垃圾收集算法
1、标记-清除算法(Mark-Sweep)。首先标记处所有需要回收的对象,在标记完成后统一回收。缺点:标记和清除两个过程都效率低;标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配大对象时,无法找到足够的连续内存而不得不提取触发GC。
2、复制算法。将可用内存按容量划分成大小相等的两块,每次只使用一块。当这一块使用完了,就将还存活着的对象复制到另一块上面,然后再把已使用过的内存一次清理掉。这样不用考虑内存碎片的问题,只要移动堆顶指针,按顺序分配即可,实现简单、运行高效。缺点:内存缩小为原来的一半。
现代商用虚拟机都采用这种算法回收新生代。而新生代中约98%的对象都是“朝生夕死”,所以不需按1:1划分。HotSpot默认Eden和Survivor是8:1,所以每次可用内存为90%。但我们没法保证每次回收只有不多于10%的对象存活,当Survivor空间不够时,需要依赖其他内存(这里指老年代)进行分配担保(直接进入老年代)。
缺点:如果对象存活率太高,要进行较多复制操作,效率低。且需要额外空间担保,老年代不能选用这种算法。
3、标记-整理算法。
过程与“标记-清除”一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。老年代因为对象存活率高、没有额外空间进行分配担保,必须使用“标记-清理”或“标记-整理”算法。
JVM垃圾收集器
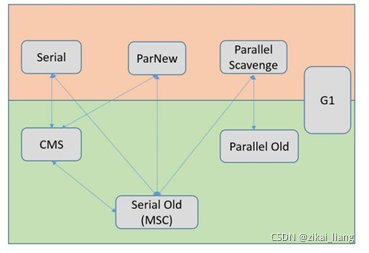
1、Serial是一个单线程收集器,在它进行垃圾收集时,必须暂停其他所有工作线程(Stop The World);简单高效,是虚拟机在Client模式下默认的新生代收集器(复制算法)。停顿时间在几十到一百多毫秒以内,可以接受。
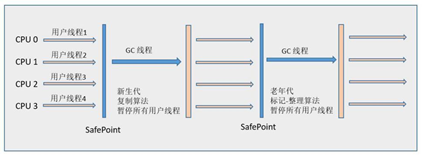
Serial/Serial Old收集器运行示意图
2、ParNew其实就是Serial收集器的多线程版本;ParNew收集器是许多运行在Server模式下的虚拟机中首选的新生代收集器。除去性能因素,很重要的原因是除了Serial收集器外,目前只有它能与CMS收集器(老年代)配合工作。(复制算法)
但是,在单CPU环境中,ParNew收集器绝对不会有比Serial收集器更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个CPU的环境中都不能百分之百地保证可以超越Serial收集器。然而,随着可以使用的CPU的数量的增加,它对于GC时系统资源的有效利用还是很有好处的。
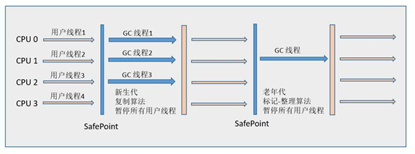
ParNew/Serial Old收集器运行示意图
3、Parallel Scavenge收集器是新生代垃圾收集器,使用复制算法,也是并行的多线程收集器。与ParNew收集器相比,很多相似之处,但是Parallel Scavenge收集器更关注可控制的吞吐量(运行用户代码时间/(运行用户代码+垃圾收集时间))。吞吐量越大,垃圾收集的时间越短,则用户代码则可以充分利用CPU资源,尽快完成程序的运算任务。
直观上,只要最大的垃圾收集停顿时间越小,吞吐量是越高的,但是GC停顿时间的缩短是以牺牲吞吐量和新生代空间作为代价的。比如原来10秒收集一次,每次停顿100毫秒,现在变成5秒收集一次,每次停顿70毫秒。停顿时间下降的同时,吞吐量也下降了。

4、Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,采用“标记-整理算法”进行回收。其运行过程与Serial收集器一样。
Serial Old收集器的主要意义也是在于给Client模式下的虚拟机使用。如果在Server模式下,那么它主要还有两大用途:一种用途是在JDK 1.5以及之前的版本中与Parallel Scavenge收集器搭配使用,另一种用途就是作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用。
5、Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法进行垃圾回收。其通常与Parallel Scavenge收集器配合使用,“吞吐量优先”收集器是这个组合的特点,在注重吞吐量和CPU资源敏感的场合,都可以使用这个组合。
6、**CMS(Concurrent Mark Sweep)**收集器是一种以获取最短回收停顿时间为目标的收集器,基于“标记-清除”算法,从总体上来说,CMS收集器的内存回收过程是与用户线程一起并发执行的(有的过程也是StopTheWorld)
CMS分为四个步骤:初始标记(GCRoots能直接关联到的对象,速度快,可达性分析,Stop The World),并发标记(可达性分析),重新标记(修正并发标记期间因用户程序继续运作而导致的变动,速度快,Stop The World),并发清除
CMS的优点很明显:并发收集、低停顿。由于进行垃圾收集的时间主要耗在并发标记与并发清除这两个过程,虽然初始标记和重新标记仍然需要暂停用户线程,但是从总体上看,这部分占用的时间相比其他两个步骤很小,所以可以认为是低停顿的。
缺点:
对CPU资源太敏感,这点可以这么理解,虽然在并发标记阶段用户线程没有暂停,但是由于收集器占用了一部分CPU资源,导致程序的响应速度变慢
CMS收集器无法处理浮动垃圾。所谓的“浮动垃圾”,就是在并发标记阶段,由于用户程序在运行,那么自然就会有新的垃圾产生,这部分垃圾被标记过后,CMS无法在当次集中处理它们(为什么?原因在于CMS是以获取最短停顿时间为目标的,自然不可能在一次垃圾处理过程中花费太多时间),只好在下一次GC的时候处理。这部分未处理的垃圾就称为“浮动垃圾”。由于垃圾收集阶段用户线程还需要运行,那就不能等老年代几乎全满了再收集,一般达到92%时就开始收集,而CMS运行期间预留的内存无法满足程序需要,就会出现“Concurrent Mode Failure”,此时将启动备用方案serial old
由于CMS收集器是基于“标记-清除”算法的(可能是为了时间短),前面说过这个算法会导致大量的空间碎片的产生,一旦空间碎片过多,大对象就没办法给其分配内存,那么即使内存还有剩余空间容纳这个大对象,但是却没有连续的足够大的空间放下这个对象,所以虚拟机就会触发一次Full GC。
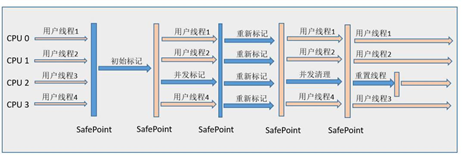
在使用CMS收集老年代时,新生代只能选用ParNew或者Serial收集器中的一个(CMS与其他不配套,其他的没有使用传统的GC收集器框架)
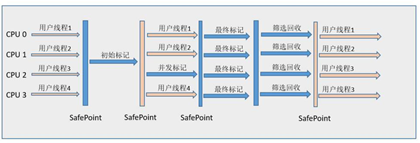
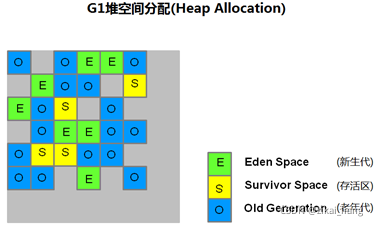
7、**G1(Garbage-First)**收集器,JDK1.7才开始商用。使用G1收集器时,Java堆内存布局与其他收集器有很大差别,它将整个Java堆分为多个大小相等的独立区域(Region),虽然还保留新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,他们都是Region(不需要连续)的集合。
特点:并行与并发。分代收集(不需要其他收集器配合)。空间整合(整体来看采用“标记-整理”,局部(两个Region之间)采用复制)。可预测的停顿。
G1跟踪各个Region里面的垃圾堆积价值大小(回收所获得的空间大小以及回收所需的时间),在后台维护一个优先列表,每次优先收集价值最大的Region(所以叫Garbage-First),从而保证了G1在有限时间内可以获取尽可能高的收集效率。
(老年代)过程:初始标记(Stop The World)、并发标记、最终标记(Stop The World)、筛选回收(Stop The World)
G1的YoungGC就是将E区和S区复制到灰色的空白区。
G1中有Humongous区(巨大区)用于存放比标准块大50%的对象
JVM垃圾回收机制
在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集(有eden和survivor供复制,有老年代做分配担保)。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来进行回收。
发生Minor GC,采用复制算法,发现
1、 复制对象无法全部放入Survivor,只好通过分配担保机制提前转移到老年代中
2、 大对象(长字符串或长数组等需要大量连续空间的对象)直接进入老年代(防止大对象在eden和Survivor中经常复制)通过-XX:PretenureSizeThreshold参数设置(如3MB),大于这个参数的直接进入老年代
3、 长期存活对象进入老年代(默认15岁)
Minor GC:新对象先放入eden区,当eden满了会触发Minor GC。
Full GC(等于Major GC):
1、每次进行Minor GC时,JVM会计算Survivor区移至老年区的对象的平均大小,如果这个值大于老年区的剩余值大小则进行一次Full GC
2、老年代空间不足时触发Full GC,只有在新生代对象转入或创建为大对象、大数组时才会出现不足的现象(大对象直接进入老年代),分配担保
3、永久代满(永久代JDK8被移除)
优化Full GC本身不会先进行Minor GC,我们可以配置,让Full GC之前先进行一次
Minor GC,因为老年代很多对象都会引用到新生代的对象,先进行一次Minor GC可以提高老年代GC的速度。
在jvm分带垃圾回收机制中,将应用程序可用的堆空间分为年轻代和老年代,又将年轻代分为eden区、from区、to区,新建对象总是在eden区中被创建,当eden区空间已满,就触发一次Minor gc,将还被使用的对象复制到from区,这样整个eden区都是未被使用的空间,可供继续创建对象,当eden区再次用完,再触发一次Minor gc,将eden区和from区还在被使用的对象复制到to区,下一次Minor gc则是将eden区和to区还被使用的对象复制到from区。因此,经过多次Minor gc,某些对象会在from区和to区多次复制,如果超过某个阈值对象还未被释放,则将对象复制到老年代。如果老年代空间也已用完,那么就会触发full gc,即所谓的全量回收。
永久代的垃圾回收主要有两部分:废弃常量和无用的类。如没有任何String对象引用“abc”。在大量使用反射、动态代理、CGlib等ByteCode框架,动态生成JSP以及OSGi这类频繁自定义ClassLoader的场景都需要虚拟机具备类卸载功能(回收永久代),以保证永久代不会溢出。
JVM参数
java -Xms256m -Xmx1024m在命令行
eclipse、tomcat都是java写的程序,它们也使用jvm,它们相当于jvm的一部分,我们的程序在它们之上运行,所以可以通过它们设置jvm参数。开两个java程序会启动两个jvm实例。
修改垃圾收集器:-XX:+UseParNewGC(在eclipse或Tomcat修改catalina.bat文件)
查看使用的垃圾收集器:可以通过命令行输入:jvisualvm,打开Java VisualVm查看,
Eclipse中,-XX:+UseG1GC,默认使用G1

Eclipse默认堆大小256m到1024m
Tomcat初始堆大小128mb(8GB/64)(开启tomcat进入localhost:8080后,点击server status后查看)

JVM初始分配的堆内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的堆内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
首先JVM内存限制于实际的最大物理内存,假设物理内存无限大的话,JVM内存的最大值跟操作系统有很大的关系。简单的说就32位处理器虽然可控内存空间有4GB,但是具体的操作系统会给一个限制,
这个限制一般是2GB-3GB(一般来说Windows系统下为1.5G-2G,Linux系统下为2G-3G),而64bit以上的处理器就不会有限制了。
Tomcat修改堆大小,修改catalina.bat文件
加上这句

或打开tomcat8w.exe,根据图形化界面修改
-Xms :设置Java堆栈的初始化大小,默认物理内存的1/64(<1GB)
-Xmx :设置最大的java堆大小,默认物理内存的1/4(<1GB)
-Xmn :设置年轻代区大小,整个堆大小=年轻代大小 + 年老代大小 + 持久代大小。增大年轻代后会减小老年代
-Xss :设置java线程堆栈大小,JDK5.0以后每个线程堆栈大小为1M,以前为256K
-XX:PermSize:设置永久代初始大小,默认物理内存的1/64(<1GB)
-XX:MaxPermSize :设置永久代最大大小,默认物理内存的1/4(<1GB)
-XX:NewRatio :设置年轻代和老年代的比值,默认4
-XX:NewSize :设置年轻代的大小(JDK1.3/1.4)
-XX:SurvivorRatio=n :设置年轻代中eden与Survivor比值,默认8
-XX:MaxTenuringThreshold=0:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.
-XX:PretenureSizeThreshold参数设置(如3MB),大于这个参数的直接进入老年代
java -Xmx3550m -Xms3550m -Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
发现虚拟机频繁GC,扩大堆大小,使用jconsole或jvisualvm查看