一、HashMap数据结构
二、初始化
三、put操作过程
以上内容可查看:深入源码谈HashMap(一)
四、HashMap扩容机制
查看HashMap的putVal源码
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
.....
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
发现其实就只有两个地方调用了扩容方法resize(),第一个地方在上一篇文章中已经说明过了,也就是第一次put操作,数组为null或者长度为0的时候调用,用来做初始化。第二次调用就是在put操作结束后,判断元素个数是否大于了阈值,大于了就调用就行扩容操作。
size:就是插入的元素的个数,这里要注意是所有元素个数,而不是只算插在数组里面的,插在链表里的也算;
threshold:阈值,也就是加载因子乘容量,默认为0.75*16=12。
下面假设表长为16阈值为12,已经插入了13个元素,那么就会调用resize方法,来看源码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//旧表长度为16,满足条件
if (oldCap >= MAXIMUM_CAPACITY) {//判断是否大于最大容量,就表长度16不满足该条件
//最大容量为:MAXIMUM_CAPACITY = 1 << 30 = 2的30次方
threshold = Integer.MAX_VALUE;//设置阈值为整形最大值也就是2的31次方减1
return oldTab;//不扩容了返回旧表
}//如果不大于最大容量
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)//旧表满足该条件
newThr = oldThr << 1;
//先给旧容量扩大两倍,然后如果扩大两倍后小于最大容量且
//旧容量大于等于默认初始化任意也就是大于等于16,那么阈值也
//扩大两倍,否则不扩大
//本次运行,运行到这里后容量有16变成了32,阈值由12变成了24
}
.....
threshold = newThr;//局部变量赋值给全局变量
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//扩容创建一个新数组
table = newTab;//局部变量赋值给全局变量
...
return newTab;
}
上述代码运行完毕后,数组也就算是扩容了,但还有个步骤,那就是数据迁移。
为什么要数据迁移?
首先前面说过,不同的hash值通过相同的算法是可以得到相同的下标的,例如有两个元素A和B,设两个key的hash值为5和21,在扩容之前数组长度为16,通过(len-1)& hash计算得出A元素数组下标为5,B元素数组下标也为5,所以A和B都会插入下标为5的数组里,组成一个单链表。
现在扩容后,长度为32,A、B元素key的hash值不变,再次通过计算得出A元素数组下标为5,B元素数组下标为21,两个元素已经不适合组成一个单链表了,所以得将B数据迁移,重新找到合适位置。
怎么实现迁移?
针对四种情况有四种不同的解决方案
- 旧表中数据为null的,不用管;
- 旧表中数据不为null但没链化的,重新计算下标插入;
- 旧表中数据不为null但链化了的,根据高位情况分为两条链表;
- 旧表中数据不为null但树化了的,根据高位情况分为两条链表或树。
先来看resize方法里数据迁移源码:
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
下面开始分析
首先判断旧数组是不是为null:
if (oldTab != null) {
....
}
为null肯定就不用迁移了,不为null利用for开始遍历数组:
for (int j = 0; j < oldCap; ++j) {
.....
}
接下来判断第一种情况:元素是不是为null:
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
......
}
可以看到,如果不为null,就先断开引用,接下来判断第2、3、4种情况,如果为null就不用管,没有else。
下面判断第二种情况:不为null但没链化:
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
链化的特征就是next属性不为null,指向另一个节点,这里判断为null那就说明没有链化,那么获取hash值重新计算下标插入新表中,为null那么进入第4种情况判断:不为null但是树化了:
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
这判断就很简单了,因为树化后节点就变了,由Node变成了TreeNode,直接判断该节点是不是TreeNode对象就可以判断有没有树化,树化了怎么操作后面再讲。
如果没有树化那肯定就是链化了,看源码:
else {
Node<K,V> loHead = null, loTail = null;//定义低位链表的头节点和尾结点
Node<K,V> hiHead = null, hiTail = null;//定义高位链表的头节点和尾结点
Node<K,V> next;//定义旧链表的下一个节点
do {
next = e.next;//先获取e的下一个节点
if ((e.hash & oldCap) == 0) {//判断高位是不是0
//是0就往低位链表里插
if (loTail == null)//判断尾结点是不是null
loHead = e;//是就说明是第一个节点,让该节点变成头结点
else
loTail.next = e;//不是就说明不是第一个节点,插最后节点的后面
loTail = e;//新插的节点变成最后的节点
}
else {//不是0就往高位链表插
//下面代码和上面代码类似
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);//知道遍历到链表末尾
if (loTail != null) {//如果低位链表有节点
loTail.next = null;
newTab[j] = loHead;//将头节点原来的位置
}
if (hiTail != null) {//如果高位链表有节点
hiTail.next = null;
newTab[j + oldCap] = hiHead;//插到原来位置在家原来数组长度的位置
}
}
解释一下上面的操作。
什么是高位?
高位就是旧数组长度写成二进制,数据为1的那一位算高位,1右边的都是低位。
例如:16
写成二进制(为了方便只写8位):0001 0000
那么第5位就是高位。
怎么判断高位是不是0?
代码里使用的是:e.hash & oldCap
也就是hash值和就数组长度进行与运算就可得出,例如上面举的例子5和21
5 二进制为: 0000 0101
16二进制为:0001 0000
得出结果为0,那么高位就是0。
再来计算21
21二进制为:0001 0101
16二进制为:0001 0000
得出结果为1,那么高位就是1。
得出高位来了有什么用呢?为什么高位是分组的依据呢?
当然这里的高位指的是分组前的高位也就是第五位,前面分析过,哈希值为5和21组成的链表要进行数据迁移是因为扩容后,21通过算法计算下标时,下标已经改变了,计算出高位就是将那些下标要改变了的节点挑出来。他们以前能在一个节点是因为他们低位相同,5和21的低位都是0101所以他们才在一条链表上,扩容后低位+1,变成了五位,高位由第五位变成第六位,5和21的低位已经不一致了,5为00101,21为100101,不能再放到同一个链表了。换句话说就是扩容前的高位不一致了,这里就是第5位不一致了,所以用第五位来作为分组依据,效率高。
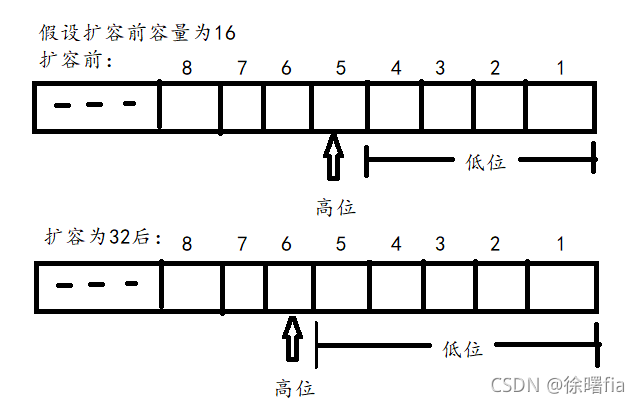
于是就分成了两个链表,低位链表位置不变原来在哪里就插到哪里,高位链表位置插到原来下标加原来数组长度计算得出的下标位置,比如ke的yhash值为21的节点,原来下标为5,新下标为5+16=21,为什么要这么加?因为21的低位加了一个第五位也就是加了16,新下标自然也就加了16。
还有个问题没有解决,树化了怎么迁移数据?
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
源码中,如果是树节点,先强制转换成TreeNode类型,在调用split方法,来看源码:
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
//bit就是旧容量
TreeNode<K,V> b = this;//b就是调用者,也就是resize方法里面的e
//也是分为高低链表
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;//链表长度+1
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)//判断是不是小于6
tab[index] = loHead.untreeify(map);//小于6变成链表
else {
tab[index] = loHead;
if (hiHead != null)
loHead.treeify(tab);//否则变成树
}
}
//与上面类似
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
经过前面的讲解上面代码已经很简单了,就是比链表迁移多了一个步骤,判断长度是否大于6,大于6就将链表树化,否则将TreeNode节点链表变成Node节点链表插入。
扩容机制就讲解完毕了,用一段话来概括就是:
HashMap都有一个阈值,阈值是加载因子乘容量,每次插入后都会判断是否需要扩容,如果已经插入了的元素个数大于阈值,那么就调用扩容方法resize。新容量一般都是旧容量的两倍,阈值也是旧阈值的两倍,然后new一个新容量大小的数组,将引用赋值给旧数组。之后就进行数据迁移,循环遍历数组,数据迁移分为四种情况:第一种如果数组元素为null,就不用操作;第二种如果不为null且没有成链表,重新计算下标赋值;第三种如果不为null但是是树节点,开始遍历树,根据高位是否为0分成两条新链表,分完之后为0的链表先判断链表长度是否小于等于6,是就将TreeNode节点链表转换成Node节点链表,否则变成树,插在原来的位置,不为0的链表同样先判断链表长度是否小于等于6,是就将TreeNode节点链表转换成Node节点链表,否则变成树,插在在原来的位置上偏移旧容量大小的位置;第四种如果不为null已经成链表,根据高位是否为0分成两条新链表,分完之后为0的链表插在原来的位置,不为0的链表在原来的位置上偏移旧容量大小的位置。
五、HashMap的多线程问题
在JDK1.7中,多线程下数据迁移会造成链表成环的问题,前面分析的是1.8版本的源码,在1.8版本中成环问题已经修复,因此成环过程不详细讨论,成环的主要原是是从旧链表的头结点开始采用头插法插入新链表,导致插入的顺序和原来链表的顺序相反的。数组是共享的,数组里面的元素也是共享的,while 循环都直接修改数组 里面的元素的 next 指向,导致指向混乱。
JDK1.8怎么修复的呢?
从前面分析的源码可以看出,JDK8加入了红黑树,改用尾插法,且扩容时是等链表整个 while 循环结束后,才给数组赋值,此时使用局部变量 loHead 和 hiHead 来保存链表的值,因为是局部变量,所以多线程的情况下,就没有问题了。
下面讨论一下JDK1.8在多线程下出现的问题
①数据丢失问题
在putVal方法中,每次put之前都会判断是否出现hash碰撞:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
如果有两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的且该下标对应的元素为null,就比如前面举例的5和21,假设当线程A执行完判断后由于时间片用完成中断状态。
if ((p = tab[i = (n - 1) & hash]) == null)
//线程在此A中断
ab[i] = newNode(hash, key, value, null);
线程B得到时间片后,因为线程A还没插入依旧为null,所以线程B可以在该下标处插入了元素,并且完成了插入,然后线程A获得时间片,此时不会再进行判断,而是直接插入,这就导致了线程B插入的数据被线程A覆盖了,从而导致B插入的数据丢失。
②元素数量计算错误
依旧是putVal方法,该方法的后面++size操作:
if (++size > threshold)
resize();
我们知道 ++size不是原子操作,完成这条指令需要分几步完成,将size取出、size+1、赋值给size,同样如果有两个线程A、B,这两个线程同时进行put操作时,假设zise大小为8,当线程A执行到++size代码时,获得size的值为8后准备进行+1操作,但是由于时间片用完让出CPU执行权,线程B的拿到CPU又从获得size的值也就是8进行+1操作,完成了put操作并将size=9写回内存,然后线程A再次拿到CPU并继续执行size,前面已经拿出来了所以size还是8,,当执行完put操作后,还是将size=9写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,就造成元素数量计算错误,可能就会丢失某个数据。
六、解决Hash冲突的方法
解决Hash冲突一般是四种办法,这里简单介绍。
①开放地址法
开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入 。
公式为:fi(key) = (f(key)+di) MOD m (di=1,2,3,……,m-1)
比如说,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。 计算key = 37时,发现f(37) = 1,且1位置有元素,此时就与1位置冲突。
于是我们应用上面的公式f(37) = (f(37)+1) mod 12 = 2。于是将37存入下标为2的位置。
②拉链法
对于相同的值,使用链表进行连接。使用数组存储每一个链表,也就是HashMap使用的方法。
③再哈希法
对于冲突的哈希值再次进行哈希处理,有多个不同的Hash函数,直至没有哈希冲突。可以理解为p=hash(key)如果冲突就p=hash2(key)…
④建立公共溢出区
建立公共溢出区存储所有哈希冲突的数据。将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
七、HashMap相关面试题
这里整理里网上的一些HashMap的相关面试题,看完这两篇文章相信都能回答出来。
- 对hash的理解?
- hash会不会有问题?
- hash冲突可以避免吗?
- HashMap存储的结构?
- HashMap数组初始长度?
- 什么时候创建数组?
- 默认的负载因子是多少?有什么用?
- 链表转化为红黑树有什么条件?
- hash是key的hashcode的返回值吗?
- 计算hash为什么要采用高低位异或?
- put写数据流程 ?
- 红黑树写入找到它的父节点流程?
- 红黑树的几个原则?
- HashMap为什么要引入红黑树?
- 什么情况下回触发HashMap的扩容机制?
- 扩容后会扩容多大?算法是什么样的?
- 扩容为什么要位移运算?为什么不能直接乘2?
- 创建新数组后老数组数据怎么迁移?
到处结束!