һ,��������
��java��,���dz��õIJ���������:
1)˳��(����)����
2)���ֲ���/�۰����
3)��ֵ����
4)쳲���������
��,˳��(����)����
**����:**��һ������:{1,9,11,-1,34,89},�ж��������Ƿ����ij����ֵ
**Ҫ��:**����ҵ���,����ʾ�ҵ�,�������±�ֵ
1.����ʵ��
package com.atguigu.search;
public class SeqSearch {
public static void main(String[] args) {
int arr[] = {1,9,11,-1,34,89}; //û��˳�������
int index = seqSearch(arr,11);
if (index == -1) {
System.out.println("û���ҵ�");
} else {
System.out.println("�ҵ���,�±�=" + index);
}
}
/**
* ��������ʵ�ֵ����Բ������ҵ�һ������������ֵ�ͷ���
* @param arr
* @param value
* @return
*/
public static int seqSearch(int[] arr,int value) {
//���Բ�������һ�ȶ�,��������ֵͬ,�ͷ����±�
for (int i = 0; i < arr.length; i++) {
if (arr[i] == value) {
return i;
}
}
return -1;
}
}
��,���ֲ���
**����:**���һ������������ж��ֲ���{1,8,10,89,1000,1234},����һ���������������Ƿ���ڴ���,���Ҹ����±�,���û�о���ʾ��û���������
1.˼·����
���ֲ��ұ��뽨��������������������ʵ��,�����������
���������Ǵ�С�����˳��
1)����ȷ����������м��±�
mid = (left + right) / 2
2)Ȼ������Ҫ���ҵ���findVal �� arr[mid] �Ƚ�
2.1)findVal > arr[mid],˵����Ҫ���ҵ�����mid���ұ�,�����Ҫ�ݹ�����Ҳ���
2.2)findVal < arr[mid],˵����Ҫ���ҵ�����mid�����,�����Ҫ�ݹ���������
2.3)findVal == arr[mid],˵���ҵ�,����
ʲôʱ��������Ҫ�����ݹ�
1)�ҵ��ͽ����ݹ�
2)�ݹ�����������,��Ȼû���ҵ�findVal,Ҳ��Ҫ�����ݹ�,��left > right ����Ҫ�˳�
2.����ʵ��
//ע��:ʹ�ö��ֲ��ҵ�ǰ���Ǹ����������
public class BinarySearch {
public static void main(String[] args) {
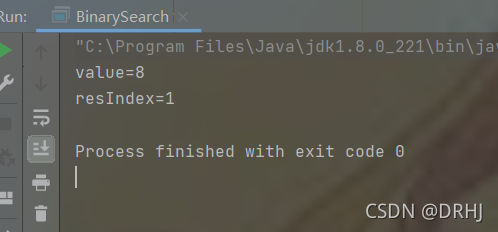
int[] arr = {1,8,10,89,1000,1234};
int value = 8;
int index = binarySearch(arr,0,arr.length - 1, value);
System.out.println("value=" + value);
System.out.println("resIndex=" + index);
}
//���ֲ��ҷ�
/**
*
* @param arr ����
* @param left ��ߵ�����
* @param right �ұߵ�����
* @param findVal Ҫ���ҵ���
* @return ����ҵ��ͷ����±�,���û���ҵ�,�ͷ���-1
*/
public static int binarySearch(int[] arr,int left,int right,int findVal) {
//��left > right ʱ,˵��û�еݹ���������,����û���ҵ�
if (left > right) {
return -1;
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if (findVal > midVal) { //���ҵݹ�
return binarySearch(arr,mid + 1,right,findVal);
} else if (findVal < midVal) {
return binarySearch(arr,left,mid - 1,findVal);
} else {
return mid;
}
//return -1;
}
}
3.����
4.��������
**Ҫ��:**���һ������������ж��ֲ���{1,8,10,89,1000,1000,1000,1234},��1000�������±궼��ӡ������
˼·����
1)���ҵ�mid����ֵ,��Ҫ���Ϸ���
2)��mid����ֵ�����ɨ��,����������1000��Ԫ�ص��±�,���뵽����ArrayList
3)��mid����ֵ���ұ�ɨ��,����������1000��Ԫ�ص��±�,���뵽����ArrayList
4)��ArrayList����
����ʵ��
//ע��:ʹ�ö��ֲ��ҵ�ǰ���Ǹ����������
public class BinarySearch {
public static void main(String[] args) {
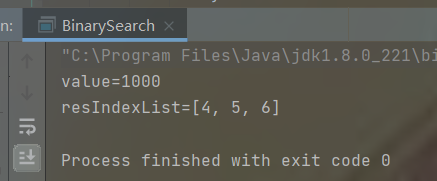
int[] arr = {1,8,10,89,1000,1000,1000,1234};
int value = 1000;
List<Integer> resIndexList = binarySearch2(arr,0,arr.length - 1, value);
System.out.println("value=" + value);
System.out.println("resIndexList=" + resIndexList);
}
//���ֲ��ҷ�
/**
*
* @param arr ����
* @param left ��ߵ�����
* @param right �ұߵ�����
* @param findVal Ҫ���ҵ���
* @return ����ҵ��ͷ����±�,���û���ҵ�,�ͷ���-1
*/
public static int binarySearch(int[] arr,int left,int right,int findVal) {
//��left > right ʱ,˵��û�еݹ���������,����û���ҵ�
if (left > right) {
return -1;
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if (findVal > midVal) { //���ҵݹ�
return binarySearch(arr,mid + 1,right,findVal);
} else if (findVal < midVal) {
return binarySearch(arr,left,mid - 1,findVal);
} else {
return mid;
}
//return -1;
}
/**
* 1)���ҵ�mid����ֵ,��Ҫ���Ϸ���
* 2)��mid����ֵ�����ɨ��,����������1000��Ԫ�ص��±�,���뵽����ArrayList
* 3)��mid����ֵ���ұ�ɨ��,����������1000��Ԫ�ص��±�,���뵽����ArrayList
* 4)��ArrayList����
* @param arr
* @param left
* @param right
* @param findVal
* @return
*/
public static List binarySearch2(int[] arr, int left, int right, int findVal) {
//��left > right ʱ,˵��û�еݹ���������,����û���ҵ�
if (left > right) {
return new ArrayList<Integer>();
}
int mid = (left + right) / 2;
int midVal = arr[mid];
if (findVal > midVal) { //���ҵݹ�
return binarySearch2(arr,mid + 1,right,findVal);
} else if (findVal < midVal) {
return binarySearch2(arr,left,mid - 1,findVal);
} else {
List<Integer> resIndexList = new ArrayList<>();
int temp = mid - 1;
while (true) {
if (temp < 0 || arr[temp] != findVal) { //�˳�
break;
}
//����,��temp���뵽resIndexList
resIndexList.add(temp);
temp -= 1; //temp����
}
resIndexList.add(mid);
temp = mid + 1;
while (true) {
if (temp > arr.length - 1 || arr[temp] != findVal) { //�˳�
break;
}
//����,��temp���뵽resIndexList
resIndexList.add(temp);
temp += 1; //temp����
}
return resIndexList;
}
//return -1;
}
}
����
��,��ֵ����
1.����
����ѯ����{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20},�����Dz�ѯ����1ʱ,ʹ�ö��ֲ���ִ����4��,��Ȼ�е㡰�����㡱,��ô�Ƿ�������Ӧ�ķ������ٶ�λ1��?
2.��ֵ����ԭ������
1)��ֵ�����㷨�����ڶ��ֲ���,��ͬ�IJ�ֵ����ÿ������Ӧmid����ʼ����
2)���۰�����е�mid�����Ĺ�ʽ,low��ʾ�������,high��ʾ�ұ�����,key������Ҫ���ҵ�ֵ
mid = (low + high) / 2 = low + (high - low) / 2 �ij� mid = low + (key - arr[low] ) / (a[high] - a[low]) * (high - low)
3)int midIndex = low + (high - low )* (key - arr[low] ) / (a[high] - a[low]);/��ֵ����/
��Ӧǰ����빫ʽ:
int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]);
3.����ʵ��
public class InsertValueSearch {
public static void main(String[] args) {
int[] arr = new int[100];
for (int i = 0; i < 100; i++) {
arr[i] = i + 1;
}
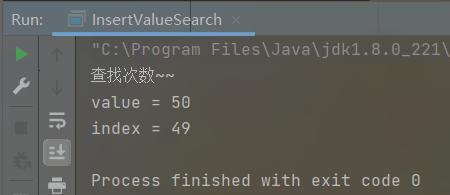
int value = 50;
// int[] arr = {1,100,1000,10000,10000};
int index = insertValueSearch(arr,0,arr.length - 1,value);
System.out.println("value = " + value);
System.out.println("index = " + index);
//System.out.println(Arrays.toString(arr));
}
//��д��ֵ�����㷨
//Ҫ�������������
/**
*
* @param arr ����
* @param left �������
* @param right �ұ�����
* @param findVal ����ֵ
* @return ����ҵ�,�ͷ��ض�Ӧ���±�,���û���ҵ�,����-1
*/
public static int insertValueSearch(int[] arr,int left,int right,int findVal) {
System.out.println("���Ҵ���~~");
//ע��:findVal < arr[0] findVal > arr[arr.length - 1] ������Ҫ,�������ǵõ���mid����Խ��
if (left > right || findVal < arr[0] || findVal > arr[arr.length - 1]) {
return -1;
}
//���mid
int mid = left + (right - left) * (findVal - arr[left]) / (arr[right] - arr[left]);
int midVal = arr[mid];
if (findVal > midVal) { //˵��Ӧ�����ұ߲���
return insertValueSearch(arr,mid + 1,right,findVal);
} else if (findVal < midVal) {
return insertValueSearch(arr,left,mid - 1,findVal);
} else {
return mid;
}
}
}
4.����
5.ע������
1)ͬ��Ҫ���Ƕ�����������в��ҡ�
2)�����������ϴ�,�ؼ��ֲַ��ȽϾ��ȵIJ��ұ���˵,���ò�ֵ����,�ٶȽϿ졣
3)�ؼ��ֲַ�������(��Ծ�Ժܴ�,����1��10000,�ͺܴ���)�������,�÷�����һ�����۰�(����)����Ҫ�á�
��,쳲�����(�ƽ�ָ)����
1.��������
1)�ƽ�ָ����ָ��һ���߶ηָ�Ϊ������,ʹ����һ������ȫ��֮�ȵ�����һ�������ⲿ��֮�ȡ�ȡ��ǰ�������ֵĽ���ֵ��0.618�����ڰ��˱�����Ƶ�����ʮ������,��˳�Ϊ�ƽ�ָ�,Ҳ��Ϊ����ȡ�����һ�����������,��������벻����Ч����
2)쳲���������{1,1,2,3,5,8,13,21,34,55}����쳲��������е��������ڵı���,���ӽ��ƽ�ָ�ֵ0.618��
2.ԭ��
쳲���������ԭ����ǰ��������,�����ı����м���(mid)��λ��,mid�������м�����Dz�ֵ�õ�,����λ�ڻƽ�ָ�㸽��,��mid = low + F(k - 1) - 1(F����쳲���������),����ͼ��ʾ
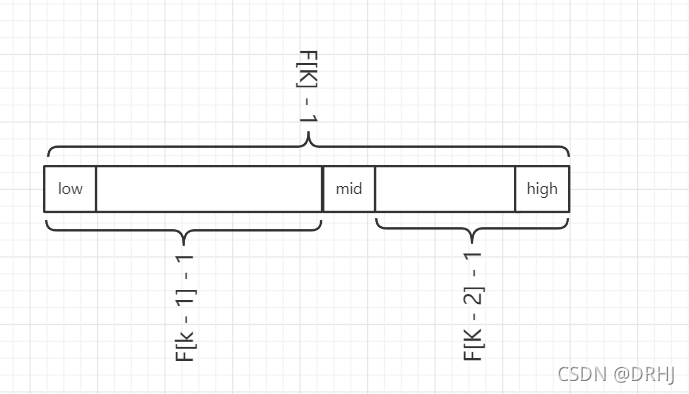
��F[k - 1] - 1������
1)��쳲���������F[k] = F[k - 1] + F[k - 2]������,���Եõ�(F[k] - 1)= (F[k - 1] - 1)+ (F[k - 2] - 1)+ 1����ʽ˵��:ֻҪ˳����ij���ΪF[k] - 1,����Խ��ñ���ΪF[k - 1] - 1 �� F[k - 2] - 1 ������,������ͼ��ʾ���Ӷ��м�λ��Ϊ mid = low + F(k - 1) - 1
2)���Ƶ�,ÿһ�Ӷ�Ҳ��������ͬ�ķ�ʽ�ָ�
3)��˳�������n��һ���պõ���F[k] - 1,������Ҫ��ԭ����˳�������n���ӵ�F[k] - 1�������kֵֻҪ��ʹ��F[k] - 1,ǡ�ô��ڻ����n����,�����´���õ�,˳����������Ӻ�,������λ��(��n + 1��F[k] - 1λ��),����Ϊnλ�õ�ֵ���ɡ�
while(n > fib(k) - 1)
k++;
3.����ʵ��
public class FibonacciSearch {
public static int maxSize = 20;
public static void main(String[] args) {
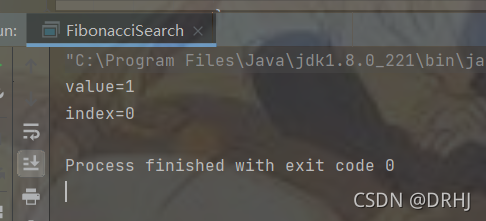
int[] arr = {1,8,9,10,89,1000,1234};
int value = 1;
int index = fibSearch(arr,value);
System.out.println("value=" + value);
System.out.println("index=" + index);
}
//����������Ҫʹ�õ�쳲���������,���������Ҫ�Ȼ�ȡ��һ��쳲���������
//ʹ�÷ǵݹ�ķ�ʽ�õ�һ��쳲���������
public static int[] fib() {
int[] f = new int[maxSize];
f[0] = 1;
f[1] = 1;
for (int i = 2; i < maxSize; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
//��д쳲����������㷨
//ʹ�÷ǵݹ�ķ�ʽ��д�㷨
/**
*
* @param a ����
* @param key ������Ҫ���ҵĹؼ���(ֵ)
* @return ���ض�Ӧ���±�,���û�з���-1
*/
public static int fibSearch(int[] a,int key) {
int low = 0;
int high = a.length - 1;
int k = 0; //��ʾ쳲������ָ���ֵ���±�
int mid = 0; //���mid��ֵ
int[] f = fib(); //��ȡ��쳲���������
//��ȡ��쳲������ָ���ֵ���±�
while (high > f[k] - 1) {
k++;
}
//��Ϊf[k]ֵ���ܴ���a�ij���,���������Ҫʹ��Arrays��,����һ���µ�����,��ָ��a[]
//����IJ��ֻ�ʹ��0���
int[] temp = Arrays.copyOf(a,f[k]);
//ʵ������Ҫʹ��a�������������temp
//����: temp = {1,8,10,89,1000,1234,0,0,0} => {1,8,10,89,1000,1234,1234,1234,1234}
for (int i = high + 1; i < temp.length; i++) {
temp[i] = a[high];
}
//ʹ��while��ѭ������,�ҵ����ǵ���key
while (low <= high) { //ֻҪ�����������,�Ϳ��Բ���
mid = low + f[k - 1] - 1;
if (key < temp[mid]) { //����Ӧ�ü����������ǰ�����(���)
high = mid - 1;
//˵��:
//1.ȫ��Ԫ�� = ǰ���Ԫ�� + ����Ԫ��
//2. f[k] = f[k-1] + f[k-2]
//��Ϊǰ����f[k - 1]��Ԫ��,���Կ��Լ������ f[k-1] = f[k-2] + f[k-3]
//����f[k-1] ��ǰ���������k--
//���´�ѭ��mid = f[k-1-1] - 1
k--;
} else if (key > temp[mid]) { //����Ӧ�ü���������ĺ������(�ұ�)
low = mid + 1;
//˵��:
//1.ȫ��Ԫ�� = ǰ���Ԫ�� + ���Ԫ��
//2.f[k] = f[k-1] + f[k-2]
//3.��Ϊ����������f[k-2] ���Կ��Լ������ f[k-1] = f[k-3] + f[k-4]
//4.����f[k-2]��ǰ����в��� k -= 2
//5.���´�ѭ��mid = f[k - 1 - 2] - 1
k -= 2;
} else { //�ҵ�
//��Ҫȷ��,���ص����ĸ��±�
if (mid <= high) {
return mid;
} else {
return high;
}
}
}
return -1;
}
}
�ɻ���
**�ɻ�1:**Ϊʲô����߲�ѯʱ,k�C,���ұ߲�ѯ��ʱ��,k-=2;
�����ѯ��ʱ���ʱ��,���赱ǰmidΪlow+f(k)-1,
��������ѯ,�������low��low+f(k)-1֮��,������low+f(k)-1,����low+f(k-1)-1��Ϊ���������ĵ�,��k�C;
������Ҳ�ѯ,�������low+f(k)-1��low+f(k+1)-1֮��,������low+f(k)-1��low+f(k+1)-1,��ʱ,low��=low+f(k),���ʱ�����ʹ��k�C,��mid = low + f(k) + f(k-1) - 1 = low + f(k+1) - 1,��Ȼ��ѯ��������֮ǰ�����,��k-=2���ܱ�֤���mid��low+f(k)-1��low+f(k+1)-1֮�䡣
**�ɻ�2:**Ϊʲô�������и��ж�����,��mid>highʱ,�����high
��Ϊ������������ݵĵ�ԭʼ�������������f(k)����,�ͻ��������,������������ԭ�������һλԪ�����,���Ե���ѯ���������һλԪ��,Ҫ����high��ԭ�������һλ������
4.����