1���������ݽṹ
1.1���ݽṹ����
����
ջ
���к�˫�˶���
����
����
�ֵ��ɢ�б�
�ݹ�
��
����ѺͶ�����
��дÿ��֪ʶ���ʱ�� ���Լ��ܽ�ķ�ʽ�ǰ��ն���>javascriptʵ�ַ�ʽ>��Ӧ�ķ���>�㷨ʵ�ֵĽṹȥд�� �������뷨�ڼ�������
1.2 ����
1.2.1 ���鶨��
js������ʵ����API�ĵ��� ��һ������ڴ����ݽṹ ����洢һϵ��ͬһ���������͵�ֵ
ע:javascript��������Ա��治ͬ���͵�ֵ ����һ�㲻�Ƽ���
1.2.2 ���鴴��
��javascript�������ִ�������ķ�ʽ
1.ʹ��Array���캯��
let shuzu=new Array();
ע��:����������������в���,��Ϊһ������,��ʾ������ij���,���Ϊ������ֻ���һ��(���)�����ֱ�ʾ���Ǵ���������Ӧ�ð�����ֵ��
2.ʹ������������
let shuzu=[];
1.2.3 ���鷽��
����Ԫ�� (��β)
ɾ��Ԫ��(��β)
1��������ĩβ����Ԫ��
ʹ��push����
numbers.push(11);
ԭ���ķ���:
numbers[numbers.length] = 10;
��Javascript��,�����ǿ����ĵĶ���,���Ҫ����Ԫ��,�ᶯ̬����,����ֱ�Ӹ�ֵ���������һ����λ����
2�������鿪ͷ����Ԫ��
ʹ��unshift����
numbers.unshift(10);
3������ĩβɾ��Ԫ��
ʹ��pop����;
numbers.pop();
4�����鿪ͷɾ��Ԫ��
ʹ��shif����
number.shif();
5������λ�����ӻ���ɾ��Ԫ��
ʹ��splice����:
splice���ܶ������
number.splice(4.,0,6,4)
��һ��������ʶҪɾ�����߲����Ԫ������ֵ
�ڶ���������ɾ��Ԫ�صĸ���,�����������Ҫ����Ԫ�����Եڶ���ɾ��Ԫ�صĸ���Ϊ0.
��������������,�������� Ҫ���ӵ����������ֵ
1.2.4 �������չ
��ά���鱾��������������Ϊ����Ԫ�ص�����,������������顱,
����˵���� ������[��������ʽ][��������ʽ]����ά�����ֳ�Ϊ����,
��������ȵľ����Ϊ���Գƾ���a[i][j] = a[j][i],
�ԽǾ���:n�������Խ����ⶼ����Ԫ��
var arr = [[1,2],[��a��,��b��]];
console.log(arr[1][0]); //a ��2�е�1�����ڵ�Ԫ��
1.2.5 javascript���õ����鷽��
1��concat(),�����������߸��������,������һ���µ�����**
2��ES6:copyWithin(),�������ָ��λ�ø���Ԫ�ص������ָ��λ�á��:array.copyWithin(target, start, end)
3��ES6:entries(),��������ĵ�������
4��every(),�����������Ԫ���Ƿ���ָ������,����һ��������Ϊ����,���ڼ�������е�Ԫ��
5��ES6:fill(),��һ���̶���ֵ�滻���������Ԫ�ء��:array.fill(value, start, end)
6��filter(),����һ������,�����������������Ԫ��
7��find(),���������з��������ĵ�һ��Ԫ��
8��findIndex(),���������з��������ĵ�һ��Ԫ�ص�����λ��
9��forEach(),����ÿ��Ԫ�ض�ִ��һ�λص�����
10��ES6:from(),��α����ת��Ϊ����������
11��ES6:includes(),�ж��������Ƿ���ָ����ֵ,���з���true,����false
12��indexOf(),����������ָ��Ԫ�ص�λ��,���������û��ָ����Ԫ����-1
13��isArray(),�ж�һ�������Ƿ�Ϊ����,�� ����true,���� ����false
15��ES6:keys(),�����鴴��һ������������Ŀɵ�������
16��lastIndexOf(),����ָ����Ԫ���������������ֵ�λ��,������ĺ��濪ʼ����
17��map(),����һ��������,�����е�Ԫ����ԭʼ�����Ԫ�ص��ú���֮������ֵ
18��pop(),ɾ����������һ��Ԫ��,������ɾ����Ԫ��
19��push(),���������������Ԫ��,�����������µij���
20��reduce(),��Ԫ�ص�ֵ����Ϊһ��ֵ,������
21��reduceRight(),��Ԫ�ص�ֵ����Ϊһ��ֵ,���ҵ���
22��reverse(),��ת����Ԫ�ص�����˳��
23��shift(),ɾ�������������һ��Ԫ��
24��unshift(),���������ǰ��������Ԫ��,�������µ����鳤��
25��slice(),����ָ��������Ԫ��,��һ�������ǿ�ʼ��λ��,�ڶ����ǽ���λ��(����������λ�õ�Ԫ��)
26��splice(),���Ӻ�ɾ�������е�Ԫ��,��һ��������Ҫɾ����Ԫ�صĿ�ʼλ��,�ڶ���������Ҫɾ����Ԫ�صĸ������������Լ��Ժ�IJ����������ӵ������е���Ԫ��
27��some(),����������Ƿ���ָ����Ԫ��,�еĻ��ͷ���true,û�оͷ���false
28��sort(),�������������,���Խ���һ���ȽϺ���
29��toString(),������תΪ�ַ���,�����ؽ��
30��valueOf(),������������ԭʼֵ
���õ����Ѿ��Ӵ���!!!
1.2.6 ��������
����javascript��c��Java�����Բ�ͬ,javascript���鲻��ǿ���͡����Դ洢������������
��ô�����javascript������Ҳ�洢��һ������������?
������õ��������顣
�����:
let myArray = new TypedArray(length)
//��ʵ��ʹ���� ��TypedArray���������б�����Ҫ������
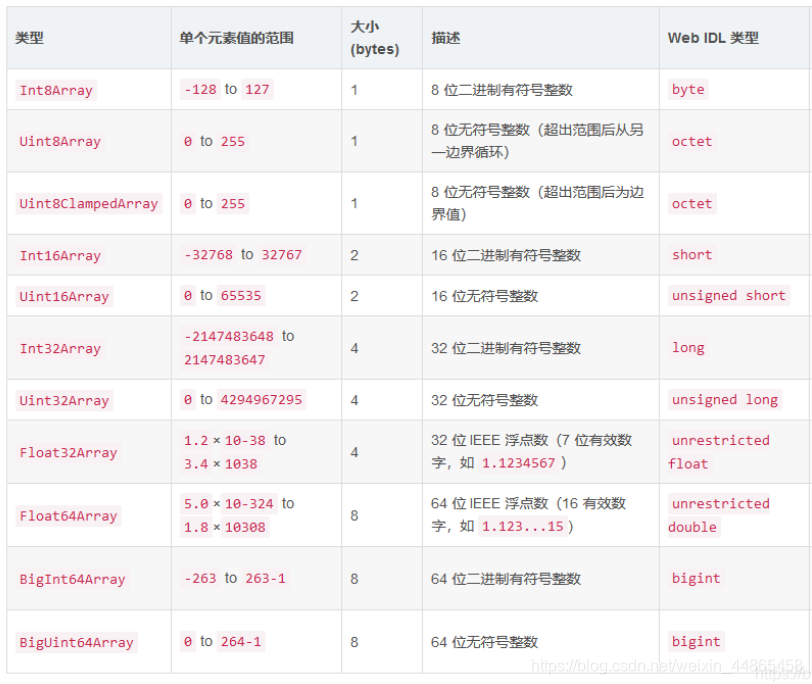
1.2.7TypeScript�����
Typescript����ķ�����ʹ�á����� + �����š�����ʾ����
let fibonacci: number[] = [1, 1, 2, 3, 5];
��������������������������:
��ʹ�����鷽��ʱ,��Ӧ��ɾ�IJ��Ԫ�����ͱ���һ��,����ᱨ����
�������:
TypeScript ����Array����
1.3 ջ
1.3.1 ����
ջ��һ������Ƚ����(LIFO)ԭ������ϡ�
�����ӻ��ɾ����Ԫ�ض�������ջ��ĩβ,����ջ��,��һ�˾ͽ�ջ�ס�
��ջ��,��Ԫ�ض�����ջ��,��Ԫ�ض��ӽ�ջ��
���ճ������е�����:
ջ�������ǵ��·��ڴ�,�ȷŽ�ȥ�Ķ�����ȡ����,��Ž�ȥ�Ķ�������ȡ����
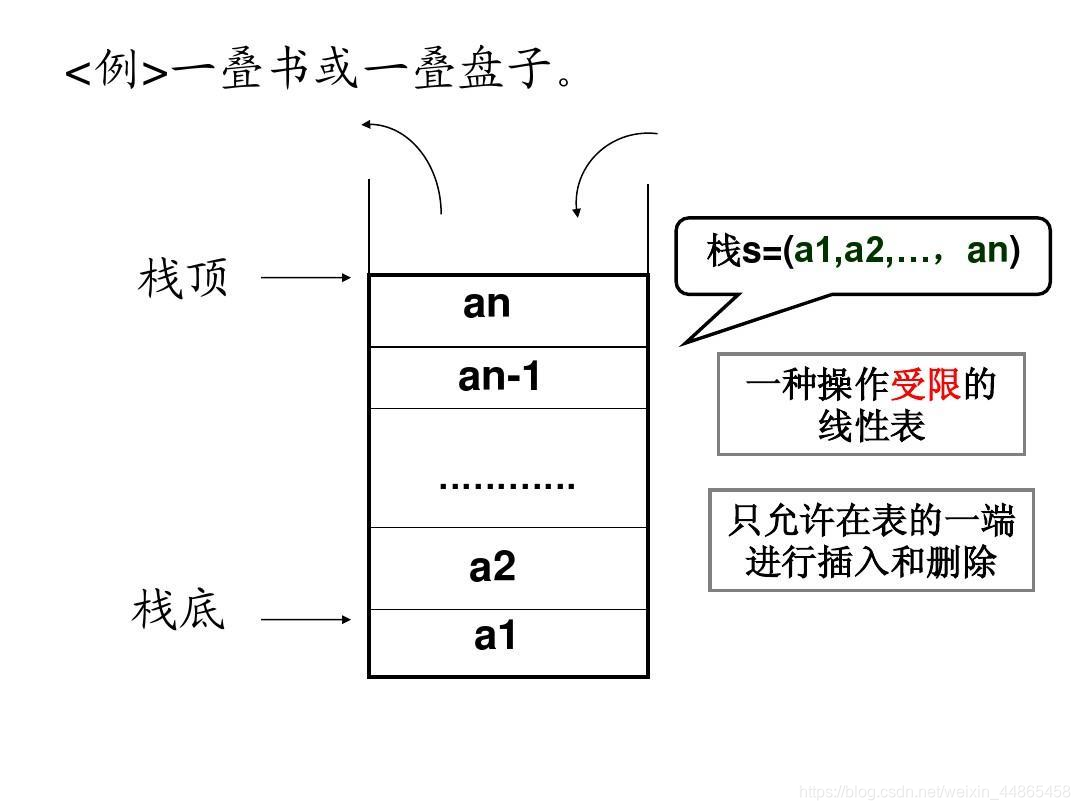
ջ�����ڱ�����Եı��������ڴ������ڱ������,�������õȵ�,Ҳ�������������ʷ��¼(������ķ��ذ�ť)
1.3.2 ����javascript���鴴��ջ
��javascript�������鴴��һ��ջһ��7������:
1��������һ��stack��,���ڴ��ջ
2����ջ��ʹ��push����Ԫ��(ֻ�ܴ�ջ������)
3����ջ��ʹ��pop�����Ƴ�Ԫ��(��ջ���Ƴ�)
4.�鿴ջ��Ԫ��(peek����)
5.���ջ�Ƿ�Ϊ�� ����ΪisEmpty ���ջΪ�շ���true ����false
6.ʹ��clear�������ջԪ��
7.���Կ�ʼʹ��stack��
�������������,stack�ѽ�������ջ���ص㡣
����ʵ��:
//����һ���������鵥λջ
class stack{
constructor{
this.items = [];
}
}
//��ջ��ʹ��push��������Ԫ��
push () {
this.items.push();
}
// ʹ��pop������ջ���Ƴ�Ԫ��
pop(){
reyurn this.items.pop();
}
//������������������,����ʵ����ջ���Ƚ������ԭ��
//�鿴ջ��Ԫ�� (length -1)
peek{
return this.items{this.items.length - 1};
}
//ʹ��isEmpty���ջ�Ƿ�Ϊ��
isEmpty(){
return this.items.length === 0;
}
//�������IJ����,ʹ��clear�������ջ���������Ԫ��
clear(){
return this.items.length;
}
//���ˡ�ջ�Ѿ������
�Ϳ���ʹ��ջ�ķ�������ջ���в�����
1.3.3 ����javascript����ջ
ǰ�������Ѿ�ѧ��ʹ������������ջ��,����ʵ�ʵ�Ӧ����,�����������ݵ�ʱ��,��Ҫ�������ʹ�����������Ч��,ʹ�������ʱ�临�Ӷ�Ϊ0(n),n��������ij���,��Ϊ������һ������,Ϊ�˱�֤Ԫ������,��ռ�ø�����ڴ�������Ҫ������������ֱ��Ѱ�ҵ�Ŀ��Ԫ�ء�
�ɴ������˶���ջ
������ֱ�ӻ�ȡԪ��,ռ�ý��ٵ��ڴ�ռ�,�����ܹ��������ǵ�Ҫ���������ݡ�
��������һ������:
1������һ��stack��
2����ջ�в���Ԫ��
3����֤ջ�Ƿ�Ϊ�պ����Ĵ�С
4����ջ�е���Ԫ��
5���鿴ջֵ����ջ���
6������tostring����
����ʵ��:
//��������һ��stack��
class stack {
constructor () {
this.count = 0 ; //ʹ��count����¼ջ�Ĵ�С,Ҳ�ܰ�������ɾ��������Ԫ��
this.items = {};
}
}
//��ջ�м���Ԫ��
push(element) {
this.items[this.count ] = element;
this.count ++ ;
}
//��js��,�����Ǽ�ֵ�Ե���ʽ���ֳ���,����ʹ��count��Ϊitems����ļ���,�����Ԫ����������ֵ,����Ԫ�غ�,���ǰ�count++,�Ա�����һ������ֵ����
//count����Ҳ��ʾջ�Ĵ�С,���ǿ��Է���count��size������ջ�Ĵ�С
size(){
return this.count;
}
//��֤ջ�Ƿ�Ϊ��
isEmpty(){
return this.count === 0;
}
//�鿴ջ����ֵ����ջ���
peek{
if (this.isEmpty()){
return unerfined;
}
return this.items{this.items.length - 1};
}
//���ջ��ֵ��Ϊ���캯���ij�ʼֵ��ok
clear (){
this.items = {};
this.count = 0;
}
//Ҳ����ʹ������һ�ַ���:
while (!this.isEmpty()){
this.pop();
}
//����tostring����
��ǰ���������û����string����,����Ϊ�������þ���tostring����,ʹ�ö����ʱ��,����Ҫ�����ֶ�ȥ������
toString () {
if (this.isEmpty()){
return '';
}
let objStru=ing = '${this.items[0]}';
for (let i = 1 ; i < this.count; i++ ){
objString = '${objstring},${this.items[i]}';
}
return objstring ;
}
//���ջ�ǿյ�,���ؿ�ֵ��ok��
//������ǿյġ��ײ���һ��Ԫ����Ϊ�ַ����ij�ʼֵ,Ȼ���������ջ
����,һ�����ڶ�����ջ�������
1.3.4 �������ݽṹ�ڲ�Ԫ��
�����Ǵ���һ��ջ��,���ͬ��Ҳ����Ҫʹ��,�����뱣���ڲ���Ԫ��,ֻ�����ı����DZ�¶��Ԫ��,���ʱ����ἰ���˱������ݽṹ�ڲ�Ԫ��:
��Ҫ�����ַ���:
1���»�������Լ��
�»�����������
һ���ֿ�����ϲ����javascript��ʹ���»�������Լ�������һ������Ϊ˽������
�»�������Լ��ʵ����������֮���һ���»���-,�������ַ���ֻ��һ��Լ��,���ܱ�������,�������ij���Ա��gg��
����ʵ��:
class stack {
constructor () {
this._count = 0;
this._items = {};
}
}
2��symbolʵ����
ʹ��symbolʵ����
��es6�й涨,symbol�Dz��ɱ��,�����������������
����ʵ��:
cosnt_items = symbol('stacItems');
class stack {
constoructor () {
this[_items] = [];
}
//ջ�ķ���
}
3��ʹ��weakMapʵ����
ʹ��weakMapʵ����
weakMap����ȷ������˽��,weakMap�Ǽ�ֵ�ԵĴ���,���Ƕ���,ֵ�����ԡ�
1.3.5 javascript����ջ���ʵ������
ʹ��ջʵ�ֽ׳˵ĵݹ�
ʹ��ջ��ģ��5!�Ĺ���,���Ƚ�����5��1ѹ��ջ,Ȼ��ʹ��һ��ѭ�������ְ�������������
����ʵ��:
1 function fact(num) {
2 var stack=new Stack;
3 while(num>0){
4 stack.push(num--);
5 }
6 var sum=1;
7 while(stack.length>0){
8 sum*=stack.pop;
9 }
10 return sum;
11 }
12
13 console.log(fact(5)) //120
1.3.6 �Ϸ�����
������ַ����а���С����,���дһ�������ж��ַ����е������Ƿ�Ϸ�,��ν�Ϸ�,�������ųɶԳ���
sdf(ds(ew(we)re)rwqw)qwrwq �Ϸ�
(sd(qwqe)sd(sd)) �Ϸ�
()()sd()(sd()dw))( ���Ϸ�
˼·����
���Ŵ���Ƕ��ϵ,Ҳ���ڲ��й�ϵ,���ʹ���������洢��Щ����,Ȼ������취һ��һ�ĵ�����,�ƺ����С������������ж�һ�������Ŷ�Ӧ������һ�������š�������ĽǶ�˼���������,����Щ���ѡ�
����,����ʹ��ջ������������
����������,�Ͱ�������ѹ��ջ��
����������,�ж�ջ�Ƿ�Ϊ��,���Ϊ����˵��û����������֮���Ӧ,�ַ������Ų��Ϸ������ջ��Ϊ��,���ջ��Ԫ���Ƴ�,������ž͵����ˡ�
��forѭ������,���ջ�ǿյ�,˵�����е��������Ŷ�������,���ջ������Ԫ��,��˵��ȱ��������,�ַ������Ų��Ϸ���
����ʵ��:
function is_leagl_brackets(string){
var stack = new Stack();
for (var i = 0;i<string.length;i++) {
var item = string[i];
// ������������ջ
if(item == '('){
stack.push(item)
}else if (item == ')'){
// ����������,�ж�ջ�Ƿ�Ϊ��
if(stack.isEmpty()){
return false
}else {
stack.pop() // ����������
}
}
}
// ���ջΪ��,˵���ַ������źϷ�
return stack.isEmpty()
}
console.log(is_leagl_brackets('sdf(ds(ew(we)re)rwqw)qwrwq')) // true
console.log(is_leagl_brackets('(sd(qwqe)sd(sd))')) // true
console.log(is_leagl_brackets('()()sd()(sd()dw))(')) // false
ʵ��һ����min������ջ
��һ��min����,����ջ�����С��Ԫ��,��ʱ�临�Ӷ�ΪO(1)
function MinStack() {
var data_stack = new Stack();
var min_stack = new Stack();
// ��min_stack ��¼ÿ�� push ������Ԫ��֮��,ջ�е���Сֵ
this.push = function (item) {
data_stack.push(item);
if(min_stack.isEmpty() || item < min_stack.top()){
min_stack.push(item)
}else {
min_stack.push(min_stack.top())
}
};
// ����,ÿ��pop֮��,min_stack Ҳ�Ὣ�ϴ�ջ�е���Сֵ����
this.pop() = function () {
data_stack.pop()
min_stack.pop()
}
this.min = function () {
return min_stack.top()
}
}
ʵ��Ӧ���л�������,�����ҾͲ������о� �ˡ�
1.4 ���к�˫�˶���
1.4.1�������ݽṹ
1�����еĸ���:
������ѭ�����Ƚ��ȳ�ԭ���һ��������С�������β������Ԫ��,�����Ƴ�Ԫ����
��ϵ���ճ��������ŶӸ���,���,��������Ŷ�,ǰ����˸������ߡ�
2�����еĴ���:
1��ʹ��һ��������������
class Queue { constructor() { this.count = 0; this.lowestCount = 0;//�ٶ��еĵ�һ��Ԫ�� this.items = {}; }
2.ʹ��enqueue���������������Ԫ��(�����ڶ���ĩβ)
enqueue(element) { this.items[this.count] = element; this.count++; }
3��ʹ��dequeue�����Ӷ�����ɾ��Ԫ��(�Ӷ��ж����Ƴ�)
size() { return this.count - this.lowestCount; };isEmpty() { return this.size() === 0; };
4���鿴������ǰ�����(ʹ��peek����)
peek() { if (this.isEmpty()) { return undefined; } return this.items[this.lowestCount]; }
5��ʹ��isEmpty�����������Ƿ�Ϊ�պͻ�ȡ���ij���
6.��ն���
clear() { this.items = {}; this.count = 0; this.lowestCount = 0; }
7.����tostring����
toString() { if (this.isEmpty()) { return ����; } let objstring =${this.items[this.lowestCount]}; for (let i = this.lowestCount + 1; i < this.count; i++) { objstring =${objString},${this.items[i]}; } return objString; }
�����������ݶ��е�ԭ����ǰ�潲����ջ����,�����ҾͲ��ظ���
1.4.2 ˫�˶������ݽṹ(deque)
1��˫�˶��еĸ���:
˫�˶�����һ����������ͬʱ�Ӷ��е�ǰ�˺ͺ�����Ӻ��Ƴ�Ԫ�ص��������
�ڼ������˫�˶��г�����Ӧ���Ǵ���һϵ�еij�������,�û��ڳ�����,�ò����ᱻ�洢��һ��˫�˶�����,���Ե�������ͷ�����,
����˫�˶���ͬʱ�������Ƚ��ȳ��ͺ���ȳ���ԭ��,����˵���ǰѶ��к�ջ��ϵ�һ�����ݽṹ��
2��˫�˶��еĴ���:
1�� ����˫�˶���
class Deque { constructor() { this.count = 0; this.lowestCount = 0; this.items = {}; }
2����������Ԫ��
addFront(element) { if (this.isEmpty()) {//�ն��� this.addBack(element); } else if (this.lowestCount > 0) {//֮ǰ��ɾ��,�������� this.lowestCount�C; this.items[this.lowestCount] = element; } else { for (let i = this.count; i > 0; i�C) { this.items[i] = this.items[i - 1]; } this.count++; this.items[0] = element; } }
3�� ��β����Ԫ��
addBack(element) { this.items[this.count] = element; this.count++; }
4������ɾ��Ԫ��
removeFront() { if (this.isEmpty()) { return undefined; } const result = this.items[this.lowestCount]; delete this.items[this.lowestCount]; this.lowestCount++; return result; }
5����βɾ��Ԫ��
removeBack() { if (this.isEmpty()) { return undefined; } this.count�C; const result = this.items[this.count]; delete this.items[this.count]; return result; }
6�����ض���Ԫ��
peekFront() { if (this.isEmpty()) { return undefined; } return this.items[this.lowestCount]; }
7�����ض�βԪ��
peekBack() { if (this.isEmpty()) { return undefined; } return this.items[this.count - 1]; }
1.4.3���к�˫�˶����Ӧ��
ģ����Ĵ�����Ϸ
�龰:������Χ��һȦ,�ѻ����ݸ����ߵ���,ijһʱ��ֹͣ,����˭����,˭���Ƴ����ظ��������,ʣ�µ����һ���˾���ʤ���ߡ�
����ʵ��:
function hotPotato(elementsList, num) { const queue = new Queue(); const elimitatedList = [];
for (let i = 0; i < elementsList.length; i++) { queue.enqueue(elementsList[i]); }
while (queue.size() > 1) { for (let i = 0; i < num; i++) { queue.enqueue(queue.dequeue()); } elimitatedList.push(queue.dequeue()); }
return { eliminated: elimitatedList, winner: queue.dequeue() };}
���ļ����
���һ����������ַ����Ƿ�Ϊ���ġ�
����ʵ��:
function palindromeChecker(aString) { if ( aString === undefined || aString === null || (aString !== null && aString.length === 0) ) { return false; } const deque = new Deque(); const lowerString = aString.toLocaleLowerCase().split(' ').join(''); let firstChar; let lastChar;
for (let i = 0; i < lowerString.length; i++) { deque.addBack(lowerString.charAt(i)); }
while (deque.size() > 1) { firstChar = deque.removeFront(); lastChar = deque.removeBack(); if (firstChar !== lastChar) { return false; } }
return true;};
1.5 ����
1.5.1 ��������(LinkedList)
�����洢�����Ԫ�ؼ���,����ͬ������,�����е�Ԫ�����ڴ��в������������õġ�ÿ��Ԫ����һ���洢Ԫ�ر����Ľڵ��һ��ָ����һ��Ԫ�ص�����(Ҳ��Ϊָ�������)��ɡ���ͼ����:
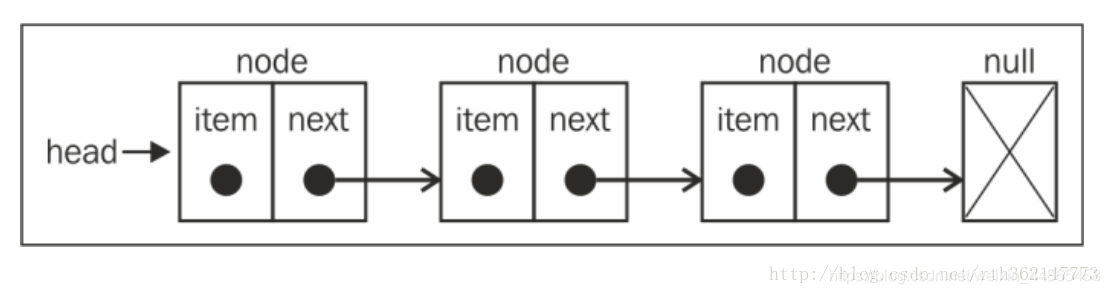
����ڴ�ͳ������,������һ���ô�����,���ӻ��Ƴ�Ԫ�ص�ʱ����Ҫ�ƶ�����Ԫ�ء�Ȼ��,������Ҫʹ��ָ��,���ʵ��������ʱ����Ҫע�⡣�������һ��ϸ���ǿ���ֱ�ӷ����κ�λ��Ԫ��,��Ҫ����������м��һ��Ԫ��,��Ҫ�����(��ͷ)��ʼ�ʹ��б�ֱ���ҵ�����ҪԪ�ء�
��ʵʵ�����ǻ�,���ж�ڳ�����ν�,ͨ���ӹ������ӻ��������������Ԫ��,���ӹ����ָ�롣

1.5.2 ��������
function LinkedList() {
var Node = function (val) {������������ //��Ԫ�ع���
this.val = val;
this.next = null;
};
var length = 0;
var head = null;
this.append = function (val) {
var node = new Node(val);�������� //�����µ�Ԫ�ؽڵ�
var current;
if (head === null) {����������������//ͷ�ڵ�Ϊ��ʱ ��ǰ�����Ϊͷ�ڵ�
head = node;
} else {
current = head;����������������������������
while (current.next) {����������//����,ֱ���ڵ��nextΪnullʱֹͣѭ��,��ǰ�ڵ�Ϊβ�ڵ�
current = current.next;
}
current.next = node;������������//��β�ڵ�ָ���µ�Ԫ��,��Ԫ����Ϊβ�ڵ�
}
length++;����������������������������//������������
};
this.removeAt = function (position) {
if (position > -1 && position < length) {
var current = head;
var index = 0;
var previous;
if (position == 0) {
head = current.next;
} else {
while (index++ < position) {
previous = current;
current = current.next;
}
previous.next = current.next;
}
length--;
return current.val;
} else {
return null;
}
};
this.insert = function (position, val) {
if (position > -1 && position <= length) {������//У��߽�
var node = new Node(val);����������������
current = head;
var index = 0;
var previous;
if (position == 0) {������������ //��Ϊͷ�ڵ�,���½ڵ��nextָ��ԭ�е�ͷ�ڵ㡣
node.next = current;
head = node;������������������//�½ڵ㸳ֵ��ͷ�ڵ�
} else {
while (index++ < position) {
previous = current;
current = current.next;
}������������������������������//���������õ���ǰposition���ڵ�current�ڵ�,����һ���ڵ�
previous.next = node;��������//��һ���ڵ��nextָ���½ڵ� �½ڵ�ָ��ǰ���,���Բ�����ͼ����
node.next = current;
}
length++;
return true;
} else {
return false;
}
};
this.toString = function () {
var string = head.val;
var current = head.next;
while (current) {
string += ',' + current.val;
current = current.next;
}
return string;
};
this.indexOf = function (val) {
var current = head;
var index = -1;
while (current) {
if (val === current.val) { //��ͷ�ڵ㿪ʼ����
return index;
}
index++;
current = current.next;
}
return -1;
};
this.getLength = function () {
return length;
}
this.getHead = function () {
return head;
}
}
// ��������
var li = new LinkedList();
li.append(1);
li.append(2);
li.append(4);
li.append(4);
li.append(5);
li.insert(2,3);
li.insert(2,3);
console.log(li.toString()) // 1,2,3,3,4,4,5
console.log(li.getHead()) // 1->2->3->3->4->4->5
�����:
�����ݽṹ�������JS�д���һ������
1.5.3 ˫������
˫���б�����ͨ�б�����������:
�ڵ����б���һ���ڵ�ֻ��������һ���ڵ������,����˫���б���,������˫���һ����������һ��Ԫ��,��һ������ǰһ��Ԫ�ء�
˫������:�ȿ��Դ�ͷ������β,�ֿ��Դ�β������ͷ��Ҳ����˵�������ӵĹ�����˫���,����ʵ��ԭ����:һ���ڵ������ǰ���ӵ�����,Ҳ��һ��������ӵ����á�
˫��������ȱ��:
ÿ���ڲ����ɾ��ij���ڵ�ʱ,����Ҫ�����ĸ�����,����������,ʵ������������Щ;
����ڵ�������,��ռ�ڴ�ռ����һЩ;
����,�����˫�������ı����Զ���,��Щȱ���������
��ͼ��ʾ:
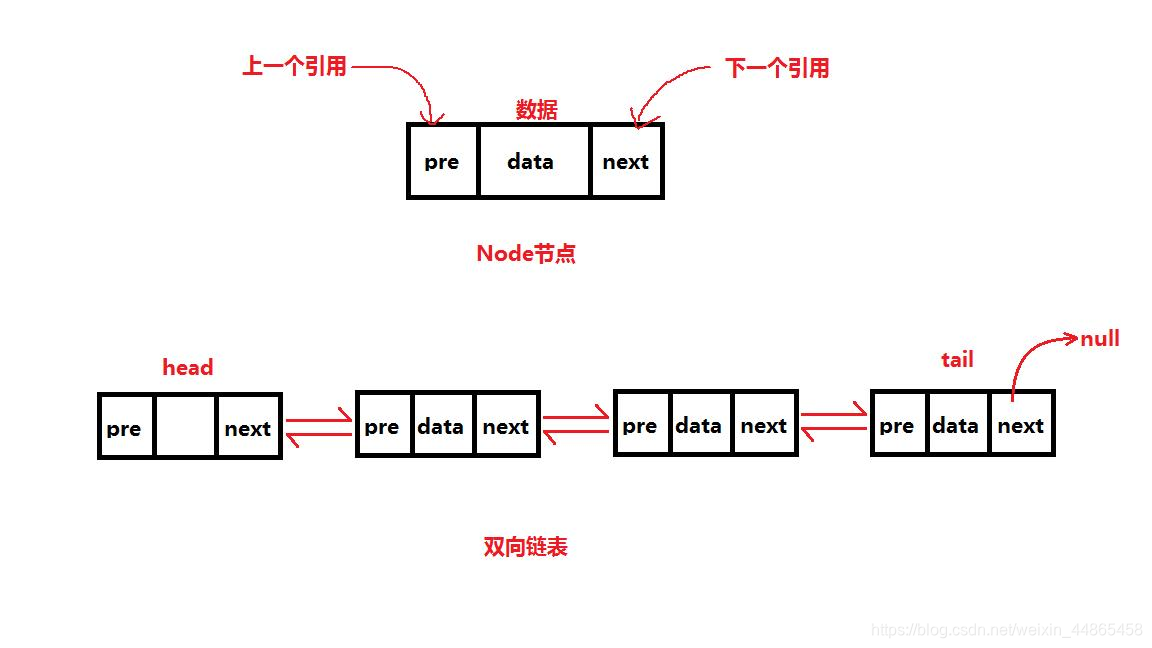
����ʵ��:
//�ȴ���˫��������DoubleLinklist,�����ӻ�������,��ʵ��˫�������ij��÷���:
//��װ˫��������
function DoubleLinklist(){
//��װ�ڲ���:�ڵ���
function Node(data){
this.data = data
this.prev = null
this.next = null
}
//����
this.head = null
this.tail ==null
this.length = 0
}
1.5.4ѭ������
˫��������ÿ�������Ҫ����ǰһ�����ͺ�һ�����,������Ҫ��������ָ����,�ֱ�ָ��ǰһ�����ͺ�һ����㡣
˫��������ͷ�ڵ��prevָ��ָ��β�ڵ�,β�ڵ��nextָ��ָ��ͷ�ڵ㡣
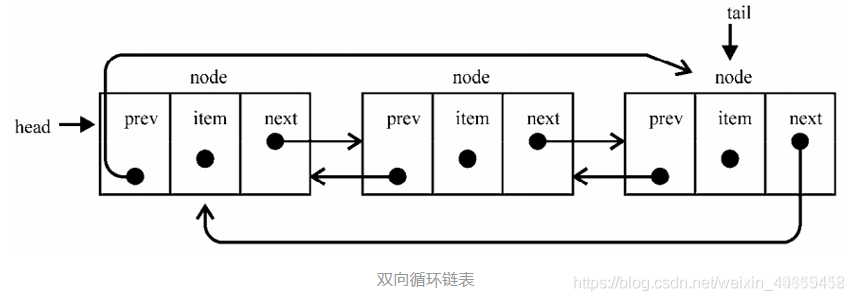
ѭ���б���ʵ��:
1������˫��ѭ������
function DoublyCircularLinkedList(){
function Node(element){
this.element=element
this.next=null
this.prev=null
}
let length=0
let head=null
let tail=null
}
2��β�������½ڵ�
this.append=function(element){
let node = new Node(element)
let current // ��ǰ�ڵ�
let previous // ǰһ���ڵ�
if(!head){
head=node
tail=node
head.prev=tail
tail.next=head
}else{
current=head
while(current.next !== head){
previous = current
current = current.next
}
current.next=node
node.next=head
node.prev=current
}
length++
return true
}
3������λ�ò���ڵ�
// ������λ�ò���һ���ڵ�
this.insert=function(position,element){
if(position > 0 && position <= length){
let node = new Node(element)
let index = 0
let current = head
let previous
if(position === 0){ // ͷ������
if(!head){
node.next=node
node.prev=node
head=node
tail=node
}else{
current.prev=node
node.next=current
}
}else if(position === length){ // �������
current=tail
current.next=node
node.prev=current
tail=node
node.next=head
}else{
while(index++ < position){
previous=current
current=current.next
}
current.prev=node
node.next=current
previous.next=node
node.prev=previous
}
length++
return true
}else{
return false
}
}
4������λ��ɾ���ڵ�
this.removeAt = function(position){
if(position > -1 && position < length){
let current = head
let index = 0
let previous;
if(position === 0){
current.next.previous = tail
head = current.next;
}else if(position === length - 1){
current = tail;
current.prev.next = head
head.prev = current.prev
tail = current.prev
}else{
while(index++ < position){
previous = current
current = current.next
}
previous.next = current.next
current.next.prev = previous
}
length--
return true
}else{
return false
}
}
5�����ݽڵ�ֵɾ���ڵ�
this.remove = function(element){
let current = head
let previous
let indexCheck = 0
while(current && indexCheck < length){
if(current.element === element){
if(indexCheck === 0){
current.next.prev = tail;
head = current.next
}else{
current.next.prev = previous
previous.next = current.next
}
length--
return true
}
previous = current
current = current.next
indexCheck++
}
return false
}
1.5.5��������
����������ָ����Ԫ������������ṹ,����ʹ�������㷨֮��,���ǻ����Խ�Ԫ�ز��뵽��ȷ��λ������֤�����������ԡ�
����ʵ��:
const Compare = {
LESS_THAN:-1,
BIGGER_THAN:1
};
function defaultCompare(a,b){
if(a === b){
return 0;
}
return a < b?Compare.LESS_THAN : Compare.BIGGER_THAN;
}
class SortedLinkedList extends LinkedList{//LinkedList�������Լ�https://www.cnblogs.com/MySweetheart/p/13212220.html
constructor(equalsFn = defaultEquals, compareFn = defaultCompare){
super(equalsFn);
this.compareFn = compareFn;
}
insert(element,index = 0){
if(this.isEmpty()){
return super.insert(element,0);
}
const pos = this.getIndexNextSortedElement(element);
return super.insert(element,pos);
}
getIndexNextSortedElement(element){
let current = this.head;
let i = 0;
for(;i < this.size() && current; i++){
const comp = this.compareFn(element,current.element);
if(comp == Compare.LESS_THAN){
return i;
}
current = current.next;
}
return i;
}
}
1.5.6 ������ʵ��ջ
������Ͻ��ıȽ�ģ��,���Բο�������ƪ����:
JAVASCRIPT����ͨ������ʵ��ջ����
1.7����
1.7.1 ���ϵĸ����ص�
��es6�������set()����,����������Ψһֵ�ļ���,��������һ��������Ψһ�������,��һ�ֲ������ظ������ݽṹ�������е�Ԫ�ؿ����Ǽ�����,Ҳ�����Ǹ��ӵĶ���,�����������Ϊû���ظ����ݵ����顣
�ص�:
�������ظ���˳�����ݽṹ
�:
new Set([iterable]);
1.7.2���ϴ���
1������һ��set��
2��add(element):��������һ����Ԫ��
3��delete(element):�Ӽ�����ɾ��һ��Ԫ��
4��has(element):���Ԫ���ڼ�����,����true ,����false
5��clear():��������е�����Ԫ��
6��size():���ؼ����а���Ԫ�ص�����,�������е�length��������
7��values():����һ����������������ֵ��(Ԫ��)����������ʵ��:
class Set {
constructor () {
this.items = {};
}
add (value) { // ��������Ԫ��
if (!this.has(value)) {
this.items[value] = value;
return true;
}
return false;
}
delete (value) { // �Ӽ�����ɾ����Ӧ��Ԫ��
if (this.has(value)) {
delete this.items[value];
return true;
}
return false;
}
has (value) { // �жϸ�����Ԫ���ڼ������Ƿ����
return this.items.hasOwnProperty(value);
}
clear() { // ��ռ�������
this.items = {};
}
size () { // ��ȡ���ϵij���
return Object.keys(this.items).length;
}
values () { // ���ؼ���������Ԫ�ص�����
return Object.values(this.items);
}
}
1.7.3��������
������������ѧ�����Ǿ�ѧϰ��,�ڼ������Ҳͬ��������,��ѯ���ݿ��SQL���Ļ������Ǽ������㡣��ѯ������ݿ�Ҳ�᷵��һ�����ݼ���
1.����
���ڸ�������������,��������һ��������������������Ԫ�ص��¼��ϡ�
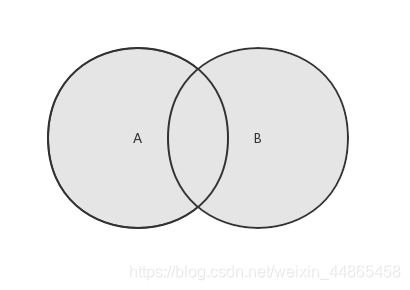
˼·:���ȱ�����һ������,�����е�Ԫ�����ӵ��¼�����,Ȼ���ٱ����ڶ�������,�����е�Ԫ�����ӵ��¼����С�Ȼ���¼��ϡ����õ��Ļ������ظ���Ԫ��,��Ϊ���ϵ�add()�������Զ��ų��������ӵ�Ԫ�ء�
����ʵ��:
union (otherSet) { // ����
let unionSet = new Set();
this.values().forEach(value => unionSet.add(value));
otherSet.values().forEach(value => unionSet.add(value));
return unionSet;
}
2.����
���ڸ�������������,��������һ���������������й���Ԫ�ص��¼���
����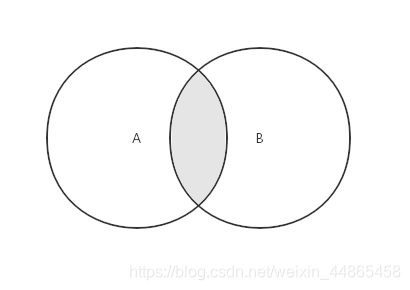
˼·:������һ������,���Ԫ�س����ڵڶ���������,�������ӵ��¼��ϡ�Ȼ���¼��ϡ�
����ʵ��:
intersection (otherSet) { // ����
let intersectionSet = new Set();
this.values().forEach(value => {
if (otherSet.has(value)) intersectionSet.add(value);
});
return intersectionSet;
}
3.�
���ڸ�������������,�����һ���������д����ڵ�һ�������Ҳ������ڵڶ������ϵ�Ԫ�ص��¼���
����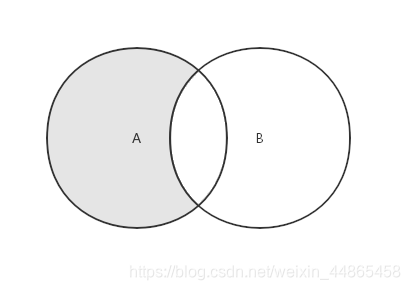
˼·:������һ������,���Ԫ��û�г����ڵڶ���������,�������ӵ��¼��ϡ�Ȼ���¼��ϡ�
����ʵ��:
difference (otherSet) { // �
let differenceSet = new Set();
this.values().forEach(value => {
if (!otherSet.has(value)) differenceSet.add(value);
});
return differenceSet;
}
4.�Ӽ�
��֤һ�����������Ƿ�����һ�����ϵ��Ӽ�,���жϸ����ļ����е�����Ԫ���Ƿ�������һ��������,�����,��������Ͼ�����һ�����ϵ��Ӽ�,��֮���ǡ�
����
˼·:
�������A�ȼ���B�ij��ȴ�,��ֱ�ӷ���false,��Ϊ�������A��������B���Ӽ���Ȼ��ʹ��every()������������A������Ԫ��,һ���������е�Ԫ��û���ڼ���B�г���,��ֱ�ӷ���false,����ֹ����
����ʵ��:
subset (otherSet) { // �Ӽ�
if (this.size() > otherSet.size()) return false;
let isSubset = true;
this.values().every(value => {
if (!otherSet.has(value)) {
isSubset = false;
return false;
}
return true;
});
return isSubset;
}
1.8 �ֵ��ɢ�б�
1.8.1�ֵ�ĸ�����ص�
����һ�������ǽ�������:��ʾһ�鲻�ظ�������,�ֵ�ͼ��ϵ���Ҫ���������,��������������[ֵ,ֵ]����ʽ�����,����ֻ����ֵ����;�����ֵ��ɢ�б�����������[��,ֵ]����ʽ�����,�������ظ�,���Dz������ļ�,Ҳ���ļ�����Ӧ��ֵ
�ֵ�Ҳ����Ϊ:ӳ��,���ű�,�������顣
1.8.2�ֵ䴴��
��������:
set(key,value ):���ֵ���������Ԫ�ء����key����,��ô�Ѿ����ڵ�valueֵҲ�ᱻ��ֵ����
remove(key):ͨ��ʹ�ü�ֵ��Ϊ���������ֵ����Ƴ���Ӧ������ֵ
hasKey(key):���ij����ֵ�������ֵ���,����true,����false
get(key):ͨ���Լ�ֵ��Ϊ���������ض�����ֵ������
clear():ɾ�����ֵ��е�����ֵ
size():�����ֵ�������ֵ������,�������е�length����
isEmpty():��size�������ʱ��true,����ʱ��false
keys():���ֵ������еļ������������ʽ����
values():���ֵ������еļ�ֵ���������ʽ����
keyValues():���ֵ������еġ���,ֵ������
forEach(callbackFn):�����ֵ��е����м�ֵ��,����������:key��value
����ʵ��:
class Dictionary {
constructor () {
this.items = {};
}
set (key, value) { // ���ֵ������ӻ���Ԫ��
this.items[key] = value;
}
get (key) { // ͨ����ֵ�����ֵ��е�ֵ
return this.items[key];
}
delete (key) { // ͨ��ʹ�ü�ֵ�����ֵ���ɾ����Ӧ��Ԫ��
if (this.has(key)) {
delete this.items[key];
return true;
}
return false;
}
has (key) { // �жϸ����ļ�ֵ�Ƿ�������ֵ���
return this.items.hasOwnProperty(key);
}
clear() { // ����ֵ�����
this.items = {};
}
size () { // �����ֵ�������Ԫ�ص�����
return Object.keys(this.items).length;
}
keys () { // �����ֵ������еļ�ֵ
return Object.keys(this.items);
}
values () { // �����ֵ������е�ֵ
return Object.values(this.items);
}
getItems () { // �����ֵ��е�����Ԫ��
return this.items;
}
}
1.8.4ɢ�б��ĸ�����ص�
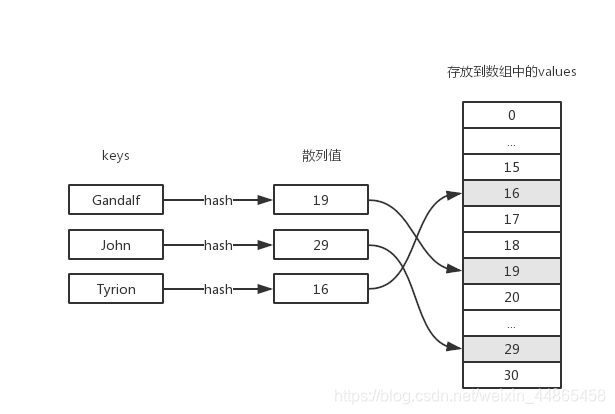
ɢ�б�(���߽й�ϣ��),��һ�ָĽ���dictionary,����keyͨ��һ���̶����㷨(ɢ�к������ϣ����)�ó�һ������,Ȼ��dictionary��key����Ӧ��value��ŵ������������Ӧ�������±��������Ĵ洢�ռ��С���ԭʼ��dictionary��,���Ҫ����ij��key����Ӧ��value,������Ҫ���������ֵ䡣Ϊ����߲�ѯ��Ч��,���ǽ�key��Ӧ��value���浽������,ֻҪkey����,ʹ����ͬ��ɢ�к���������������־��ǹ̶���,���ǾͿ��Ժܿ�����������ҵ�����Ҫ���ҵ�value��������ɢ�б������ݽṹʾ��ͼ:
��
1.8.4 ɢ�б���ʵ��
lose lose ɢ�к����DZȽϼ�һ��:��ÿ����ֵ���е�ÿ����ĸ��ASCIIֵ���
������ɢ�к���loseloseHashCode()��ʵ�ִ���:
loseloseHashCode (key) {
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37;
}
���ɢ�к�����ʵ�ֺܼ�,���ǽ������key�е�ÿһ���ַ�ʹ��charCodeAt()����(�йظú�������ϸ���ݿ��Բ鿴����)����ת����ASCII��,Ȼ����ЩASCII�����,�����37����,�õ�һ������,������־������key����Ӧ��hashֵ��������Ҫ���ľ��ǽ�value��ŵ�hashֵ����Ӧ������Ĵ洢�ռ��ڡ����������ǵ�HashTable�����Ҫʵ�ִ���:
class HashTable {
constructor () {
this.table = [];
}
loseloseHashCode (key) { // ɢ�к���
let hash = 0;
for (let i = 0; i < key.length; i++) {
hash += key.charCodeAt(i);
}
return hash % 37;
}
put (key, value) { // ����ֵ�Դ�ŵ���ϣ����
let position = this.loseloseHashCode(key);
console.log(`${position} - ${key}`);
this.table[position] = value;
}
get (key) { // ͨ��key���ҹ�ϣ���е�ֵ
return this.table[this.loseloseHashCode(key)];
}
remove (key) { // ͨ��key�ӹ�ϣ����ɾ����Ӧ��ֵ
this.table[this.loseloseHashCode(key)] = undefined;
}
isEmpty () { // �жϹ�ϣ���Ƿ�Ϊ��
return this.size() === 0;
}
size () { // ���ع�ϣ���ij���
let count = 0;
this.table.forEach(item => {
if (item !== undefined) count++;
});
return count;
}
clear () { // ��չ�ϣ��
this.table = [];
}
}
1.9 �ݹ�
1.9.1����ݹ�
һ�����̻������䶨���˵������ֱ�ӻ��ӵ���������һ�ַ���,��ͨ����һ�������ӵ�������ת��Ϊһ����ԭ�������ƵĹ�ģ��С�����������,�ݹ����ֻ�������ij���Ϳ������������������Ҫ�Ķ���ظ�����,���ؼ����˳���Ĵ�������
����˵�����Լ������Լ�,�Ѵ�������зֳ�С��ģ����
1.9.2 ����һ��n�Ľ׳�
1��ʹ��ѭ���ķ�������n�Ľ׳�
function xunhuan (number) {
if (number<0,) return underfind;
let tatal = 1;
for (let n = 1, n> 1,n++){
total = total *n;
}
return total ;
}
console.xunhuan(10)
//����10�Ľ׳�
2��ʹ�õݹ�ķ�������n�Ľ׳�
function factorial (n) {
if ( n === 1 || n === 0){
return 1;}
return n*factorial(n-1);
}
console.log(factorial(10))
//����10�Ľ׳�
1.9.3쳲���������
쳲���������ָ��������һ������:1��1��2��3��5��8��13��21��34����������ѧ��,쳲��������������±��Ե��Ƶķ�������:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n��N)*
�ܽ���˵���ǵ�һ�ڶ�������1 ,����ÿ������ǰ������֮��
���ּ��㷽��
����
�ݹ�
�������(������ֹ����εļ���ֵ ��֮ǰ���ֵ����¼����)
����:
function Fibo(n) {
if(n <= 0) {
return -1;
}
if(n <= 2) {
return 1;
}
let pre = 1; //��һ��ѭ��pre��f(1)Ҳ����1
let next = 1; //��һ��ѭ��next��f(2)Ҳ����1
let n_value = 0; // ����f(n)��ֵ
for(let i = 3; i <= n; i++) {
n_value = pre + next; //ÿһ��ѭ��n_value����ǰ�������ĺ�
pre = next; // Ȼ���next��ֵ��pre
next = n_value; //���µ�n_value��ֵ��ֵ��next
}
return n_value;
}
�ݹ�:
function Fibo(n) {
if(n <= 0) {
return -1; //�����n���Ϸ�,����-1
}
if(n <= 2) {
return 1; // ��һ��͵ڶ���Ϊ1
} else {
return Fibo(n-2) + Fibo(n-1); // �ӵ����ʼ����ǰ����ĺ�
}
}
���仯:
const fibonacci = (( cache = {} ) => n => {
if( cache[ n ] ){
return cache[ n ];
}
if( n < 2 ){
return cache[ n ] = n;
}
return cache[ n ] = fibonacci( n - 1 ) + fibonacci( n - 2 );
})();
1.10 ��
1.10.1 ���Ļ������������
�ڼ������ѧ��,����һ��ʮ����Ҫ�����ݽṹ����������Ϊһ�ֲַ����ݳ���ģ��,�������������ݼ�IJ㼶��ϵ����֯�ṹ����Ҳ��һ�ַ�˳������ݽṹ����ͼչʾ�����Ķ���:
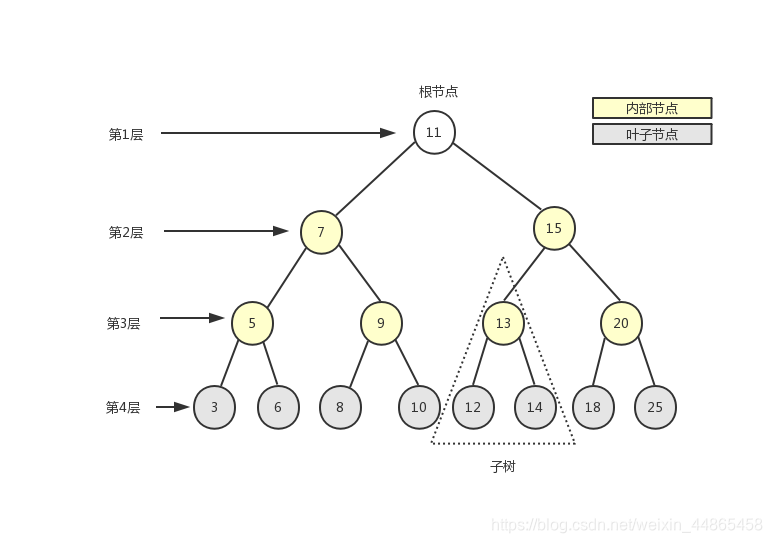
����ͼ��ʾ,һ��������������һ��λ���������Ľڵ�,��֮Ϊ���ڵ�(11),��û�и��ڵ㡣���е�ÿһ��Ԫ�ض�����һ���ڵ�,�ڵ��Ϊ�ڲ��ڵ�(ͼ����ʾΪ��ɫ�Ľڵ�)���ⲿ�ڵ�(ͼ����ʾΪ��ɫ�Ľڵ�),������һ���ӽڵ�Ľڵ��Ϊ�ڲ��ڵ�,û����Ԫ�صĽڵ��Ϊ�ⲿ�ڵ��Ҷ�ӽڵ㡣һ���ڵ����������(���ڵ����)�ͺ���������ɽڵ㱾�������ĺ�����,����ͼ����������еIJ��־���һ���������ڵ�ӵ�е������ĸ�����֮Ϊ�ڵ�Ķ�,����ͼ�г�Ҷ�ӽڵ�Ķ�Ϊ0��,����ڵ�Ķȶ�Ϊ2���Ӹ��ڵ㿪ʼ,��Ϊ��1��,��һ���ӽڵ�Ϊ��2��,�ڶ����ӽڵ�Ϊ��3��,�Դ����ơ����ĸ߶�(���)�����нڵ�����㼶����(��ͼ�����ĸ߶�Ϊ4)��
��һ������,������ͬ���ڵ��һ��ڵ��Ϊ�ֵܽڵ�,����ͼ�е�3��6��5��9�ȶ����ֵܽڵ㡣
���ķ���:
������,����������,��ƽ����,�����,��ȫ��
�ں���������ж�����ϸ����
�����ص㽲����������
1.10.2 �������Ͷ���������
������
�����������еĽڵ����ֻ���������ӽڵ�,һ�������ӽڵ�,һ�������ӽڵ㡣�����ӽڵ��˳���ܵߵ������,�������в����ڶȴ���2�Ľڵ㡣
����������(BST����Binary Search Tree)�Ƕ�������һ��,���涨�����ӽڵ��ϴ洢С(�ȸ��ڵ�)��ֵ,�����ӽڵ���(�ȸ��ڵ�)�洢��(�����)��ֵ����ͼ����һ��������������
���ݶ�����������,һ���ڵ����ֻ�������ӽڵ�,���ǿ���ʹ�á�JavaScript���ݽṹ����������ʵ����Ӧ�á�һ���е�˫��������ʵ�ֶ����������е�ÿһ���ڵ㡣�����Ƕ��������������ݽṹʾ��ͼ:
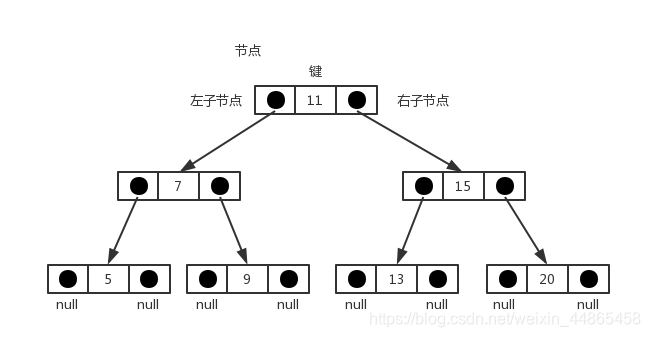
����ʵ��:
class BinarySearchTree {
constructor () {
this.root = null;
}
// �����в���һ���ڵ�
insert (key) {}
// �����в���һ���ڵ�
search (key) {}
// ͨ�����������ʽ�������е����нڵ�
inOrderTraverse () {}
// ͨ�����������ʽ�������е����нڵ�
preOrderTraverse () {}
// ͨ�����������ʽ�������е����нڵ�
postOrderTraverse () {}
// �������е���С�ڵ�
min () {}
// �������е����ڵ�
max () {}
// �������Ƴ�һ���ڵ�
remove (key) {}
}
��DoubleLinkedList����,ÿһ���ڵ�����������:element��next��prev��������������element��ʾ���нڵ��key,��next��ʾ���нڵ�����ӽڵ�(right),��prev��ʾ���нڵ�����ӽڵ�(left)��
insert (key) {
let newNode = new Node(key);
if (this.root === null) this.root = newNode;
else insertNode(this.root, newNode);
}
������rootΪnullʱ,��ʾ��Ϊ��,��ʱֱ�ӽ������ӵĽڵ���Ϊ���ĸ��ڵ㡣����,������Ҫ������˽�к���insertNode()����ɽڵ�����ӡ���insertNode()������,������Ҫ���������ӽڵ��key�Ĵ�С���ݹ������������ӽڵ�����Ҳ��ӽڵ�,��Ϊ�������ǵĶ����������Ķ���,ֵС�Ľڵ���Զ����������ӽڵ���,ֵ��Ľڵ�(����ֵ��ȵ����)��Զ�������Ҳ��ӽڵ��ϡ�������insertNode()������ʵ�ִ���:
let insertNode = function (node, newNode) {
if (newNode.element < node.element) {
if (node.prev === null) node.prev = newNode;
else insertNode(node.prev, newNode);
}
else {
if (node.next === null) node.next = newNode;
else insertNode(node.next, newNode);
}
};
1.10.3 ��ƽ����(ALV��)
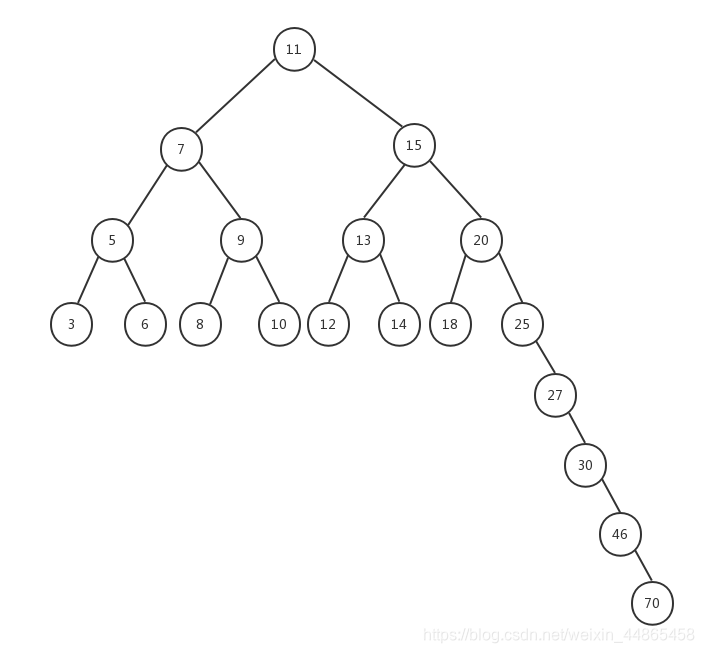
�����BST��(����������)����һ������,����һ���߿��ܻ�dz���,��������ȴֻ�м���,�������������ķ�֧�����ӡ��Ƴ��������ڵ�ʱ����һЩ�������⡣����ͼ��ʾ:
Ϊ�˽���������,������������ƽ�����������(AVL����Adelson-Velskii-Landi)����AVL��,�κ�һ���ڵ��������������ĸ߶�֮�����Ϊ1,���ӻ��Ƴ��ڵ�ʱ,AVL���᳢����ƽ�⡣��AVL���IJ����Ͷ�BST���IJ���һ��,��ͬ���������ǻ���Ҫ����ƽ��AVL��,�ڽ����AVL����ƽ�����֮ǰ,�����ȿ�һ��ʲô��AVL����ƽ�����ӡ�
����ǰ�����ǽ��ܹ�ʲô����(����)�ĸ߶�,����AVL����˵,ÿһ���ڵ㶼����һ��ƽ�����ӡ�
�ڵ��ƽ������ = �������ĸ߶� - �������ĸ߶�
�����۲����������,�����������ע��ÿ���ڵ��ƽ�����ӵ�ֵ:
����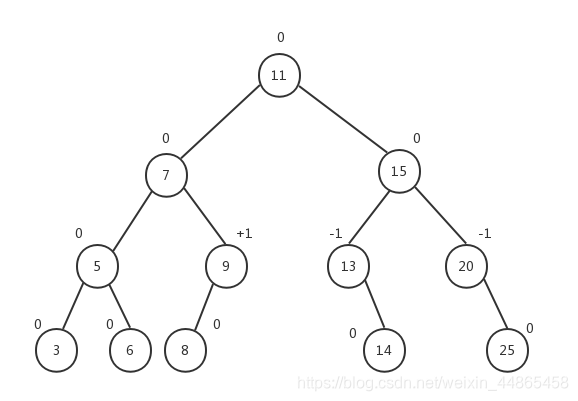
�����ӽڵ��ƽ�����Ӷ�Ϊ0,��Ϊ�ӽڵ�û���������ڵ�5�����������ĸ߶ȶ�Ϊ1,���Խڵ�5��ƽ��������0���ڵ�9���������߶�Ϊ1,�������߶�Ϊ0,���Խڵ�9��ƽ��������+1���ڵ�13���������߶�Ϊ0,�������߶�Ϊ1,���Խڵ�13��ƽ��������-1��AVL�������нڵ��ƽ�����ӱ�������ֵ:0��+1��-1��ͬʱ,����Ҳע�,��ij���ڵ��ƽ������Ϊ+1ʱ,����������������б��(left-heavy);����ij���ڵ��ƽ������Ϊ-1ʱ,����������������б��(right-heavy);���ڵ��ƽ������Ϊ0ʱ,�ýڵ���ƽ��ġ�һ�������ĸ��ڵ��ƽ�����Ӵ����˸�������ƽ���ԡ�
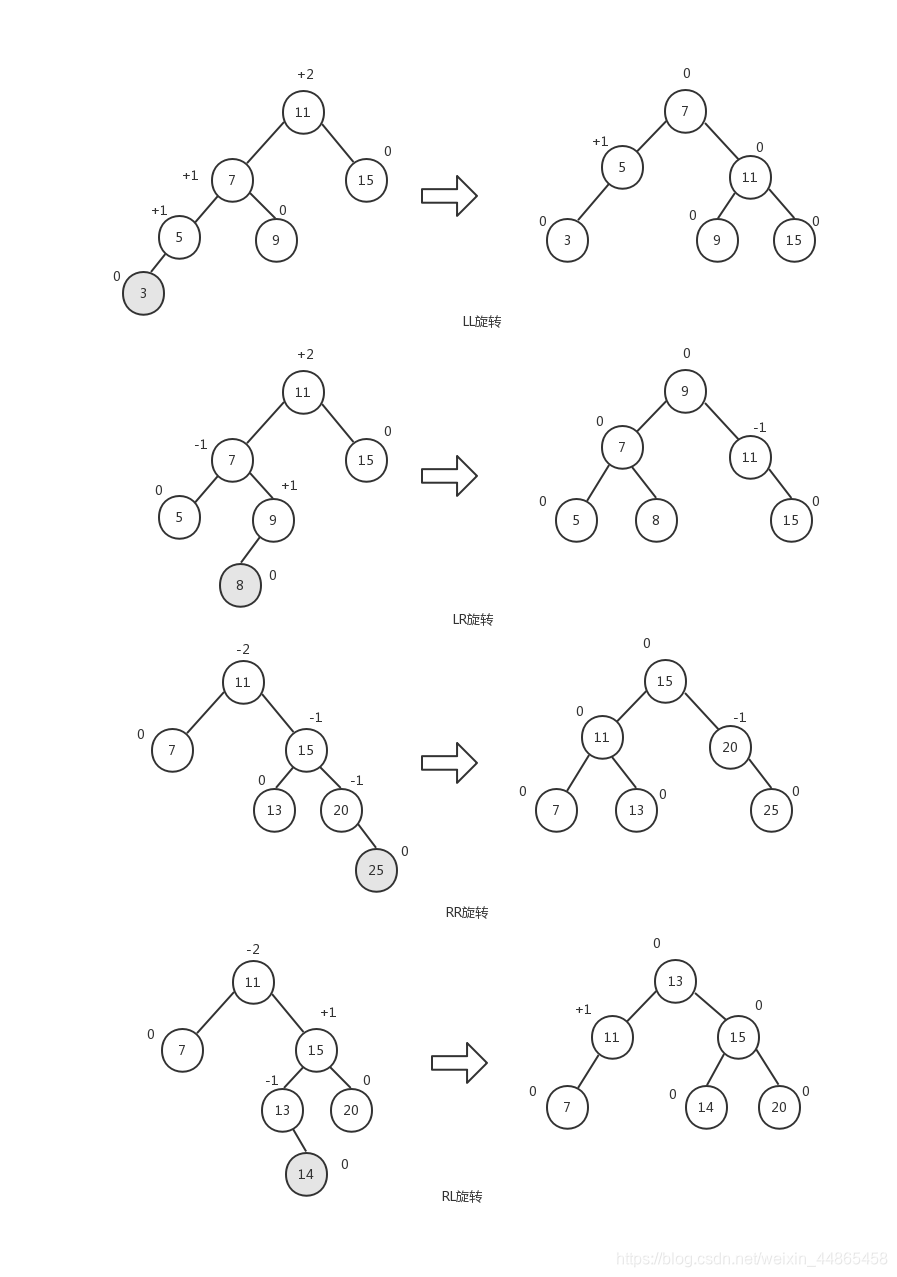
Ϊ��ʹAVL�����´ﵽƽ��״̬,������Ҫ��AVL���еIJ��ֽڵ������������,ʹ��ȷ��϶����������Ķ���,�ַ�����ƽ��������Ķ���,������̽���AVL������ת��
AVL������תһ����Ϊ����:
LL(left-left)��ת,�����ӵĽڵ�λ�����ĸ��ڵ�����������������ϡ��Է�ƽ�����ӵĽڵ�Ϊ���Ľ�������������ת��
LR(left-right)��ת,�����ӵĽڵ�λ�����ĸ��ڵ�����������������ϡ���ִ��RR��ת,Ȼ����ִ��LL��ת��
RR(right-right)��ת,�����ӵĽڵ�λ�����ĸ��ڵ�����������������ϡ��Է�ƽ�����ӵĽڵ�Ϊ���Ľ�������������ת��
RL(right-left)��ת,�����ӵĽڵ�λ�����ĸ��ڵ�����������������ϡ���ִ��LL��ת,Ȼ����ִ��RR��ת��
��������������ת�IJ���ʾ��ͼ:
����
�����
�������һ��ƽ������������������Խ��и�Ч�����������ͨ�����κ�һ���Ӹ���Ҷ�ӵļ�·���ϸ����ڵ����ɫ����Լ��,ȷ��û��һ��·���������·����2��,����ǽ���ƽ��ġ�����������ϸ�Ҫ��ƽ���AVL����˵,������ת����ƽ��������١���������ʱ,����ɾ�����������������Ǿ��ú������ȡ��AVL
����������е�Ѿ�,д����,����ҾͿ�����ƪ���°�:
javascript ������㷨��˵��
JavaScriptʵ�����ݽṹ���㷨08���������
�������ֱ�����ʽ
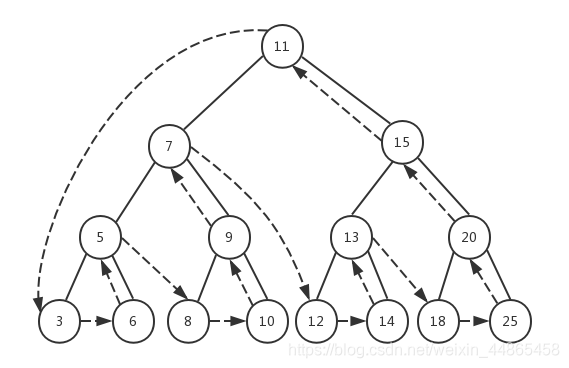
ǰ�����(NLR����Preorder Traversal)Ҳ���������,�ȷ���������,�ڷ��ʸ��ڵ�,������������
�ھ�:�����
�������(LNR����Inorder Traversal),�ȷ��ʸ��ڵ�,�������������������
�ھ�:������
�������(LRN����Postorder Traversal),�ȷ���Ҷ�Ӽ�����������������������
���Ҹ�
ǰ�����:
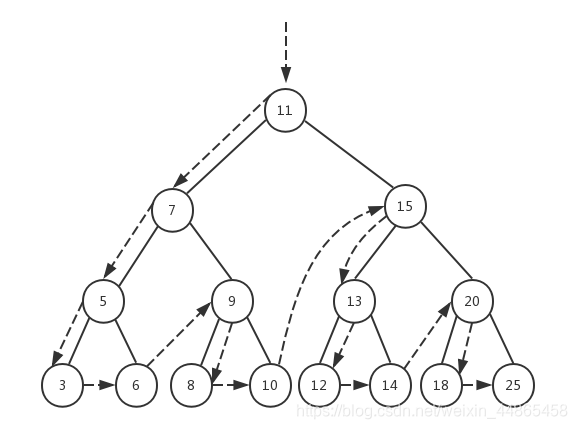
�������:
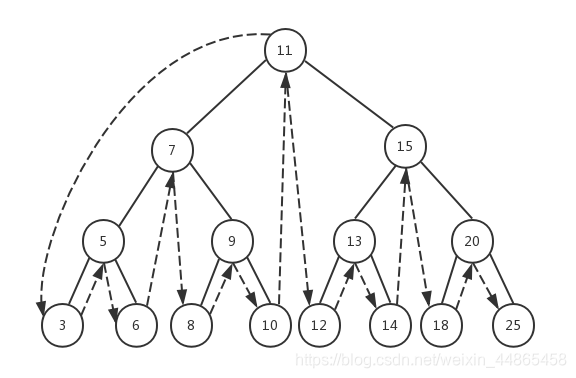
�������:
����ʵ��:
// ǰ�����
let preOrderTraverseNode = function (node, callback) {
if (node !== null) {
callback(node.element);
preOrderTraverseNode(node.prev, callback);
preOrderTraverseNode(node.next, callback);
}
};
// �������
let inOrderTraverseNode = function (node, callback) {
if (node !== null) {
inOrderTraverseNode(node.prev, callback);
callback(node.element);
inOrderTraverseNode(node.next, callback);
}
};
// ��������
let postOrderTraverseNode = function (node, callback) {
if (node !== null) {
postOrderTraverseNode(node.prev, callback);
postOrderTraverseNode(node.next, callback);
callback(node.element);
}
};
���ij���
�������е���Сֵ
�������е����ֵ
�������е��ض�ֵ
ɾ���ڵ�
�������е���Сֵ
����������,�ҵ����һ���ӽڵ�
����ʵ��:
let minNode = function (node) {
if (node === null) return null;
while (node && node.prev !== null) {
node = node.prev;
}
return node;
};
�������е����ֵ
�����ҽڵ�,ֱ���ҵ����һ���ӽڵ�
����ʵ��:
`let maxNode = function (node) {
if (node === null) return null;
while (node && node.next !== null) {
node = node.next;
}
return node;
};`
�������е��ض�ֵ
�����ַ�ʽ�������ض���ֵ,������Ҫ�Ƚ�Ҫ������ֵ�뵱ǰ�ڵ��ֵ,���Ҫ������ֵС�ڵ�ǰ�ڵ��ֵ,��ӵ�ǰ�ڵ㿪ʼ�ݹ����������(���ӽڵ�)�����Ҫ������ֵ���ڵ�ǰ�ڵ��ֵ,��ӵ�ǰ�ڵ㿪ʼ�ݹ����������(���ӽڵ�)
����ʵ��:
let searchNode = function (node, key) {
if (node === null) return null;
if (key < node.element) return searchNode(node.prev, key);
else if (key > node.element) return searchNode(node.next, key);
else return node;
};
ɾ���ڵ�
���ɾ���Ľڵ�ΪҶ�ӽڵ�,��ֱ��ɾ����
���ɾ���Ľڵ�ֻ��һ���ӽڵ�,��ֱ��ɾ���ڵ�ĸ��ڵ�,ָ�����ӽڵ�
�����ɾ���Ľڵ���������ӽڵ�,����ѡ������������Сֵ����һ����ʱ�ӽڵ�,Ȼ���Ƶ���ɾ�ڵ�,Ȼ��ɾ����С�ӽڵ㡣
1.11����ѺͶ�����
1.11.2����Ѹ������ص�
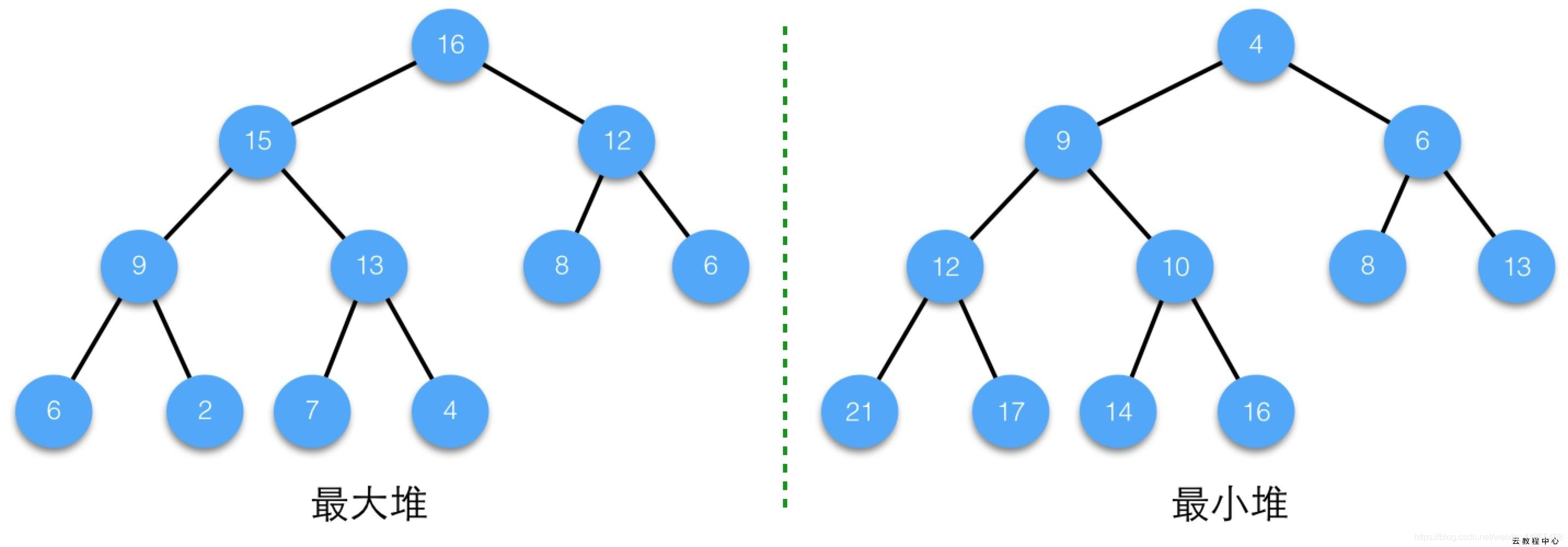
�������һ������Ķ�����
Ҳ���Ƕѵ����ݽṹ,Ҳ���������,�ܸ�Ч�IJ��ҳ����ֵ����Сֵ
����Ӧ�������ȶ�����,Ҳ����������ע���Ķ������㷨��
�ص�:
�������һ����ȫ������,��ȫ��������ʾ����ÿһ�㶼����������������,(�������һ��Ҷ�ӽڵ�),�������һ�����ٶ�Ӵһ��������,
����ṹ����
����Ѳ�����С�Ѿ�������,��С�����������ҳ���Сֵ,���������ҳ����ֵ,���еĽڵ㶼���ڵ���(����)��С�ڵ���(��С��)��ÿ���ӽڵ�,
���������
1.11.3 ����ѵ�ʵ��
����:
class MinHeap{
constructor() {
this.heap = []
}
// �滻�����ڵ�ֵ
swap(i1,i2){
const temp = this.heap[i1];
this.heap[i1] = this.heap[i2];
this.heap[i2] = temp;
}
// ��ȡ���ڵ�
getParentIndex() {
return (i -1) >> 1; //���2����
}
// ��ȡ��ڵ�
getLeftIndex() {
return i * 2 + 1; //���2����
}
// ��ȡ�ҽڵ�
getRightIndex() {
return i * 2 + 2; //���2����
}
// ����
shiftUp(index) {
if(index == 0) {return;}
const parentIndex = this.getParentIndex(index);
if(this.heap[parentIndex] > this.heap[index]) {
this.swap(parentIndex,index);
this.shiftUp(parentIndex);
}
}
// ����
shiftDown() {
const leftIndex = this.getLeftIndex(index);
const rightIndex = this.getRightIndex(index);
if(this.heap[leftIndex] < this.heap[index]) {
this.swap(leftIndex,index);
this.shiftDown(leftIndex);
}
if(this.heap[rightIndex] < this.heap[index]) {
this.swap(rightIndex,index);
this.shiftDown(rightIndex);
}
}
// ����
insert(value) {
this.heap.push(value);
this.shiftUp(this.heap.length - 1);
}
// ɾ���Ѷ�
pop() {
this.heap[0] = this.heap.pop();
this.shiftDown(0);
}
// ��ȡ�Ѷ�
peek() {
return this.heap[0];
}
// ��ȡ�ѵĴ�С
size() {
return this.heap.length;
}
}
const h = new MinHeap();
h.insert(3);
h.insert(2);
h.insert(1);
h.pop();
�����:
JavaScript ʵ��:��С����
����:
let heap = [];
function swap(index1, index2) {
let temp;
temp = heap[index1];
heap[index1] = heap[index2];
heap[index2] = temp;
}
function shiftup(index) {
let parentIndex = (index - 1) >> 1// Math.floor((index - 1) / 2);
if (index != 0 && heap[parentIndex] < heap[index]) {
swap(parentIndex, index);
shiftup(parentIndex);
}
}
function shiftDown(index) {
let leftNodeIndex = (index + 1) * 2 - 1, rightNodeIndex = (index + 1) * 2
if (leftNodeIndex < heap.length && heap[leftNodeIndex] > heap[index]) {
swap(leftNodeIndex, index);
shiftDown(leftNodeIndex);
} else if (rightNodeIndex < heap.length && heap[rightNodeIndex] > heap[index]) {
swap(rightNodeIndex, index);
shiftDown(rightNodeIndex);
}
}
function insert(val) {
heap.push(val);
shiftup(heap.length - 1);
}
function remove() {
swap(0, heap.length - 1);
heap.pop();
shiftDown(0);
return heap[0];
}
insert(1);
insert(3);
insert(2);
insert(5);
remove();
insert(4);
insert(6);
remove();
console.log(heap);//[ 4, 3, 2, 1 ]