Inductive Representation Learning on Large Graphs
���ķ�����NIPS 2017.GraphSAGE��ʱ��ͱ����϶���������š�
abstract
����ͼ�ĵ�άǶ����кܴ��Ӧ�ü�ֵ�������ִ�ķ�����Ҫ��ͼ�е����нڵ���ѵ��ʱ������,��������transductive��,����Ȼ�ط�����δ�����Ľڵ��ϡ�������������GraphSAGE,һ��inductive�Ŀ��,���ýڵ�������Ϣ��Ϊδ�������������ɽڵ�embeddings������ͨ������ѵ��ÿ���ڵ��embedding,����ͨ���ӽڵ�ľֲ��ھ��ϲ����;ۺ�������ѧϰ��������embedding�����ǵ��㷨������inductive �ڵ��������ݼ��ϳ�Խ��������strong baselines:���ǻ������ĺ� Reddit ���ӵ��ݻ���Ϣͼ�е����ݶԿ������Ľڵ�������з���,ͬʱ���DZ������ǵ��㷨�����ƹ㵽��ȫδ֪��ͼͨ��ʹ�õ�����-�����ʽ����Ķ�ͼ���ݼ���
1.introduction
�ڵ�Ƕ�뷽���Ļ���idea��:ʹ��ά���½����������ڵ���ھӵĸ�γ��Ϣ����һ���ܼ�������Ƕ���ϡ�Ȼ��,֮ǰ�Ĺ������۽��ڴӵ����̶�ͼ��ѧϰ�ڵ�embedding,��������ʵ��Ӧ����Ҫ��δ֪�ڵ��Ͽ��ٻ�ȡembedding,�����Ǵ�ȫ�µ�ͼ�ϡ�����inductive���������ڸ�������,�����Ļ���ѧϰϵͳ�DZ�Ҫ��,������ͼ�ݻ��ͳ�������δ�����Ľڵ�֮ʱ��һ�����ɽڵ�Ƕ��Ĺ��ɷ���(inductive approach)Ҳ�ٽ�������ͬ������ʽ��ͼ֮��ķ���:����,����ѵ������ģ������ĵ�����-�����ʽ���ͼ�ϵ�Ƕ��������,Ȼ��ʹ�����־���ѵ����ģ�����ɵ�Ϊ�����������ռ����������ɽڵ�Ƕ�롣
���ֹ��ɵĽڵ�Ƕ�뷽������,��transductive setting���,����δ֪�ڵ���Ҫ���¹۲쵽��ͼ��ԭ��ѵ���õ��㷨�Ľڵ��Ƕ����ж��롣inductive ��ܱ���ѧ��ʶ��ڵ��ھӵĽṹ�����Լ���ʾ�ڵ�ľֲ�����,�Լ��ڵ��ȫ��λ�á�
�ִ�Ľڵ�Ƕ�뷽��������������transductive������ͨ������ֽ�ķ����ڵ����̶�ͼ����ɶ�ÿ���ڵ��Ƕ�빤����Ȼ����Щ�������Ա��Ľ�Ϊinductive setting,��Ϊ��Щ�Ľ���Ҫ��ļ���������֮,�ִ��GCN����Ӧ���ڹ̶�ͼ�ϵ�transductive setting�������о����ǽ�GCN��չ���ල��inductive learning,�Լ���GCN�ƹ㵽ʹ�ÿ�ѵ���ľۺϺ���(���˾�����ѵ��֮��)��
present work:
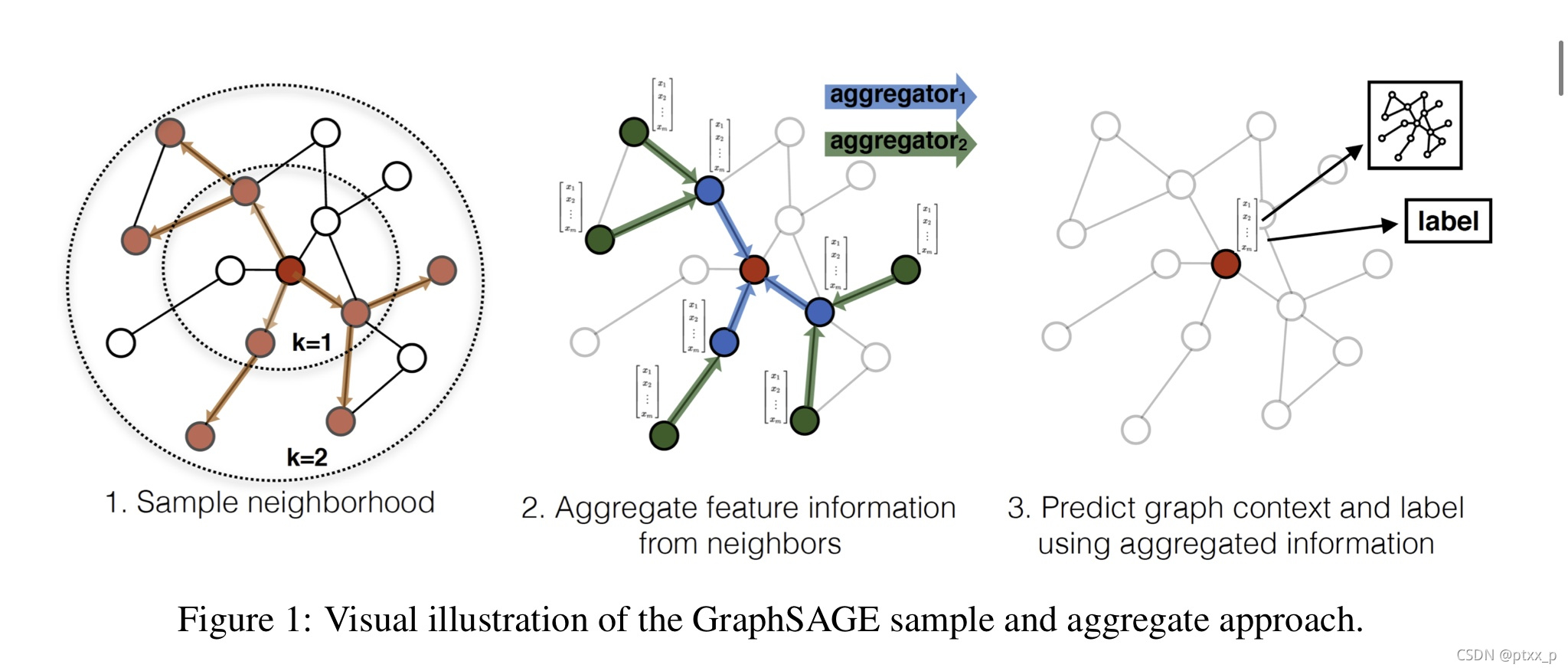
���������һ��ͨ�ÿ��GraphSAGE(sample and aggregate),������inductive node embedding������ͳ�Ļ��ھ���ֽ��embedding����,���������˽ڵ������,Ϊ�˶�δ֪�ڵ����Ƕ�뷽�̵�ѧϰ��ͨ�����ڵ���������ѧϰ�㷨,����ͬʱѧϰ���ھӽڵ�����˽ṹ�Լ��ھӽڵ�������ֲ������ǵķ���Ҳ��������û��������Ϣ��ͼ��
���Ƕ�ÿ���ڵ�ѧϰһ��embedding����,����ѵ��һ��aggregator functions�ļ������ӽڵ�ľֲ��ھ��Ͼۺ�������Ϣ��ÿ��aggregator function�Ӳ�ͬ�������ھ��Ͼۺ���Ϣ���ڲ��Խ�,ͨ��ѧϰ���ľۺϺ�����Ϊû�����Ľڵ�����embedding�����������һ���ල��ʧ����������GraphSAGE����������ļල�½���ѵ��,������Ҳ�������мල������½���ѵ����
ͨ��ʵ��,������֤�����ǵķ����ܹ�Ϊû�����Ľڵ�����embeddings�Լ��ܴ�̶��ϳ�Խ������baselines�����,���ǻ���֤�����ǵķ����ı�������,ͨ�����۷���,GraphSAGE����ѧϰͼ�нڵ�Ľṹ��Ϣ������,�������ǻ��ڽڵ��ѧϰ��
3.proposed method:GraphSAGE
���Ƿ����ĺ���idea��:��δӽڵ�ľֲ��ھ�ѧϰȥ�ۺ���Ϣ��
3.1 embedding generation(forward propagation)algorithm

���������Ѿ�ѧϰ�� K K K��aggregator functions�IJ���( A G G R E G A T O R k , ? k �� { 1 , . . . , K } AGGREGATOR_k,\forall k \in \{1,...,K\} AGGREGATORk?,?k��{1,...,K}),�����ھӽڵ��оۺ���Ϣ,��ʵ����һ��Ȩ�ؾ���ļ��� W k , ? k �� { 1 , . . . , K } W^k,\forall k \in \{1,...,K\} Wk,?k��{1,...,K},������ģ�͵IJ�ͬ��֮��ۺ���Ϣ��
�㷨1�е��������̳�������ʱ,�ڵ���Խ��Խ��Ϣֱ������ȫͼ����Ϣ��
��ν��㷨1�ƹ㵽minibatch setting:��������ڵ�ļ���,�������Ȳ�������Ҫ���ھӼ���,Ȼ���ٽ����ھӵľۺϲ���,���Dz��Ƕ����еĽڵ㶼���е�������,����ֻ��������ÿ��ݹ�ı�����
3.1.1 relation to the Weisfeiler-Lehman Isomorphism Test
Weisfeiler-Lehman Isomorphism Test:���ڲ�������ͼ��ͬ���ԡ�������һ�����������ͼ��ͬ���ġ�����test��ijЩ������������,�����ڴ��������������õġ�GraphSAGE���Ա�������WL test�������ıƽ�,���DZ����ڽڵ��embedding����,������ͬ������֤��WL test��GraphSAGEѧϰ�ھӽڵ�����˽ṹ�����ۻ�����
����� K = �O V �O K=|V| K=�OV�O,�����е�Ȩ�ؾ�����Ϊһ��,ʹ�ú��ʵ������Ե�hash����������ۺϺ������Ǿ͵õ���Weisfeiler-Lehman Isomorphism Test��
3.1.2 neighborhood definition
�ڱ�����,���Dz����˹̶���Ŀ���ھ�,������ʹ��ȫ�����ھӽڵ㡣per-batch�Ŀռ��ʱ�临�Ӷ�Ϊ O ( �� i = 1 K S i ) O(\sum_{i=1}^K S_i) O(��i=1K?Si?),���� S i , i �� { 1 , . . . , K } S_i,i \in \{1,...,K\} Si?,i��{1,...,K}�Լ� K K K�����û��Զ���ij�����
3.2 learning the parameters of GraphSAGE
������ȫ�ල��ѧϰ�����ֻ���ͼ����ʧ����ʹ������Ľڵ�������Ƶı���,����Զ�Ľڵ�ı�ʾ��߶Ȳ�ͬ��
���� v v v��һ���ڹ̶����ȵ���������ϵ� u u u�������ֵĽڵ�, P n P_n Pn?��һ���������ֲ�, Q Q Q������������������Ŀ��
�����ල����ʧ����������ʱ���滻����ǿ������task-specific��Ŀ��(�罻������ʧ)��
3.3 aggregator architectures
�㷨1�еľۺϺ�����������������Ľڵ㼯��,��˾ۺϺ��������ǶԳƵ�(����Ľڵ�˳��Ӱ����)ͬʱ���ֿ�ѵ���Լ����ָ߱����������ۺϺ����ĶԳ����Ա�֤�����ǵ�������ģ�Ϳ��Ա�ѵ����Ӧ�õ�����˳��Ľڵ��ھ���������֮�ϡ�������֤��һ�����ֺ�ѡ�ľۺϺ���:
3.3.1 mean aggregator
���Խ��㷨1���������滻�����¹�ʽ:
3.3.2 LSTM aggregator
��mean aggregator���,���ֻ���LSTM�ľۺ������и��õı���������������Ҫע�����,LSTM�����ϲ����ǶԳƵ�(�����Ǽ��㲻���,������˳��ĸ���),��ΪLSTM��������һ�����С����ǸĽ�lstm������ļ�����,ͨ����lstmӦ�õ��Խڵ��ھӵ����ϴ���ϡ�
3.3.3 pooling aggregator
�����ܵ����־ۺ���ͬʱ���жԳ��ԺͿ�ѵ���ԡ���pooling������,ÿ���ھ�������������ͨ��һ��ȫ���ӵ������硣
������,�����MLP���Ա���Ϊ�Ƕ��ھӼ��ϵĽڵ����������������ʵ��,�κζԳƵ��������̶�������������max����,����mean,������ʵ��֤��,��������ֲ�����û��ʲôʵ��Ч���IJ��졣
4.experiments
4.1 inductive learning on evolving graphs:citation and Reddit data
�ʼ������ʵ�������ݻ���Ϣͼ�ϵĽڵ��������,��ͨ������������ϵͳ���,��������unseen data��GraphSAGE��Խ������baselineģ�͵ı��֡�
4.2 generalizing graphs:protein-protein interactions
GraphSAGE��Խ������baselineģ�͵ı��֡�
4.3 runtime and parameter sensitivity
����ͨ���²��������˸߷���,GraphSAGE��Ȼ�ܹ����ֺ�ǿ��Ԥ��ȷ��,���Ҵ���ʡ������ʱ�䡣

4.4 summary comparison between the different aggregator architectures
LSTM-��pool-based aggregator������ѡ�����LSTM-basedҪ��poll���öࡣ
5. theoretical analysis
clustering coefficients:��ӳ�˽ڵ��һ���ھӵľۼ��̶ȡ�����֤�����㷨1���ж�����̶ȵ�ȷ�ȵ�ͼ��clustering coefficients��Ԥ���������
theorem 1:����һ�����
��
?
\theta^*
��?for �㷨1,ʹ����
K
=
4
K=4
K=4�ĵ���֮��: