9.5 Set接口与Map接口
9.5.1 Set接口
Set接口是Collection的子接口,适用于不允许出现重复的元素。放入Set的元素必须定义equals() 方法,以确保对象的唯一性。 与List 不同的是Set 中元素的次序不保持有序。Set接口以普通的散列表数据结构实现,用于存储键-值数据对,能提供快速的查找功能。每个对象都作为数据存放在散列表中,由类库负责维护散列表,把对象存储到合适的位置。
Set接口有一个子接口SortedSet,它提供了保证迭代器按照元素递增顺序遍历的方法,可以按照元素的自然顺序排序,或者按照创建有序集合时提供的比较器Comparator进行排序。比较器可用于对象排序程序中,但它不负责排序,只比较两个对象,把结果传递给排序
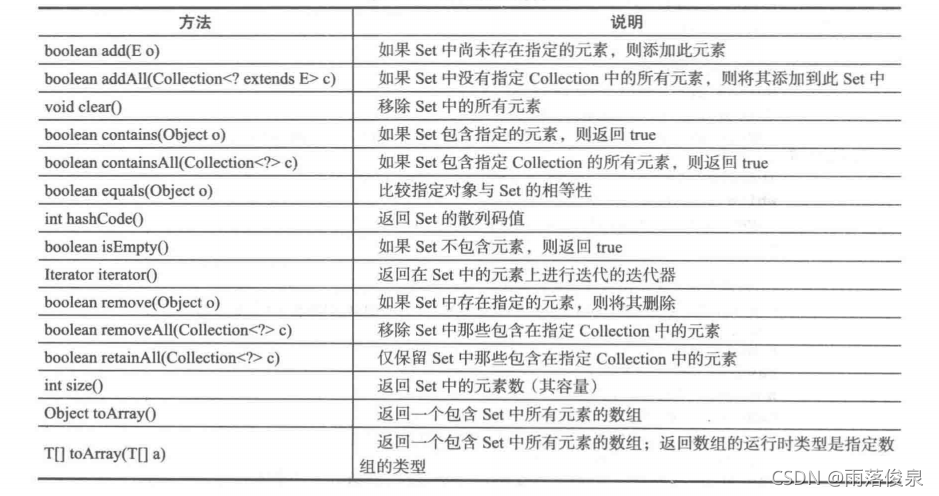
的方法,Set 接口的主要方法如表所示。
实现Set接口有以下三个主要具体类
HashSet :使用散列表结构存储元素,可以随机访问,通常用于快速检索。它不保证集合的迭代顺序,特别是不保证该顺序恒久不变,此类允许使用null元素。
TreeSet:使用树结构来存储元素,此类保证排序后的Set按照升序排列元素,比HashSet检索慢。它实现了SortedSet 接口,也就是加入了对象比较的方法,通过迭代集合中的对象,可以得到一个升序的对象集合。
LinkedHashSet :具有HashSet的查询速度,此实现与HashSet的不同之处在于,其内部使用链表维护元素的插入次序。此链表定义了迭代顺序,在使用迭代器遍历Set时,将按照元素插入集合中的顺序进行迭代。
下面举例说明三种Set的用途,它们都可以用来过滤重复元素。使用时首先实例化,然后把对象作为新元素添加到散列表中。
示例:将有重复元素的字符串添加到HashSet、TreeSet和LinkedHashSet集合中,在添加过程中,集合自动去掉重复的元素。
代码如下
public class SetTest {
public static void main(String[] args) {
//过滤重复元素,但是不保证元素的迭代次序
String[] strArray = new String[]{"one","world","one","dream"};
Set<String> s = new HashSet<String>();
for (int i = 0; i <4 ; i++) {
if(!s.add(strArray[i])){
//添加strArray元素到集合s中
System.out.println("Duplicate detected: "+strArray[i]);
}
}
System.out.println(s.size()+" distinct words: "+s);
//自动按照升序排列内容,并过滤重复元素
TreeSet<String> treeSet = new TreeSet<>();
treeSet.add("b");
treeSet.add("a");
treeSet.add("c");
treeSet.add("d");
treeSet.add("b");
System.out.println("TreeSet:");
System.out.println(treeSet);
System.out.println("the first element is: "+treeSet.first());
//返回第一个元素
Iterator<String>iterator = treeSet.iterator();//迭代器
while(iterator.hasNext()){
System.out.println(iterator.next()+";");
}
//过滤重复元素,不保证元素的迭代次序
LinkedHashSet<String> hashSet =new LinkedHashSet<>();
hashSet.add("b");
hashSet.add("a");
hashSet.add("c");
hashSet.add("d");
hashSet.add("b");
System.out.println("LinkedHashSet: ");
System.out.println(hashSet);
Iterator<String> iterator1 = hashSet.iterator();
while(iterator1.hasNext()){
System.out.println(iterator1.next()+";");
}
}
}
运行结果如下
Duplicate detected: one
3 distinct words: [world, dream, one]
TreeSet:
[a, b, c, d]
the first element is: a
a;
b;
c;
d;
LinkedHashSet:
[b, a, c, d]
b;
a;
c;
d;
9.5.2 Map接口
Map提供了一个更通用的元素存储方法,Map接口是Map集合框架的根接口,它不属于Collection接口。Map集合类用于存储元素对(称为键-值对),其中每个键映射到一个值,而且不能有重复的键。每个键只能够映射到一个值,但是允许多个键映射到同一个值。这种键-值对的例子日常用到不少,如姓名与电话号码、书号和书名、宠物和主人等,Map 通常用于由某个对象查找另一类型对象。
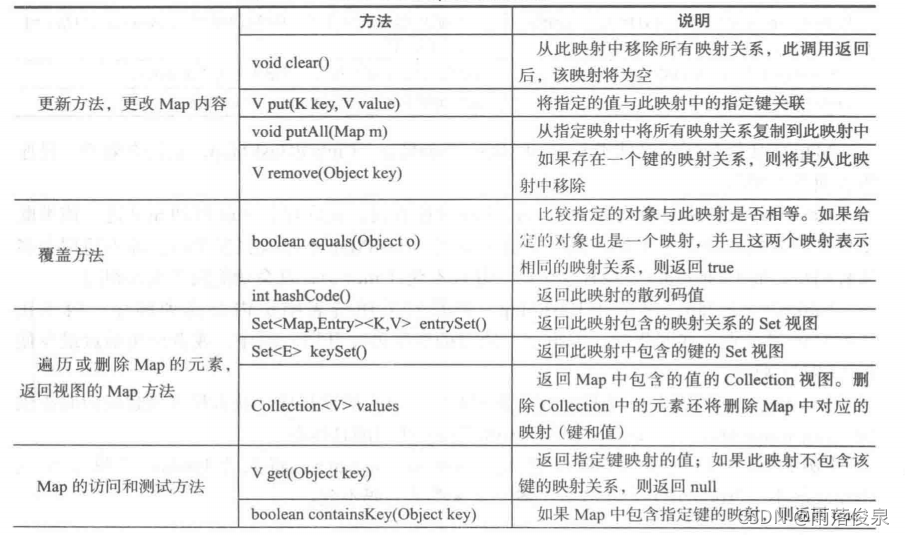
几乎所有通用的Map都使用散列映射,这是一种将元素映射到数组的简单机制,通过散列函数将对象转换为一个适合内部数组的整数,期间会调用每个对象都包含的一个返回整数值的hashCode()方法,Map的常用方法如表所示
Map接口提供3种可能的视图,允许以键集、值集或键-值对集的形式查看某个映射的内容,或者要遍历的所有元素。以下是三种可能的视图:
●键-值对集:参见entrySet()。
●键集:参见keySet()。
●值集:参见values()。
键-值对集和键集两个视图均返回Set对象,值集视图返回Collection对象,若要遍历,则需要获得一个Iterator 对象。
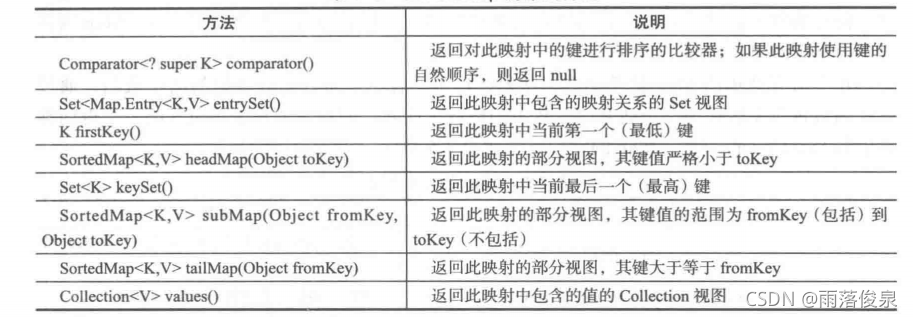
Map接口的一个重要子接口SortedMap提供排序功能,凡是实现此接口的具体类都属于排序的子类,比如TreeMap就是SortedMap的子类,具备排序功能。SortedMap的常用方法如表所示。
Map中比较常用的具体类有HashMap、TreeMap、 LinkedHashMap,它们在效率、排序等方面各不相同。
HashMap:使用对象的hashCode()实现快速查找,允许存储null值和null键,该类既不保证映射的顺序,也不保证该顺序持久不变。HashMap不是线程安全的,即不适用于多线程同步;而HashTable是线程安全的,并且不允许null值,其余功能两者大致相同。
LinkedHashMap:类似于HashMap,但是它采用链表维护内部排列顺序,效率比HashMap慢一点, 在遍历时,取得键-值对的顺序遵循其插人顺序,或者使用最近最少使用(LRU)顺序。
TreeMap:采用红黑树结构实现,根据其键的自然顺序排序,或者根据创建映射时提供的Comparator排序。TreeMap 是实现SortedMap接口的具体类。
示例 使用HashMap,将几个Product对象添加到HashMap中,ProductID 作为Map的键,其余类的代码不变。
代码如下
public class MapTest {
public static void main(String[] args) {
Product t1 = new Product(11,"lenovo");
Product t2 = new Product(12,"dell");
Product t3= new Product(13,"mac");
Map<Integer,String> map = new HashMap<>();
map.put(t1.getId(),t1.getName());
map.put(t2.getId(),t2.getName());
map.put(t3.getId(),t3.getName());
Set<Integer> set = map.keySet();
System.out.println("Map集合中所有元素是:");
Iterator<Integer>it = set.iterator();
while (it.hasNext()){
Integer key = (Integer)it.next();
String name = (String)map.get(key);
System.out.println(key+"――"+name);
}
map.remove(11);//将id为"11"的对象从集合中删除
System.out.println("Map集合执行删除操作以后所有元素是:");
Iterator<Integer>iterator = set.iterator();
while (iterator.hasNext()){
Integer key = (Integer)iterator.next();
String name = (String)map.get(key);
System.out.println(key+"――"+name);
}
}
}
运行结果如下
Map集合中所有元素是:
11――lenovo
12――dell
13――mac
Map集合执行删除操作以后所有元素是:
12――dell
13――mac
Java集合框架中各种集合的使用方法总结如下:
1)Collection、List、 Set、 Map都是接口,不能实例化,只有实现它们的ArrayList、LinkedList、HashTable、 HashMap这些常用具体类才可被实例化。
2)在各种List集合中,LinkedList 适用于快速插人、删除元素,可用于构建栈Stack、队列Queue; ArrayList 适用于快速随机访问元素。最好的做法是以ArrayList作为默认选择。
3)在各种Set中,HashSet 的插人、查找效率通常优于HashTree, 一旦需要产生一个经过排序的序列,则可选用TreeSet,因为它能够维护其内元素的排序状态。
4)在各种Map中,HashMap的用途最为广泛,可提供快速查找,TreeMap 适用于需要排序的序列。