一、读程序,看输出―异常
public class TestOrder {
static void methodA() {
try {
System.out.println("进入方法A");
throw new RuntimeException("制造异常");
}finally {
System.out.println("用A方法的finally");
} }
static void methodB() {
try {
System.out.println("进入方法B");
return;
} finally {
System.out.println("调用B方法的finally");
} }
public static void main(String[] args) {
try {
methodA();
} catch (Exception e) {
System.out.println(e.getMessage());
}
methodB();
}
}
注意方法的执行顺序
二、读程序,看输出
public class CollectionDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add(1);
list.add(2);
list.add(3);
updateList(list);
System.out.println(list);//
}
private static void updateList(List list) {
list.remove(2);
//list.remove(new Integer(2));
}
}
三、 Set集合添加数据的过程
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set);// 两个元素
set.add(new Person(1001,"CC"));//
System.out.println(set);
set.add(new Person(1001,"AA"));
System.out.println(set);

四、 迭代器的执行原理

五、 Set接口的主要实现类及其源理分析
HashSet、LinkedHashSet、TreeSet
1. 三者的区别
相同点:存储无序的、不重复的数据(无序不等于随机性)
HashSet:作为Set接口的主要实现类;线程不安全,可以存储null值
LinkedHashSet:作为HashSet子类,遍历其内部数据时,会按照添加的顺序遍历
TreeSet:可以按照添加对象的属性,进行排序
Set 判断两个对象是否相同不是使用 == 运算符,而是根据 equals() 方法
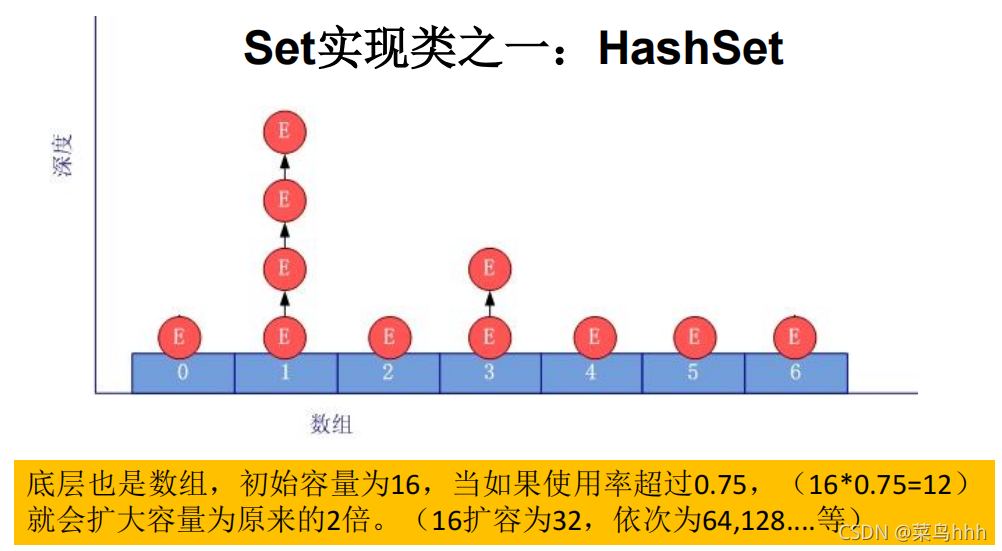
2. HashSet中add()操作的过程
对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”。
-
当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据 hashCode 值,通过某种散列函数决定该对象在 HashSet 底层数组中的存储位置。(这个散列函数会与底层数组的长度相计算得到在数组中的下标,并且这种散列函数计算还尽可能保证能均匀存储元素,越是散列分布,该散列函数设计的越好)
-
如果两个元素的hashCode()值相等,会再继续调用equals方法,如果equals方法结果为true,添加失败;如果为false,那么会保存该元素,但是该数组的位置已经有元素了,那么会通过链表的方式继续链接。
-
如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相等,hashSet 将会把它们存储在不同的位置,但依然可以添加成功。
3. LinkedHashSet
- LinkedHashSet 是 HashSet 的子类
- LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。但实际上在内存中排列还是无序的。
- 具有可预知迭代顺序的Set接口的哈希表和链接列表实现。
4. TreeSet
- TreeSet 是 SortedSet 接口的实现类,TreeSet 可以确保集合元素处于排序状态。
- TreeSet底层使用红黑树结构存储数据
- 向TreeSet添加数据时,要求是相同类的对象,因为TreeSet会对添加的对象进行排序,具有相同的属性
- 如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口。(实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过compareTo(Object obj) 方法的返回值来比较大小。 )
- TreeSet 两种排序方法:自然排序和定制排序。默认情况下,TreeSet 采用自然排序。
- 自然排序:TreeSet 会调用集合元素的 compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列
- 对于 TreeSet 集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过 compareTo(Object obj) 方法比较返回值。
- TreeSet和后面要讲的TreeMap采用红黑树的存储结构
六、读程序,看输出―参数传递
public class StringTest {
String str = new String("good");
char[] ch = { 't', 'e', 's', 't' };
public void change(String str, char ch[]) {
str = "test ok";// 由于String的不可变型,没有改变原来的
ch[0] = 'b';
}
public static void main(String[] args) {
StringTest ex = new StringTest();
ex.change(ex.str, ex.ch);
System.out.print(ex.str + " and ");//
System.out.println(ex.ch);//
}
}
七、读程序,看输出―String
String str = null;
StringBuffer sb = new StringBuffer();
sb.append(str);
System.out.println(sb.length());//
System.out.println(sb);//
StringBuffer sb1 = new StringBuffer(str);
System.out.println(sb1);//
看源码
八、负载因子值的大小,对HashMap有什么影响
- 负载因子的大小决定了HashMap的数据密度。
- 负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成查询或插入时的比较次数增多,性能会下降。
- 负载因子越小,就越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也就越短,查询和插入时比较的次数也越小,性能会更高。但是会浪费一定的内容空间。而且经常扩容也会影响性能,建议初始化预设大一点的空间。
- 按照其他语言的参考及研究经验,会考虑将负载因子设置为0.7~0.75,此时平均检索长度接近于常数。
九、HashMap的底层原理
1. JDK1.7中的
HashMap map = new HashMap();
在实例化以后,底层创建了一个长度为16的一位数组Entry[] table
map.put(key1,value1):
首先,调用key1所在的类的hashCode()方法计算出key1的哈希值,此哈希值经过某种计算之后,得到在Entry数组存放的位置
如果此位置上的数据为空,此时的key1-value1添加成功 -- 情况1
如果此位置不为空(意味着此位置上存在着一个或者多个(链表)数据),比较key1和已经存在的一个或者多个哈希值,如果key1的哈希值与其他的都不相同,则添加成功 -- 情况2
如果key1与已经存在的哈希值相同,则调用equals继续比较。
如果equals()方法返回false,则添加成功 --情况3
如果返回true,则使用value1替换相同key的value值
补充:此时key1-value1和原来的数据以链表的方式存储
在不断添加的过程中涉及到扩充问题,当超出临界值(且要存放的位置非空)默认的扩容方式:扩容为原来的两倍,再把原来的复制过去
2. JDK1.8实现方式的不同
HashMap map = new HashMap();
没有创建一个长度为16的一维数组
底层数组是Node[] 而非entry
首次调用put时,才创建一个长度为16的一维数组
当数组的索引的某一个位置上的链表形式存在的数据个数超过8,且当前数组的长度超过64,此时此索引位置上的数据改用红黑树存储
十、接口的一些注意点
/**
* 接口
* JDK1.7及以前:只能定义全局常量和抽象方法
* 全局常量:public static final 书写时可以省略
* 抽象方法:public abstract 书写时可以省略
* JDK1.8:除了定义全局常量和抽象方法,还可以定义静态方法、默认方法
* 接口中定义的静态方法,其实现的子类不能通过对象.方法名的方式调用,只能通过接口.方法名调用
* 实现类的对象可以调用默认方法
* 如果子类(或实现类)继承的父类和实现类的接口中声明了同名同参的方法,则默认调用的父类的(类优先原则)
* 若一个接口中定义了一个默认方法,而另外一个接口中也定义了一个同名同参数的方法(不管此方法是否是默认方法),在实现类同时实现了这两个接口时,会出现:接口冲突。
* ? 解决办法:实现类必须覆盖接口中同名同参数的方法,来解决冲突。
*
*
*
* 接口中不能定义构造器
* 如果实现类覆盖了接口中所有的抽象方法,则该实现类可以实例化,否则该实现类依然为一个抽象类
*
* 可以实现多个接口,先写extends,后写implements
* class A extends B implements C,D
* 接口之间可以继承,而且可以多继承
*/