""-----------输出----------------
特征名字为:
['city=上海', 'city=北京', 'city=深圳', 'temperature']
返回结果为:
[[ 0. 1. 0. 100.]
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
-----------------------------------"""
#输入字典数据
data=[{"city":"北京","temperature":100},
{"city":"上海","temperature":60},
{"city":"深圳","temperature":30}]
#实例化一个转化器
tranfer = DictVectorizer(sparse=True)
#进行特征提取
data = tranfer.fit_transform(data)
#输出结果
print("特征名字为:\n",tranfer.get_feature_names())
print("返回结果为:\n",data)
"""---------------------输出--------------------------
特征名字为:
['city=上海', 'city=北京', 'city=深圳', 'temperature']
返回结果为:
(0, 1) 1.0
(0, 3) 100.0
(1, 0) 1.0
(1, 3) 60.0
(2, 2) 1.0
(2, 3) 30.0
-------------------------------------------------------"""决策树代码
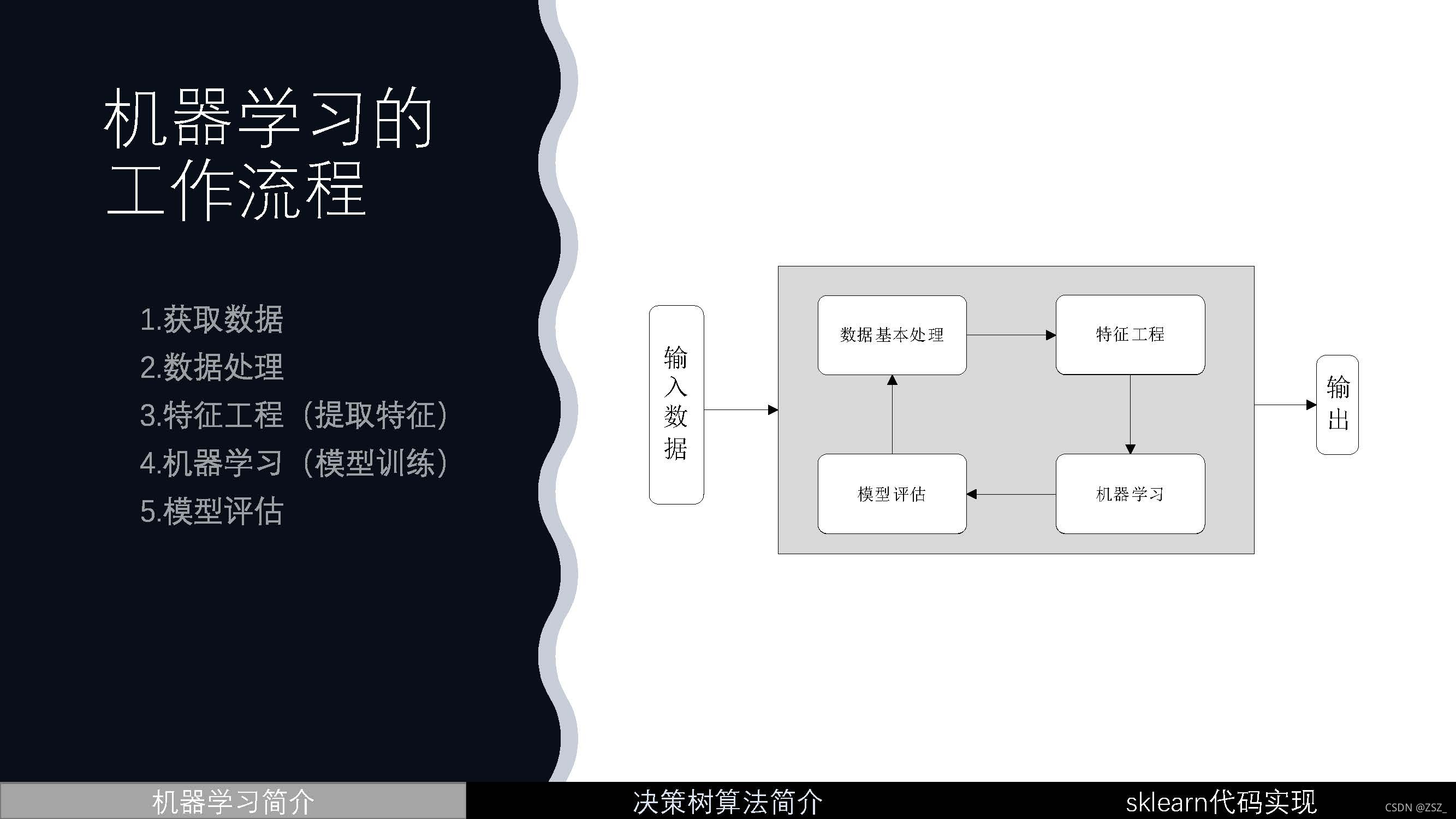
""" 1.获取数据
2.数据基本处理
-2.1 确定特征值、目标值
-2.2 缺失值处理
-2.3 数据集划分
3.特征工程(字典特征抽取)
4.机器学习(决策树)
5.模型评估"""
#读取文件库
import pandas as pd
import numpy as np
#数据集划分库
from sklearn.model_selection import train_test_split
#特征工程库
from sklearn.feature_extraction import DictVectorizer
#决策树库
from sklearn.tree import DecisionTreeClassifier
#可视化库
from sklearn.tree import export_graphviz
# 1.获取数据
data = pd.read_csv("DataSet.csv")
# 2.数据基本处理
# -2.1 确定特征值、目标值
x = data[["house","marital status","income"]]
y = data["default loan"]
#2.3 数据集划分
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=11,test_size=0.2)
#3.特征工程
x_train = x_train.to_dict(orient="records")
x_test = x_test.to_dict(orient="records")
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
#4. 机器学习(决策树)
estimator = DecisionTreeClassifier()
estimator.fit(x_train,y_train)
#5. 模型评估
y_pre =estimator.predict(x_test)
estimator.score(x_test,y_test)
#决策树可视化
export_graphviz(estimator,out_file="tree1.dot",feature_names=transfer.get_feature_names())data.csv
house marital status income default loan
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
1 Single 125 0
0 Married 100 0
0 Single 70 0
1 Married 120 0
0 Divorced 95 1
0 Married 60 0
1 Divorced 220 0
0 Single 85 1
0 Married 75 0
0 single 90 1
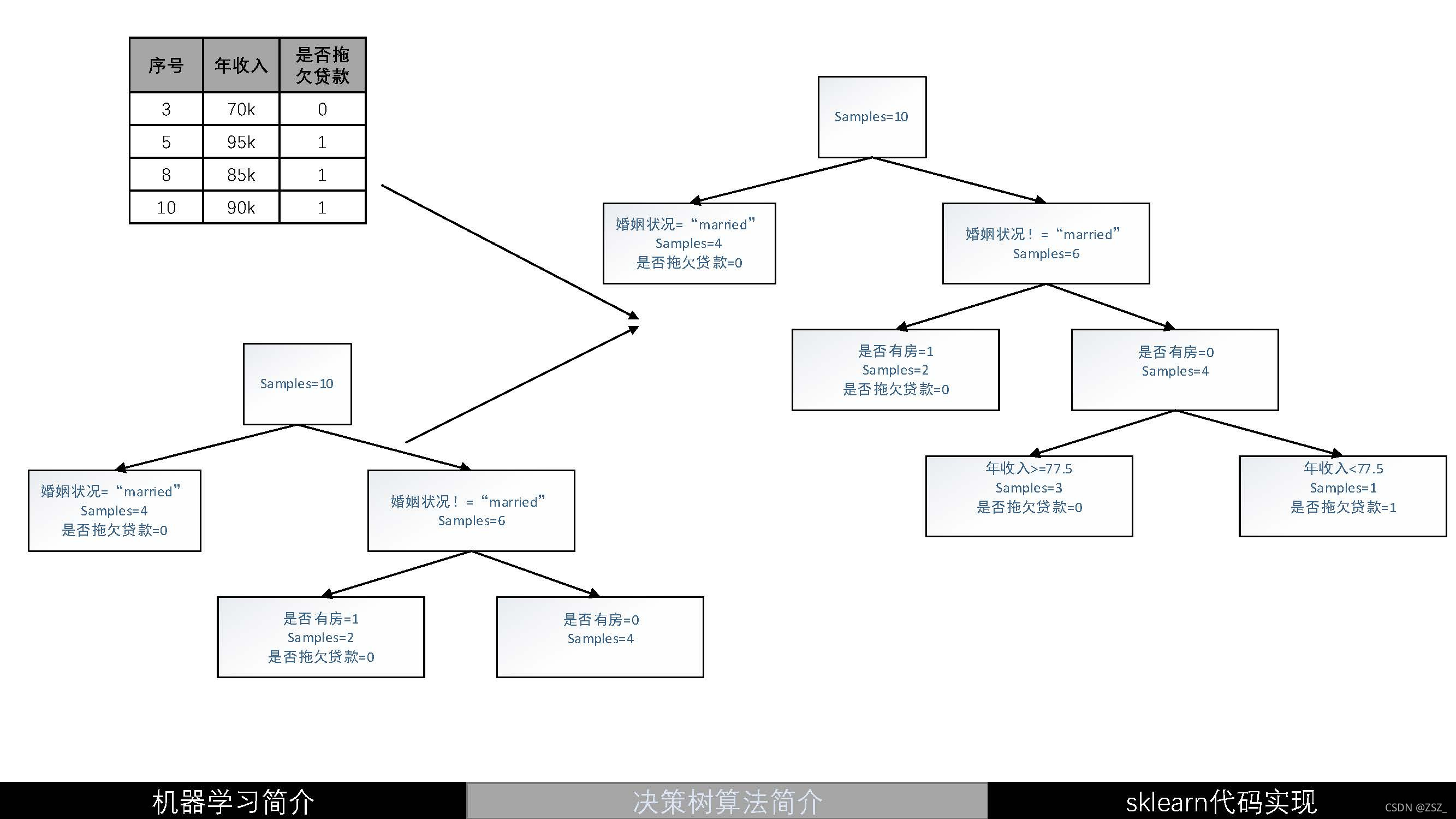
生成的决策树

?