简介
- EM算法
最大期望算法(Expectation-maximization algorithm,简称EM,又译期望最大化算法)在统计中被用于寻找依赖于不可观察的隐性变量的概率模型中,参数的最大似然估计。在统计计算中,最大期望(EM)算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐性变量。最大期望算法经常用在机器学习和计算机视觉得数据聚类领域。EM算法的标准计算框架由E步和M步交替组成,算法的收敛可以确保迭代至少逼近局部极大值。EM算法被广泛应用于处理数据的缺失值,以及很多机器学习算法,包括高斯混合模型和隐马尔科夫模型的参数估计。
- Jensen不等式
琴生不等式是以丹麦技术大学数学家约翰・延森(Johan Jensen)命名,它给出积分的凸函数值和凸函数的积分值间的关系。Jensen不等式是关于凸函数性质的不等式,它和凸函数的定义是息息相关的。

- 设f是定义域为实数的函数,如果对于所有的实数x,f(x)的二次导数大于等于0,那么f是凸函数
- 如果f是凸函数,X是随机变量,那么满足Jensen不等式:E(f(x))>=f(E(x))
- Jensen不等式应用于凹函数时,不等号方向反向。
算法原理
实例解析

初始假设
我们有AB两个硬币,我们进行抛硬币的实验,假设每枚硬币的出现正反的概率不一致。这个概率就是一个隐变量。我们假设:
A币出现正面概率是0.6,B币是0.5:
我们分别抛十次硬币,会出现5正5反的概率是:
p(a):C10(5)*0.6^5 *0.4^5
p(b):C10(5)*0.5^5 *0.5^5
那么我们选择A硬币的概率是P(A) = p(a)/p(a)+p(b) = 0.45
选择B的概率是P(B) = 1-P(A) = 0.55
E-step
-
1、初始值选择A的概率是:0.45,此时有5次H,5次T,可以计算出
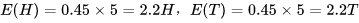
选择B的概率是:0.55,此时有5次H,5次T,可以计算出
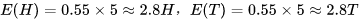
-
2、先来看一下投掷出9次正面1次反面的概率
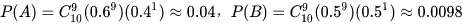
选择硬币A的概率
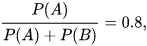
选择硬币B的概率
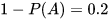
我们分别计算硬币A正反面的期望:
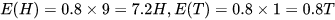
硬币B正反面的期望:
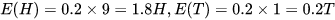
-
3、依次计算出所有的样本,并分别将A和B硬币出现H和T的期望求和,
A硬币
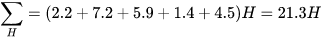
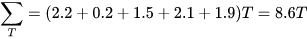
B硬币
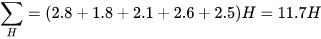
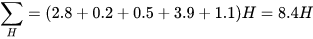
M-step
通过E-step计算的结果分别求出两个硬币的分布
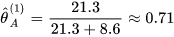
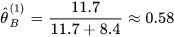
将上述两个结果带入第一步进行迭代,不断更新P(A)和P(B),直到结果收敛为止就得到了我们需要的结果。
算法流程
-
1、初始化分布参数
-
2、E-step:根据参数计算每个样本属于的概率
-
3、M-step:根据每个样本所属概率,求出含有的似然函数的下界并最大化它,得到新的参数
-
4、不断地迭代更新下去,直到P(A) P(B)收敛。
GMM算法
GMM高斯混合模型,也可以简写成MOG.高斯模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。GMM的目的就是找到一个合适的高斯分布(也就是确定高斯分布的参数μ,Σ),使得这个高斯分布能产生这组样本的可能性尽可能大(即:拟合样本数据)。高斯混合模型也?被视为一种聚类方法,是机器学习中对“无标签数据”进行训练得到的分类结果。其分类结果由概率表示,概率大者,则认为属于这一类。
-
算法适合的情形:
数据内部有多个类别,每个类别的数据呈现不同的分布,这时我们就可以使用GMM算法,尤其是有隐变量,隐变量有不同的分布。
案例分析1
数据:桥上自行车的数量
https://mijisou.com/q=%EF%BC%9F%EF%BC%9F&category_general=on&time_range=&language=zh-CN&pageno=1
1.观察数据集和相应的处理
data = pd.read_csv("F:\Mechine_learning_code1\数据\Fremont_Bridge_Bicycle_Counter.csv")
data = data.drop(labels="Fremont Bridge Total",axis = 1)
data["Date"] = [i[0:-3] for i in data["Date"]]
data = data.set_index(data['Date'])
data = data[['Fremont Bridge East Sidewalk','Fremont Bridge West Sidewalk']]
# print(data.head(10))
%matplotlib inline
data.plot()
plt.show()

2.数据重采样
# 重采样
data.index = pd.to_datetime(data.index)
data.resample('w').sum().plot()
plt.show()

3.通过天的形式呈现年的数据

4.按照每天的时间求平均值,观察峰值

5.按桥两边计算每个时间的停车数

6.降维


7.聚类操作和分类结果
# 使用GMM进行聚类
gmm = GaussianMixture(n_components=2)#两种高斯分布
print(np.isnan(data).any())
data = data.fillna(0)
# data_inf = np.isinf(data)
# data[data_inf] = 0
# print(data.info())
gmm.fit(data)
labels = gmm.predict_proba(data)
x = gmm.predict(data)
print(labels)
# 分类结果
data = data.values
plt.scatter(data[:,0],data[:,1],c=x,cmap='rainbow')
plt.show()


案例分析2
数据:使用sklearn.make_blobs自动生成
第一次GMM和K-means对比,数据1
plt.rcParams['axes.unicode_minus'] = False#解决不显示负数问题
# n_samples:表示数据样本点个数,centers :数据产生的中心点个数,random_state:随机生成的种子,方便后期复现
X,y_true = make_blobs(n_samples=800,centers=4,random_state=11)
# 查看的生成的数据
print(X)
plt.scatter(X[:,0],X[:,1])
plt.show()
kmeans = KMeans(n_clusters=4)
kmeans.fit(data)
y_kmeans = kmeans.predict(data)
# 第一个数据集的k-means
plt.scatter(data[:,0],data[:,1],c=y_kmeans,s=50,cmap='viridis')
plt.show()
centers = kmeans.cluster_centers_
print(centers)
# 第一个数据集的GMM
gmm = GaussianMixture(n_components=4,random_state=1)
gmm.fit(data)
labels = gmm.predict(data)
plt.scatter(data[:,0],data[:,1],c=labels,s=40,cmap='viridis')
plt.show()
数据1效果

k-means效果

GMM效果:

第二次GMM和K-means对比,数据2
# 第二次制作数据集
rng = np.random.RandomState(13)
# randn:生成随机的m*n的随机项矩阵 生成Y为随机的矩阵
Y = np.dot(X,rng.randn(2,2))
plt.scatter(Y[:,0],Y[:,1])
plt.show()
# k-means
kmeansy = KMeans(n_clusters=4,random_state=1)
kmeansy.fit(dataY)
datay_kmeans = kmeansy.predict(dataY)
plt.scatter(dataY[:,0],dataY[:,1],c=datay_kmeans,s=40,cmap='viridis')
plt.show()
# GMM
gmmY = GaussianMixture(n_components=4)
gmmY.fit(dataY)
labelsY = gmmY.predict(dataY)
plt.scatter(dataY[:,0],dataY[:,1],c=labelsY,s=40,cmap='viridis')
plt.show()
数据二效果
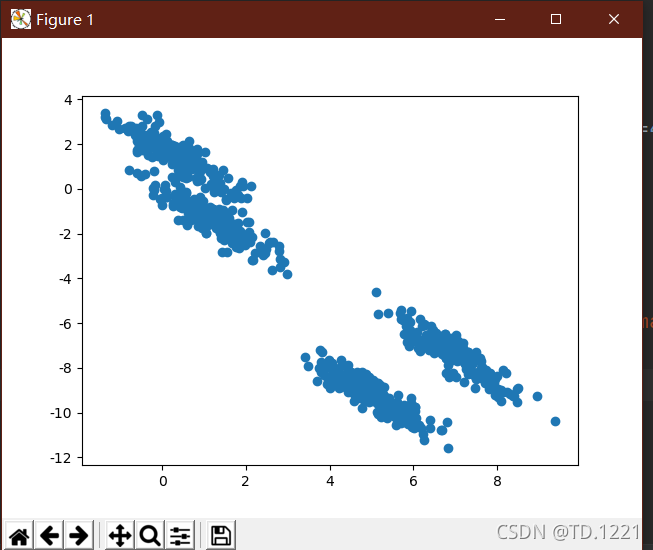
k-means效果
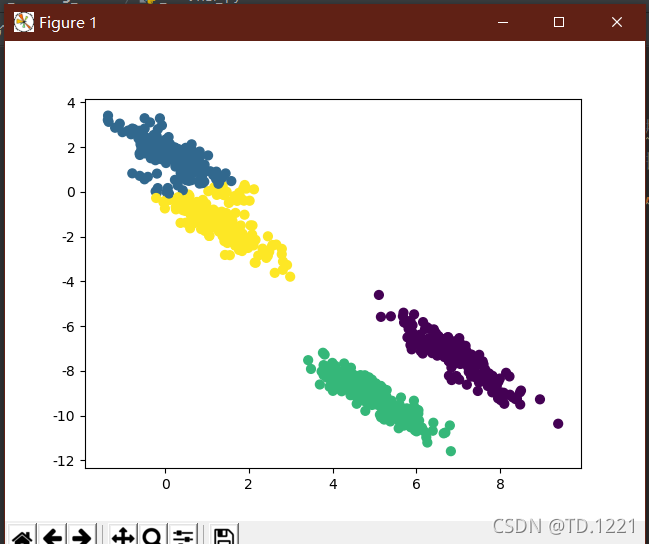
GMM效果

总结
第一次对比效果两种算法所得结果差不多
当第二次稍复杂时,GMM算法的聚类效果明显要比k-means好,具体请看左上角部分